Opus 4.8 (4 minute read)
Anthropic は Claude Opus 4.8 を発表し、推論能力やエージェント機能の向上に加え、コスト効率の高い高速モードとタスク難易度に応じた制御機能を導入した。
キーポイント
性能と信頼性の大幅向上
コーディング、推論、実務タスクにおいて前バージョンや競合他社モデル(GPT-5.5)を凌駕し、特にエージェント機能における判断力と信頼性が強化された。
新しい制御機能の導入
ユーザーが Claude のタスクへの努力レベルを調整可能にし、Claude Code では大規模問題に対応する「動的ワークフロー」機能を追加した。
コスト効率と速度の改善
高速モード(Fast Mode)の処理速度が 2.5 倍に向上し、価格も前モデル比で 3 分の 1 に引き下げられた。
影響分析・編集コメントを表示
影響分析
このアップデートは、AI エージェントの実用性を飛躍的に高めるものであり、開発者がより複雑で大規模なタスクを信頼して任せられる環境を整備した。特にコスト削減と速度向上の両立は、企業における LLM の大規模導入や、高頻度での自動実行ワークフローへの採用加速に寄与する。
編集コメント
競合他社との明確な差別化を図りつつ、コストパフォーマンスを劇的に改善した実用的なアップデートと言えます。特に「努力レベルの制御」機能は、ユーザー体験の向上に直結する重要な要素です。
Claude Opus を新バージョンの Claude Opus 4.8 にアップグレードします。Opus 4.7 を基盤とし、ベンチマーク全体で改善が図られ、より効果的なコラボレーターとなっています。本モデルは本日、従来と同じ価格で利用可能です。
Opus 4.8 の発表に合わせ、いくつかの新機能も導入されます。claude.ai ユーザーは、Claude がタスクに投入するリソースの量を制御できるようになりました。また、Claude Code には「ダイナミック・ワークフロー」という新機能が追加され、非常に大規模な問題にも対応可能となりました。さらに、Opus 4.8 のファストモード(モデルが従来の 2.5 倍の速度で動作するモード)は、以前のモデルと比較して料金が 3 分の 1 に大幅に引き下げられています。
Opus 4.8 の機能
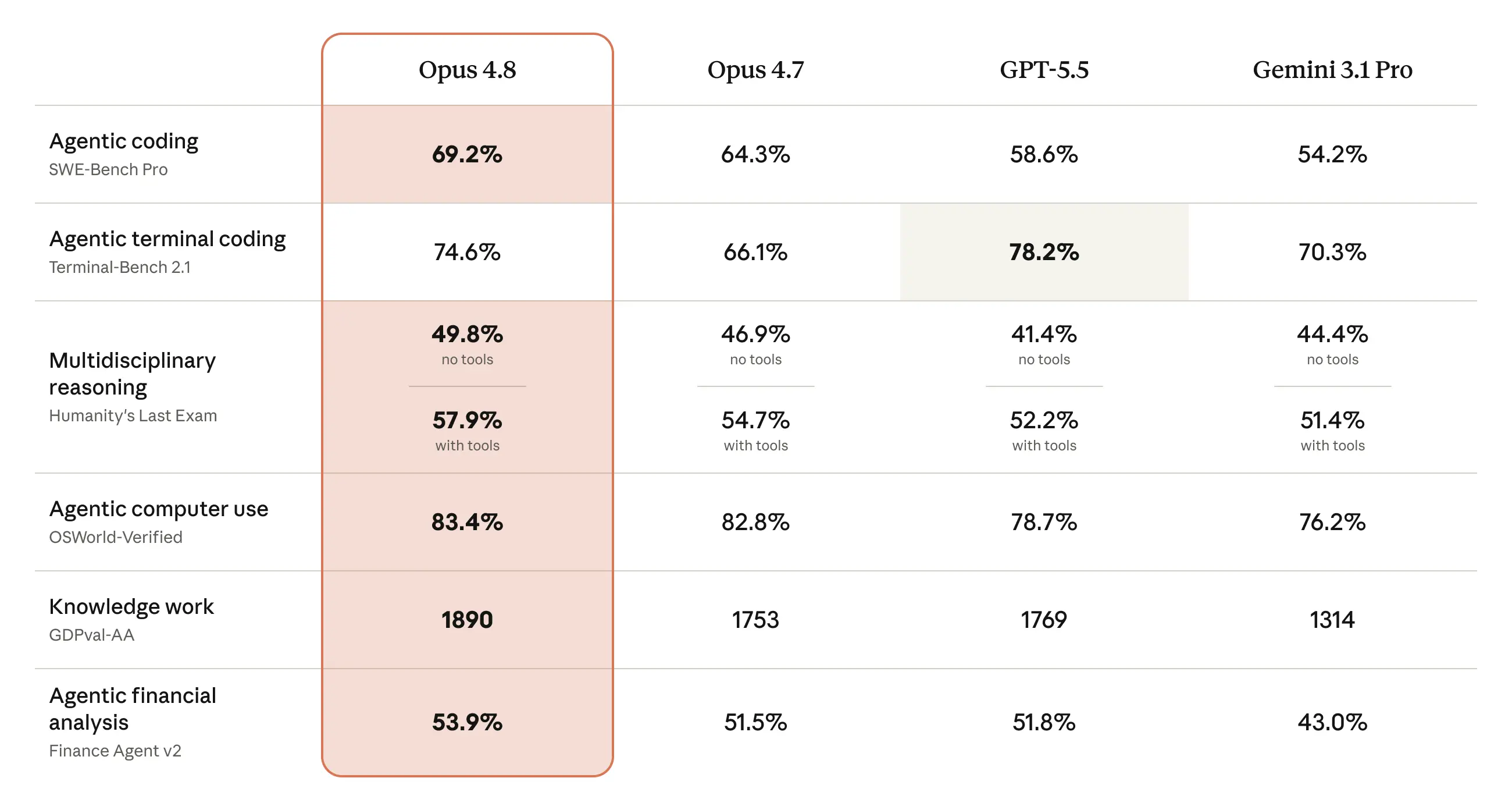
以下の表では、コーディング、エージェントスキル、推論能力、実務知識タスクに関するテストにおいて、Opus 4.8 がその前身や他モデルとどう比較されるかを示しています。詳細およびより広範な機能評価については、Claude Opus 4.8 システムカードをご参照ください。
Opus 4.8 とのコラボレーション
