システム向けAI:LLMを用いたデータベースクエリ実行の最適化
Together AIはスタンフォード大学らと共同で、LLMを活用してデータベースエンジンを変更せずにクエリ実行計画を最適化し、パフォーマンス向上を実現する手法を実証した。
キーポイント
LLMによるクエリ最適化の実証
スタンフォード大学、ウィスコンシン大学マディソン校、Bauplanとの共同研究により、LLMがデータベースクエリの実行計画を再構成し、パフォーマンスを向上させることができることが示された。
データベースエンジン非依存の最適化
既存のデータベースエンジンを修正・置換することなく、LLMによるガイダンスで実行計画を書き換えることで最適化を行うため、導入コストとリスクが低い。
AIとシステムインフラの双方向関係
従来の「AIを支えるインフラ」から、「AIがインフラを最適化する」という非対称な関係の打破を示唆し、大規模システム機能へのAI応用の可能性を広げた。
重要な引用
We worked in collaboration with Stanford University, the University of Wisconsin–Madison, and Bauplan to test whether LLMs can optimize database query execution plans.
The results show that LLM-guided plan rewrites can improve execution performance without modifying the database engine itself.
Recent advances in AI have been driven by improvements in the underlying systems infrastructure. But this relationship does not have to be asymmetric: AI and LLMs can also be used to optimize the functional components of large-scale systems themselves.
影響分析・編集コメントを表示
影響分析
この研究は、LLMの応用範囲をコンテンツ生成からシステム運用・最適化へと拡大する重要なマイルストーンである。特に、既存のデータベース基盤を刷新せずにパフォーマンス改善が可能となるため、大規模データ処理を行う企業にとって、コスト効率の高い最適化手段として期待される。今後は実証規模の拡大と、より複雑なクエリへの適用可能性が注目される。
編集コメント
LLMをインフラ層の最適化に適用する試みは、AIエージェントが自律的にシステムを管理・改善する未来への一歩であり、DBAの業務効率化に直結する可能性を秘めている。
 imageimage要約
imageimage要約
