Argoワークフロー移行に挑んだ話
サイバーエージェントのインターン生が、大規模バッチ処理におけるバージョン管理の不整合やリトライ機能不足を解消するため、Cloud Workflows から GKE 上の Argo Workflows への移行を実践した事例を紹介している。
キーポイント
Cloud Workflows の課題と背景
広告クリエイティブ生成の AI プロダクトにおいて、:latest イメージ参照によるバージョン不整合や、失敗ステップからのリトライ不可という Cloud Workflows の限界がボトルネックとなっていた。
Argo Workflows への移行戦略
GKE(Google Kubernetes Engine)上に Argo Workflows を構築し、大規模なマルチメディアバッチ処理の基盤として再設計することで、柔軟性と機能性を向上させた。
具体的な実装と成果
BigQuery 上のデータ整形・集計ジョブを Argo の CronWorkflow として移行し、安定した実行環境の構築に成功している。
dbtジョブのアーキテクチャ移行と可視化
BigQuery処理用のdbtジョブをCloud WorkflowsからArgo Workflowへ移行し、WorkflowTemplateとCronWorkflowを組み合わせて再実装しました。これにより、GUI上で各ステップの進捗や成功・失敗状況を視覚的に確認できるようになりました。
Slack通知機能の実装とセキュリティ対策
Exit Hookを活用してワークフロー完了時の自動通知を実現し、Secret ManagerへのアクセスにはWorkload Identityを用いて外部コンポーネントを追加せずシンプルかつ安全に実装しました。
Pythonワークロードの基盤移行
広告クリエイティブ関連のPython処理の一部をArgo Workflowsへ移行するプロジェクトが進行中です。
Terraform の依存関係とリリース順序の重要性
GCP サービスアカウントと Workload Identity のバインディング間には明示的な依存関係があるため、自動解決できない場合は手動で変更順序を設計し、先にリソース作成後にバインディング適用を行う必要がある。
重要な引用
ループの途中で新しいバージョンがデプロイされると、同じワークフローの中で前半と後半で異なるバージョンのコードが動いてしまいます
Cloud Workflows は失敗したステップからのリトライができないなど、ワークフローエンジンとしては機能が限られていました
より柔軟で機能豊富な Argo Workflows への移行を進めることになりました
実装当初はSlack OAuthトークンを手動で設定する方法をとっていましたが、セキュリティと運用の観点から自動取得できる仕組みを検討しました。
最終的には、プロジェクト内の別サービスPythonプロセス内でSecret Managerから直接取得するシステムを採用しました。
インフラの変更はリソース間の依存関係を意識した上でリリース順序を設計することが重要だと学びました
影響分析・編集コメントを表示
影響分析
この記事は、大規模 AI バッチ処理システムにおける運用上の課題(バージョン管理とエラーハンドリング)に対し、Kubernetes ネイティブなワークフローエンジンへの移行という実証済みの解決策を提示しています。特に、開発チームが実際に直面した「異なるバージョンのコードが混在する」リスクを具体例として挙げている点は、現場のエンジニアにとって非常に参考になる実践知です。
