エージェントとアプリケーションの間の欠落したリンク
LangChain は、エージェントがサーバー側ではなくクライアント側のブラウザやアプリの状態、デバイス機能に直接アクセスできる「ヘッドレスツール」を導入し、実世界での操作能力とプライバシーを大幅に向上させた。
キーポイント
サーバー中心のアーキテクチャの限界
従来のエージェントはサーバー上で動作するため、ブラウザ固有の API や同期されていないフロントエンドの状態、ローカルメモリへの直接アクセスが不可能で、実用的な操作に課題があった。
クライアント側実行による能力拡張
LangChain の新機能により、エージェントはジオロケーション、クリップボード、ローカルメモリ、およびアプリ固有のアクションを第一級ツールとして直接呼び出せるようになった。
プライバシーとデータフローの改善
機密データをサーバーに送信する必要がなくなるため、デバイス上で処理が可能となり、ユーザーのプライバシー保護とデータの安全性が高まる。
影響分析・編集コメントを表示
影響分析
このアプローチは、AI エージェントが単なる情報処理から実際のアプリケーション操作へと進化するための決定的なステップとなる。特に Figma や Google スライドのようなリッチなクライアントアプリとの連携において、サーバーを介さない直接的な制御を実現することで、開発者の実装負担を減らしつつ、ユーザー体験に直結する高度な自動化を可能にする。
編集コメント
従来のサーバー中心のアプローチの限界を打破し、エージェントが『現場』で実際に動くための基盤を整えた重要な技術的転換点です。プライバシー保護と実用性の両立を図るこの手法は、次世代の AI アプリ開発において標準的なパターンになり得るでしょう。