私たちはスタンフォード大学、ウィスコンシン大学マディソン校、および Bauplan と協力し、大規模言語モデル(LLM)がデータベースのクエリ実行計画を最適化できるかどうかを検証しました。その結果、LLM によるガイダンスを受けた計画の書き換えは、データベースエンジン自体を変更することなく、実行パフォーマンスを向上させることができることが示されました。
最近の AI の進歩は、基盤となるシステムインフラストラクチャの改善によって牽引されてきました。しかし、この関係が非対称である必要はありません。AI や LLM は、大規模システムそのものの機能的コンポーネントを最適化するためにも利用可能です。私たちの最新の論文では、データベースクエリ最適化に AI をどのように活用できるかを示しています。
従来のクエリ最適化は、統計モデルと事前定義されたヒューリスティックを用いて実行パスを計算するコストベース推定器に依存しています。"宇宙旅行のあるSF ショーをすべて見つける"というクエリを実行する場合、最適化器は実行戦略を選択する必要があります:まず SF ショーをフィルタリングしてその後に宇宙旅行があるかを確認すべきか、それとも逆の順序で行うべきか?もしデータが複数のテーブル(例えば shows テーブルと genres テーブル)に分散されている場合、どちらのテーブルを先にスキャンし、どのように結合すべきでしょうか?最適化器は、各条件に一致する行数を見積もることでこれらの質問に答え、見積もられたコストが最小となる実際のプラン(操作の順序)を選択します。
しかしながら、これらの推定は属性間の独立性を仮定していることがよくあります。 "SF"かつ"宇宙旅行がある"という両方の条件を満たすショーを見つけたいストリーミングサービスのデータセットを考えてみましょう。もしショーの 15% が SF で、8% が宇宙旅行を描いている場合、独立性を仮定すると、両方の基準に一致するショーは 1.2%(15% × 8%)と推定されます。しかし実際には、宇宙旅行を描くショーのほとんどが SF であるため、実際の重複率は約 7% に近く、予測値のほぼ 6 倍にもなります。
実際、これらのシステムは一般的に良好に機能しますが、ヒューリスティックがスキーマ内またはデータ内の意味的な相関関係を考慮できない場合に苦戦します。Lohman(2014 年)による例で指摘されているように、カーディナリティ推定はオプティマイザの非効率性の主要な原因であり、行数の誤った推定がコストモデルを通じて伝播し、結合順序、アクセスパス、物理演算子の体系的に不適切な選択につながるからです。この桁違いの誤差は、手動で修正するために多大なエンジニアリング努力を要する最適化されていない物理プランをもたらします。
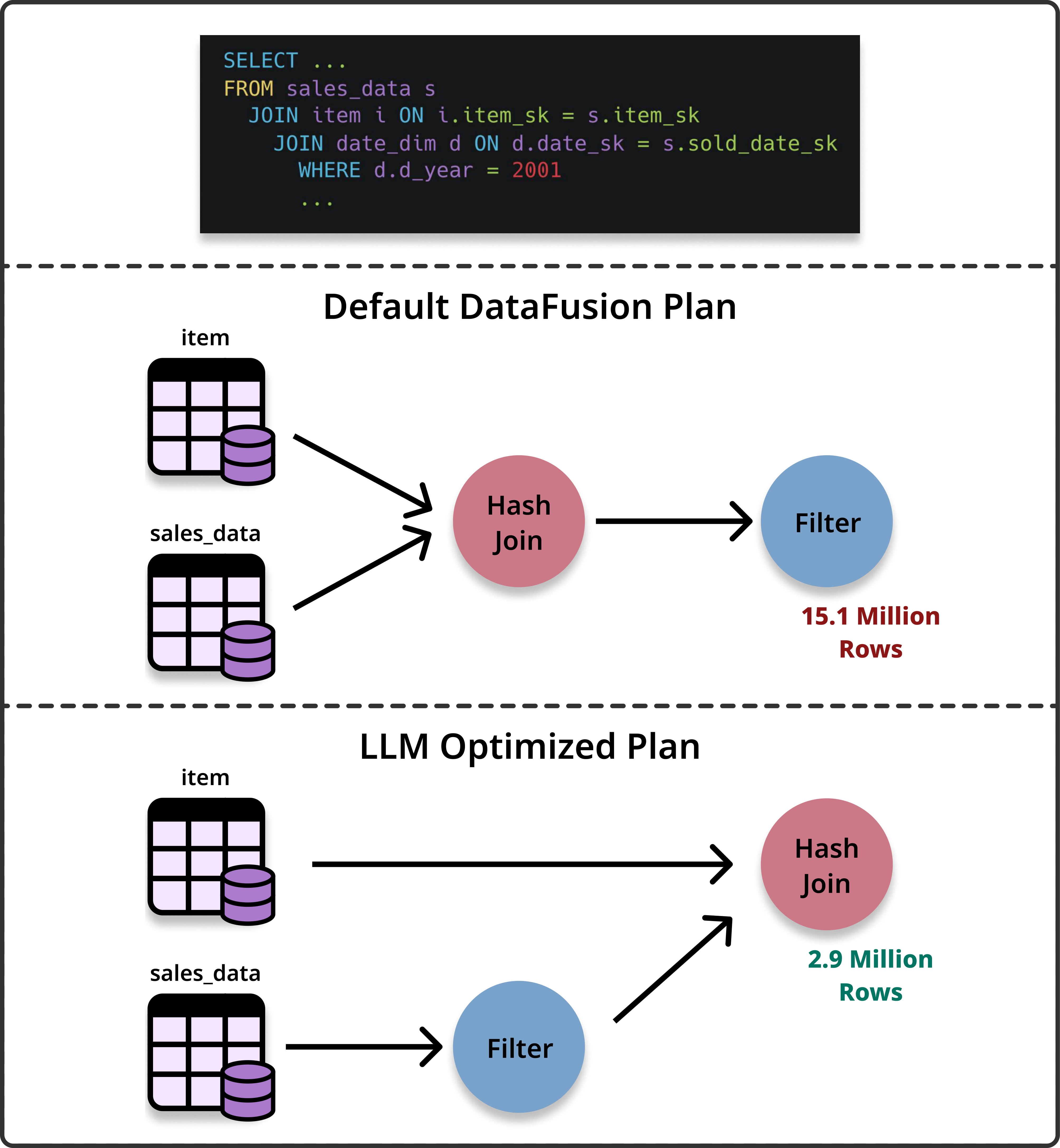
意味認識型結合最適化。選択的な date フィルタを早期に適用することで、LLM はプランを再順序付けし、結合前に販売事実テーブルの行数を 1,510 万件から 290 万件に削減し、はるかに高速なクエリを実現します。
クエリ最適化は解決済みの問題か?
