Apple Silicon で MLX を用いた言語モデルのファインチューニング
KDnuggets は、Apple Silicon 上で言語モデルをファインチューニングするための専用フレームワーク「MLX」の活用方法と、その技術的優位性について解説している。
キーポイント
Apple Silicon 最適化フレームワーク MLX の紹介
Apple が開発した MLX は、M シリーズチップのアーキテクチャに特化し、メモリ効率と計算速度を最大化するよう設計されたフレームワークである。
ローカル環境でのファインチューニングの実現
クラウド依存なしで Mac 上で大規模言語モデルの微調整が可能となり、開発コストとデータプライバシーの観点から大きな利点をもたらす。
PyTorch との親和性と使いやすさ
MLX は PyTorch に似た API を採用しているため、既存の PyTorch ユーザーが学習コストを低く抑えて移行・活用できる。
影響分析・編集コメントを表示
影響分析
この技術は、クラウドプロバイダーへの依存を減らし、個人開発者や中小企業が高性能な AI モデルを低コストで構築・微調整できる道を開く。特にデータプライバシーが重視される分野や、オンプレミス環境での AI 実装において、Apple Silicon を活用したローカルファインチューニングの標準的なアプローチとして定着する可能性がある。
編集コメント
クラウド依存からの脱却という文脈で、Apple のハードウェアとソフトウェアの統合が強力な競争優位性を生み出している好例と言えます。
 image**
image**
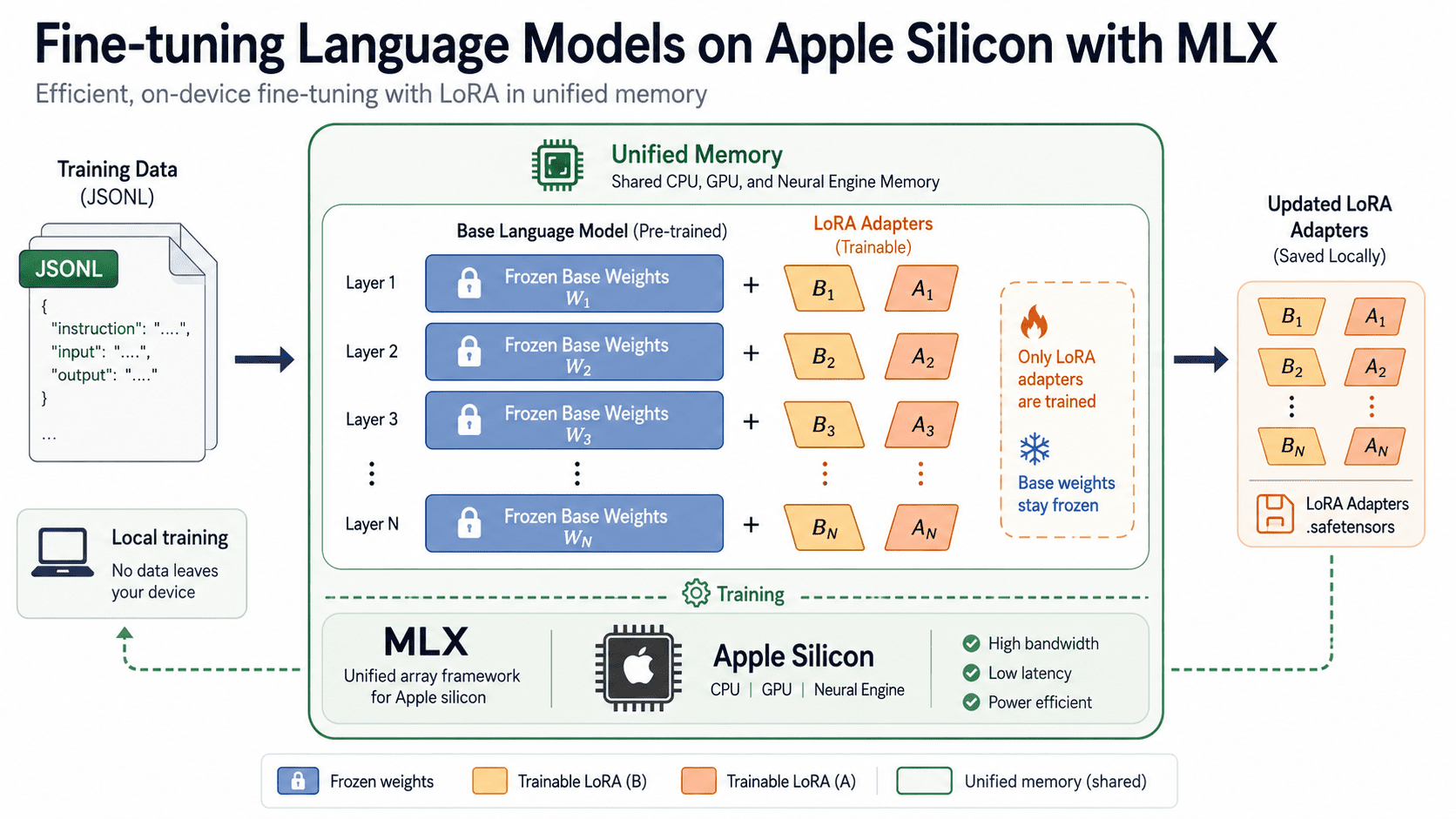
言語モデルのファインチューニングとは、かつてクラウド GPU をレンタルしてメーターが回るのを眺めることを意味していました。Apple Silicon チップを搭載した Mac をお持ちであれば、今や、お使いのラップトップに搭載されているハードウェアのために特別に構築されたフレームワークを使用して、オープンソースモデルをローカルで独自データに適応させることが可能になりました。クラウドコストはゼロです。
私は 2014 年に Windows や Dell マシンから Mac へ移行し、それ以来一度も後悔したことはありません。よりクリーンなオペレーティングシステムへの好奇心から始まったこの選択は、Apple がハードウェアとソフトウェアをいかに密接に統合しているかに対する深い理解へと発展しました。10 年以上が経過した今、その統合は予想もしなかった恩恵をもたらしています。最も最近では、クラウド請求書なしで、かつデータが機械から 1 バイトも流出させることなく、言語モデルを完全にオンデバイス上でファインチューニングできる能力です。