*TL;DR: 多くのエージェントツールはサーバー上で動作するため、エージェントは API を呼び出すことはできますが、ユーザーが実際に作業を行うブラウザ、アプリの状態、またはデバイスの機能とは直接対話できません。LangChain のヘッドレスツールを用いることで、地理情報、クリップボードへのアクセス、ローカルメモリ、アプリ内アクションといったクライアントサイドの機能をファーストクラスのツールとしてエージェントに呼び出させることが可能になり、このギャップを埋めることができます。これにより、エージェントはより有用で、プライバシー保護にも優れ、実際のアプリケーション動作とも整合性が取れたものになります。*
今日のエージェントはますます能力が高まっていますが、ユーザーが関心を持つ多くの機能はサーバー上ではなく、クライアントランタイム内に存在します。ブラウザやアプリケーションは、ローカル状態、ユーザーの選択結果、デバイス API、バックエンドシステムでは利用できないアプリ固有のアクションなどを管理しています。その結果、エージェントは次に何が起こるべきかを推論することはできても、ユーザーが実際に作業を行っている環境に対して行動を起こすことには依然として苦労します。
このギャップが生じる理由の一つは、多くのエージェントツールがサーバー上で実行されている点にあります。モデルがツールの使用を決定すると、エージェントはそのツールをプロセス内で実行するか、MCP サーバーなどの外部サービスに委任し、その結果を推論ループに戻してフィードバックします。これは API、データベース、バックエンドシステムにとってはよく機能しますが、明確な限界があります:
- ブラウザ固有またはデバイス固有の API に直接アクセスすることはできません。
- サーバーに同期されたことのないフロントエンドの状態に対して行動を起こすことはできません。
- 頻繁にプライバシーに関わるデータをデバイスから外部へ持ち出させることになります。