これらの推定エラーが persists(持続)していることは、物理プランニングが解決された問題ではないことを示しており、特に機能的依存関係が一般的な複雑な OLAP ワークロードにおいてその傾向が強いです。
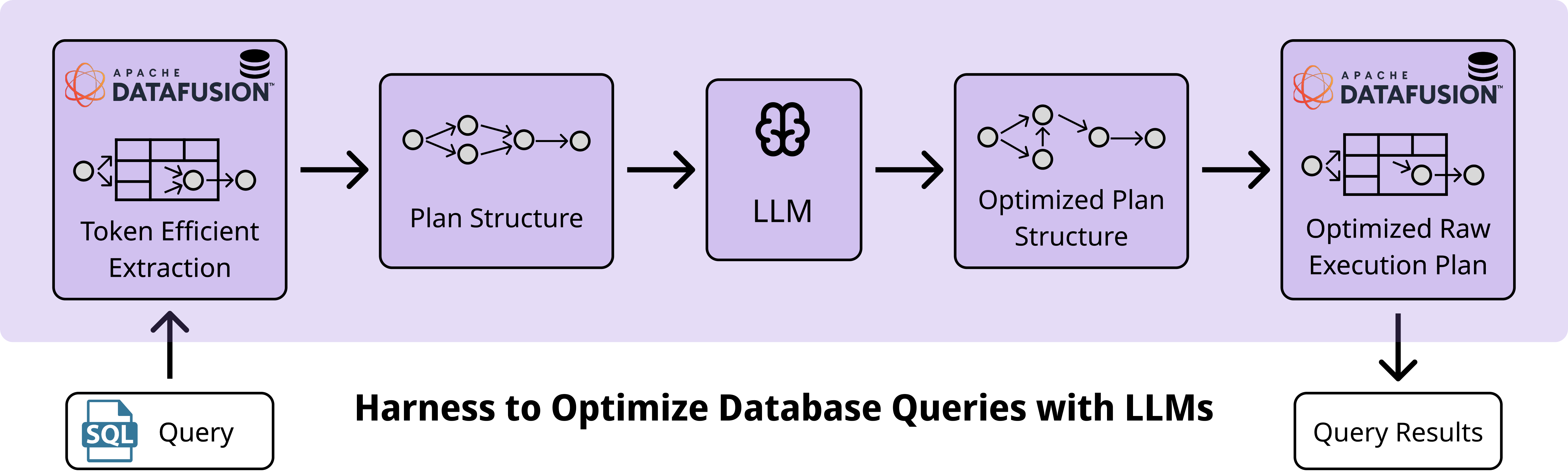
これに対処するため、Apache DataFusion エンジンのクエリ実行プロセスを公開するハネス「DBPlanBench」を導入しました。このシステムは、結合戦略やパーティショニングスキームを含む内部の物理演算子グラフを大規模言語モデル(LLM)に公開します。ここで主要な技術的課題は、生きた物理計画に内在する情報の密度です。これには冗長なファイルパス、パーティションメタデータ、型符号化が含まれており、これらがコンテキストウィンドウを急速に埋め尽くしてしまいます。
注意深いシリアライゼーションを行わないと、計画全体が 200 万文字を超え、LLM が入力に対して効果的かつ効率的に推論することが不可能になります。当社のハネスは、エンジンの物理演算子グラフを走査し、多様なオブジェクトを統一されたトークン効率の高い JSON スキーマにマッピングするシリアライゼーション層を実装しています。

単一のテーブルに対するエンジン統計情報を圧縮した具体例です。完全な JSON には多くの実行に不要なフィールド(例えば precisionInfo、各列の最小値・最大値および null カウントなど)が含まれていますが、簡潔な統計情報では n_rows や total_bytes のような主要なシグナルのみを保持します。この表現形式はファイルレベルの統計情報を重複排除し、実行に不要なフィールドを除去することで、ネイティブなシリアライゼーションと比較して約 10 倍小さいペイロードを実現しています。
DBPlanBench はこれにより、最適化タスクを統計計算からセマンティック推論の問題へと変換します。ここでは LLM がプランのトポロジーを分析し、結合順序における論理的な欠陥を特定します。
DataFusion 内の物理プランを最適化するための最適化ハッチ。これらの修正を安全に実装するために、LLM には物理プランを一から再生成しないよう指示します。代わりに、DataFusion の既存の物理プランに対してターゲットを絞った編集を適用し、構文エラーや無効なプラントポロジーのリスクを低減します。具体的には、LLM は結合側の入れ替えやノードの順序変更など、局所的な編集を記述する JSON Patches(RFC 6902)を生成します。これらのパッチは完全なプランに比べて桁違いに小さく、シリアライズされたグラフに対して直接適用されるため、実行 DAG の構造的整合性が保証されます。

