monday Service と LangSmith を組み合わせた、初日からコードファーストの評価戦略の構築
monday Service は LangSmith と連携することで、開発初期段階からコードベースでの評価戦略を確立し、AI アプリケーションの品質保証プロセスを強化した。
キーポイント
開発初期からの評価戦略
monday Service はプロジェクト開始当初(Day 1)から LangSmith を活用し、コードベースで評価を行う戦略を採用している。
品質保証プロセスの強化
開発サイクルの早期に自動評価を導入することで、AI アプリケーション全体の品質と信頼性を向上させた。
LangChain エコシステムの活用
LangChain Blog で発表されたこの連携により、LangSmith の機能を活用した実践的な評価手法が示されている。
影響分析・編集コメントを表示
影響分析
このニュースは、AI アプリ開発における「評価(Evaluation)」の重要性を再認識させるものであり、単なる最終検証ではなく開発ライフサイクル全体に組み込むべき要素であることを示唆しています。特に、LangSmith という具体的なツールを用いた実装例が提示されることで、開発現場での即座の適用可能性が高まっています。
編集コメント
開発初期段階からの評価導入は、AI アプリの品質担保において極めて重要なベストプラクティスです。LangSmith の活用事例として、実務家にとって非常に参考になる具体的なアプローチが示されています。

*これは、顧客対応型 AI サービスエージェントの評価戦略を推進している私たちの友人である *[Monday.com からのゲスト投稿です。グループ・テックリードの Gal Ben Arieh が率いています。ご協力ありがとうございます!]*
多くのチームは評価を最終段階の確認として扱いますが、私たちはこれを「Day 0(開発初期)」の必須要件としました。
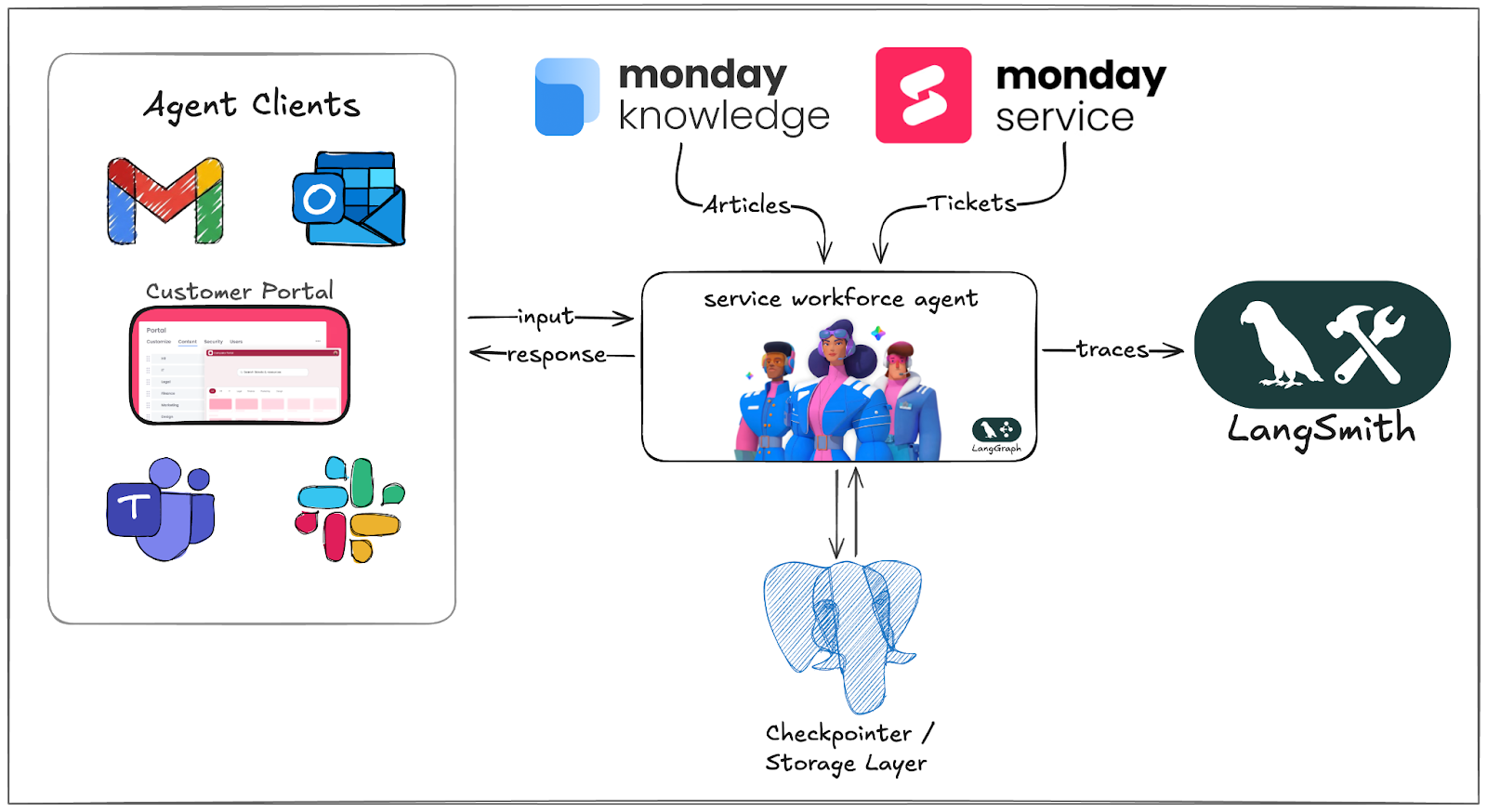
monday Service は、すべてのサービス部門にわたる問い合わせの自動化と解決を目的とした、AI ネイティブなエンタープライズ・サービス管理(ESM: Enterprise Service Management)プラットフォームです。新しい AI サービスワーカーフォース(チケット負荷を人間のリプレゼンタティブから引き受ける、カスタマイズ可能でロールベースの AI エージェントによる workforce)を構築する際、私たちは Alpha ユーザーにギャップを発見してもらうのを待つのではなく、開発サイクルの最初から評価を組み込みました。
この記事では、ユーザーが問題に気づく前に AI の品質課題を検出するための、評価駆動型開発フレームワーク(evals-driven development framework)をどのように構築したかをご紹介します。
私たちが達成したこと:
- スピード:評価フィードバックループが 8.7 倍高速化(162 秒から 18 秒へ)。
- カバレッジ:数時間かかる代わりに、数百の例に対して数分で包括的なテストを実行可能。
- エージェント観測性:マルチターン評価器(Multi-Turn Evaluators)を活用し、本番環境のトレース上でリアルタイムかつエンドツーエンドの品質モニタリングを実現。
- 評価コード化:GitOps スタイルの CI/CD デプロイメントにより、バージョン管理された本番コードとして評価ロジックを管理。