- 本質的にローカルなアクションに対して、不必要な往復通信を導入してしまいます。
ブラウザは、多くの高価値なエージェントのアクションが実際に発生する場所です:ローカルアプリケーションの状態を読み取り、現在の UI に基づいて行動し、データをバックエンドに送信することなくデバイス機能を利用します。デスクトップアプリもまた、ローカルファイル、ネイティブ統合、セッション固有の状態を通じて同じパターンを露出しています。もしあなたのエージェントがこのランタイムに到達できないなら、バックエンドワークフローでは優れていても、ユーザーが実際に体験するインタラクションにおいては弱くなります。
Figma、Google スライド、あるいはリッチテキストエディタ向けのサイドカー型エージェント(sidecar agent)を構築していることを想像してください。エージェントはサーバー上でユーザーの要求について推論できますが、ドキュメントモデル、選択状態、編集コマンドはすべてクライアント側に存在します。サーバー側のツールでは、カーソル位置へのテキスト挿入、選択されたオブジェクトの書式変更、アクティブなスライドへのジャンプを行うことができません。なぜならそれらのアクションはアプリケーションランタイムに属するものであり、バックエンド API には属さないからです。現在、チームはこのギャップを、クライアントの状態の一部をシリアライズしてサーバーへ送り、レスポンスを受け取ってからクライアントを命令的にパッチする、場当たり的な UI ブリッジ(UI bridge)で埋め合わせています。これは機能しますが、脆く、組み合わせが難しく、モデルの推論ループからは見えない存在です。
