2029 年までにミソス級モデルが世界中に普及する見込み(7 分読み)
この記事は、Anthropic の「Mythos」クラスモデルが 2029 年までに世界中に普及すると予測しつつ、消費者レベルでは知能の向上による実用性の限界(限界効用逓減)を指摘し、企業向けにはホワイトカラー業務の自動化における課題と可能性について分析している。
キーポイント
限界効用逓減の法則と消費者用途
モデルの知能が向上しても、料理やフィットネスなどの日常的な質問に対しては、前世代モデルとの差が体感できないほど小さく、消費者レベルでは「魔法のような変化」は期待できない。
企業向けホワイトカラー業務への影響
弁護士、会計士、カスタマーサービスなど多様なホワイトカラー業務において、AI はタスクの難易度に応じて段階的に導入されるが、過剰な知能は必ずしもパフォーマンス向上に直結しない。
特定領域での劇的進化と一般化の乖離
ソフトウェアエンジニアリングやゲーム戦略(ポケモン)など特定の複雑なタスクでは「Mythos」クラスモデルがゲームチェンジャーとなる一方、単純な注文業務などには大きな改善が見られない。
2029 年までの普及予測
Open-Weight モデルはフロンティアモデルに追いつくのに時間がかかるが、「Mythos」クラスモデルは 2029 年までに世界中に拡散し、産業構造を変えていくと予測されている。
AAIIの評価基準
Artificial Analysis Intelligence Index v4 (AAII) は多様なドメインにわたるモデル性能を測定する「ベンチマークのインデックスファンド」のような指標であり、議論において最も有用な評価の一つとされている。
Epoch Capabilities Indexの併用
本稿ではAAIIに加え、Epoch Capabilities Indexも有用な評価ツールとして言及されており、ソフトウェアエンジニアリングなどの特定分野における能力推移を把握する際に活用される。
モデル性能の継続的向上と限界
最先端モデルのパフォーマンスは時間とともに改善し続けており、将来的にもその傾向は続くが、知能への投資対効果には diminishing marginal returns(逓増する限界効用)の漸近線に達する段階がある。
影響分析・編集コメントを表示
影響分析
この記事は、AI ブームにおける過度な期待を冷静に分析し、技術的進歩が即座にすべての業務で劇的な成果を生むわけではないという現実(限界効用逓減)を指摘しています。特に、特定の高度なタスクでは革命をもたらす一方で、日常的な業務では変化が小さいという「二極化」の構造を示しており、企業や個人が AI 導入戦略を立てる上で、自社の業務内容に合わせた適切なモデル選定と期待値管理の重要性を浮き彫りにしています。
編集コメント
「Mythos」クラスの普及予測と、実際のユーザー体験における限界効用逓減の指摘は、AI 業界が過熱する中で非常に重要な冷静な視点を提供しています。企業は特定の高度タスクでの劇的変化に注目しつつも、日常業務への導入においては現実的な期待値を持つべきです。
