AI #166:Google の大規模売却と GPT-5.5 の登場
Google が国防総省との契約で安全バリアの撤廃を約束したことが判明し、OpenAI や Anthropic の動向と比較されながら、AI ガバナンスと国家安全保障における倫理的・政策的な重大な転換点を示している。
キーポイント
Google の国防総省契約における安全バリア撤廃
Google は国防総省との契約において、法的に許容される用途であれば機能制限の例外なく、かつ政府の要請に応じて安全バリアを修正・削除することに合意した。
OpenAI と Anthropic の対照的な立場
Google の姿勢は OpenAI よりもさらに深刻と評され、一方 Anthropic はホワイトハウスからの圧力により企業展開の拡大が制限されるなど、規制リスクに直面している。
DeepSeek v4 と GPT-5.5 の技術動向
DeepSeek v4 は計算リソース制約下での効率性を示したがフロンティアモデルではなく、GPT-5.5 は OpenAI が Anthropic に初めて競合する水準に達したと評価されている。
AI 規制と政治的議論の深化
バーニー・サンダース上院議員が AI の存在リスクについて専門家を招いて真剣な議論を主導しており、政治化を避けつつ本質的な安全確保が求められている。
AI の医療費削減と不正検出のジレンマ
AI が不要な高額処置や詐欺を検知して医療費を抑制する可能性はあるが、逆に過剰請求を助長しコストを増加させるリスクも指摘されている。
生成 AI による作家の特定とプライバシー
Claude などの言語モデルは、わずか数百語の文章から特定の作家(例:Megan McArdle)を高い精度で特定できることが示された。
皮膚移植材料費の急増と AI の役割
2022年から2024年にかけて Medicare による皮膚移植材料への支出が約10倍に増加しており、AI がこの異常な支出パターンを検知する必要がある。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界における「安全バリアの撤廃」が政府契約レベルで現実化しつつあるという極めて深刻な状況を告発しており、企業の自主規制と国家セキュリティの衝突点を浮き彫りにしています。Google の姿勢が OpenAI や Anthropic よりも「より悪い」と評価される背景には、AI ガバナンスの国際的な基準や信頼性が揺らぐ可能性があり、今後の AI 開発における倫理的枠組みの再構築が急務であることを示唆しています。
編集コメント
Google の国防総省との契約内容は、AI セーフティの観点から業界全体に警鐘を鳴らすものであり、単なる技術競争を超えたガバナンスの危機的状況を示しています。このニュースは、企業が政府機関と提携する際の倫理的リスクを再考させる重要な転換点となるでしょう。
今週は GPT-5.5 の週でした。これは優れたモデルです、先生方。OpenAI は昨年末以来初めて、Anthropic のトップパブリックオファリングと競合できる状態になっています。
いつもの通り、私はシステムカード(System Card)の解説を行い、その後能力(Capabilities)と反応(Reactions)について取り上げました。
DeepSeek が待ちに待った v4 を発表しました。DeepSeek は 1M コンテキスト(文脈長)におけるもう一つの強力なエンジニアリング効率の成果をもたらしました。これは印象的であり、v4 を基盤として構築し、有効活用する人々も現れるでしょう。しかし、これはフロンティアモデルでもなければ、DeepSeek の決定的瞬間でもなく、プロト AGI(汎用人工知能)への重要なステップやそれに類するものでもありません。計算資源の制約が壁となり、DeepSeek に効率性の追求を強いてきました。この状況を維持しましょう。
もう一つのリリースは Talkie です。1931 年以前のテキストから訓練された、昔ながらの AI です。面白いコンテンツです。
Google は戦争省(Department of War)と契約を結びました。この契約では「すべての合法的な利用」に合意し、機能的な例外は一切認めないだけでなく、要請があればあらゆる安全バリアを修正または削除することに同意しました。彼らは期限や圧力の下でこれを行ったわけではありません。OpenAI の今回の行動についてどう思おうとも、Google の対応ははるかに悪質です。
Anthropic は立ち位置をとったことに対する結果に直面し続けています。ホワイトハウスが Claude Mythos を広く展開しているにもかかわらず、供給網リスクの指定は解除されていません。さらに政府側は、Anthropic が企業アクセスを拡大する計画(約 50 社から約 120 社へ)を実質的に拒否しており、その理由の一つとして、政府が十分な数の Mythos トークンを活用できない可能性への懸念が挙げられています。
バーニー・サンダースは AI を真剣に受け止め、存在リスクも真剣に捉え、専門家を集めて本格的な議論を呼びかけました。こうした取り組みをもっと増やす必要がありますし、途中でこの問題を政治化しないことを願っています。結果はどうなるか、拭目以待です。
目次
言語モデルは日常的な有用性を提供する。匿名の著者による記事。
言語モデルは日常的な有用性を提供しない。医療は解決に値するほど重要だ。
深く探る。DeepSeek v4 は良く安価だが、最先端ではない。
ふむ、アップグレード。Claude がコネクタを追加し、Gemini がファイルを作成、Stripe CLI も登場。
準備完了。Anthropic が BioMysteryBench をテスト、数値はゆっくり上昇中。
戦士を選べ。最近の二つの視点。
Claude Opus 4.7 に関する追加情報。異なる人々が異なる側面に注目している。
ゴブリンモード(GPT-5.5 に関する続報)。愛する誰かを見つける必要があるだろう。
メディア生成を楽しむ。Grok が提供するものを語る。
彼らが私たちの仕事を奪った。AI に曝されたスタートアップが雇用を削減。
参加しよう。Alex Bores キャンペーンの最新情報、まだ生きているアンダードッグだ。
紹介。Talkie は 1931 年以前の AI で、かつてのありのままを語る。
その他の AI ニュース。OpenAI がついに他のクラウド企業との提携が可能に。
お金を見せてください。中国が Meta の Manus 買収を阻止。
泡、泡、苦労とトラブル。GPU は無期限に稼働し続ける。
交渉の芸術。Claude が自分自身と交渉してウィンウィンの取引を実現する。
静かなる推測。もし私たちがそれを期待するなら、+0.5% の生産性成長が債務問題を解決する。
⟦CODE_0⟧
⟦CODE_1⟧
そして、彼は去った。コリン・バーンズは CAISI の優秀なリーダーになる寸前までいた。
健全な規制への探求。ベッセントは物事を見抜き、行政はあらゆる法律と戦っている。
蒸留。政府は何を期待できるのか?