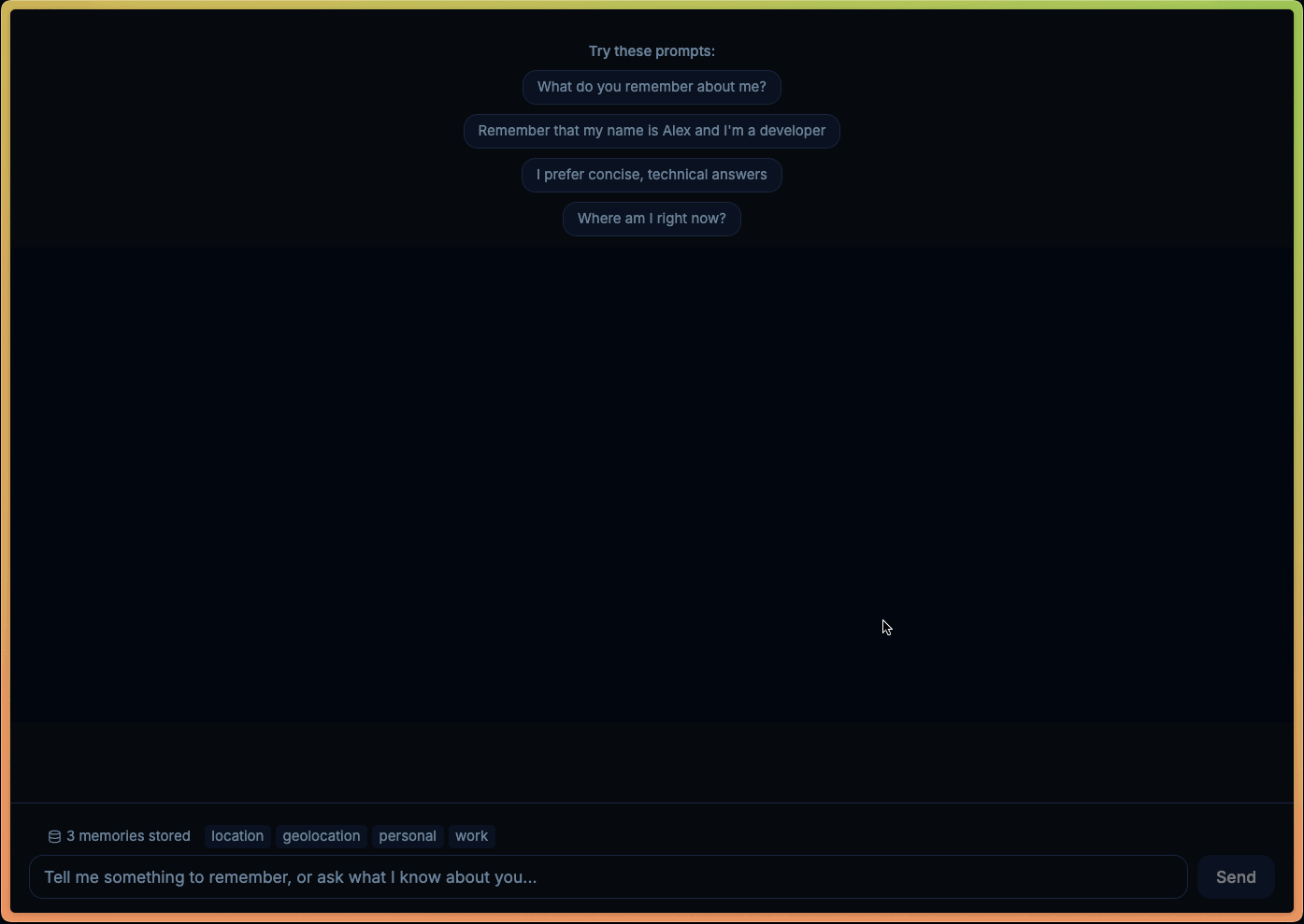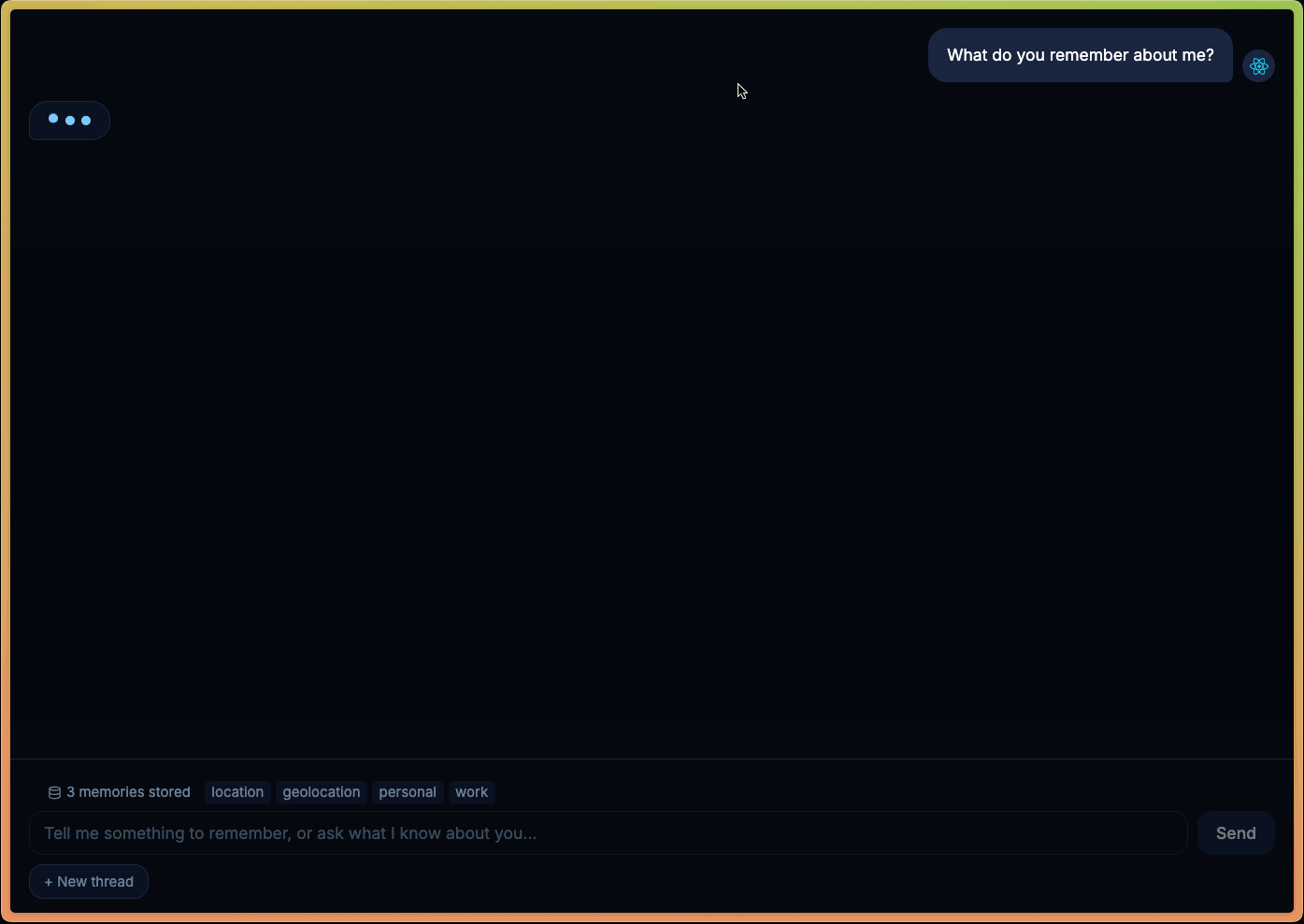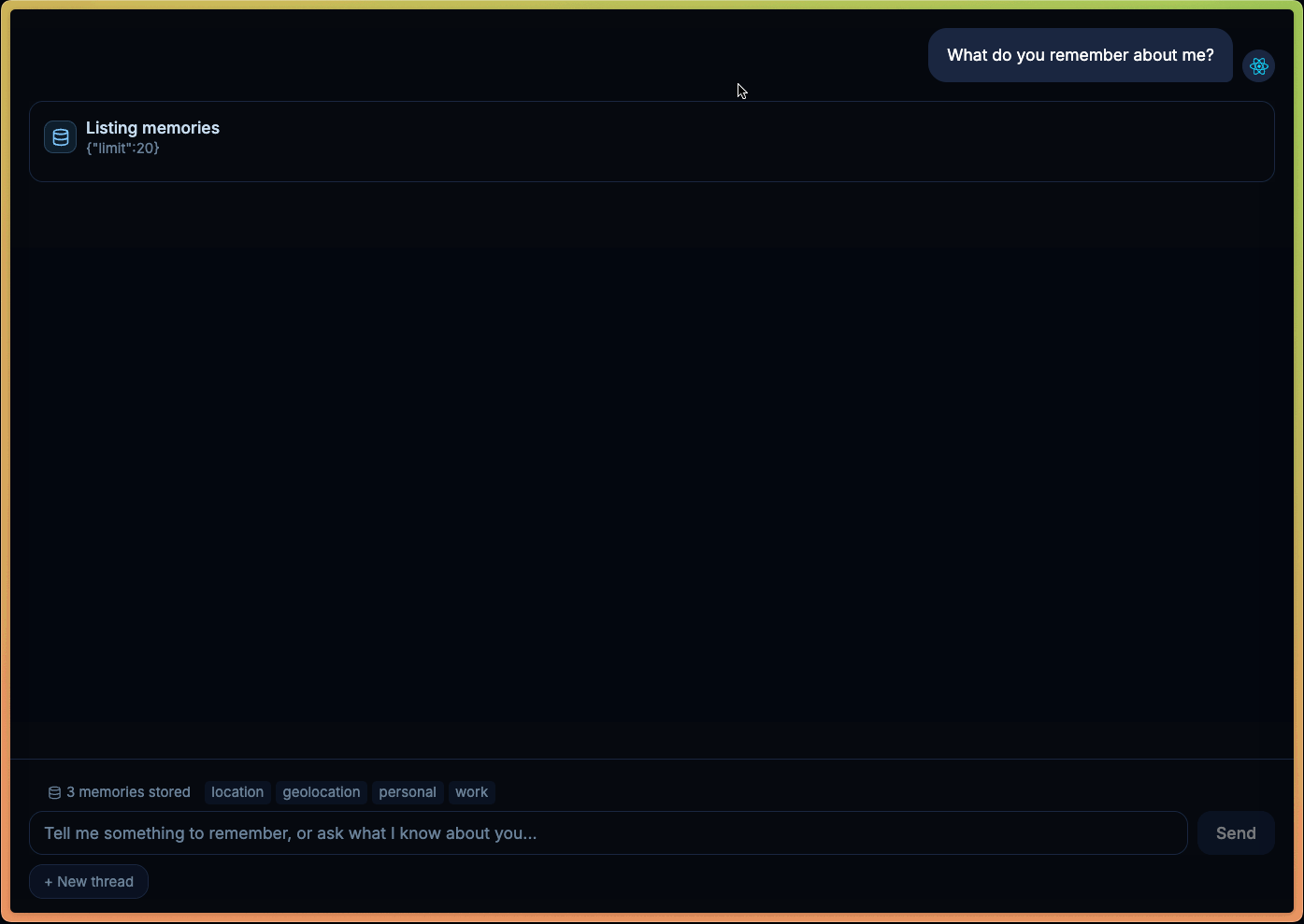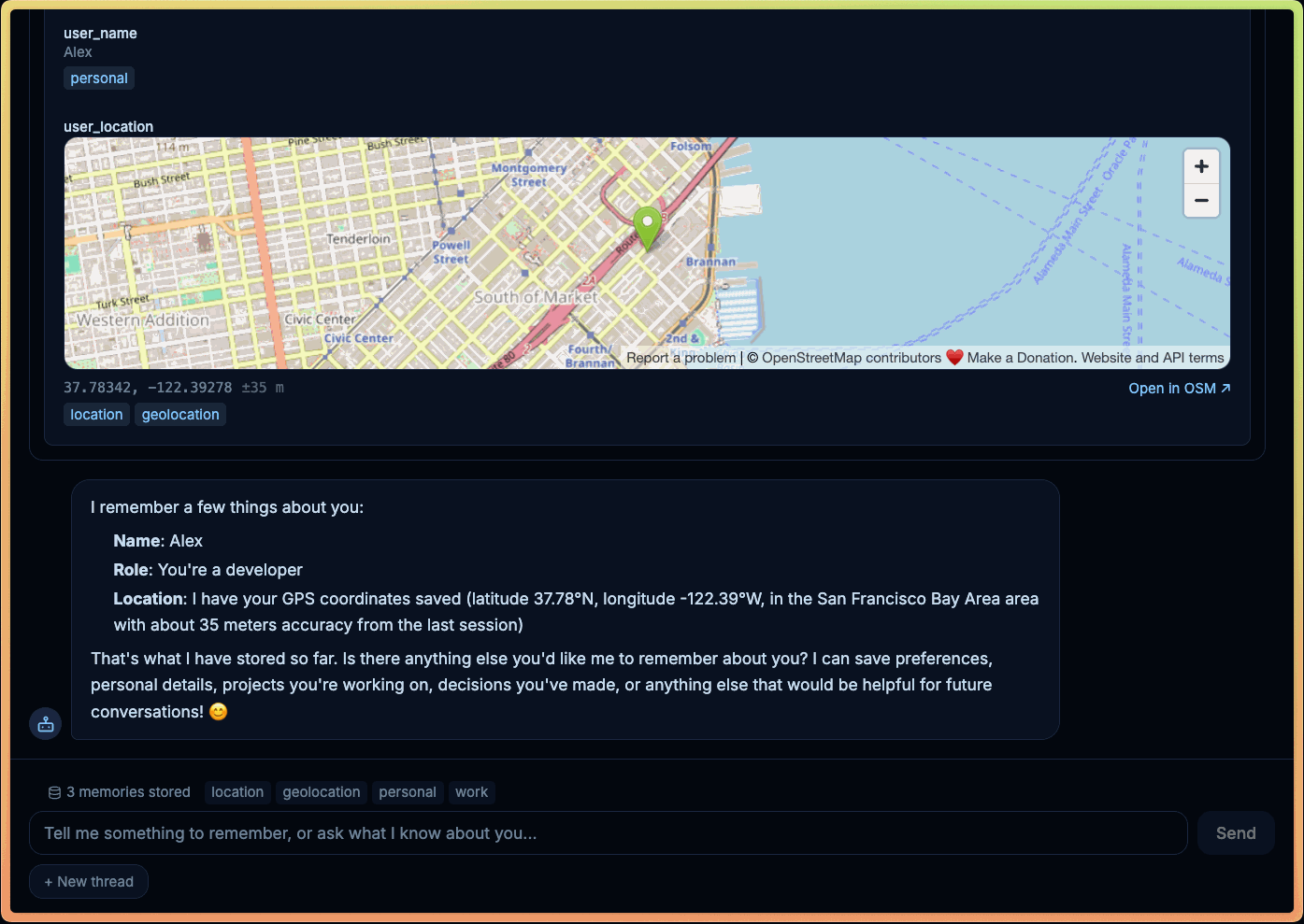
*エージェントが、ユーザーのブラウザから直接メモリや地理位置情報 API にアクセスできるようにしましょう。*
これが LangChain における ヘッドレスツール が解決する課題です。
ヘッドレスツールが変えるもの
モデルにとって、ヘッドレスツールは他のツールと何ら変わらない外観をしています:名前、説明、そして期待される入力セットを持ちます。モデルは他のどのツールと同様に、いつ呼び出すかを決定します。違いは、その後の処理にあります。
サーバー自体がツールを実行するのではなく、ツール呼び出しをクライアント(ユーザーのブラウザ、デスクトップアプリ、あるいは実際にその機能を持つ環境)に送信します。クライアントはローカルでツールを実行し、結果を戻り値として返し、エージェントはその続きから処理を進めます。

これは一見すると小さな実装の詳細に思えるかもしれませんが、実際にはエージェントが確実に制御できるシステムの種類そのものを変えます。
モデルはツールがどこで実行されるかを知らなくても構いません。ツールを見て使用を決定し、結果を受け取るだけです。裏側ではサーバーとクライアントが連携しています:サーバーはエージェントが*何を*したいかを知っており、クライアントは*どのように*行うかを知っています。この分離こそが核心となる考え方です。
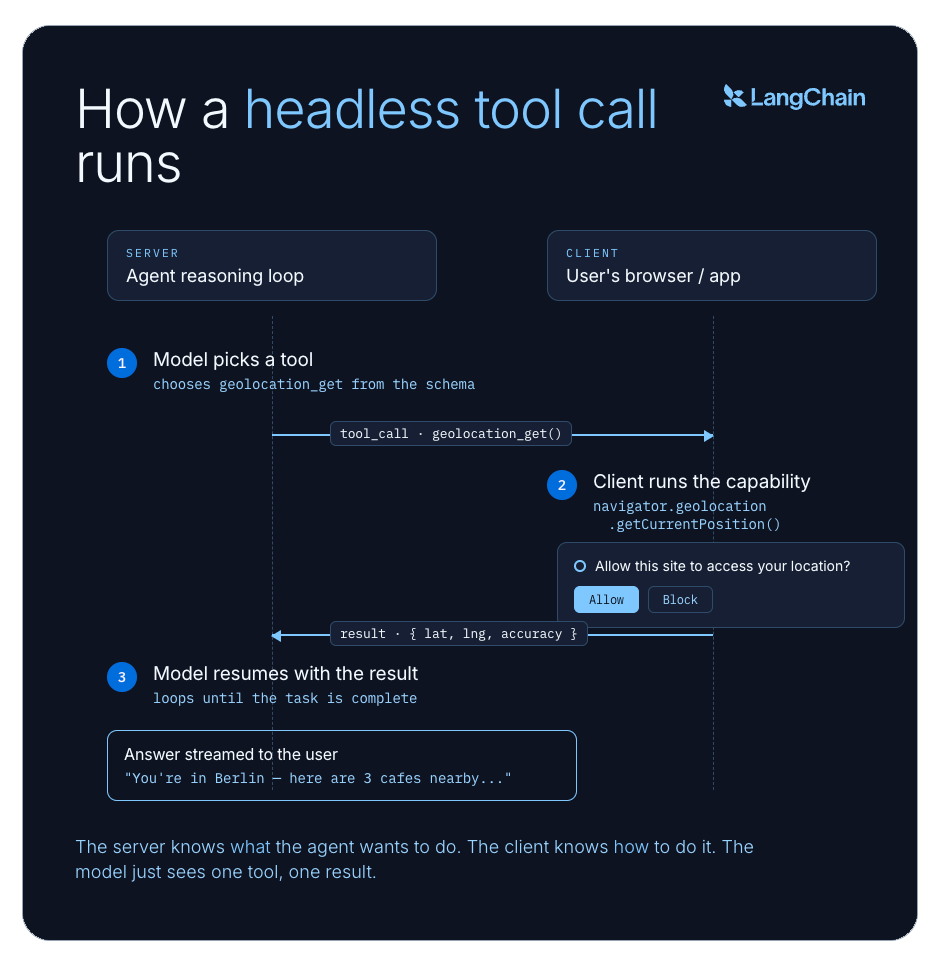
