オープンモデル生態系がもたらす複合効果について
Interconnects の分析は、LLM 開発コストの大部分が最終モデル訓練ではなく R&D に費やされており、中国のオープンエコシステムがこの非効率を解消することで競争優位を生んでいると指摘している。
キーポイント
R&D コストの支配的割合
Ai2 と Epoch AI の研究によると、先端的モデル開発における計算リソースの約 80% が最終モデルのトレーニングではなく R&D に費やされている。
中国型オープンエコシステムの優位性
中国の主要プレイヤーはオープンであり、競合他社の知見を迅速に学習して重複投資(ダブルスペンディング)を防ぐことで、コスト構造において潜在的な優位性を築いている。
OSS と AI オープンソースの構造的差異
ソフトウェア開発と異なり、AI のオープンソース化には「多くの目」によるバグ修正や機能追加というフィードバックループが弱く、コスト削減効果は開発者自身よりもエコシステム全体に及ぶ。
オフザシェルフ利用の逆説
最小限のイテレーションで AI を利用するケースでは、オープンモデルの方が統合・ホスト型クローズドソリューションより高コストになる可能性があり、スケール効果はクローズドモデルに有利に働く。
オープンソースの分岐と内部化の限界
企業がオープンソースツールをフォークして独自バージョンを作る慣行は、コスト削減やコミュニティ全体の成長を阻害するため、今後減少する必要がある。
共有基盤モデルコンソーシアムの必要性
ハードウェアやデータインフラの最適化が個別に行われる現状では非効率であり、将来の競争力を維持するにはオープンなモデルコンソーシアムによる共有リソースが不可欠である。
クローズド企業の学習効果
開発リードタイムがある程度あるクローズド企業もオープンフロンティアの研究から恩恵を受けるが、コミュニティが強くなるほど各社の性能曲線(パレート曲線)は近づき、コスト競争のインセンティブが高まる。
影響分析・編集コメントを表示
影響分析
この記事は、LLM 開発の真のコスト構造と、国ごとの戦略(特に中国のオープンエコシステム)が競争優位にどう影響するかを明確にし、業界関係者が「オープン=安価」という単純な認識から脱却するよう促す。また、OSS の成功モデルを AI にそのまま適用できない構造的欠陥を指摘することで、今後のオープンソース戦略やインフラ投資の方向性を再考させる重要な示唆を与える。
編集コメント
「オープンソース=安価」という通説を覆す、計算資源の配分構造に関する鋭い洞察です。特に中国の戦略が OSS の知見共有モデルに似ている点は、今後の業界動向を読む上で極めて重要です。
注:有料購読者の方は、Interconnects の設定をクリックして説明を管理することで、ポッドキャストアプリの有料ポストの音声読み上げを利用できます。お聞きいただきありがとうございます!
最先端モデルを構築するための計算資源の大部分は、最終的な大規模モデルをエンドツーエンドで訓練する計算資源ではなく、研究開発(R&D)コストから生じます。中国のような生態系では主要プレイヤーがすべてオープンであるため、これはコスト構造において潜在的な有意義な優位性をもたらし、ラボが外部の観察者が予想するよりも長く構築を継続できる可能性があります。
最近の研究として、Olmo 3 の開発を文書化した Ai2 の研究と、さまざまな最先端ラボからのコストに関する公開ドキュメントを調査した Epoch AI の研究があり、最終モデルではなく研究開発に費やされた計算資源の見積もりは約 80%(有意な誤差範囲付き)であると示しています。
