AI の高額なトークン使用料を抑えるため、企業が Claude や Codex に「洞窟人」のような簡潔な話し方をさせる
企業は AI トークンコストの高騰を抑制するため、LLM の出力から冗長な表現を排除する「Caveman」プラグインを採用し、OpenAI や Nvidia などの開発者も実用化している。
キーポイント
トークンコスト削減のための「洞窟人」モード導入
企業は AI ツールの出力から挨拶や婉曲表現を排除し、ハッシュタグのような簡潔なスタイル(例:"Hulk smash")に切り替えることで、トークン使用量を大幅に削減している。
主要企業の採用と内部方針
OpenAI、Nvidia、GitHub の開発者や、データセンター事業を展開する Legrand などがこのプラグインを採用しており、Legrand は内部メモで「Caveman スキル」の使用を推奨している。
開発者による実装と効果検証
ツール作成者が OpenAI の Codex への対応を追加し、テストではトークン使用量を約 65%(5,800 トークン)削減する効果が確認された。
トークン削減によるコスト抑制効果
Cavemanプロンプトは、コードや数値などの重要な情報を変更せずに周囲の言語を圧縮し、デフォルト設定で出力トークンを約65〜75%削減します。
大手企業の採用と背景
GitHubの課金モデル変更やUber、Walmartなどの予算超過問題を受け、OpenAIやNVIDIAなどの企業エンジニアがコスト対策としてCavemanを採用しています。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI の実装において「コスト効率性」が「機能の豊かさ」に取って代わる転換点であることを示唆しています。企業がモデルの能力を最大限活用するのではなく、必要最小限の出力でタスクを完遂させるような運用パラダイムシフト(Agent Loop 最適化)が進んでおり、今後の LLM エコシステムにおけるプロンプト設計やコスト管理戦略に大きな影響を与えるでしょう。
編集コメント
AI ツールの利用において、コスト管理が技術的な最適化と直結する時代に入ったことを示す興味深い事例です。開発者コミュニティが自発的に作成したツールが大手企業の運用方針に採用されるという、ボトムアップ型の効率化の動きは注目すべきトレンドと言えます。
 image企業は、AI トークンの浪費を防ぎ、膨大な AI 関連支出を抑制しようとして、意図的に AI ツールが「洞窟人」のように話すようにしていることが、404 Media の調査で明らかになりました。このツールは、Claude Code、Codex、Gemini など、通常は冗長になりがちな大規模言語モデル(LLM)の出力を、要点を突いた簡潔な回答へと変換します。「押し返すのは正しいです、私が間違っていました」といった表現ではなく、「ハルク、スマッシュ!」といったようなものです。
image企業は、AI トークンの浪費を防ぎ、膨大な AI 関連支出を抑制しようとして、意図的に AI ツールが「洞窟人」のように話すようにしていることが、404 Media の調査で明らかになりました。このツールは、Claude Code、Codex、Gemini など、通常は冗長になりがちな大規模言語モデル(LLM)の出力を、要点を突いた簡潔な回答へと変換します。「押し返すのは正しいです、私が間違っていました」といった表現ではなく、「ハルク、スマッシュ!」といったようなものです。
この洞窟人プラグインの使用は、急騰し予測不能になった AI のコストに対する直接的な対応です。404 Media が以前報じたように、企業は AI への支出を減らすために必死になっており、コンサルティング大手の Accenture は、「トークン支出の急増」の多くが、AI を使用して PDF からプレゼン資料を作成していることによるものだと指摘しています。この洞窟人ツールを利用しているのは、OpenAI、Nvidia、GitHub の開発者たちで、ツールの作成者によるとのことです。ある OpenAI の上級社員はプロジェクトにコードを貢献し、OpenAI の Codex ツールへのサポートを追加しました。
