エージェントのための自己改善メモリシステム(6 分読了)
Perplexity は、エージェントの作業履歴を分析して自己改善を行う「Brain」と呼ばれる新しいメモリシステムを発表し、従来のユーザー中心モデルからタスク効率化中心への転換を図っている。
キーポイント
Brain の導入と機能
Perplexity が発表した「Brain」は、エージェントが実行した作業の文脈グラフを構築し、定期的にレビューして自己改善を行うシステムである。
メモリモデルのパラダイムシフト
従来のユーザーの嗜好や設定を記憶するモデルから、何を行ったか・何が成功・失敗したかを記録し、エージェントの業務能力向上に寄与するモデルへ転換された。
再帰的自己改善の実現
プロジェクトや接続先、成果物の学習を通じてエラーから修正を学び、使用頻度が高まるほどエージェントの効率と精度が向上する仕組みを採用している。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントにおけるメモリ設計の根本的な転換点を示しており、単なる記憶装置から自律学習システムへと進化させる可能性を提示しています。業界全体として、エージェントの長期運用効率と信頼性を高めるためのアーキテクチャ標準が確立されつつあることを示唆しており、実務レベルでのAI導入加速に寄与する重要な進展です。
編集コメント
従来の「ユーザーの記憶」に留まらず、エージェント自身の「業務経験」を学習リソースとして活用するアプローチは、実用化されたAIエージェントの次のステップとして極めて重要です。
エージェントのための自己改善型メモリ
AI における一般的なメンタルモデルは、エージェントを「労働者」として捉えることです。新しい機能は、「最近大学を卒業した新卒社員」や「2 年目のアナリスト」に相当するかもしれません。これは AI の能力を考える上で最良の方法ではありませんが、職場における AI の重要な概念を説明しています:労働者を雇う際、彼らが現場で学び、成長することを期待するものです。
AI エージェントも同様に振る舞うべきです。これにより、「メモリ」が AI において本当に何を意味するのかについて、より詳細な検討が必要となります。
Brain の紹介
本日、私たちは AI におけるメモリに対する全く新しいアプローチを発表します。これを Brain と名付けました。
Brain は自己改善型のメモリシステムです。これは、Computer が実行する作業の文脈グラフを構築します。夜間などの設定された間隔で、Brain はその文脈グラフを見直し、より効率的に作業を行う方法を自ら学習します。
作業量が増えるほど、Brain はあなたの Computer をより賢く、より効率的なものへと進化させます。
AI メモリのためのより優れたモデル
AI におけるメモリには、2 つの重要な軸があります。1 つ目は「メモリが何を対象とするか」であり、2 つ目は「メモリを何に利用するか」です。
従来の AI メモリは、あなた、つまりユーザー自身を対象としていました。あなたの好み、趣味、作業スタイル、連絡先、役割などです。Brain は、AI エージェントにとってより効果的なモデルを先駆けています:Brain はエージェントが何を行ったかを記憶します。何が成功し、何が失敗したか、そしてその作業に対してどのような修正が行われたかを記憶します。そして、より良い作業を行う方法を学習するのです。
第二に、ユーザーに関する AI の記憶は、あなたが AI エージェントにより深く関与していると感じるのを助ける目的を果たします。Brain などの作業用メモリは、エージェントが業務をより上手に行うのを助ける目的を果たします。これがメモリの最も重要な目的です。
このアプローチによって、時間の経過とともに Computer のパフォーマンスが向上します。Brain を備えた Computer は、新しいタスクごとに前日より良い出発点を持ちます。その理由は、Brain が過去のセッション、何が機能し、何が機能しなかったかに基づいて、ユーザーが達成しようとしている可能性が高いものを新鮮なマップとして作成するからです。
つまり、Computer はより速く回答に到達し、最も信頼性の高いソースにアクセスでき、時間とトークンの無駄を避けることができます。
再帰的自己改善
