Amazon Bedrock AgentCore を用いた大規模なエージェント AI の運用管理「AgentOps」の紹介
AWS は、予測不可能な意思決定を行うエージェント型 AI の運用課題に対処するため、Amazon Bedrock AgentCore を活用した「AgentOps」の概念と実装フレームワークを提示し、ガバナンス、ビルド、評価、可観測性の 4 つの柱を解説している。
キーポイント
AgentOps の 4 つの柱
ガバナンスとセキュリティ(多アカウント戦略、ヒューマン・イン・ザ・ループ)、ビルドと運用(CI/CD によるバージョン管理)、評価(ツールからシステム全体までの多段階検証)、可観測性(4 層のテレメトリ)という 4 つの柱で構成される。
Amazon Bedrock AgentCore の役割
AWS は、これらの運用原則を実装するための具体的なコンポーネントを提供する「AgentCore」を公開し、エージェントのデプロイ、管理、継続的改善を可能にするプラットフォームとして位置づけている。
非決定性への対応とベストプラクティス
従来のワークフローとは異なり、推論や適応を行うエージェント特有の「コストの暴走」や「デバッグ不可能性」といった課題に対し、実装例を交えた具体的な対策とアーキテクチャを提案している。
重要な引用
That's where AgentOps comes in, the operational discipline for deploying, managing, and continuously improving AI agents in production.
Agents make unpredictable decisions, costs spiral unexpectedly, and debugging non-deterministic failures seems impossible.
treat every agent, tool, and memory configuration as a versioned, deployable artifact with its own CI/CD pipeline.
影響分析・編集コメントを表示
影響分析
本記事は、生成 AI から自律的な「エージェント型 AI」への移行期において、開発者が直面する運用上のボトルネック(コスト管理、デバッグの難しさ)に対する具体的な解決策を提示しており、業界標準となる運用フレームワークの確立に寄与します。AWS の戦略として AgentCore を中心に据えることで、大規模なエージェント導入における信頼性とスケーラビリティを担保する道筋を示しています。
編集コメント
生成 AI の運用(GenAI Ops)から、自律的な意思決定を行うエージェントの運用(AgentOps)へと焦点がシフトしている重要な転換点を示す記事です。AWS が提供する具体的なアーキテクチャは、大規模なエージェント導入を検討する企業にとって即戦いとなる参考資料となります。
エージェント型 AI ソリューションを構築する際、独自の運用上の課題に直面します。エージェントは予測不能な判断を下し、コストが予期せず膨れ上がり、非決定論的な障害のデバッグは不可能に見えることもあります。エージェント型 AI アプリケーションは単に事前に定義されたワークフローを実行するだけでなく、推論を行い、適応し、自律的に判断するため、DevOps のプラクティスも適応させる必要があります。そこで登場するのが AgentOps です。これは、本番環境で AI エージェントをデプロイし、管理し、継続的に改善するための運用上の分野です。
当ブログシリーズの第 1 部では、生成 AI ワークロードを運用化する方法を紹介しました。今回の投稿では、Amazon Bedrock AgentCore を活用して AgentOps を実装することで、エージェント型 AI ワークロードの本番環境への移行を加速し、エージェントとツールの品質を検証し、組織内でのエージェント型 AI の採用を推進する方法を示します。ガバナンスとセキュリティ、構築と運用、評価、観測性の 4 つの柱にわたる実世界の実装からのベストプラクティスについて議論します。また、AWS のサービス、人材、プロセスがどのように統合され、組織に合わせて適応可能な参照アーキテクチャを形成するかについても解説します。