ハッシュ結合の左側と右側の入力を入れ替え、両方の子 ID と結合キーを更新する JSON Patch の例です。これは、プラン全体を再生成することなく、結合(例えば、より小さなテーブルをビルド側に配置するなど)を書き換えるために、小さく局所的なパッチがどのように機能するかを示しています。
ケーススタディ
統計推定失敗の帰結は、クエリレイテンシとシステムリソース消費量の両方で測定可能です。クロスチャネル販売を含む TPC-DS の派生バージョンから生成された特定クエリにおいて、デフォルトの DataFusion オプティマイザは、より小さな結合が安価であると仮定し、まず小さいアイテムテーブル(36K 行)を大きい日付次元テーブル(73K 行)よりも先に結合する優先順位をつけました。このヒューリスティックは、日付次元におけるフィルタ d_year=2001 の高い選択性(selectivity)を考慮していませんでした。LLM で最適化されたプランはこの順序を逆転させ、日付フィルタを早期に適用することで、その後の結合処理の前に売上事実テーブルを 1510 万行から 290 万行まで削減しました。
この構造的な最適化により、クエリの速度が 4.78 倍向上しました。より重要なのは、リソースフットプリントが劇的に減少したことです。最適化されたプランは、集約ハッシュテーブルの構築時間を 10.16 秒から 0.41 秒に短縮し、総構築メモリ使用量を 3.3 GB から 411 MB に大幅に削減しました。実験では、TPC-H および TPC-DS の生成されたクエリワークロードにおいて、中央値の速度向上は約 1.1 倍から 1.2 倍程度でしたが、この手法は一部の複雑な多結合クエリにおいてもより大きな利益をもたらしました。例えば、最大で 4.78 倍の速度向上や、いくつかのケースで 1.5 倍から 1.7 倍の範囲での向上が確認されました。
進化的プランパッチング
私たちは、反復的な改良を通じてクエリプランを進化させます。システムは GPT-5 を用いて候補となる改善策(JSON パッチ形式)を生成し、各変更を検証してレイテンシを短縮するパッチのみを採用します。これらのパッチが適用された後、システムは新しいプランから新たな候補の生成を試みます。複数のステップにわたる成功した最適化を積み重ねていくことで、この進化的アプローチは、多数のプランを独立してサンプリングする単純な手法よりも優れた速度向上を実現します。
すべてのクエリが効果的に最適化できるわけではありません。プランがすでに最適化されている場合もあるからです。しかし、私たちがサンプリングしたデータセットでは、60.8% のクエリが 5% 以上の改善が可能であることがわかりました。以下の図は、派生させたデータセットの一つにおける改善状況を示しています:
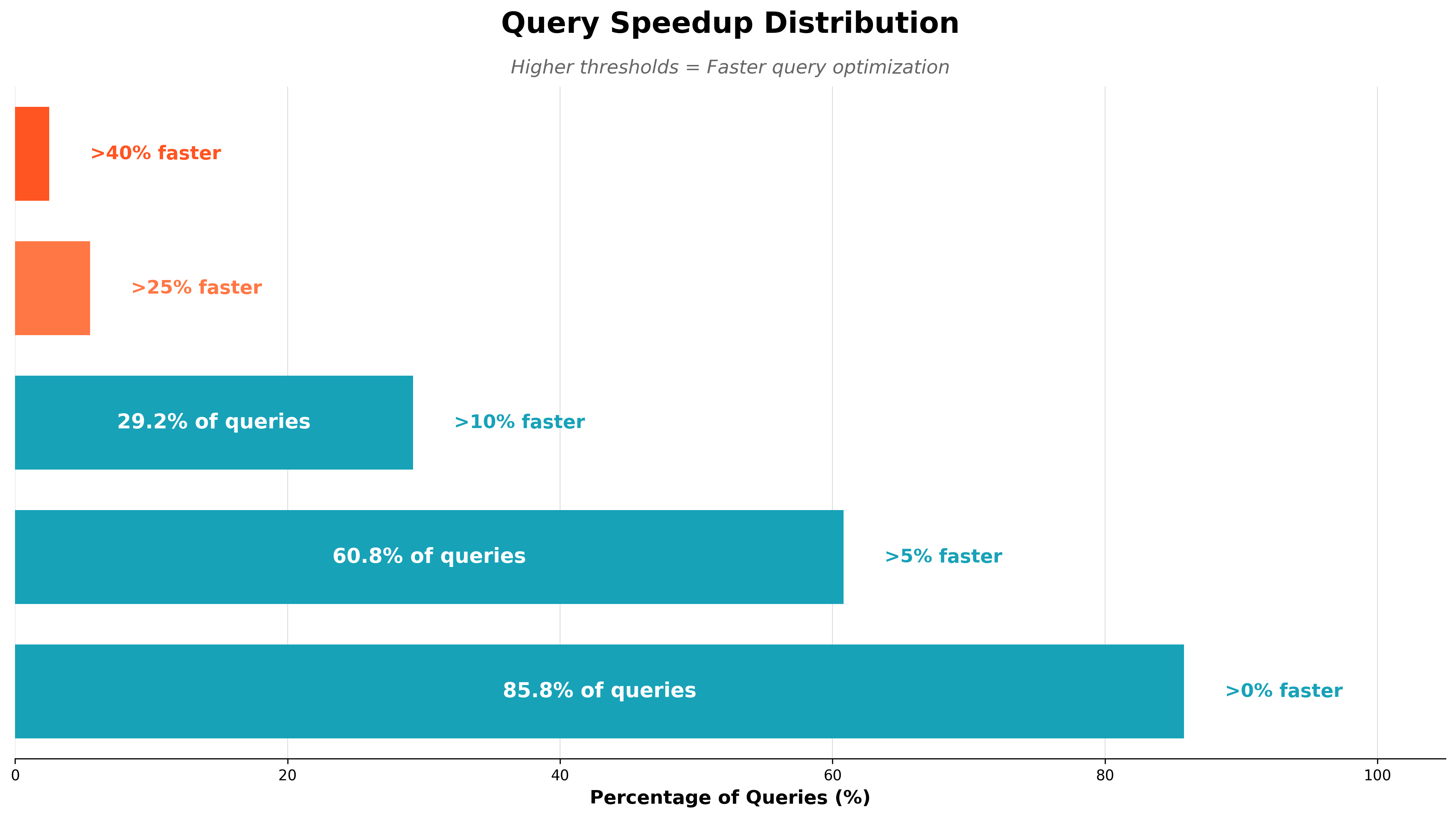
テストされたデータセットの一つにおける速度向上の分布(クエリ数 120)。より多くのクエリを最適化できる可能性はありますが、興味深いことに、約 30% のクエリで 10% を超える速度向上を実現できることが示されています。
スケールファクタ間での速度向上の転送
私たちが使用するベンチマークには、テーブルの基数(cardinality)をスケーリングしつつ、基盤となるスキーマは固定するスケールファクタパラメータが用意されています。実務的にはこれにより、同じ構造を持ちサイズのみが異なる、小規模なプロトタイプデータベース(例えばスケールファクタ 3、または SF3)と、大規模な本番環境に近いデータベース(例えば SF10)を構築することが可能になります。
フルスケールのデータ上で多数の候補プランを検索することは高コストです(各ステップにはクエリの実行に加え、LLM 生成パッチへの支払いと待機が必要となるため)。そこでまず、進化探索を用いて SF3 上で優れた最適化済みプランを特定します。その後、各クエリに対して、決定論的かつルールベースのスクリプトにより、最良の SF3 プランを SF10 に転送します。このスクリプトは、正規化されたスキーマ/投影/述語シグネチャを通じてスケール間でのスキャン演算子をマッチングさせ、結合順序の入れ替えや結合側の交換といった構造的な編集を保持しつつ、安全性チェック(例:参照先の欠落なし、有効な DAG トポロジー)を適用して、実行可能な SF10 プランへと書き換えます。
実証結果として、SF3 で選択した最適化済みプランはすべて SF10 への転送に成功し、得られた速度向上は元の値とほぼ一致しました。これは、「小さく最適化し、大きく展開する」という実践的なワークフローの有効性を裏付けるものです。つまり、負荷のコンパクトなレプリカ上で高コストな探索を一度実行し、その結果得られたプランを最小限の追加エンジニアリングでより大規模な本番データベースへ引き上げるというアプローチです。
小規模な SF3 データベースで見つかった速度向上は、大規模な SF10 においてもほぼそのまま引き継がれます。各点は一つのクエリを表しており、SF3 での速度向上(横軸)と SF10 での速度向上(縦軸)を比較しています。
結論
