記憶するエージェント:Agent Memoryの紹介
CloudflareはAIエージェントのコンテキスト劣化問題を解決する「Agent Memory」プライベートベータを公開し、検索ベースのマネージドメモリサービスを提供開始した。
キーポイント
コンテキスト窓肥大の限界とcontext rot
100万トークン超のコンテキスト窓でも情報劣化(context rot)が発生し、品質低下や重要情報の喪失リスクが実務上の課題となっている。
既存アーキテクチャの比較と設計方針
自己ホスティングや生データベースアクセス型に対し、Cloudflareは抽出・検索パイプラインを統合したマネージドサービスと意図的(opinionated)なAPIを採用し、コストと推論精度を最適化した。
長期エージェントへの適用と機能
数週間〜数月間稼働するエージェント向けに、関連情報の取得・不要情報の忘却を自動化し、時間的論理や命令追従などの複雑な推論タスクに対応可能にした。
設計の背景と要件
長期稼働するエージェントには、メモリが成長しても有用性を保ちつつ、高速な取り込みと会話ブロックしない検索、そして低コストでの実行が求められる。
操作と統合方法
プロファイル単位で「ingest(一括処理)」「remember(明示的保存)」「recall(検索と合成)」などの操作を提供し、Cloudflare WorkerのバインディングまたはREST API経由で統合可能。
アーキテクチャ互換性
多様なエージェントアーキテクチャに対応し、Cloudflare Agents SDKのSessions APIにおけるコンパクションや検索の実装例として組み込み可能。
コンパクション時の知識保持
従来のエージェントがコンテキスト制限や劣化を避けるために情報を破棄するのに対し、Agent Memoryはコンパクション時に知識を保持し、将来の検索に備える。
影響分析・編集コメントを表示
影響分析
Cloudflareの登場は、エージェント開発におけるメモリ管理の標準化を加速させる。特に「コンテキスト窓肥大=解決」ではないという認識を広め、検索ベースのメモリアーキテクチャを実践レベルで普及させるきっかけとなる。開発者は複雑なストレーストラテジーの実装コストを削減でき、エージェントの長期安定運用と推論精度の向上が期待できる。
編集コメント
製品発表ではあるが、コンテキスト窓の限界と「context rot」の実態を明確に指摘しており、エージェント開発の設計思想に重要な示唆を与える。マネージドメモリサービスが標準化されれば、開発者は推論ロジックに集中できる分、エコシステムの成熟が早まる可能性が高い。
Workers AIによるローカルモデル推論。抽出、分類、合成のパイプライン全体は、Cloudflareネットワーク上にデプロイされたWorkers AIモデルで実行されます。すべてのAI呼び出しは、メモリプロファイル名に基づいてルーティングされるセッションアフィニティヘッダーを通過するため、繰り返しのリクエストはプロンプトキャッシングの恩恵を受けるために同じバックエンドに到達します。
モデル選択から得られた興味深い知見の一つは、より大きく強力なモデルが常に優れているわけではないということです。現在、抽出、検証、分類、クエリ分析にはLlama 4 Scout(17B、16-expert MoE)、合成にはNemotron 3(120B MoE、12Bアクティブパラメータ)をデフォルトで使用しています。Scoutは構造化された分類タスクを効率的に処理し、一方でNemotronのより高度な推論能力は自然な
原文を表示
As developers build increasingly sophisticated agents on Cloudflare, one of the biggest challenges they face is getting the right information into context at the right time. The quality of results produced by models is directly tied to the quality of context they operate with, but even as context window sizes grow past one million (1M) tokens, context rot remains an unsolved problem. A natural tension emerges between two bad options: keep everything in context and watch quality degrade, or aggressively prune and risk losing information the agent needs later.
Today we're announcing the private beta of Agent Memory, a managed service that extracts information from agent conversations and makes it available when it’s needed, without filling up the context window.