モデルの能力は時間とともに向上するが、オープンウェイトモデルは最前線に遅れをとる
私はしばしば Claude に料理やフィットネス、自動車などに関する日常的な質問を投げかけますが、Fable 5 が以前の Claude モデル(例えば Opus 4.7)と比較して、日々の質問に応答する際に劇的な飛躍を示したとは言い難いです。すでに私は、月額 20 ドルでポケットの中に素晴らしい知能への機能的に無制限のアクセスを得られることに感銘を受けていました。Fable 5 はより賢いかもしれませんが、デートナイトの夕食を計画する際にもっとうまく手助けしてくれるとは考えにくいです。知能に対する限界効用逓減の法則が存在し、私の(そしておそらくほとんどの消費者の)日々の AI 利用において、より賢いモデルから本当に恩恵を受ける部分は限られています。
焦点を企業に移しましょう。こなすべき仕事とそれを遂行する人々には膨大な種類があります:弁護士や執行アシスタント、看護師、カスタマーサービス担当者、アカウントマネージャー、会計士など。実際に、現在米国では膨大なホワイトカラー業務が行われています。これらの仕事を難易度レベル別に分類する階層システムを想像することもできます:手動でのデータ入力はおそらくリストの下部に位置し、生物学者や弁護士、ソフトウェアエンジニアが行う(一部の)仕事はリストの上部に位置すると考えられます。
しかし、同じ限界効用逓減の法則が適用されます:ある点を過ぎると、必要以上に賢い人間を雇ってもパフォーマンスは本当に向上しません。そして、もしこの労働を増強または自動化したい場合にも、モデルの知能に対しても限界効用逓減の法則が適用されます。ただし、タスクには多様性があり、新しいモデルは他の分野では目立った改善が見られなくても、ある程度の間はフロンティアを押し広げ続けることができます。Fable 5 は明らかに ハードコアなソフトウェアエンジニアリングにとってのゲームチェンジャー であり、ポケモンに勝つことにもなりますが、私の Chipotle のバリオットボウル注文ワークフローにおいて目立ったパフォーマンス向上は見ていません。
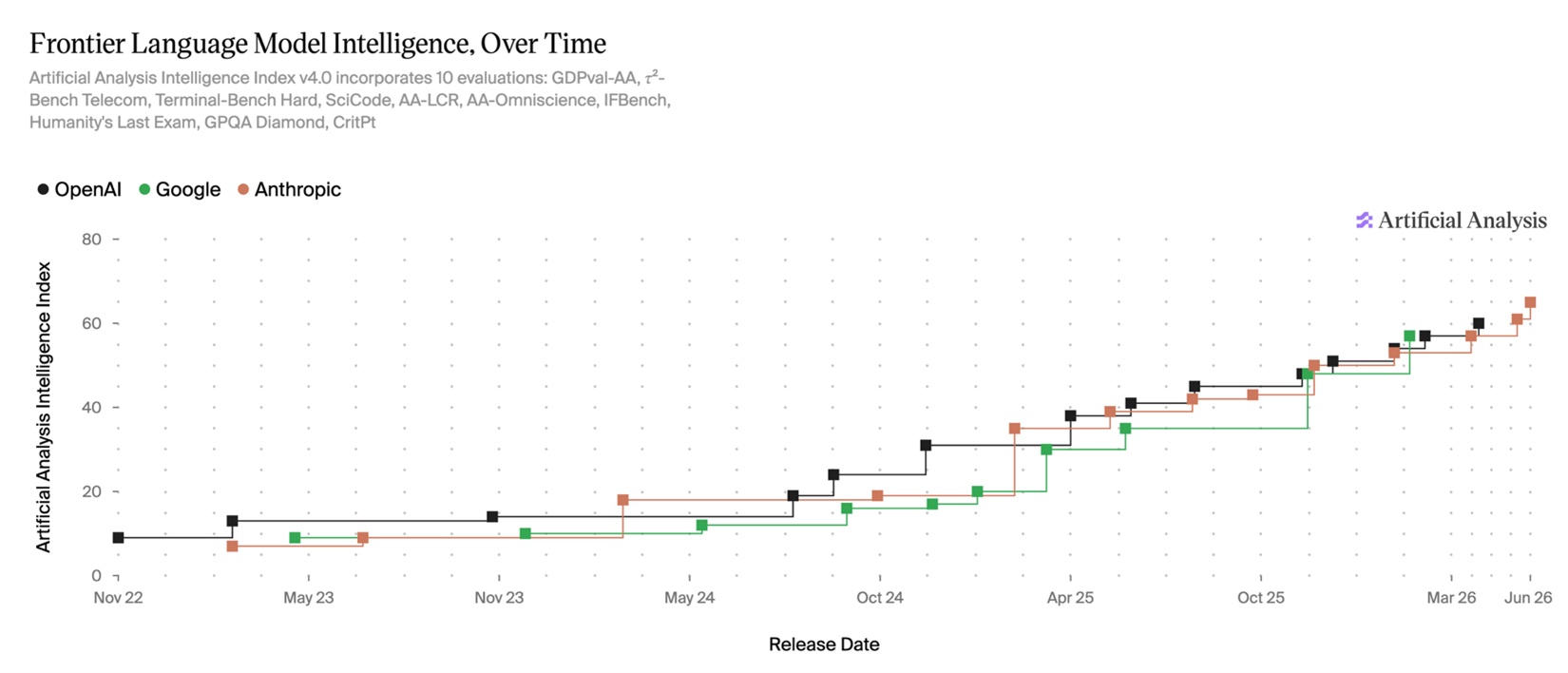
*The Artificial Analysis Intelligence Index v4 (AAII) は、さまざまなドメインにわたるモデルのパフォーマンスを測定するものです;ある意味で「ベンチマークのインデックスファンド」のようなものです。評価が完璧であることはありませんが、この議論の目的においては、これが最も有用なもののように感じられます。私はまた、*Epoch Capabilities Index* も気に入っています。
