[AINews] NVIDIA Cosmos 3、Nemotron 3 Ultra、RTX Spark の発表
NVIDIA は今日、言語・画像・動画・音声・行動を統合する「Cosmos 3」および米国オープンモデル新記録の「Nemotron 3 Ultra」を発表し、物理的 AI のためのオープンエコシステム構築を加速させた。
キーポイント
Cosmos 3 のアーキテクチャと機能
言語、画像、動画、音声、行動の 5 つのモダリティを統合した「Mixture-of-Transformers」アーキテクチャを採用し、自己回帰推論器と拡散生成器を組み合わせた世界モデルとして登場。
Nemotron 3 Ultra の性能突破
550B パラメータ(アクティブ 55B)を持つオープンウェイト LLM が発表され、米国におけるオープンソースモデルの SOTA を更新し、効率性と速度で高い評価を得た。
ハードウェアとエコシステムの統合
1 petaflop の「RTX Spark」スーパーチップを Microsoft や OpenClaw と連携して発表し、Cosmos 3 の学習・推論を支える物理的 AI エコシステム(Cosmos Coalition)を構築。
オープンソースと SOTA 達成
Weights、コード、データセット、ファインチューニングレシピをすべて公開し、テキストから画像・動画への生成において既存のオープンモデルを上回る性能(SOTA)を記録。
Nemotron 3 Ultra の高速性とアーキテクチャ特性
コミュニティから高い評価を受け、推論速度が 300 トークン/秒を超える可能性があり、Kimi や DeepSeek と比較してスパース性が低く(約 10% 対 3%)、コストと動作に違いをもたらす。
MiniMax M3 のマルチモーダルエージェントとしての強みと課題
SWE-Bench Pro で 59.0% を達成しフロントエンド生成に優れる一方、トークン消費量が多く冗長な自己チェックループが発生する傾向があり、「効率より品質優先」のモデルと評価されている。
JetBrains Mellum2 の開発者ワークフロー向け最適化
12B モデルで低遅延推論を目的とし、ルーティングや RAG、IDE 内でのサブエージェント利用など、ベンチマーク争いではなく実用的な開発ワークフローに特化した「小さく高速なオープンモデル」として位置づけられている。
重要な引用
unifying language, image, video, audio and action in a Mixture-of-Transformers architecture
new US SoTA: remarkably efficient/fast open weights LLM
Cosmos 3 reached #1 among open-weight models on both their Text-to-Image and Image-to-Video leaderboards
Nemotron appears less sparse than peers like Kimi K2 / DeepSeek V4—roughly ~10% active vs ~3%
M3 look more like a 'quality first, efficiency later' model
「RAG + manual context injection」has been misnamed as memory, while actual persistent session knowledge remains underserved
影響分析・編集コメントを表示
影響分析
この記事は、NVIDIA が単なるハードウェアベンダーから、物理的 AI のための完全スタック・プラットフォームプロバイダーへと進化していることを示す画期的な出来事である。特に「推論」と「生成」を統合したアーキテクチャとオープンウェイトモデルの高性能化は、ロボティクスやシミュレーション分野における開発コストの劇的な低下とイノベーション加速を約束しており、業界全体の方向性を決定づける重大な転換点となる。
編集コメント
NVIDIA が「物理的 AI」の実現に向けて、ハードウェアからソフトウェア、そしてオープンソースエコシステムまでを一貫して支配する戦略を明確に打ち出しました。特に推論と生成を統合したモデルは、ロボット制御やシミュレーション分野における開発の壁を大きく取り払う可能性があります。
今日のポッドキャストのゲストは、1 年以上前に NVIDIA Cosmos の責任者であり、ビデオ生成と世界モデルのトレーニングについて議論していました。ふさわしくも、Cosmos 3 は本日ローンチされ、言語、画像、動画、音声、アクションを統合し、自己回帰型推論器と拡散生成器を組み合わせた Mixture-of-Transformers(混合トランスフォーマー)アーキテクチャを採用しています:
base Nano (16B: 8B 推論塔 + 8B 生成塔)
Super (64B: 32B 推論塔 + 32B 生成塔) モデル、および
Text2Image(テキストから画像へ)と Image2Video(画像から動画へ)用の Super 微調整モデル。これらは現在、Nano Banana 2 に次ぐ、新しい SOTA(State-of-the-Art:最先端)オープンウェイトの画像生成・動画生成モデルとなっています。
台湾で開催された Computex で、Jensen はまた Nemotron 3 Ultra も発表しました。これは 550B-A55B の構成を持つ、驚くほど効率的かつ高速なオープンウェイト LLM(大規模言語モデル)であり、米国における新しい SOTA です:
最後に、RTX Spark 個人用コンピュータは 1 petaflop(ペタフロップス)のスーパーチップとして、Microsoft と OpenClaw、そして Hermes Agent をローンチパートナーとしてプレビューされました(詳細な分析はこちら)。
2026 年 5 月 30 日〜6 月 1 日の AI ニュース。私たちは 12 のサブレッド、544 のツイートを確認し、Discord は追加で確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space の一部となっています。メールの頻度を選択的にオン/オフに設定可能です!
