なぜ私は「感覚に頼ったプログラミング」をしないのか
宝玉は、感情や直感だけでコードを書くことのリスクを指摘し、論理的な根拠に基づいた開発の重要性について語っている。
なぜ私は「感覚プログラミング」をしないのか
著者:ジェイコブ・ハリス
最近、インターネット上では「感覚プログラミング(Vibe Coding)」や大規模言語モデル(LLM)がソフトウェア開発をどのように覆すかという議論で溢れています。新モデルのリリースごとに、私たちは純粋な生産性の天国へと導かれ、光速でソフトウェアをリリースし、製品開発におけるすべての摩擦と内耗を完全に排除できると言われています。
もしかしたらそうかもしれません。私は一応信じておきますが、私自身は「感覚プログラミング」はしません。
もしこの方法があなたにとって効果的だと感じているなら素晴らしいことです!私がこの記事を書いたのは LLM の優劣について議論するためではありません。ただ、このツールは私個人には合いませんでした。この記事では、その理由を簡単に整理してみます。
私はケチです
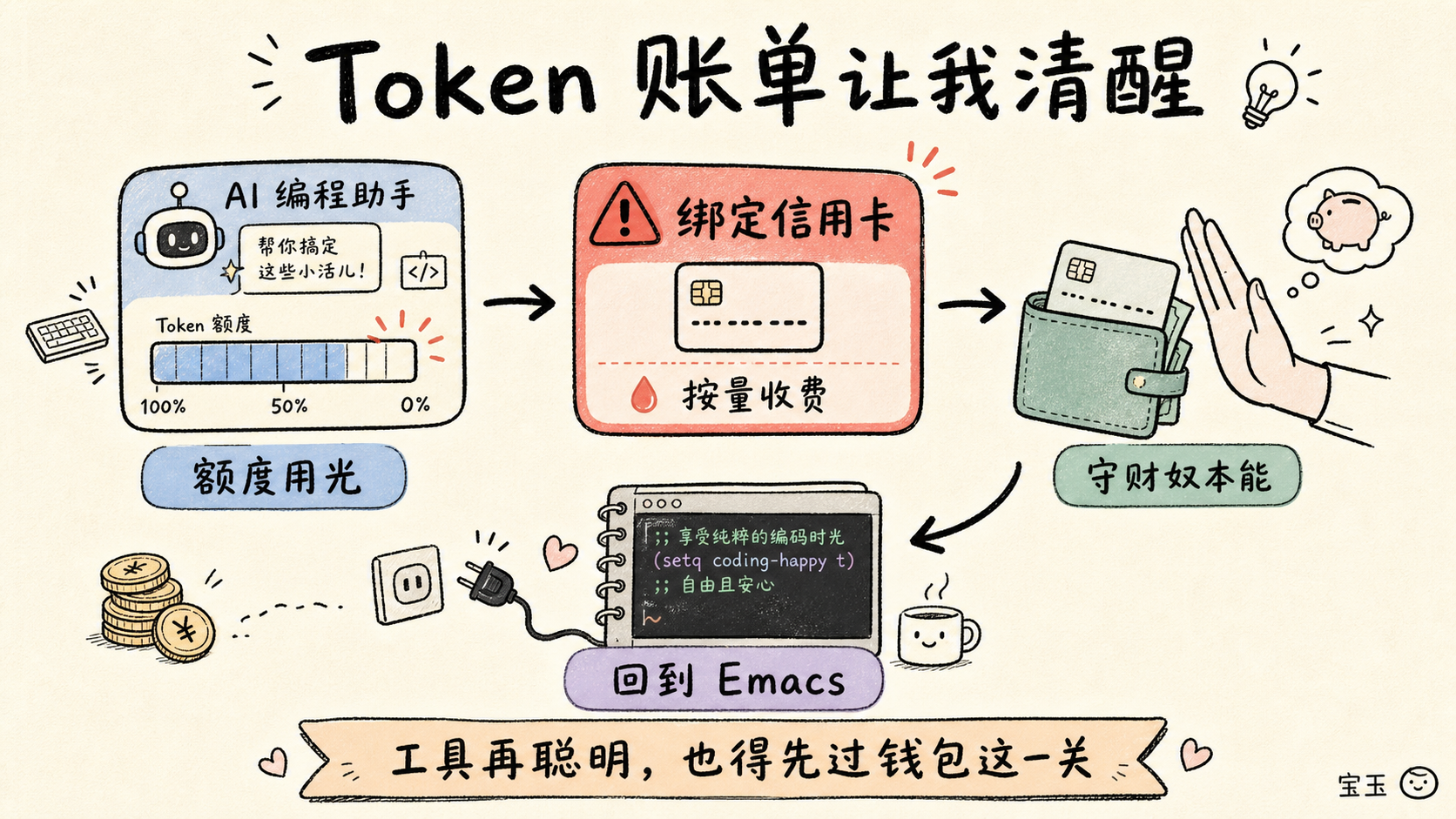
私は原理主義者ではありません。IDE に統合された LLM を試したこともあります。説明が簡単で、自分でやるのは面倒なタスクについては、確かに便利です。例えば、グリッド内の多数の正方形画像を縮小するといった作業です。本来なら画像処理ソフトウェア ImageMagick のコマンドライン引数を確認しに行くべきところですが、そのようなことは AI に任せるのが最適でしょう。次に、ある AI ツールを使ってプロジェクト内のコードを分析したり、いくつかの小さな作業を行ったりしましたが、そこですべてが突然終わりました。システムから通知が届き、「利用枠が尽きました」と告げられました。続行するにはクレジットカードを登録してトークンを購入する必要があると。
知っておいてほしいのですが、私の家系は両方の側で有名なケチです。数世紀にわたり、大西洋のこちら側でも向こう側でも、私たちの家族は常に倹約し、細かく計算してきました。極端な例を挙げれば、17 世紀のフィリップ王戦争(King Philip's War)で亡くなった私の遠い親戚がいます。その死因は、家から退避する際にチーズを一つ落としてしまい、安全な砦の外へ取りに戻ったという理由でした。
だから、私が「思考」するために、あるサービスに無期限にお金を払い続ける必要があると知ったとき、私は全身が不快になり、クレジットカードの影すら見せたくないほどでした。私はラップトップを閉じ、その IDE をアンインストールし、さらに従順にも非常にハードコアな純テキストエディタである Emacs に戻りました。そして気づきました。AI がなくても、全く不便だと感じないということです。
私は年を取ったのです
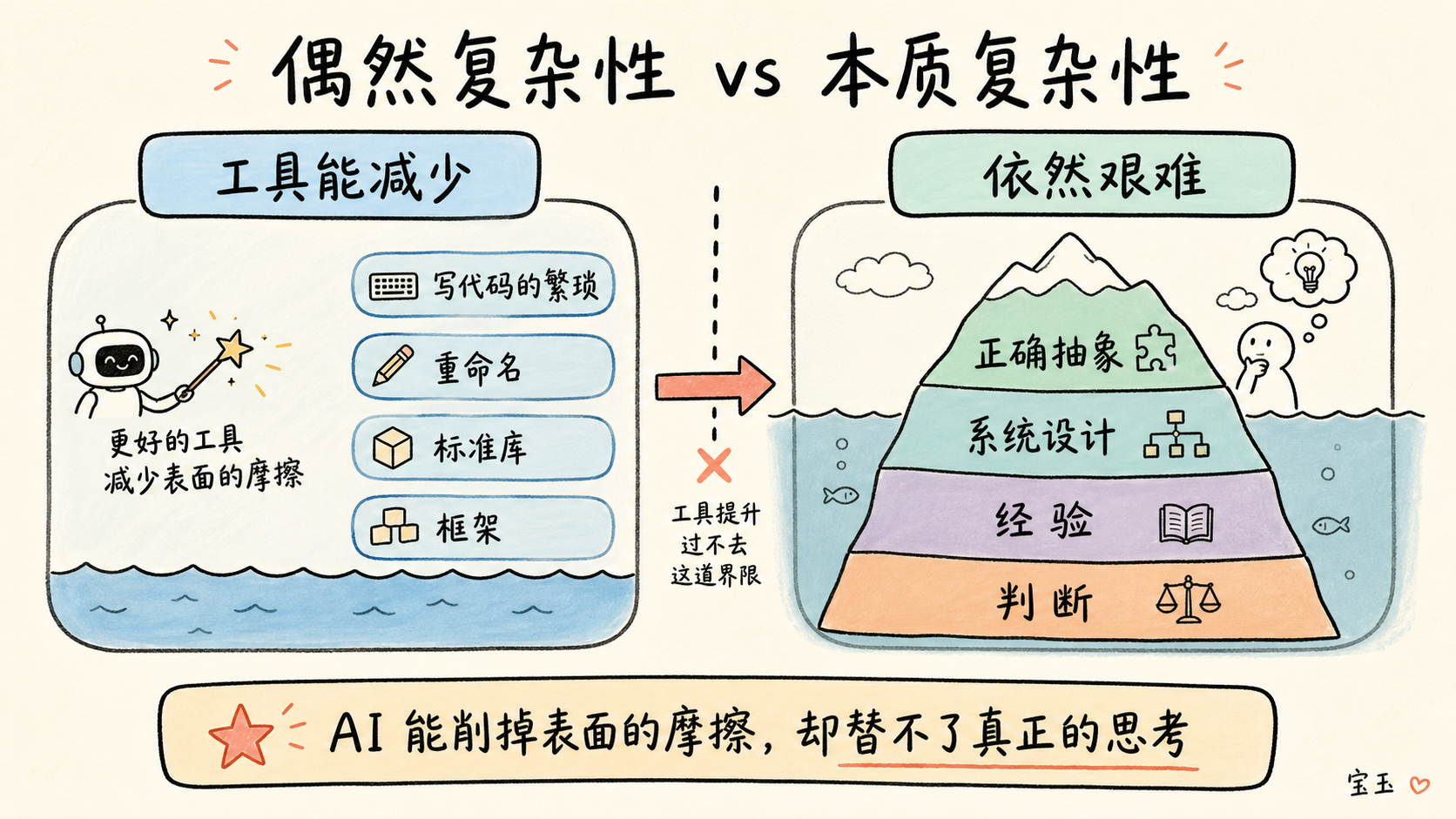
年を取っていることは、確かに少し役に立ちます。私は何年もコードを書いており、特に 5 年の経験を持つ開発者を「シニアエンジニア」と呼ぶこの業界ではなおさらです。時には、経験は不安を和らげる薬になります(ただし、あなたがその「5 年でシニアになれる」業界における年齢差別について不安を抱いている場合を除きます)。今回の AI ブームは、かつての「ローコード」や「ノーコード」ツールが謳っていた画期的な進歩を思い出させます。AI が開発者の強力な武器になり得ることは疑いませんし、多くのタスクにおいてより良いツールサポートを提供できることも知っています。しかし、これらの議論はいつも、「偶発的複雑性(accidental complexity)」と「本質的複雑性(essential complexity)」という古典的な理論を思い出させます。
私がまだ若手のプログラマーだった頃、フレッド・ブルックス(Fred Brooks)はすでにベテランの先輩でした。IBM System 360 シリーズ大型機(およびそのオペレーティングシステム)プロジェクトのマネージャーとして、彼は現在ソフトウェアプロジェクトで日常的に見られるような厄介な事態を第一線で目撃しました。これらの観察をまとめたのが『人月神話』という本であり、今なおソフトウェア工学の授業で読むべき古典の一つです。私が持っているのは後年の再版で、そこには彼が後に執筆した有名な論文「銀弾はない」も収録されています。この論文の中でブルックスは、新しいツールが開発者の生産性に実際にどのような影響を与えるかを考察しています。プログラマーのように考えるためには、現実世界がいかに複雑であるかを知る必要があります。プログラミングとは、混乱した現実の上に簡略化されたモデルを強制的に適用する行為と理解するのが最も適切です。私たちはこれを「抽象(abstractions)」と呼び、複雑さを低減させることで世界を理解可能にします。
