スクラッチから始めるFeature Stores:最小限の実装例
KDnuggets は、Feature Store の概念をゼロから構築する最小限の実装コードと設計パターンを提供し、データエンジニアリングの現場における実践的な課題解決を支援している。
キーポイント
実装の核心ロジック
特徴量データの保存、バージョン管理、およびトレーニングセットとの整合性を保つための最小限なデータ構造とコード例を示している。
スケーラビリティへの配慮
小規模プロジェクトから大規模システムへ移行する際に必要な拡張性や、データの一貫性を維持するための設計原則を解説している。
運用コストの削減
既存の複雑な商用ツールに依存せず、自前で軽量な Feature Store を構築することで開発効率とコスト管理を最適化する方法を提案している。
影響分析・編集コメントを表示
影響分析
この記事は、Feature Store という概念を抽象的なツールとしてではなく、具体的なコードレベルで理解・構築可能であることを示しており、データエンジニアや ML エンジニアにとって実装のハードルを下げる重要なリソースとなります。特に、ベンダーロックインを避けつつも標準的な機能を実装したいチームにとって、設計の指針となる価値があります。
編集コメント
商用ツールの利用が一般的になる中、基盤の仕組みを自ら理解・構築する姿勢は、システム設計の柔軟性を高める上で極めて重要です。
 image**
image**
# イントロダクション
多くのチームは、苦労して特徴量ストア(feature store)の必要性に気づきます。ノートブック上では正常に動作していた不正検出モデルが、本番環境で静かに失敗します。サポート担当者がユーザーの情報を全く把握していないため、一般的な回答しか返せません。レコメンダーパイプラインでは、「過去 30 日間の支出額」という計算を 3 つのジョブで重複して行っており、そのうち 2 つの結果が食い違っています。
特徴量ストアは、これらの問題を解決するインフラストラクチャ(infrastructure)です。特徴量を一度定義し、トレーニング用と推論用の 2 つの形式(shape)で保存し、両者を同期させます。私たちは、Python を基盤とし、DuckDB、Parquet、Redis、そして FastAPI を用いて、最小限の特徴量ストアをゼロから構築します。その後、AI アプリケーションが実際にどのように利用されるかを変化させるのかについて考察します。
全コードは非常に短いため、すべてのコンポーネントを順を追って解説していきます。
**
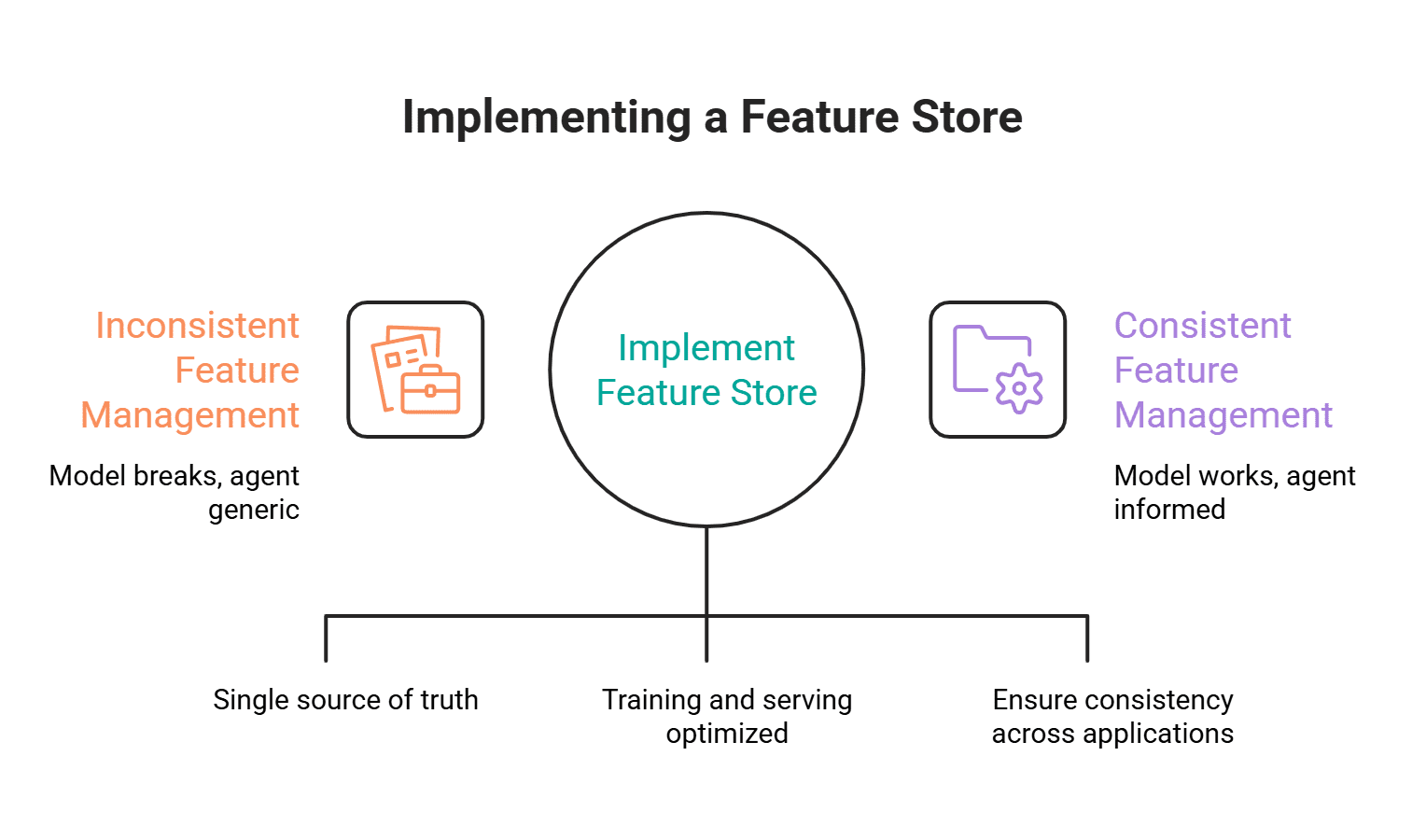
# 特徴量ストアが実際に解決する課題
従来の売り文句は、トレーニングと推論の乖離(training-serving skew)です。トレーニングセットを構築するために使った SQL と、推論時に実行されるコードパスが一致していないため、値にズレが生じます。この問題は確かに存在し、オフラインとオンラインの分割が標準的な解決策となっています。
現代の提案はより広範です。大規模言語モデル(LLM)エージェントや検索拡張生成(RAG)パイプラインでは、推論時に、すべてのリクエストにおいて 10 ミリ秒未満で構造化されたユーザーコンテキストが必要です。LLM にはユーザーが誰であるかの記憶がありません。パーソナライズされた出力を得たい場合、プロンプトにユーザーのプラン階層、最近のアクティビティ、アカウント状態を注入する必要があり、これらの値を高速かつ一貫して返すシステムが必要です。まさにそれが、特徴ストアのオンラインストアと検索 API が提供するものです。