It gives AI agents persistent memory, allowing them to recall what matters, forget what doesn't, and get smarter over time. In this post, we’ll explain how it works — and what it can help you build.
The state of agentic memory
Agentic memory is one of the fastest-moving spaces in AI infrastructure, with new open-source libraries, managed services, and research prototypes launching on a near-weekly basis. These offerings vary widely in what they store, how they retrieve, and what kinds of agents they're designed for. Benchmarks like LongMemEval, LoCoMo, and BEAM provide useful apples-to-apples comparisons, but they also make it easy to build systems that overfit for a specific evaluation and break down in production.
Existing offerings also differ in architecture. Some are managed services that handle extraction and retrieval in the background, others are self-hosted frameworks where you run the memory pipeline yourself. Some expose constrained, purpose-built APIs that keep memory logic out of the agent's main context; others give the model raw access to a database or filesystem and let it design its own queries, burning tokens on storage and retrieval strategy instead of the actual task. Some try to fit everything into the context window, partitioning across multiple agents if needed, while others use retrieval to surface only what's relevant.
Agent Memory is a managed service with an opinionated API and retrieval-based architecture. We've carefully considered the alternatives, and we believe this combination is the right default for most production workloads. Tighter ingestion and retrieval pipelines are superior to giving agents raw filesystem access. In addition to improved cost and performance, they provide a better foundation for complex reasoning tasks required in production, like temporal logic, supersession, and instruction following. We'll likely expose data for programmatic querying down the road, but we expect that to be useful for edge cases, not common cases.
We built Agent Memory because the workloads we see on our platform exposed gaps that existing approaches don't fully address. Agents running for weeks or months against real codebases and production systems need memory that stays useful as it grows — not just memory that performs well on a clean benchmark dataset that may fit entirely into a newer model's context window.
They need fast ingestion. They need retrieval that doesn't block the conversation. And they need to run on models that keep the per-query cost reasonable.
How you use it
Agent Memory stores memories in a profile, which is addressed by name. A profile gives you several operations: ingest a conversation, remember something specific, recall what you need, list memories, or forget a specific memory. Ingest is the bulk path that is typically called when the harness compacts context. Remember is for the model to store something important on the spot. Recall runs the full retrieval pipeline and returns a synthesized answer.
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// Get a profile -- an isolated memory store shared across sessions, agents, and users
const profile = await env.MEMORY.getProfile("my-project");
// Ingest -- extract memories from a conversation (typically called at compaction)
await profile.ingest([
{ role: "user", content: "Set up the project with React and TypeScript." },
{ role: "assistant", content: "Done. Scaffolded a React + TS project targeting Workers." },
{ role: "user", content: "Use pnpm, not npm. And dark mode by default." },
{ role: "assistant", content: "Got it -- pnpm and dark mode as default." },
], { sessionId: "session-001" });
// Remember -- store a single memory explicitly (direct tool use by the model)
const memory = await profile.remember({
content: "API rate limit was increased to 10,000 req/s per zone after the April 10 incident.",
sessionId: "session-001",
});
// Recall -- retrieve memories and get a synthesized answer
const results = await profile.recall("What package manager does the user prefer?");
console.log(results.result); // "The user prefers pnpm over npm."
return Response.json({ ok: true });
},
};
Agent Memory is accessed via a binding from any Cloudflare Worker. It can also be accessed via a REST API for agents running outside of Workers, following the same pattern as other Cloudflare developer platform APIs. If you’re building with the Cloudflare Agents SDK, the Agent Memory service integrates neatly as the reference implementation for handling compaction, remembering, and searching over memories in the memory portion of the Sessions API.
What you can build with it
Agent Memory is designed to work across a range of agent architectures:
Memory for individual agents. Regardless of whether you're building with coding agents like Claude Code or OpenCode with a human in the loop, using self-hosted agent frameworks like OpenClaw or Hermes to act on your behalf, or wiring up managed services like Anthropic’s Managed Agents, Agent Memory can serve as the persistent memory layer without any changes to the agent's core loop.