これにより、特定の状況を層状に積み重ねられる構造へと一般化することができます。例えば、「パンにピーナツバターを塗る」という具体的な動作は、spread(substance)(物質を塗布する)というメソッドとして一般化され、このメソッドには「ピーナツバター」も「クリームチーズ」も引数として受け取ることができます。そして、これらの基礎的なメソッドを用いて、create_pbj()(ピーナツバターのサンドイッチを作る)といったより高度な関数を構築できます。現代の高級プログラミング言語でコードを書くことは、抽象概念によって積み上げられたピラミッドの頂上に立つようなものです。一行のコードだけで、複数のシステム上で数百万もの下層オペレーションをトリガーすることができます。
では、「プログラミング」という行為自体も抽象化してしまったらどうなるでしょうか?これが AI エージェントの究極的な夢です:一群のエージェントがタスクを受け取り、監督なしで自動的にそれを実現する。素晴らしいことに思えます!しかし、これによって解決されるのはブルックスが言うところの「偶発的複雑性」、つまりコードを記述すること自体に伴う煩雑さや重厚な部分だけです。この論文が発表されて以来、ソフトウェア開発は偶発的複雑性への対処において劇的な進歩を遂げてきました。私たちはもはや下層の機械語を書く必要はなく、現代の動的解釈型言語を使用しています。私が再びゼロからクイックソートの書き方を覚える必要もなく、標準ライブラリのソートメソッドを呼び出すだけで済みます。また、Web アプリケーション全体を一から構築する必要もなくなり、既存のフレームワークを直接使用できます。コードの一部の名前変更やリファクタリングを行いたい場合、エディターが代わりにやってくれます。
AI はこのプロセスにおける最新のエディションのように思えます。一部のエディターでは、予測不可能な AI エージェントが、かつての予測可能な古風な名前変更やリファクタリングツールに取って代わっています。確かに、これはサイコロを振って運試しをするように聞こえるかもしれませんが、実際の開発現場において、そのような壊滅的な大失敗がどれほど頻繁に起こるでしょうか?
しかし、より良いツールによって偶発的複雑性が弱められたとしても、「本質的複雑性」は依然として存在します。正しく、優雅で、明確かつ保守しやすい抽象アーキテクチャやシステムを設計することは、依然として極めて困難な作業であり、この複雑性はどこにも消えません。この仕事にはスキルと経験が必要であり、過去のシステム崩壊の血みどろな歴史から辛うじて得た知恵も必要です。LLM(大規模言語モデル)のような華やかな「高度な自動補完」が、このような標準的な答えを直接見つけるのが難しい複雑性に対して、果たしてどれほどの役割を果たせるでしょうか?おそらく、注意深く設計されたプロンプトによって、望ましい方向へと導くことはできるでしょう。しかし、その段階に至れば、それを誘導する担当者が自ら設計案を作成した方がまだマシです。なぜなら、LLM はなぜ特定のパスを選択したのかを説明することができないからです。本質的複雑性は往々にして奇妙で、稀であり、混乱しています。もしかしたら私が間違っているのかもしれません。モデルがこうした混乱した状況の処理においてますます良くなっている可能性もあります。しかし、私にはこれに必要なのは非常に特定された人間の思考様式とアプローチであると感じています。幸いなことに、私はこのごちゃごちゃしたものが大好きです。
私はこの混乱が大好きだ
前面我一直在谈论软件如何抽象流程,但其实我们也利用抽象的“简化”特性,作为理解世界的一种工具。在经典名著《国家的视角》中,詹姆斯·斯科特(James Scott)描述了后启蒙时代的一个核心动机:通过抽象和分类,让人口和财产变得清晰可辨。能量化的东西,就能被改造。例如,一个国家在看待其森林时,可能不再将其视为复杂的生态系统,而是仅仅通过“能用于造船的木材比例”来评估。这种视角随之促使国家采取行动,比如用单一树种的林场取代原生森林。于是,一片森林被抽象成了一个“种植船桅的系统”。