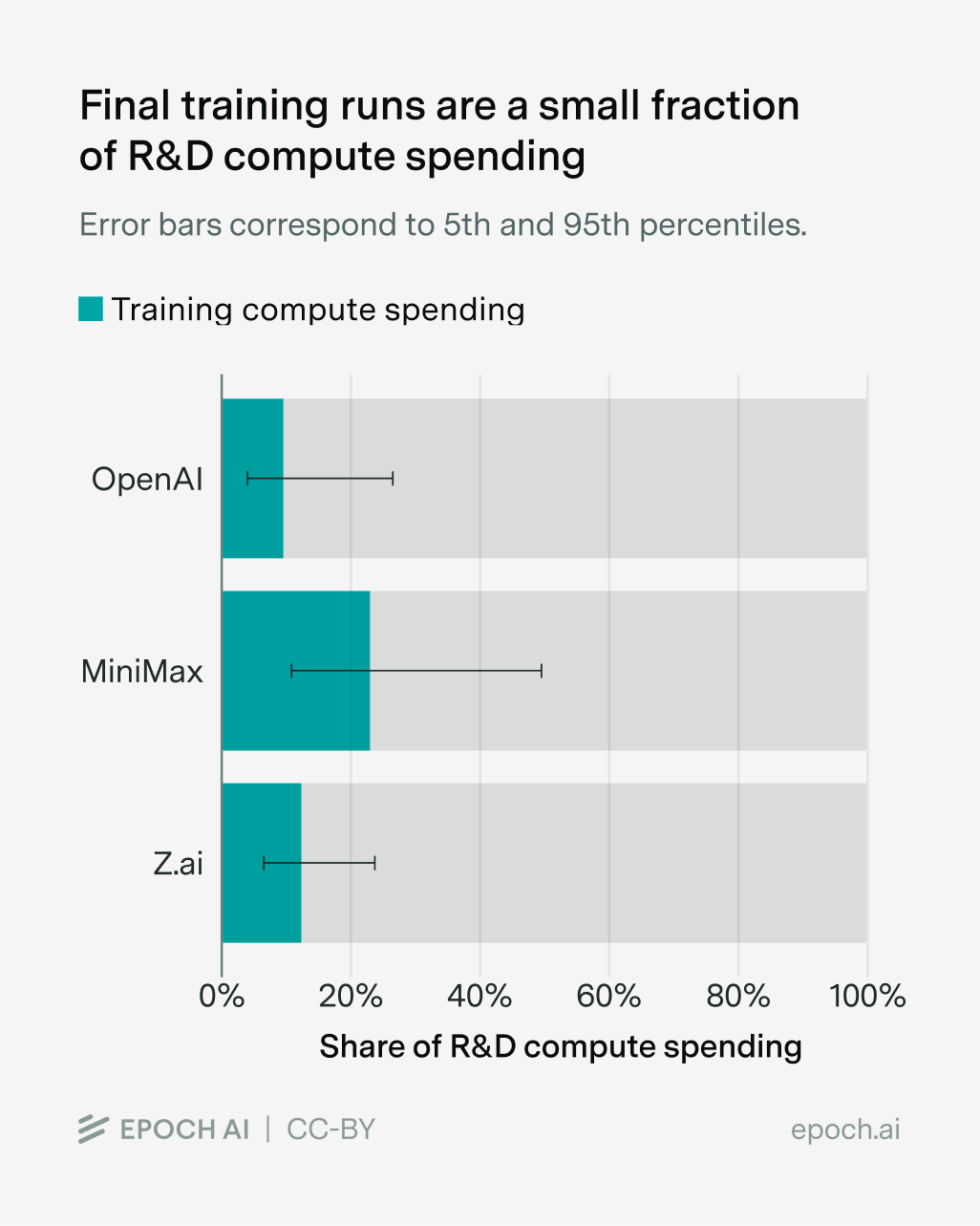
研究開発の大部分が計算リソースを消費する世界において、中国のシステムは、同業者から素早く学習し、研究用計算リソースやインフラへの重複投資を防ぐように設計されています。完璧とは程遠いですが、大規模言語モデル(LLM)を構築するためのオープンソースソフトウェア(OSS)エコシステムに最も近いアナログと言えます。AI に関する公的な議論では常に、モデルが非常に高価であり、それが計算リソースそのものが成果物専用に割り当てられているかのように受動的な読者に思わせる点に焦点が当てられてきました。これは DeepSeek V3 の事例でも確認された通りです。
この状況は、オープンソース AI の核心的な課題を再考させるものでした。つまり、オープンソースソフトウェア(OSS)のユーザーが Linus の法則「十分な数の目があれば、すべてのバグは浅い」というフィードバックループを通じて創造自体に貢献し、巨大な価値を生み出すような仕組みが、オープンソース AI には欠けているという点です。この OSS 特有の自己強化構造こそが、大規模展開におけるコストを可能な限り最小化する結果をもたらします。すべてのユーザーがバグ修正や機能追加のコストを共有するからです。
オープンソース AI の分野では、コストのほとんどがモデル開発者に負担されます。同時に、モデルを公開することでコスト削減につながる大きなメリットもありますが、それらは主に創作者自身にとっての将来の開発・展開コストを減らすだけであり、何よりも重要なのは、エコシステム全体にとって広くコスト削減に寄与する点です。
Open AI のモデル、ツール、インフラストラクチャ、およびその間のすべては、開発におけるコスト削減をもたらしますが、これは「アップル・トゥ・アップル」のソリューションや製品におけるプラグ・アンド・プレイ型のコスト削減ではありません。もし誰かが最小限の反復や内部開発のみで市販の AI を利用しようとするなら、オープンモデルを利用することはほぼ常に高価になります。クローズドで統合され、ホスティングされたソリューションは、一般的な利用における規模の経済によって低価格帯を実現しています。
オープンソースエコシステムは、継続的なパフォーマンスにおいて OSS(オープンソースソフトウェア)スタイルの財務的およびパフォーマンス上の利益を模倣しようと試みるのみです。中国の研究機関は、極めて詳細な技術レポートと研究機関間での意図的な知識共有を通じて、同僚企業に対して必ずしも同等のリソースを投資する必要がないアイデアのリスクを軽減しています。
これが機能するためには、AI企業がオープンソースツールをフォークして内部専用バージョンへと進化させるという現在の慣行は、おそらく衰退する必要があるでしょう。オープンソース AI企業が、人々が最初に使用する完全なオープンツールのアクセシビリティが後れをとる中で、企業契約や内部ツールによるパフォーマンス向上を売り点とするのはあまりにも一般的な設定です。
大規模な MoE モデルの RL 学習(強化学習)における真にオープンなレシピは存在しません。Thinking Machine の Tinker や Prime Intellect の Lab のように、オープンサポートを提供しつつ部分的にクローズドなツールが、オープンエコシステムのメリットを維持できるほど十分にオープンであるかどうかは不明です。