Memory for custom agent harnesses. Many teams are building their own agent infrastructure, including background agents that run autonomously without a human in the loop. Ramp Inspect is one public example; Stripe and Spotify have described similar systems. These harnesses can also benefit from giving their agents memory that persists across sessions and survives restarts.
Shared memory across agents, people, and tools. A memory profile doesn't have to belong to a single agent. A team of engineers can share a memory profile so that knowledge learned by one person's coding agent is available to everyone: coding conventions, architectural decisions, tribal knowledge that currently lives in people's heads or gets lost when context is pruned. A code review bot and a coding agent can share memory so that review feedback shapes future code generation. The knowledge your agents accumulate stops being ephemeral and starts becoming a durable team asset.
While search is a component of memory, agent search and agent memory solve distinct problems. AI Search is our primitive for finding results across unstructured and structured files; Agent Memory is for context recall. The data in Agent Memory doesn't exist as files; it's derived from sessions. An agent can use both, and they are designed to work together.
Your memories are yours
As agents become more capable and more deeply embedded in business processes, the memory they accumulate becomes genuinely valuable — not just as an operational state, but as institutional knowledge that took real work to build. We're hearing growing concern from customers about what it means to tie that asset to a single vendor, which is reasonable. The more an agent learns, the higher the switching cost if that memory can't move with it.
Agent Memory is a managed service, but your data is yours. Every memory is exportable, and we're committed to making sure the knowledge your agents accumulate on Cloudflare can leave with you if your needs change. We think the right way to earn long-term trust is to make leaving easy and to keep building something good enough that you don't want to.
How Agent Memory works
To understand what happens behind the API shown above, it helps to break down how agents manage context. An agent has three components:
A harness that drives repeated calls to a model, facilitates tool calls, and manages state.
A model that takes context and returns completions.
State that includes both the current context window and additional information outside context: conversation history, files, databases, memory.
The critical moment in an agent’s context lifecycle is compaction, when the harness decides to shorten context to stay within a model's limits or to avoid context rot. Today, most agents discard information permanently. Agent Memory preserves knowledge on compaction instead of losing it.
Agent Memory integrates into this lifecycle in two ways:
Bulk ingestion at compaction. When the harness compacts context, it ships the conversation to Agent Memory for ingestion. Ingestion extracts facts, events, instructions, and tasks from the message history, deduplicates them against existing memories, and stores them as memories for future retrieval.
Direct tool use by the model. The model gets tools to interact directly with memories, including the ability to recall (search memories for specific information). The model can also remember (explicitly store memories based on something important), forget (mark a memory as no longer important or true), and list (see what memories are stored). These are lightweight operations that don't require the model to design queries or manage storage. The primary agent should never burn context on storage strategy. The tool surface it sees is deliberately constrained so that memory stays out of the way of the actual task.
The ingestion pipeline
When a conversation arrives for ingestion, it passes through a multi-stage pipeline that extracts, verifies, classifies, and stores memories.
 image
image
The first step is deterministic ID generation. Each message gets a content-addressed ID — a SHA-256 hash of session ID, role, and content, truncated to 128 bits. If the same conversation is ingested twice, every message resolves to the same ID, making re-ingestion idempotent.
Next, the extractor runs two passes in parallel. A full pass chunks messages at roughly 10K characters with two-message overlap and processes up to four chunks concurrently. Each chunk gets a structured transcript with role labels, relative dates resolved to absolutes ("yesterday" becomes "2026-04-14"), and line indices for source provenance. For longer conversations (9+ messages), a detail pass runs alongside the full pass, using overlapping windows that focus specifically on extracting concrete values like names, prices, version numbers, and entity attributes that broad extraction tends to miss. The two result sets are then merged.
The next step is to verify each extracted memory against the source transcript. The verifier runs eight checks covering entity identity, object identity, location context, temporal accuracy, organizational context, completeness, relational context, and whether inferred facts are actually supported by the conversation. Each item is passed, corrected, or dropped accordingly.