DBPlanBench は、LLM(大規模言語モデル)が統計的ヒューリスティックでは見逃される物理計画の誤りを修正するための意味的なカーディナリティ推定器として効果的に機能し得ることを実証しました。コンパクトな計画シリアライゼーションと進化的パッチ探索を組み合わせることで、このシステムはコアデータベースエンジンへの変更を必要とせず、実行時間の大幅な短縮とメモリ負荷の軽減を実現しています。ハーン(検証環境)およびコードは、さらなる研究のためにオープンソースとして公開されています。
参考文献
Lohman, G. Is query optimization a "solved" problem? ACM SIGMOD Blog, April 2014. URL: https://wp.sigmod.org/?p=1075. アクセス日:2026-01-26。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文のコピーはここに記載されます(lorem ipsum dolor sit amet)
- ビューポイントここにロレム イプスム
- ビューポイントここにロレム イプスム
- ビューポイントここにロレム イプスム
インフラストラクチャ
最適用途
- 処理速度の向上(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- ロレム イプスム ドルル シット アメト,コンセクテトゥール アディピシング エリート,セド ドイウスモス テンポル インキディデント。
- ロレム イプスム ドルル シット アメト,コンセクテトゥール アディピシング エリート,セド ドイウスモス テンポル インキディデント。
- ロレム イプスム ドルル シット アメト,コンセクテトゥール アディピシング エリート,セド ドイウスモス テンポル インキディデント。
リスト項目 #1
ロレム イプスム ドルル シット アメト,コンセクテトゥール アディピシング エリート,セド ドイウスモス テンポル インキディデント ウト ラボレ エト ドローレ マグナ アルィクア。ウト エニム アド ミニム ヴェニアム,キス ノストル エクセルチタティオン ウルマコウ ラボリス ニシィ ウト アリキップ エク エア コモドゥオ コンセクァトゥール。
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に記述してください。推論は以下のルールに従って行ってください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用しないでください。
ここに質問があります:
ナタリアさんは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数のクリップを販売しました。ナタリアさんが 4 月と 5 月の合計で販売したクリップの数は何個ですか?