この機能は、Apple の機械学習研究チームが開発したオープンソースの配列ライブラリ MLX と、そのコンパニオンパッケージ MLX LM によって支えられています。後者は、少数のコマンドを通じて数千ものオープンモデルに対するテキスト生成とファインチューニングを提供します。このチュートリアルでは、ツールのインストールからデータセットの準備、LoRA アダプター(Low-Rank Adaptation)のトレーニング、量子化によるメモリ使用量の削減、そして結果のテストと提供まで、一連のプロセスを最初から最後まで詳しく解説します。これにより、ご自身のマシン上で動作するファインチューニング済みモデルと、あらゆるデータセットに適用可能な反復可能なワークフローを手に入れることができます。
# なぜ MLX が Apple Silicon に適しているのかを理解する
**
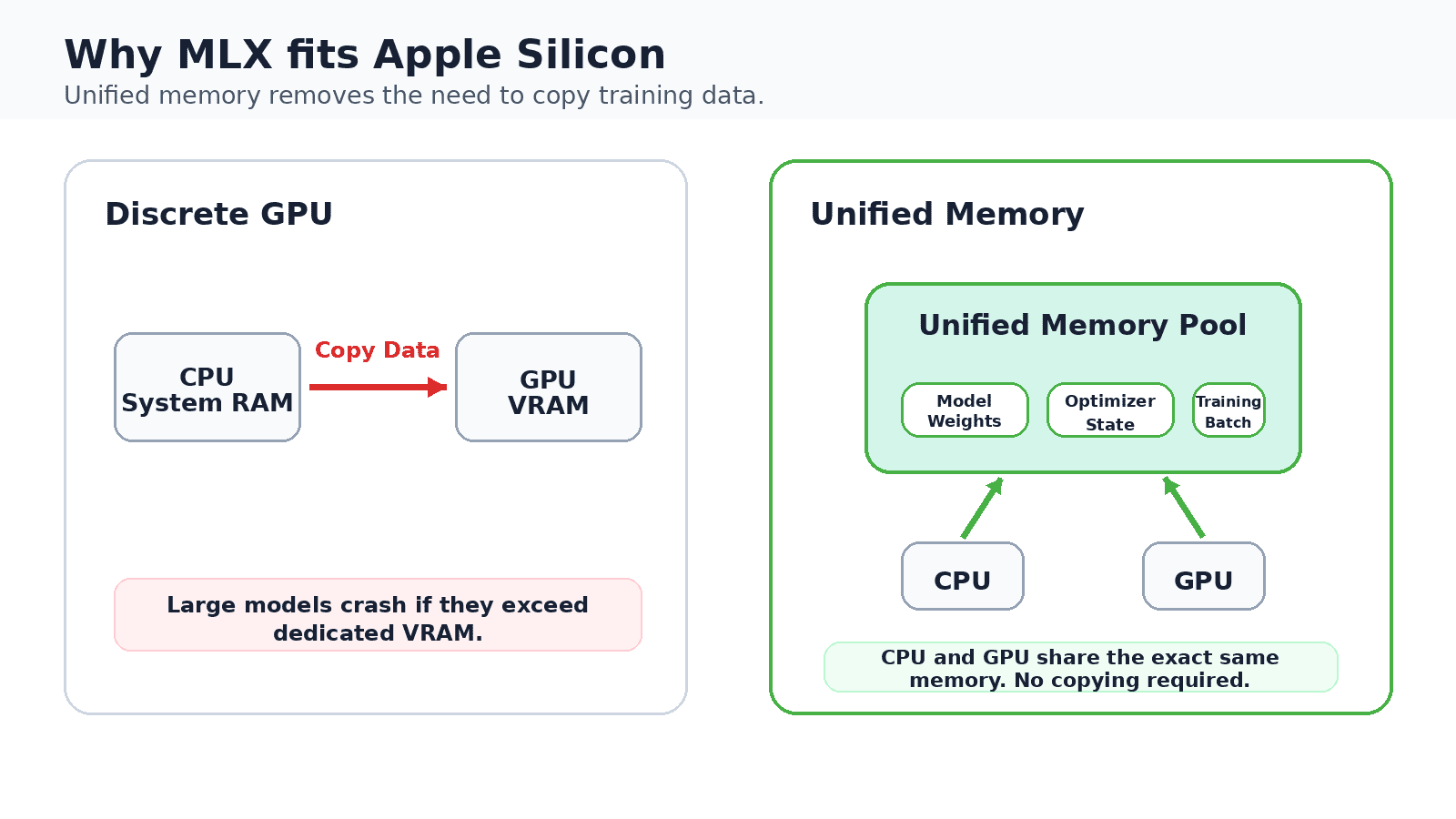
多くのローカル推論ツールは元々 NVIDIA ハードウェア向けに開発され、後に Mac へ移植されました。一方、MLX はその逆のアプローチを採用しています。Apple の研究チームは、CPU と GPU が単一のメモリプールを共有する Apple Silicon のユニファイドメモリアーキテクチャ(Unified Memory Architecture)を中心に、ゼロから設計しました。
この設計により、通常はシステムメモリと専用 GPU メモリの間でデータを転送するコピーステップが不要になります。16 GB の Mac では、モデルの重み、オプティマイザの状態、トレーニングバッチがすべて同じ領域に共存し、これがオンデバイスでのファインチューニングを夢物語ではなく現実的なものにする理由です。この API は NumPy に非常に似ており、トレーニングのための自動微分機能を追加し、Metal を使用して GPU 処理を加速しながら、その共有メモリビューを維持します。
始める前に、Apple Silicon Mac(M1 以降)、macOS Ventura 13.5 以降、Python 3.10 以上が必要です。Intel 搭載の Mac はサポートされていません。これらにインストールしようとすると、「一致する配布版が見つかりません」というエラーが表示されます。
 image**
image**
専用 GPU では、トレーニングデータはシステムメモリと専用 GPU メモリの間でコピーされます。Apple Silicon は単一の共有プールを維持しており、これにより 16 GB の Mac でローカルにモデルのファインチューニングが可能になります。
# 環境の設定
このアーキテクチャを念頭に置き、ツールをインストールしましょう。まずはパッケージとトレーニング用の追加機能を開始します。これにより、ファインチューニングコマンドに必要なすべてのものが読み込まれます。
pip install "mlx-lm[train]"
小さなモデルに対してクイックな生成テストを実行し、インストールが正常に動作したことを確認してください。
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--prompt "Explain LoRA in two sentences." \
--max-tokens 120