編集コメント
インターン生による実践的な技術移行事例として、Cloud Workflows の限界と Argo Workflows の優位性を対比させた構成が非常に説得力があります。大規模バッチ処理を扱うチームにとって、バージョン管理の重要性と基盤刷新のタイミングを知るための良いケーススタディです。
はじめに
こんにちは、University of British Columbia 学部4年の保井祐理です。
2026年4月3日から4月30日の1ヶ月間、CA Tech JOBに参加しました。
私は、バックエンドエンジニアとして極AIの開発チームに配属していただきました。
この記事では、インターンシップ期間中に私が取り組んだことと、その成果についてご紹介します。
背景
極AI開発チームについて
極予測AIというAIを使った広告クリエイティブに関するプロダクトがあります。
開発チームは、マルチメディアを取り扱う大規模なバッチ処理の開発・運用を行なっています。
元々のワークフロー
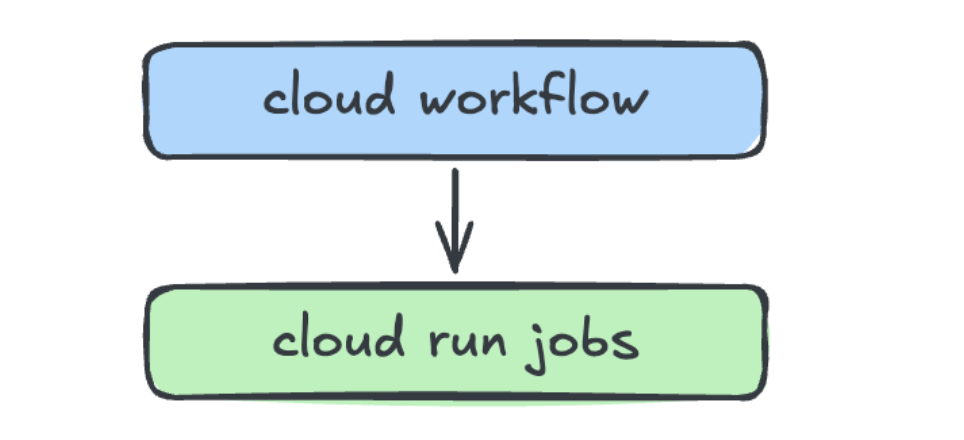
もともと、このパイプラインは以下のようなアーキテクチャでCloud Workflowsを使用して構成されていました。
課題
Cloud Run Jobs を呼び出すたびに、その時点の最新の Docker イメージ(:latest)を取得します。そのため、ループをしながら同じ処理を呼び出したいケースでは、ループの途中で新しいバージョンがデプロイされると、同じワークフローの中で前半と後半で異なるバージョンのコードが動いてしまいます。
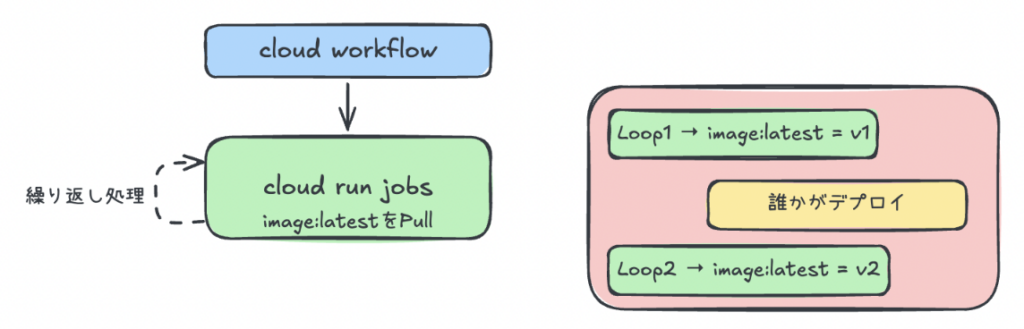
またそれだけでなく、Cloud Workflows は失敗したステップからのリトライができないなど、ワークフローエンジンとしては機能が限られていました。パイプラインが大規模になってきたことで、より柔軟で機能豊富な Argo Workflows への移行を進めることになりました。
GKE(Google Kubernetes Engine)は Google が提供する Kubernetes のマネージドサービスです。Kubernetes とは、複数のコンテナをまとめて管理・実行するためのプラットフォームで、GKE を使うことで Kubernetes クラスターの構築・運用を Google に任せることができます。
Argo Workflows は Kubernetes 上で動作するワークフローエンジンです。各処理をコンテナとして定義し、それらの実行順序や依存関係を管理します。Cloud Workflows と比較して、失敗したステップからのリトライや、GUI(Graphical User Interface:グラフィカルユーザーインターフェース)での実行状況の視覚的な確認など、より豊富な機能を持っています。今回はこの GKE 上に Argo Workflows を構築し、移行先の実行基盤としました。
取り組んだタスクについて
こうした背景から、Cloud Workflows で管理されていたワークフローを Argo Workflows へ移行するというタスクに取り組みました。
1. データ変換・集計を担うジョブを Argo Workflows に移行
最初に担当したのは、Cloud Workflows で管理されていたデータ変換・集計ジョブを Argo Workflows へ移行するタスクです。
