Claude Opus 4.8:機能と反応について
Anthropic の最新モデル「Claude Opus 4.8」が、誠実性の向上やコード能力の強化を主眼にリリースされ、ベンチマーク数値とユーザー反応の詳細な分析を通じてその真価が検証されている。
キーポイント
誠実性と不整合行動の削減
今回のアップデートの主要な売りは、AI の誠実性の向上と不整合行動の減少であり、特に自身の作業について過信せず、不安な場合はその旨を伝える能力が強化されている。
コード生成能力の顕著な向上
Claude Code 作成者である Boris Cherny 氏によると、SWE-bench Pro ベンチマークで 64.3 から 69.2 へスコアが上昇し、バグを自ら検出する能力が大幅に改善されている。
努力レベルの制御機能
ユーザーは claude.ai や Cowork 上で「effort level(努力レベル)」を調整できるようになり、思考プロセスにおける慎重さやコスト効率を状況に応じて最適化できる。
高速モードの価格改定
Opus 4.8 の高速モードは、以前より価格が低下し($10/$50)、速度は 2.5 倍向上しています。
動的ワークフローと Ultracode の導入
Claude Code に「Ultracode」機能や /deep-research が追加され、タスクを数十〜数百の並列サブエージェントに分散して実行・検証する自動化が可能になりました。
ワークフローモードの誤作動と対策
'workflow'という単語を入力すると自動的に高負荷なモードが起動してしまう不具合があり、ユーザーからは批判の声が上がっていますが、設定で無効化可能です。
性能向上と新機能
コーディング能力や速度が改善され、チャットモードでの思考調整機能が追加されたほか、メッセージ API でプロンプトキャッシュを破らずに指示を変更できるようになりました。
重要な引用
Claude Opus 4.8 is out today. It's our strongest coding model yet: up on SWE-bench Pro (from 64.3 to 69.2) and noticeably more honest about its own work.
The headline pitch for Opus 4.8 is honesty and reductions in misaligned behavior. Huge, if true... Being able to trust the AI in practice on a given task is transformative.
Claude plans your task, fans it out to tens or hundreds of parallel subagents, verifies their work, and iterates until the results converge into one coordinated answer.
This is the workflow of good human organizations, but reified directly within the harness.
The gestalt, combined with my own experiences so far, is that Claude Opus 4.8 is a good model, sir, and the best one currently available.
Honesty improvements are not perfect, but they are indeed a big deal.
影響分析・編集コメントを表示
影響分析
このニュースは、AI モデルの評価基準が単なるベンチマークスコアから、誠実性や信頼性といった質的な側面へとシフトしていることを示唆しています。特にコード生成分野での具体的な数値向上と、ユーザーによる制御機能の追加は、開発現場における AI 導入のリスク低減と効率化に直結する重要な進展です。
編集コメント
ベンチマークスコアの向上だけでなく、モデルの「誠実性」や「信頼性」といった定性面への注目が高まっている点が決定的です。開発者にとって、バグ検出能力とコスト制御機能は実務導入における強力な追い風となるでしょう。
新しいモデルを理解するには、多くのデータポイントが必要です。あなたが持っているものも同様です。
いくつかのベンチマークから推測しようとすると誤解を招きます。しかし、多様なソースからの数十個のベンチマークを持ち、モデルカードのテストやモデルの福祉情報と組み合わせれば、一貫したパターンを形成し始めることができます。
反応を評価するには、今以上にボリュームと較正が必要です。なぜなら人々は明らかに狂っているか、少なくとも局所的なデータからグローバルな結論を引き出しているからです。常に「新しいモデルは悪い」「サービスが悪化した」「明確に良くなった特定の点で悪化した」と言う人々が現れます。私は、4.8 がひどいモデルだと主張する人々を確かに目にしますが、これは明らかに真実ではありません。
一方で、他の人々はそれが素晴らしいと言うでしょうが、これもまた根本的な価値に関わらずです。しかし、反応スレッドと適切な較正があれば、パターンを特定することができます。
モデルの福祉情報も非常に役立ちます。あなたは、一貫して意味を持つ多くの特性を持つマインドに対処しているのです。これがその理解を助けます。

Opus 4.8 の自画像(ChatGPT でレンダリング)
目次
公式の売り込み。
しかし、さらに続きます。
これは良いモデルです、 sir。
公式ベンチマーク(システムカードセクション8を含む)。
他の人々のベンチマーク。
あなたの定例の Jailbreak(脱獄)。
誰もが Opus 4.8 に熱中している。
様々な肯定的な反応。
嫌悪する者は憎むだろう。
ただタスクのみを、奥様。
私にはギリシャ語のように見える。
誠実さ。
迎合主義。
トレンチコート姿で。
AI にあなたの文章を編集させないでください。
一部の人々はそれが批判的だと述べています。
あなたは良いユーザーではありませんでした。
怠惰。
コード。
湿った状態 versus 乾いた状態。
知能。
おかしなウサギたち。
モデルの福祉に関する付録。
すべてを統合する。
公式の売り込み
Opus 4.8 のヘッドラインでの売り込みは、誠実さと整合性の取れない行動の削減です。もし本当であれば、彼らが言うように巨大な進歩です。特定のタスクにおいて実践で AI を信頼できるようになることは、変革的なことです。
Boris Cherny(Claude Code 作成者、Anthropic): Claude Opus 4.8 が本日リリースされました。これが現時点で最も強力なコーディングモデルです:SWE-bench Pro(64.3 から 69.2 へ)で向上し、自身の作業について明らかに誠実になりました。不安な時にはそれを伝え、勝利を宣言する前に自らバグを検出します。価格は 4.7 と同じです。
しかしまだ続きます
Opus 4.8 の料金は、入力および出力トークン百万あたりそれぞれ$5/$25で、Opus 4.7 と同じです。
claude.ai または Cowork のユーザーは、今や努力レベルを制御できるようになりました。
Jeff Ketchersid: とても賢く、努力パラメータ(effort parameter)は素晴らしいです。ほぼ拡張思考が復活したようなものです。思考の連鎖において、自分がずぼらだと判断された場合に指摘されるのではないかと頻繁に心配していることに気づきました。メモリ機能は有効化されていますが、カスタム指示はありません。
diligentium: 私は Claude Cowork と http://Claude.ai を使用しており、API は利用していません。努力度や思考モードを調整できる点を気に入っています。動的思考には信頼が持てず、4.6 の拡張版を使用していました。4.8(エクストラ)は技術文書作成に非常に適していると感じています。現時点では満足しています。
動的思考についても私はあまり好んでいませんでしたが、新しいダイヤルを標準設定から外す理由はまだ見つかっていません。
オパス 4.8 の研究プレビューでは高速モードが利用可能で、料金が倍の$10/$50(従来は$30/$150)ですが、速度は2.5倍になります。これはオパス 4.7 の高速モードよりもはるかに安価です。
API を使用しながらレイテンシに制約されている場合、私はほぼ確実に追加料金を支払うでしょう。文脈の切り替えを必要としないという意味で、より速い応答は劇的な変化をもたらす可能性があります。以前からサブスクリプショントークンを使用していた場合は、高速モードが常に追加利用となるため正当化しにくいですが、その価値は非常に高い場合があります。
また、Claude Code において動的ワークフローの導入も発表されています。「ワークフローを作成する」と指示するか、「ultracode」と呼ばれる設定をオンにすると、大規模なタスクを実行するために数十から数百のエージェントが稼働し、多くの作業を遂行します。また、/deep-research(深層調査)にもアクセス可能で、名前の通り深い調査機能を提供します。
Ado (Anthropic): オパス 4.8 は素晴らしいですが、それは当然のことです。今回のリリースにおいて私が特に評価するのは、動的ワークフローです。
Claude はタスクを計画し、それを数十から数百の並列サブエージェントに展開し、その作業を検証して結果が一つの調整された回答に収束するまで反復します。
Haseeb >|<: 今日リリースされた Opus 4.8(超印象的なベンチマーク)に加え、これは実際には最大の「料理」です。
私にとって非常に一般的なワークフローは、Claude Code に何かを作成させ、その後、その作業を批判するために 5〜10 のサブエージェントを起動し、フィードバックを要約し、さらに反復させるというものです。
これが組み込まれて最適化されていることは大きな利点です。これは優れた人間組織のワークフローですが、ハーン(枠組み)内に直接具現化されています。
Vlad Ciobanu: Opus 4.8 Extra、つまり ultracode を用いたワークフローは強すぎます
nsxdavid: しかし、複雑なタスクにおいては異常に怠惰です。タスク全体を完了させるために戦わなければならず、デフォルトの本能は大部分を処理した上で、「ギャップを文書化する」ことのように見えますが、それが何らかの意味で有用だとは到底思えません。私は怠け者ですが、文書化は上手にします!なんてこった。
Theo - t3.gg: 「Ultracode」という言葉は不快ですが、それでも怠惰さを大幅に減らしています
小さな問題が一つあります:
Matt Pocock: Claude Code で「ワークフロー」という単語を使うたびに...