XX
タイトル
本文ここにローラム イプサム ドロール シット アメット
XX
タイトル
本文ここにローラム イプサム ドロール シット アメット
XX
タイトル
本文ここにローラム イプサム ドロール シット アメット
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
パフォーマンス & スケーラビリティ
本文ここにローラム イプサム ドロール シット アメット
- ビールポイントここにロレムイプサム
- ビールポイントここにロレムイプサム
- ビールポイントここにロレムイプサム
インフラストラクチャー
最適用途
- 処理速度の向上(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- ロレムイプサム ドロル シット アメト,コンセクテトゥール アディピスキング エリート,セド ドゥイウスモル テンポル インシジデント。
- ロレムイプサム ドロル シット アメト,コンセクテトゥール アディピスキング エリート,セド ドゥイウスモル テンポル インシジデント。
- ロレムイプサム ドロル シット アメト,コンセクテトゥール アディピスキング エリート,セド ドゥイウスモル テンポル インシジデント。
リスト項目 #1
ロレムイプサム ドロル シット アメト,コンセクテトゥール アディピスキング エリート,セド ドゥイウスモル テンポル インシジデント ウト ラボレ エト ドロレ マグナアリクア。ウト エニム アド ミニム ヴェニアム,キス ノストル エクセルチタティオン ウルマコウ ラボリス ニシィ ウト アリキップ エク エア コモドゥー コンセクァトゥール。
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に記述してください。推論は以下のルールに従って行ってください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用しないでください。
ここに質問があります:
Natalia は 4 月に友人 48 人にクリップを売り、5 月にはその半分の数のクリップを売りました。Natalia は 4 月と 5 月の合計で何個のクリップを売ったでしょうか?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
原文を表示
Summary
We worked in collaboration with Stanford University, the University of Wisconsin–Madison, and Bauplan to test whether LLMs can optimize database query execution plans. The results show that LLM-guided plan rewrites can improve execution performance without modifying the database engine itself.
Recent advances in AI have been driven by improvements in the underlying systems infrastructure. But this relationship does not have to be asymmetric: AI and LLMs can also be used to optimize the functional components of large-scale systems themselves. Our recent paper shows how AI can be used for database query optimization.
Traditional query optimization relies on cost-based estimators that calculate execution paths using statistical models and predefined heuristics. When executing a query like "find all sci-fi shows with space travel," the optimizer must decide on an execution strategy: Should it first filter for sci-fi shows and then check which have space travel, or vice versa? If the data is spread across multiple tables (e.g., a shows table and a genres table), which table should be scanned first and how should they be joined? The optimizer answers these questions by estimating how many rows will match each condition, then choosing the actual plan (the order of the operations) with the lowest estimated cost.
However, these estimates often assume attribute independence. Consider a streaming service dataset where you want to find shows that are both "sci-fi" AND "have space travel." If 15% of shows are sci-fi and 8% feature space travel, assuming independence would estimate that 1.2% of shows match both criteria (15% × 8%). However, space travel shows are overwhelmingly sci-fi, so the actual overlap is closer to 7%—nearly 6 times higher than predicted.
In fact, these systems generally function well but struggle when heuristics fail to account for semantic correlations within the schema or data. As noted in an example by Lohman (2014), cardinality estimation is the dominant source of optimizer inefficiency because row-count misestimates propagate through the cost model and can lead to systematically poor choices of join order, access paths, and physical operators. This order-of-magnitude error leads to suboptimal physical plans that require substantial engineering effort to correct manually.
Is query optimization a solved problem?
The persistence of these estimation errors shows that physical planning is not a solved problem, particularly for complex OLAP workloads where functional dependencies are common.
To address this, we introduce DBPlanBench, a harness that exposes the query execution process of the Apache DataFusion engine. This system exposes the internal physical operator graph, including join strategies and partitioning schemes, to an LLM. The primary technical challenge here is the information density inherent in raw physical plans, which contain verbose file paths, partition metadata, and type encodings that fill up the context window quickly.
Without careful serialization, the entire plan can exceed 2M characters, making it impossible for LLMs to reason over the inputs effectively and efficiently. Our harness implements a serialization layer that traverses the engine's physical operator graph and maps heterogeneous objects into a unified, token-efficient JSON schema.