Brain は Computer を使用するほどに向上します。エージェントは、最適な出力につながるプロジェクト、コネクタ、アーティファクト、および他のソースを学習するにつれて、コンテキストを更新する能力が高まります。
また、エラーからも学習し、ユーザーが修正を行った時や、あるソースが行き止まりであったことを記憶します。その結果、ターン数が減り、モデル呼び出し回数が減少し、出力の質が向上します。
このフィードバックループこそが、Brain を継続的に自己改善させる要因です。
ユーザーにとって、エージェントは業務を遂行するために必要なコンテキストを理解する能力が高まります。また、現在のトークン使用量は、将来的により効率的なトークン使用量への投資であることを意味します。
コンテキストグラフ
Brain は、Computer がユーザーの世界を理解し、その仕事から学び、将来のタスクにそれを適用できるよう支援する追跡可能なグラフを作成することで、Computer のための生きたコンテキストグラフを形成します。
このコンテキスト層は、エージェントサンドボックスに自動的に読み込まれる LLM ウィキ(大規模言語モデルウィキ)という形態をとります。ユーザーの LLM ウィキページには、その世界を構成するアイデア、人々、プロジェクト、その他の要素が反映されており、Computer はこの個人情報のウェブを横断して移動することができます。
このウィキは、Brain システムによって夜間に逐次的に更新されます。これは、ユーザーのセッションとコネクタの結果、ソースドキュメントの変更、および修正点を統合して行われます。
この絶え間なく刷新されるコンテキストにより、Computer は、ユーザーに対して何をすべきか、どこを見るべきか、そしてどのように出力を届けるべきかについて、より強力なシグナルを得ることができます。
パフォーマンスの向上
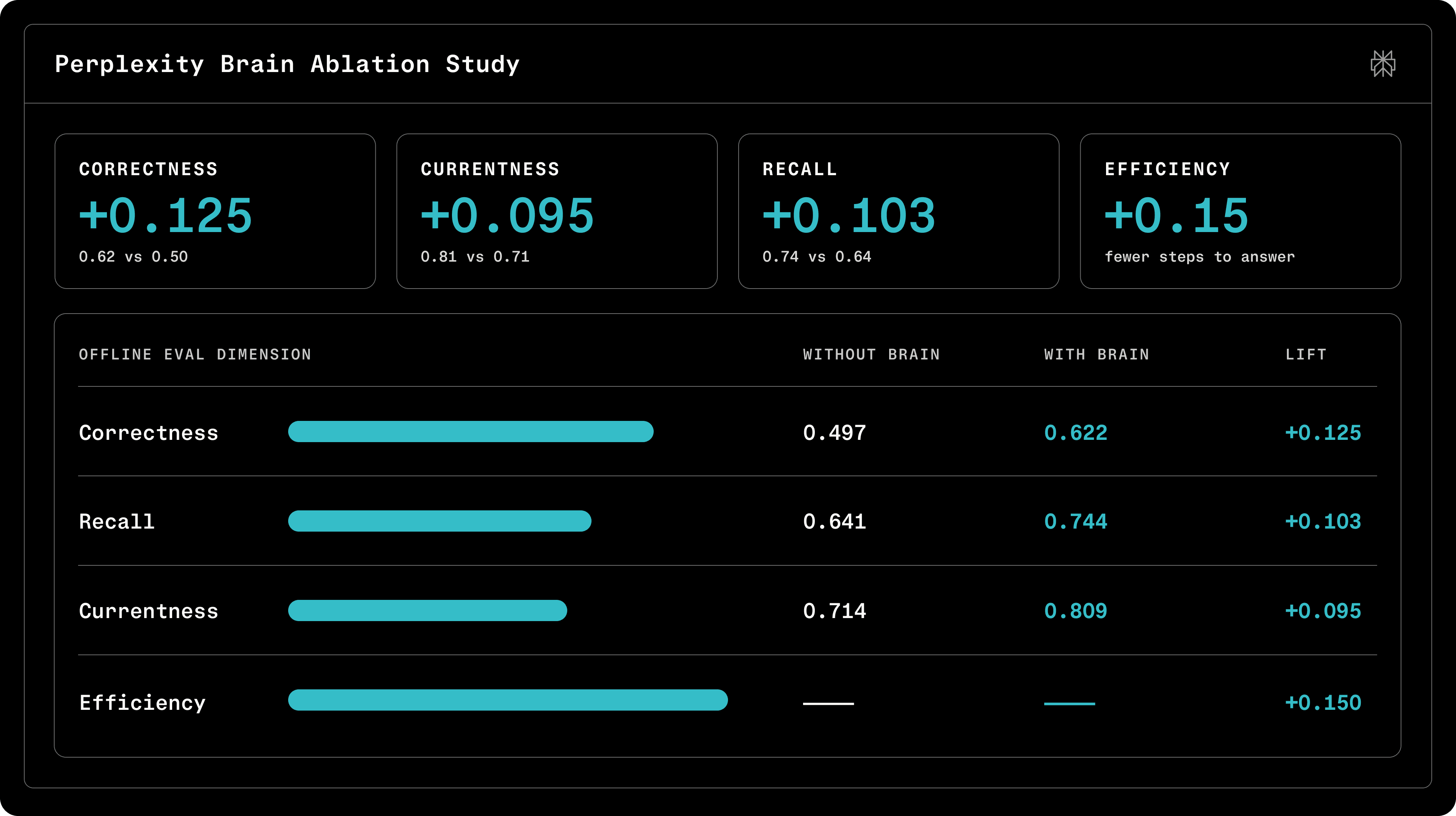
展開
初期の測定結果によると、Brain は Computer が以前に見たことのあるタスクにおいて、回答の正答率を 25% 向上させます。また、想起(リコール)能力も 16% 向上します。
同じ結果は、履歴コンテキストを必要とするタスクのコストを 13% 削減することも示しています。さらに、Brain を長く使用する人々については、エージェントがその世界を学習するにつれて結果が改善していくことがわかります。
Brain は他の Perplexity によって生成された出力と同様に、その作業内容を明示します。すべてのメモリエントリは、それが由来したセッション、ファイル、またはソースへとリンクされています。
能動的 AI を駆動する
コンピュータがユーザーや企業が求める能動的 AI となるのは、継続的な学習を通じてのみです。エージェントは業務とその改善方法を学び、記憶します。
フロンティア AI とは、自組織のために構築した個別の AI システムのことです。エージェントが私たちが行う業務から積極的に学習すれば、私たちが尋ねていない機会を特定したり、誰も気づく前に問題を警告したりできます。
このバージョンの Brain は始まりに過ぎません。新しい機能については近日発表します。
Brain は本日、Research Preview において Max および Enterprise Max のサブスクライバー向けに展開を開始しました。
原文を表示
Self-improving Memory for Agents
A popular mental model in AI is to think of an agent as a worker. A new capability might be equivalent to “a recent college graduate,” or “a second-year analyst.” This is not the best way to think about AI capabilities, but it does illustrate a critical concept of AI at work: whenever you hire any worker, you expect them to learn and develop on the job.