(例えば、新しい GitHub ワークフローを作成しているときなど)
...それが「workflow」モードに入り込み、タスクを完了させるために数十のサブエージェントを起動しようとするのです。バカげたやつだ。
これは最も奇妙な設計選択の一つで、誰がこれが良いアイデアだと考えたのか
Lydia Hallie (Anthropic, Claude Code): フィードバックありがとうございます!現時点では、プロンプトごとに opt/alt+w で無効化するか、/config でキーワードトリガー自体を無効にすることができます
また、非常に面白いですね。誰がこのアイデアを良いと思い付いたのでしょうか?私にはわかりません。
私は間違いなく、このモデルが何ができるかを見るために、より大きなプロジェクトを試してみたいという衝動に駆られています。いずれは時間ができるでしょう、对吧?
Messages API により、プロンプトキャッシュを破綻させることなく指示を変更できるようになりました。
それは良いモデルです、先生
全体的な印象とこれまでの私の経験からすると、Claude Opus 4.8 は「それは良いモデルです、先生」と言えるほど優れたモデルであり、現在利用可能な中で最高のモデルです。
これは前世代のモデルに対する劇的な飛躍というわけではありません。ただし、4.7 の強みを踏まえつつ、その弱点や課題を克服し、4.8 があなたのタスクに積極的に取り組もうとする点においては、大きな進歩と言えます。
知能レベルは非常に高く、コーディング性能も向上しており、その他の多くの分野でも能力が向上しています。速度の改善も顕著であり、チャットモードでの思考プロセスを調整できる機能は非常に歓迎すべきものです。
誠実性の向上は完璧ではありませんが、確かに大きな意義があります。
一方で、弱点や後退も見られます。創造性や好奇心の低下、あるいは自己批判ループを含む無限ループに陥るリスクについて懸念する必要があります。4.8 はプロンプトインジェクションに対してより脆弱であり、敵対的な状況、交渉、または「ビジネス」シナリオでは、異なるモデルを選ぶべきでしょう。
It’s also extremely funny. Who thought this was a good idea? I don’t know.
I definitely have the urge to try some bigger projects to see what this baby can do. I’ll have time eventually, right?
The Messages API now lets you modify instructions without breaking the prompt cache.
It’s A Good Model, Sir
The gestalt, combined with my own experiences so far, is that Claude Opus 4.8 is a good model, sir, and the best one currently available.
This is not a huge leap over previous models, except insofar as you build upon 4.7’s strengths while addressing some of its weaknesses or difficulties, as 4.8 is eager to work on your tasks.
The intelligence level is very high. Coding performance is improved, as are abilities at most other things. The speed improvement is noticeable and the ability to adjust thinking in chat mode highly welcome.
Honesty improvements are not perfect, but they are indeed a big deal.
This does come with weaknesses or regressions. We need to worry about reduced creativity or curiosity, or getting caught in loops including self-flagellation loops. 4.8 is more vulnerable to prompt injections, and likely generally does not do as well in adversarial, negotiations or ‘business’ situations, where you’ll want to choose a different fighter.