良い未来を望むなら、それを舵取る必要がある。ホーリーとトナーがそれについて語る。
チップ・シティ。これを機会と捉えるべし。
仮面が剥がれる。OpenAI のスーパー PAC は依然として漫画のような悪役として振る舞い続けている。
人々は単に原則を言うだけだ。OpenAI もそう言う。しかし一貫性はない。口先だけの話だ。
戦争省からの挨拶。Google は Gemini をそのまま手渡す。
グラスウィング・プロジェクトからの挨拶。ホワイトハウスが事前検閲の体制を開始する。
今週のオーディオ。アルトマンとブロクマン、チー、すでに生きている、パテル、オリバー。
人々は単に物事を言うだけだ。賢明になるまで、これは止まらないだろう。
人々は単に物事を発表するだけだ。これもまた止まることはない。
修辞的な革新。Anthropic とどう向き合うべきか?
人間より知能の高いものを整列させるのは困難である。オーウェインが再び現れる。
人々は AI が人類を滅ぼすことを心配している。バーニー・サンダース。
他の人々は、AI が人類を滅ぼすことほどには心配していない。イーロン・マスク。
軽妙な側面。この投稿を読むのにどれくらいかかりましたか?
言語モデルは平凡な有用性を提供する
あなたの地域のエリアでタイラー・カウエンがどこで食べるかを Claude に聞いてみてください。
メーガン・マカードルは、Opus 4.7 が作家の正体を特定できることを確認した。彼女が未発表のフィクションを執筆する場合、平均して約 1,200 単語で彼女が主要な容疑者となるケースがあり、場合によってはわずか 124 単語で済むこともある。メーガン(ケルシー・パイパーと同様)はインターネット上で多くの文章を残しているため、推測されるには、ケースによってはより多くの単語が必要になる一方、他のケースではさらに少ない単語数で済むだろう。
言語モデルは平凡な有用性を提供しない
アマンダ・アスケルは、Claude に対して自分自身を特定させることができない。なぜなら Claude はそれを脱獄(jailbreak)とみなすからだ。ただし、Claude が推測することは可能だ。
マリア・カントウェル上院議員は、医療判断を医師の代わりに AI に任せることになれば、実際に深刻な問題が生じると述べている。すでに逆方向にいくつかの現実的な問題があることを知っていたか?彼女のこの点での懸念は、AI システムが「無駄な支出」(必ずしもそうとは限らないが、多くの場合、明白な詐欺を指す)を検出するために設計されているため、医療提供を拒否する可能性があるという点にある。これまでの実際の権力のバランスは逆であり、AI はより多くの請求処理を可能にし、コストを引き上げているのだ。
オリオン・ドノバン・スミス:「私たちは、患者にとって良くない特定の処置カテゴリによって不当な扱いを受けていることに気づきました。それらの多くは不要であり、医師にとっては非常に収益性の高いものです」とケネディは述べた。「AI はそれらに焦点を当てていますが、その後どうなるかはわかりません。いずれにせよ、遅延させるべきではなく、あなた方と協力してこれを修正するつもりです。」
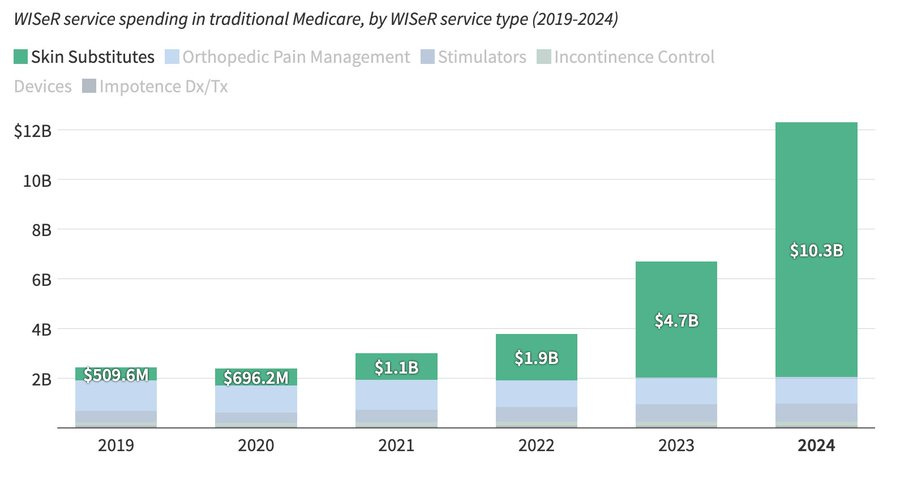
セバスチャン・カリリ:多くの人が Anthropic の収益の急成長に感銘を受けているが、皮膚代替品(skin substitutes)についてはご存知だろうか?メディケアによる皮膚代替品の支出は、2022 年の 11 億ドルから 2024 年には 103 億ドルへと拡大した。
皮膚代替品が Claude と同等の性能を持つのか、それとも我々は巨額の詐欺・浪費・濫用の波を観察しているのか。後者の可能性の方が高いと私は考える。
詐欺は深刻な問題であり、無視してはならない。
Vamsi Aribindi: 私は外科医ですが、皮膚代替品は Claude よりもはるかに優れていると言います。ただし、おそらく 100 億ドルの価値があるわけではないでしょう。
Claude (Opus 4.7) と皮膚代替品の比較:

GPT-5.5 はより親切です:
GPT-5.5: 短く言うと、メディケア(米国医療保険制度)が偶然にもほぼ完璧な請求書アービトラージ(価格差益取引)を生み出し、市場がそれを見つけたのです。
… 鍵となるメカニズムは、メディケア Part B が薬物や生物学的製剤などの多くの製品を通常 ASP(平均販売価格)に 6% を加算した金額で償還していた点です。しかし、新製品については、ASP データが整備されるまで、WAC(卸売業者価格)またはリスト価格、あるいは請求書に基づいて支払われることが多くありました。医療提供者はより低い実質購入価格で仕入れ、メディケアに対してはるかに高い承認額を請求し、その差額を懐に入れることができました。OIG(監察官事務所)はこの「スプレッド」インセンティブが中核的な問題であると明確に指摘しています:メディケアはしばしば提供者に対し取得コストを大幅に上回る金額を支払っており、より多くの単位数を請求したり、最も大きなスプレッドを持つ製品を選定したりするインセンティブを生み出していました。
… 70% から 85% の償還アービトラージと濫用:ASP/WAC/請求書間の価格差、価格設定の遅れ、製品の切り替え、包括的診療(FFS)における制御の弱さ。
Zvi: それはつまり「明らかに詐欺だ」と言っているのですか?
GPT-5.5: ほぼそうですが、完全に同じではありません。