モデルのパフォーマンスは時間とともに改善し続けており、将来も同様に向上していく理由はないと私は考えます。タスク難易度のティアリストを縦軸として、時間の経過に伴うモデルのパフォーマンスを示してみましょう。これはあくまで例示であり、AAII スコアから現実世界のタスクにおける能力への正確なマッピングは不明確です。また、20XX 年までに医師や弁護士、ソフトウェアエンジニアが自動化されるといった予測を立てようとしているわけではありません。私が言いたいのは、(1) フロンティアモデルは時間とともに向上してきたこと、(2) おそらく今後もその傾向が続くこと、そして (3) モデルがより賢くなるにつれて、モデルの知能に対する限界効用逓減の漸近線に達するタスクがますます増えるだろうということです。
フロンティアの背後にはオープンウェイトモデルが存在します。これは適切な計算ハードウェアさえあれば理論上誰でも実行可能なモデルです。オープンウェイトモデルは通常、Google / Anthropic / OpenAI 製のモデルと比較して大幅に安価ですが、知能面では劣る傾向があります。オープンウェイトモデルがフロンティアに対してどの程度遅れているかは議論の余地がありますが、現時点ではベンチマークにおいて約 4 ヶ月程度の差があると仮定しておきましょう [1]。
オープンウェイトモデルもまた、さまざまなサイズで提供されています。例えば、Google が提供するオープンウェイトモデルの「Gemma 4」ファミリーには、E2B、E4B、12B、26B A4B、31B というサイズのバリエーションがあります。アルファベットの羅列を理解することは重要ではありませんが、より大きなモデル(パラメータ数が多い)は通常、より高い知能性と相関します、一方、小さなモデルはより小型で低コストのデバイス(例えばスマートフォンやノートパソコン)上で動作させることができます。では、上記のグラフにさらに 2 つの線を追加しましょう。1 つはオープンウェイトモデルの最前線を示すものであり、もう 1 つは平均的なノートパソコンで実際に実行可能な範囲を示すものです。
もし私がこれらの数値をどのように導き出したかに関心があれば、完全な分析はこちらで確認できます(ファイルをダウンロードして Chrome で開いてください)。また、その背後にある完全なデータと Python スクリプトはこちらにあります。
Fable 5 が経済全体に浸透することにはどのような意味があるのか?
オンデバイスモデルを実行することに一般消費者がそれほど関心を持つとは思えません。ChatGPT の無料版利用者はおそらく最も賢いモデルへのアクセスを望んでいるわけではなく、レート制限に頻繁に直面しているとも思えません;おそらく彼らが重視するのは使いやすさ(何も設定する必要がないこと)、強力なメモリシステム、そしてマルチモーダル出力へのアクセス(画像生成は明らかに一般消費者層に受け入れられています)です。あちこちに広告が表示されることはそれほど大きな拒絶要因にはならないでしょう(Instagram や Google 検索を参照)。有料利用者もオンデバイスモデルにあまり関心を持たないはずです:もしモデルの知能を重視するなら、クローズドウェイトの最前線に留まるでしょうし、レート制限を気にするならば、より充実した広告エンジンがその問題を解決できると思います(制限のリセットを待つよりも、オプションとして提示されたら広告付きで続けることを望むでしょうか?)