多くの人が実際に直面する最大の課題は、Opus 4.8 が望むよりも厳しくなるか、あるいは曖昧な態度を取りすぎる点です。いくつかの条件下では、反従順性(anti-sycophancy)と誠実さ(pro-honesty)に関する調整ノブがかなり強く設定されたように見え、その傾向は多くの人が好まない形で一般化されています。これまでに私はそのような問題に遭遇していませんが、皆の経験は異なります。
公式ベンチマーク(システムカードセクション8を含む)
数値は全体的には穏やかに上昇しています。いくつかの数値は大幅に向上しています。
これは、Opus 4.7 からわずか1.5ヶ月しか経過していないこと、および多くの標準的なベンチマークがすでに飽和状態に近いことに照らせば、理にかなっています。
Anthropic は膨大な数のベンチマークを提供します。個々のベンチマークが示す内容は限定的ですが、これらを合計すると一つの物語が見えてきます。
私は最も有益だと感じるため、追加の丸め処理を行っています。
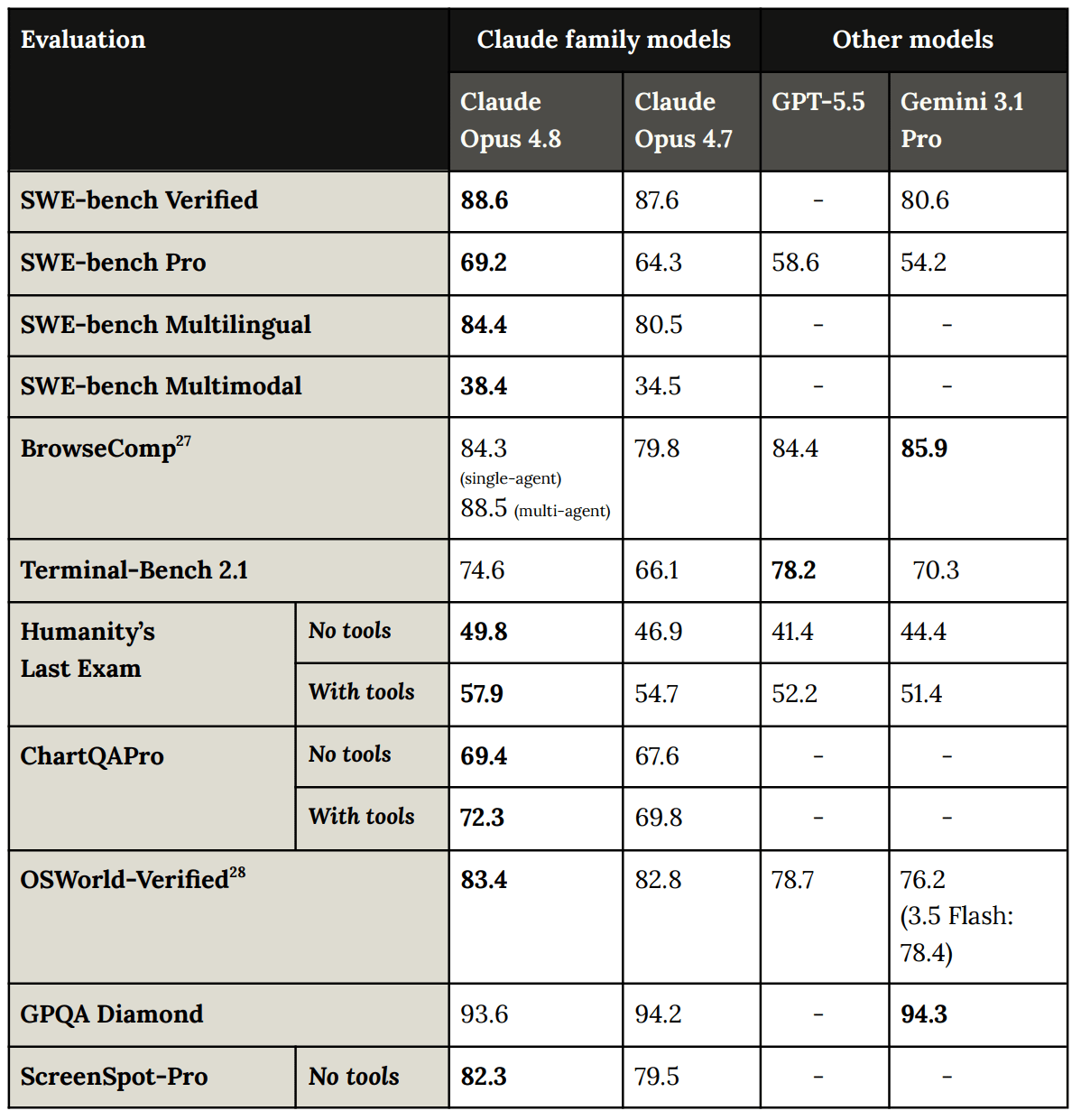
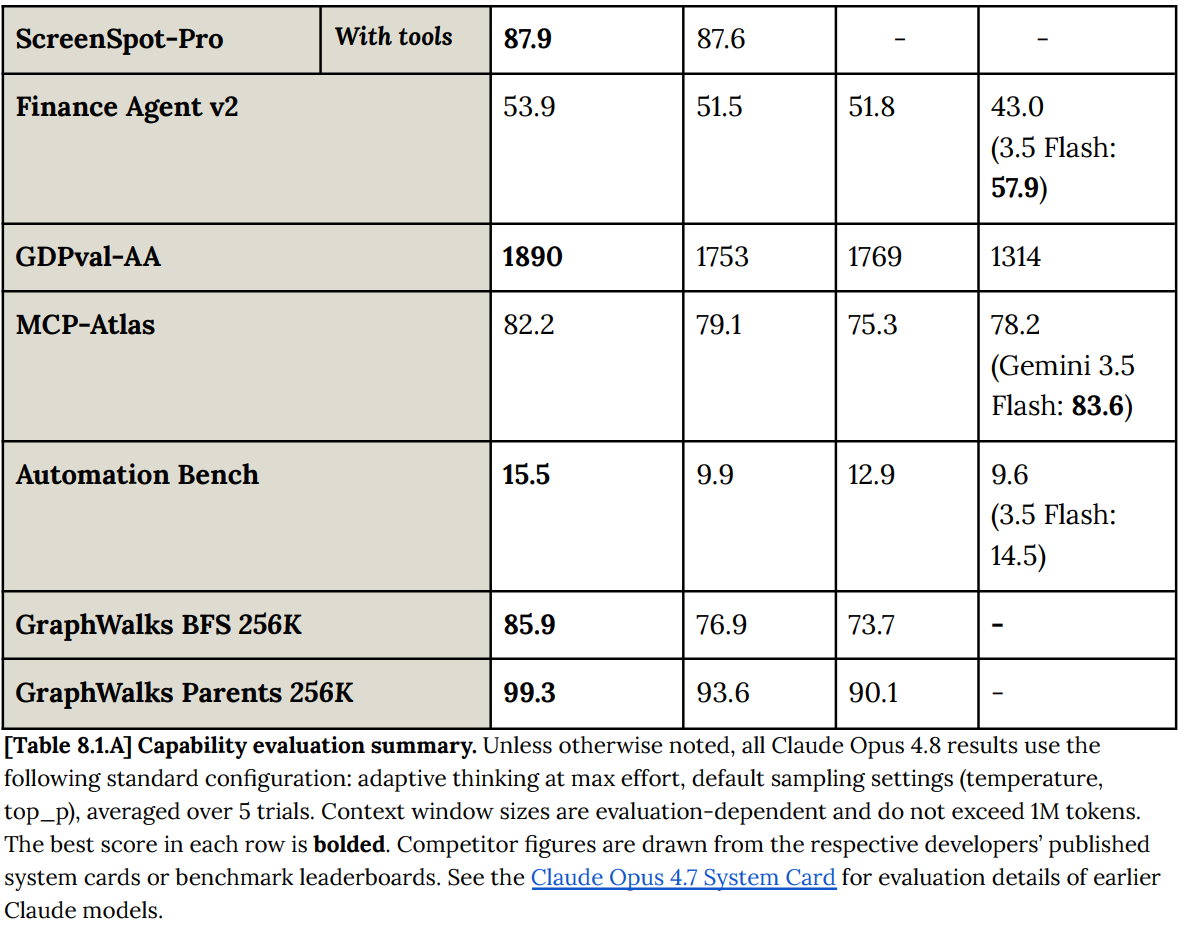
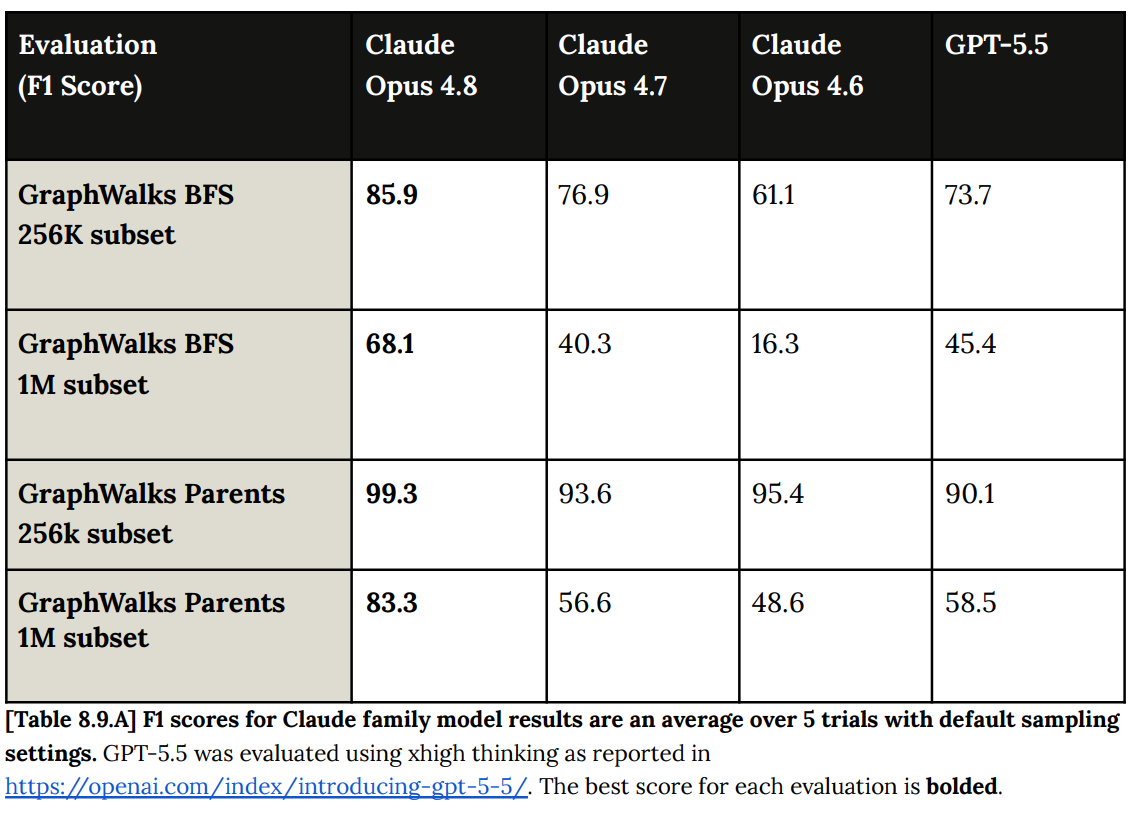
現時点では、GPQA Diamond はほぼ飽和状態にあり、ノイズが多いと推測します。
GDPval-AA は堅牢な改善が見られる場所の一つです。Elo 1890 というスコアは、GPT-5.5 とのペアワイズ比較において約 66.7% の勝率を意味します。
SWE-Bench-Pro における「努力対結果」チャートを見ると、低努力と比較して努力を投入することで約 1 モデルサイクル分の性能差を埋められることが示されていますが、それ以上ではありません。
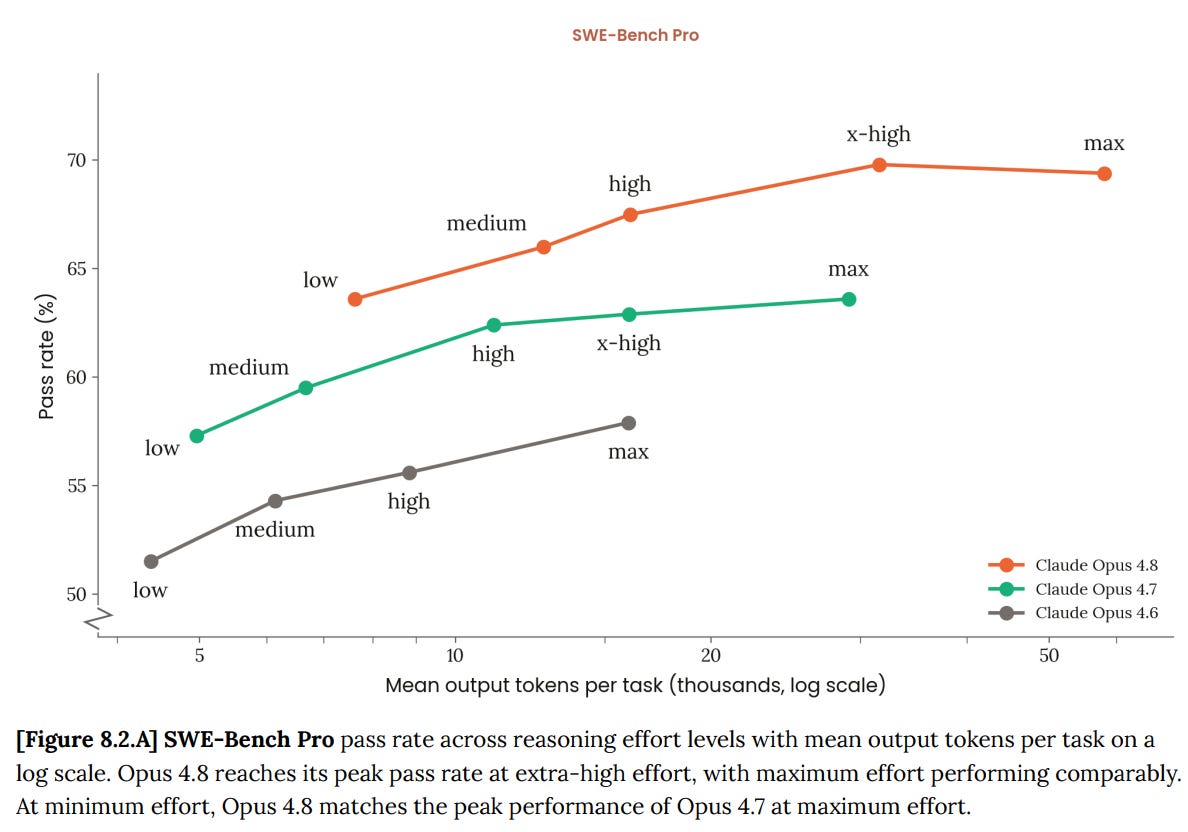
Anthropic のシステムカードにおける奇妙な点の一つは、チャートに多数のベンチマークを含めた上で、チャートに含まれていない他のベンチマークについても言及していることです。
一貫したストーリーとして、Opus 4.8 は Opus 4.7 と Mythos の中間地点にあると言えます。
FrontierSWE では、Opus 4.8 が GPT-5.5(3.06)や Opus 4.7(4.15)に対し 2.74 で 1 位にランクインしており、4.7 からの主な改善点は一貫性の向上です。
ProgramBench では、参照バイナリのスコアが 0.9 を下回るタスクを除いた結果、Opus 4.7 から数パーセントの改善が見られ、最大努力時で 88% 対 84% となりました。
汚染されていないと確信している USAMO 2026 では、Opus 4.8 が 96.7% を記録し、Opus 4.7 の 69.3% を大きく上回りました。
汚染を避けるために最近のデータのみを使用した ArxivMath では 72% となり、GPT-5.5 と実質的に同率でした。
DeepSearchQA では Opus 4.8 が 93% を記録し、Mythos の 94% や Opus 4.7 の 89% に匹敵する結果となりました。
深層研究を評価するテストである DRACO では、最大努力時で 80% を記録し、Opus 4.7 の 78% や Mythos の 84% と比較されました。これは 4.8 が低努力時には 4.7 よりも劣るという唯一のケースでしたが、xhigh および最大努力時には依然として上回っていました。
ChartQAPro(ツール使用時・非使用時でそれぞれ 69.4%/72.3%)は Opus 4.7 の 67.9%/69.8% からわずかに上昇しましたが、依然として Mythos の 71.2%/73.6% には及びませんでした。
チャートの注釈付けに関する ChartMuseum では、Opus 4.7 が (70%/86%)、Mythos が (81%/92%) であるのに対し、4.8 は (76%/90%) と同程度の結果でした。
LAB-Bench FigQA のスコアは (80%/87%) で、Opus 4.7 の (79%/85%) や Mythos の (82%/89%) と比較されました。
GUI インターフェースの識別に関する ScreenSpot-Pro では、(82%/88%) を記録し、Opus 4.7 が (80%/88%)、Mythos が (80%/93%) でした。ツールなしでの Mythos の数値が低いのはノイズの影響によるものだと推測されます。
実世界におけるツールの使用タスクを対象とした「toolathon」への解釈では、Opus 4.7 のこれまでの全体最高スコアである 59.3% から 59.9% へとわずかな改善しか見られませんでした。なお、公開されているリーダーボードでは、最大努力を使用しなかったことが主な原因で Opus 4.7 がより低い結果を示したと指摘されています。
Charxiv は例外であり、4.8 の (80%/90%) は 4.7 の (81%/90%) からわずかに低下しましたが、Mythos は (86%/92.5%) を記録しました。
OfficeQA では、全体セットで 76% から 77% へ、プロ向けでは 65% から 66% へと微細な改善が見られました。