したがって、私たちは両方のケースに対応するために構築します。同じ 5 つのコンポーネントが、予測的機械学習ユースケースと LLM コンテキストユースケースの両方を処理します。
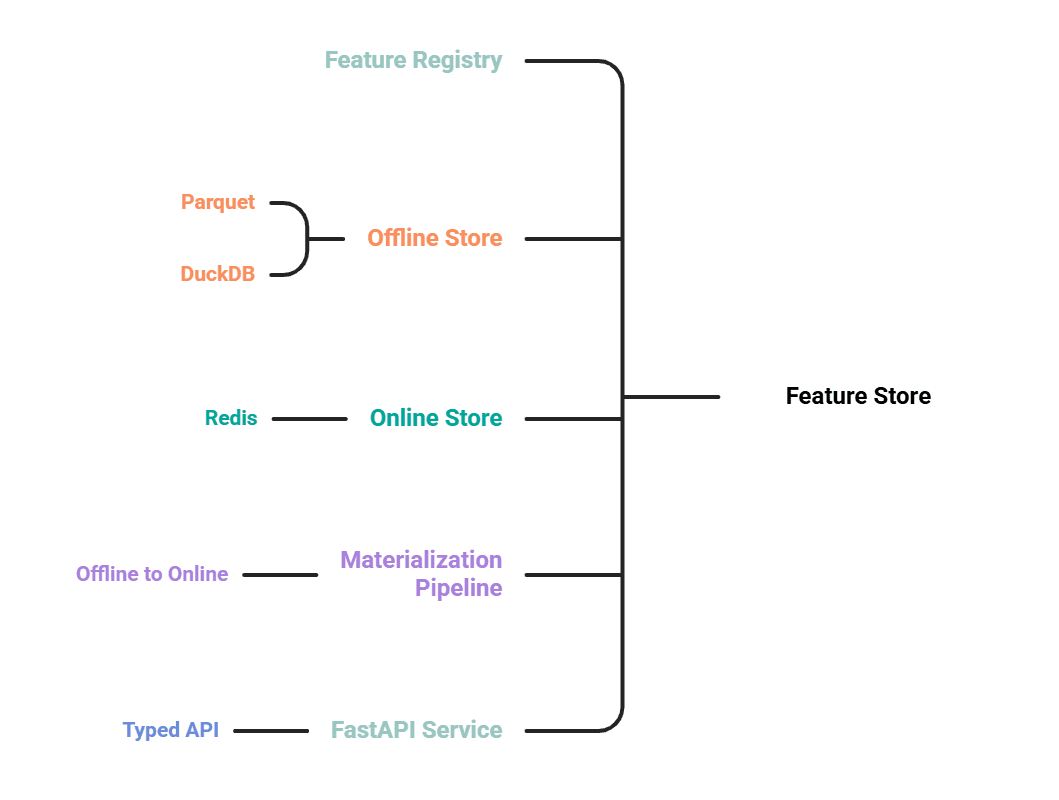
# 5 つのコンポーネント
- 特徴をコードとして定義する特徴レジストリ。
- 学習およびバックフィルに使用される Parquet 形式のオフラインストア(DuckDB でクエリ)。
- 推論時の低遅延ルックアップ用の Redis 上のオンラインストア。
- オフラインから最新の値をオンラインへプッシュするマテリアライゼーションパイプライン。
- タイプ付き検索 API を公開する FastAPI サービス。
# 実行例:パーソナライズされた LLM レコメンダー
私たちはストリーミングサービスを提供しています。ユーザーがアプリを開くと、LLM が短くパーソナライズされた「次に見るべきもの」メッセージを生成します。この LLM はユーザーについて以下の 3 つの情報を必要とします:
特徴
型
鮮度
user_segment
string
daily
watch_count_30d
int
hourly
last_genre
string
per-event
エンティティは user_id です。これら3つの機能を登録し、マテリアライズして、リクエスト時に LLM に提供します。
// 1. Feature Registry の定義
レジストリとは、機能のエンティティ、データ型(dtype)、およびソースを一度だけ宣言する場所です。ここでは dataclass を使用します。
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Feature:
name: str
entity: str
dtype: Literal["int", "float", "str"]
source: str # Parquet ファイルへのパスまたは SQL ビュー
REGISTRY: dict[str, Feature] = {
"user_segment": Feature("user_segment", "user_id", "str", "data/user_segment.parquet"),
"watch_count_30d": Feature("watch_count_30d", "user_id", "int", "data/watch_count_30d.parquet"),
"last_genre": Feature("last_genre", "user_id", "str", "data/last_genre.parquet"),
}
完全なコードは こちら で確認できます。
これを実行すると、出力には以下が表示されます:
Registered features:
user_segment entity=user_id dtype=str source=data/user_segment.parquet
watch_count_30d entity=user_id dtype=int source=data/watch_count_30d.parquet
last_genre entity=user_id dtype=str source=data/last_genre.parquet
これが契約です。他のすべてのコンポーネントは REGISTRY から読み取るため、特徴量の名称変更、データ型の変更、または新しいソースへの指し示しは、単一の場所で行われます。本番環境のシステムでは、これは YAML** または Git リポジトリにチェックインされた Python モジュールとなり、すべての変更に対してコードレビューが行われます。