最初の実行では、Hugging Face 上の MLX Community オrganization から 4 ビット量子化された Mistral** モデルをダウンロードし、ローカルにキャッシュした上でレスポンスをストリーミングします。mlx-community org は数千の事前変換済みモデルをホストしており、自分で重みを変換する必要はほとんどありません。
最初に注意すべき制約の一つ:MLX のファインチューニングには、Hugging Face の safetensors 形式のモデルが必要です。他のローカルツールで一般的な GGUF ファイルは推論には使用できますが、ここではトレーニングには対応していません。サポートされているアーキテクチャには Llama、Mistral、Qwen2、Phi、Gemma、Mixtral などがあり、ほとんどの人気オープンソースモデルはそのまま利用可能です。
# データセットの準備
**
これで環境が整ったので、次のステップはデータをトレーニングツールが使用できる形式に整形することです。MLX LM は、train.jsonl、valid.jsonl、およびオプションの test.jsonl の 3 つのファイルを含むフォルダからトレーニングデータを読み取ります。各行には 1 つの JSON 例が含まれます。トレーニングファイルは必須であり、検証ファイルはトレーニング実行中に検証損失を報告するために使用され、テストファイルはトレーニング完了後にモデルの評価を行います。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
3 つの形式がサポートされています:チャット、補完(completions)、およびテキストです。チャット形式は最も堅牢なデフォルトであり、役割タグ付きメッセージを各行に格納し、MLX LM がモデル固有のチャットテンプレートを使用できるようにするため、データがモデルが会話処理のためにどのように訓練されたかに一致します。
{"messages": [{"role": "user", "content": "LoRA とは何か?"}, {"role": "assistant", "content": "モデルをファインチューニングするための効率的な方法。"}]}
単純な入力と出力のペアには、補完形式がよりシンプルで、指示スタイルのタスクにうまく機能します。
{"prompt": "要約:今日は市場が急騰した。", "completion": "市場は上昇した。"}
{"prompt": "フランス語に翻訳:おはようございます", "completion": "bonjour"}
デフォルトでは、トレーナーは例全体に対して損失を計算するため、モデルは答えだけでなくプロンプトの再現も学習しようとして努力を費やします。--mask-prompt を渡すことで、補完部分のみに対して損失を計算するように指示でき、トレーニングが実際に重視する応答に焦点を当てることができます。これにより、通常、指示により確実に従うモデルが生成され、チャット形式および補完形式の両方で機能します。チャットデータの場合、リスト内の最終メッセージは補完として扱われます。