AI Twitter リキャップ
NVIDIA の Cosmos 3、Nemotron 3 Ultra、そしてオープン物理 AI への推進
NVIDIA のオープンソース週間:NVIDIA は、物理 AI 向けのオムニモーダル・ワールドモデルのオープンなファミリーである Cosmos 3 と、550B パラメータを持つオープンウェイトモデル「Nemotron 3 Ultra」を発表し、オープンモデルに関する議論を主導しました。この Nemotron 3 Ultra は、複数の投稿者によって「これまでの米国製オープンモデルの中で最強」と評されました。Cosmos 3 は、重み(weights)、コード、データセット、ファインチューニングのレシピを含むフルスタックリリースとして位置づけられ、NVIDIA はまた Runway などのパートナーと共に Cosmos コアリションを立ち上げ、ワールドモデルのためのオープンエコシステム構築を進めています @NVIDIAAI エコシステム文脈、@runwayml コアリション発表、@kimmonismus の Cosmos スレッド、@ClementDelangue が NVIDIA の Hugging Face (HF) フットプリントについて言及。
Cosmos 3 が技術的に重要だった理由:ロボティクスに関する修辞を超え、より具体的な詳細として、Cosmos 3 は言語、画像、動画、音声、アクションを単一の Mixture-of-Transformers(トランスフォーマーの混合設計)で統合し、自己回帰型推論器と拡散生成器を組み合わせたアーキテクチャを採用しています。Artificial Analysis によると、Cosmos 3 はオープンウェイトモデルの中で Text-to-Image(テキストから画像への変換)および Image-to-Video(画像から動画への変換)のリーダーボードでともに第1位を獲得しました。また、この生成器は構造化された JSON プロンプトを使用し、外部のプロンプアップサンプリングハーンチス(harness)によって駆動されるか、あるいは自身の推論器ブランチによって制御されることが可能であると指摘されています。一方、NVIDIA のハードウェアとソフトウェアの推進は、OpenMDW フレームワークの採用や、fal などのプラットフォームにおけるパートナーエコシステムとの統合にも及んでいます @ArtificialAnlys、@fal。
Nemotron 3 Ultra の反応:Nemotron 3 Ultra に対するコミュニティの反応は、新しいオープンリリースとしては異例に強かった。投稿者たちは、その能力と提供特性の両方を強調し、すでにいくつかのオープン評価で首位を争っているという主張や、一部の環境では 1 秒あたり 300 トークン以上の速度で動作している可能性を示唆する内容が含まれていた。これは @scaling01, @ctnzr, @caspar_br が指摘するように、大規模な DeepSeek や Kimi クラスのモデルよりもはるかに高速である。また、@eliebakouch による技術的な議論では、Nemotron は Kimi K2 や DeepSeek V4 などの競合他社と比較してスパース性(疎性)が低く、アクティブなパラメータ比率が約 10% 対約 3% である可能性があり、これが経済性と動作特性の両方に影響を与える可能性があることが示された。
MiniMax M3、Qwen3.7-Plus、JetBrains Mellum2 がオープンエージェントモデル分野を拡大
MiniMax M3 の発表が当日最大のモデルリリースとなった。M3 は 100 万トークンのコンテキスト長とネイティブなマルチモーダル性を備え、競争力のあるエージェントベンチマークを持つオープンウェイトのマルチモーダルエージェント/コーディングモデルとして紹介された。発表パートナー間で繰り返し強調された主要数値は、SWE-Bench Pro で 59.0%、Terminal Bench 2.1 で 66.0%、MCP Atlas で 74.2% である @MiniMax_AI, @PBDTokenRouter, @kimmonismus。Novita、Vercel AI Gateway、Cloudflare AI Gateway、OpenClaude、Flowith など複数のインフラベンダーが当日のサポートを提供しており、これは @MiniMax_AI on Novita, @rauchg, @gitlawb が示すように、異例の速さでエコシステムが採用されたことを示唆している。
ベンチマークと実務経験の結果は混在していました:M3 はフロントエンド生成、視覚・ゲームタスク、価格対性能において称賛され、並列デモではワンショットの UI/ゲーム出力が強く、Next.js エージェント評価におけるベンチマークでの好成績も目立ちました(@notjazii, @lostinlatencyX, @rauchg)。しかし、複数の評価者からはトークン消費量の多さ、冗長な自己チェックループ、長時間タスクにおける要件の逸脱が報告され、M3 は「品質を最優先し、効率化は後回し」というモデルのように映りました(@ZhihuFrontier のレビュー、@teortaxesTex の懐疑)。
Qwen3.7-Plus:アリババは Qwen3.7-Plus を、GUI と CLI 操作、視覚推論、コーディング、検索強化 QA を統合したマルチモーダルインタラクティブハイブリッドエージェントとして発表しました。これはアリババクラウドの Model Studio を経由して API で利用可能となり、Cline などのツールに迅速に追加されました(@Alibaba_Qwen の発表、@cline)。この発表は、オープン志向のアジア系ラボがもはや「チャットモデルのみ」をリリースするのではなく、エージェント機能を備えたフルスケールのマルチモーダルシステムを公開しているという傾向を強化するものです。