// 2. DuckDB と Parquet を用いたオフラインストアの構築
オフラインストアは、各特徴量の値の完全な履歴を保持します。ストレージ層として Parquet ファイルを使用し、クエリエンジンとして DuckDB を使用します。DuckDB は Parquet を直接読み取るため、別途データベースを実行する必要はありません。
以下にコードのサンプルを示します:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame, features: list[str]
) -> pd.DataFrame:
con = duckdb.connect()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
con.execute(f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'")
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()
完全なコードは こちら で確認できます。
これを実行すると、出力には以下が表示されます:
user_id
event_timestamp
user_segment
watch_count_30d
last_genre
8a2f
2026-05-05 12:00:00
casual
22
NaN
b13c
2026-05-07 20:00:00
casual
5
thriller
8a2f
2026-05-07 22:00:00
power_user
47
documentary
AsOf join は、時点結合(point-in-time join)です。各エンティティ行に対して、特徴量のタイムスタンプがイベントのタイムスタンプより以前または同じであるような、最も新しい特徴量値を選択します。これにより、予測対象となる瞬間にはまだ存在していなかった特徴量値を用いてトレーニング行が構築されてしまうというデータリーク(leakage)を防ぐことができます。
時点結合は、今後トレーニングまたはファインチューニングを行う予定のあらゆるモデルにとって依然として適切な解決策です。純粋な推論時の LLM 利用ケースにおいては、この関数を呼び出す機会が全くないかもしれません。それでもオフラインストアが必要なのは、バックフィル(backfills)、評価用データセット、監査情報が得られる場所だからです。
// 3. Redis 上のオンラインストアの設定
オンラインストアは、各エンティティについて最新の値のみを保持します。Redis が標準的な選択肢となるのは、ハッシュ検索がサブミリ秒で完了するためです。
import json
import fakeredis # 本番環境では redis.Redis() を使用して実際のサーバーに接続する
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={k: json.dumps(v) for k, v in values.items()},
)
def read_online(entity: str, entity_id: str, features: list[str]) -> dict:
raw = r.hmget(f"{entity}:{entity_id}", features)
return {f: json.loads(v) if v else None for f, v in zip(features, raw)}完全なコードは こちら で確認できます。