これを手動で接続し、React アプリから navigator.geolocation.getCurrentPosition() を呼び出して結果をエージェントに送ることもできます。しかし、その場合、モデルにはその機能の発見やいつそれを呼び出すかを決定する方法がありません。それは推論ループの外側、アドホックなサイドチャネルとして存在することになります。ヘッドレスツールは、クライアント側のアクションを推論ループの横ではなく、ループ内部に組み込みます。
なぜこれが重要なのか
その利点は単なる「ブラウザへのアクセス」だけではありません。スライドデッキの作成を手伝うエージェントを想像してみてください。アクティブなスライドへジャンプし、ローカルコンテキストを読み取り、セッション全体をバックエンドに転送することなく、その場でプレゼンテーションを更新できるはずです。ヘッドレスツールは、クライアント側の機能をエージェントループ内の実際のツールとして公開することで、そのようなインタラクションを可能にします。
一部の操作は、バックエンドで正しくエミュレートすることは不可能です。地理位置情報は明白な例であり、ブラウザが権限プロンプトとデバイス信号を管理しています。クリップボードへのアクセス、キャンバス描画、ファイルピッカー、ライブ UI ナビゲーションはすべて、アクティブなクライアント環境に依存します。標準的なツールはバックエンドサービスを通じてこれらの機能を近似することができますが、ヘッドレスツールは実際の機能そのものを呼び出すことができます。

しかし、ヘッドレスツールはブラウザ API のためのものだけではありません。これは、エージェントにアプリケーションネイティブなアクションへの安全なアクセスを与える一般的なメカニズムです。例えば:人気のある Slidev 発表フレームワーク用のプラグインである slidev-agent は、ヘッドレスツールを使用して、ユーザーのアクティブなプレゼンテーション内の特定のスライドへ移動します。これはデータ取得の問題でもサーバー自動化の問題でもありません。
このパターンはプライバシーのトレードオフも変化させます。エージェントのメモリが常に集中型バックエンドにある必要はありません。IndexedDB などのブラウザストレージに支えられたヘッドレスツールを使用すれば、デフォルトでメモリをローカルに保つことができます。これは永続性があり、低レイテンシであり、そのユーザーとブラウザに自然にスコープされたものであり、リコールをサーバーサイドのデータ管理の問題に変えることなく実現できます。
コード内での動作方法
TypeScript では、定義と実装の分離が特に明確です。ツールは一度定義し、.implement(...) で実装をアタッチし、その実装を frontend streaming hook に渡します。サーバーとクライアントは同じスキーマを共有しますが、ブラウザ固有の実行ロジックを読み込むのはクライアントのみです。
// tools.ts
import { tool } from "langchain";
export const geolocationGet = tool({
name: "geolocation_get",
description: "Get the user's current location from the browser.",
schema: z.object({}),
});
// App.tsx
import { useStream } from '@langchain/react';
// shared tools definition
import { geolocationGet as geolocationGetDefinition } from './tools';
export function App() {
const stream = useStream({
// ...