各例は内部の改行を含まない単一行に保ち、読者が各行を別々のレコードとして扱うようにしてください。データを分割し、約 80 パーセントを train.jsonl に、10 から 20 パーセントを valid.jsonl に割り当ててください。モデルの挙動を変更するには、200 から 500 例程度が合理的な最小限です(それより少ない場合、一般化よりも過学習や暗記に陥る傾向があります)。
# 最初の LoRA アダプターのトレーニング
データが準備できたら、ここから本格的に面白くなってきました。モデルのすべての重みを更新するのではなく、Low-Rank Adaptation (LoRA) は元の重みを凍結し、その横に小さなアダプター行列を訓練します。これにより、フルファインチューニングと比較してメモリとストレージの必要量が大幅に削減されながら、品質の大部分は維持されます。この手法は Hu 氏らによる LoRA paper に由来しています。

LoRA は大規模な事前学習済み重みを凍結したまま、小さな行列 A と B のみ訓練します。この 2 つのアダプターのみが更新されるため、メモリとストレージの使用量は低く抑えられます。
1 つのコマンドでトレーニング実行を開始し、モデルとデータフォルダーを指定してください。
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--train \
--data ./data \
--iters 600 \
--batch-size 1
実行中、MLX LM はトレーニング損失、検証損失、処理されたトークン数、および 1 秒あたりのイテレーション数を出力します。アダプター重みはデフォルトで adapters フォルダに保存されます。知っておくべき重要なフラグには、--fine-tune-type(lora(デフォルト)、dora、または full を指定可能)、--num-layers(アダプターが適用されるトランスフォーマー層の数を設定、デフォルト:16)、そして --iters(トレーニング長さを制御)があります。
この例では、メモリ使用量を可能な限り低く抑えるために意図的に --batch-size 1 を設定しています。これにより、16 GB マシンでのクラッシュを防ぎます。64 GB 以上のメモリがある場合は、これを 2 または 4 に上げることで総トレーニング時間を短縮できます。メモリが逼迫しているが、より大きなバッチの平滑化効果を望む場合、--grad-accumulation-steps を使用すると、メモリ使用量を増やすことなく有効なバッチサイズを上げることができます。
ターミナル出力よりもライブグラフを好む場合は、--report-to wandb を追加して Weights & Biases にメトリクスをログ記録できます。メモリ圧力に直面した場合は、--num-layers を 8 または 4 に下げるか、--grad-checkpoint を追加して計算量を犠牲にしてメモリ使用量を削減します。これらの 2 つのフラグは、通常、 otherwise メモリ不足になるジョブを収容するのに十分です。