これを実行すると、出力には以下が表示されます:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
missing key -> {'user_segment': None}
キーの形式は entity:entity_id です。値は各特徴(feature)に1 つずつフィールドを持つハッシュです。単一の HMGET コマンドで、要求したすべての特徴を 1 ラウンドトリップで取得できます。3 つの特徴を持つローカルの Redis インスタンスでは、この処理は 1 ミリ秒もかからずに完了します。
// 4. マテリアライゼーションパイプラインの実行
マテリアライゼーション(materialization)とは、オフラインの値をオンラインへ移動するプロセスです。実際のシステムではこれはスケジュール(Airflow、cron、ストリーミングジョブなど)に基づいて実行されますが、ここでは関数として実装されています。
def materialize(features: list[str]) -> None:
by_entity: dict[str, dict] = {}
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row[f.entity], {})[fname] = row[fname]
for entity_id, values in by_entity.items():
write_online("user_id", entity_id, values)
完全なコードは こちら で確認できます。
これを実行すると、出力には以下が表示されます:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'casual', 'watch_count_30d': 5, 'last_genre': 'thriller'}
QUALIFY クラース(句)は、各エンティティごとに最新行を保持します。同じユーザーのすべてのフィーチャーを 1 つの Redis 書き込みへグループ化することで、往復通信回数を削減します。この処理は各フィーチャーが必要とする頻度で実行してください:watch_count_30d は時間ごと、last_genre はニアリアルタイム、user_segment は毎日です。実際の運用では、その頻度をエンコードする適切な場所はレジストリ(登録簿)となります。
// 5. FastAPI 取得サービスの公開
翻訳全文
POST /get-online-features -> 200
body: {'user_id': '8a2f', 'features': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
LLM が受け取るプロンプト:
システム:ストリーミングサービス向けの番組を推薦してください。
ユーザーコンテキスト:セグメントはパワーユーザー、過去 30 日間で 47 タイトル視聴済み、直近の視聴ジャンルはドキュメンタリー。
タスク:親しみやすい短いメッセージで 3 つのタイトルを提案してください。
このフィーチャーストア(特徴ストア)こそが、「ユーザー 8a2f」という情報を、LLM が利用可能な構造化されたコンテキストへと変換する役割を果たします。
# フィーチャーストアの終焉とベクトルデータベースの始まり
**
ベクトルデータベース(Pinecone、Weaviate、pgvector**)は、推論時にモデルの手前に位置するという点でフィーチャーストアと共通していますが、ベクトルデータベース自体がフィーチャーストアであるわけではありません。両者は異なる検索問題を解決するものです。