tools: [
// actual tool implementation on the client side
geolocationGetDefinition.implement(async () => {
const position = await new Promise<GeolocationPosition>((resolve, reject)
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return {
latitude: position.coords.latitude,
longitude: position.coords.longitude,
accuracy: position.coords.accuracy,
};
}),
],
});
return <div> ... </div>;
}
LangChain のドキュメントにあるライブデモ LangChain docs をチェックしてください。ここでは、ブラウザローカルのメモリと地理情報機能、そして任意の人間の承認を組み合わせています。
Summary
標準的なツールはエージェントにバックエンドシステムへのアクセス権を与えました。ヘッドレスツール(headless tools)は、ユーザーが実際に作業を行う場所へのアクセスを可能にします。
ユーザーはあなたのバックエンドに住んでいるわけではありません。彼らはブラウザ、アプリ、デバイスの中に住んでおり、そこで最も価値のあるエージェントとのインタラクションの多くが発生しています。ヘッドレスツールは、型付きスキーマ(typed schemas)、明示的な機能(explicit capabilities)、構造化された出力(structured outputs)、そしてレビュー可能性を維持しながら、それらのインタラクションを利用可能にします。これにより、エージェントはサーバーにとって便利なだけでなく、ユーザーにとってネイティブなツールを使用できるようになります。
ヘッドレスツールは、LangChain Python または LangChain JS で始められます。
@huntlovell、@colifran_、そして @sydneyrunkle には、思慮深いレビューとフィードバックをいただき、感謝申し上げます。
原文を表示
*TL;DR: Most agent tools run on the server, which means agents can call APIs but not interact with the browser, app state, or device capabilities where users actually work. With headless tools in LangChain we close this gap by letting agents invoke client-side capabilities like geolocation, clipboard access, local memory, and in-app actions as first-class tools. That makes agents more useful, more private, and better aligned with real application behavior.*
Today's agents are increasingly capable, but many of the capabilities users care about live in the client runtime rather than on the server. Browsers and applications own things like local state, user selections, device APIs, and application-specific actions that are often unavailable through backend systems. As a result, agents can reason about what should happen next but still struggle to act on the environment where the user is actually working.
One reason for this gap is that most agent tools execute on the server. When a model decides to use a tool, the agent runs it in-process or delegates it to an external service such as an MCP server, then feeds the result back into the reasoning loop. This works well for APIs, databases, and backend systems, but it has clear limitations:
- It cannot directly access browser-only or device-only APIs.
- It cannot act on frontend state that has never been synchronized to the server.
- It often forces privacy-sensitive data to leave the device.
- It introduces unnecessary round trips for actions that are inherently local.
The browser is where many high-value agent actions actually happen: reading local application state, acting on the current UI, and using device capabilities without shipping that data to a backend first. Desktop apps expose the same pattern through local files, native integrations, and session-specific state. If your agent cannot reach that runtime, it stays good at backend workflows but weak at the interactions users actually experience.
Imagine you are building a sidecar agent for Figma, Google Slides, or a rich-text editor. The agent can reason about the user's request on the server, but the document model, selection state, and editing commands all live in the client. A server-side tool cannot insert text at the cursor, reformat the selected object, or jump to the active slide, because those actions belong to the application runtime, not the backend API. Today, teams usually bridge this with an ad-hoc UI bridge: serialize some client state to the server, get a response back, then imperatively patch the client. It works, but it is fragile, hard to compose, and invisible to the model's reasoning loop.