なお、本稿はエージェントの設計ではなく運用に焦点を当てています。実装例では Amazon Bedrock AgentCore とそれを支える AWS サービスを使用していますが、ここで議論する原則は広く適用可能です。参照アーキテクチャは出発点に過ぎず、組織の要件に応じてどのように適応させるかが決まります。
AgentOps: 4 つの柱
本稿では、AgentOps の各柱に関するベストプラクティスと実世界での知見を解説します。
- ガバナンスとセキュリティ:マルチアカウント戦略、決定論的制御、推論制御、およびヒューマン・イン・ザ・ループ(人間を介在させる仕組み)を活用し、エージェントが承認された範囲内で動作していることを検証し、すべての行動を追跡可能にします。
- ビルドと運用:各エージェント、ツール、メモリ設定を、独自の CI/CD パイプラインを持つバージョン管理されデプロイ可能なアーティファクトとして扱います。
- 評価:開発環境および本番環境において、4 つのレベル(ツール、会話ターン、セッション結果、システム全体)で評価を行います。
- 観測性とモニタリング:4 つのテレメトリ層に計装を施し、各エージェントの意思決定を追跡し、品質の低下を監視し、インタラクションあたりのコストを追跡できるようにします。
Amazon Bedrock AgentCore は、これらの柱を実装するために単独または組み合わせて使用できるコンポーネントを提供しています。これは、大規模かつ安全に効果的なエージェントを構築・デプロイ・運用するための AWS のアジェンティック AI プラットフォームです。AgentCore はあらゆるオープンソースフレームワークおよびあらゆる大規模言語モデル(LLM)と連携し、インフラストラクチャの管理なしでローカル開発から本番環境への移行が可能です。
AWS における AgentOps ライフサイクル
他のソフトウェアソリューションと同様に、エージェントもアイデアから本番環境に至るまでの開発ライフサイクルに従い、その進行は真に終わることはありません。各段階において、継続的な運用上の注意と改善が必要です。以下に、アジェンティック AI が DevOps パイプラインの各段階(計画、開発、ビルド、テスト、デプロイ&リリース、保守、モニタリング)にどのように影響するかをマッピングしました。
DevOps ステージ
AgentOps の考慮事項
計画 (Plan)
AI の適合性、リスク、倫理を評価する。法的・コンプライアンス上の承認を取得し、パフォーマンス指標を設定し、データを準備する。人間の監視ポイント、ツールの権限、エージェントの信頼モデル、クロスエージェント認証、初期のエージェント設計を定義する。
開発 (Develop)
実験とモデル選択、評価、検索拡張生成(RAG)/プロンプト、チャンキング戦略、ガードレール。オーケストレーション、メモリ、状態管理、ツールレジストリ/ディスカバリー、Model Context Protocol (MCP) ツール、エージェント間通信(A2A)、エージェントID、エージェント評価、認証パターン。
ビルド (Build)
ユニットテスト、統合テスト、セキュリティテスト、エージェントテストを実施し、プレプロダクションへデプロイする。ワークフローテスト、ツールチェーンの検証。ロールベースアクセス制御(RBAC)の検証。
テストとリリース
品質、パフォーマンス、エンドツーエンド、セキュリティテストを実行する。AI の考慮事項を反映したリリースノートを更新する。実行パスの評価、エンドツーエンド目標、ループ制限、人間-in-the-loop(HITL)テスト、不正なエージェントアクション。
デプロイ
ソリューションを生産環境へデプロイする。MCP サーバー、ツールをデプロイする。並行処理、最小権限の原則、エージェントエンドポイント用のネットワーク設定。ロールバック戦略、カナリアデプロイメント、またはトラフィック管理を設定する
維持と監視