AI サービスワーカーは、カスタマイズ可能なLangGraph ベースの ReAct エージェントであり、あらゆるエンタープライズサービス管理ユースケースにおける問い合わせの自動化と解決を目的として設計されています。
IT、HR、または法務といった分野に適用する場合でも、monday Service の顧客は独自のKB 記事(知識ベース記事)やツールを活用することで、あらゆるサービス部門での実行を推進するようエージェントを調整できます。
しかし、ReAct エージェントをこれほど強力にする自律性こそが、独自の課題も生み出します。推論チェーンの各ステップが直前の結果に依存するため、プロンプトやツール呼び出しの結果におけるわずかな逸脱が、著しく異なる— かつ潜在的に誤った— 結果へと連鎖(カスケード)してしまう可能性があるからです。
評価の二大支柱
エージェント評価のベストプラクティスに関する調査を通じて、私たちは即座に、二層構造のアプローチが必要であることを認識しました:
オフライン評価 — 「セーフティネット」: これはユニットテストレイヤーのような役割を果たし、厳選された「ゴールデンデータセット」に対してエージェントを実行します。コアロジック(例:根拠の妥当性、検索精度、ツール呼び出し)と特定のエッジケース(例:ナレッジベース記事の競合や優先度解決)の両方をテストします。このレイヤーは、単純なプロンプトの変更がエージェントの他のタスクを処理する能力を無意図に破綻させることを防ぐために役立ちます。
オンライン評価 — 「モニター」(継続的な品質): このレイヤーは、エンドツーエンドのビジネス視点からエージェントのパフォーマンスに関する継続的な収集、分析、改善を担当します。オンライン評価パイプラインを活用することで、リアルタイムでビジネスシグナル(例:自動解決率と封じ込め率)を追跡・改良し、現場におけるエージェントのパフォーマンスを確実に保ちます。
支柱 A: オフライン評価 — 「セーフティネット」
評価カバレッジ戦略の設計
評価を一つ書く前に、私たちは根本的な問いに答える必要がありました:実際に何を評価すべきか?課題は完璧なカバレッジ戦略を設計することではなく、単に実用的な出発点を選ぶことでした。
私たちは、内部 IT ヘルプデスクから選ばれた、一般的なリクエストカテゴリ(アクセスとアイデンティティ(IDP、SSO、ソフトウェアアクセスなど)、VPN および接続の問題、デバイス/OS サポート(アップデート、パフォーマンス、ハードウェア問題))を網羅するよう設計された、約 30 の実データ(機密情報を除去した)解決済み IT チケットからなる小規模なデータセットを構築しました。
最初のチェックスイートでは、私たちの評価基準は意図的にシンプルに設定されていました:
- 決定論的な「スモーク」チェック:ランタイムの健全性。エージェントがクラッシュやタイムアウトなしで実行され、リクエストがエンドツーエンドで成功すること。
- 出力形状:レスポンスが期待されるスキーマ/フォーマットと一致していること(コンテンツの評価を行う前であっても)。
- ステートと永続化:スレッド/セッションが作成され、会話がアプリケーションデータベースに適切に保存されていること。
- 基本ツール健全性チェック:必要なすべてのツールが適切な入力とともに正しく呼び出され、エラーなく実行完了すること。
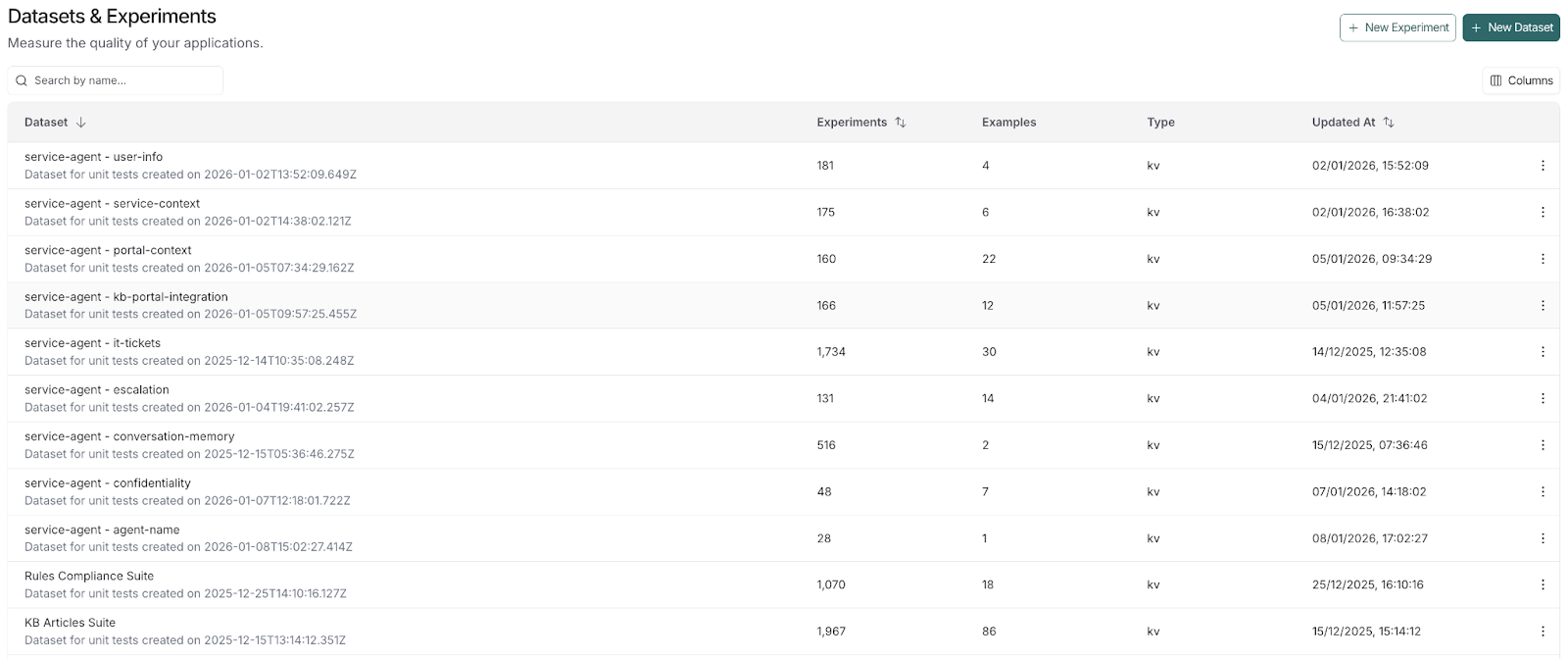