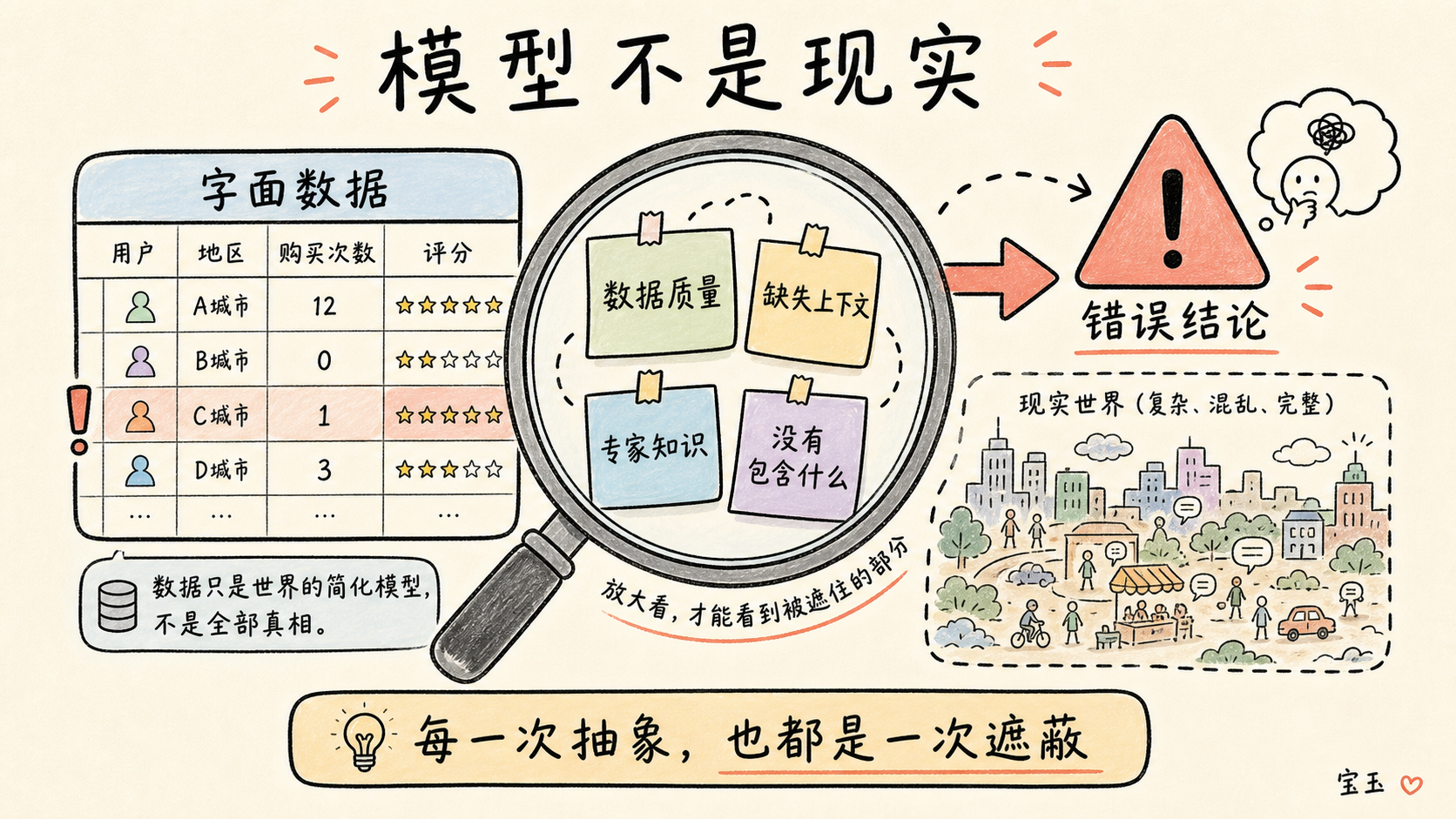
这种方法催生了官僚机构和纸质表格,进而演变成了今天的网页表单和数据库。作为程序员,为了对世界采取行动,我们必须减少现实数据中的混乱。我们期望日期必须是精确的,期望人的名字相对简单规范,期望数据在输入时是完整的且随着时间推移保持一致。每一个程序员和每一次系统设计,都在做出一种削足适履的强制妥协:我们决定系统应该反映现实的哪些方面,又该丢弃哪些方面。我这么说并非为了批评,因为要想构建出不被无数特殊情况(我们称之为“边缘用例”,因为它们本应是处于边缘的罕见情况)所拖垮的系统,这是唯一的方法。
但是,这个过程如此根深蒂固,以至于我们有时会忘记它同时也是一种人为的造作,尤其是在用它来描述人的时候。强制性别字段只接受“男”或“女”,并不能迫使性别的本质变得非黑即白;我们对种族的定义是一种不断变化的社会建构。我们简化的模型可能会给我们提供洞见(过去 20 年自闭症诊断率猛增了 300%!),但却无法捕捉到这些洞见背后的潜在因素(这很可能只是因为我们对自闭症定义的改变以及筛查力度的加大)。退一步去审视任何模型是如何构建的,以及它遗漏了哪种类型的知识,这非常重要。每一次抽象,同样也是一次遮蔽。
作为一名前数据记者,我学会了如何“审问”数据,并且严谨地防范我得出的答案可能会在哪些方面产生误导。如果你想避免发布令人尴尬的更正声明,“迫害妄想症”绝对是数据记者最好的朋友。你不仅要能思考数据说了什么,还要能思考它没有包含什么。
不幸的是,这种试图跳出来审视系统本身的元认知,是 LLM(大语言模型)永远无法做到的。对它们来说,模型本身就是现实。正如 Robin Sloan 在其引人入胜的文章《语言模型是在地狱里吗?》中精辟指出的那样:AI 模型的构建基础和它们看待世界的方式,都被极度剥离了细节。当你我看着一段文字时,我们能看到它的上下文(比如文本格式、标题、作者简介、提供链接的网站等),而 LLM 仅仅在一个纯粹由字母构成的世界里运转(严格来说,它们接收的是子词标记,这就是为什么早期的模型数不清单词 'strawberry' 里有几个字母 'r')。要求 LLM 去认识到它所看到的现实是有局限性的,就像是问金鱼水温怎么样一样,对牛弹琴。
写到这一节时,我满脑子都是 DOGE(政府效率部)在社会保障局(SSA)试图揪出欺诈行为时的那些拙劣表演。举个例子,DOGE 审查了 SSA 的数据库,发现里面有超过 900 万条记录的出生日期在 120 多年前,却没有记录死亡日期。马斯克断言,唯一的解释就是数以百万计的人在欺诈性地领取福利。但他对问题的起因和严重程度都判断错了。DOGE 本可以质疑数据质量,本可以去查查实际是否有钱打进了这些账户,甚至本可以随便找个 SSA 的专家给他们解释一下。但他们没有,他们直接照单全收了字面数据,并草率地得出了错误的结论。
这个套路他们玩了一遍又一遍。在另一个关于付款的欺诈指控中:
関係文書の調査および『ニューヨーク・タイムズ』に情報を提供した関係者によると、その後の広範な分析において政府機関の専門家は DOGE における論理の誤りを慎重に記録しました。
DOGE の業務を監査する代理副局長のショーン・ブレンは、ある問題に関するレビューメモの中で「これらの支払いは合法かつ有効である」と記述しています(財務省の広報担当者はコメントを拒否しました)。
しかし、ルソー氏の発言に詳しい関係者によると(ルソー氏はコメント依頼に応じませんでした)、彼は DOGE が職業公務員を信頼しないと考えていると述べました。その代わり、彼は 21 歳の若手であるアカシュ・ボバ氏に自身の分析を行わせるよう強く主張しました。ボバ氏はかつてパラメーターでインターンシップを経験し、現在は DOGE の中核プログラマーとして活動しています。
彼ら独自の荒々しい方法で、DOGE チームは大規模言語モデル(LLM)が誤った方向へ進んでしまったのと同じ論理を繰り返しています。彼らはデータの文字通りの意味以外のいかなる解釈も考慮することを拒否し、自分たちのサークル外の誰とも交流せず、極めて単純化された一つの説明に固執します。それは単に彼らの好みに合致しているからです:これは「政府職員は全員バカで、詐欺が至るところにある」という彼らの世界観を完璧に裏付けるものだからです。
私は自分が馬鹿らしく見られることを極端に恐れているため、決してデータ分析の仕事を LLM に外注することはありません。しかし、そうする人は大勢います。この問題はますます悪化していくのではないかと心配しています。