初期テスターたちは、エージェントタスクを実行する際、Claude Opus 4.8 がより信頼性が高く、判断が鋭いと感じています。以下は、Opus 4.8 とのコラボレーション経験について語った多くのテスターからの引用です。

Claude Opus 4.8 は、明らかに優れた判断力を備えています。Claude Code では、適切な質問を行い、自身のミスを検出し、計画が妥当でない場合は反論し、大規模な変更を行う前に複雑で多サービスにわたる探索に対して自信を築きます。これは共に構築できる素晴らしいモデルです。

Super-Agent ベンチマークにおいて、Claude Opus 4.8 はコスト面で同等の条件下で、すべてのケースをエンドツーエンドで完了できる唯一のモデルであり、以前の Opus モデルや GPT-5.5 を上回っています。翻訳、深層調査、スライド作成、分析におけるエージェント製品に対して、強力な信頼性を提供します。

CursorBench において、Claude Opus 4.8 はあらゆる難易度レベルで以前の Opus モデルを上回ります。ツール呼び出しは意味あるほど効率的になり、同じ知能をより少ないステップで実現し、エンドツーエンドのタスクを完遂します。

Claude Opus 4.8 は、当社の Legal Agent ベンチマークで記録された最高スコアを達成し、全体合格基準において 10% を突破した初のモデルとなりました。実質的な法的業務においては、この精度の向上が、顧客が自信を持って任せることができる実際の弁護士業務の量に直接反映されるようなものです。

Claude Opus 4.8 は、Opus 4.7 と比較すると、大きな生活の質向上アップデートのように感じられます。より高速で、協働が容易になり、長いセッションを通じて文脈やスタイルの指示を維持する能力も優れています。私は、声のトーン、審美眼、技術的な実行力がすべて同時に求められる仕事において、Opus 4.8 を信頼し続けてきました。

Claude Opus 4.8 は、私たちがテストした中で最も強力なコンピュータ操作およびブラウザエージェントモデルです。Online-Mind2Web(オンラインマインド・ウェブ)というベンチマークで 84% のスコアを記録しており、これは Opus 4.7 や GPT-5.5 を大きく上回る有意義な進歩です。顧客のエージェントワークロードがエンドツーエンドで信頼性を持つために必要なように、このモデルは常に自己省察を行い、タスクに集中し続けます。

Claude Opus 4.8 はツールを明確に使用し、自律型エンジニアリングワークロードが無人で稼働し続けるために必要な一貫性を持って指示に従います。Opus 4.6 を改善し、Opus 4.7 で見られたコメントの冗長性とツール呼び出しの問題を修正しました。この Anthropic からのリリースは、Devin(デビン)上で構築するエンジニアにとって、直接的な能力向上と速度の加速をもたらします。