品質、ガードレール、レイテンシ、スループット、責任ある AI、エラー、使用状況とコストを追跡する。ユーザーフィードバック。トレース/スパンの監視、ドリフト、アラート、アクション監査証跡、異常検知、エージェントのエンドツーエンド呼び出しに対するガードレール
The pillars apply irrespective of where you are in the lifecycle. From a responsible AI perspective, you need systematic risk management throughout. "The Agentic AI Security Scoping Matrix: A framework for securing autonomous AI systems" can help identify and manage risks.
Solution Overview
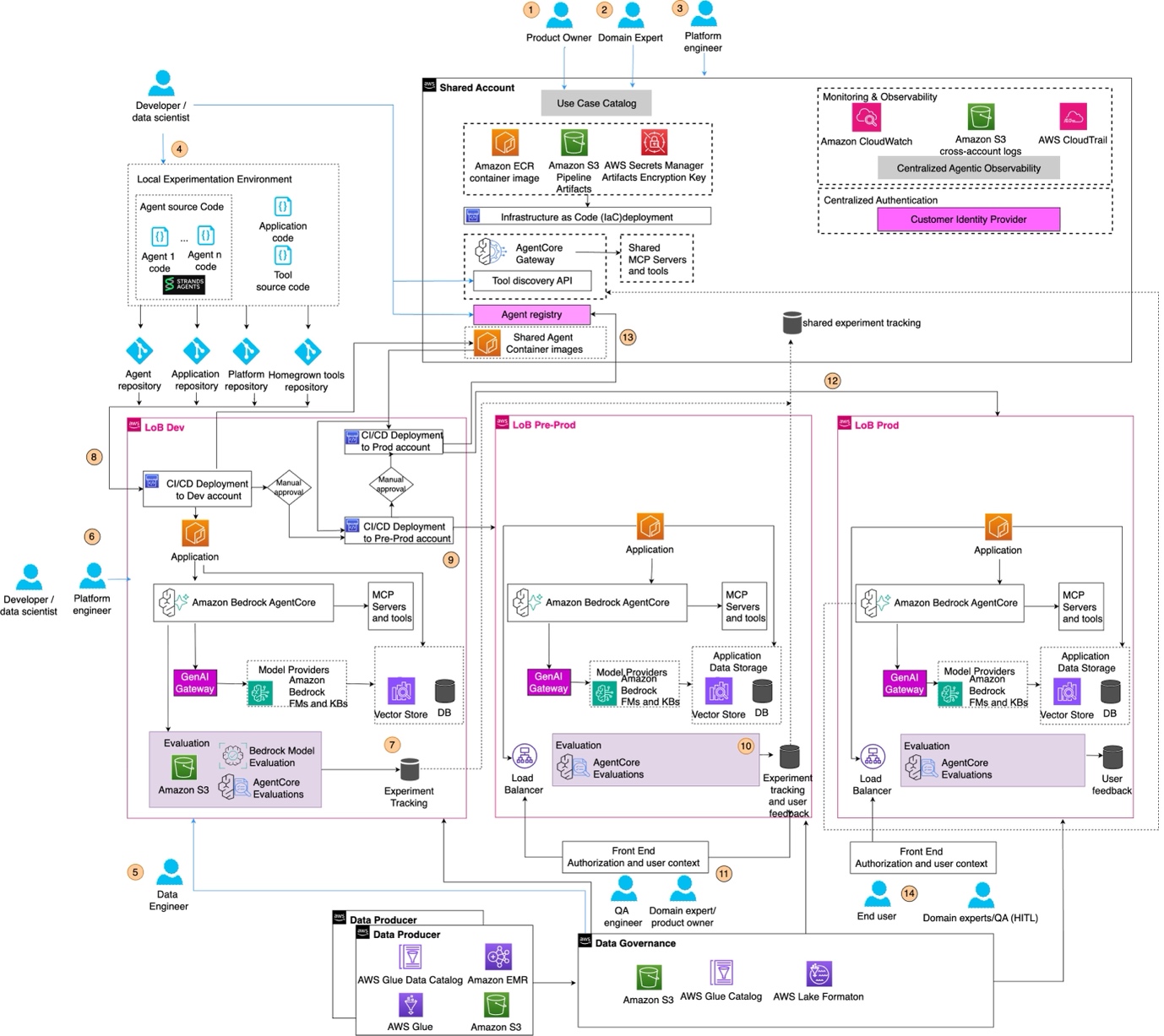
The following reference architecture shows how the pillars, lifecycle, people, processes, and AWS services connect. Let's go through it step-by-step.
Planning and setup
- The product owner registers the use case in a centralized catalog. Legal and compliance teams assess risks and provide guidance.
- Once the use case is approved, the product owner works with domain experts and technical teams to establish scope, success metrics, and source-of-truth test prompts for evaluation.
- Platform engineers deploy environments using IaC with access controls agreed with security teams and tagging for governance and cost tracking.
Development
- 開発者とデータサイエンティストは、シードコードを用いてエージェント、アプリケーション、およびツールのリポジトリを作成し構築を開始します。共有された AgentCore Gateway の背後にある承認済みツールや、AWS Registry の背後にあるエージェントを利用することがあります。新しいツールまたは MCP サーバーの要求は、製品オーナー、プラットフォームチーム、および法務部門を経由して承認を得る必要があります。
- データエンジニアは、開発とテスト用のデータセットおよび評価セットを作成します。
- 開発者は、ツールの選択精度、多段階推論の検証、会話の一貫性、メモリ永続化などを含む手動および自動評価を実行します。ドメインエキスパートが結果を検証しフィードバックを提供します。
- 実験結果は開発中はローカルで追跡され、その後、共有アカウントに同期されて中央集権的な追跡とチーム間比較が可能になります。
- 開発者は main ブランチへマージし、デプロイメントパイプラインをトリガーします。
ビルドおよびデプロイメントパイプライン
- CI/CD パイプラインはリリースブランチを作成し、AgentCore Runtime へのエージェントデプロイを含む ECR を介したリソースのプレプロダクションへのデプロイを実行し、評価パイプラインをトリガーします。RAG(Retrieval-Augmented Generation)実装の場合、インジェストパイプラインはデータガバナンスアカウントにデプロイされます。
- プレプロダクションでは、認証フロー、ユーザーコンテキストの伝播、ツールアクセス権限の検証を含む、統合テスト、パフォーマンステスト、UAT(ユーザー受入テスト)、回帰テスト、および生成 AI 評価テストが実行されます。