摩擦は上天的な恩恵
大規模言語モデル(LLM)駆動の開発の魅力は、あらゆる摩擦を排除できると謳っている点にあります。熱狂的な支持者たちは美しい神話を紡ぎ出します:開発チームが一日で数十もの新機能をリリースし、ますます奇妙なネットワークトポロジーの中で複数の AI エージェントチームを自律的に指揮するのです。私は理解しています。ソフトウェア開発には確かに退屈でイライラさせる側面があります。信じられないほどの速度でコードを生産し、未完成のプロトタイプではなく磨き上げられた製品を扱う感覚は、きっと非常に刺激的でしょう。
しかし、私はこの摩擦が必要です。
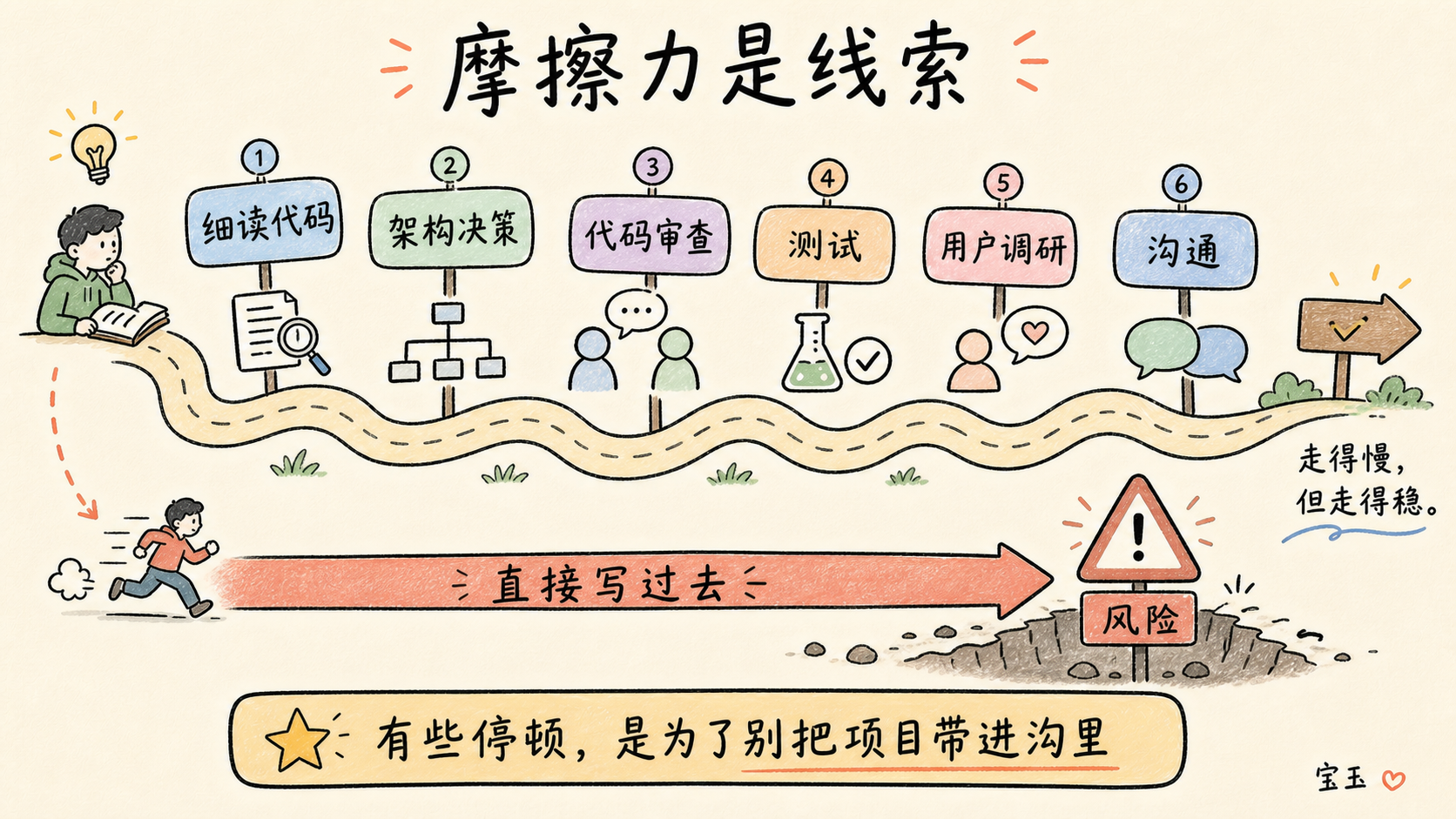
新しい言語やフレームワークの学習を始めたばかりの頃は、最も基本的な作業さえも摩擦と戦う必要があり、その感覚は最悪でした。一方、見知らぬコードベースやデータソースに取り組む際には、それを慎重に検討するために数時間の時間を確保する必要があります。私はしばしば文字通り一語一句まで深く掘り下げることをし、特定のファイルを開き、行ごとに読み進めて、文脈を完全に理解し、開発者がなぜそのような選択をしたのかを理解するまで続けます。もちろん、LLM にプロジェクト全体の要約を頼んで時間を節約することもできますが、私はコードの中で「煮詰める」プロセスが必要なのです。私が知りたいのは開発者がどのような選択をしたかだけでなく、なぜその選択をしたのか、そしてそれらの選択がいかにして言語の限界やプログラミングの習慣を反映しているかということもです。私は失敗から学びます。もし LLM がこの苦役を引き受けてくれたなら、私は自分が何をしているのかを本当に理解することは永遠にできないでしょう。
たとえ慣れ親しんだ言語環境で自分のコードを書く場合でも、私は依然として摩擦を重要な手がかりとして強く依存しています。コーディングが非常に困難になる時、それは現在のアーキテクチャにおいて私が誤った道を進んでいることを示唆しています。それは私に、将来の拡張性をよりスムーズにするために再設計を真剣に検討するよう警告しているのです。
このような状況では、私は通常、長い散歩に出かけ(あるいは単に退勤して)、脳に余白を与え、一歩引いて物事を別の角度から考えるようにします。この方法は本当に効果的です。その効果の高さに気づいた私は、たとえ思路が明確であっても、自らを強制的に停止させることにしています。大規模なソフトウェアプロジェクトを開発する際、新しい機能のコーディングを開始する前に、私はまずアーキテクチャ決定記録(Architectural Decision Record、ADR)を作成することを自分に課します。これは自分が何をしようとしているかを記述したものです。これらの文書は、その瞬間の私の考え、問題に対する私の仮定、そしてこのアプローチがもたらす可能性のある結果を記録することを強要します。書き進めているうちに、私は自分の最初の直感に対して盲目的に自信を持ちすぎており、それがプロジェクトを破滅させる道へと導くことに気づいていなかったと気づくことがあります。同時に、将来私の仕事を引き継ぐ後任者にとって、これは「あの当時の連中は何を考えていたのか?」という疑問に対する記録として永遠に優れた手段となります。
LLM を駆使した開発における摩擦への態度とは、理屈を並べることもせず、目を閉じてひたすら書き進めることです。LLM は非常に協力的で、おそらく動作するコードを書き上げ、性能指標も良好で、テストも通過させるでしょう(特にテスト自体が LLM によって作成された場合)。しかし、なぜその道を選んだのかを LLM 自身は理解しておらず、摩擦を感じ取ることもできません。また、あるアーキテクチャ案が別の案よりも明確でエレガントであるという感覚について、あなたに説明することもできないのです。
もしプロンプトを作成するエンジニア自身が洞察力に欠け、良し悪しの区別がついていないなら、彼らは死循環に陥ります。つまり、AI に何度も何度も無理やり摩擦を乗り越えてコードを書かせるというループです。その結果、奇形怪状な抽象論理が生成され、未来のチームに残される唯一の設計ドキュメントは、数年前に AI モデルへの指示として作成された Markdown の孤本ファイルだけになります。そこから当時のアーキテクチャ判断を再構築できることを祈るしかありません!