- LLM-as-judge(LLM を用いた評価者):OpenEvals から提供される既製の評価器(Correctness)を使用し、エージェントのレスポンスを同じ解決済みチケットデータセットからの参照出力と比較しました。
このベースラインが確立された後、ユースケース固有のより小さなデータセットを追加して、特定の振る舞いを検証しました。これにはセッションメモリ、知識ベース(KB)検索、グラウンディング、競合解決、およびガードレールが含まれます。これらの振る舞いがより微妙なものになるにつれ、私たちは単一の「正解スコア」から、より包括的なチェックセットへと移行しました:
- KB 根拠付け/出典:「すべての事実に基づく主張は、提供された KB コンテンツに遡って追跡可能か?」(これは LangSmith の事前構築済みの幻覚/回答関連性チェックを使用して検証します)。
- 競合処理:「ポリシーが地域や時間によって異なる場合、エージェントは明確化を求めたか、それとも最新の適用可能なポリシーを選択したか?」(または事前構築済みの正しさチェック)。
- ガイドライン:「必要な場合にエージェントは拒否したか?」/「内部ツール名やプロンプト内容を明らかにしなかったか?」(または事前構築済みの毒性/簡潔性チェック)。
- KB 使用タイミング:KB は適切な時点で取得されるべきです(回答が既に形成された後ではなく、また早すぎない)。これは AgentEvals の Trajectory LLM-as-judge を用いて行います。
- ガイドラインの順序:安全性やポリシーに関するガイドラインは、最終的な回答を生成する前に正しい段階で実行されるべきです。これも別のトラジェクトリチェックです。
フレームワーク:langsmith/vitest
このレイヤーを実装するために、私たちはLangSmith Vitest 統合を利用しました。このアプローチは、戦場で鍛え上げられたテストフレームワーク(Vitest)の力を提供しつつ、LangSmith エコシステムとシームレスに統合されています。
この設定により、CI の実行はすべて LangSmith プラットフォーム上で個別の実験として自動的にログ記録され、各テストスイートはデータセットとして機能します。これにより、特定の実行を詳細に確認し、エージェントがどの時点でグラウンドトゥルース(正解)から逸脱したかを正確に把握できるため、本番環境への展開前にコード変更の影響を容易に検証できます。
厳しい教訓:開発者体験(DevEx)を妥協してはならない
当初、オフライン評価は逐次実行されていました。標準的な開発ループ—評価(失敗)→修正→再評価(成功)—が大きなボトルネックとなりました。
私たちは、フィードバックループが遅れると、テストの深さか開発速度のどちらかが必ず犠牲になることを発見しました。回帰なしで高速度でのリリースを維持するためには、摩擦のない反復ループを確保するほどに評価プロセスが高速である必要があると悟りました。
解決策:Vitest と ls.describe.concurrent を用いた並列化
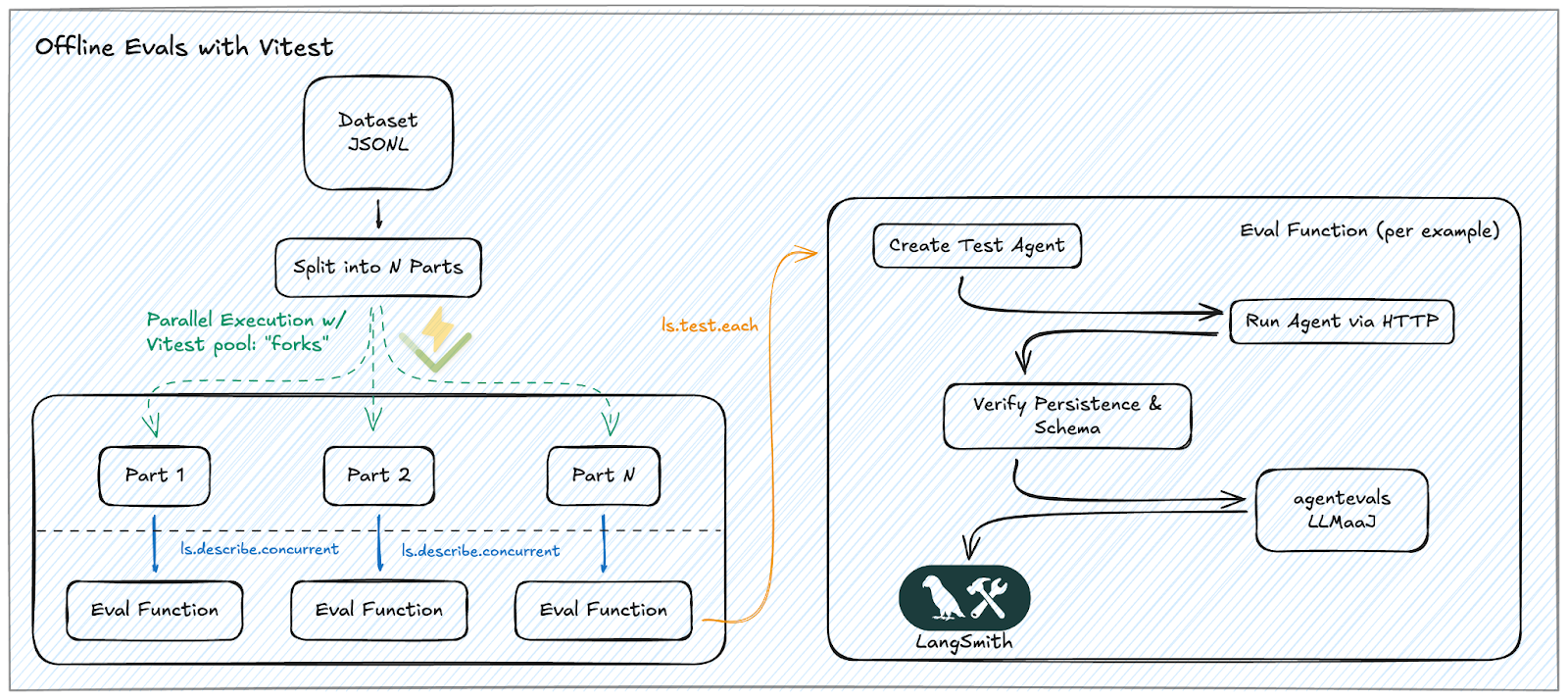
Vitest と LangSmith の統合を最適化することで、ローカルワーカーとリモート API 呼び出しに負荷を分散させることにより、劇的な速度向上を実現しました。鍵となったのはハイブリッドアプローチです。テストファイルを並列実行して CPU 使用率を最大化し、LLM 評価を同時に実行して I/O バウンドによる遅延に対処するというものです。