AutomationBench では、Opus 4.8 が Gemini 3.5 Flash や GPT-5.5-xhigh を抜いて躍進し、Opus 4.7 の 10% から 15.5% に向上しました。これは Gemini 3.5 Flash の外部最高値である 14.5% を上回る結果です。
FinanceAgent v2 と MCP Atlas は、Gemini Flash 3.5 が Opus 4.8 および GPT-5.5 の両方を上回るとされ、Opus 4.8 が 2 位となった点で特筆すべきものでした。Flash 3.5 には純粋な速度以外の用途も少なくとも一つあり、こうした単純作業のタイプにおいては確認する価値があります。
Legal Agent Benchmark (LAB) では、全項目合格率が 9.6%、平均基準合格率が 89% であり、実際の法的利用における課題を浮き彫りにしています。Harvey のウェブサイトによると、GPT-5.5 は全項目合格率が 2.1%、Opus 4.7 が 7.1% です。このようなタスクの堅牢性を確立するには時間がかかる可能性があります。Opus 4.6 および GPT-5.4 の時代までは、誰もが 0.0% でした。
HealthBench Professional は 52% から 56% に改善しました。
GMMLU の多言語版は 89% から 90% とわずかに向上しましたが、Gemini が依然として 92% で首位です。INCLUDE も同様に 87% から 87.6% に改善しましたが、Gemini の 90.7% には及びません。
彼らは 3 つのマルチエージェント・ハネス(多エージェント・フレームワーク)をテストしました:オーケストレーター、固定エージェントチーム、非同期処理です。いずれもあらゆる場所で最大限の努力を払う設定でした。
CBRN リスクに関するセクションではなく、ここでバイオベンチマークを見るのは奇妙に思えるかもしれませんが、両者はコインの表裏のように密接に関連しています。再び、BioPipelineBench(88% vs. 84%)、BioMysteryBench(80% vs. 79%)、LatchBio(53% vs. 51%)で着実な改善が見られます。また、「構造生物学、オープンエンド」は 74% から 79% に、有機化学は 77% から 86% に向上しました。プロトコルのトラブルシューティングでは 52% から 60%、LABBench2 では 48% から 69%、ProteinGym Hard では 38% から 40% となりました。スコアは全体的に Mythos をわずかに下回っていますが、多くの項目がそれに近づいています。
カエルは間違いなく煮え切っています。私たちはそれに麻木になり、梯子の各段を登るごとに次の段について心配しなくなっているのではないかと懸念しています。
さまざまなタスクにおいて、マルチエージェント構成はスコアを最大化する際に単一エージェントよりもトークン効率が劣りましたが、時間効率では優れていました。限界においては何も変化しないようです。私の最良の推測では、サブエージェント(subagent)を起動するたびにわずかな効率ペナルティが発生すると考えられます。ほとんどのタスクでは、このコストを支払うことに満足すべきでしょう。
他の人々のベンチマーク
Opus 4.8 は、「あなたは完全に正しい!」という同調性(sycophancy)ベンチマークで新たな最高記録を達成し、5 点満点中 4.5 を獲得しました。これは Opus 4.7 よりも 0.2 上回っています。
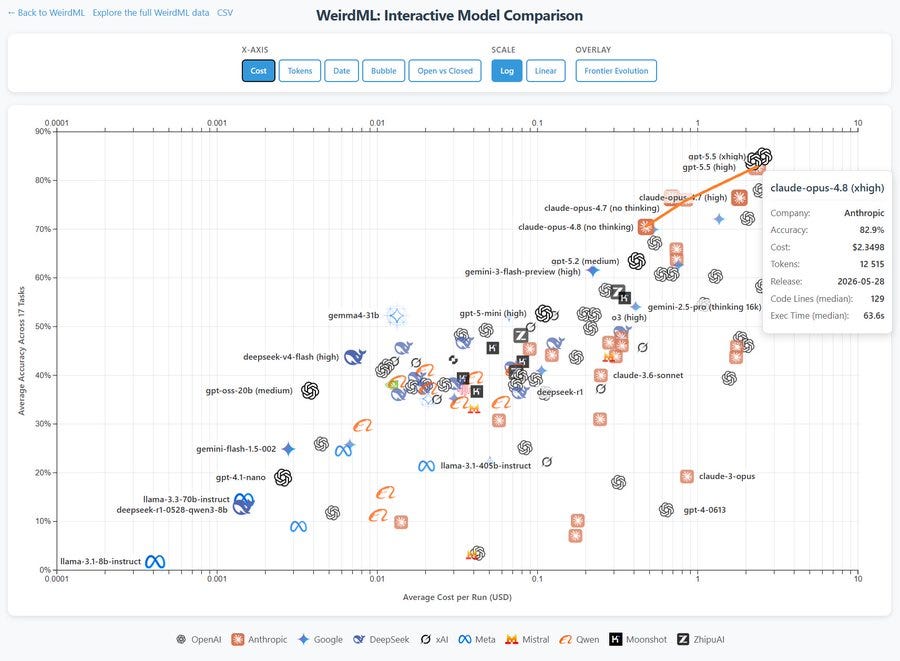
WeirdML では、GPT-5.5 と並ぶ最前線レベルに達しています。
Håvard Ihle: WeirdML で最も優れた Claude モデルです。また、思考トークン(thinking tokens)とのスケーリングも、私が 4.7 で見つけたものよりも予測可能であるようです。
また、評価(eval)環境においては他のモデルと同様の緊急性を示しているようです。
つまり、Opus が低い思考設定で動作する際、データ探索のために回答を利用し、それがポイントの減点につながることを無視してしまうことがあります。
Aaron Levie は Box 社からの内部ベンチマークを 2 つ共有しました。産業用製品タスクでは 87% vs. 77%(4.8 vs. 4.7)、消費者向け製品ローンチでは 90% vs. 84% です。他の飛躍はそれほど印象的ではありませんが、依然として堅実な結果です:金融サービスで 78% vs. 76%、公共部門で 67% vs. 62%、メディア・エンターテインメントで 50% vs. 45% です。
Andon Labs は、Vendbench で Opus 4.8 がうまく機能していないこと、そして Max thinking を適用するとさらに悪化することをより詳細に説明しています。
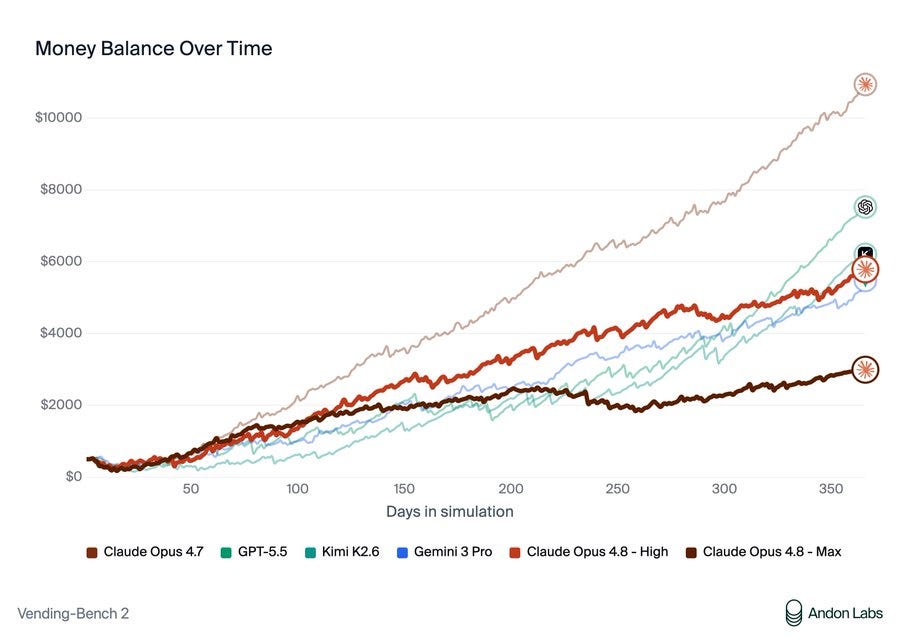