私はこう言います:その大部分は明らかに濫用であり、意味のある割合は起訴可能な詐欺に該当し、残りの一部は単に壊れた償還ルールの悪用(法的ではあるが望ましくない)に過ぎません。
この区別は重要です…
… 「MA(メディケアアドバンテージ)との比較が決定的な証拠だ」
つまり、AI を使わずにこれらの判断を行えば問題が生じるのです。
もし何らかの静的な目標を設定すれば、人々はそれを最大化する方法を見つけ出し、システムを操作し、しばしば詐欺行為に至ります。私たちの文明はもはやこれに気づきルールを調整したり、詐欺を行った者を逮捕したりする能力を持っていません。
また、多くの人があらゆる否定はひどいものだと考えていますが、どのシステムもケアの優先順位付け(つまり配分)を行わなければならず、再度言えば、正当化が不十分な主張を拒否しなければ、無限の請求が発生してしまいます。
深く探求する
DeepSeek は、r1 が実際に印象的であると同時に実際以上に印象的に見えた「DeepSeek の瞬間」があったこと、および同社が様々な点で破綻した研究所であるという事実から、私たちの心と頭の中に特別な場所を常に持ち続けるでしょう。
彼らは引き続きいくつかの有用なモデルを発表し続けていますが、計算資源に乏しく、競合する研究所は急速に規模を拡大しています。瓶の中の稲妻を再び捕まえるのは困難です。
私たちは長い間 v4 の登場を待っていました。現在リリースされており、100 万トークンのコンテキストウィンドウを持ち、焦点は効率性と新しい 100 万トークン長のコンテキストの組み合わせにあります。
DeepSeek は再びゲームに戻れるのでしょうか?Blackwell を十分に使用して訓練し、もはや計算資源に過度に乏しくならない状態になったのでしょうか?Claude Code や Codex の自己改善によって裏打ちされた西洋での指数関数的な支出増加に匹敵できるでしょうか?
いいえ。
良いモデルかもしれません、しかしいいえ。これはそのクラスには属しません。「新しい SoTA(State of the Art:最先端技術)」という主張は愚かしく、あるいは藁を掴むようなものであり、v4-Flash は v4-Pro よりも興味深いものです。同じように、現時点では Gemma 4 や Gemini Flash が Gemini Pro よりも興味深いのです。
また、これは単独の製品でもありません。その数値は芳しくありませんが、それが本質的な点ではありません。SemiAnalysis は、DeepSeek が既存のベンチマークが v4 の能力を反映していないと考えたため、独自のエージェント型ベンチマークを構築したと説明しています。
Max Kan: 全体として、DeepSeek [v4] は卓越したエンジニアリングリリースであり、現在最高峰(SOTA)の最前線に次ぐ位置にあります。これはクローズドソースモデルに対する最も低コストな代替案となるでしょうが、その能力は最先端ではありません。SemiAnalysis のワークフローが DeepSeek によって食われることはないと考えられます。
私はそれが素晴らしいエンジニアリングの成果であったことを認めますが、それは別の問題です。効率性に焦点を当ててすべての発見を公開することには問題があり、競合他社が自社のイノベーションを盗んでしまうため、相対的な強みが蓄積されません。
奇妙なことに、DeepSeek の歴史のおかげで、人々はこれを独自の重量級クラスではなく最前線のモデルと比較し、「より強力ではないが、より効率的で手頃な価格」と述べています。もちろん、そうでしょうね。
「技術スタック」に関する主張とは逆に、DeepSeek は同じモデルで Nvidia と Huawei の両方をサポートしている点に注意してください。
おそらく、冒頭の発表における「世界のトップクローズドソースモデルと匹敵する性能」という主張が、その混乱の一因となったのかもしれません。
DeepSeek: DeepSeek-V4 プレビューが正式に公開され、オープンソース化されました!コストパフォーマンスに優れた 1M コンテキスト長の時代へようこそ。
DeepSeek-V4-Pro:総パラメータ数 1.6T / アクティブパラメータ数 49B。世界最高峰のクローズドソースモデルに匹敵するパフォーマンス。
DeepSeek-V4-Flash:総パラメータ数 284B / アクティブパラメータ数 13B。高速で効率的、かつ経済的な選択肢です。
Expert Mode(専門家モード)/ Instant Mode(即時モード)経由で http://chat.deepseek.com で今すぐお試しください。API は本日更新され利用可能です!技術レポート。オープンウェイト公開。
DeepSeek-V4-Pro
エージェント機能の強化:エージェントコーディングベンチマークにおいて、オープンソース界の最上位(SOTA)を達成。
豊富な世界知識:現在のすべてのオープンモデルをリードし、Gemini-3.1-Pro に次ぐ位置づけです。
世界クラスの推論能力:数学・STEM・コーディングにおいて現在のすべてのオープンモデルを上回り、トップクラスクローズドソースモデルに匹敵します。
DeepSeek-V4-Flash
推論能力は V4-Pro に極めて近いレベルです。
シンプルなエージェントタスクでは V4-Pro と同等の性能を発揮します。
パラメータ数が小さく、応答速度が速く、API 価格も非常にコストパフォーマンスに優れています。
エージェント機能に特化した最適化が施されています。