**
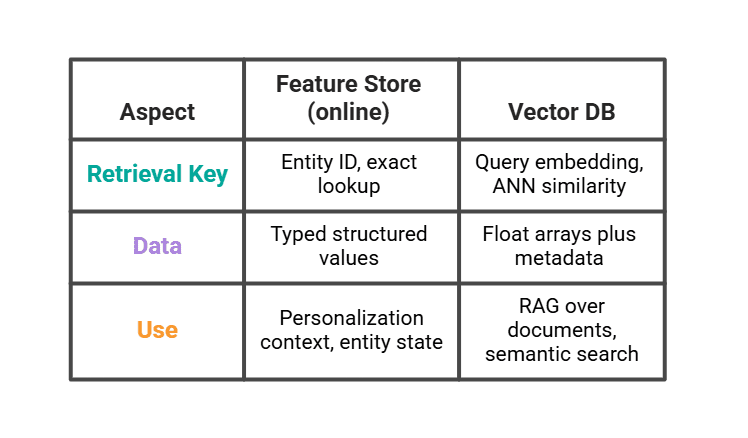
実際の LLM スタックでは、これら 2 つを併用します。ベクトルデータベースは過去に視聴されたセッションの中で最も類似した 3 つを返します。一方、フィーチャーストアはユーザーのセグメントと直近のカウント情報を返します。プロンプトはこの両者を組み合わせて構成されます。
# よくあるアンチパターン
頻繁に見られる失敗のパターンがいくつかあります:
- モデルサービス内で特徴量を計算する。同じロジックがトレーニングノートブックと API の両方に実装される結果、2 つの定義は四半期ごとに乖離してしまう。
- オンラインストアを真の信頼源(ソース・オブ・トゥルース)として扱うこと。Redis は再起動時にデータ損失を起こす可能性がある。オフラインストアが正統な情報源であり、オンラインストアは単なるキャッシュに過ぎない。
- レジストリをスキップする。3 つのチームがそれぞれ独立して active_user を定義するため、ダッシュボードとモデルの出力が一致しなくなる。
- ベクトルデータベースを特徴量ストアと呼ぶこと。これはエンティティキーに基づく構造化された照合を行うことができないため、両方の機能が必要なプロンプトは結局 2 つのシステムに接続されることになる。
- 時点別結合(point-in-time joins)なしでバックフィルを実行すること。トレーニングセットは完璧に見えるが、本番環境のモデルは壊れているように見え、そのギャップこそがデータリーケージである。
Feast, Tecton, Databricks と比較する
私たちの約 200 行のコードは、同じ機能をミニマムな規模で実現している。
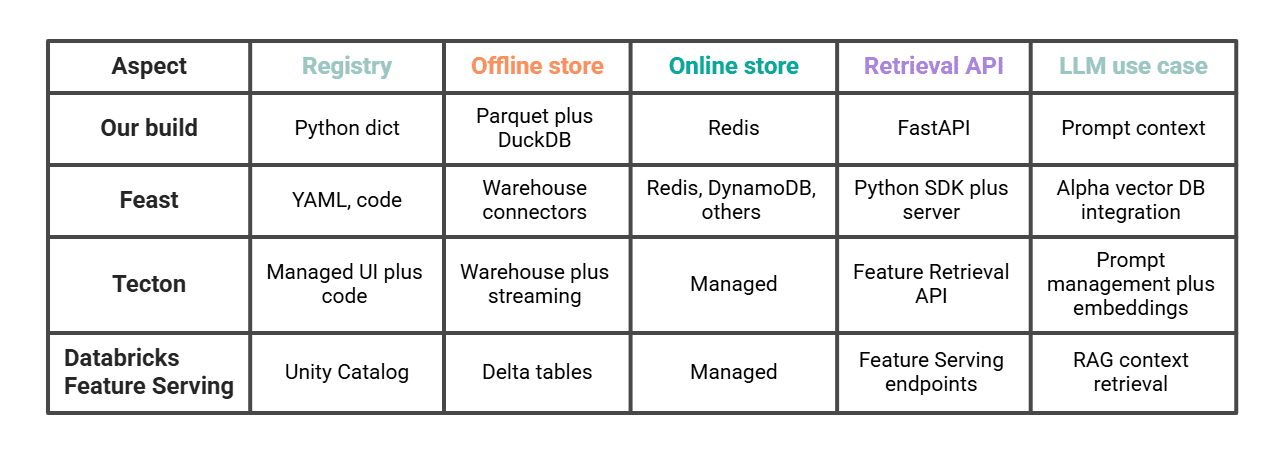
Feast は、同じパターンを踏襲してさらに拡張する場合、特にセルフホスト環境において最も近い比較対象となる。Tecton と Databricks** はマネージド型のパスであり、LLM 向けの特徴量機能(Tecton の LLM 用特徴量検索 API、Databricks の複合生成 AI システム向けの Feature Serving)を明示的に備えている。これらの中から選択するのは、主に自前で運用する範囲をどこまでにするか、そして残りのスタックがすでに Databricks に依存しているかどうかという問題である。
結論
**
動作するフィーチャーストアは、レジストリ、オフラインストア、オンラインストア、マテリアライゼーションステップ、および取得 API の 5 つのコンポーネントで構成されます。これを一度構築することで、なぜ生産環境のシステムが現在の姿をしているのかを理解できます。また、AI における設計変更のポイントも示してくれます:LLM がアクセスする表面はオンライン取得パスであり、トレーニングや評価を行う際にはポイントインタイム結合が重要となり、ベクトルデータベースはフィーチャーストア内部ではなくその隣に位置します。
これらの部品が揃えば、最小限のバージョンを Feast、Tecton、または Databricks に置き換えることは、主にレジストリの移行に過ぎません。システムの形状は同じままです。
Nate Rosidi** はデータサイエンティストであり、製品戦略に関わる人物です。また、分析を教える非常勤教授でもあり、トップ企業からの実際の面接質問を用いてデータサイエンティストの面接準備を支援するプラットフォーム「StrataScratch」の創設者でもあります。Nate はキャリア市場における最新動向について執筆し、面接に関するアドバイスを提供し、データサイエンスプロジェクトを紹介し、SQL 関連のあらゆるトピックを取り上げています。
原文を表示
**
# Introduction
Most teams discover they need a feature store** the hard way. A fraud model works in the notebook and quietly breaks in production. A support agent gives a generic answer because it has no idea who the user is. A recommender pipeline duplicates the same "30-day spend" calculation across three jobs, and two of them disagree.
A feature store is the piece of infrastructure that fixes those problems. It defines features once, stores them in two shapes (one for training, one for serving), and keeps both in sync. We are going to build a minimal one from scratch in Python, using DuckDB, Parquet, Redis, and FastAPI. Then we will look at how AI applications change what we actually use it for.
The full code is short enough that we will walk through every component.
**
# What a Feature Store Actually Solves
The classic pitch is training-serving skew: the SQL that built your training set is not the same code path that runs at inference, so the values drift. That problem is real, and the offline plus online split is the standard fix.
The modern pitch is broader. Large language model (LLM) agents and retrieval-augmented generation (RAG) pipelines need structured user context at inference time, on every request, in under 10ms. An LLM has no memory of who the user is. If we want personalized output, we have to inject the user's plan tier, recent activity, and account state into the prompt, and we need a system that can return those values fast and consistently. That is exactly what a feature store's online store and retrieval API give us.