- QA エンジニアとドメインエキスパートは確立された指標に対して検証を行い、本番環境へのプロモーションを承認します。
本番環境でのデプロイと運用
- ソリューションは本番環境にデプロイされます。本番環境のテレメトリデータ、ユーザーフィードバック、およびパフォーマンス指標は、継続的な改善のために計画プロセスへフィードバックされます。
- エージェントは Agent Discovery API に登録され、再利用やエージェント間コラボレーションのために発見可能になります。
- エンドユーザーがアプリケーションと対話し、フィードバックを提供します。AgentCore Observability(観測性)ダッシュボードでは、意思決定の追跡、ツール呼び出しパターン、レイテンシ、エラー、メモリ使用量、および各インタラクションあたりのコストを追跡します。
次に、各ピラーについてより詳細に説明します。
ピラー 1:ガバナンスとセキュリティ
エージェントシステムでは、単一のユーザーリクエストが階層的なチェーンに広がったり、複数のエージェントがユーザーの代わりに行動する協調的な群れをトリガーしたりすることがあります。ユーザーとエージェント間の各インタラクションは厳密に制御される必要があります。エージェント A がエージェント B を呼び出す場合、どのエージェントがどのアクションを実行する権限を持っているのかという曖昧さが生じることがあります。制限された権限を持つユーザーがエージェントをトリガーした場合、そのエージェントはその制限を引き継ぐ必要があります。この曖昧さは、より深い呼び出しチェーンにおいてさらに複雑化します。誰がエージェントにアクセスできるか、エージェントがどのデータ・ツール・API にアクセスできるか、これらの権限を誰が承認できるか、そして問題が発生した際に何が起きるのかについて、厳格なガバナンスが必要です。
以下の図は、エージェントがリクエストを処理する各ステップで行うべきセキュリティ判断を示しています。ユーザーの入力は環境を経てエージェントに流れ込み、そのエージェントはツールとメモリを使用して出力を生成します。アプリケーションは、ユーザーの身元を確認し、そのユーザーがエージェントを呼び出す権限があるか、また特定のパラメータで要求されたコンテキスト・メモリ・ツールへのアクセス権限がエージェントにあるかを検証します。さらに、入力内容が安全であること、およびエージェントが特定の出力を返す権限を持っていることも検証されます。
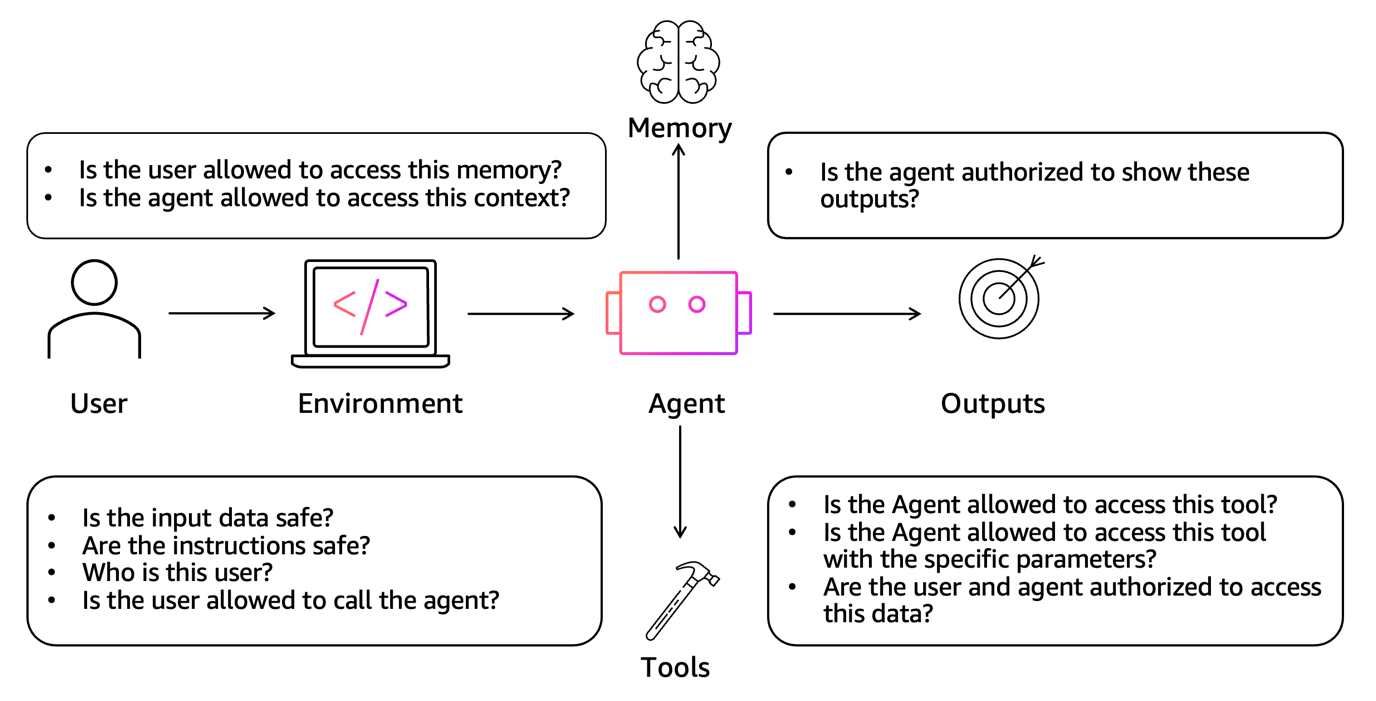
エージェントが明確に定義された境界内で動作しつつ、監査可能性を維持できるようにする階層型セキュリティアプローチを実現するには、以下の次元を検討する必要があります。
マルチアカウントアーキテクチャ
AgentOps は、MLOps が DevOps の拡張であるのと同様に、GenAIOps の拡張です。Part 1: GenAIOps をお読みいただいた方であれば、AgentOps にも同じ設計原則が適用されることをご存知でしょう。組織的な分離のために マルチアカウント戦略 を採用し、アカウント全体にセキュリティガードレールを設定するために Service Control Policies (SCPs) を使用すべきです。
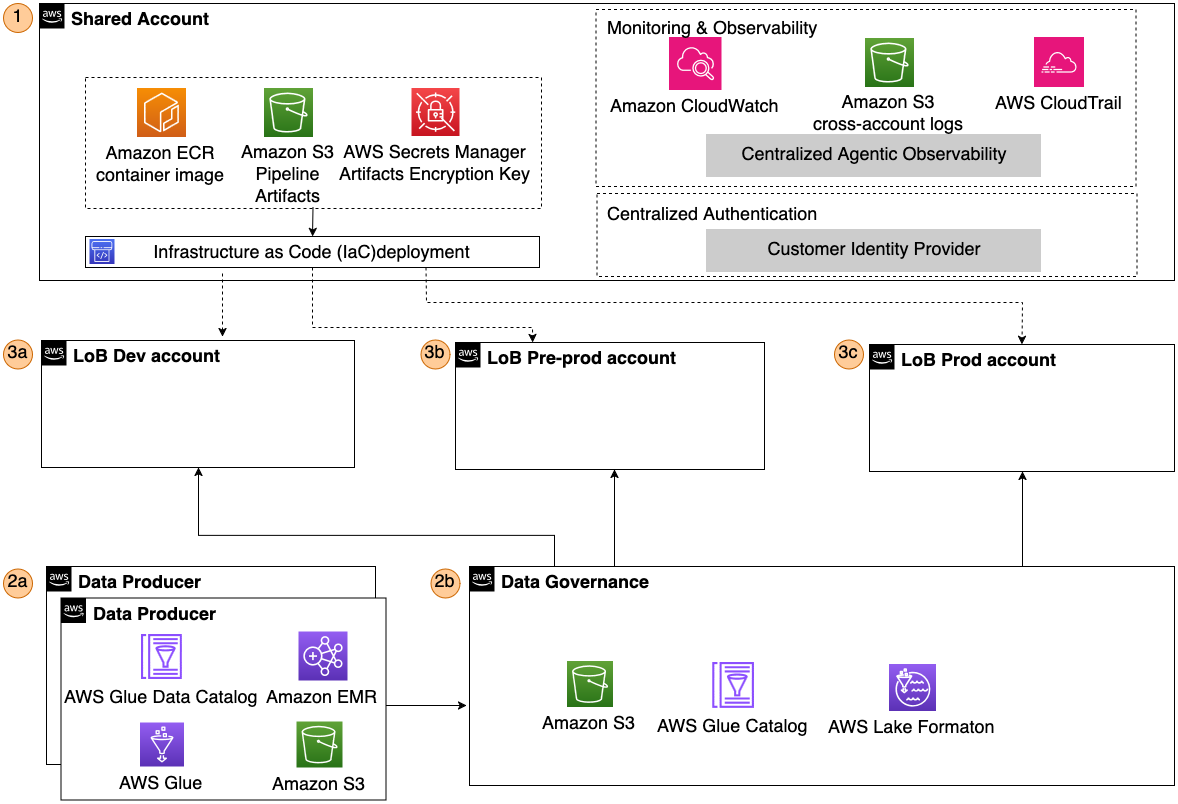
以下の参照図は、マルチアカウントの AWS アーキテクチャを示しています。
- Amazon Elastic Container Registry (ECR) のコンテナイメージ、パイプライン成果物、AWS Secrets Manager、および集中型の監視・認証サービスを利用した共有サービスアカウント。
- 生産者アカウントとデータガバナンスアカウントを分離し、コンプライアンス要件に準拠したナレッジベースへの隔離された安全なアクセスをサポートするデータアカウント。
- アプリケーションアカウント。a. 各事業ラインまたはアプリケーションチームごとの専用開発(dev)環境、b. プレビュー本番前(pre-prod)環境、c. 本番(prod)環境。ガバナンスとコスト追跡のためのタグ付けが行われます。