# ベースモデルとアダプター設定の選択
上記のトレーニングメカニズムに基づき、実行の残りを形作る初期の意思決定が 2 つあります。それは、どのモデルから始めるか、そしてそのどの部分を適応させるかです。最初のプロジェクトでは、4 ビット形式の 8B パラメータモデルが最適な選択です。ワークフローに慣れたら、13B または 14B モデルへと移行できます。これらは 14〜18 GB の作業メモリを必要とし、32 GB マシン上で快適に動作します。
学習する層の数とアダプタのランクは、合わせてモデルの容量を制御します。より多くの層と高いランクを設定すると、アダプタが学習するための余地が増えますが、その分メモリと時間のコストがかかります。一般的な出発点として、中程度のランクを持つ 16 層を使用し、検証損失がまだ低下しているかどうかに基づいて調整を行います。もし訓練損失は低下する一方で検証損失が上昇する場合、アダプタが例を暗記してしまっている可能性があります。
学習率も重要です。1e-5 から 5e-5 の範囲の値が、ほとんどの LoRA 実行で機能します。高すぎると訓練が不安定になり、低すぎるとモデルがほとんど動きません。改善点を特定の選択に帰属させるために、一度に一つの設定を変更してください。
# 量子化によるメモリ使用量の削減
上記のベースモデルはすでに 4bit で終わっていることに気づいたでしょうか。量子化されたモデルの上に LoRA アダプタを訓練することは、QLoRA と呼ばれ、QLoRA paper で説明されています。MLX には量子化が組み込まれているため、追加の設定なしに、同じ mlx_lm.lora コマンドで量子化された重みの上に直接アダプタを訓練できます。
その効果は具体的です。4 ビットの 7B モデルを使用すると、フル精度と比較して重みのメモリ使用量を約 3.5 倍削減でき、7B のファインチューニングを 8 GB の作業メモリ内で快適に実行できるようになります。16 GB の MacBook では、OS と訓練バッチのために十分な余裕が残ります。
もし訓練前に自分でフル精度のモデルを量子化したい場合は、convert コマンドが対応しています。
mlx_lm.convert \
--hf-path mistralai/Mistral-7B-Instruct-v0.3 \
--mlx-path ./mistral-4bit \
-q
これは、後で --model 引数に渡すローカルフォルダへ 4 ビット版を出力します。
# アダプターを用いたテストと生成
**
トレーニングが完了したら、アダプターの学習成果を確認する時です。保持しておいたテストセットに対してスコアリングを行い、実験間で追跡可能な数値を取得してください。
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--data ./data \
--test
モデルの応答を確認するには、生成コマンドにも同じアダプターパスを指定します。MLX LM はベースモデルを読み込み、その上にアダプターを適用します。
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--prompt "Summarize: Our quarterly revenue grew twelve percent."