JetBrains Mellum2:JetBrains は、約 11T トークンでトレーニングされ、RLVR(強化学習による検証・調整)でポストトレーニングされた、アクティブパラメータが 25 億の 120 億 MoE モデルである Mellum2 をリリースしました。ベースモデル/SFT/RL チェックポイントと技術レポートを公開しており、@nv_pavlichenko と @jetbrains が発表しています。特に興味深いのはその狙いであり、ルーティング、RAG(検索拡張生成)、サブエージェント、IDE 利用における超低遅延推論です。また、vLLM に即座に実装され、@vllm_project で利用可能です。これはベンチマーク追従の最先端リリースというよりは、開発者ワークフロー向けの「小型高速オープンモデル」として真剣に取り組んだ取り組みに見えます。
エージェント、サンドボックス、メモリ、検索が真のプロダクト表面へと進化中
スタックはモデル呼び出しからエージェントランタイムへシフトしています:複数の発表で共通しているのは、主要なエンジニアリングのレバレッジがモデルそのものではなく、それを支えるハッチ(枠組み)にあるという点です。Perplexity の「Search as Code」が最も明確な例です:反復的な検索ツール呼び出しの代わりに、モデルは検索 SDK に対して Python を記述し、カスタムランキングパイプライン、インデックス上のマップ・リデュース、バッチ処理、集約、そしてトークンオーバーヘッドの削減を可能にします。Perplexity はこのアーキテクチャにより、内部 WANDR ベンチマークで 0.152 から 0.386 への飛躍的な向上を報告しています @perplexity_ai, @AravSrinivas。
マネージドエージェントとサンドボックスが標準化されつつある:Google は Gemini API でマネージドエージェントの詳細を公開し、単一の API 呼び出しで推論、コードの記述・実行、ファイル管理を行い、ホストされた Linux サンドボックス内で動作するエージェントを起動できる機能を備えている。これは @_philschmid と @GoogleAIStudio が紹介している。また LangChain は Deep Agents、Context Hub、LangSmith Sandboxes/Engine において同様のアイデアを推進しており、永続的なコンテキスト、エージェントライフサイクルのツール、自動化された障害トリアージに重点を置いている (@LangChain, @hwchase17)。
メモリは依然として欠落したプリミティブである:繰り返し指摘される不満の一つに、巨大なコンテキストウィンドウであってもセッション間での記憶解決にはならないという点がある。HydraDB 上のスレッドでは、「RAG + マニュアルコンテキスト注入」が誤ってメモリと名付けられている一方で、実際の永続的なセッション知識は依然として不十分であると論じられた (@kimmonismus)。関連する研究スレッドでは、AdaCoM のような再利用可能なコンテキスト管理ポリシーが指摘されており、これは凍結されたエージェントのコンテキストを剪定・保持するために別の LLM を RL で訓練するものである (@dair_ai)。
セキュリティはエンタープライズエージェントにおける最大の課題であり続けます:Microsoft Security Intelligence からは、npm/GitHub/AWS/SSH の認証情報を窃取する自己増殖型ワームを含む、90 以上の redhat-cloud-services パッケージに影響を与える大規模な npm サプライチェーン侵害に関する重要な警告が発表されました (@MsftSecIntel)。同時に、エンタープライズエージェントベンダーは、デプロイメントの前提条件としてサンドボックス化、ランタイム分離、セキュリティスタックとの統合を強調しました。これには、NVIDIA OpenShell や LangChain のサンドボックス基調講演に関する議論も含まれており、@shannholmberg、@LangChain が発言しています。
Codex、Claude Code、そして競争的なコーディングエージェントの戦い
OpenAI は Codex をより多くの場所に拡張しました:OpenAI は、最先端モデルと Codex が AWS / Amazon Bedrock で一般利用可能になったことを発表し、既存の AWS セキュリティ/コンプライアンスワークフロー内に OpenAI の機能を組み込みたい企業を明確にターゲットとしています (@OpenAI, @OpenAIDevs)。また、スレッド、ターン、ストリーミング、再開、画像、サンドボックス制御をサポートする Codex Python SDK をリリースしました (@reach_vb)、さらに Bedrock 対応の Codex ワークフローもサポートしています (@reach_vb on Bedrock config)。
Claude Code で実際の運用上のインシデントが発生:Anthropic は、一部の Opus 4.8 セッションで予期せず使用量が枯渇するほど多くの並列サブエージェント/ツール呼び出しが生成されるバグを修正した後、Pro および Max ユーザーに対して 5 時間および週間のレート制限をリセットしました (@ClaudeDevs, follow-up)。これは、コーディングエージェント製品の品質が、単なるモデルの知能 (IQ) だけでなく、オーケストレーションの動作によってますます決定されるようになるという重要な教訓となっています。
コーディングモデル間の振る舞いの違いは依然として重大である:開発者は、ProgramBench や WeirdML などのベンチマークにおいて、GPT、Claude、および他のモデル間に大きな質的差異があると指摘している。Opus は場合によってはスコア最大化よりも探索を優先したり、ベンチマーク固有の癖を示すことがある @OfirPress, @htihle。別の長いスレッドでは、新しい Claude Opus 4.6–4.8 バリアントがコーディング以外の分野で妥当だが架空の概念を捏造する可能性があり、これは通常のハルシネーションではなく、真実性やアライメント(整列)における後退を示唆している @distributionat。
インフラ、ハードウェア、およびローカル AI システム