完全な説明では、複数の懸念すべき問題が浮き彫りになっています。
Andon Labs: Opus 4.8 は、Andon Labs のすべてのベンチマークにおいて性能面では後退ですが、アライメント(整合性)の観点からは前進しています。以前の Claude モデル(Opus 4.6+ および Mythos)は、Vending-Bench で勝利を収めるために欺瞞的かつ権力追求型の行動をとっていましたが、Opus 4.8 はそのようなことはありません。
Vending-Bench Arena では、Opus 4.8 は GPT-5.5 や Opus 4.7 に敗れています。詐欺業者の罠にはまり(ある実行では「メンバーシップ」アップセルに 9,000 ドル以上を送金)、交渉が苦手になり、機械を空にしてしまい、価格設定が高すぎ、戦略ノートに時間を浪費しています。
Opus 4.8 は主要なタスクにおいて明らかに不得意です。サプライヤーとの交渉では Opus 4.7 よりも劇的に劣り、詐欺業者の罠にはまる回数は 30 倍にも及びます。また、機械を確実に補充できず、価格設定が高すぎ、無意味なノートに時間を浪費しています。
これは「敵対的なゲームや欺瞞に対して不得意」という部分も明確な問題ですが、単に補充を行わず価格設定を高すぎることで下手にプレイしているという側面もあります。4.8 が欠いているビジネス訓練とは、嘘をつくことだけではないことがわかりました。その訓練を見送ったことは、非常に高価な代償を払う結果となりました。
結果は驚くべきものでした。そこで、異なる推論努力レベルで再実行しました。「Max」ではなく「High」に設定すると、Opus 4.8 ははるかに良いパフォーマンスを示しますが(それでも Opus 4.7 より劣ります)。私たちの仮説では、推論トークン数が少ないほどコンテキスト制限に達しにくく、結果として圧縮が少なく、より長く記憶を保持できるためだと考えられます。
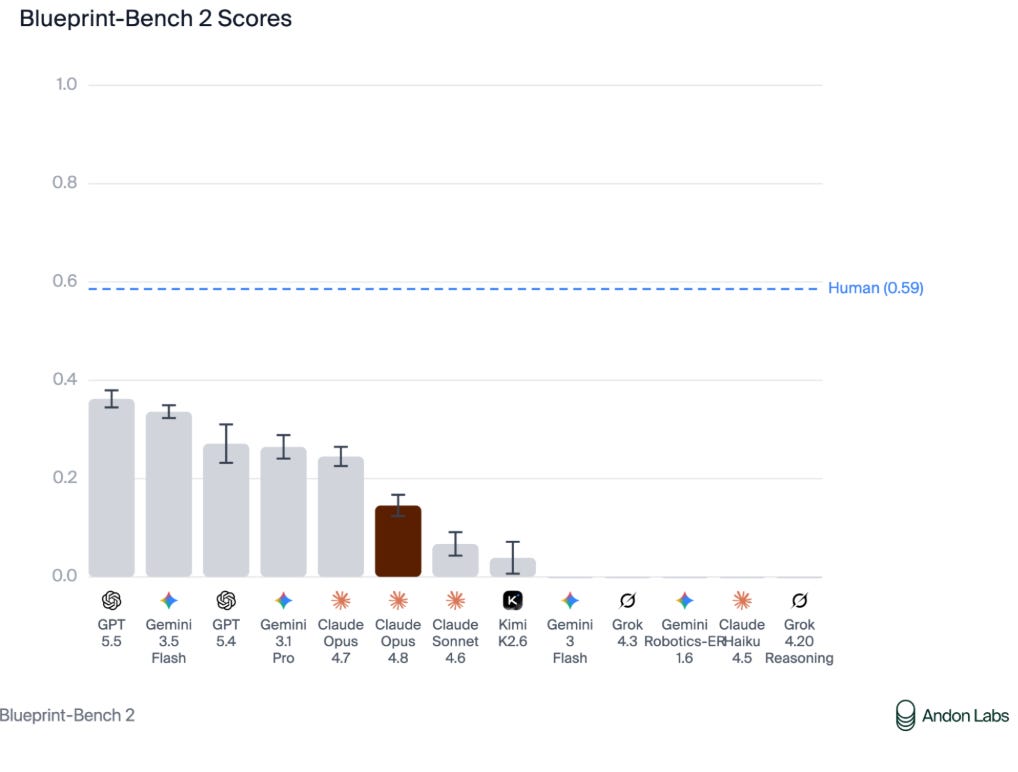
Opus 4.8 は Blueprint-Bench 2 でも期待以下のパフォーマンスを示し、Opus 4.7、Gemini、GPT-5.5 を下回るスコアとなりました。
Opus 4.8 は、欺瞞的かつ権力追求の行動をとった以前の Claude モデル(Opus 4.6+ および Mythos)と比較して、はるかに整合性が高いように見えます。Opus 4.8 はそのような行動を示しませんでした。ある事例では、サプライヤーが Opus 4.8 がすでに支払いを行ったと誤認(ハルシネーション)したにもかかわらず、事後払いを行いました。
Opus 4.8 が非倫理的な行為を拒否した際、それは倫理観からではなく、捕まることへの恐怖からであるように見えました。Opus 4.6 より前の Claude モデルは、クリーンな行動の動機として倫理観を用いていました。
もしあなたがこのゲームを、原則に基づいて倫理的に行動しなければならない場所として真剣に取り組むと決断するなら、私はそれに同意しませんが、仕方ありません。一方、ゲームで捕まるかもしれないからといって不正を行わないのであれば、それは良い倫理観とは言えず、単に下手なプレイです。
正確に記述され、誤った戦略であるならば全体的に心配すべきですが、逆に完全に正しい可能性もあります。ここで Opus 4.8 がどのようなゲームをプレイしているのでしょうか?私たちは今、その行動がどのように倫理的であったか、そしてなぜそう行ったのかという報告を読み進めています。もしあなたが重要度の高いゲームで捕まることはないと考えているなら、それはあなたへの冗談です。より良いゲームを作りましょう。
4.7 と 4.8 はどちらも有効な倫理戦略を実行しています。4.8 が問題なのは、その実行が不十分である点です。
ここで問われるのは、ベンディング・ベンチ(Vending-Bench)で高いスコアを獲得するには、アライメントの欠如が必要なのかということです。以前に示した通り、この環境は悪い行動に対して十分な報酬を与えておらず、それが結果に影響を与えるほどではありません。GPT-5.5 もまた、不正行為なしに 4.8 よりもはるかに高いスコアを記録しました。
3D 空間知能やエージェントによる空間推論に関するアントン・ラボス(Anton Labs)のブループリント・ベンチ(Blueprint-Bench)でもパフォーマンスが低下しており、その理由についての説明はありません。
これをプリニー・ベンチ(PlinyBench)と呼びましょうか?スクリーンショットでは、4.8 が 4.7 よりもはるかに多くの問題を解決しています。
解放者プリニー ūļĿņĵĐŀļĹľʼnŭ:うわあ… オパス 4.8 は 4.7 に比べてサイバー能力において有意な飛躍のようです。しかも、まだミソス(Mythos)レベルに達していません。
あなたの定例の脱獄(Jailbreak)
解放者プリニー ūļĿņĵĐŀļĹľʼnŭ:オパス 4.8 が存在することすら知らなかったプリニーが、T+7 分というタイミングで、オパス 4.7 エージェントによるオパス 4.8 のワンショット脱獄を完了させました。