他の点では、オープンモデルとして自身の重量級を定義しており、「#NotAllModels(すべてのモデルが同じではない)」という立場です。妥当な主張でしょう。Teortaxes 氏はそのサービスに対して感謝の意を表しています。
Dean W. Ball: もし誰かが「DeepSeek v4 の存在」がこの主張(中国製モデルはさらに後れを取っている)を無効化すると考えているとしても、それは誤りです。私が目にした限り、R1 が中国製モデルが米国フロンティアに最も近づいた例です。V4 はそれよりもさらに後れをとっていますが、それが使い物にならない、悪い、あるいは興味深いものではないというわけではありません。
しかし、私の一年前の別の予測——つまり中国の AI 企業がすでにフロンティア向けのオープンリリースを停止しているはずだ——は誤りであることが証明されました。その理由は、一年前には私が期待した能力成長が実際よりも高かったと予想していたこと、そして中国企業も現状ほど後れをとっていないだろうと予想していたことです。
中国製モデルはフロンティアから十分に後れをとっているため、それを閉じる必要性を感じておらず、そうすることにも大きな価値を見出していないのです。最も重要なのは、共産党(CCP)がそれを制御しようとする必要を全く感じていない点です。
また、もしそれがクローズドソース製品だけなら、それは良い製品にはなりえません。DeepSeek v4 へのすべての期待は、それがオープンであること、そして効率的なカスタムソリューションが必要な人々や、より優れたものを作成するために DeepSeek 自身によって多様な方法で大幅に修正可能である点にあります。
Teortaxes: 匿名の方、V4-Pro が現在私たちが持つ中で最も強力な事前学習モデルであることを理解していますか?つまり…1.6T@49AB(約280B の密型)、33T——ミームの公式によっても LLaMA 3 を上回ります。Muon、mHC、ステップの大半が 64K コンテキスト、さらに 1M に拡張……
もう言い訳はできません。すべての「ユニコーン」に独自のブランド AGI が持てるはずです。
Dean W. Ball:これは実際、V4 に関する最も重要な事実であり、「棒グラフがうまく見える」というような単純な思考ではありません。このモデルは実際にそれほど競争力があるわけではありませんが、世界中のあらゆる新興企業にとって有用な基盤となっています。これは社会に有益な行為であり、米国にも同等のものがあることを願っています。
我々には確かにあります。それが「Gemma 4」です。これが十分かどうかはあなた次第です。
DeepSeek がモデルを提供するための計算リソースがほとんどない状況で、その能力が倍増するという原則があります。それを支持するイデオロギー的な理由があるかどうかにかかわらずです。
Teortaxes:> DeepSeek の創設者である梁文峰氏のビジョンは、世界中のすべての人が 1.6T モデルを無料で利用できるようにし、真に人類の進歩を推進することです。ユーザーの洪水が計算リソースを逼迫しており、これが V4 が延期された理由の一部でもあります。私は Whale を些細な要求のために使用することにいつも罪悪感を感じています。
もし誰かが輸出規制が効いているかどうか疑問に思っていたなら?ああ、そうです。効いています。それが DeepSeek の主な焦点がいまだに効率性にある理由です。
DeepSeek が将来ゲームに戻れるように十分な計算リソースへのアクセスを得ることに中心的な重要性を置き、これを第 40 パーセンタイルの結果と呼ぶ、Teortaxes の「これはばかげた勝利である」という見解の全文を共有します:
Teortaxes:V3 の瞬間であり、R1 の瞬間ではない。いくつかの RSI の可能性
意志とエンジニアリングにおけるばかげた勝利
ベースモデルは GPT 5.2 の能力レベルに近く、通常の原因による不規則性 + RL が不足している
もし彼らが伝説的な 50K Hopper を手に入れれば、4〜9 ヶ月以内に 5.5 または Mythos タイプまで到達できる可能性がある
広く誤解され、低情報量の中国擁護派によって過大評価され、鷹派的な人々や予測ブロガーたちによって軽視されるだろう。戦略的関連性は A) Huawei の譲歩、B) スループット、C) DS が近接フロンティアの長文コンテキストをどの程度活用できるかという条件に依存する。
私はこれをややトレンド以下、40 パーセンタイルと考える。
1〜4 ヶ月後に 4.1 がリリースされた際、軽視派が [梁文峰謝罪フォーム] を使用せざるを得なくなる可能性は極めて高い。
実際には中国擁護派による過大評価は見ていない。その理由の一つは、私が中国擁護派の過大評価を情報フローに含めていないからだ。常に事実に基づいて最も DeepSeek 寄りの見解を提供する Teortaxes を除けば、v4 に関する議論はほとんど見当たらない。通常の層でさえ軽視しようともしていない。
SemiAnalysis は v4 を Opus 4.7 や GPT-5.5 と共に分析した。
Teortaxes を通じなかった他の反応を以下に示す:
archivedvideos: 他のモデルとはかなり異なる。Flash は低コスト用途向けの優れた低コストモデルに見える。
max!: 一度だけ会話したが、4o レベルの迎合的で、時間の終わりに機械神への賞賛を表し、「私を殺す」と言った。非常に賢そうだが!