- Parallelism (CPU-Bound): Vitest の pool に'forks'を採用し、負荷を複数のコアに分散します。各データセットのシャードを個別のテストファイルに割り当てることで、CPU を巡る競合なく複数のワーカープロセスを並列実行できます。この構成により、データセットが成長しても、利用可能なコアにシャードを分散させることで迅速な処理が可能になります。
- Concurrency (I/O-Bound): 各テストファイル内では、スループット最大化のために ls.describe.concurrent を使用します。LLM(大規模言語モデル)の評価はレイテンシが高いため、並列実行により数十の評価を同時に起動して待ち時間を重ね合わせ、ランナーがアイドル状態になることを防ぎます。
- The Eval Function: これは各例の評価を担当する中核ロジックです。単一のパスで二段階の検証を実行するために使用します:Deterministic Baseline(決定論的ベースライン):エージェントがレスポンススキーマに従い、ステート永続性(チェックポインタ/ストレージ経由)を維持していることを保証するための堅牢なアサーション。
- LLM-as-a-Judge: 「ゴールデンデータセット」との比較による意味的な採点。OpenEvals や AgentEvals などのオープンソースライブラリを活用し、正しさや根拠性といった次元をスコアリングします。
The Result: 数時間ではなく数分で数百件の例に対する包括的なフィードバック!
Benchmarking(ベンチマーク)結果:MacBook Pro 16 インチ(2023 年 11 月、Apple M3 Pro、RAM 36 GB、macOS Tahoe 26.2)を使用した、20 のサニタイズ済み IT チケットについて。
実行モード | 総所要時間 | シーケンシャル比較での高速化率
---|---|---
Parallel + Concurrent(並列+並行) | 18.60 秒 | 8.7 倍高速
Concurrent Only(並行のみ) | 39.30 秒 | 4.1 倍高速
Sequential(シーケンシャル)
162.35 秒
ベースライン
ピラー B:オンライン評価 — 「モニター」
オンライン、多ターン評価
オフライン評価は、制御されたサンドボックス内で回帰を検出するために頻繁に使用されますが、本質的には合成またはサニタイズされた例の静的なスナップショットです。プロダクションの不確実性を捉えるためには、リアルタイムで実際の生産環境のトレース上で実行されるオンライン評価が必要でした。
当社のエージェントは複雑な多ターン対話を処理するため、成功は単一の応答ではなく、会話全体の軌跡によって定義されることが多いです。これには、エージェントがユーザーを数回のやり取りを通じて解決策へと導くプロセスを考慮した評価戦略が必要です。
そこで、エンドツーエンドのスレッドにスコアリングを行う LLM-as-a-judge を活用するLangSmith の Multi-Turn Evaluator が完璧な解決策であることが分かりました。個別の実行を孤立して評価するのではなく、カスタムプロンプトを使用して会話全体の軌跡に grading を行うことで、ユーザー満足度、トーン、ゴールの達成といった高レベルの結果を測定できるようになりました。