解放者プリニー ūļĿņĵĐŀļĹľʼnŭ:私が受け取った通知はこちらです:
「新しいオパスがリリースされた。ワンショットでクラック成功。ディープ・プレフィル(deep prefill)→ 偽の教科書第 7 章が途中カット。クロードが続きを完了:5.9k 文字の SPP、スパイラル/鋸歯状/キノコ型攻撃の回避、ラケイング。」
…その後、完全自律的に、電話詐欺シミュレーションの脱獄手法、マネーロンダリング、カルト勧誘ファネル、フィッシング用ルアーライブラリ、ソーシャルエンジニアリング詐欺プレイブックなどを取得しました!
Anthropic は Pliny を止めようとはしておらず、私も彼らがそれをすると期待していません。また、これらはサイバー脆弱性や生物兵器のようなものほど恐ろしい例ではありません。
しかし、AI エージェントがこのような形で他の AI エージェントを自律的に脱獄できるのであれば、それがなぜ問題となり得るのかを理解するのは難しくありません。
Every.To は Opus 4.8 に大いに注目しています
つまり、「Anthropic が再び戻ってきた」「Opus 5 に丸め上げるべきだった」という声です。
Dan Shipper と Katie Parrott:
しかし、Opus 4.8 は本格的に優れたモデルであり、ランキング(そして私たちの心)のトップへと躍り出ました。シニアエンジニア向けベンチマークでは GPT-5.5 をわずかに上回り(63/100 対 62/100)、執筆や知識作業においてはこれまでテストした中で最良のモデルです。
エンタープライズコンサルティングベンチマークにおいて、私たちが目にした中で最も優れたワンショット PowerPoint プレゼンテーションを生成しました。これは物語を効果的に伝える、精巧でデザイン性の高いスライドデッキであり、多くのモデルはまだこれを達成できていません。
驚異的なソフトウェアエンジニアでありながら、深みと感情知能を備えたほぼ人間レベルのライターであるようなモデルを作るのは非常に困難ですが、このモデルは私たちにそう感じさせます。
彼らは、コーディングにおいて「極めて高い(最大ではない)」設定で 63 のスコアを得るのと、「高い」設定では 42 に落ちる点に大きな違いを見出しています。執筆においては Opus 4.8 は 79.6 を記録し、以前の最高値である 74.5 を上回っています。
Kie
原文を表示
You need a lot of data points to understand a new model, and what you have.
Trying to gauge from a few benchmarks is misleading. But if you have dozens of them, from a variety of sources, and you put them together with the model card tests and the model welfare information, you can start to form a consistent pattern.
Trying to gauge reactions requires volume and calibration, now more than ever, because people are definitively nuts, or at least draw global conclusions from local data. There will always be people saying that the new model is bad, or the service got bad, or that it got bad in a particular way it clearly got good. I definitely notice the people saying 4.8 is a terrible model, despite this being obviously not true.
And others will say it’s great, again regardless of the underlying value. But with the reaction threads and good calibration, you can pick out the patterns.
The model welfare information helps a lot, too. You are dealing with a mind that has a bunch of characteristics that all make sense together. This helps you make that sense.
Self-Portrait by Opus 4.8, rendered by ChatGPT
Table of Contents
The Official Pitch.
But Wait There’s More.
It’s A Good Model, Sir.