AI agents should do the same. This begs a closer look at what “memory” really means in AI.
Introducing Brain
Today we are launching a wholly new approach to memory in AI. We’re calling it Brain.
Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews the context graph and teaches itself how to do the work better.
The more work you do, the better and more efficient Brain makes your Computer.
A better model for AI memory
There are two axes of importance for memory in AI. The first is what the memory is about, and the second is what the memory is for.
Traditionally, AI memory has been about you, the user. Your preferences, tastes, working styles, contacts, role, and more. Brain pioneers a much more effective model for AI agents: Brain remembers what the agent did. It remembers what worked and what failed, and what corrections got made to the work. It learns to do better work.
Second, AI memory about the user serves the purpose of helping you feel more engaged with the AI agent. Work memory like Brain serves the purpose of helping the agent get better at the job. This is the most important purpose of memory.
Together, this approach to memory improves Computer’s performance over time. Every day, Computer with Brain has a better starting point for each new task. That’s because Brain creates a fresh map of what the user is most likely hoping to accomplish based on past sessions, what’s worked, and what hasn’t.
That means Computer can get to answers faster, access the most reliable sources, and avoid wasting time and tokens.
Recursive self-improvement
Brain gets better as you use Computer. Agents become more effective at updating context as they learn the projects, connectors, artifacts, and other sources that lead to the best outputs.
They also learn from their mistakes, remembering when a user has made a correction or when a source was a dead end. That results in fewer turns, fewer model calls, and better outputs.
This feedback loop is what makes Brain continuously self-improving.
For users, the agents get better at understanding the context they need to know to do the work. It also means that the current token usage is an investment in more efficient token usage later.
The context graph
Brain forms a living context graph for Computer by creating a traceable graph that helps Computer understand the user’s world, learn from their work, and apply that work to future tasks.
The context layer takes the form of an LLM wiki that’s automatically loaded onto the agent sandbox. A user's LLM wiki pages reflect the ideas, people, projects, and other elements that make up their world, allowing Computer to traverse this web of personal information.
The wiki is incrementally updated by the Brain system overnight as it synthesizes the user’s sessions along with connector results, changes in source documents, and corrections made.
That persistently refreshing context gives Computer stronger signal on what to do, where to look, and how to deliver outputs for a user.
Improved performance
Expand
Early measurement results show that Brain increases answer correctness by 25% on tasks Computer has seen before. And recall goes up by 16%.
The same results show Brain cuts the cost of tasks that require historical context by 13%. And the results for people who use Brain longer improve as the agents learn their world.
Brain also shows its work, like other outputs generated by Perplexity. Every memory entry links back to the session, file, or source that it came from.
Powering proactive AI
Only through continuous learning does Computer become the proactive AI that users and businesses ask us for. Agents learn and remember the work and how to get better at it.
The frontier AI is the individual system you build for AI in your own organization. When agents actively learn from the work we do, they can identify opportunities we didn’t ask about, or flag a problem before anyone has noticed.
This version of Brain is just the beginning. We will announce new capabilities soon.
Brain is rolling out today to Max and Enterprise Max subscribers in Research Preview.
関連記事
Perplexity がエージェントの作業文脈グラフを構築し夜間に学習する自己改善型メモリシステム「Brain」を発表
Perplexity は、自社のエージェント製品「Computer」向けに、ユーザーではなくエージェントの行動履歴を記憶する自己改善型メモリシステム「Brain」を発表した。これは作業の文脈グラフを構築し、夜間に学習を行う仕組みである。
LLM による継続的な更新が記憶の誤りを招く
AI エージェントは、LLM が記憶を連続的に書き換えることで、かえって性能が低下する。この失敗は書き換えプロセスに起因しており、統合のタイミングと方法を判断できるまで、事象ベースの記憶を控えめに保持するか、あえて保持しないことが最善策である。
AI エージェントの記憶機能の仕組み(28 分読了)
この記事は、言語モデルが応答後に情報を忘却する課題に対し、対話を継続させるための記憶システムが情報ループ内で果たす役割と、各ループで伝達すべき情報の選定方法について解説している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み