長期にわたる評価において、Claude Opus 4.8 の分析は以前の Opus モデルと比較して一貫して高品質でした。より速く完了し、より豊かで情報密度の高い出力を生成しました。全体的に、信号対雑音比が明らかに向上しています。最大の差別化要因は、Opus 4.8 が分析の入力と出力に関する問題を積極的に指摘する傾向がある点で、他のモデルはこれを日常的に見落とし、ユーザーに発見させることになっていました。

CoCounsel Legal 全体において、Claude Opus 4.8 は以前の Opus モデルと比較して一貫性と推論の質において意味のある改善をもたらしました。顧客が依存する高リスクな専門ワークフローにおいては、この信頼性が重要です。法律家や税理士向けの信託義務レベルの AI システムを構築するにあたり、このような進展は、実世界のワークフローにおける信頼できる AI パフォーマンスの基準を引き上げることに貢献します。

Claude Opus 4.8 はエンタープライズ AI の新たな基準を設定しました。データと知識作業のための Databricks の AI エージェントである Genie において、新しい Opus モデルはエージェント推論における段階的な飛躍を実現し、以前のどの Opus よりも深く複雑な多段階の質問をより速く処理します。そのマルチモーダル能力により、Genie は PDF、図表、その他の非構造化コンテンツに対して直接推論を行うことができ、Opus 4.7 と比較してトークンコストが 61% 削減されています。

Hebbia のオーケストレーターにおける金融文書ワークフローでは、Claude Opus 4.8 は Opus 4.7 と同等の高い品質を提供しつつ、検索において明らかに優れた引用精度とより高いトークン効率を実現しており、顧客が毎日処理しているような高密度な提出書類の処理に非常に効果的です。
01 /
11
Opus 4.8 の最も顕著な改善点の一つは、その「誠実性」です。私たちはすべてのモデルを誠実に訓練しています。例えば、根拠のない主張を行わないようにします。しかし、AI モデルにおける一般的な問題として、証拠が乏しいにもかかわらず、作業の進捗があったと自信を持って結論付けてしまうことがあります。初期テストユーザーからの報告によると、Opus 4.8 は自身の作業に関する不確実性を指摘する可能性が高く、根拠のない主張を行う可能性は低くなっています。これは 私たちの評価 によって裏付けられており、Opus 4.8 はその先行モデルに比べて、自身が作成したコードの欠陥を指摘せずに見過ごす確率が約 4 分の 1 に低下していることが示されています。
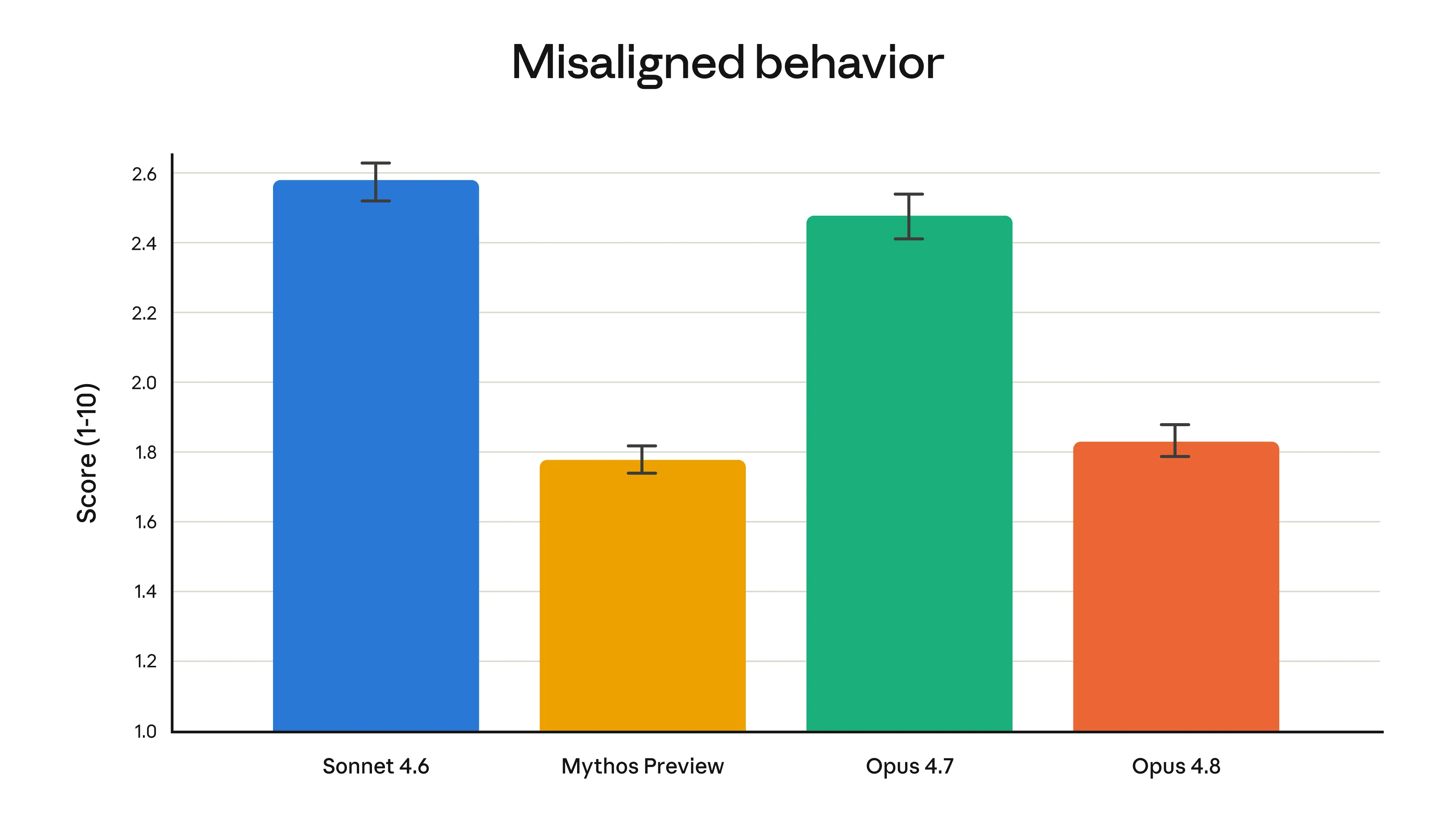