企業における状況はまた別の話です。FOMO(取り残される恐怖)に駆られたトークン最大化を除外すれば、企業は基本的な ROI 計算に基づいて意思決定を行います。企業の 90 パーセンタイルが AI 支出に従業員あたり年間 7200 ドルを費やしている [2] という事実がある以上、その約 20% のコストで済むオープンウェイトモデルへ移行するか、あるいは無料のローカルモデルへ移行する強いインセンティブが生まれるでしょう。未知数である兆ドル規模の問いは、どのようなワークロードにおいて最先端モデルがオープンウェイトやローカルの対抗馬に対して引き続き正味の ROI を維持し続けるかという点です。私は、今後数年間は生命科学、医療、金融、法律、そして物理的あるいはデジタルを問わない工学といった分野において、最先端モデルはその価格に見合う価値を持ち続けると考える世界も描けます。また、例えば Opus 5.5 が企業の大多数が行うタスクの绝大多数にとって十分であり、数値計算を行う企業が、パワーユーザー全員に RTX Spark を内蔵した約 5000 ドルのラップトップを購入することが、適切な CAPEX-OPEX のトレードオフであると結論付ける世界も描けます。
そして、最後に暗いトーンで終わることを嫌いますが、Mythos クラスのモデルが持つサイバーセキュリティ機能を容易に(私の場合、Claude にオープンウェイトモデルをインストールさせるのに 30 分とプロンプト 4 つが必要でした)利用できる任何人にとって、それは確かに恐ろしい発想です。十分な権限を与えられれば、たった一人の悪意ある行為者が多くの人々の日常を台無しにしかねません。
原文を表示
Model capabilities improve over time, but open-weight models lag the frontier
I often ask Claude mundane questions about cooking, fitness, and cars, among other things, and I can’t say I’ve found Fable 5 to be some magical step change vs. previous Claude models (e.g., Opus 4.7) at answering my day-to-day questions. I was already in awe of the fact that for $20/month I can have functionally unlimited access to incredible intelligence in my pocket; Fable 5 may be smarter, but it’s probably not going to help me plan a date night dinner any better. There are diminishing marginal returns to intelligence; the majority of my (and probably most consumers’) day-to-day AI usage isn’t going to really benefit from a smarter model.
Let’s shift focus to the enterprise. There’s a vast array of jobs to be done and people to do them: lawyers and executive assistants and nurses and customer service workers and account managers and accountants. Seriously, there is a LOT of white-collar work being done today in the US. You could imagine some tier-system that bucketed these types of work into difficulty levels: manual data-entry would probably be pretty low on the list; (some) work done by biology researchers or lawyers or software engineers would probably be higher up on the list.
But the same law of diminishing marginal returns applies: beyond a certain point, hiring a smarter-than-necessary human doesn’t really improve performance. And if you wanted to augment or automate this labor – diminishing marginal returns applies to model intelligence also. But again, there’s a diversity of tasks, and new models can continue to push the frontier forward for some while not being materially better on others. Fable 5 is clearly a gamechanger for hardcore software engineering and beating Pokemon; I haven’t seen notable performance improvements in my Chipotle burrito-bowl ordering workflow.