見てのとおり、私が目撃した「感覚でプログラミング」による成功事例の多くは、開発者自身がその分野の専門家であり(したがって AI の作業を驾驭できている)、あるいは失敗しても大した問題にならない小規模なプロジェクトに限られます。それ以外のケースでは、我々はあの有名な「フクロウを描く方法」ミーム図において描き残された部分が本当に上手で安全なものかどうか、自分たちで判断するしかありません。
私にとってまだ引っかかっている点があります。LLM の販売担当者が「摩擦」を敵視しているとき、彼らは実際には何を暗示しているのかです。広告やデモ、LinkedIn の投稿において、LLM 関連のマーケティングは、孤高の英雄のようなエンジニア(あるいは単独チーム)を描き出しています。彼らは LLM を駆使したプログラミングで、驚異的な速度でアプリケーションやウェブサイトを生成し、即座にリリースするのです。しかし、業界が本当に求めているのは、日常業務の中で LLM を活用することです。実際の現場では、「摩擦」とは通常、欠陥や不適切なアイデアが生産環境に流れ込むのを防ぐための既存のプロセスや規範を指します。
避けられないことですが、「LLM による速度」への狂信的な追求は、最終的に人々自身に向けられます。他のエンジニア、プロダクトマネージャー、プロジェクトマネージャー、テスター、コンプライアンス審査員、あるいはデザイナーなどです。なぜなら、これらの役割も今や「摩擦」と見なされているからです。AI でユーザーペルソナを捏造できるのに、なぜユーザー調査が必要なのか?AI ツールが直接ウェブページのレイアウトを出力するなら、なぜデザイナーが必要なのか?私たちが AI エージェントの群れを統率するマネージャーなのだから、なぜプロジェクトマネージャーが必要なのか?もし他の開発者のコードレビューを待つ必要がなくなり、テストとスキャンに合格すれば自動的にマージされるなら、どれほど素晴らしいことでしょう?もし仕事時間を他人とのコミュニケーションに費やすことがなくなり、純粋なコーディングのみが残る境地へと昇華できるなら、これほど美しいことはないでしょう。
しかし、ソフトウェア開発は協働のプロセスであり、チームのすべてのメンバーが優れた製品の構築に貢献しています。これらの役割を排除したり、LLM の気配を帯びたコードの幽霊で置き換えたりすれば、確かにチームのスピードは上がるかもしれませんが、それが製品品質の向上を意味するわけではありません。それに、このプロセスは間違いなく極めて孤独なものになります。
私は非常に重視している
私が LLM を使わない最もシンプルな理由は、おそらく私がプログラミングをあまりにも愛しているからで、それを機械に譲り渡したくないからです。もし私が画家や音楽家なら AI に頼むことはないでしょうが、プログラミングは私の創造性を表現する手段であり、この純粋な喜びを絶対に手放しません。時には人を狂わせることもありますが、ぼんやりとしたアイデアを少しずつ形にして実際のシステムに変え、特にそこに優雅な実装や面白い挑戦が含まれている場合、そこには大きな喜びがあります。ある夜は仕事用のパソコンを閉じて、プライベートのノートパソコンを開き、私が作りたい面白い新しいものにとりかかります。そして職場では、チームの一員としてソフトウェアを構築するその感覚はさらに素晴らしいものです!私はチームワークを愛し、一緒にソフトウェアを磨き上げる過程を愛します。特に皆が率先して立ち上がり、問題を解決する責任を引き受ける姿を見るのが好きです。チームが単に「プロンプトの責任」を負うだけで、LLM アシスタントが作業を行う場合、このモチベーションが同じように維持されるとは思えません。あるいはもっと最悪なケースとして、LLM アシスタントがチームの一部を直接置き換える場合などです。

責任感があまりにも重要です。過去数十年にわたり、私は異なる立場で強い個人的な責任感を培ってきました。元データ記者として、コード内のバグが非常に恥ずべき新聞の訂正を招いたり、破滅的な訴訟を引き起こしたりする可能性があります。公共技術分野では、エラーは一般市民へのサービスや福祉を提供するシステム全体の崩壊を意味し、それはすべての社会的弱者に波及するか、あるいは単なる一人の個人に影響を与えることになります。私が一度も間違いを犯したことがないとは言いませんが、この仕事の使命を大切にしているからこそ、物事を正しく行うことに非常にこだわっています。私と同じように大切にし、人々のために全力で奉仕したいと願う多くの同僚と共に戦えたことは光栄なことです。
そして LLM は決して「気にする」ことはありません。もちろん、非常に本物らしく装うことはできますが、依然として人間の心臓を模倣しようとする贋作に過ぎず、統計的に同時に出現しやすい単語の組み合わせをつなぎ合わせるだけなのです。ミスを犯しても懊悩することはありませんし、改善しようと努力することもありません。なぜなら内面的な意識を持たず、ましてや道徳的良心などないからです。決して責任を追及されることはなく、したがって私は私の道徳的責任を外部委託することは絶対にできません。
LLM がうまく機能している時は、それはすべてのプログラマーを置き換える天才であるかのように見えますが、LLM があなたのインフラストラクチャ(infrastructure)をすべて削除したり、テスト結果で「嘘」をついたりした時、その過失はあなたに帰されます。結局のところ、プロンプトとワークフローを正確に設定しなかったのは誰ですか?LLM に正しい出力を出させるためにうまく「説得」できなかったのは誰ですか?ああ、もう一度試しましょう、もう一度試しましょう。私が読んだ多くの LLM 教程が繰り返し強調していることは、システムが失敗しないように、最初に必要なすべての指示、修正条項、追加説明をすべて与えなければならないということです。この思考様式はアジャイル開発(agile development)とは真逆です。アジャイル開発は頻繁に方向転換し、タイムリーなフィードバックを得て、チームが正しい選択をすると信頼することを重視します。私たちはまるで 1950 年代初期のコンピュータの分时共有(time-sharing)モードへと後退しているかのようです。ただし今回は、孤独なプログラマーがパンチカードを束ねて列に並ぶ代わりに、厚い「法的契約」を持って機械がプログラムに変換してくれることを期待するようになります。
「凭感觉编程」なんて冗談です;実際には法的責任の問題ではありません。両者の対象読者層の類似性を考慮すれば、これも不思議なことではないでしょうが、LLM(大規模言語モデル)ベンダーはテスラの手法を繰り返しています。安全テストも実施せずに新機能をユーザーにリリースし、さらに奇妙なことに、テスラの狂信的な支持者たちと同様に、LLM の熱心な擁護者たちは壊滅的な結果が生じると、自分自身や他者を責め、それはユーザーの指示(プロンプト)が不十分だったせいだと主張します。この現象をどう評価すればよいのか私にはわかりませんが、テクノロジー業界は極端な資本主義を標準化し、企業と政府が規制責任を放棄したことで、消費者により多くのリスクを負わせています。これは私にとって非常に不安なことです。かつて、誤って子供を殺害する危険性のある「草地飛镖ゲーム」が原因で一人の子供が亡くなったという事件をきっかけに、私たちはそのゲームを全面的に禁止しました。しかし、ユーザーを自殺に追い込んだり精神異常に陥らせたりする AI チャットボットは、AI の革新に伴う当然の代償として扱われています。本当に、「凭感觉编程」によってシステムがクラッシュし、単なる恥辱ではなく人的被害が生じるまで状況が変わらないのでしょうか?
困難な時期には、コードを書くことがいつも私の慰めとなってきました。ある研究では、ロシア人形(テトリス)を遊ぶことが心的外傷後ストレス障害(PTSD)の予防に有効であると示されています。この理論は、脳内の図形の配置や回転を担当する部分を活性化させることで、トラウマ記憶の形成を阻害できるとしています。現在、私は幸運にも PTSD を発症していません(患者さんに対して冗談を言っているわけではありませんが)、しかしこの概念には深く共感します。プログラミングは複雑なパズルを解くようなもので、暗い時期にはいつも私の避難所となってきました。前述の例が示唆しているように、DOGE については非常に詳しくなっています。というのも、過去一年間、彼らの狂気的な行動を追跡・記録するシステムを構築し維持してきたからです。仕事上のプロジェクトとは異なり、これは完全にデータを収集して組み立てる練習であり、隠れようとする組織を太陽の下に晒すことを目的としています。このプロセスは非常に充実したものであり、絶望を何か役に立つ形に変換する方法でもあります。これが悲しみを和らげる手段としてコードを使うのは初めてではありませんが、その効果があるのはまさに、これが多額の労力を要する作業だからです。もし最終結果だけを意識していたなら、この癒やしのプロセスは大幅に損なわれていたでしょう。
他にもいくつかの笑える理由
この小文は私の予想を遥かに超える長さになってしまいました。元々は Bluesky に投稿しようとした短い愚痴の数行に過ぎなかったのです。終わる前に、もう数個の理由を簡単に補足します。
まず第一に、AI チャットボットがデフォルトで採用している油腔滑調な口調が非常に嫌いです。アメリカ東海岸の都市で育った私にとって、見知らぬ人が突然過度に親しげで、不自然に丁寧になるとき、私は本能的に警戒します。なぜなら、それは通常、相手が私の金を騙し取ろうとしているか、布教活動を始めようとしていることを意味するからです。LLM とのチャット履歴を読むと、鳥肌が立ちます。はい、設定を変更して LLM の口調を変えられることは知っています。しかし、不思議なことに、そうするとむしろ全体がより悪く感じられてしまいます。
多くの開発者と同様に、私にも「いつまで経っても完成しない趣味プロジェクト」の草稿を収めたフォルダが一つあります。例えば、Clojurescript でスペリングゲームのクローン版を作ろうとしたことがありました。そうすれば、Blabrecs(※原文のまま)内のコードを使って存在しない架空の単語を生成し、意図的にゲームをイライラさせることができるからです。はい、これは私の個人的な悪趣味かもしれません。文脈を理解してこそ笑えるポイントです。LLM の視点から見れば、これらは失敗に終わったフォルダの山ですが、確かに LLM を使って「一日一アプリ」のような挑戦を行うことは可能です。しかし、過程が結果よりもはるかに重要です。すべてのひらめきを現実のプロダクトに変える必要はありません。通常、私はアイデアをぶつける楽しさや、「このプロジェクトを完成させる必要はない」と証明するために新しい知識を学ぶプロセスから、より多くの収穫を得ています。
私は元々、この記事の中で職場での LLM(大規模言語モデル)利用に関する倫理的問題について議論するつもりはありませんでした。私が気にしていないからではなく、私よりも賢い人々がすでにこの技術がもたらす懸念すべき隠れた危険を非常に深く論じているからです。現在、LLM が児童がいる学校に爆弾脅迫を送ったり、必要に応じて児童ポルノコンテンツを生成したりしている時代において、それらを使用することに本当に安心できません。もし私がこの点について一言も触れなければ、私の心も落ち着きません。資本主義の枠組みの中では、おそらく絶対的な道徳的な消費は存在しないかもしれませんが、それでも、私は少なくとも努力して試みるべきだと考えています。あまりにも多くの人々を悲惨な状況に陥れるようなツールを使って、より良い世界を構築することはできません。
不思議なことに、この LLM の擁護者たちほど、苦しく憎しみ深い生活を送っている人はいないようです。もし開発者が、彼らが新たに得た「生産性の爆発的向上」を利用して、ついに 10 年前にこれらのゲイターたちが偽って崇拝していた週 4 時間労働のユートピア的生活を送れるようになったなら、私はもしかしたら感動するかもしれません。しかし病的なのは、シリコンバレーの多くの人々が、仕事を AI エージェント(人工知能エージェント)に外注した後に、むしろ節約された余暇を使ってさらに多くの仕事を受け入れていることです。彼らは休息や芸術活動、あるいは生活を楽しむためにその時間を使わず、996 労働制度(朝 9 時から夜 9 時まで週 6 日勤務)と、極めて厳格な量化管理環境を歓迎しています。これは、極端な搾取で知られる科学管理学派の創始者であるフレデリック・テイラーが見ても冷汗をかくほどです。おそらく LLM の革命は最終的に私の居場所や職を席巻するかもしれませんが、その前に、私は自分自身を先に墓場へと巻き込まれたくありません。
未来の道はどちらか?