システム上で BigQuery 上のデータを整形・集計するための dbt ジョブが複数動いており、それぞれ Cloud Workflows + Cloud Scheduler + Cloud Run Jobs で定期実行されていました。今回の移行では、これらのジョブを Argo の CronWorkflow(cron ワークフロー)として再実装しました。
Argo Workflows では、処理の単位を WorkflowTemplate として定義し、それを組み合わせて CronWorkflow を構成します。今回は dbt のビルドジョブを WorkflowTemplate として切り出し、スケジュール実行の設定を CronWorkflow に記述する形で実装しました。
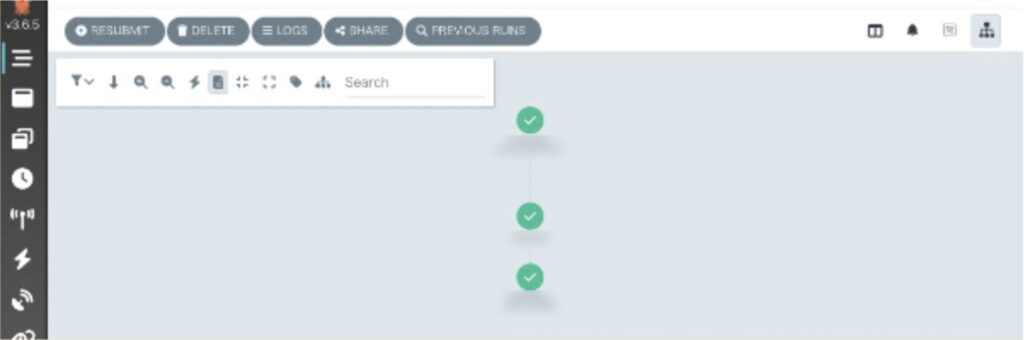
実装後は Argo Workflows の GUI を使って実行状況を確認しました。各ステップが視覚的にノードとして表示され、チェックマークで正常完了していることをひと目で確認できます。
このタスクを通じて、WorkflowTemplate(ワークフローテンプレート)や CronWorkflow といった Argo の基本的な構成要素を一通り実務で習得しました。
2. Slack 通知の Argo Workflow 実装
2 つ目のタスクは、Argo Workflows での共通 Slack 通知機能の実装です。
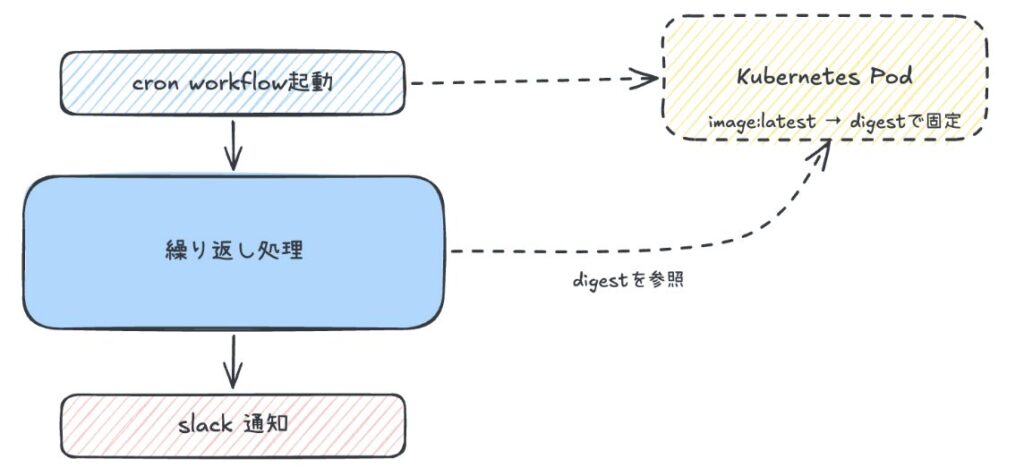
Cloud Workflows 時代は Log Router でログを検知し Pub/Sub 経由で Cloud Run Function を呼び出すという仕組みを取っていました。Argo への移行に伴い、Argo Workflows の exit hook(終了フック)を使い、全ワークフロー共通で完了・失敗時に Slack へ自動通知する仕組みを実装しました。
実装当初は Slack OAuth トークンを手動で設定する方法をとっていましたが、セキュリティと運用の観点から自動取得できる仕組みを検討しました。まず External Secrets Operator(ESO:外部シークレットオペレーター)を使う構成を検討しましたが、追加コンポーネントの管理コストが高いため採用を見送りました。
最終的には、プロジェクト内の別サービス Python プロセス内で Secret Manager から直接取得するシステムを採用しました。Secret Manager へのアクセスに必要なライブラリを、ワークフロー内でスクリプトを実行するためのコンテナイメージに追加し、Workload Identity の権限を使ってトークンを取得する実装で、既存の設計パターンとの一貫性を保ちながらシンプルに実現できました。
3. Python ワークロードの Argo Workflow 実装
3 つ目のタスクは、広告クリエイティブの Python ワークロードのうちの一つの実行基盤を Argo Workflows へ移行することです。
実装中、Terraform の apply が失敗するという問題に直面しました。原因を調査した結果、デプロイの順序に依存関係があることが判明しました。今回の実装では、Argo Workflows 用に新たに GCP サービスアカウントと Kubernetes サービスアカウントを作成し、Workload Identity で紐付ける構成をとっています。GCP サービスアカウントと Workload Identity のバインディングは別モジュールで管理されており、後者は前者のサービスアカウントをメールアドレスの文字列として参照しています。そのため Terraform が依存関係を自動解決できず、サービスアカウントが存在しない状態で一括 apply するとエラーになります。解決策として、まずサービスアカウントの変更を先にリリースし、その後で Workload Identity バインディングを含む変更を適用するという順序を踏みました。インフラの変更はリソース間の依存関係を意識した上でリリース順序を設計することが重要だと学びました。