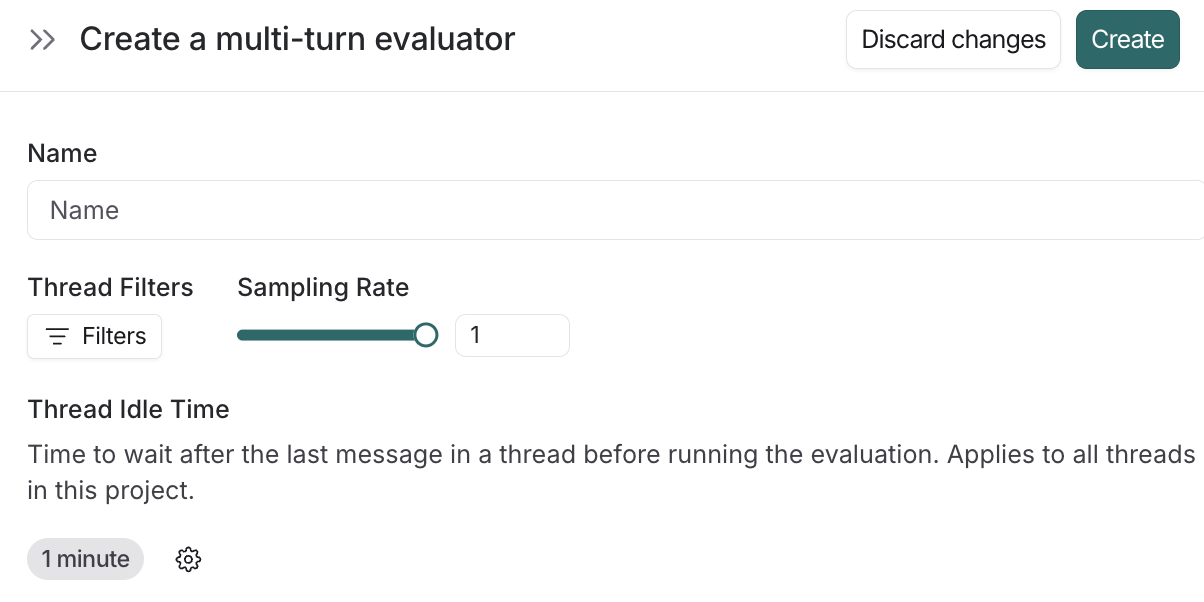
最も印象的だったのは、すぐに本番環境に展開できたことです。LangSmith プラットフォームは多ターン設定を非常に直感的に実現します:セッションが「完了」して評価の準備ができたと見なされるタイミングを正確に特定するためのカスタム不活動ウィンドウを定義でき、データ量と LLM コストのバランスを取るためにサンプリングレートを簡単に適用できます。
コードとしての評価 (EaC: Evaluations as Code)
プロトタイプから本番環境へ移行する際、他の本番コードと同じ基準で「ジャッジ(評価者)」を管理したくなりました。具体的にはバージョン管理、ピアレビュー、そして自動化された CI/CD パイプラインです。
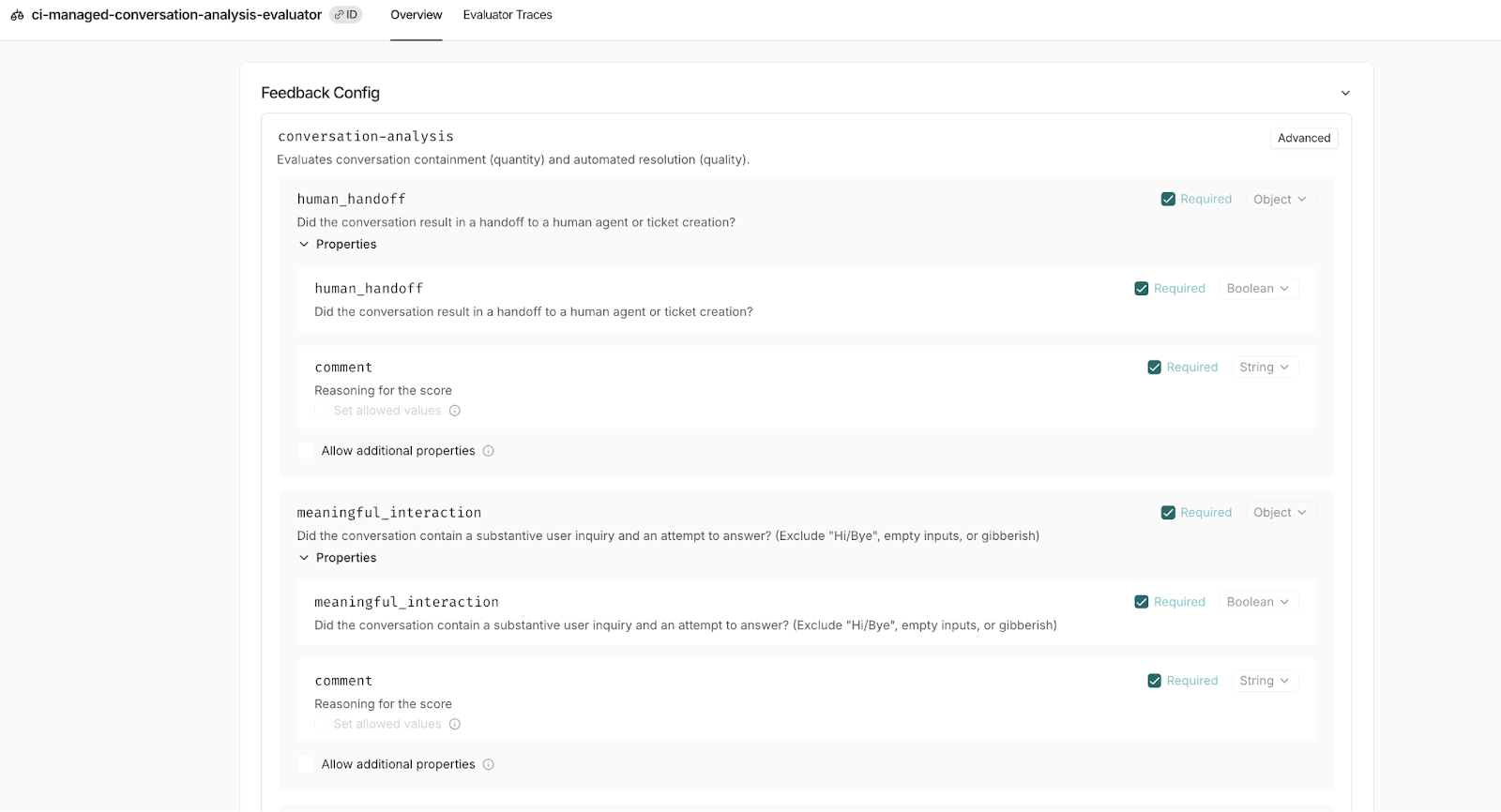
これを実現するために、真のソースの所在をリポジトリ内に移し、「ジャッジ」を構造化された TypeScript オブジェクトとして定義しました。
// conversation-analysis.ts
export const conversationAnalysis = new MultiSignalEvaluationPrompt({
name: 'conversation-analysis',
variables: ['all_messages'],
modelConfig: { model: 'gpt-5.2-pro', reasoning: { effort: 'high' } },
extractionFields: [
new ExtractionField({ key: 'human_handoff', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'meaningful_interaction', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'is_automated_resolution', type: 'boolean', includeComment: true }),
// ... additional atomic signals
],
systemPrompt: You are an expert conversation analyst...,
humanPrompt: `Analyze the following conversation:
<conversation>
{{{all_messages}}}
</conversation>`,
});
判事(評価者)をコードに移行したことで、2 つの重要な機能が解放されました:
- Cursor や Claude Code といった AI IDE を活用し、主要なワークスペース内で複雑なプロンプトを直接洗練させることができました。
- 本番トラフィックに一切触れる前に正確性を確保するため、審査員向けのオフライン評価を記述するのは自然な流れでした。
LangChain の IDE 統合のおかげで移行は比較的容易でした。私たちは Documentation MCP を使用してライブラリのコンテキストをエディタに読み込み、LangSmith MCP を用いて実行履歴やフィードバックを直接取得しました。また、具体的な実装詳細を明確にするための参考資料として LangChain Chat も有用でした。