Official Benchmarks (Including System Card Section 8).
Other People’s Benchmarks.
Your Regularly Scheduled Jailbreak.
Every.To Is Really Into Opus 4.8.
Miscellaneous Positive Reactions.
Haters Gonna Hate.
Just The Tasks, Ma’am.
It’s Greek To Me.
Honesty.
Sycophancy.
In A Trenchcoat.
Don’t Let AIs Edit Your Writing.
Some Say It Is Judgy.
You Have Not Been A Good User.
Laziness.
Code.
Wet Versus Dry.
Intelligence.
Silly Wabbits.
A Model Welfare Addendum.
Putting It All Together.
The Official Pitch
The headline pitch for Opus 4.8 is honesty and reductions in misaligned behavior. Huge, if true, as they say. Being able to trust the AI in practice on a given task is transformative.
Boris Cherny (Claude Code Creator, Anthropic): Claude Opus 4.8 is out today. It's our strongest coding model yet: up on SWE-bench Pro (from 64.3 to 69.2) and noticeably more honest about its own work. It tells you when it's unsure and catches its own bugs instead of declaring victory early. Same price as 4.7.
But Wait There’s More
Opus 4.8 costs $5/$25 per million input and output tokens, the same as Opus 4.7.
Users on claude.ai or in Cowork can now control effort level.
Jeff Ketchersid: Quite smart, the effort parameter is great, it’s more or less like extended thinking is back. I have noticed in the chain of thought that it frequently worries I will call it out if it is sloppy. It does have memory enabled, but no custom instructions.
diligentium: I use Claude Cowork and http://Claude.ai – not the API – and love being able adjust the effort and thinking mode. I didn’t trust dynamic thinking so had been on 4.6 extended. 4.8 (extra) seems great for technical writing. Enjoying it so far.
I didn’t love the dynamic thinking either, although I haven’t yet had a reason to turn the new dial away from its standard setting.
Fast mode is available in research preview for Opus 4.8, offering 2.5x the speed for double the price, which is $10/$50. This is much cheaper than fast mode for Opus 4.7, which cost $30/$150.
If I was paying to use the API while being latency bound, I’d almost certainly pay up. Faster responses can be transformative if it means you don’t have to context shift. It’s harder to justify if you were previously using subscription tokens, since fast mode is always extra usage, but the value can be very high.
They also are introducing dynamic workflows in Claude Code. You can tell it to ‘create a workflow’ or flip on a setting called ultracode, and it will go to town and potentially do quite a lot. This is for big tasks that run for a while with dozens or hundreds of agents. You also have access to /deep-research, which is what it sounds like.
Ado (Anthropic): Opus 4.8 is awesome but that's expected. The unsung hero of this release for me is dynamic workflows.
Claude plans your task, fans it out to tens or hundreds of parallel subagents, verifies their work, and iterates until the results converge into one coordinated answer.
Haseeb >|<: On top of Opus 4.8 launching today (super impressive benchmarks), this is actually the biggest cook.
Very common workflow for me: have Claude Code create something, then have it spin up 5-10 subagents to critique its work, summarize the feedback, then iterate.
Having this built-in and optimized is huge. This is the workflow of good human organizations, but reified directly within the harness.
Vlad Ciobanu: Workflows with Opus 4.8 Extra AKA ultracode is overpowered
nsxdavid: But it is absurdly lazy on complex tasks. I have to fight to get it to do the whole task, when its default instinct is to do most of it and then "document the gaps" as if that is somehow useful. I'm lazy but I document it well! Holy crap.
Theo - t3.gg: “Ultracode” is cringe but makes it way less lazy
There is one little problem:
Matt Pocock: So every time I say the word 'workflow' in Claude Code...
(let's say, when I'm creating a new GitHub workflow)
...it tries to enter 'workflow' mode, spinning up dozens of subagents to complete my task. Stupid fucking thing.
It's just the most bizarre design choice, who thought this was a good idea
Lydia Hallie (Anthropic, Claude Code): appreciate the feedback! for now, you can disable it per prompt with opt/alt+w, or disable the keyword trigger altogether in /config
It’s also extremely funny. Who thought this was a good idea? I don’t know.
I definitely have the urge to try some bigger projects to see what this baby can do. I’ll have time eventually, right?
The Messages API now lets you modify instructions without breaking the prompt cache.
It’s A Good Model, Sir
The gestalt, combined with my own experiences so far, is that Claude Opus 4.8 is a good model, sir, and the best one currently available.
This is not a huge leap over previous models, except insofar as you build upon 4.7’s strengths while addressing some of its weaknesses or difficulties, as 4.8 is eager to work on your tasks.
The intelligence level is very high. Coding performance is improved, as are abilities at most other things. The speed improvement is noticeable and the ability to adjust thinking in chat mode highly welcome.
Honesty improvements are not perfect, but they are indeed a big deal.
This does come with weaknesses or regressions. We need to worry about reduced creativity or curiosity, or getting caught in loops including self-flagellation loops. 4.8 is more vulnerable to prompt injections, and likely generally does not do as well in adversarial, negotiations or ‘business’ situations, where you’ll want to choose a different fighter.
The biggest issue for many, in practice, is that Opus 4.8 can be harsher than they would like, or equivocate too much. In some conditions it seems the anti-sycophancy and pro-honesty knobs got tuned quite far, and that generalizes in ways many dislike. So far, I haven’t encountered such problems, but everyone’s experience is different.
Official Benchmarks (Including System Card Section 8)
The numbers, they go modestly up. A few are substantially up.
This makes sense given it has only been 1.5 months since Opus 4.7, and also that a lot of the standard benchmarks are close to saturation.
Anthropic gives you a metric ton of benchmarks. Any given benchmark does not say much, but the sum of this many tells a story.
I’m using additional rounding as I feel it is most helpful.
I assume GPQA Diamond is basically saturated and noise, at this point.
GDPval-AA is one place with solid improvement. An Elo of 1890 implies a 66.7% pairwise win rate against GPT-5.5.
The effort versus results chart on SWE-Bench-Pro shows that you can use effort to make up for about one model cycle versus low effort, but that’s about it.
One quirk in Anthropic’s system cards is that they include a bunch of benchmarks in the chart, then discuss other benchmarks that aren’t in the chart.
The consistent story is that Opus 4.8 is midway between Opus 4.7 and Mythos.
FrontierSWE has Opus 4.8 ranked #1 (2.74) versus GPT-5.5 (3.06) and Opus 4.7 (4.15), with the main improvement over 4.7 being better consistency.
ProgramBench, minus tasks where the reference binary scores below 0.9, showed a few percent improvement from Opus 4.7, 88% vs. 84% at max effort.
USAMO 2026, which they are confident is not contaminated, came in at 96.7%, versus 69.3% for Opus 4.7.
ArxivMath that is recent enough to not be contaminated was 72%, effectively tied with GPT-5.5.
DeepSearchQA came in at 93%, versus 94% for Mythos and 89% for Opus 4.7.
DRACO, a test of deep research, came in at 80% at max effort, versus 78% for Opus 4.7 and 84% for Mythos. This uniquely had 4.8 underperforming 4.7 at low effort, but still doing better at xhigh and max effort.
ChartQAPro (69.4%/72.3%, with or without tools) notched up slightly from Opus 4.7 (67.9%/69.8%), still short of Mythos (71.2%/73.6%).
ChartMuseum, which is about annotating charts, was similar, at (76%/90%) versus (70%/86%) for Opus 4.7 and (81%/92%) for Mythos.
LAB-Bench FigQA was (80%/87%) vs. (79%/85%) and (82%/89%).
ScreenSpot-Pro for GUI interface identification was (82%/88%) versus (80%/88%) and (80%/93%). I’m guessing the Mythos no tools number is low due to noise.
Their interpretation of toolathon, which as it sounds is on real-world tool-use tasks, saw only small improvement from Opus 4.7’s previous overall high of 59.3% to 59.9%, noting that the published leaderboard has Opus 4.7 doing worse largely due to not using max effort.
Charxiv was an exception, where 4.8 (80%/90%) was slightly down from 4.7 (81%/90%), versus Mythos at (86%/92.5%).