スタックがよりオープンであればあるほど、また共有される情報が多ければ多いほど、将来の反復においてコストは削減されます。
企業がオープンソースツールをフォークして内部バージョンを作成するのと同じ推論は、なぜ誰もが構築できる共有された単一の基盤モデルが存在しないのかという理由にも当てはまります。今日最高のモデルを構築することは、ハードウェア、データ、インフラストラクチャを統合し、パフォーマンスの最前線に追いつくためにこれらすべてを比較的高い速度で進化させる芸術となります。LLM が数年にわたり性能向上を着実に続ける兆候がすべて示されていることを考えると、この均衡が近いうちに変化すると期待するのは unlikely です。まさにこれが、私がオープンモデルコンソーシアムの不可欠な必要性について投稿を書いた理由です – この共有リソースははるかに効率的であり、オープンモデルで将来の最前線規模で競争するための唯一の財政的に実行可能な方法となる可能性があります。
もちろん、クローズドラボもオープンフロンティアモデル企業の調査を把握しており、そこから恩恵を受けることができますが、クローズドラボが開発ツリー上で数ヶ月先行しているという前提の下では、共有された洞察から自然に得られる利益は相対的に少なくなります。オープンソースコミュニティが強力であればあるほど、各企業がパフォーマンスのパレート曲線上で互いに近接して存在するコスト上のインセンティブが高まります。
開発コストの違い、あるいはプロセス指向の技術と、すべてのラボが直接構築する共有基盤との違いに対するこの認識は、私の最近の中国訪問要約へのフィードバックで受けた質問に端を発しています。その質問とは、「中国のエコシステムがコスト削減のために単一のベースモデルに収束する可能性はあるか?」というものでした。この質問への続投として、中国のオープンウェイト企業の中で、オープンソースを戦略的に意味のある方法で使用しているところがあるかどうかについて問われました。ここではさらに多くの有用な質問を行う余地があり、特にエコシステムの異なる運用パターンを理解しようとする際にはなおさらです。
中国のファウンデーションモデル開発モデル
私は、ビル・ガーリーが『Breakneck』の著者であるダン・ワンと、『Apple in China』の著者であるパトリック・マギー(両書とも強く推奨します - 必読です)とのインタビューを非常に考えさせられるものと感じました。これは、米国と中国の技術文化における最大の違いについて深く考察させるものです。
私は現在、オープンソース AI の弧においてこれらの違いに多く触れる機会があります。過去一年で中国の AI エコシステムから湧き上がった、西洋の聴衆や思考に影響を与えたいという深い渇望が存在します。これは明らかに、SAIL グループが最近の訪問でそのようなアクセスを得た理由の強力な前例となりました - AI エコシステムの誰かが多くの企業のシニアリーダーシップと話すことは、当然のことではありません。
続きを読む
原文を表示
Note: Voice-overs for paywalled posts are available for paid subscribes in podcast apps if you click on settings on Interconnects, then manage your description. Thanks for listening!