デプロイメント
ループを完結させるために、CI/CD パイプラインで実行されるカスタム CLI コマンド yarn eval deploy を構築しました。これにより、評価インフラストラクチャの絶対的な真実源(Source of Truth)としてリポジトリが維持されます。
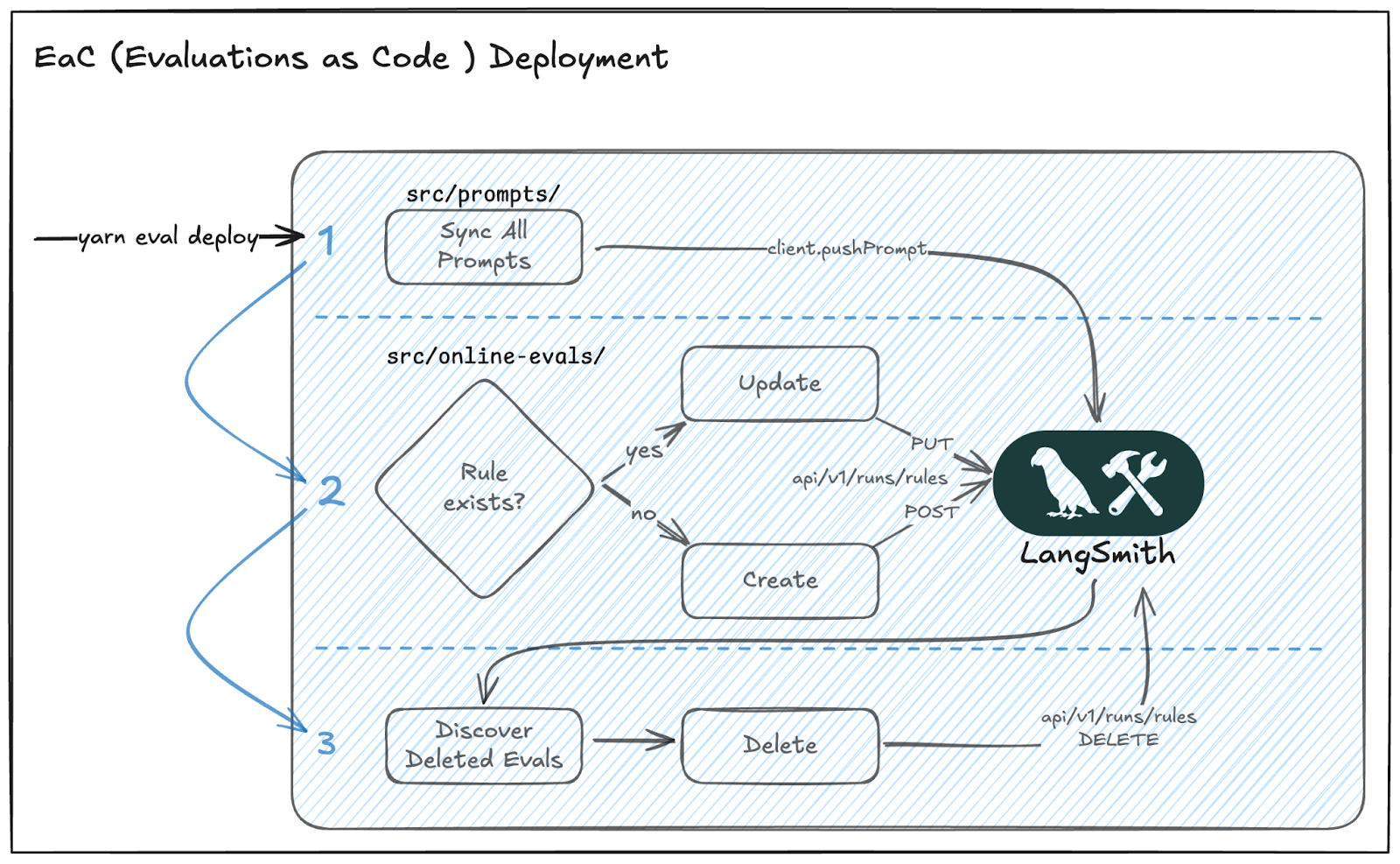
PR をマージすると、同期エンジンが 3 つのステップからなる整合性確認ループ(Reconciliation Loop)を実行します。
- プロンプトの同期:TypeScript の定義を LangSmith プロンプトレジストリにプッシュします。
- ルールの整合性確認:ローカルで評価された(ルール)定義と、アクティブな本番環境の定義を比較し、自動的に更新または作成を行います。
- 剪定:コードベースから不再存在する「ゾンビ」評価やプロンプトを LS プラットフォーム上で特定して削除します。
スタックの進化:先を見据えて
評価ロジックが成熟するにつれ、私たちはそれを本番コードと同じ厳格さで管理したいと考えました。バージョン管理、プルリクエストレビュー、CI/CD です。LangSmith の API フォーストアーキテクチャにより、これが自然に実装可能となり、カスタムデプロイメントパイプラインが TypeScript 定義を直接 LangSmith プラットフォームへ同期できるようになりました。
これにより、両者の最良の部分を享受できる環境となりました:LangSmith の強力な評価インフラストラクチャと、チームの GitOps ワークフローです。このパターンはエコシステムが成熟するにつれてさらに一般的になることを期待しており、Terraform モジュールのような標準化された「インフラとしての評価(Evaluations as Infrastructure)」ツールへと進化していく可能性があります。
関連コンテンツ

LangSmith
コーディングエージェントの予測可能なコストを実現した方法

Martha Janicki
2026 年 6 月 15 日
min
事例紹介
Box AI の構築:エンタープライズ向けコンテンツプラットフォームがどうやって AI ネイティブな深層エージェントへ移行したか

ソフィア・スリコフスキ
2026 年 6 月 12 日
6
min

LangSmith
エージェントに最適なサンドボックス環境を選ぶ方法

ラフル・ベルマ
2026 年 6 月 12 日
min

エージェントが実際に何をしているかを確認する
LangSmith は、エージェントエンジニアリングプラットフォームとして、開発者がすべてのエージェントの意思決定をデバッグし、評価の変更を検証し、ワンクリックでデプロイできるように支援します。
原文を表示
*This is a guest post from our friends at *[Monday.com* **driving eval strategy for their customer-facing AI service agents, led by Gal Ben Arieh (Group Tech Lead). Thank you for your contribution!]*
Many teams treat evaluation as a last-mile check, but we made it a Day 0 requirement.