学んだこと
1. Argo Workflows の実装、Terraform をゼロから習得
CronWorkflow / WorkflowTemplate / Kustomize による環境管理など、Kubernetes 周りの知識も含めて実務を通じて習得しました。
2. Vibe Coding では「背景の言語化」が品質を左右する
Python ワークロードの Argo 移行タスクを行っていた際、私は当初「既存の Cloud Workflows を CronWorkflow に変更してほしい」という内容のみで Claude に指示を出していました。しかし実際には、Cloud Workflows が呼び出しのたびに :latest イメージを取得するためバージョンが揃わないという課題を解決するための移行であり、その背景を伝えていませんでした。その結果、Docker イメージのバージョン管理まで考慮した実装にならず、気づかないまま PR を出してしまいました。移行の目的と背景を最初から指示に含めていれば、Claude がバージョン管理の必要性まで踏まえた設計を提案でき、手戻りを避けられたはずです。
要件だけでなく「なぜそうしたいか」「既存の制約は何か」を自分の中で整理してから渡すことが、Vibe Coding を効果的に使う上で重要だと気づきました。
3. 問題の切り分けの大切さ
インフラ実装では、エラーメッセージだけでは原因が掴みにくい問題に直面することがありました。
実際に実装した範囲をリリースした際、本番環境では正常に動作しているにもかかわらず、ステージング環境と開発環境では動かないという状況が発生しました。まずどの環境で・何が・どのステップで失敗しているのか」を整理するところから始めました。ステージング環境を調査すると、そもそも Cloud Build によるビルド自体が失敗しておりデプロイまで到達できていないことがわかりました。一方、開発環境では、ビルドは成功しているものの全く別の原因で失敗していることが判明し、環境ごとに原因が異なっていました。
この経験を通じて、エラーに直面したときはまずどの環境で再現するか、どのステップまで正常に進んでいるかを切り分けることが、原因特定への最短経路だと学びました。
まとめ
1 ヶ月のインターンシップを通じて、dbt の定期実行フローの移行、Slack 通知の共通化、Python ワークロードの Argo Workflows 移行という 3 つのタスクを完遂しました。
技術面では、Argo Workflows や Kubernetes 周りの知識をゼロから実務を通じて習得したことが大きな収穫でした。また、Vibe Coding を実務で活用する中で、「要件だけでなく背景を言語化してから渡す」という気づきは、AI との協働を今後さらに活かしていく上で自分の中に残る学びになりました。
短い期間ながら、トレーナーさん、メンターさんをはじめ、実際のプロダクト開発に深く関わらせていただいた極 AI チームの皆さんに感謝します。1 ヶ月間本当にありがとうございました!