This representation deduplicates file-level statistics and removes execution-irrelevant fields, resulting in a payload approximately 10x smaller than the native serialization.
DBPlanBench thereby converts the optimization task from a statistical computation into a semantic reasoning problem, in which the LLM analyzes the plan's topology to identify logical flaws in join ordering.
To implement these fixes safely, we instruct the LLM to avoid regenerating an entire physical plan from scratch; instead, it applies targeted edits to DataFusion’s existing physical plan, reducing the risk of syntax errors or invalid plan topology. Concretely, the LLM generates JSON Patches (RFC 6902) that describe localized edits, such as swapping join sides or reordering nodes. These patches are orders of magnitude smaller than the full plan and are applied directly to the serialized graph, ensuring the structural integrity of the execution DAG.
A case study
The consequences of statistical estimation failures are measurable in both query latency and system resource consumption. In a specific query generated from a derived version of TPC-DS involving cross-channel sales, the default DataFusion optimizer prioritized joining a smaller item table (36K rows) before a larger date dimension table (73K rows), assuming the smaller join was cheaper. This heuristic failed to account for the high selectivity of the filter d_year=2001 on the date dimension. The LLM-optimized plan inverted this order, applying the date filter early to prune the sales fact table from 15.1 million rows to 2.9 million rows before subsequent joins.
This structural optimization resulted in a 4.78x speedup for the query. More significantly, the resource footprint decreased drastically. The optimized plan reduced the aggregate hash-table build time from 10.16 seconds to 0.41 seconds and slashed total build memory usage from 3.3 GB to 411 MB. The experiments showed that, on generated query workloads for TPC-H and TPC-DS, the median speedups hovered around 1.1x to 1.2x, and the method also delivered much larger gains on some complex multi-join queries, for example, speedups of up to 4.78×, with several others in the 1.5-1.7x range.
Evolutionary plan patching
We evolve query plans through iterative refinement. The system generates candidate improvements (via JSON patches) using GPT-5, validates each change, and keeps patches that reduce latency. Once these patches are applied, the system tries again to generate new candidates starting from the new plans. By building on successful optimizations across multiple steps, this evolutionary approach achieves better speedups than simply sampling many plans independently.
Not all queries can be effectively optimized, as the plans might already be optimal, but we find that in our sampled datasets, 60.8% of those queries could be optimized by more than 5%. The following figure shows the improvements on one of our derived datasets:
Transferring speedups across scale factors
The benchmarks we use expose a scale factor parameter that scales table cardinalities while keeping the underlying schema fixed. In practice, this lets us build a smaller prototype database (e.g., Scale Factor 3, or SF3) and a larger production-like database (e.g., SF10) that share the same structure but differ only in size.
Because exploring many candidate plans on full-scale data is expensive (each step requires executing the query plus paying and waiting for LLM-generated patches), we first discover good optimized plans on SF3 using evolutionary search. For each query, we then transfer the best SF3 plan to SF10 using a deterministic, rule-based script. This script matches scan operators across scales via normalized schema / projection / predicate signatures and rewrites the SF3 optimized plan into a runnable SF10 plan, preserving structural edits such as join reorderings and join-side swaps while enforcing safety checks (e.g., no dangling references, valid DAG topology).
Empirically, every optimized plan we selected at SF3 could be successfully transferred to SF10, and the resulting speedups closely tracked the original ones. This validates a practical “optimize small, deploy large” workflow: run the expensive search once on a compact replica of the workload, then lift the resulting plans to larger production databases with minimal additional engineering effort.
Conclusion
DBPlanBench establishes that LLMs can effectively function as semantic cardinality estimators to correct physical plan errors that statistical heuristics miss. By combining compact plan serialization with evolutionary patch search, the system achieves significant reductions in execution time and memory pressure without requiring changes to the core database engine. The harness and code are released as open-source for further research.
References
Lohman, G. Is query optimization a “solved” problem? ACM SIGMOD Blog, April 2014. URL: https://wp.sigmod.org/?p=1075. Accessed: 2026-01-26.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み