アカウントおよびリソースは、Infrastructure as Code (IaC) を用いてデプロイ・管理されます。
制御されたモデルアクセス
Amazon Bedrock を使用する際、SCP と IAM アイデンティティベースのポリシー を用いて、アプリケーションがアクセスできるモデルを制御します。エージェントはこれらのモデルを直接利用するか、LiteLLM などの生成 AI ゲートウェイを経由して利用できます。ゲートウェイを利用することで、複数のモデルプロバイダーにわたるアクセス制御の一元化とガバナンス実装の簡素化が可能となり、ユーザーまたはエージェントごとのレート制限、トークン予算管理、コスト追跡および予算強制執行、セキュリティポリシーに基づくモデルルーティング、コンプライアンスのための集約監査証跡を提供する統一 API インターフェースを実現できます。AWS は生成 AI ゲートウェイのデプロイ方法に関するガイダンスを公開しています。当初は簡便さのためゲートウェイを共有サービスに配置していましたが、個別のエージェントへのコスト帰属が困難であることが判明したため、アプリケーションアカウントへ移行しました。
アイデンティティとアクセス制御
細粒度のアクセス制御には AWS Identity and Access Management (IAM) を利用できます。さらに、AgentCore Identity を用いることで、エージェント間での認証と認可を管理し、リクエストがシステム内を伝播する際にセキュリティ境界を維持するための細粒度のアクセス制御やクロスエージェント認証プロトコルを提供します。詳細については、Amazon Bedrock AgentCore Identity: Securing agentic AI at scale をご参照ください。包括的な監査ログ記録やフォレンジック分析には AWS CloudTrail を利用できます。
データガバナンス
データは複数のタッチポイントを流れます:ユーザー入力(テキスト、添付ファイル)、エージェントの指示、出力、アクセスされたデータソース、およびメモリ操作です。それぞれが潜在的なセキュリティリスクをもたらします。Amazon Bedrock Guardrails を設定して、ユーザーのプロンプトとモデルの応答を安全ポリシーに対して評価し、意図しない個人識別情報(PII)の漏洩などの脅威から保護してください。ガードレールの実装方法や生成 AI ゲートウェイとの統合に関する詳細なセットアップ手順については、Amazon Bedrock Guardrails を使用して生成 AI アプリケーションを保護する を参照してください。
上記に加え、評価用データセット(数百例程度)のバージョン管理を活用し、RAG ナレッジベース内のドキュメントおよび生成された埋め込みベクトルに対する変更を体系的に追跡して、評価と監査要件に対応してください。
メモリ
エージェントアプリケーションにおいて、データはエージェントが検索メカニズム(RAG など)を通じてアクセスする基礎となる事実、ドキュメント、構造化情報(ナレッジベース、データベース、API)を表しており、従来のアクセス制御によって管理されます。一方、メモリはエージェントの作業コンテキスト(会話やユーザーの嗜好、インタラクションパターンについて保持している情報)です。これは動的かつ対話的であり、各インタラクションを通じて進化します。
AgentCore Memory を利用すると、組み込みおよびカスタム戦略による短期記憶と長期記憶が提供されます。また、抽出ロジックのオーバーライドや、専門的な要件に対応するための自己管理型戦略の実装も可能です。名前空間は、長期記憶における戦略設定の一部として作成時に定義され、アクター、セッション、または戦略ごとに記憶を整理します。これにより、ユーザー間でのパーソナライゼーションと共有学習を支援する構造が提供されます。AgentCore Memory はデータをアクターレベルの個別集計にスコープします。エージェントがクロスユーザーのパターンを学習する必要がある場合、記憶はより高いアプリケーション全体レベルで集約できます。マルチアカウント展開パターンでは、各アカウント(開発、プレプロダクション、本番)には独自の AgentCore Memory リソースがあり、チームはこれらのリソースをアプリケーションと共にデプロイおよび管理します。この展開パターンは、セキュリティの分離、独立したスケーリング、データ居住要件への適合、およびアプリケーションごとのコスト配分を支援します。