That is the problem headless tools solve in LangChain.
What headless tools change
A headless tool looks like any other tool to the model: it has a name, a description, and a set of expected inputs. The model decides when to call it, just like any other tool. The difference is what happens next.
Instead of the server running the tool itself, it sends the tool call to the client: the user's browser, desktop app, or whatever environment actually has the capability. The client runs the tool locally and sends the result back, and the agent picks up where it left off.
While this sounds like a small implementation detail at first, it actually changes what kinds of systems an agent can reliably control.
The model never needs to know where the tool runs. It sees a tool, decides to use it, and gets a result. But behind the scenes, the server and the client are coordinating: the server knows *what* the agent wants to do, and the client knows *how* to do it. That separation is the core idea.
You could wire this up manually, call navigator.geolocation.getCurrentPosition() from your React app and send the result to the agent. But then the model has no way to discover or decide when to invoke that capability. It lives outside the reasoning loop as an ad-hoc side channel. Headless tools put client-side actions inside the agent's reasoning loop, not alongside it.
Why this matters
The benefit is not just "browser access." Imagine an agent helping you work through a slide deck: it should be able to jump to the active slide, read local context, and update the presentation in place without shipping the whole session to a backend. Headless tools make that kind of interaction possible by exposing client-side capabilities as real tools inside the agent loop.
Some operations are impossible to emulate correctly on the backend. Geolocation is the obvious example — the browser owns permission prompts and device signals. Clipboard access, canvas rendering, file pickers, and live UI navigation all depend on the active client environment. A standard tool can approximate these through a backend service. A headless tool can call the real thing.
But headless tools are not just for browser APIs. They are a general mechanism for giving agents safe access to application-native actions. For example: slidev-agent , a plugin for the popular Slidev presentation framework, uses a headless tool to navigate to a specific slide in the user's active presentation. This is not a data retrieval problem or a server automation problem.
This pattern also changes privacy tradeoffs. Agent memory does not always belong in a centralized backend. With a headless tool backed by a browser storage like IndexedDB, memory can stay local by default — durable, low-latency, and naturally scoped to that user and browser — without turning recall into a server-side data management problem.
How it works in code
In TypeScript, the separation between definition and implementation is especially clean. You define the tool once, attach the implementation with .implement(...), and pass the implementation into the frontend streaming hook. The server and client share the same schema, but only the client loads the browser-specific execution logic.
// tools.ts
import { tool } from "langchain";
export const geolocationGet = tool({
name: "geolocation_get",
description: "Get the user's current location from the browser.",
schema: z.object({}),
});
// App.tsx
import { useStream } from '@langchain/react';
// shared tools definition
import { geolocationGet as geolocationGetDefinition } from './tools';
export function App() {
const stream = useStream({
// ...
tools: [
// actual tool implementation on the client side
geolocationGetDefinition.implement(async () => {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return {
latitude: position.coords.latitude,
longitude: position.coords.longitude,
accuracy: position.coords.accuracy,
};
}),
],
});
return ... ;
}
Check out a live demo in our LangChain docs, combining browser-local memory with geolocation and optional human approval.
Summary
Standard tools gave agents access to backend systems. Headless tools give them access to where users actually work.
Users do not live on your backend. They live in browsers, apps, and devices, where many of the most valuable agent interactions happen. Headless tools make those interactions available while preserving typed schemas, explicit capabilities, structured outputs, and reviewability, allowing agents to use tools that are native to the user, not just convenient for the server.
Get started with headless tools in LangChain Python or LangChain JS.
Thanks to @huntlovell, @colifran_, and @sydneyrunkle for their thoughtful review and feedback.
関連記事
ループエンジニアリングの芸術
LangChain は、信頼性の高いエージェントを実現するには優れたモデルだけでなく、特定のタスク向けに設計された慎重なハネスが必要だと説明し、コア・エージェント・ループやスタッキング手法について解説している。
LangSmith のノーコードエージェントビルダーの紹介
LangChain が提供する LangSmith に、プログラミング不要で AI エージェントを構築できる新機能が導入された。
エージェント性は十分か?独自ツールを用いたオープンモデルのベンチマーク調査
Hugging Face が、独自に構築したツール環境において、オープンソースモデルがどれほど「エージェント性」を発揮できるかを評価するベンチマーク手法を発表しました。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み