原文を表示
はじめに
こんにちは、University of British Columbia 学部4年の保井祐理です。
2026年4月3日から4月30日の1ヶ月間、CA Tech JOBに参加しました。
私は、バックエンドエンジニアとして極AIの開発チームに配属していただきました。
この記事では、インターンシップ期間中に私が取り組んだことと、その成果についてご紹介します。
背景
極AI開発チームについて
極予測AIというAIを使った広告クリエイティブに関するプロダクトがあります。
開発チームは、マルチメディアを取り扱う大規模なバッチ処理の開発・運用を行なっています。
元々のワークフロー
もともと、このパイプラインは以下のようなアーキテクチャでCloud Workflowsを使用して構成されていました。
課題
Cloud Run Jobs呼び出すたびに、その時点の最新のDockerイメージ(:latest)を取得します。そのため、ループをしながら同じ処理を呼び出したいケースでは、ループの途中で新しいバージョンがデプロイされると、同じワークフローの中で前半と後半で異なるバージョンのコードが動いてしまいます。
またそれだけでなく、Cloud Workflowsは失敗したステップからのリトライができないなど、ワークフローエンジンとしては機能が限られていました。パイプラインが大規模になってきたことで、より柔軟で機能豊富なArgo Workflowsへの移行を進めることになりました。
GKE(Google Kubernetes Engine)はGoogleが提供するKubernetesのマネージドサービスです。Kubernetesとは、複数のコンテナをまとめて管理・実行するためのプラットフォームで、GKEを使うことでKubernetesクラスターの構築・運用をGoogleに任せることができます。
Argo WorkflowsはKubernetes上で動作するワークフローエンジンです。各処理をコンテナとして定義し、それらの実行順序や依存関係を管理します。Cloud Workflowsと比較して、失敗したステップからのリトライや、GUIでの実行状況の視覚的な確認など、より豊富な機能を持っています。今回はこのGKE上にArgo Workflowsを構築し、移行先の実行基盤としました。
取り組んだタスクについて
こうした背景から、Cloud Workflowsで管理されていたワークフローをArgo Workflowsへ移行するというタスクに取り組みました。
1. データ変換・集計を担うジョブをArgo Workflowsに移行
最初に担当したのは、Cloud Workflowsで管理されていたデータ変換・集計ジョブをArgo Workflowsに移行するタスクです。
システム上でBigQuery上のデータを整形・集計するためのdbtジョブが複数動いており、それぞれCloud Workflows \+ Cloud Scheduler \+ Cloud Run Jobsで定期実行されていました。今回の移行では、これらのジョブをArgoのCronWorkflowとして再実装しました。
Argo Workflowsでは、処理の単位をWorkflowTemplateとして定義し、それを組み合わせて CronWorkflowを構成します。今回はdbtのビルドジョブをWorkflowTemplateとして切り出し、スケジュール実行の設定をCronWorkflowに記述する形で実装しました。
実装後はArgo WorkflowsのGUIを使って実行状況を確認しました。各ステップが視覚的にノードとして表示され、チェックマークで正常完了していることをひと目で確認できます。
このタスクを通じて、WorkflowTemplate・CronWorkflowといったArgoの基本的な構成要素を一通り実務で習得しました。
2. Slack通知の Argo Workflow 実装
2つ目のタスクは、Argo Workflowsでの共通Slack通知機能の実装です。
Cloud Workflows時代はLog Routerでログを検知しPub/Sub経由でCloud Run Functionを呼び出すという仕組みを取っていました。Argoへの移行に伴い、Argo Workflowsのexit hookを使い、全ワークフロー共通で完了・失敗時にSlackへ自動通知する仕組みを実装しました。
実装当初はSlack OAuthトークンを手動で設定する方法をとっていましたが、セキュリティと運用の観点から自動取得できる仕組みを検討しました。まず External Secrets Operator(ESO)を使う構成を検討しましたが、追加コンポーネントの管理コストが高いため採用を見送りました。