アプリケーションは複数のメモリリソースにアクセスできます。以下の図はこのアプローチを示しており、不正検出アプリケーションと請求処理アプリケーションの 2 つが、それぞれ専用のリソースからリスクシグナルやポリシー詳細を取得し、共有されたメモリリソースからユーザー詳細を取得する方法を説明しています。IAM ポリシーを使用して、これらのアプリケーションがアクセスできるメモリリソースおよび情報を制御できます。
原文を表示
When you build agentic AI solutions, you face unique operational challenges. Agents make unpredictable decisions, costs spiral unexpectedly, and debugging non-deterministic failures seems impossible. Agentic AI applications don’t just execute predetermined workflows. They reason, adapt, and make autonomous decisions, and DevOps practices need to be adapted. That’s where AgentOps comes in, the operational discipline for deploying, managing, and continuously improving AI agents in production.
The first part of our blog series introduced how to operationalize generative AI workloads. In this post, we show how to accelerate the path to production for agentic AI workloads, check the quality of your agents and tools, and drive agentic AI adoption in your organization by implementing AgentOps with Amazon Bedrock AgentCore. We discuss best practices from real world implementations across four pillars: governance and security, build and operations, evaluation, and observability. We also show how AWS services, people, and processes come together into a reference architecture that you can adapt for your organization.
Note that this post focuses on operations and not agent design. The implementation examples use Amazon Bedrock AgentCore and supporting AWS services, but the principles discussed apply broadly. The reference architecture is a starting point: your organization’s requirements will determine how you adapt it.