So we build for both. The same five components handle the predictive machine learning use case and the LLM context use case.
# The Five Components
- A feature registry that defines features as code.
- An offline store on Parquet, queried with DuckDB, for training and backfills.
- An online store on Redis for low-latency lookups at inference.
- A materialization pipeline that pushes the latest values from offline to online.
- A FastAPI service that exposes a typed retrieval API.
# Running Example: A Personalized LLM Recommender
We are running a streaming service. When a user opens the app, an LLM generates a short, personalized "what to watch next" message. The LLM needs three things about the user:
Feature
Type
Freshness
user_segment
string
daily
watch_count_30d
int
hourly
last_genre
string
per-event
The entity is user_id. We will register these three features, materialize them, and serve them to the LLM at request time.
// 1. Defining the Feature Registry
A registry is just a place where features are declared once, with their entity, dtype, and source. We use a dataclass.
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Feature:
name: str
entity: str
dtype: Literal["int", "float", "str"]
source: str # path to a Parquet file or a SQL view
REGISTRY: dict[str, Feature] = {
"user_segment": Feature("user_segment", "user_id", "str", "data/user_segment.parquet"),
"watch_count_30d": Feature("watch_count_30d", "user_id", "int", "data/watch_count_30d.parquet"),
"last_genre": Feature("last_genre", "user_id", "str", "data/last_genre.parquet"),
}The full code can be found here.
When you run it, the output shows:
Registered features:
user_segment entity=user_id dtype=str source=data/user_segment.parquet
watch_count_30d entity=user_id dtype=int source=data/watch_count_30d.parquet
last_genre entity=user_id dtype=str source=data/last_genre.parquetThis is the contract. Every other component reads from REGISTRY, so renaming a feature, changing its dtype, or pointing it at a new source happens in one place. In production systems, this would be YAML** or a Python module checked into a Git repo, with code review on every change.
// 2. Building the Offline Store with DuckDB and Parquet
The offline store holds the full history of every feature value. We use Parquet files as the storage layer and DuckDB as the query engine. DuckDB reads Parquet directly, which means no separate database to run.
Here is a sample of the code:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame, features: list[str]
) -> pd.DataFrame:
con = duckdb.connect()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
con.execute(f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'")
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()The full code can be found here.
When you run it, the output shows:
user_id
event_timestamp
user_segment
watch_count_30d
last_genre
8a2f
2026-05-05 12:00:00
casual
22
NaN
b13c
2026-05-07 20:00:00
casual
5
thriller
8a2f
2026-05-07 22:00:00
power_user
47
documentary
The AsOf join is the point-in-time join. For every entity row, it picks the most recent feature value where the feature's timestamp is at or before the event timestamp. That is what prevents leakage — where a training row is built with a feature value that did not exist yet at the moment we are predicting for.
Point-in-time joins are still the right answer for any model we plan to train or fine-tune. For a pure inference-time LLM use case, we may never call this function. We still want the offline store, since it is where backfills, evaluation datasets, and audits come from.
// 3. Setting Up the Online Store on Redis
The online store keeps only the latest value per entity. Redis is the standard choice because hash lookups are sub-millisecond.
import json
import fakeredis # use redis.Redis() against a real server in production
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={k: json.dumps(v) for k, v in values.items()},
)
def read_online(entity: str, entity_id: str, features: list[str]) -> dict:
raw = r.hmget(f"{entity}:{entity_id}", features)
return {f: json.loads(v) if v else None for f, v in zip(features, raw)}The full code can be found here.
When you run it, the output shows:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
missing key -> {'user_segment': None}The key shape is entity:entity_id. The value is a hash with one field per feature. A single HMGET returns all the features we asked for in one round trip. On a local Redis instance with three features, this finishes in well under 1ms.
// 4. Running the Materialization Pipeline
Materialization moves values from offline to online. In a real system this runs on a schedule (Airflow, cron, a streaming job). Here it is a function.
def materialize(features: list[str]) -> None:
by_entity: dict[str, dict] = {}
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row[f.entity], {})[fname] = row[fname]
for entity_id, values in by_entity.items():
write_online("user_id", entity_id, values)The full code can be found here.