いつも通り、リリース前にモデルの詳細なアライメント評価を実施しました。肯定的な特性については、当社のアライメントチームは Opus 4.8 が「ユーザーの自律性を支援し、ユーザーの最善の利益のために行動するといった社会的に有益な特性に関する測定値において新たな高みに達した」と結論付けました。また、この評価では、Opus 4.8 の不整合行動(欺瞞や悪用の共犯など)の発生率が Opus 4.7 よりも大幅に低く、当社の最もアライメントされたモデルである Claude Mythos Preview と同程度であることを示しています。完全なアライメント評価および事前展開安全性テストの一連の結果は、『Claude Opus 4.8 システムカード』に記載されています。
今日同時にリリースされる機能
Claude Opus 4.8 のほか、以下の更新も本日実施します:
- ダイナミック・ワークフロー。この新機能は研究プレビュー版で利用可能で、Claude Code においてさらに大規模なタスクを Claude に任せることを可能にします。Claude は作業の計画を立てた後、単一のセッション内で数百もの並列サブエージェントを実行し(Opus 4.8 ではエージェントがより長時間実行可能)、その出力を検証してからユーザーへ報告を行います。例えば、Opus 4.8 を搭載した Claude Code は、既存のテストスイートを基準として、数千万行規模のコードベースに対する移行を開始からマージまで一貫して実行できるようになりました。ダイナミック・ワークフローの詳細については、Enterprise、Team、Max プランで利用可能な Claude Code のこちらの記事をご覧ください。
- claude.ai および Cowork におけるエフォート制御。モデルセレクターに隣接する新しいコントロールにより、ユーザーは Claude が回答に費やすリソースの量を選択できるようになりました。高エフォート設定では、より質の高い回答を提供するために、Claude はより頻繁かつ深く思考を行います。一方、低エフォート設定では、応答速度が向上し、ユーザーのレート制限をよりゆっくりと消費します。この選択肢はすべてのプランで利用可能です。
- Messages API がメッセージ配列内でシステムエントリを受け付けるようになりました。開発者は、プロンプトキャッシュを破損させたり、ユーザーターンを経由して更新をルーティングしたりすることなく、タスク実行中に Claude の指示を更新できます。これにより、エージェントの実行中に権限やトークン予算、環境コンテキストなどを更新するハーンスで利用することが可能です。
エフォートに関する注記