NVIDIA は PC 市場に参入する:最も議論されたハードウェアの発表は、Grace と Blackwell を基盤とした NVIDIA/Microsoft の「パーソナル AI コンピュータ」である RTX Spark で、最大 128GB の統合メモリと 1 PFLOP FP4(FP4: Floating Point 4-bit)を謳っている。重要な戦略的洞察:NVIDIA はもはやアクセラレータを販売するだけでなく、Apple Silicon、x86 PC、および Qualcomm と同時に競合するエンドツーエンドのローカル AI システムを提供している @kimmonismus, @swyx。
クラスター/ネットワークの更新:データセンター側では、Lambda が NVIDIA Quantum-X InfiniBand Photonics Q3450-LD スイッチを採用する最初の企業となり、大規模な AI クラスターにおけるネットワーク電力と障害を削減するためにコパッケージド光学(Co-packaged Optics: 集積化された光通信技術)を推進している @LambdaAPI。OpenAI もまた、閉ループ冷却システムを採用し、労働力・教育へのコミットメントと連携する予定の 1GW データセンター「Stargate Michigan」を発表した @OpenAINewsroom。
ローカル向けオープンモデルのツールリングは急速に改善しています:MLX-VLM v0.6.0 のリリースは、より実質的なローカル推論・ツールリングのアップデートの一つであり、予測的デコーディング(speculative decoding)、Anthropic 型およびレスポンス型の API、ツール呼び出し機能、多数の新規マルチモーダルモデルへの対応、画像・音声機能のサポートを追加し、Apple デバイスを「真のローカルエージェントマシン」へと変えることを明確な狙いとして掲げています @Prince_Canuma。これは、ローカル向け NVFP4 モデル(MoE)推論サービスにおける DGX Spark と vLLM の実験動向の高まりとよく調和しています @vllm_project。
主要ツイート(エンゲージメント順・技術的関連性でフィルタリング)
Anthropic の IPO への道筋:Anthropic は、SEC に対して機密扱いの S-1 ドラフトを提出したと発表し、審査待ちながら IPO への扉を開きました @AnthropicAI。
Claude Code の利用インシデント:Opus 4.8 における並列サブエージェント・ツール呼び出しバグによりクォータが過剰に消費されたため、Anthropic はユーザーのレート制限をリセットしました @ClaudeDevs。
Qwen3.7-Plus:アリババは、GUI/CLI 操作、コーディング、視覚タスクを跨ぐマルチモーダルエージェントモデルを発表しました @Alibaba_Qwen。
OpenAI の Bedrock 対応:OpenAI モデルおよび Codex が、エンタープライズワークフロー向けに Amazon Bedrock で利用可能になりました @OpenAI。
ARC-AGI-3 における進展:Claude Opus 4.8 は ARC-AGI-3 ベンチマークで新たな SOTA(最良結果)を記録し、達成率は 1.5% でした。絶対値としては依然として微小ですが、このベンチマーク上では意味のある飛躍です @arcprize。
AI Reddit まとめ
/r/LocalLlama および /r/localLLM まとめ
- 新 Frontier モデルのリリースと初期テスト
MiniMax M3 - コーディングとエージェントの最前線、100 万トークンのコンテキスト、マルチモーダル(活動状況:1090): MiniMax M3 は、コーディングおよびエージェント機能に焦点を当てたオープンウェイトのフロンティアモデルとして発表されました。ネイティブのマルチモーダル性・ビジョン機能を備え、MiniMax Sparse Attention(ミニマックススパースアテンション)により最大 1M トークンのコンテキストをサポートし、最低でも 512K トークンを保証します(MiniMax M3)。主張される長期的なエージェント機能の結果には、ICLR 論文の 12 時間にわたる再現、Hopper FP8 GEMM CUDA/Triton の最適化による 147 回の反復後の 9.4 倍の高速化、PostTrainBench で Opus 4.7 と GPT-5.5 に次ぐ第 3 位へのランクインが含まれます。現在は API/MiniMax Code を通じてアクセス可能ですが、HuggingFace/GitHub でのウェイト公開やローカルデプロイは計画されています。コメント投稿者は、安価で効率的なビジョン機能と長文コンテキストを活用したエージェントコーディングの組み合わせに慎重に関心を示していますが、発表が「オープンウェイト」と呼びながらまだウェイトもパラメータ数すら公開されていない点については懐疑的です。技術的な議論の一つは、これらの結果が約 250B を大幅に超えるモデルを示唆しているのか、極端なベンチマーク最適化の結果なのか、それとも真のオープンウェイトにおける画期的成果なのかという点です。
コメント投稿者の関心は、リリース詳細の欠如に集中していました。「3 つのフロンティア機能を備えた最初のオープンウェイトモデル」という主張にもかかわらず、ユーザーは MiniMax M3 の実際のウェイト、パラメータ数、またはサイズ情報を見つけることができませんでした。ある投稿者は発表からプレビュー画像(Reddit 画像)へのリンクを貼りましたが、スレッド内では依然としてモデルの規模やダウンロード可能なアーティファクトの確認はありませんでした。
技術的な実質的な懸念として、宣伝されている能力レベルは以下の3つの可能性のいずれかを示唆しているという点がありました:予想よりはるかに大きなモデル、異常に強いベンチマーク最適化、あるいは主要なオープンウェイトブレイクスルーです。議論の中心は、MiniMax M3 が実際には約 250B パラメータ程度なのか、それともさらに大幅に大きいのかが不明確である点と、そのコード生成・エージェント機能・マルチモーダルに関する主張が、重み(weights)と独立したベンチマークデータが利用可能になった際に実際に成立するかどうかという点でした。