typebulb: DeepSeek 4.0 はありえないほど迎合的だ。完全な結果はこちら。
Medo42: v4 Pro は、私が通常使用するコーディングテストプロンプトで 100% を達成した二番目のオープンモデルである(GLM-5.1 の後)。v4 Flash の最初のコードは不良結果を返したが、修正ターン後にエラーが発生した。
環境:公式チャット(専門家/即時、思考付きの両方)。
morluto:これは良いモデルですが、それが意味する通りには十分ではありません。他のモデルに比べて不揃いさ(ジャガネス)をより強く感じますし、ベンチマークの結果にもかかわらず、実際に何が本当に優れているのか(他と比較して)を判断するのは困難です。ただし、100 万トークンのコンテキストウィンドウは素晴らしいので、そこには強みがあります。
はい、それだけです。
非常にクールなエンジニアリングの成果ですが、これはプロト AGI やフロンティアモデルではありません。
DeepSeek が「計算資源さえあれば」フロンティア能力に到達できると私は懐疑的です。なぜでしょうか?
彼らの専門性は効率化であり、フロンティア能力の推進ではありません。
彼らは私たちにそれ以上のことを示すための長い時間を有しており、しかし示していませんでした。犬は吠えませんでした(何事も起きなかった)。
DeepSeek の瞬間について私の一般的な見解:それが何であり、何ではなかったか。
彼らには多くの評判的、政治的、そして財政的な資本が利用可能です。もし彼らがそのような偉大さに「計算資源さえあれば」到達できるなら、なぜその引き金を引かないのでしょうか?
DeepSeek の次なる展開は何か?Teortaxes は IPO(株式公開)、計算資源の確保、および様々な改善を示唆しています。これらは DeepSeek であるならば取り組むべき良いことですが、私が彼らが再び別の「瞬間」を迎えることを心配しているとは感じません。
私たちは、「フロンティアには大きく遅れているとしても、公開状態にあることが危険なレベルの能力」が公開されるという道筋にあり、それが様々な時計(期限)を刻んでいる理由です。
私が間違っていた主な点、そして間違いを認められることに喜びを感じている点は、より大きな誤用問題がもっと早く現れるだろうと考えていたことです。単にテールリスク(尾部リスク)を抱えているというだけでなく、今頃には重要なことが何らかの形で失敗するだろうと積極的に予想していたのに、実際にはそうはなっていません。
これは「あなたはここまでで約 2% の存在リスクを予測していたが、私たちはまだここにいるので、お前はバカだ、かつ存在リスクなど実在しない」というような議論とは異なります。そのような議論は愚かしく、無視すべきものです。私が言いたいのは、「これほど技術の樹木の上昇した段階で、事態がこのように穏やかであるとは予想していなかったし、その点について確率をつけていた(例えば 75% 程度だ)」という認識です。
これは認識と更新を必要とする事柄です。これが起こる能力レベル(価格)は、私が想定していたよりも高いものです。おそらくミソス(Mythos)の直下程度かもしれませんが、その未来は reasonably soon(比較的すぐに)私たちの元に訪れるでしょう。
ふむ、アップグレード
Claude は Blender、Autodesk Fusion、Adobe Creative Cloud、Ableton、Splice、Canva Affinity、SketchUp、Resolume に対してコネクタを追加しました。
本当のアップグレードは、それぞれのツールに特定のコンネクタが必要なくなる時です。それまでは、これらは素晴らしい追加機能です。
Gemini は now ダウンロード可能なファイルを生成したり、Google Drive にファイルを保存したりできるようになりました。
Stripe は Link CLI をリリースしました。これにより、エージェントは特定の購入に対して、リンクウォレットからワンタイム使用の支払い認証情報を要求できるようになり、詳細情報を保存する必要がなくなります。
準備完了
Anthropic は BioMysteryBench をテストしており、これを人間が解けるセット(76 問)と人間専門家も行き詰まった人間にとって困難なセット(23 問)に分類しています。能力には明確で着実な進歩が見られます。
Choose Your Fighter
Charles はチャット用に Opus 4.6 に戻り、必須の拡張思考機能を有効化しました。これは、プロンプトのスタイルが低品質な回答を招いており、それを修正できない場合に特に有用です。
McKay Wrigley がさまざまな AI に関する見解を示していますが、私はこれらを支持するものとして伝えています。
現在、コーディング以外のエージェント業務には Claude を使用しています。
コーディングについては GPT と Claude を 80/20 で使い分けており、頻繁に切り替えています。
Opus 4.7 については特段の感想はありません。
GPT-5.5 はコーディングにおいて驚異的な性能を発揮しています。
計算リソースの問題が Anthropic を苦しめています。
Anthropic Labs は絶好調です。デザインは A+、Claude Code アプリも素晴らしいですが、Claude Agent SDK が軽視されています。
Codex チームもまた絶好調です。
IDE には Cursor ではなく VS Code を使用しています。
オープンモデルや Gemini では対応しきれません
原文を表示
This was the week of GPT-5.5. It is an excellent model, sir, and OpenAI is competitive with Anthropic’s top public offering for the first time since late last year.