AgentOps: The four pillars
This post covers best practices and real-world learnings for each of the AgentOps pillars:
- Governance & Security: use multi-account strategy, deterministic controls, reasoning controls and human-in-the-loop, to verify agents operate within authorised boundaries and every action is traceable.
- Build & Operations: treat every agent, tool, and memory configuration as a versioned, deployable artifact with its own CI/CD pipeline.
- Evaluation: evaluate at four levels, tool, conversation turn, session outcome, and system in development and production.
- Observability and monitoring: instrument across four telemetry layers so you can trace every agent decision, monitor quality drops, and track cost per interaction.
Amazon Bedrock AgentCore offers components that you can use independently or together to implement these pillars. It is AWS’s Agentic AI platform for building, deploying, and operating effective agents securely at scale. AgentCore works with any open source framework and any large language model (LLM) and you can transition from local development to production without managing infrastructure.
The AgentOps Lifecycle on AWS
Like other software solutions, agents follow a development lifecycle from idea to production, and that progression never truly ends. Agents require continuous operational attention and improvements across every stage. Below, we’ve mapped out how agentic AI impacts each stage of your DevOps pipeline: Plan, Develop, Build, Test, Deploy & Release, Maintain and Monitor.
DevOps Stage
AgentOps Considerations
Plan
Assess AI fit, risks, ethics. Secure legal/compliance approvals, establish performance metrics, prepare data. Define human oversight point, tool permissions, agent trust model, cross-agent authentication, initial agent design
Develop
Experimentation and model selection, evaluations, Retrieval Augmented Generation (RAG)/prompts, chunking strategies, guardrails. Orchestration, memory, state, tool registry/discovery, Model Context Protocol (MCP) tools, Agent-to-Agent (A2A), agent identity, agent evaluations, auth patterns
Build
Unit/integration/security/agent tests, deploy to pre-production. Workflow tests, tool chain validation. Role-Based Access Control (RBAC) validation
Test & release
Run quality, performance, end-to-end, security tests. Update release notes with AI considerations. Execution path evaluation end-to-end goals, loop limits, human-in-the-loop (HITL) tests, unauthorized agent actions.
Deploy
Deploy solution to production.Deploy MCP servers, tools. Concurrency, least privilege, networking for agent endpoints. Configure rollback strategies, canary deployments, or traffic management
Maintain and monitor
Track quality, guardrails, latency, throughput, responsible AI, errors, track usage and cost. User feedback. Traces/spans monitoring, drift, alerts, action audit trails, anomaly detection, guardrails for agent end-to-end calls
The pillars apply irrespective of where you are in the lifecycle. From a responsible AI perspective, you need systematic risk management throughout. “The Agentic AI Security Scoping Matrix: A framework for securing autonomous AI systems” can help identify and manage risks.
Solution Overview
The following reference architecture shows how the pillars, lifecycle, people, processes, and AWS services connect. Let’s go through it step-by-step.
Planning and setup
- The product owner registers the use case in a centralized catalog. Legal and compliance teams assess risks and provide guidance.
- Once the use case is approved, the product owner works with domain experts and technical teams to establish scope, success metrics, and source-of-truth test prompts for evaluation.
- Platform engineers deploy environments using IaC with access controls agreed with security teams and tagging for governance and cost tracking.
Development
- Developers and data scientists create agent, application, and tool repositories with seed code and begin building. They may use approved tools behind the shared AgentCore Gateway and agents behind the AWS Registry. New tool or MCP server requests go through the product owner, platform team, and legal for approval.
- Data engineers create datasets and evaluation sets for development and testing.
- Developers run manual and automated evaluations including tool selection accuracy, multi-step reasoning validation, conversation coherence, and memory persistence. Domain experts review results and provide feedback.
- Experiment results are tracked locally during development, then synchronized to the shared account for centralized tracking and cross-team comparison.
- Developers merge to main, triggering the deployment pipeline.
Build and deployment pipeline
- The CI/CD pipeline creates a release branch, deploys resources to pre-production including agent deployment to AgentCore Runtime via ECR, and triggers the evaluation pipeline. For RAG implementations, the ingestion pipeline deploys to the data governance account.
- In pre-production, integration, performance, UAT, regression, and generative AI evaluation tests run, including authentication flows, user context propagation, and authorization validation for tool access.
- QA engineers and domain experts validate against established metrics and approve promotion to production.
Production deployment and operations
- The solution is deployed to production. Production telemetry, user feedback, and performance metrics flow back to planning for continuous improvement.
- Agents are registered in the Agent Discovery API, making them discoverable for reuse and agent-to-agent collaboration.
- End users interact with the application and provide feedback. AgentCore Observability dashboards track decision traces, tool invocation patterns, latency, errors, memory usage, and cost per interaction.
Now let’s go through each pillar in more detail.