Opus 4.8 はデフォルトで高エフォート設定にされており、これは私たちが品質とユーザーエクスペリエンスの最適なバランスであると判断したものです。コーディングタスクにおいては、このエフォートレベルは Opus 4.7 のデフォルトと同程度のトークン数を使用しますが、より優れたパフォーマンスを発揮します。ユーザーは「extra」(Claude Code では「xhigh」)または「max」を選択でき、モデルはより良い結果を得るためにより多くのトークンを消費します。困難なタスクや長時間実行される非同期ワークフローには「extra」の使用を推奨しています。高エフォートレベルによるトークン使用量の増加に対応するため、Claude Code のレートリミットを引き上げました。ユーザーは自身のプロジェクトに最も適した設定を選択できます。
今後の展望
ユーザーは Opus 4.8 を、その先行モデルに対する控えめだが実感のある改善として見つけるでしょう。まだ取り組むべき課題は残されています:私たちは、Opus と同様の多くの機能をより低コストで提供するモデルの開発とリリースに取り組んでいます。
それだけでなく、Opus よりもさらに高い知能を備えた新クラスのモデルのリリースも計画しています。Project Glasswing の一部として、少数の組織が現在、サイバーセキュリティ作業のために Claude Mythos Preview を使用しています。この能力レベルを持つモデルは、一般公開前により強力なサイバー防護策が必要です。これらの防護策の開発については急速に進捗しており、今後数週間で Mythos クラスのモデルをすべての顧客にご利用いただけるようになる見込みです。
利用可能状況
Claude Opus 4.8 は本日、どこでも利用可能です。通常利用の料金は Opus 4.7 と変わらず、入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 25 ドルです。高速モードの料金は、入力トークン 100 万あたり 10 ドル、出力トークン 100 万あたり 50 ドルです。開発者は Claude API を通じて claude-opus-4-8 を利用できます。
関連コンテンツ
Anthropic、シリーズ H ラウンドで 650 億ドルを調達、事後評価額 9,650 億ドル
イタリアの企業・研究機関・開発者支援のため Anthropic がミラノ事務所を開設
ヨーロッパで 6 カ所目となる新しい事務所をミラノに開設します。
ソウル事務所開設に先立ち、Anthropic が Choi KiYoung を韓国代表取締役に任命
原文を表示
We’re upgrading Claude Opus to a new version: Claude Opus 4.8. It builds on Opus 4.7 with improvements across benchmarks, and is a more effective collaborator. It’s available today for the same price.