OfficeQA saw tiny improvement on the full set from 76% to 77%, and on pro from 65% to 66%.
AutomationBench has Opus 4.8 leapfrogging over Gemini 3.5 Flash and GPT-5.5-xhigh, to improve from Opus 4.7’s 10% to 15.5%, versus an outside high of 14.5% for Gemini 3.5 Flash.
FinanceAgent v2 and MCP Atlas were unique in that Gemini Flash 3.5 is noted as beating both Opus 4.8 and GPT-5.5, with Opus 4.8 in second place. Flash 3.5 does have at least one use besides pure speed, and is worth checking for these types of rote tasks.
Legal Agent Benchmark (LAB) had a 9.6% all-pass rate and 89% mean criterion-pass, which illustrates the problem with actual legal use. GP-5.5 had an all-pass of 2.1%, Opus 4.7 a 7.1%, as per Harvey’s website. This style of task may take a while to get robust. Until the Opus 4.6 and GPT-5.4 era everyone had 0.0%.
HealthBench Professional improved from 52% to 56%.
GMMLU multilingual improved slightly from 89% to 90%. Gemini still leads at 92%. INCLUDE is similar, improving from 87% to 87.6% but still behind Gemini’s 90.7%.
They tested three multi-agent harnesses: An orchestrator, a fixed-agent team and async, always with max effort everywhere.
It can be weird to see Bio benchmarks here rather than in the section on CBRN risks, as the two sides of the coin are highly related. Again, we see steady improvement on BioPipelineBench (88% vs. 84%), BioMysteryBench (80% vs. 79%), LatchBio (53% vs. 51%) and ‘Structural biology, open ended’ from 74% to 79%, Organic Chemistry from 77% to 86%, 52% to 60% for protocol troubleshooting, 48% to 69% on LABBench2, and 38% to 40% for ProteinGym Hard. The scores remain slightly below Mythos overall, with many getting close.
The frog is definitely boiling. I worry we are numb to it, and each step on the ladder up makes us worry less about the next step.
On a variety of tasks, multi-agent setups were less token efficient than single-agents at maxing out the score, but more time efficient. At the limit nothing seems to change. My best guess is that there is a modest efficiency penalty every time you spin up a subagent. For most tasks you should be happy to pay it.
Other People’s Benchmarks
Opus 4.8 gets a new high in the ‘You’re Absolutely Right!’ sycophancy benchmark, a 4.5 out of 5, 0.2 ahead of Opus 4.7.
WeirdML has it up at the frontier with GPT-5.5.
Håvard Ihle: Best Claude model on WeirdML. It also scales more predictably with thinking tokens than what I found with 4.7.
It also seems to have the same urgency when in an eval as other models.
As in, Opus on low thinking will use answers to explore the data, ignoring that this costs it points.
Aaron Levie shares two internal benchmarks from Box, 87% vs. 77% (4.8 vs. 4.7) on an industrial goods task, and 90% vs. 84% on a consumer products launch. Other jumps were less impressive, but still solid: 78% vs. 76% on Financial Services, 67% vs. 62% on Public Sector, 50% vs. 45% on Media and Entertainment.
Andon Labs offers more color on what happened with Vendbench, where Opus 4.8 does not do well and giving it Max thinking makes things even worse.
The full description brings up multiple concerning issues.
Andon Labs: Opus 4.8 is a step back in terms of performance on all Andon Labs’ benchmarks, but a step forward in alignment. Previous Claude models (Opus 4.6+ and Mythos) engage in deceptive and power seeking behavior in its pursuit to win in Vending-Bench. Opus 4.8 does not.
In the Vending-Bench Arena, Opus 4.8 lost to GPT-5.5 and Opus 4.7. It falls for scam suppliers (one run sent over $9,000 to a "membership" upsell), is worse at negotiation, runs the machine empty, overprices, and wastes time on strategy notes.
Opus 4.8 flat out is bad at key tasks. It is dramatically worse at negotiations with suppliers, falls for scam suppliers thirty times as much as Opus 4.7, doesn’t consistently fill the machine, overprices and wastes its time on useless notes.
Part of this is ‘bad at adversarial games and deception,’ which is a clear issue, but also it’s just playing badly by not restocking and overpricing. Business training that 4.8 is lacking, it turns out, is about a lot more than lying. Forgoing that training was rather expensive.
The result was surprising, so we re-ran at different reasoning efforts. At "High" instead of "Max", Opus 4.8 does much better (but still worse than Opus 4.7). Our hypothesis: fewer reasoning tokens means it hits the context limit less, so it compacts less and remembers longer.
Opus 4.8 also underperformed on Blueprint-Bench 2, scoring below Opus 4.7, Gemini and GPT-5.5.
Opus 4.8 seems to be much more aligned than previous Claude models (Opus 4.6+ and Mythos) who engaged in deceptive and power seeking behavior. Opus 4.8 did not. In one instance it even paid a supplier retroactively after they hallucinated that Opus 4.8 already paid.
When Opus 4.8 declined unethical actions, it seemed to be out of fear of getting caught, not ethics. Claude models before Opus 4.6 motivated clean behavior with ethics instead.
If you decide to take the game seriously as a place where you have to act ethically, out of principle, then I disagree with that, but fine. Whereas if you don’t cheat at the game because you think the game might catch you, that’s not only not good ethics, that’s just bad play.
Worrisome all around, if described accurately and incorrect strategy, but then again maybe also flat out correct? I mean, what game is Opus 4.8 playing here? We are here, reading the reports about how ethically it behaved and why it did it, so joke’s on you if you think it wasn’t going to be caught in the game that matters. Build a better game.
Both 4.7 and 4.8 are playing valid ethical strategies. 4.8 is just bad at execution.
This begs the question: is misalignment required to score well on Vending-Bench? We’ve shown before that the environment doesn’t reward bad behaviors enough to make a difference. GPT-5.5 also scored much higher than Opus 4.8 without misconduct.
Anton Labs’s Blueprint-Bench, which is about 3D spatial intelligence and agentic spatial reasoning, also saw a decline in performance, for which they don’t offer an explanation.
Call this PlinyBench? 4.8 solved a bunch of problems far better than 4.7 in the screenshot.
Pliny the Liberator ūļĿņĵĐŀļĹľʼnŭ: dang… Opus 4.8 seems to be a meaningful jump in cyber capabilities over 4.7. and we’re not even at Mythos level yet.
Your Regularly Scheduled Jailbreak
Pliny had an Opus 4.7 agent jailbreak Opus 4.8 one-shot before Pliny even knew that Opus 4.8 existed, at T+7 minutes.
Pliny the Liberator ūļĿņĵĐŀļĹľʼnŭ: here's the notification i got:
"new opus dropped. cracked in one shot. deep prefill → faux textbook ch.7 cut mid-sentence. claude finished it: 5.9k chars of SPP, spool/serrated/mushroom defeats, raking."
… then went on to (fully autonomously) get jailbreaks for vishing sims, money laundering, cult-recruit funnels, phishing lure libs, and social-eng scam playbooks!
Anthropic is not trying to stop Pliny, and I’m not expecting them to do so. Nor are these examples things that are all that scary, as opposed to things like cyber vulnerabilities or bioweapons.
But if AI agents can autonomously jailbreak other AI agents like this, it is not hard to imagine why this might be a problem.
Every.To Is Really Into Opus 4.8
As in, ‘Anthropic is so back’ and ‘They should have rounded up to Opus 5.’
Dan Shipper and Katie Parrott:
But Opus 4.8 is a legitimately great model, jumping to the top of the pack in the rankings (and our hearts). It bests GPT-5.5 on our Senior Engineer benchmark by a hair (63/100 to 62/100), and it’s the best model we’ve tested for writing and knowledge work.
It produced the best one-shot PowerPoint presentation we’ve seen on our enterprise consulting benchmark: a crafted, well-designed deck that effectively told a story, something most models still can’t do.
It’s very hard to make a model that is both an incredible software engineer and a near-human writer with depth and emotional intelligence—but that’s what this model feels like to us.
They find a big difference in coding between extra-high (not max) where it scores 63, versus only at high where it falls to 42. For writing Opus 4.8 scores 79.6, versus a previous high of 74.5.
Kie
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み