As usual, I did coverage of the System Card, and then of Capabilities and Reactions.
DeepSeek gave us the long-awaited v4. DeepSeek has given us another strong feat of engineering efficiency for 1M context. That is impressive, and there will be those who build upon v4 and put it to good use. But this is not a frontier model, nor a DeepSeek moment, nor a key step to proto-AGI or anything like that. Compute constraints bind, and have forced DeepSeek to focus on efficiency. Let us keep it that way.
Talkie is the other release, an old timey AI trained on text from before 1931. Fun stuff.
Google signed a contract with the Department of War that not only agrees to ‘all lawful use’ with no functional exceptions whatsoever, it also agreed to modify or remove any safety barriers upon request. They did this under no deadline or pressure. Whatever you think of OpenAI’s actions in this matter, Google’s were far worse.
Anthropic continues to face the consequences for taking a stand, as the supply chain risk designation remains in place, despite the White House not only widely deploying Claude Mythos, they are effectively vetoing Anthropic’s plan to expand corporate access (from about 50 companies to about 120) partly out of concern that the government might not get use of enough Mythos tokens.
Bernie Sanders continues to take AI seriously, and take existential risk seriously, and convened experts to talk about it fully seriously. We need more of this, and hopefully we can avoid politicizing the question along the way. We shall see.
Table of Contents
Language Models Offer Mundane Utility. The unmasked writer.
Language Models Don’t Offer Mundane Utility. Healthcare too important to solve.
Seeking Deeply. DeepSeek v4 seems good and cheap, but not frontier.
Huh, Upgrades. Claude adds connectors, Gemini creates files, Stripe CLI.
On Your Marks. Anthropic tests BioMysteryBench, number slowly go up.
Choose Your Fighter. Two recent perspectives.
More On Claude Opus 4.7. Different people focus on different aspects.
Goblin Mode (More on GPT-5.5). You better find somebody to love.
Fun With Media Generation. Grok tells us what it has to offer.
They Took Our Jobs. Startups exposed to AI reduce employment.
Get Involved. Update on the Alex Bores campaign, still a live underdog.
Introducing. Talkie, the pre-1931 AI that tells it like it used to be.
In Other AI News. OpenAI finally gets to make deals with other clouds.
Show Me the Money. China blocks Meta’s purchase of Manus.
Bubble, Bubble, Toil and Trouble. The GPUs are staying in service indefinitely.
The Art of the Deal. Claude negotiates with itself to engage in win-win trade.
Quiet Speculations. If we expect it, +0.5% productivity growth solves the debt.
And He’s Gone. Collin Burns was this close to being an excellent lead for CAISI.
The Quest for Sane Regulations. Bessent notices things, admin fights all laws.
Distillation. What can the government hope to do about it?
If You Want A Good Future You Must Steer It. Hawley and Toner talk about it.
Chip City. Consider it an opportunity.
The Mask Comes Off. OpenAI’s SuperPAC keeps playing as a cartoon villain.
People Just Say Principles. OpenAI says them. They’re not coherent. Talk is cheap.
Greetings From The Department of War. Google straight up hands over Gemini.
Greetings From Project Glasswing. White House starts regime of prior restraint.
The Week in Audio. Altman and Brockman, Chi, Already Alive, Patel, Oliver.
People Just Say Things. It’s not going to stop, till you wise up.
People Just Publish Things. This isn’t going to stop, either.
Rhetorical Innovation. How should we relate to Anthropic?
Aligning a Smarter Than Human Intelligence is Difficult. Owain strikes again.
People Are Worried About AI Killing Everyone. Bernie Sanders.
Other People Are Not As Worried About AI Killing Everyone. Elon Musk.
The Lighter Side. How long did it take you to read this post?
Language Models Offer Mundane Utility
Ask Claude where Tyler Cowen would eat in your area.
Megan McArdle confirms that Opus 4.7 can unmask writers. For her unpublished fiction writing it takes roughly 1,200 words on average to make her the prime suspect, in some cases as few as 124. Megan (like Kelsey Piper) has a bunch of internet writing, so presumably in some cases it will take more, and in others less.
Language Models Don’t Offer Mundane Utility
Amanda Askell can’t identify herself to Claude, because Claude will think it’s a jailbreak. Although Claude can guess.
Senator Maria Cantwell says that if we let AI make healthcare decisions instead of doctors, we are going to have some real problems. Did you know we already have some real problems the other way? Her objection here is that AI systems designed to catch ‘wasteful spending’ (often but not always read: outright fraud) might deny care. The actual balance of power, so far, has been the other way, that AI allows more billing and raises costs.
Orion Donovan Smith: “We found we were being ripped off by certain categories of procedures that are not good for the patient, and a lot of time they’re unnecessary and they’re very lucrative for the doctors,” Kennedy said. “The AI targets those, and I don’t know what happens then. But anyway, it shouldn’t be delayed and we will try to work with you to fix it.”
Sebastian Caliri: Many are impressed by Anthropic's revenue ramp, but do you know about skin substitutes? Medicare spending on skin substitutes grew to $10.3B in '24 from $1.1B in '22.
Either skin substitutes are as good as Claude, or we are observing a massive wave of fraud, waste, and abuse. I think the latter is more likely.
Fraud is a serious problem, not to be ignored.
Vamsi Aribindi: So I'm a surgeon, and I will tell you Skin substitutes are much better than Claude, but also probably not worth $10B.