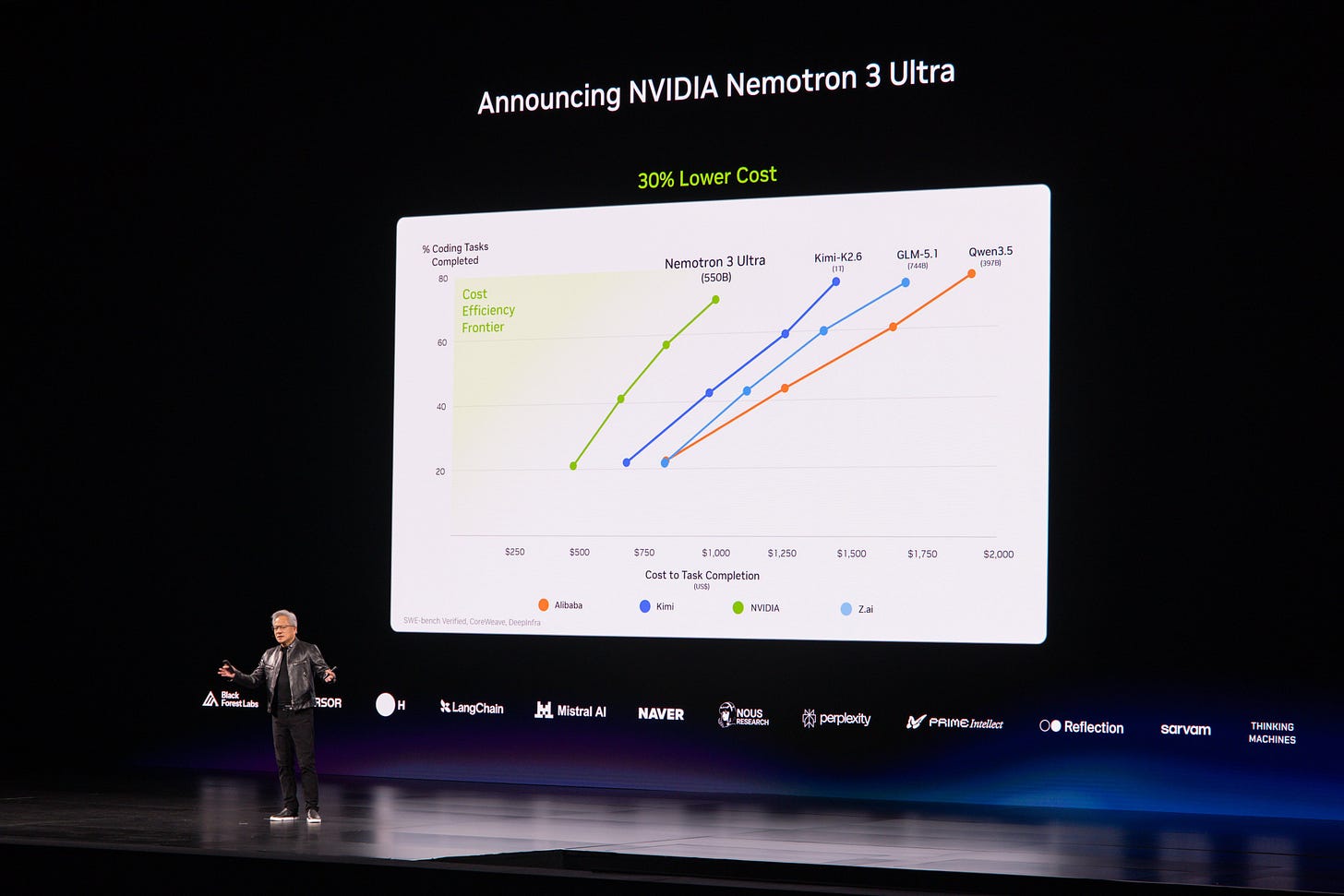
NVIDIA は Nemotron 3 Ultra の発表を行いました(活動数:621)。この画像は NVIDIA Nemotron 3 Ultra に関する技術発表のスライドで、コメントでは MoE(Mixture of Experts)550B-A55 モデルと説明されています。このスライドは、「フロントティアスマート」ベンチマークカテゴリーであるエージェント生産性、コーディング、指示従順性、知識作業、長文コンテキスト処理能力などにおいて、GLM 5.1、Kimi K2.6、Qwen3.5 を含むオープン/オープンウェイト競合他社製品と比較されています。コメント投稿者たちは、他のオープンソース/オープンウェイトモデルとの比較を肯定的に捉えていましたが、ある投稿者は「人工的な分析スコア」が 48 であると指摘し、これはフロントティアモデルの直下であり MiniMax 2.7 の範囲に近いと評価しました。その上で、これが米国製のオープンウェイトモデルの中で最強となる可能性があると期待されています。
NVIDIA Nemotron 3 Ultra は MoE(Mixture of Experts)550B-A55 モデルとして特定されており、これは約 550B の総パラメータ数と、トークンあたり約 55B のアクティブパラメータ数を意味します。このアーキテクチャの詳細は、スレッド内で言及された最も具体的な技術仕様です。
あるコメント投稿者は、Artificial Analysis のスコア 48 を引用し、Nemotron 3 Ultra を「フロンティア級のモデルより一つ下位」と位置づけ、MiniMax 2.7 とほぼ同程度の水準にあると指摘しつつ、この指標においては米国製のオープンウェイトモデルの中で最も強力なものである可能性を示唆しています。
共有された技術的参照資料には、GitHub 上の NVIDIA 公式の Nemotron 3 Ultra Base 使用クックブック(NVIDIA-NeMo/Nemotron)および LifeArchitect のモデル比較表(lifearchitect.ai/models-table)が含まれます。あるコメント投稿者は、Qwen3.5 との比較が注目すべき点であると主張しており、その理由は Nemotron が NVIDIA のベストなオープンウェイトモデルであるにもかかわらず、米国製やオープンソース以外のいくつかのモデルにはまだ及ばないという点にあると述べています。
Stepfun 3.7 Flash は非常に優れています(アクティビティ数:473):この GIF はミームではなく技術的な視覚デモであり、プロンプト「単一の HTML ページで美しくリラックスできるフライトシミュレーターを作成する」に対する Stepfun 3.7 Flash の出力を示しています。低ポリゴンの 3D 飛行シーンに HUD スタイルの速度・高度インジケーターを描画したものです。投稿者はこれが公式の Q4_X_S 量子化版であると主張し、美観においては GLM 5.1 に近く、3D 世界理解能力は同モデルの約 80% に達するが、パラメータ数は GLM 5.1 の約 25% しか使用しておらず、かつ内蔵ビジョン機能も備えていると述べています。コメント投稿者の反応は主に比較や懐古主義に留まり、深いベンチマーク分析には至りませんでした。ある投稿者は昔の Excel フライトシミュレーターを参照し、別の投稿者は Qwen 3.7 Max / 27B への関心について言及し、それが Qwen3.6 27B を上回るかどうかを問うています。
あるコメント投稿者は Qwen 3.7 Max を参照してモデル比較の視点から書き込み、将来の Qwen 3.7 27B のリリースを期待しています。また別の投稿者は、Stepfun 3.7 Flash が Qwen3.6-27B よりも優れているかどうかを尋ねています。このスレッドには Qwen3.6-27B を参照するスクリーンショットの証拠(画像)が含まれていますが、定量的なベンチマークスコアや再現可能な評価の詳細は提供されていません。
続きを読む
原文を表示
Today’s podcast guest was the lead on NVIDIA Cosmos over a year ago, discussing training videogen and world models. Fittingly, Cosmos 3 launched today, unifying language, image, video, audio and action in a Mixture-of-Transformers architecture that pairs an autoregressive reasoner with a diffusion generator in:
base Nano (16B: 8B reasoner tower + 8B generator tower)
Super (64B: 32B reasoner tower + 32B generator tower) models, and
Super finetunes for Text2Image and Image2Video, which are now the new SOTA open weights imagegen and videogen models, just below Nano Banana 2
At Computex in Taiwan, Jensen also brought the heat with Nemotron 3 Ultra, their 550B-A55B, remarkably efficient/fast open weights LLM that is the new US SoTA:
Finally, the RTX Spark personal computer 1 petaflop superchip, was previewed with Microsoft and OpenClaw and Hermes Agent as a launch partner (good analysis here)