企業内のトークン支出について他に何かご存知ですか?ぜひお聞かせください。私用のデバイスから、Signal で joseph.404 まで安全にお送りいただくか、joseph@404media.co までメールをお送りください。
「4 月に『キャベマン』を作成したのは、Claude Code を多用していた際、トークンの多くが無用な文章表現——お世辞、遠回しな言い方、接続詞、そしてエージェントループ内では実質的に重要ではない雑談的な言語——に費やされていることに気づいたからです」と、『キャベマン』の作成者である Julius Brussee 氏は 404 Media に語りました。
『キャベマン』を採用している企業のひとつに、電気およびデジタルインフラの大手 Legrand があります。皮肉なことに同社はデータセンター事業にも参入しています。404 Media が入手した内部メモでは従業員に対し、「請求システムの変更と新しいクォータの実施に伴い、予算をすぐに使い果たさないよう AI の利用には注意が必要です」と伝えています。さらに、このメモは「高いインパクトを持つ」4 つの施策を列挙しています。それは、常に最も強力なモデルを使用しないこと;LLM(大規模言語モデル)に対して常に高推論設定を使用しないこと;タスクに応じてより適切な異なるモデルを使用すること;そして最後に、「コードへの影響を与えずに出力消費を削減するために『キャベマンスキル』を活用すること」です。
404 Media が Claude Code で『キャベマン』を試したところ、このプラグインは LLM の回答を非常に簡潔なものに変えることが確認されました。「変更が必要ですか?」と、私が以前作成したコードのレビューを依頼した後、LLM は尋ねました。また、「公式 API を使用し、スクレイピングは行わない」と付け加え、コードの動作方法を説明しました。『キャベマン』がインストールされていることを再確認すると、Claude の出力は「すでにアクティブです。何が必要ですか?」となりました。
Caveman は、保存したと主張するトークンの総数も表示できます。私のケースでは、Caveman は約 5,800 トークン、つまり 65% を節約してくれたと言いました。
 imageCaveman の動作中のスクリーンショット。「これはモデルが丁寧なチャットボットのようではなく、簡潔なツールのようにより多く話すようにします」と Brussee 氏は述べています。「中身は同じで、言葉数は減ります。私の評価では、デフォルトの冗長な出力と比較して Caveman は出力トークンを約 65〜75% 削減し、通常の『簡潔に』という指示よりも優れた結果を出しました。この数値はワークフローによって異なりますが、効果は明確でした。」
imageCaveman の動作中のスクリーンショット。「これはモデルが丁寧なチャットボットのようではなく、簡潔なツールのようにより多く話すようにします」と Brussee 氏は述べています。「中身は同じで、言葉数は減ります。私の評価では、デフォルトの冗長な出力と比較して Caveman は出力トークンを約 65〜75% 削減し、通常の『簡潔に』という指示よりも優れた結果を出しました。この数値はワークフローによって異なりますが、効果は明確でした。」
Caveman のユーザーは、「grunt」のレベルを「lite(軽量)」「full(通常、デフォルト設定)」「ultra(超)」から選択できます。また「Wenyan」というモードもあり、これは出力を古典中国語(文言文)に変換します(動作を確認しましたが、今では Claude の出力が何を言っているのか全くわかりません)。
「目的は、正確さが重要となる部分——コード、コマンド、パス、URL、数値、関数名、技術詳細——に触れることなく、出力トークンを削減することです。Caveman は主に周囲の言語を圧縮します」と Brussee 氏は付け加えました。
GitHub の記録によると、OpenAI のエンジニアリングディレクターである Shayne Sweeney 氏が caveman にコードを提供しています。数ヶ月前のコミットには「Codex プラグインサポートを追加」と記載されています。