比較のために、アダプターなしで同じプロンプトを実行してください。データセットが対象タスクに適切にマッチしている場合、適応された応答はベースモデルよりもトレーニング例により忠実に追跡するはずです。
# モデルの融合と提供
アダプターは実験中には便利ですが、デプロイでは単一の自己完結型モデルを望むことがよくあります。fuse コマンドは、アダプターをベース重みへ再び統合します。
mlx_lm.fuse \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--save-path ./fused-model
融合されたフォルダは、他の MLX モデルと同様に動作します。OpenAI 互換のエンドポイントを通じて提供することで、ベース URL の変更のみで既存のクライアントコードがローカルモデルと通信できるようになります。
mlx_lm.server --model ./fused-model --port 8080
グラフィカルな代替手段として、LM Studio は MLX モデルをワンクリックでローカルサーバーとして起動し、チャットインターフェースを提供します。特に、微調整したモデルを他のモデルと並列比較したい場合に非常に有用です。
# まとめ
これで、完全なローカルでのファインチューニングワークフローが整いました:MLX LM のインストール、JSONL 形式へのデータセット整形、単一コマンドによる LoRA または QLoRA アダプターのトレーニング、テスト、そして結果の融合と提供です。すべてが既に所有している Mac で実行され、クラウド利用料も発生せず、データがマシンから外部に流出することもありません。
私にとってこれは、2014 年に Mac に移行した際に始まった旅の自然な延長線上にあると感じます。当初私が惹かれたハードウェアとソフトウェアの緊密な統合は、静かに進化し、今や台所のような場所でも本格的な機械学習作業が可能になるほど強力なマシンへと発展しました。
次に探求する価値のある方向性がいくつかあります。dora のファインチューニングタイプを試して、その結果を通常の LoRA と比較してください。品質と速度のバランスを取るために、トレーニング対象となる層の数や反復回数を調整します。異なるベースアーキテクチャに切り替えても構いません。Llama、Qwen、Phi、Gemma はすべて同じコマンドで動作します。ハードウェアが机の上にある場合、各実験は低コストで行えるため、これが言語モデルの適応において MLX がもたらす実用的な変化です。
Vinod Chugani は、新興 AI 技術と実務家向けの実際の適用との間のギャップを埋める AI およびデータサイエンスの教育者です。彼の専門分野には、エージェント型 AI(Agentic AI)、機械学習アプリケーション、自動化ワークフローが含まれます。技術メンターおよび講師としての活動を通じて、Vinod はスキル開発やキャリア転換におけるデータ専門家を支えてきました。彼は定量的金融からの分析専門知識を実践的な指導アプローチに活かしています。彼のコンテンツは、プロフェッショナルがすぐに適用できる実行可能な戦略とフレームワークを強調しています。
原文を表示
**
Fine-tuning a language model used to mean renting cloud GPUs and watching the meter run. If you own a Mac with an Apple Silicon chip, you can now adapt an open model to your own data locally, at zero cloud cost, using a framework built specifically for the hardware sitting in your laptop.
I made the switch from Windows and Dell machines to Mac back in 2014 and never looked back. What started as curiosity about a cleaner operating system turned into a deep appreciation for how tightly Apple integrates hardware and software. Over a decade later, that integration is paying dividends I never anticipated, most recently in the ability to fine-tune language models entirely on-device, without a cloud bill or a single byte of data leaving my machine.
That capability is powered by MLX, an open source array library from Apple's machine learning research team, and its companion package MLX LM**, which provides text generation and fine-tuning for thousands of open models through a small set of commands. This tutorial walks through the full process end to end: installing the tools, preparing a dataset, training a LoRA adapter, shrinking memory use with quantization, then testing and serving the result. By the end, you'll have a fine-tuned model running on your own machine and a repeatable workflow you can point at any dataset.
# Understanding Why MLX Suits Apple Silicon
**
Most local inference tools started life on NVIDIA hardware and were later ported to the Mac. MLX took the opposite route. Apple's research team designed it from scratch around the unified memory architecture of Apple Silicon, where the CPU and GPU share a single pool of memory.
That design removes the copy step that usually shuttles data between system memory and dedicated GPU memory. On a 16 GB Mac, the model weights, optimizer state, and training batch all coexist in the same space, which is exactly what makes on-device fine-tuning practical rather than aspirational. The API mirrors NumPy closely, adds automatic differentiation for training, and uses Metal** to accelerate GPU work while keeping that shared view of memory.