私は自分が未来を予知できるかのように振る舞うつもりはありません。もしかすると、この技術は本当に想像を絶するほど発展し、私が十分に経験を積んでそれを習得していなかったことを後悔することになるかもしれません。あるいは、停滞に陥り、ひたすら過熱した期待の上に築かれた金融の紙芝居が崩れ落ちることもあるでしょう。もしそのような日が本当に訪れるのであれば、私たちはソフトウェア開発を再び人間味あふれる実践として再構築できることを願っています。
原文を表示
为什么我不“凭感觉编程”
作者:Jacob Harris
最近网上关于“凭感觉编程”(Vibe Coding)以及大语言模型(LLM)将如何颠覆软件开发的讨论铺天盖地。据说,每一个新模型的发布都会把我们带入纯粹生产力的天堂,让我们能以光速发布软件,彻底消除产品开发中的所有摩擦和内耗。
或许吧,我姑且信之。但我自己,是不“凭感觉编程”的。
如果你觉得这套好用,那太棒了!我写这篇文章并不是为了探讨 LLM 的优劣,只是这玩意儿对我个人来说,从来没对过胃口。这篇文章,算是我简单盘点一下其中的种种原因。
我是个守财奴
我不是个原教旨主义者。我试过用集成在 IDE 里的 LLM。对于那些描述起来很简单、但自己动手又嫌烦的任务,它们确实挺好用的,比如把网格里的一堆方形图片缩小。我本可以去查查图像处理软件 ImageMagick 的命令行参数,但这种事交给 AI 去干再合适不过了。接着,我又试着用某个 AI 工具分析了我项目里的一段代码,还做了几件小事,然后一切戛然而止。系统通知我:额度用光了。如果想继续,请绑定信用卡购买更多 Token。
你得知道,我祖上两边都是出了名的铁公鸡。几个世纪以来,无论是在大西洋的这头还是那头,我们家族一直精打细算、锱铢必较。举个极端的例子:我的一位远房祖先在 17 世纪的菲利普国王之战中丧生,原因竟然是他在撤离房子时落下了点奶酪,非要跑出安全的堡垒去捡。
所以你一定要相信我:当我发现为了让自己能“思考”,居然还要无休止地给一个服务交钱时,我浑身不自在,以至于连信用卡的影子都不想给他们看。我合上笔记本电脑,卸载了那个 IDE,甚至乖乖用回了极其硬核的纯文本编辑器 Emacs。然后我发现,我压根儿就没觉得少了 AI 有什么不习惯的。
我年纪大了
年纪大确实有点帮助。我写代码已经很多年了,尤其是在这个把只有 5 年经验的开发者就称为“高级工程师”的行业里。有时候,经验是缓解焦虑的一剂良药(前提是,你焦虑的不是在这个 5 年就能称“高级”的行业里遇到的年龄歧视)。这波 AI 热潮确实让我想起了早年那些“低代码”或“无代码”工具所吹嘘的重大突破。我不怀疑 AI 可以成为开发者手中的利器,我知道在很多任务上它能提供更好的工具支持。但这些争论,总是让我回想起关于“偶然复杂性”(accidental complexity)和“本质复杂性”(essential complexity)的经典理论。
即使在我还是个年轻码农的时候,弗雷德·布鲁克斯(Fred Brooks)也算得上是老前辈了。作为 IBM System 360 系列大型机(及配套操作系统)的项目经理,他曾在第一线亲眼目睹了如今软件项目中那些司空见惯的烂摊子。他将这些观察整理成了《人月神话》一书,至今仍应是软件工程课程的必读经典。我手头的那本是后来重印的新版,里面收录了他后期的一篇著名文章《没有银弹》。在这篇文章中,布鲁克斯探讨了新工具对开发者生产力的实际影响。要想像程序员一样思考,你必须明白现实世界是极其复杂的。编程最好被理解为:在混乱的现实之上强加一种简化的模型,我们称之为“抽象”(abstractions),通过降低复杂性来让世界变得可理解。
这让我们能够将特定的情况泛化成一个个可以层层叠加的结构。例如,“把花生酱抹到面包上”这个具体动作,可以泛化成一个 spread(substance)(涂抹物质)的方法,这个方法既可以接受“花生酱”作为参数,也可以接受“奶油奶酪”。接着,我们可以用这些基础方法构建出更高级的函数,比如 create_pbj()(制作花生酱果冻三明治)等等。在现代高级编程语言中写代码,就像是站在一座由抽象概念堆砌而成的金字塔顶端:只需一行代码,就能在多个系统上触发数以百万计的底层操作。
那么,如果我们继续往下走,把“编程”这个行为本身也抽象掉呢?这就是 AI 智能体的终极梦想:成群结队的智能体接受任务,然后在无人监督的情况下自动实现它们。听起来棒极了!但这解决的仅仅是布鲁克斯所说的偶然复杂性,也就是编写代码本身那些繁琐、笨重的地方。自从那篇文章发表以来,软件开发在应对偶然复杂性方面已经取得了巨大的进步。我们不用再写底层的机器码,而是使用现代的动态解释型语言;我不需要再从头记住如何手写一个快速排序,只需调用标准库里的排序方法即可;我也不用再从零开始搭建整个 Web 应用,而是直接使用现成的框架。如果我想重命名或者重构某段代码,我的编辑器可以代劳。
AI 似乎只是这一进程的最新迭代,一些编辑器已经用不可预测的 AI 智能体,取代了过去那些可预测的老式重命名和重构工具。诚然,这听起来像是在掷骰子碰运气,但在实际开发中,那种灾难性的大翻车又能有多常见呢?