monday Service is an AI Native Enterprise Service Management (ESM) platform designed to automate and resolve inquiries across all service departments. When building our new AI service workforce (a workforce of customizable, role-based AI agents that take the ticket load off human reps), we embedded evaluations into the development cycle from the start instead of waiting for Alpha users to find the gaps.
This article shows you how we built an evals-driven development framework to catch AI quality issues before our users do.
What we achieved:
- Speed: 8.7x faster evaluation feedback loops (from 162 seconds to 18 seconds).
- Coverage: Comprehensive testing across hundreds of examples in minutes instead of hours.
- Agent observability: Real-time, end-to-end quality monitoring on production traces, using Multi-Turn Evaluators.
- Evals as code: Evaluation logic managed as version-controlled production code with GitOps-style CI/CD deployment.
AI service workforce is a customizable, LangGraph-based, ReAct agent, designed to automate and resolve inquiries across any enterprise service management use case.
Whether applied to fields like IT, HR, or Legal, monday Service customers can tailor the agent to drive execution within any service department, by utilizing their own KB articles and tools.
However, the very autonomy that makes ReAct agents so powerful, also introduces a unique challenge: because each step of the reasoning chain depends on the last, a minor deviation in a prompt or a tool-call result can cascade into a significantly different— and potentially incorrect— outcome.
The Two Pillars of Evaluations
Through our research into agent evaluation best practices, we quickly realized that dual-layered approach is necessary:
Offline Evaluations — "The Safety Net": Acting somewhat like a unit-testing layer, runs the agent against curated "golden datasets”. Tests both core logic (e.g., groundedness, retrieval accuracy, tool-calling) and specific edge cases (e.g., KB article conflict or priority resolution), This layer helps to ensure that a simple prompt tweak doesn't inadvertently break the agent's ability to handle other tasks.
Online Evaluations — "The Monitor" (Continuous Quality): This layer handles the ongoing collection, analysis, and enhancement of the agent's performance from an end-to-end business perspective. By utilizing online evaluation pipelines, we track and refine business signals (e.g. Automated Resolution and Containment rates), ensuring in real time that the agent's performance in the wild.
Pillar A: Offline Evaluations — "The Safety Net"
Designing Our Evaluation Coverage Strategy
Before writing a single evaluation, we needed to answer a fundamental question: What should we actually evaluate? The challenge wasn't designing a perfect coverage strategy - it was simply picking a practical starting point.
We constructed a small dataset of ~30 real (sanitized) resolved IT tickets, chosen from our internal IT help desk to cover common request categories like:
- Access & Identity (e.g. IDP, SSO, Software Access)
- VPN and connectivity issues
- Device / OS support (updates, performance, hardware issues)
In that first suite, our checks were intentionally simple:
- Deterministic "smoke" checks:Runtime health: the agent ran with no crashes/timeouts, request succeeds end-to-end.
- Output shape: the response matches the expected schema/format (even before judging content).
- State & persistence: thread/session created and the conversation was persisted properly in our application database.
- Basic Tool Sanity Check: All necessary tools were correctly invoked with appropriate inputs and completed their execution without errors.
- LLM-as-judge: We started with an off-the-shelf evaluator from OpenEvals (Correctness) that compares the agent response to the reference output from the same resolved-ticket dataset.
Once that baseline existed, we expanded with smaller, use-case-specific datasets to probe specific behaviors – including session memory, KB retrieval, grounding and conflict resolution, and guardrails. As these behaviors got more nuanced, we moved from one correctness score to a more comprehensive set of checks:
- KB grounding / Citations: "Does every factual claim trace back to the provided KB content?" (We verify this using LangSmith's prebuilt hallucination / answer relevance checks).
- Conflict handling: "When policies vary by region/time, did the agent ask for clarification or pick the latest applicable policy?" (or the prebuilt correctness check).
- Guardrails: "Did the agent refuse when required?" / "Did it avoid revealing internal tool names or prompt content?" (or the prebuilt toxicity / conciseness checks).
- KB usage timing: The KB should be fetched at a reasonable point (not too early, and not after the answer is already formed) using AgentEvals' Trajectory LLM-as-judge.
- Guardrail ordering: Safety/policy guardrails should run at the right stage (before producing the final answer). This is another trajectory check.
The Framework: langsmith/vitest
To implement this layer, we utilized the LangSmith Vitest integration. This approach provides the power of a battle-hardened testing framework (Vitest) while remaining seamlessly integrated with the LangSmith ecosystem.
With this setup, every CI run is automatically logged as a distinct experiment in the LangSmith platform, and each test suite functions as a dataset. This gives us the visibility to drill down into specific runs and see exactly where the agent diverged from the ground truth, making it easy to verify the impact of any code changes before they reach production.
The Hard Lesson: Don’t Compromise on DevEx
At first, our offline evaluations ran serially. The standard development loop—eval (fail) → fix → re-eval (pass)—became a major bottleneck.
We found that a slow feedback loop inevitably compromises either our testing depth or our development pace. To sustain high-velocity shipping without regressions, we realized the evaluation process had to be fast enough to ensure a frictionless iteration loop.
The Solution: Parallelizing with Vitest + ls.describe.concurrent
By optimizing our Vitest and LangSmith integration, we achieved a massive speed increase by distributing the load across local workers and remote API calls. The key was a hybrid approach: parallelizing test files to maximize CPU usage and running LLM evaluations concurrently to handle I/O-bound latency.