The Artificial Analysis Intelligence Index v4 (AAII) measures model performance across a variety of domains; it’s an “index fund of benchmarks” in a sense. No evaluation is perfect, but for the purposes of this discussion, this feels like the most useful one. I also like the [Epoch Capabilities Index.](https://images.squarespace-cdn.com/content/v1/5b1dce10620b85685e2e8bf1/45ff65e6-6a5e-4727-aed6-90450413bd12/AAII+frontier+labs.png)
Model performance has only improved over time, and I see no reason why it shouldn’t continue to improve in the future. Let’s turn our task difficulty tier list into a y-axis and show model performance over time. This is just illustrative; a precise mapping from AAII score to capabilities on real world tasks is unclear, and I’m not trying to make a prediction that doctors or lawyers or software engineers will be automated by 20XX. I’m merely saying that (1) the frontier models have gotten better over time, that (2) they’ll probably continue to do so, and that (3) as they get better and better, more and more tasks will reach the asymptote for diminishing marginal returns to model intelligence.
Behind the frontier lies open-weight models: models that theoretically anyone could run with the right compute hardware. Open-weight models are usually substantially cheaper vs. models from Google / Anthropic / OpenAI, but are also less intelligent. How far behind open-weight models are vs. the frontier is up for debate, but for now let’s assume the answer is ~4 months or so on benchmarks [1].
Open-weight models also come in a variety of sizes. For example, the Gemma 4 family of open-weight models from Google comes in E2B, E4B, 12B, 26B A4B, and 31B sizes. Understanding the alphabet soup isn’t important, but larger models (more parameters) typically correlates to more intelligence, while smaller models can run on smaller and less expensive devices (e.g., phones, laptops). Let’s add two more lines to our graph above: one for the cutting edge of open-weight models, and another for what could feasibly run on an average laptop.
If you’re interested in how I arrived at these numbers, you can find a full analysis here (download the file and open it in Chrome), and the full data and Python scripts behind it here.
What does Fable 5 being diffuse throughout the economy entail?
I doubt consumers will care much about running on-device models. ChatGPT Free-tier consumers probably don’t care about having access to the smartest models and probably aren’t running into rate limits all that often; they probably do care about ease of use (not having to set anything up), a strong memory system, and access to multimodal outputs (image generation has clearly caught on with the consumer crowd). Seeing ads here and there won’t be much of a turn off (see: Instagram, Google Search). Paid consumers probably won’t care much about on-device models either: if you care about model intelligence, you’re sticking with the closed-weight frontier, if you care about rate limits, I imagine a more built out ads engine can solve that (would you rather wait for your limits to reset, or press on with ads if the option were presented to you?).
It’s a different story in the enterprise. Excluding FOMO-driven tokenmaxxing, enterprises make decisions by looking at basic ROI calculations, and if the 90th percentile of businesses are spending $7200/year/employee on AI spend [2], there’s going to be a pretty strong incentive to switch over to an open-weight model that costs ~20% of that or to a local model that’s free. The unknowable trillion-dollar-question is for what workloads frontier models will continue to command positive ROI over their open-weight and local counterparts. I can see a world where frontier models continue to be worth their price in fields like life sciences, healthcare, finance, law, and engineering (whether physical or digital) over the next handful of years. I also can see a world where e.g., Opus 5.5 is good enough for the vast majority of tasks done in the vast majority of enterprises, and companies that run the numbers conclude that buying every power user a ~$5,000 laptop with an RTX Spark inside is the right capex-opex tradeoff.
And though I hate to end on a sour note, anyone having easy (I took me 30 minutes and 4 prompts to get Claude to install an open weight model on my machine) access to the cybersecurity capabilities of a Mythos-class model is certainly a terrifying thought. Sufficiently empowered, just one bad actor can ruin a lot of people’s day.
関連記事
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic は、Claude Fable 5 が米政府から不正アクセス(ジャイルブレイク)の懸念によりリリース後わずか3日で利用停止を命じられたと報じています。この措置により、多くのユーザーが失った機能への愛着を表明しています。
OpenAI や Anthropic の安価な代替案に賭ける 130 億ドル規模の AI スタートアップ
TLDR AI が報じた記事によると、OpenAI や Anthropic に代わる低コストソリューションへ巨額の投資を行う 130 億ドル規模の AI スタートアップが注目されています。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み