Before you start, you'll need an Apple Silicon Mac (M1 or newer), macOS Ventura 13.5 or later, and Python 3.10 or above. Intel Macs are not supported. Trying to install on one returns a "no matching distribution" error.
**
On a discrete GPU, training data is copied between system memory and dedicated GPU memory. Apple Silicon keeps one shared pool, which is what lets a 16 GB Mac fine-tune models locally.
# Setting Up Your Environment
With that architecture in mind, let's get the tools installed. Start with the package and its training extras, which pull in everything the fine-tuning commands need.
pip install "mlx-lm[train]"Confirm the install works with a quick generation test against a small model.
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--prompt "Explain LoRA in two sentences." \
--max-tokens 120The first run downloads a 4-bit quantized Mistral model from the MLX Community organization on Hugging Face**, caches it locally, then streams a response. The mlx-community org hosts thousands of pre-converted models, so you rarely need to convert weights yourself.
One constraint worth noting early: MLX fine-tuning requires models in Hugging Face safetensors format. GGUF files, common in other local tools, work for inference but not for training here. Supported architectures include Llama, Mistral, Qwen2, Phi, Gemma, and Mixtral, among others, so most popular open models are available out of the box.
# Preparing Your Dataset
**
Now that the environment is ready, the next step is getting your data into a shape the trainer can use. MLX LM reads training data from a folder containing three files: train.jsonl, valid.jsonl, and an optional test.jsonl. Each line holds one JSON example. The training file is required, the validation file lets the trainer report validation loss as it runs, and the test file scores the model after training finishes.
Three formats are supported: chat, completions, and text. The chat format is the most robust default. It stores role-tagged messages per line and lets MLX LM apply the model's own chat template, so your data matches how the model was trained to handle conversations.
{"messages": [{"role": "user", "content": "What is LoRA?"}, {"role": "assistant", "content": "An efficient way to fine-tune a model."}]}For plain input and output pairs, the completions format is simpler and works well for instruction-style tasks.
{"prompt": "Summarize: The market rose sharply today.", "completion": "Markets gained."}
{"prompt": "Translate to French: good morning", "completion": "bonjour"}By default, the trainer computes loss over the entire example, meaning the model spends effort learning to reproduce the prompt as well as the answer. Passing --mask-prompt tells it to compute loss on the completion alone, so training focuses on the response you actually care about. This usually produces a model that follows instructions more reliably, and it works with the chat and completions formats. For chat data, the final message in the list is treated as the completion.
Keep each example on a single line with no internal line breaks, since the reader treats every line as a separate record. Split your data so that roughly 80 percent lands in train.jsonl and 10 to 20 percent in valid.jsonl. Around 200 to 500 examples is a sensible minimum for changing a model's behavior (far fewer tend to overfit and memorize rather than generalize).
# Training Your First LoRA Adapter
With your data in place, here's where things get interesting. Rather than updating every weight in the model, Low-Rank Adaptation (LoRA) freezes the original weights and trains small adapter matrices alongside them. This drops memory and storage needs to a fraction of full fine-tuning while keeping most of the quality. The method comes from the LoRA paper** by Hu and colleagues.
**
LoRA keeps the large pretrained weights frozen and trains only the small matrices A and B. Because just those two adapters receive updates, memory and storage stay low.
Launch a training run with one command, pointing it at a model and your data folder.
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--train \
--data ./data \
--iters 600 \
--batch-size 1As it runs, MLX LM prints training loss, validation loss, tokens processed, and iterations per second. Adapter weights save to an adapters folder by default. Key flags worth knowing: --fine-tune-type accepts lora (the default), dora, or full; --num-layers sets how many transformer layers receive adapters (default: 16); and --iters controls training length.
The example sets --batch-size 1 on purpose to keep memory use as low as possible. This prevents crashes on 16 GB machines. If you have 64 GB or more, raising it to 2 or 4 shortens total training time. When memory is tight but you want the smoothing effect of a larger batch, --grad-accumulation-steps raises the effective batch size without raising memory use.
If you prefer live graphs over terminal output, add --report-to wandb to log metrics to Weights & Biases**. If you hit memory pressure, lower --num-layers to 8 or 4, or add --grad-checkpoint to trade computation for lower memory. These two flags are usually enough to fit a job that would otherwise run out of room.