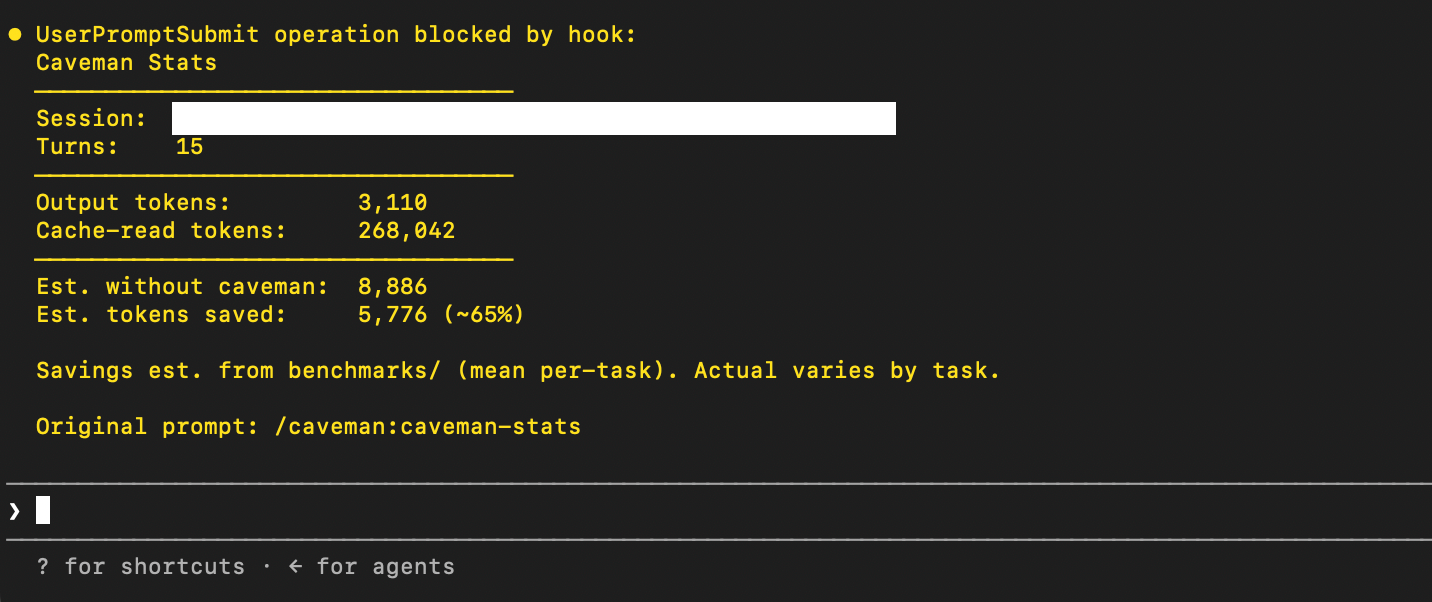 image 洞窟住人のアクションのスクリーンショット。Caveman はまた、すべての内容を洞窟住人言語に要約する完全なエージェントも提供しています。「caveman-code はすべてを縮小します——フルターミナルコーディングエージェント、トップからボトムまで洞窟住人方式。同じタスクで Codex より約 2 倍少ないトークン数。20 以上のプロバイダー対応・プランモード・自律目標ループ・MIT」と、Caveman の GitHub リポジトリには記載されています。Caveman はまた、今年初めに大規模にバズったエージェント型 AI ツールである OpenClaw と併用することも可能です。
image 洞窟住人のアクションのスクリーンショット。Caveman はまた、すべての内容を洞窟住人言語に要約する完全なエージェントも提供しています。「caveman-code はすべてを縮小します——フルターミナルコーディングエージェント、トップからボトムまで洞窟住人方式。同じタスクで Codex より約 2 倍少ないトークン数。20 以上のプロバイダー対応・プランモード・自律目標ループ・MIT」と、Caveman の GitHub リポジトリには記載されています。Caveman はまた、今年初めに大規模にバズったエージェント型 AI ツールである OpenClaw と併用することも可能です。
このプラグインは明らかにかなり面白いものですが、非常に現実的な問題への対応として登場しました。4 月、GitHub は従来定額制サブスクリプション料金だったものを、トークン数に応じた課金方式に移行すると発表しました。Uber は従業員の AI ツール利用を制限し、同社の CTO(最高技術責任者:Chief Technology Officer)は Uber が AI 関連予算のすべてをわずか 4 ヶ月で使い果たしたと述べています。Walmart も AI ツールの利用を制限しています。そして今、企業たちは Caveman を使用し始めています。
「OpenAI、NVIDIA、GitHub、DEPT の人々を含む、多くの個人開発者や社内エンジニアから、このツールを使用またはテストしているという声を聞いています」と Brussee 氏は語りました。
404 Media が入手した漏洩音声において、Accenture はまずクライアントに AI の早期導入を促しておきながら、この問題に対する解決策として自社を位置づけました。その音声の中で、上級社員は「クライアントとの新たな機会として、本当にトークン経済について考える必要がある」と述べています。
昨年、OpenAI のCEOサム・アルトマンは、LLM に「 please」や「thank you」といった礼儀正しい挨拶を続けることが、OpenAI にとって電気代で数千万ドルの損失になると示唆しました。
Legrand、OpenAI、Nvidia、GitHub は、この「 caveman(原人)」の使用に関するコメント依頼に対して回答しませんでした。
Caveman の GitHub リポジトリのほぼ末尾には、「Caveman save you token, save you money.」と記されています。
原文を表示
imageCompanies are deliberately making their AI tools speak like cavemen in an attempt to stop burning through AI tokens and curb their massive expenditure on AI, 404 Media has found. The tool turns the usually verbose outpost of LLMs like Claude Code, Codex, or Gemini into a much more to the point answer. Think less “you’re right to push back, I was wrong,” and more “Hulk smash.”