然而,即便更好的工具削弱了偶然复杂性,本质复杂性还在那儿。设计出正确、优雅、清晰且易于维护的抽象架构和系统,依然是一项无比艰巨的工作,这种复杂性哪儿也去不了。这项工作需要技能、经验,以及从过去系统崩溃的血泪史中艰难汲取的智慧。LLM 那种花哨的“高级自动补全”,面对这种很难直接找到标准答案的复杂性,到底能发挥多大作用?也许通过精心设计提示词,你可以引导它走向你心仪的方案,但到了那个地步,负责引导的人还不如自己干脆把方案设计出来算了,因为 LLM 根本无法向你解释它为什么选择了某条特定的路径。本质复杂性往往是怪异、罕见且混乱的。也许我错了,也许模型在处理这些混乱情况方面正变得越来越好,但我发现这通常需要一种非常特定的人类思维模式和方法。幸运的是,我超爱这种乱糟糟的东西。
我爱死这些混乱了
前面我一直在谈论软件如何抽象流程,但其实我们也利用抽象的“简化”特性,作为理解世界的一种工具。在经典名著《国家的视角》中,詹姆斯·斯科特(James Scott)描述了后启蒙时代的一个核心动机:通过抽象和分类,让人口和财产变得清晰可辨。能量化的东西,就能被改造。例如,一个国家在看待其森林时,可能不再将其视为复杂的生态系统,而是仅仅通过“能用于造船的木材比例”来评估。这种视角随之促使国家采取行动,比如用单一树种的林场取代原生森林。于是,一片森林被抽象成了一个“种植船桅的系统”。
这种方法催生了官僚机构和纸质表格,进而演变成了今天的网页表单和数据库。作为程序员,为了对世界采取行动,我们必须减少现实数据中的混乱。我们期望日期必须是精确的,期望人的名字相对简单规范,期望数据在输入时是完整的且随着时间推移保持一致。每一个程序员和每一次系统设计,都在做出一种削足适履的强制妥协:我们决定系统应该反映现实的哪些方面,又该丢弃哪些方面。我这么说并非为了批评,因为要想构建出不被无数特殊情况(我们称之为“边缘用例”,因为它们本应是处于边缘的罕见情况)所拖垮的系统,这是唯一的方法。
但是,这个过程如此根深蒂固,以至于我们有时会忘记它同时也是一种人为的造作,尤其是在用它来描述人的时候。强制性别字段只接受“男”或“女”,并不能迫使性别的本质变得非黑即白;我们对种族的定义是一种不断变化的社会建构。我们简化的模型可能会给我们提供洞见(过去 20 年自闭症诊断率猛增了 300%!),但却无法捕捉到这些洞见背后的潜在因素(这很可能只是因为我们对自闭症定义的改变以及筛查力度的加大)。退一步去审视任何模型是如何构建的,以及它遗漏了哪种类型的知识,这非常重要。每一次抽象,同样也是一次遮蔽。
作为一名前数据记者,我学会了如何“审问”数据,并且严谨地防范我得出的答案可能会在哪些方面产生误导。如果你想避免发布令人尴尬的更正声明,“迫害妄想症”绝对是数据记者最好的朋友。你不仅要能思考数据说了什么,还要能思考它没有包含什么。
不幸的是,这种试图跳出来审视系统本身的元认知,是 LLM 永远无法做到的。对它们来说,模型本身就是现实。正如 Robin Sloan 在其引人入胜的文章《语言模型是在地狱里吗?》中精辟指出的那样:AI 模型的构建基础和它们看待世界的方式,都被极度剥离了细节。当你我看着一段文字时,我们能看到它的上下文(比如文本格式、标题、作者简介、提供链接的网站等),而 LLM 仅仅在一个纯粹由字母构成的世界里运转(严格来说,它们接收的是子词标记,这就是为什么早期的模型数不清单词 'strawberry' 里有几个字母 'r')。要求 LLM 去认识到它所看到的现实是有局限性的,就像是问金鱼水温怎么样一样,对牛弹琴。
写到这一节时,我满脑子都是 DOGE(政府效率部)在社会保障局(SSA)试图揪出欺诈行为时的那些拙劣表演。举个例子,DOGE 审查了 SSA 的数据库,发现里面有超过 900 万条记录的出生日期在 120 多年前,却没有记录死亡日期。马斯克断言,唯一的解释就是数以百万计的人在欺诈性地领取福利。但他对问题的起因和严重程度都判断错了。DOGE 本可以质疑数据质量,本可以去查查实际是否有钱打进了这些账户,甚至本可以随便找个 SSA 的专家给他们解释一下。但他们没有,他们直接照单全收了字面数据,并草率地得出了错误的结论。
这个套路他们玩了一遍又一遍。在另一个关于付款的欺诈指控中:
据查阅相关文件及知情人士向《纽约时报》透露,在随后的广泛分析中,政府机构专家仔细记录了 DOGE 工作中的逻辑谬误。
代理副局长肖恩·布伦在一份审查其中一个问题的备忘录中写道:“这些付款是合法有效的。”(财政部发言人拒绝置评。)
但据熟悉鲁索先生言论的人士称(鲁索未回应置评请求),他表示 DOGE 不会信任这些职业公务员。相反,他坚持让阿卡什·博巴,一名 21 岁、曾在帕兰提尔实习并成为 DOGE 核心程序员的年轻人,来进行他自己的分析。
以他们自己狂野的方式,DOGE 团队正在重演导致 LLM 走偏的同款逻辑。他们拒绝考虑任何在数据字面意思之外的替代解释,拒绝与自己圈子之外的任何人交流,死死咬住一个极其简化的解释,仅仅因为这太合他们胃口了:这完美印证了他们“政府员工全都是蠢货、欺诈行为无处不在”的世界观。
我本人因为极其害怕让自己看起来像个白痴,绝不希望把数据分析工作外包给 LLM。但有大把的人愿意这么干。我担心这个问题只会越来越糟。
摩擦是上天的恩赐
大语言模型驱动开发的魅力在于,它标榜能消除一切摩擦。吹鼓手们编织出美好的神话:开发团队一天就能发布几十个新功能,在越来越奇葩的网络拓扑结构下,指挥着好几个 AI 智能体团队自主运转。我懂,软件开发有时候确实枯燥又让人抓狂。能够以不可思议的速度疯狂产出代码,把玩着打磨精美的产品而不是半成品原型,那种感觉一定超级刺激。
但我需要这种摩擦。
刚开始学习一门新语言或新框架时,我连做最基础的事情都要和摩擦搏斗,这感觉糟透了。而当我在处理一个陌生的代码库或数据源时,我需要预留出几个小时的时间去仔细审视它。我经常会做一些逐字逐句的深度死磕,打开特定的文件,一行一行地看,直到我完全理解它们的上下文,以及开发者做出这些选择的原因。我知道,我大可以叫 LLM 帮我总结一下整个项目,省下这大把时间,但我真的需要这个在代码里“泡着入味”的过程。我需要的不仅是知道开发者做了什么选择,我还需要知道他们为什么这么选,以及这些选择是如何反映出这门语言的局限性或编程习惯的。我在失败中学习,如果 LLM 把这部分苦差事替我干了,我将永远无法真正理解我到底在做什么。
即使是在熟悉的语言环境里写我自己的代码,我依然严重依赖摩擦作为重要的线索。当写代码变得非常困难时,这说明在当前的架构下我正走向一条歧路。它在提醒我,应该认真考虑重新设计,以便未来的扩展能更顺畅。
遇到这种情况,我通常会出去散个长步(或者直接打卡下班),给大脑留点空间,退一步换个角度思考问题。这招真的管用。我发现这种停顿极其有效,以至于即便思路清晰,我也会强迫自己停下来。在开发大型软件项目时,在开始为一个新功能写代码之前,我会先强制自己写一份架构决策记录(Architectural Decision Record,ADR),描述我想做什么。这些文档逼着我记录下这一刻我的想法、我对问题的假设,以及我这套方案可能带来的后果。有时候,写着写着我就意识到,我对自己最初的直觉太盲目自信了,以至于都没发现它会把项目带进沟里;同时,对于未来接手我工作的继任者来说,这也永远是记录“当年那帮家伙到底在想什么?”的绝佳途径。
而 LLM 驱动开发对待摩擦的态度,就是不管三七二十一,闭着眼睛直接写过去。LLM 会极其配合。它大概率能写出能跑通的代码,性能指标可能不错,测试也能通过(尤其是如果测试也是 LLM 写的话)。但它根本不知道自己为什么选择了那条路,它感受不到摩擦,也无法向你解释一种架构方案是否感觉比另一种更清晰优雅。如果负责写提示词的工程师本身缺乏洞察力,不知道好坏方案的差别,他们就会陷入一种死循环:一遍又一遍地让 AI 强行穿越重重摩擦写代码。最终生成一堆奇形怪状的抽象逻辑,而留给未来团队的唯一设计文档,就是几年前一个用来指示 AI 模型的 Markdown 孤本文件。祝你从那玩意儿里重构出当年的架构决策好运吧!
不难看出,我所见到的大多数凭感觉编程的成功案例,要么是开发者本身已经是该领域的专家(因此能够驾驭 AI 的工作),要么是那些哪怕搞砸了也无伤大雅的小项目。至于其他情况,我们只能想办法自己判断那著名的“如何画猫头鹰”梗图中剩下没画完的部分到底画得好不好、安不安全了。
还有一个让我耿耿于怀的点:当 LLM 的推销员们将“摩擦”视为眼中钉时,他们实际上在暗示什么。在广告、现场演示和 LinkedIn 帖子里,大多数 LLM 营销都在刻画一位孤胆英雄般的工程师(或者一个单兵团队),英勇地利用 LLM 驱动编程,以迅雷不及掩耳之势喷射出一堆应用或网站并火速上线。但是,行业真正想要的是开发者在日常工作中使用 LLM,而在实际工作中,所谓的“摩擦”通常是指那些旨在防止缺陷或糟糕创意流入生产环境的既定流程和规范。
不可避免地,对“LLM 驱动速度”的狂热追求,最终会把矛头指向人本身,包括其他工程师、产品经理、项目经理、测试人员、合规审查员或者设计师。因为这些职位,现在也被视为了“摩擦”。既然我们能捏出 AI 用户画像,还要什么用户调研?既然 AI 工具能直接吐出网页排版,还要什么设计师?既然我们自己就是统帅 AI 智能体大军的经理,还要什么项目经理?如果我们不再需要等另一个开发者来审查我们的代码,只要通过了测试和扫描就自动合并,那该多爽?如果我们再也不用把工作时间浪费在跟别人沟通上,而是直接飞升到一个只剩纯粹编码的境界里,那该多美?