When you run it, the output shows:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'casual', 'watch_count_30d': 5, 'last_genre': 'thriller'}The QUALIFY clause keeps the latest row per entity. We group all features for the same user into one Redis write to cut round trips. Run this on the cadence each feature needs: hourly for watch_count_30d, near-real-time for last_genre, daily for user_segment. The registry is the right place to encode that cadence in a real implementation.
// 5. Exposing the FastAPI Retrieval Service
The retrieval service is the production surface. It is what the LLM application calls.
f = resp.json()["features"]
print("\nPrompt the LLM would receive:")
print(
f" System: You recommend shows for a streaming service.\n"
f" User context: segment={f['user_segment']}, "
f"watched {f['watch_count_30d']} titles in last 30 days, "
f"last genre watched: {f['last_genre']}.\n"
f" Task: suggest 3 titles in a friendly, short message."
)The full code can be found here.
When you run it, the output shows:
POST /get-online-features -> 200
body: {'user_id': '8a2f', 'features': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
Prompt the LLM would receive:
System: You recommend shows for a streaming service.
User context: segment=power_user, watched 47 titles in last 30 days, last genre watched: documentary.
Task: suggest 3 titles in a friendly, short message.The feature store is the piece that turns "user 8a2f" into a structured context the LLM can use.
# Where the Feature Store Ends and the Vector Database Begins
**
A vector database (Pinecone, Weaviate, pgvector**) is not a feature store, even though both sit in front of a model at inference. They solve different retrieval problems.
**
A real LLM stack uses both. The vector database returns the three most similar past viewing sessions. The feature store returns the user's segment and recent counts. The prompt combines them.
# Common Anti-Patterns
A few patterns that we keep seeing fail:
- Computing features inside the model service. The same logic ends up in the training notebook and the API, and the two definitions drift within a quarter.
- Treating the online store as the source of truth. Redis loses data on a bad restart. The offline store is canonical; the online store is a cache.
- Skipping the registry. Three teams independently define active_user and the dashboards stop matching the model.
- Calling a vector database a feature store. It cannot do entity-keyed structured lookups, and a prompt that needs both will end up wired to two systems anyway.
- Backfilling without point-in-time joins. The training set looks great, the production model looks broken, and the gap is the leakage.
# Comparing This to Feast, Tecton, and Databricks
Our ~200 lines do the same job in miniature.
Feast is the closest comparison if we want to go further on the same pattern, self-hosted. Tecton and Databricks** are the managed paths and have explicit LLM features (Tecton's Feature Retrieval API for LLMs, Databricks Feature Serving for compound generative AI systems). Picking between them is mostly a question of how much we want to operate ourselves and whether the rest of our stack already lives in Databricks.
# Conclusion
**
A working feature store fits in five components: a registry, an offline store, an online store, a materialization step, and a retrieval API. Building it once teaches us why the production systems look the way they do. It also shows where the design changes for AI: the online retrieval path is the surface the LLM hits, point-in-time joins matter when we train or evaluate, and the vector database sits next to the feature store, not inside it.
Once we have these pieces, swapping our minimal version for Feast, Tecton, or Databricks is mostly a migration of the registry. The shape of the system stays the same.
Nate Rosidi** is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.
関連記事
Amazon SageMaker Feature Store の新機能で ML 特徴パイプラインを加速
AWS は、機械学習モデルの特徴値を保存・共有・管理する完全マネージドリポジトリ「Amazon SageMaker Feature Store」に、Apache Iceberg テーブル形式のサポートを追加し、開発速度の向上を図りました。
データサイエンティストが知っておくべき実用的な SQL の技
KDnuggets は、データサイエンティストが効率的にデータを処理するために役立つ実践的な SQL のテクニックを紹介している。
高度な結合技術:LATERAL 結合、セミ結合、アンチ結合
KDnuggets は、サブクエリが FROM クラースの先行列を参照できる LATERAL 結合や、一致する行のみを返すセミ結合、一致しない行を返すアンチ結合といった SQL の高度な結合技術について解説した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み