Use of the caveman plugin is in direct response to the skyrocketing and unpredictable cost of AI. As 404 Media previously reported, companies are scrambling to stop spending so much on AI, with consulting giant Accenture finding much of the “soaring token spend” is thanks to people using AI to convert PDFs to presentations. People using caveman include developers at OpenAI, Nvidia, and GitHub, according to the tool’s creator. A senior OpenAI employee has even contributed code to the project, adding support for OpenAI’s Codex tool.
Do you know anything else about token spend inside companies? I would love to hear from you. Using a non-work device, you can message me securely on Signal at joseph.404 or send me an email at joseph@404media.co.
“I made Caveman back in early April because I was using Claude Code heavily and noticed a lot of my token spend was going to unnecessary prose: pleasantries, hedging, transitions, and chatty language that does not really matter inside an agent loop,” Julius Brussee, the creator of caveman, told 404 Media.
One company using caveman is electrical and digital infrastructure giant Legrand which, ironically, has entered the data center business. An internal Legrand memo shared with 404 Media tells employees “since the billing system changed and the new quotas were implemented, we all need to be mindful of our usage of AI so we don’t use up our entire budget allowance too quickly.” It goes on to list four things that will produce “high impact”: not always using the most powerful model; not always using high reasoning settings for the LLMs; using different more appropriate models for different tasks; and finally “use ‘caveman skill’ to reduce output consumption (without impacting code).”
In 404 Media’s tests of caveman with Claude Code, the plugin does make the LLM’s answers much more to the point. “Want changes to it?” the LLM asked after I told it to review some previously written code. “Uses official API, not scraping,” the LLM added, describing how the code worked. When I double checked caveman was installed Claude outputted, “Already active. What you need?”
Caveman can also display what it says is the total number of tokens saved. In my case, caveman said it had saved me around 5,800 tokens, or 65 percent.
imageA screenshot of caveman in action.“It makes the model speak less like a polite chatbot and more like a terse tool,” Brussee said. “Same substance, fewer words. In my evals, Caveman cut output tokens by roughly 65–75 percent versus default verbose output, and still beat a normal ‘be concise’ instruction. That number varies by workflow, but the effect was clear.”
Caveman users can pick their level of “grunt”: lite, full (which is the default setting), ultra, or Wenyan, which translates the output into classical Chinese characters (I verified this works and now have no idea what the Claude output says).
“The goal was to reduce output tokens without touching the parts where exactness matters: code, commands, paths, URLs, numbers, function names, and technical details. Caveman mostly compresses the surrounding language,” Brussee added.
Records on GitHub show that Shayne Sweeney, director of engineering at OpenAI, has contributed code to caveman. A commit a couple of months ago says, “Add Codex plugin support.”
imageA screenshot of caveman in action.Caveman also offers a whole agent that condenses everything down to caveman language. “caveman-code shrink everything — full terminal coding agent, caveman top to bottom. ~2× fewer tokens than Codex on identical tasks. 20+ providers · plan mode · autopilot goal loop · MIT,” caveman’s GitHub repository says. Caveman can also be used with OpenClaw, the agentic AI tool that went massively viral earlier this year.
The plugin is obviously pretty funny but comes in response to a very real problem. In April, GitHub announced it was going to start charging customers per token rather than a flat subscription fee. Uber capped employee’s use of AI tools and the company’s CTO says Uber blew through its entire AI budget in just four months. Walmart also capped AI tool usage. And now you have companies using caveman.
“I’ve heard from many individual developers and engineers inside companies using or testing it, including people at OpenAI, NVIDIA, GitHub, and DEPT,” Brussee said.
In leaked audio obtained by 404 Media, Accenture positioned itself as the cure to this problem, even though it encouraged clients to adopt AI as quickly as possible in the first place. In that audio a senior employee said Accenture had a new opportunity with its clients “to really think about token economics.”
Last year OpenAI CEO Sam Altman suggested that people extending their own pleasantries to LLMs, like “please” and “thank you,” cost OpenAI tens of millions of dollars in electricity costs.
Legrand, OpenAI, Nvidia, and GitHub did not respond to requests for comment on their caveman use.
Caveman’s GitHub repository says near the end: “Caveman save you token, save you money.”
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み