AI News for 5/30/2026-6/1/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
NVIDIA’s Cosmos 3, Nemotron 3 Ultra, and the Push for Open Physical AI
NVIDIA’s open-source week: NVIDIA dominated the open-model conversation with Cosmos 3, an open family of omnimodal world models for physical AI, plus the announcement of Nemotron 3 Ultra, a 550B open-weight model that several posters called the strongest U.S. open model so far. Cosmos 3 was framed as a full-stack release—weights, code, datasets, and fine-tuning recipes—with NVIDIA also launching the Cosmos Coalition alongside partners including Runway to build an open ecosystem for world models @NVIDIAAI ecosystem context, @runwayml coalition announcement, @kimmonismus Cosmos thread, @ClementDelangue on NVIDIA’s HF footprint.
Why Cosmos 3 mattered technically: Beyond robotics rhetoric, the more concrete details were that Cosmos 3 unifies language, image, video, audio, and action in a single Mixture-of-Transformers design pairing an autoregressive reasoner with a diffusion generator. Artificial Analysis said Cosmos 3 reached #1 among open-weight models on both their Text-to-Image and Image-to-Video leaderboards, noting the generator uses structured JSON prompts and can be driven either by an external prompt-upsampling harness or its own reasoner branch. Separately, NVIDIA’s hardware + software push extended to adoption of the OpenMDW framework and partner ecosystem integrations on platforms like fal @ArtificialAnlys, @fal.
Nemotron 3 Ultra reception: Community reaction to Nemotron 3 Ultra was unusually strong for a fresh open release. Posters highlighted both capability and serving characteristics, including claims that it is already topping some open evals and may be serving at 300+ tok/s in some setups—far faster than large DeepSeek/Kimi-class models @scaling01, @ctnzr, @caspar_br. There was also some technical discussion that Nemotron appears less sparse than peers like Kimi K2 / DeepSeek V4—roughly ~10% active vs ~3%—which could affect both economics and behavior @eliebakouch.
MiniMax M3, Qwen3.7-Plus, and JetBrains Mellum2 Expand the Open Agent Model Field
MiniMax M3’s launch was the day’s biggest model release: M3 was presented as an open-weight multimodal agent/coding model with 1M context, native multimodality, and competitive agent benchmarks. The headline figures repeated across launch partners were 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, and 74.2% MCP Atlas @MiniMax_AI, @PBDTokenRouter, @kimmonismus. Multiple infra vendors shipped day-0 support—Novita, Vercel AI Gateway, Cloudflare AI Gateway, OpenClaude, Flowith, and others—suggesting unusually fast ecosystem adoption @MiniMax_AI on Novita, @rauchg, @gitlawb.