最終的には、プロジェクト内の別サービスPythonプロセス内でSecret Managerから直接取得するシステムを採用しました。Secret Manager へのアクセスに必要なライブラリを、ワークフロー内でスクリプトを実行するためのコンテナイメージに追加し、Workload Identity の権限を使ってトークンを取得する実装で、既存の設計パターンとの一貫性を保ちながらシンプルに実現できました。
3. PythonワークロードのArgo Workflow実装
3つ目のタスクは、広告クリエイティブのPythonワークロードのうちの一つの実行基盤をArgo Workflowsへ移行することです。
実装中、Terraformのapplyが失敗するという問題に直面しました。原因を調査した結果、デプロイの順序に依存関係があることが判明しました。今回の実装では、Argo Workflows用に新たにGCPサービスアカウントとKubernetesサービスアカウントを作成し、Workload Identityで紐付ける構成をとっています。GCPサービスアカウントとWorkload Identityのバインディングは 別モジュールで管理されており、後者は前者のサービスアカウントをメールアドレスの文字列として参照しています。そのためTerraformが依存関係を自動解決できず、サービスアカウントが存在しない状態で一括applyするとエラーになります。解決策として、まずサービスアカウントの変更を先にリリースし、その後でWorkload Identityバインディングを含む変更を適用するという順序を踏みました。インフラの変更はリソース間の依存関係を意識した上でリリース順序を設計することが重要だと学びました。
学んだこと
1. Argo Workflowsの実装、Terraformをゼロから習得
CronWorkflow / WorkflowTemplate / Kustomizeによる環境管理など、Kubernetes周りの知識も含めて実務を通じて習得しました。
2. Vibe Codingでは「背景の言語化」が品質を左右する
PythonワークロードのArgo移行のタスクを行なっていた際に、私は最初「既存のCloud Workflowsを CronWorkflow に変更してほしい」という内容のみで、Claudに指示出しをしていました。しかし実際には、Cloud Workflowsが呼び出しのたびに :latestイメージを取得するためバージョンが揃わないという課題を解決するための移行であり、その背景を伝えていませんでした。その結果、Dockerイメージのバージョン管理まで考慮した実装にならず、気づかないままPRを出してしまいました。移行の目的と背景を最初から指示に含めていれば、Claudeがバージョン管理の必要性まで踏まえた設計を提案でき、手戻りを避けられたはずです。
要件だけでなく「なぜそうしたいか」「既存の制約は何か」を自分の中で整理してから渡すことが、Vibe Codingを効果的に使う上で重要だと気づきました。
3. 問題の切り分けの大切さ
インフラ実装では、エラーメッセージだけでは原因が掴みにくい問題に直面することがありました。
実際に実装した範囲をリリースした際、本番環境では正常に動作しているにもかかわらず、ステージング環境と開発環境では動かないという状況が発生しました。まずどの環境で・何が・どのステップで失敗しているのか」を整理するところから始めました。ステージング環境を調査すると、そもそもCloud Buildによるビルド自体が失敗しておりデプロイまで到達できていないことがわかりました。一方、開発環境では、ビルドは成功しているものの全く別の原因で失敗していることが判明し、環境ごとに原因が異なっていました。
この経験を通じて、エラーに直面したときはまずどの環境で再現するか、どのステップまで正常に進んでいるかを切り分けることが、原因特定への最短経路だと学びました。
まとめ
1ヶ月のインターンシップを通じて、dbtの定期実行フローの移行、Slack通知の共通化、 PythonワークロードのArgo Workflows移行という3つのタスクを完遂しました。
技術面では、Argo WorkflowsやKubernetes周りの知識をゼロから実務を通じて習得したことが大きな収穫でした。また、Vibe Codingを実務で活用する中で、「要件だけでなく背景を言語化してから渡す」という気づきは、AIとの協働を今後さらに活かしていく上で自分の中に残る学びになりました。
短い期間ながら、トレーナーさん、メンターさんをはじめ、実際のプロダクト開発に深く関わらせていただいた極AIチームの皆さんに感謝します。1ヶ月間本当にありがとうございました!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み