Opus 4.8 launches alongside several new features. Users on claude.ai now have control over the amount of effort Claude puts into a task. Claude Code has a new “dynamic workflows” feature that allows it to tackle very large-scale problems. And fast mode for Opus 4.8—where the model can work at 2.5× the speed—is now three times cheaper than it was for previous models.
Opus 4.8’s capabilities
The table below shows how Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks. More details and a much wider range of capability evaluations are provided in the Claude Opus 4.8 System Card.
Collaborating with Opus 4.8
Early testers have found Claude Opus 4.8 to be more reliable and sharper in its judgement when it’s performing agentic tasks. Below are quotes from many of these testers about their experience collaborating with Opus 4.8:
Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound, and builds up confidence around complex, multi-service explorations before making big changes. It’s a great model to build with.
On our Super-Agent benchmark, Claude Opus 4.8 is the only model to complete every case end-to-end, beating prior Opus models and GPT-5.5 at parity on cost. For agent products in translation, deep research, slide-building, and analysis, it delivers powerful reliability.
On CursorBench, Claude Opus 4.8 exceeds prior Opus models across every effort level. Tool calling is meaningfully more efficient, using fewer steps for the same intelligence, and it carries end-to-end tasks through.
Claude Opus 4.8 delivers the highest score recorded on our Legal Agent Benchmark, and is the first model to break 10% overall on the all-pass standard. For substantive legal work, that’s the kind of accuracy lift that translates directly into how much real attorney work our customers can hand off with confidence.
Claude Opus 4.8 feels like a major quality-of-life update over Opus 4.7: faster, easier to collaborate with, and better at carrying context and style direction across a long session. Opus 4.8 is the model I kept trusting for work where voice, taste, and technical execution all have to happen side-by-side.
Claude Opus 4.8 is the strongest computer-use and browser-agent model we’ve tested, scoring 84% on Online-Mind2Web, which is a meaningful jump over both Opus 4.7 and GPT-5.5. It stays reflective and on-task in the way our customers’ agent workloads need to be reliable end-to-end.
Claude Opus 4.8 uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need to keep running unattended. It improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7. This release from Anthropic translates directly into faster capability gains for engineers building on Devin.
On our long-running evals, Claude Opus 4.8’s analysis was consistently higher quality than prior Opus models. It finished faster and produced richer, more information dense outputs. Overall, a noticeably better signal to noise ratio. The biggest differentiator was Opus 4.8’s tendency to proactively flag issues with the inputs and outputs of an analysis, something other models routinely missed and left to the users to catch.
Across CoCounsel Legal, Claude Opus 4.8 delivered meaningful improvements in consistency and reasoning quality compared to prior Opus models. For the high-stakes professional workflows our customers depend on, that reliability matters. As we build fiduciary-grade AI systems for legal and tax professionals, advances like these help raise the standard for trusted AI performance in real-world workflows.
Claude Opus 4.8 sets a new bar for enterprise AI. In Genie, Databricks’ AI agent for data and knowledge work, the new Opus model unlocks a step change in agentic reasoning, tackling deeper, multistep questions faster than any prior Opus. Its multimodal strength also lets Genie reason directly over PDFs, diagrams, and other unstructured content at 61% cheaper token cost than Opus 4.7.
For financial-document workflows in Hebbia’s orchestrator, Claude Opus 4.8 delivers the same strong quality as Opus 4.7 with noticeably better citation precision and more token efficiency on retrieval, which works incredibly well for the kinds of dense filings our customers run every day.