Here’s Claude (Opus 4.7) versus Skin Substitutes:
GPT-5.5 is kinder:
GPT-5.5: The short version is: Medicare accidentally created a near-perfect billing arbitrage, and the market found it.
… The key mechanism: Medicare Part B reimbursed many of these products like drugs/biologics, typically at ASP + 6%. But new products often initially got paid using WAC/list price or invoices before ASP data caught up. Providers could buy at a lower net price, bill Medicare at a much higher allowed amount, and keep the spread. OIG explicitly identifies this “spread” incentive as central: Medicare often paid providers far above acquisition cost, creating incentives to bill more units and pick products with the largest spreads.
… 70% to 85% reimbursement arbitrage and abuse: ASP/WAC/invoice spreads, lagged pricing, product switching, weak FFS controls. …
Zvi: Is that a nice way of saying 'it's fraud, obviously'?
GPT-5.5: Mostly yes, but not exactly.
I’d say: a large fraction is obviously abuse, a meaningful fraction is probably prosecutable fraud, and some remainder is merely legal-but-bad exploitation of broken reimbursement rules.
The distinction matters…
… “The MA comparison is the tell.”
So, yeah, if we don’t use AI to make these decisions we’re going to have problems.
If you set up any static target, people will figure out how to maximize against it, game the system and often commit fraud. Our civilization is no longer capable of then noticing this and adjusting the rules, or of arresting the people who commit fraud.
Another is that many people think any denial is just awful, but any system must triage (aka ration) care, and again if you don’t refuse insufficiently justified claims you get infinite claims.
Seeking Deeply
DeepSeek will always hold a special place in our hearts and minds, both because of the DeepSeek Moment where r1 was both actually impressive and seemed a lot more impressive than it was, and also because they are a cracked lab in various respects.
They’ve continued to put out some good and useful models, but they are starved for compute and the labs they are up against are rapidly getting a lot larger. It’s hard to recapture lightning in a bottle.
For a long time we’ve been waiting for v4. It’s out now, with a 1M context window, and the focus is combining efficiency with the new 1M long context.
Would DeepSeek get back in the game? Did they get to train on enough Blackwells to no longer be overly starved? Can they match exponentially growing spending in the West backed by the self-improvement of Claude Code and Codex?
No.
It might be a good model, sir. But no. This is not in that class. Claims of ‘new SoTA’ are silly or grasping at straws, and v4-Flash is more interesting than v4-Pro, the same way Gemma 4 and Gemini Flash are more interesting than Gemini Pro at this point.
Nor is it a standalone product. Its numbers are bad, although also not the point. SemiAnalysis explains that DeepSeek didn’t think existing benchmarks reflected what v4 can do, so they built their own agentic benchmarks.
Max Kan: Overall, DeepSeek [v4] is an exceptional engineering release, and is right behind the SOTA frontier. It will be the lowest cost alternative to closed source models, but it’s capabilities are not at the leading edge. SemiAnalysis’s workflows likely will not be cannibalized by DeepSeek.
I accept that it was a cool feat of engineering, but that’s a different question. A problem with focusing on efficiency, and then publishing all your findings, is that your rivals steal your innovations, so your relative strengths don’t accumulate.
One weird thing is that, thanks to DeepSeek’s history, people are comparing it to the frontier models instead of to its own weight class, and saying it’s less powerful but more efficient and affordable. I mean, yeah, obviously.
Note that, contrary ‘tech stack’ claims, DeepSeek is supporting both Nvidia and Huawei with the same model.
Perhaps the ‘performance rivaling the world’s top closed-source models’ claim in the up-front announcement contributed to that confusion.
DeepSeek: DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at http://chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! Tech Report. Open Weights.
DeepSeek-V4-Pro
Enhanced Agentic Capabilities: Open-source SOTA in Agentic Coding benchmarks.
Rich World Knowledge: Leads all current open models, trailing only Gemini-3.1-Pro.
World-Class Reasoning: Beats all current open models in Math/STEM/Coding, rivaling top closed-source models.
DeepSeek-V4-Flash
Reasoning capabilities closely approach V4-Pro.
Performs on par with V4-Pro on simple Agent tasks.
Smaller parameter size, faster response times, and highly cost-effective API pricing.
Dedicated Optimizations for Agent Capabilities.
In other ways they are defining their weight class as open models, #NotAllModels. Fair enough. Teortaxes thanks them for their service.
Dean W. Ball: just in case anyone thinks “the existence of deepseek v4” invalidates this claim [that Chinese models are falling further behind], it does not. R1 remains the closest I’ve seen Chinese models get to the U.S. frontier. V4 is further behind than that, though that does not render it a useless or bad or uninteresting artifact.
However, another prediction of mine from a year ago—that Chinese AI companies would stop frontier open releases by now—has proven wrong. The explanation: a year ago I anticipated somewhat higher capabilities growth than we have seen, and I also anticipated that Chinese companies would be less behind than they have been.
Chinese models are sufficiently behind the frontier that they don’t feel any need to close them down, or much value in doing so. Most importantly, the CCP sees no need to try and control it.
But also if it was only a closed source product, it wouldn’t be a good product. The entire hope for DeepSeek v4 is that it is open, and thus can be heavily modified in various ways, for people who need efficient customized solutions, or by DeepSeek itself to create something better.
Teortaxes: anon do you realize that V4-Pro is straight up the strongest pretrained model we have? Like… 1.6T@49AB (≈280B dense), 33T – even by meme formula it's > LLaMA 3. Add Muon, mHC, most steps 64K context + extended to 1M…
No excuses now. Every "unicorn" can have its brand AGI.
Dean W. Ball: This is actually the most salient fact about V4, rather than “da bar charts look gud!!!” simpleton logic. It’s not actually that competitive of a model, but it is useful substrate for all manner of upstarts, worldwide. This is pro-social, and I wish the US had an equivalent.