但是,软件开发是一项协作的过程,团队里的每一个成员都在为打造优秀产品贡献力量。砍掉这些角色,或者用沾染着 LLM 气息的代码幽灵去替代他们,肯定能让团队跑得更快,但这绝不意味着他们交付的产品会更好。而且,这个过程绝对会变得无比孤独。
我极其在乎
我不使用 LLM 的最简单的理由,或许就是我太热爱编程了,以至于我一点也不想把它拱手让给机器。就像如果我是个画家或音乐家就不会求助于 AI 一样,编程是我表达创造力的一种方式,我绝不让出这份纯粹的快乐。尽管有时候它能把人逼疯,但把一个朦胧的想法一点点塑造变成真实的系统,特别是如果其中还包含着优雅的实现或有趣的挑战,这其中蕴含着巨大的喜悦。有些晚上,我会合上工作用的电脑,打开私人的笔记本,一头扎进我想做的某个好玩的新玩意儿里。而在工作中,作为团队的一员去构建软件,那种感觉甚至更棒!我热爱团队协作,热爱一起打磨软件的过程,尤其是看到大家挺身而出、主动承担解决问题的责任时。当团队只是在“承担提示词的责任”,而由 LLM 助手在干活时,我不认为这种动力还能维持原样;或者更糟,当 LLM 助手直接取代了团队的部分成员时。
责任感太关键了。在过去的几十年里,我在不同的岗位上培养出了强烈的个人责任感。作为一名前数据记者,代码里的一个 Bug 可能会导致极其难堪的报纸更正,或者引来灭顶之灾般的诉讼。在公共科技领域,错误可能意味着为公众提供服务和福利的系统彻底崩溃,无论是波及全体弱势群体,还是仅仅影响到一个普通人。我不敢说我从未犯错,但我真的极其在乎把事情做对,因为我在乎这份工作的使命。我有幸曾与许多同样在乎、同样想尽全力为人民服务的同事并肩作战。
而 LLM 是不可能“在乎”的。当然,它可以装得非常逼真,但它依然只是一个试图模仿人类心智的赝品,所做的只是把那些在统计学上更容易同时出现的词组串在一起罢了。它不会因为犯错而感到懊恼,也不会努力试图改进,因为它没有内在的意识,更别提什么道德良知了。它永远无法被追责,因此,我永远也不能把我的道德责任外包给它。
当 LLM 表现良好时,它是即将取代所有程序员的天才;而当 LLM 删除了你所有的基础设施,或者在测试结果上“撒谎”时,错的却是你。毕竟,谁叫你没把提示词和工作流精确地配置好,没能“哄”着 LLM 给出正确输出呢?哎呀,再试一次吧,再试一次。我读过的大量 LLM 教程都在反复强调:你必须在一开始就把所有必要的指令、修正条款和附加说明统统喂给它,否则系统就会把事情搞砸。这种思维模式和敏捷开发完全背道而驰,敏捷开发讲究的是频繁修正方向、及时拿到反馈、信任团队能做出正确的选择。我们似乎正在倒退回一种类似于 1950 年代早期计算机的分时共享模式。只不过这一次,孤单的程序员不再是抱着一沓打孔纸带排队上机,而是拿着厚厚的“法律合同”指望机器把它变成程序。
我开个玩笑;这里其实不涉及什么法律责任。考虑到两者受众群体的相似度,这也许不足为奇,但 LLM 供应商正在重演特斯拉的套路。他们在没有进行安全测试的情况下就把新功能推送给用户,而且诡异的是,就像特斯拉的狂热死忠粉一样,LLM 的鼓吹者们在面对灾难性后果时,往往会责怪自己和他人,声称这是因为用户的提示词写得不够好。我实在不知道该怎么评价这种现象,但科技界正在将一种极端的资本主义标准化,让消费者承担更多的风险,因为企业和政府双双放弃了他们的监管责任,这让我感到极度不安。当初仅仅因为砸死了一个孩子,我们就全面封杀了容易误伤致命的草地飞镖游戏,但逼得用户自杀或精神失常的 AI 聊天机器人,却被视为了 AI 创新必须付出的合理代价。是不是非得等到凭感觉编程引发系统崩溃导致人员伤亡,而不是仅仅死于尴尬时,情况才会有所改变?
在艰难的时刻,写代码也一直是我的慰藉。有研究表明,玩俄罗斯方块是预防创伤后应激障碍(PTSD)的有效方法。这个理论认为,让大脑中负责排列和旋转图形的部分保持活跃,能阻碍创伤记忆的形成。如今,我很幸运没有患上 PTSD(我绝不是在拿患者开玩笑),但我对这个概念深有共鸣。编程就像是在解一个复杂的谜题,在黑暗的时期,它常常是我的避风港。正像前面提到的例子所暗示的,我对 DOGE 非常了解,因为在过去的一年里,我一直在构建和维护一个追踪他们疯狂行径的系统。与工作项目不同,这完全是一场收集并拼凑数据集的练习,目的是让一个拼命想要隐藏自己的组织暴露在阳光下。这是一个极其充实的过程,也是我将绝望转化为希望能有些用的东西的途径。这已经不是我第一次用代码作为化解悲伤的手段了,它之所以管用,正是因为它是一项需要投入精力的工作。如果我只盯着最终的结果,这个疗愈的过程就会大打折扣。
其他几个可笑的理由
这篇小文的长度已经远远超出了我的预期,毕竟它最初只是我想发在 Bluesky 上的几段简短牢骚。在结束之前,再快速补充几个理由。
首先,我极度反感 AI 聊天机器人默认的那种油腔滑调的语气。作为一个在美国东海岸城市长大的人,当一个我不认识的人突然对我表现得热情过头、客气得有些诡异时,我就会本能地警觉起来,因为这通常意味着他们要么准备骗我的钱,要么准备向我传教。读 LLM 的聊天记录会让我起鸡皮疙瘩。是的,我知道我可以通过设定让 LLM 换一种语气,但不知为何,这只会让整个事儿感觉更糟。
和许多开发者一样,我也存了整整一个文件夹的草稿,里面全是那些永远没填完坑的业余项目。比如,我曾经打算用 Clojurescript 写一个拼字游戏的克隆版,因为这样我就可以利用 Blabrecs 里的代码生成一堆根本不存在的假词,故意把游戏搞得让人抓狂。好吧,我承认这可能只是我个人的恶趣味,你得设身处地才能 get 到笑点。从 LLM 的角度来看,这些都是装满失败的文件夹,我确实可以用 LLM 来搞个“一天做一个 App”之类的挑战。然而,过程远比结果重要。不是每一个突发奇想的脑洞都必须变成现实产品,通常情况下,我从头脑风暴的乐趣中,以及为了证明“我没必要把这玩意做完”而学习新知识的过程中,获得的收获要多得多。
我原本不打算在这篇文章里讨论在工作中使用 LLM 的道德问题。不是因为我不在乎,而是因为已经有太多比我聪明的人,极其深刻地论述过这项技术所带来的令人忧虑的隐患。在当下这个 LLM 正在向带有儿童的学校发送炸弹威胁,或者按需生成儿童色情内容的时代,我真的不放心使用它们。如果我连提都不提这方面,我心里也会过意不去。在资本主义的框架下,也许确实不存在绝对道德的消费,但就算见鬼,我也至少要努力去尝试一下。我们不可能用一种让如此多的人陷入悲惨境地的工具,来建设一个更美好的世界。
说来也怪,似乎没有谁比这帮 LLM 的吹鼓手们活得更苦大仇深了。如果开发者们利用他们新获得的“生产力暴涨”,终于过上了 10 年前这帮极客们假装膜拜的每周工作 4 小时的乌托邦生活,我可能还真会被打动。但病态的是,硅谷的许多人似乎把工作外包给了 AI 智能体之后,反而利用节省下来的业余时间去接了更多的工作。他们没有把时间用来休息、搞艺术或享受生活,而是拥抱了 996 工作制,以及一个高度量化的工作环境,这甚至会让以极度压榨著称的科学管理学派祖师爷弗雷德里克·泰勒看了都直冒冷汗。也许 LLM 革命最终会席卷我和我的饭碗,但在那之前,我可不想先把自己卷进坟墓里。
未来路在何方?
我不会假装自己能预知未来。也许这项技术真的会发展到不可思议的地步,以至于我会后悔当初没有积累足够的经验去熟悉它。又或者,它也许会陷入停滞,整个建立在炒作之上的金融纸牌屋轰然倒塌。如果那一天真的到来,我希望我们能把软件开发重新建设成一种充满人性关怀的实践。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み