Pillar 1: Governance & Security
In agentic systems, a single user request can spread across hierarchical chains or trigger collaborative swarms where multiple agents act on the user’s behalf. Each interaction between user and agent needs to be tightly controlled. When Agent A calls Agent B, there can be ambiguity of what agent is authorized to perform which actions. If a user with limited permissions triggers an agent, the agent must inherit those restrictions. This ambiguity only compounds in deeper chain of calls. You need strict governance around who can access the agents, what data and tools and APIs the agents can access, who can authorize these permissions, and what occurs when issues arise.
The following diagram shows the security decisions to be made at each step when an agent handles a request. A user’s input flows through an environment, into the agent, which uses tools and memory to generate outputs. The application verifies the user’s identity, whether they are allowed to invoke the agent, and whether the agent can access the requested context, memory, and tools with the specific parameters. It also validates that inputs are safe and that the agent is authorised to return the specific outputs.
To achieve a layered security approach that helps agents operate within well-defined boundaries while maintaining auditability you should consider the following dimensions.
Multi-account architecture
AgentOps is an extension of GenAIOps, the same way MLOps is an extension of DevOps. If you followed Part 1: GenAIOps, the same design principles apply to AgentOps. You should follow a multi-account strategy for organizational isolation and Service Control Policies (SCPs) to set security guardrails across accounts.
The following reference diagram shows the multi-account AWS architecture:
- A shared services account with Amazon Elastic Container Registry (ECR) container images, pipeline artifacts, AWS Secrets Manager, and centralised monitoring and authentication services.
- Data accounts to separate producer accounts from data governance accounts, supporting isolation and secure access to knowledge bases aligned with compliance requirements.
- Application accounts. a. Dedicated development (dev), b. pre-production (pre-prod), and c. production (prod) accounts per line of business or application team and tagged for governance and cost tracking.
Accounts and resources are deployed and managed using Infrastructure as Code (IaC).
Controlled Model access
When using Amazon Bedrock, you control which models the applications have access to using SCPs and IAM identity-based policies. Your agents can use these models directly or via a generative AI gateway such as LiteLLM. With a gateway, you centralize access control and simplify governance implementation across multiple model providers while providing a unified API interface for rate limiting per user or agent, token budgeting, cost tracking and budget enforcement, model routing based on security policies, and centralized audit trails for compliance. AWS has published guidance on how to deploy a generative AI gateway. We initially placed the gateway in shared services for simplicity, but found it harder to attribute costs to individual agents and moved it to application accounts.
Identity and Access Control
You can use AWS Identity and Access Management (IAM) for fine-grained access control. Additionally, with AgentCore Identity you manage authentication and authorization across your agents, with fine-grained access controls and cross-agent authentication protocols that maintain security boundaries as requests propagate through your system. For more information refer to Amazon Bedrock AgentCore Identity: Securing agentic AI at scale. AWS CloudTrail can be used for comprehensive audit logging and forensic analysis.
Data governance
Data flows through multiple touchpoints: user inputs (text, attachments), agent instructions, outputs, accessed data sources, and memory operations, each presenting potential security risks. Configure Amazon Bedrock Guardrails to evaluate user prompts and model responses against your safety policies and to protect against threats like inadvertent PII disclosure. For detailed set-up instructions to implement guardrails and integrate them with a generative AI gateway refer to Safeguard generative AI applications with Amazon Bedrock Guardrails.
In addition to the above, use version control of evaluation datasets (with a few hundred examples) and systematically track changes to documents and generated embeddings within RAG knowledge bases to support evaluation and auditing requirements.
Memory
In agentic applications, data represents underlying facts, documents, and structured information agents query (knowledge bases, databases, APIs) accessed through retrieval mechanisms like RAG, governed through traditional access controls. On the other hand, memory is the agent’s working context (what it retains about conversations, user preferences, and interaction patterns). It is dynamic and conversational, evolving with each interaction.
With AgentCore Memory you get short-term memory and long-term memory with built-in and custom strategies for memory extraction. You can also override extraction logic or implement self-managed strategies for specialised requirements. Namespaces, which are defined at creation time as part of the strategy configuration in long-term memory, organise memory by actor, session, or strategy. They provide the structure that helps personalisation and shared learning across users. AgentCore Memory scopes data to individual aggregates at actor level. When agents need to learn cross-user patterns, memory can aggregate at higher application-wide levels. In a multi-account deployment pattern, each account (dev, pre-prod, prod) has its own AgentCore Memory resources that teams deploy and manage alongside their applications. This deployment pattern helps with security isolation, independent scaling, alignment with data residency requirements, and cost allocation per application.
Applications can access multiple memory resources. The following diagram illustrates this approach, showing how two applications, a fraud and a claims application, access risk signals and policy details from their dedicated resources, and user details from a shared memory resource. You can control which memory resources and information they have access to with IAM policies.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み