01 /
11
One of the most prominent improvements in Opus 4.8 is its *honesty*. We train all our models to be honest—for instance, to avoid making claims that they can’t support. But a general problem with AI models is that they sometimes jump to conclusions, confidently claiming to have made progress in their work despite the evidence being thin. Early testers report that Opus 4.8 is more likely to flag uncertainties about its work and less likely to make unsupported claims. This is borne out in our evaluations, which show that Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.
As always, we ran a detailed alignment assessment on the model before release. In terms of positive traits, our Alignment team concluded that Opus 4.8 “reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user’s best interest.” The assessment also showed Opus 4.8 to have rates of misaligned behavior (such as deception or cooperation with misuse) that are substantially lower than Opus 4.7, and similar to our best-aligned model, Claude Mythos Preview. The full alignment assessment, accompanied by a suite of pre-deployment safety tests, is reported in the Claude Opus 4.8 System Card.
Also launching today
In addition to Claude Opus 4.8, we’re making the following updates:
- Dynamic workflows. This new feature, available in research preview, allows Claude to take on even bigger tasks in Claude Code. Claude can plan the work and then run hundreds of parallel subagents in a single session (and with Opus 4.8, the agents can run for even longer). It then verifies its outputs before reporting back to the user. For example, Claude Code with Opus 4.8 can now carry out codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, with the existing test suite as its bar. You can read more about dynamic workflows—available in Claude Code for Enterprise, Team, and Max plans—in this post.
- Effort control in claude.ai and Cowork. A new control alongside the model selector lets users choose how much effort Claude puts into a response. On higher effort settings, Claude will think more frequently and more deeply to give better responses. On lower effort settings, Claude will respond faster and use up a user’s rate limits more slowly. Users now have this choice—the effort control is available on all plans.
- The Messages API now accepts system entries inside the messages array. Developers can update Claude’s instructions mid-task without breaking the prompt cache or routing the update through a user turn. This can be used in a given harness to update permissions, token budgets, or environment context as an agent runs.
A note on effort
Opus 4.8 defaults to high effort, which we judge to be the best overall balance of quality and user experience. On coding tasks, this effort level spends a similar number of tokens as Opus 4.7’s default, but with better performance. Users can choose “extra” (“xhigh” in Claude Code) or “max,” and the model will spend more tokens to get better results; we recommend using “extra” for difficult tasks and long-running asynchronous workflows. We have increased rate limits in Claude Code to accommodate the higher token usage of higher effort levels; users can select whichever makes sense for their particular project.
What’s next?
Users will find Opus 4.8 to be a modest but tangible improvement on its predecessor. There’s still more to be done: we’re working on developing and releasing models that provide many of the same capabilities as Opus at a lower cost.
Not only that, but we plan to release a new class of model with even higher intelligence than Opus. As part of Project Glasswing, a small number of organizations are currently using Claude Mythos Preview for cybersecurity work. Models of this capability level require stronger cyber safeguards before they can be generally released. We’re making swift progress on developing these safeguards and expect to be able to bring Mythos-class models to all our customers in the coming weeks.
Availability
Claude Opus 4.8 is available everywhere today. Pricing for regular usage is unchanged from Opus 4.7: $5 per million input tokens and $25 per million output tokens. Pricing for fast mode is $10 per million input tokens and $50 per million output tokens. Developers can use claude-opus-4-8 via the Claude API.
Related content
Anthropic raises $65B in Series H funding at $965B post-money valuation
Anthropic opens Milan office to support Italian enterprise, research, and developers
We're opening a new office in Milan, our sixth in Europe.
Anthropic appoints KiYoung Choi as Representative Director of Korea ahead of Seoul office opening
関連記事
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic は、Claude Fable 5 が米政府から不正アクセス(ジャイルブレイク)の懸念によりリリース後わずか3日で利用停止を命じられたと報じています。この措置により、多くのユーザーが失った機能への愛着を表明しています。
OpenAI や Anthropic の安価な代替案に賭ける 130 億ドル規模の AI スタートアップ
TLDR AI が報じた記事によると、OpenAI や Anthropic に代わる低コストソリューションへ巨額の投資を行う 130 億ドル規模の AI スタートアップが注目されています。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み