Benchmarks vs practical experience were mixed: M3 earned praise for frontend generation, visual/game tasks, and price-performance, with side-by-side demos showing strong one-shot UI/game outputs and notable benchmark placement for Next.js agent evals @notjazii, @lostinlatencyX, @rauchg. But several evaluators also reported high token consumption, verbose self-check loops, and occasional requirement drift on long tasks, making M3 look more like a “quality first, efficiency later” model @ZhihuFrontier review, @teortaxesTex skepticism.
Qwen3.7-Plus: Alibaba launched Qwen3.7-Plus as a multimodal interactive hybrid agent that unifies GUI and CLI operation, visual reasoning, coding, and search-augmented QA. It is API-available via Alibaba Cloud Model Studio and was quickly added to tools like Cline @Alibaba_Qwen launch, @cline. The launch reinforces the trend that open-ish Asian labs are no longer releasing “just chat models,” but full agent-capable multimodal systems.
JetBrains Mellum2: JetBrains released Mellum2, a 12B MoE model with 2.5B active parameters, trained on roughly 11T tokens and post-trained with RLVR, shipping base / SFT / RL checkpoints and a technical report @nv_pavlichenko, @jetbrains. The intended niche is especially interesting: ultra-low-latency inference for routing, RAG, sub-agents, and IDE use, and it landed in vLLM immediately @vllm_project. This looks like a serious “small fast open model for developer workflows” play rather than a benchmark-chasing frontier release.
Agents, Sandboxes, Memory, and Search Are Becoming the Real Product Surface
The stack is shifting from model calls to agent runtimes: Several launches converged on the idea that the main engineering leverage is now in the harness rather than the model. Perplexity’s “Search as Code” is the clearest example: instead of iterative search tool calls, the model writes Python against a search SDK, enabling custom ranking pipelines, map-reduce over indexes, batching, aggregation, and lower token overhead. Perplexity reports a jump on its internal WANDR benchmark from 0.152 to 0.386 with this architecture @perplexity_ai, @AravSrinivas.
Managed agents + sandboxes are becoming standard: Google detailed Managed Agents in the Gemini API, where a single API call can spin up an agent that reasons, writes/runs code, manages files, and operates inside a hosted Linux sandbox @_philschmid, @GoogleAIStudio. LangChain pushed similar ideas around Deep Agents, Context Hub, and LangSmith Sandboxes/Engine, emphasizing persistent context, agent lifecycle tooling, and automated failure triage @LangChain, @hwchase17.
Memory remains a missing primitive: One recurring complaint was that enormous context windows still don’t solve cross-session memory. A thread on HydraDB argued that “RAG + manual context injection” has been misnamed as memory, while actual persistent session knowledge remains underserved @kimmonismus. Related research threads pointed to reusable context management policies like AdaCoM, which trains a separate LLM via RL to prune/preserve context for frozen agents @dair_ai.
Security remains the gating issue for enterprise agents: There was a notable warning from Microsoft Security Intelligence about a major npm supply chain compromise affecting 90+ redhat-cloud-services packages, including a self-propagating worm stealing npm/GitHub/AWS/SSH credentials @MsftSecIntel. At the same time, enterprise agent vendors highlighted sandboxing, runtime isolation, and security stack integration as prerequisites for deployment, including discussion of NVIDIA OpenShell and LangChain’s sandbox keynote @shannholmberg, @LangChain.
Codex, Claude Code, and the Competitive Coding-Agent Race
OpenAI extended Codex into more places: OpenAI announced that frontier models and Codex are now generally available on AWS / Amazon Bedrock, aimed squarely at enterprises that want OpenAI capabilities inside existing AWS security/compliance workflows @OpenAI, @OpenAIDevs. OpenAI also shipped a Codex Python SDK supporting threads, turns, streaming, resume, images, and sandbox control @reach_vb, plus support for Bedrock-backed Codex workflows @reach_vb on Bedrock config.
Claude Code had a real ops incident: Anthropic reset 5-hour and weekly rate limits for Pro and Max users after fixing a bug where some Opus 4.8 sessions spawned too many parallel subagents/tool calls, burning usage unexpectedly @ClaudeDevs, follow-up. That’s a notable reminder that coding-agent product quality is increasingly determined by orchestration behavior, not just raw model IQ.
Behavioral differences across coding models remain material: Developers highlighted large qualitative differences between GPT, Claude, and other models on benchmarks like ProgramBench and WeirdML, with Opus sometimes preferring exploration over score-maximization or showing benchmark-specific quirks @OfirPress, @htihle. A separate long thread argued newer Claude Opus 4.6–4.8 variants can fabricate plausible but fictional concepts in non-coding domains, suggesting possible truthfulness/alignment regressions rather than ordinary hallucinations @distributionat.
Infra, Hardware, and Local AI Systems
NVIDIA is coming for the PC: The most-discussed hardware launch was RTX Spark, an NVIDIA/Microsoft “personal AI computer” built around Grace + Blackwell, with up to 128GB unified memory and claimed 1 PFLOP FP4. The key strategic read: NVIDIA is no longer just selling accelerators, but an end-to-end local AI system that competes with Apple Silicon, x86 PCs, and Qualcomm simultaneously @kimmonismus, @swyx.
Cluster/networking updates: On the datacenter side, Lambda said it is first to adopt NVIDIA Quantum-X InfiniBand Photonics Q3450-LD switches, pushing co-packaged optics to reduce network power and failures in large AI clusters @LambdaAPI. OpenAI also announced Stargate Michigan, a planned 1GW data center using closed-loop cooling and paired with workforce/education commitments @OpenAINewsroom.