The pipeline then classifies each verified memory into one of four types.
Facts represent what is true right now, atomic, stable knowledge like "the project uses GraphQL" or "the user prefers dark mode."
Events capture what happened at a specific time, like a deployment or a decision.
Instructions describe how to do something, such as procedures, workflows, runbooks.
Tasks track what is being worked on right now and are ephemeral by design.
Facts and instructions are keyed. Each gets a normalized topic key, and when a new memory has the same key as an existing one, the old memory is superseded rather than deleted. This creates a version chain with a forward pointer from the old memory to the new memory. Tasks are excluded from the vector index entirely to keep it lean but remain discoverable via full-text search.
Finally, everything is written to storage using INSERT OR IGNORE so that content-addressed duplicates are silently skipped. After returning a response to the harness, background vectorization runs asynchronously. The embedding text prepends the 3-5 search queries generated during classification to the memory content itself, bridging the gap between how memories are written (declaratively: "user prefers dark mode") and how they're searched (interrogatively: "what theme does the user want?"). Vectors for superseded memories are deleted in parallel with new upserts.
The retrieval pipeline
When an agent searches for a memory, the query goes through a separate retrieval pipeline. During development, we discovered that no single retrieval method works best for all queries, so we run several methods in parallel and fuse the results.
 image
image
The first stage runs query analysis and embedding concurrently. The query analyzer produces ranked topic keys, full-text search terms with synonyms, and a HyDE (Hypothetical Document Embedding), a declarative statement phrased as if it were the answer to the question. This stage embeds the raw query directly, and both embeddings are used downstream.
In the next stage, five retrieval channels run in parallel. Full-text search with Porter stemming handles keyword precision for queries where you know the exact term but not the surrounding context. Exact fact-key lookup returns results where the query maps directly to a known topic key. Raw message search queries the stored conversation messages directly via full-text search for unclassified conversation fragments that act as a safety net, catching verbatim details that the extraction pipeline may have generalized away. Direct vector search finds semantically similar memories using the embedded query. And HyDE vector search finds memories that are similar to what the answer would look like, which often surfaces results that direct embedding misses — particularly for abstract or multi-hop queries where the question and the answer use different vocabulary.
In the third and final stage, results from all five retrieval channels are merged using Reciprocal Rank Fusion (RRF), where each result receives a weighted score based on where it ranked within a given channel. Fact-key matches get the highest weight because an exact topic match is the strongest signal. Full-text search, HyDE vectors, and direct vectors are each weighted based on strength of signal. Finally, raw message matches are also included with low weight as a safety net to identify candidate results the extraction pipeline may have missed. Ties are broken by recency, with newer results ranked higher.
The pipeline then passes the top candidates to the synthesis model, which generates a natural-language answer to the original search query. Some specific query types get special treatment. As an example, temporal computation is handled deterministically via regex and arithmetic, not by the LLM. The results are injected into the synthesis prompt as pre-computed facts. Models are unreliable at things like date math, so we don't ask them to do it.
How we built it
Our initial prototype of Agent Memory was lightweight, with a basic extraction pipeline, vector storage, and simple retrieval. It worked well enough to demonstrate the concept, but not well enough to ship.
So we put it into an agent-driven loop and iterated. The cycle looked like this: run benchmarks, analyze where we had gaps, propose solutions, have a human review the proposals to select strategies that generalize rather than overfit, let the agent make the changes, repeat.
This worked well, but came with one specific challenge. LLMs are stochastic, even with temperature set to zero. This caused results to vary across runs, which meant we had to average multiple runs (time-consuming for large benchmarks) and rely on trend analysis alongside raw scores to understand what was actually working. Along the way we had to guard carefully against overfitting the benchmarks in ways that didn't genuinely make the product better for the general case.