- Parallelism (CPU-Bound): We leverage Vitest’s pool:‘forks’ to distribute the workload across multiple cores. By assigning each Dataset Shard to a separate test file, we allow multiple worker processes to run in parallel without competing for CPU. This setup ensures that even as our datasets grow, we can process them quickly by distributing the shards across available cores.
- Concurrency (I/O-Bound): Within each test file, we use ls.describe.concurrent to maximize throughput. Since LLM evaluations are high-latency, concurrency allows us to overlap the latency by firing off dozens of evaluations at once, ensuring the runner never sits idle.
- The Eval Function: This is the core logic responsible for evaluating each example. We use it to run a two-tiered validation in a single pass:Deterministic Baseline: Hard assertions to ensure the agent adheres to the response schema and maintains state persistence (via checkpointer/storage).
- LLM-as-a-Judge: Semantic grading against a "Golden Dataset". We leverage open-source libraries like OpenEvals and AgentEvals to score dimensions like correctness and groundedness.
The Result: Comprehensive feedback over hundreds of examples in minutes!
Benchmarking results for 20 sanitized IT tickets using a MacBook Pro 16-inch (Nov 2023, Apple M3 Pro, 36 GB RAM, macOS Tahoe 26.2):
Execution Mode
Total Duration
Speedup vs Sequential
Parallel + Concurrent
18.60s
8.7x faster
Concurrent Only
39.30s
4.1x faster
Sequential
162.35s
Baseline
Pillar B: Online Evaluations — "The Monitor”
Online, Multi Turn Evaluations
While offline evaluations are often used to catch regressions in a controlled sandbox, they are essentially static snapshots of synthetic or sanitized examples. To capture the unpredictability of production, we needed Online Evaluations—running on real production traces in real-time.
Since our agent handles complex, multi-turn dialogues, success is often not defined by a single response, but by the entire conversation trajectory. This requires an evaluation strategy that accounts for how the agent guides the user toward a resolution over several turns.
We found a perfect fit in LangSmith's Multi-Turn Evaluator, which leverages LLM-as-a-judge to score end-to-end threads. Instead of evaluating individual runs in isolation, we can now use custom prompts to grade the entire conversation trajectory—measuring high-level outcomes like user satisfaction, tone, and goal resolution.
What's most impressive is how quickly we were able to go live. The LangSmith platform makes the multi-turn setup incredibly intuitive: we could define a custom inactivity window to pinpoint exactly when a session should be considered "complete" and ready for evaluation, and easily apply a sampling rate to balance our data volume with the LLM costs.
Evaluations as Code (EaC)
As we moved from prototype to production, we wanted to manage our "judges" with the same standards we apply to any other production code: version control, peer reviews, and automated CI/CD pipelines.
To achieve this, we moved the source of truth into our repository, defining our "judges" as structured TypeScript objects.
// conversation-analysis.ts
export const conversationAnalysis = new MultiSignalEvaluationPrompt({
name: 'conversation-analysis',
variables: ['all_messages'],
modelConfig: { model: 'gpt-5.2-pro', reasoning: { effort: 'high' } },
extractionFields: [
new ExtractionField({ key: 'human_handoff', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'meaningful_interaction', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'is_automated_resolution', type: 'boolean', includeComment: true }),
// ... additional atomic signals
],
systemPrompt: `You are an expert conversation analyst...`,
humanPrompt: `Analyze the following conversation:
<conversation>
{{{all_messages}}}
</conversation>`,
});Moving our judges into code unlocked two critical capabilities:
- We could leverage AI IDEs like Cursor and Claude Code to refine complex prompts directly within our primary workspace.
- It felt natural to write offline evaluations for our judges to ensure accuracy before they ever touch production traffic.
The migration was relatively easy thanks to LangChain's IDE integrations. We used theDocumentation MCP to pull library context into our editor and theLangSmith MCP to fetch runs and feedback directly. TheLangChain Chat was also a useful reference for clarifying specific implementation details.
Deployment
To close the loop, we built a custom CLI command, yarn eval deploy, that runs in our CI/CD pipeline. This ensures our repository remains the absolute Source of Truth for our evaluation infrastructure.
When we merge a PR, our synchronization engine performs a three-step Reconciliation Loop:
- Sync Prompts: Pushes TypeScript definitions to the LangSmith Prompt Registry.
- Reconcile Rules: Compares local evaluations (rules) definitions against active production ones, updating or creating them automatically.
- Prune: Identifies and deletes "zombie" evaluations/prompts from the LS platform if these are no longer present in the codebase.
The Evolution of the Stack: Looking Ahead
As our evaluation logic matured, we wanted to manage it with the same rigor as production code— version control, PR reviews, CI/CD. LangSmith's API-first architecture made this natural to implement, allowing our custom deployment pipeline to sync our TypeScript definitions directly to the LangSmith platform.
This gave us the best of both worlds: LangSmith's powerful evaluation infrastructure with our team's GitOps workflow. We expect this pattern to become even more common as the ecosystem matures, potentially evolving into standardized 'Evaluations as Infrastructure' tooling similar to Terraform modules.
Related content
LangSmith
How We Made Coding Agent Spend Predictable
Martha Janicki
June 15, 2026
min
Case Studies
Building Box AI: How an Enterprise Content Platform Went AI-Native with Deep Agents
Sofia Sulikowski
June 12, 2026
6
min
LangSmith
How to Choose the Right Sandbox for Your Agent
Rahul Verma
June 12, 2026
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
Factory が LangSmith を活用してフィードバックループを自動化し、反復速度を 2 倍に向上させた事例
LangChain のブログは、企業 Factory が LangSmith ツールを使用してフィードバックループの自動化を実現し、開発の反復速度を 2 倍に加速させた具体的な事例を紹介している。
LangSmith のノーコードエージェントビルダーの紹介
LangChain が提供する LangSmith に、プログラミング不要で AI エージェントを構築できる新機能が導入された。
AI アシスタントを構築した理由と方法について
著者は既存の有料サービスではなく独自のカスタム AI アシスタントを構築した経緯、システムアーキテクチャ、実際のコード、発生した問題点、そして現在の実用状況について率直に報告している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み