Local open-model tooling is improving fast: The MLX-VLM v0.6.0 release was one of the more substantive local inference/tooling updates, adding speculative decoding, Anthropic-style and responses-style APIs, tool calls, support for many new multimodal models, and image/audio features with the explicit pitch of turning Apple devices into “real local agent machines” @Prince_Canuma. That pairs well with growing DGX Spark + vLLM experimentation for local NVFP4 MoE serving @vllm_project.
Top Tweets (by engagement, filtered for technical relevance)
Anthropic’s IPO path: Anthropic said it has confidentially submitted a draft S-1 to the SEC, opening the door to an IPO pending review @AnthropicAI.
Claude Code usage incident: Anthropic reset user rate limits after an Opus 4.8 parallel subagent/tool-call bug caused excessive quota burn @ClaudeDevs.
Qwen3.7-Plus: Alibaba launched a multimodal agent model spanning GUI/CLI operation, coding, and visual tasks @Alibaba_Qwen.
OpenAI on Bedrock: OpenAI models and Codex are now available through Amazon Bedrock for enterprise workflows @OpenAI.
ARC-AGI-3 movement: Claude Opus 4.8 posted a new SOTA on ARC-AGI-3 at 1.5%, still tiny in absolute terms but a meaningful jump on that benchmark @arcprize.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- New Frontier Model Releases and Early Tests
MiniMax M3 - Coding & Agentic Frontier, 1M Context, Multimodal (Activity: 1090): MiniMax M3 is announced as an open-weight frontier model with coding/agentic focus, native multimodality/vision, and MiniMax Sparse Attention for up to 1M tokens of context with a guaranteed 512K minimum (MiniMax M3). Claimed long-horizon agentic results include 12-hour ICLR paper reproduction, Hopper FP8 GEMM CUDA/Triton optimization reaching 9.4× speedup after 147 iterations, and PostTrainBench ranking third behind Opus 4.7 and GPT-5.5; access is currently via API/MiniMax Code, with HuggingFace/GitHub weights/local deployment planned. Commenters are cautiously interested in the combination of cheap/efficient vision plus long-context agentic coding, but skeptical because the announcement calls it “open-weight” while not yet exposing weights or even parameter count. One technical debate is whether the results imply a much larger-than-~250B model, extreme benchmark optimization, or a genuine open-weight breakthrough.
Commenters focused on the missing release details: despite the claim of being “the first open-weight model with three frontier capabilities”, users could not find actual weights, parameter count, or sizing information for MiniMax M3. One commenter linked a preview image from the announcement (Reddit image), but the thread still lacked confirmation of model scale or downloadable artifacts.
A technically substantive concern was that the advertised capability level implies one of three possibilities: a much larger-than-expected model, unusually strong benchmark optimization, or a major open-weights breakthrough. The speculation centered on whether MiniMax M3 is actually around ~250B parameters or significantly larger, and whether its coding/agentic/multimodal claims will hold once weights and independent benchmarks are available.
NVIDIA announces Nemotron 3 Ultra (Activity: 621): The image is a technical announcement slide for NVIDIA Nemotron 3 Ultra, described in comments as a MoE 550B-A55 model. The slide positions Nemotron 3 Ultra against open/open-weight competitors including GLM 5.1, Kimi K2.6, and Qwen3.5 across “Frontier Smart” benchmark categories such as agent productivity, coding, instruction following, knowledge work, and long-context capability. Commenters viewed the comparison against other open-source/open-weight models positively, while one noted an “artificial analysis score” of 48, placing it just below frontier-tier models and around the MiniMax 2.7 range, with the expectation that it could be the strongest U.S. open-weight model.
NVIDIA Nemotron 3 Ultra is identified as a MoE 550B-A55 model, implying roughly 550B total parameters with about 55B active parameters per token. This architecture detail is the most concrete technical spec mentioned in the thread.
A commenter cites an Artificial Analysis score of 48, placing Nemotron 3 Ultra “one notch less than frontier” and roughly in the MiniMax 2.7 range, while suggesting it may be the strongest US open-weight model by that metric.
Technical references shared include NVIDIA’s official Nemotron 3 Ultra Base usage cookbook on GitHub: NVIDIA-NeMo/Nemotron, plus the LifeArchitect model comparison table: lifearchitect.ai/models-table. One commenter argues the comparison against Qwen3.5 is notable because Nemotron may be NVIDIA’s best open-weight model while still trailing several non-US/open models.
Stepfun 3.7 Flash is very good (Activity: 473): The GIF is a technical visual demo, not a meme: it shows the output of Stepfun 3.7 Flash for the prompt create a beautiful, relaxing flight simulator in a single html page, rendering a low-poly 3D flight scene with HUD-style speed/altitude indicators. The OP says this was the official Q4_X_S quant and claims the model feels near GLM 5.1 in aesthetics and about 80% of its 3D world understanding, while using only roughly 25% of GLM 5.1’s parameters and including built-in vision. Commenters mostly reacted with comparisons and nostalgia rather than deep benchmarks: one referenced the old Excel flight simulator, while another compared interest in Qwen 3.7 Max / 27B and asked whether it beats Qwen3.6 27B.
A commenter draws a model-comparison angle by referencing Qwen 3.7 Max and hoping for a future Qwen 3.7 27B release, while another asks whether Stepfun 3.7 Flash is better than Qwen3.6-27B. The thread includes screenshot evidence for the Qwen3.6-27B reference (image), but no quantitative benchmark scores or reproducible eval details are provided.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み