Over time, this got us to a place where benchmark scores improved consistently with each iteration and we had a generalized architecture that would work in the real world. We intentionally tested against multiple benchmarks (including LoCoMo, LongMemEval, and BEAM) to push the system in different ways.
 image
image
Why Cloudflare
We build Cloudflare on Cloudflare, and Agent Memory is no different. Existing primitives that are powerful and easily composable allowed us to ship the first prototype in a weekend and a fully functioning, productionized internal version of Agent Memory in less than a month. In addition to speed of delivery, Cloudflare turned out to be the ideal place to build this kind of service for a few other reasons.
 image
image
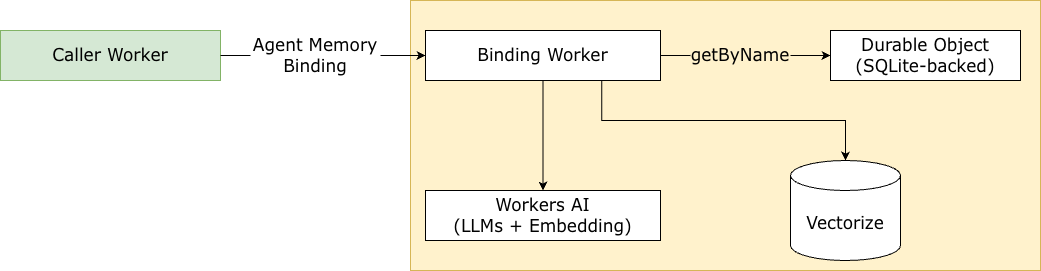
Under the hood, Agent Memory is a Cloudflare Worker that coordinates several systems:
Durable Object: stores the raw messages and classified memories
Vectorize: provides vector search over embedded memories
Workers AI: runs the LLMs and embedding models
Each memory context maps to its own Durable Object instance and Vectorize index, keeping data fully isolated between contexts. It also allows us to scale easily with higher demands.
Compute isolation via Durable Objects. Each memory profile gets its own Durable Object (DO) with a SQLite-backed store, providing strong isolation between tenants without any infrastructure overhead. The DO handles FTS indexing, supersession chains, and transactional writes. DO’s getByName() addressing means any request, from anywhere, can reach the right memory profile by name, and ensures that sensitive memories are strongly isolated from other tenants.
Storage across the stack. Memory content lives in SQLite-backed DOs. Vectors live in Vectorize. In the future, snapshots and exports will go to R2 for cost-efficient long-term storage. Each primitive is purpose-built for its workload, we don't need to force everything into a single shape or database.
Local model inference with Workers AI. The entire extraction, classification, and synthesis pipeline runs on Workers AI models deployed on Cloudflare's network. All AI calls pass a session affinity header routed to the memory profile name, so repeated requests hit the same backend for prompt caching benefits.
One interesting finding from our model selection: a bigger, more powerful model isn't always better. We currently default to Llama 4 Scout (17B, 16-expert MoE) for extraction, verification, classification, and query analysis, and Nemotron 3 (120B MoE, 12B active parameters) for synthesis. Scout handles the structured classification tasks efficiently, while Nemotron's larger reasoning capacity improves the quality of natural-l
関連記事
技術意思決定者の動機と AI 戦略の現実
ミッチェル・ハシモットは、技術意思決定者(TDM)の9割が解雇を避けることを最優先し、ガートナーなどの分析や世論に依存して「AI 戦略」を採用すると指摘した。彼らは週末に GitHub を操作する層ではなく、定時で帰宅する実務家である。
エージェントビルダーのメモリ構築方法:エージェントへの記憶機能の実装
Agent Builderチームは、エージェントの能力を向上させるためのメモリシステムを開発した。本記事では、その設計動機、技術的実装の詳細、得られた教訓、および今後の展望について解説している。
TiDB Cloudにおけるオートスケールの実現
DBREチームは2025年11月、TiDB全クラスタの水平オートスケールを導入し、CPU利用率60%で安定稼働している。