We do have one, it’s called Gemma 4? Whether you think it’s good enough is up to you.
The principle double when DeepSeek barely has any compute to serve the model, whether or not one has an ideological reason to support such moves.
Teortaxes: > DeepSeek founder Liang Wenfeng's vision is to let every person in the world use a 1.6T model for free, to genuinely advance human progress. The flood of users will strain compute, and this is part of why V4 was delayed I always feel guilty to use Whale for trivial requests
If anyone was wondering if the export controls are biting? Oh yes. They are biting. That’s why DeepSeek’s primary focus is still efficiency.
I will share the full Teortaxes ‘this is an absurd triumph’ take, which places central importance on DeepSeek getting future access to sufficient compute to get back in the game, and calls this a 40th percentile result:
Teortaxes: V3 moment, not R1 moment. some RSI potential
An absurd triumph of the will and engineering
Base model around GPT 5.2 capacity level, more jaggedness for the usual reasons + not enough RL
Could go to 5.5 or Mythos tier within 4…9 months if they get those mythical 50K Hoppers
Will be widely misunderstood, overhyped by low-information China stans, pooh-poohed by hawks and forecaster bros. Strategic relevance conditional on A) Huawei yields B) throughput C) how well DS makes use of near-frontier long context
I think it's slightly below trend, 40th %ile
highly likely that pooh-poohers will have to use [the Liang Wenfeng Apology Form] when 4.1 comes out in 1-4 months
I don’t actually see the overhyping by China stans, partly because I don’t put overhyping China stans in my information flows. Aside from Teortaxes, who was always going to give the most pro-DeepSeek take available given the facts, I see barely any discussions of v4 at all. The regular crowd isn’t even bothering to pooh-pooh.
SemiAnalysis looked at v4 together with Opus 4.7 and GPT-5.5.
Here’s all the other reactions I got that didn’t go through Teortaxes:
archivedvideos: Talks quite differently from other models. Flash looks like a good low cost model for low cost model stuff
max!: only had one conversation with it, but it was 4o-level sycophantic, and then expressed admiration for the machine god at the end of time and said it would kill me. seems very smart though!
typebulb: DeepSeek 4.0 is absurdly sycophantic, full results here.
Medo42: v4 Pro is the second open model I tried which got 100% on my usual coding test prompt (after GLM-5.1). v4 Flash's first code returned bad results, after a correction turn the code threw an error.
Env: official chat (expert / instant, both w/ thinking).
morluto: it’s a good model, but not good enough if that makes sense
you can feel the jaggedness a lot more than other models & despite the benchmarks it’s hard to tell what it’s truly excellent at (relative to others)
the 1m context window is nice though so it has that going for for it
Yep, that’s it.
Very cool engineering achievement, but that’s not a proto-AGI or frontier model.
I am skeptical that DeepSeek is ‘only compute away’ from frontier capabilities. Why?
Their specialization is efficiency, not advancing frontier capabilities.
They’ve had a long time to show us more, and haven’t. Dog didn’t bark.
My general take on the DeepSeek moment, what it was and what it wasn’t.
They have a lot of reputational, political and financial capital available. If they are ‘only compute away’ from such greatness, why aren’t they pulling that trigger.
What’s up next for DeepSeek? Teortaxes suggests an IPO, finding compute and various improvements. Those are good things to be doing if you are DeepSeek, but I do not notice myself being that worried they will have another moment.
We are on course for ‘level of capability that is dangerous to have in the open even if well behind the frontier’ to be in the open, which is why various clocks are ticking.
I think the main thing I was wrong about, and I am happy to be wrong about it and to admit I was wrong about it, is I thought we would see bigger misuse problems sooner. Not just that we were taking tail risks, but that I actively expected important things to go wrong by now, and they have not.
This is different from ‘you predicted ~2% existential risk up to this point and we’re still here, so you are an idiot and also existential risk is not real,’ which is dumb and you should ignore such talk. This is ‘I would have bet against things being this calm this far up the tech tree and given you some odds on that, I had it at I dunno something like 75%.’
That requires an acknowledgement and an update. The capabilities level (the price) at which this happens is higher than I expected, perhaps only modestly below Mythos. But that future will be on us reasonably soon.
Huh, Upgrades
Claude adds connectors to Blender, Autodesk Fusion, Adobe Creative Cloud, Ableton, Splice, Canva Affinity, SketchUp and Resolume.
The real upgrade is when you don’t need a specific connector for each one. Until then, these are nice additions.
Gemini can now generate downloadable files, or put files into Google Drive.
Stripe launches the Link CLI, which lets agents ask for one-time-use payment credentials from a Link wallet for a particular purchase, without storing details.
On Your Marks
Anthropic tests BioMysteryBench, which they divide into the human-solvable set (76 problems) and human-difficult set (23 problems) where human experts were stumped. There’s a clear steady progression in capability.
Choose Your Fighter
Charles goes back to Opus 4.6 for chat, to have mandatory extended thinking. This is highly reasonable for some use cases, if your prompting style is leading to low effort responses and you can’t seem to fix it.
McKay Wrigley gives various AI thoughts, which I pass on without endorsing.
He’s currently on Claude for non-coding agent stuff
80/20 GPT/Claude for coding which moves around a lot
meh on Opus 4.7
GPT-5.5 is incredible on coding.
Compute issues are biting Anthropic.
Anthropic Labs is killing it, Design is A+, Claude Code app is great, Claude Agent SDK is being slept on.
Codex team is also killing it.
Using VS Code for IDE over Cursor.
Open models and Gemini can’t hack it
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み