Most of the compute to build a leading frontier model comes from R&D costs, rather than the compute to train the final, big model end-to-end. In an ecosystem like China, where all the leading players are open, this creates a potential meaningful advantage in cost structures that’ll let labs keep building longer than outside observers would expect.
There are two recent pieces of research, one from Ai2 documenting the development of Olmo 3 and one from Epoch AI studying public documentation of costs from various frontier labs, that put the estimate of compute spent on R&D rather than the final model at about 80% (with meaningful error bars).
In a world where research and development is most of the compute, the Chinese system is designed around quickly learning from your peers and avoiding double-spending research compute — or infra effort. It’s far from perfect, but it’s the closest analog to the OSS ecosystem that one can get for building LLMs. The public discussion of AI has always emphasized that the models are expensive in a way that naturally lets passive readers think this is compute just dedicated to the artifact — as we saw with DeepSeek V3.
Share
This had me revisiting the core issue of open-source AI, and how it doesn’t have the feedback loops akin to open-source software (OSS) users back to the creation itself, that creates immense value following Linus’s law of “given enough eyeballs, all bugs are shallow”. This self-reinforcement of OSS makes deployment at scale the cheapest possible outcome — all the users together share the costs of fixing bugs and adding features.
Within open-source AI, almost all the cost falls on the model developer. At the same time, there are huge benefits to releasing the model openly that do reduce costs, but they only help reduce future development and deployment costs for the creator themselves, but more importantly the ecosystem widely.
Open AI models, tools, infrastructure, and everything in between are a cost reduction in development, not plug and play cost reduction on apples to apples solutions or products. If someone is going to be just using AI off-the-shelf with minimal iteration or internal development, using open models will almost always be more expensive. Using closed, integrated, hosted solutions achieves low price points by economies of scale across general usage.
The open-source ecosystem can only try to mirror the OSS-style financial and performance gain in continued performance. The Chinese labs, through incredibly thorough technical reports and intentional knowledge sharing across labs effectively are de-risking ideas for their peer companies to not necessarily need to invest as many resources in.
For this to work, the current norm where AI companies fork open-source tools, to evolve them into internal-only versions, will likely need to fade out. It’s too common of a trope for open-source AI companies to have their selling point being better performance via enterprise agreements or internal tools, as the fully open tools that people start with are falling behind in accessibility. A prime example is at-scale RL training of MoE models — no truly open recipe exists. It’s unclear if the open-supporting, but partially closed tools like Thinking Machine’s Tinker and Prime Intellect’s Lab can be open enough for the advantages of an open ecosystem to sustain themselves. The more open the stack is, and the more information is shared, the more costs are reduced in future iterations.
The same reasoning that causes companies to fork open-source tools to make internal versions applies to why there isn’t a shared, single foundation model that everyone builds on. Building the best model today becomes an art of integrating your hardware, data, and infrastructure, while evolving all of them at a relatively high rate that lets you keep up with the frontier of performance. Given that all signs point to LLMs continuing their steady march in performance improvements for years, it seems unlikely to expect this equilibrium to change in the near term. This is exactly why I wrote my post on the inevitable need for an open model consortium – this shared resource is far more efficient and may become the only financially viable way to compete at the future frontier scale with open models.
It’s worth noting that, of course, the closed labs also see the investigations of the open frontier model companies and can benefit from them, but with the assumption that the closed labs are some months ahead in the development tree, they often naturally stand to benefit less from the shared insights. The stronger the open-source community is, the more cost incentive there is for the various companies to be relatively close together on the same Pareto curve of performance.
This realization of the difference between development costs, or a process-focused technology, rather than some shared foundation that all the labs build on directly was downstream of a question I got in feedback to my recent China trip summary. The question was: “Was there any chance of the Chinese ecosystem converging on a single base model to save costs?” The follow-up to this question was on if any of the open-weight companies in China are using open-source in strategically meaningful ways. There are many more useful questions to ask here, especially when trying to understand the different operational patterns of the ecosystems.
China’s foundation model development model
I found the following interview conducted by Bill Gurley with Dan Wang, author of Breakneck, and Patrick McGee, author of Apple in China, (both books I strongly recommend – must reads) very thought provoking on the biggest differences between technology cultures in the U.S. and China.
I get a lot of exposure to these differences at this point in my open-source AI arc. There’s a deep yearning to influence Western audiences and thinking that has bubbled up out of the Chinese AI ecosystem in the last year. This was obviously a strong pretext for why the SAIL group got such access in our recent trip – it’s not a given that anyone in the AI ecosystem will talk to senior leadership at so many companies.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み