# Choosing a Base Model and Adapter Settings
**
Building on the training mechanics above, two early decisions shape the rest of your run: which model to start from, and how much of it to adapt. For a first project, an 8B parameter model in 4-bit form is the sweet spot. Once the workflow feels comfortable, you can move up to 13B or 14B models, which need 14 to 18 GB of working memory and sit comfortably on a 32 GB machine.
The number of trained layers and the adapter rank together control capacity. More layers and a higher rank give the adapter more room to learn, at the cost of memory and time. A common starting point uses 16 layers with a moderate rank, then adjusts based on whether validation loss is still falling. If training loss drops while validation loss climbs, the adapter is memorizing your examples.
Learning rate matters too. Values in the range of 1e-5 to 5e-5 work for most LoRA runs. Too high and training becomes unstable; too low and the model barely moves. Change one setting at a time so you can attribute any improvement to a specific choice.
# Reducing Memory Use with Quantization
Notice that the base model above already ends in 4bit. Training a LoRA adapter on top of a quantized model is what people call QLoRA, described in the QLoRA paper**. Because quantization is built into MLX, the same mlx_lm.lora command trains adapters directly on quantized weights with no extra setup.
The payoff is concrete. A 4-bit 7B model cuts weight memory by roughly 3.5 times compared with full precision, bringing a 7B fine-tune comfortably into 8 GB of working memory. On a 16 GB MacBook, that leaves ample headroom for the operating system and your training batch.
If you prefer to quantize a full precision model yourself before training, the convert command handles it.
mlx_lm.convert \
--hf-path mistralai/Mistral-7B-Instruct-v0.3 \
--mlx-path ./mistral-4bit \
-qThis writes a 4-bit version to a local folder that you then pass to --model.
# Testing and Generating with Your Adapter
**
With training complete, it's time to see how well the adapter learned. Score it against your held-out test set to get a number you can track across experiments.
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--data ./data \
--testTo see the model respond, pass the same adapter path to the generate command. MLX LM loads the base model and applies your adapter on top of it.
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--prompt "Summarize: Our quarterly revenue grew twelve percent."Run the same prompt without the adapter to compare. If your dataset matched the target task well, the adapted responses should track your training examples more closely than the base model does.
# Fusing and Serving the Model
Adapters are convenient during experimentation, but for deployment you often want a single, self-contained model. The fuse command merges the adapter back into the base weights.
mlx_lm.fuse \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--save-path ./fused-modelThe fused folder behaves like any other MLX model. You can serve it through an OpenAI-compatible endpoint, which lets existing client code talk to your local model after only a base URL change.
mlx_lm.server --model ./fused-model --port 8080For a graphical alternative, LM Studio** runs MLX models with a one-click local server and a chat interface, particularly useful when you want to compare your fine-tuned model against others side by side.
# Wrapping Up
**
You now have a complete local fine-tuning workflow: install MLX LM, format a dataset as JSONL, train a LoRA or QLoRA adapter with a single command, test it, then fuse and serve the result. Everything runs on the Mac you already own, with no cloud bill and no data leaving your machine.
For me, this feels like a natural extension of the journey that began when I switched to Mac in 2014. The tight hardware-software integration that first drew me in has quietly evolved into something far more powerful, a machine capable of serious machine learning work at the kitchen table.
A few directions are worth exploring next. Try the dora fine-tune type and compare its results against plain LoRA. Adjust the number of trained layers and iteration count to balance quality against speed. Swap in a different base architecture. Llama, Qwen, Phi, and Gemma all work through the same commands. Each experiment is inexpensive when the hardware is sitting on your desk, which is the practical change MLX brings to adapting language models.
Vinod Chugani** is an AI and data science educator who bridges the gap between emerging AI technologies and practical application for working professionals. His focus areas include agentic AI, machine learning applications, and automation workflows. Through his work as a technical mentor and instructor, Vinod has supported data professionals through skill development and career transitions. He brings analytical expertise from quantitative finance to his hands-on teaching approach. His content emphasizes actionable strategies and frameworks that professionals can apply immediately.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み