ついにBERTの代替モデル登場:ModernBERTを発表
Answer.AI は、6800 万回の月間ダウンロードを誇る BERT の後継として、シーケンス長や処理速度を大幅に改善した「ModernBERT」を発表し、Hugging Face Transformers に統合された。
キーポイント
性能と効率の劇的向上
8192 の長いシーケンス長に対応し、Flash Attention 2 を活用することで処理速度が大幅に向上し、下流タスクでのパフォーマンスも旧世代モデルを上回る。
BERT との互換性と導入
ベース(1.49 億パラメータ)と大型(3.95 億パラメータ)サイズが用意され、既存の BERT ライクなモデルの slot-in リプレースとして容易に利用可能。
アーキテクチャの進化
従来の BERT で使用されていたトークンタイプ ID を廃止し、より現代的な設計を採用することで柔軟性と効率性を高めている。
BERT の代替モデルとしての性能向上
ModernBERT は速度と精度の両面で BERT を上回るパレート最適化を実現し、RAG パイプラインや推薦システムなどのエンコーダー専用モデル用途における新基準となる見込みです。
コンテキスト長とコード処理能力の拡大
コンテキスト長を 512 トークンから 8,000 トークンに拡張し、大規模なコードデータをトレーニングデータに含めることで、大規模コード検索や完全文書ベースの検索パイプラインといった新たな用途が可能になりました。
デコーダー型モデルの限界とエンコーダー型の必要性
大規模な生成モデル(LLM)はコストが高く遅いため、分類や検索など生成を必要としない実用的なタスクには、軽量で高速なエンコーダー型モデルの方が適しており、ModernBERT はこのニーズに応えるために設計されています。
エンコーダーモデルの役割と特性
エンコーダーモデルは双方向にトークンを参照できるため、生成モデルよりも効率的に情報を符号化し、実用的な言語処理の基盤として広く利用されています。
重要な引用
ModernBERT is a family of state-of-the-art encoder-only models representing improvements over older generation encoders across the board
ModernBERT will be included in v4.48.0 of transformers
If your GPU supports it, we recommend using ModernBERT with Flash Attention 2 to reach the highest efficiency
ModernBERT is a new model series that is a Pareto improvement over BERT and its younger siblings across both speed and accuracy.
Decoder-only models are too big, slow, private, and expensive for many jobs.
Encoder-only models are the workhorses of practical language processing, the models that are actually being used for such workloads right now in many scientific and commercial applications.
影響分析・編集コメントを表示
影響分析
この発表は、長年 AI エコシステムの基盤として君臨してきた BERT の実質的な後継モデルが登場したことを示しており、エンコーダーモデルの分野における技術的ブレイクスルーです。特に Flash Attention 2 との連携による効率化と、8192 という長いシーケンス長のサポートは、RAG や長文処理など現代の応用要件に即した進化であり、開発現場での実装基準が更新される重要な転換点となります。
編集コメント
BERT がリリースされてから 6 年が経過し、その実用性が揺らぐことなく維持されていた中で、ついに明確な後継モデルが登場したことは業界にとって大きな朗報です。特に既存の BERT ベースのコードベースを流用できる互換性を保ちつつ、性能と速度を大幅に改善している点は、現場開発者にとって即戦力となる価値が高いと言えます。
ついに BERT の代替モデルが登場
注記
これは、🤗 HuggingFace ブログに投稿された発表ブログ記事のクロスポストです。
TL;DR(要約)
本ブログ記事では、ModernBERT を紹介します。これは最新のエンコーダー専用モデルファミリーであり、あらゆる面で旧世代のエンコーダーよりも改善されており、シーケンス長は 8192、下流タスクでの性能が向上し、処理速度も大幅に高速化されています。
ModernBERT は、BERT に似たモデルに対するスロットイン(差し込み)代替として利用可能です。ベースサイズ(パラメータ数 149M)とラージサイズ(パラメータ数 395M)の両方が用意されています。
これらのモデルの使用方法についてはこちらをクリックしてください。
ModernBERT は transformers の v4.48.0 に含まれます。それまでは、メインブランチから transformers をインストールする必要があります:
pip install git+https://github.com/huggingface/transformers.git
ModernBERT はマスク言語モデル(MLM: Masked Language Model)であるため、fill-mask パイプラインを使用するか、AutoModelForMaskedLM を経由して読み込むことができます。分類、検索、QA などの下流タスクに ModernBERT を使用するには、標準的な BERT のファインチューニングレシピに従ってファインチューニングを行ってください。⚠️ GPU が対応している場合は、最高効率を達成するために Flash Attention 2 と併用することを推奨します。そのためには、以下のように Flash Attention をインストールし、通常通りモデルを使用してください:
pip install flash-attn
AutoModelForMaskedLM の使用例:
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
Predicted token: Paris
Using a pipeline:
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)
Note: ModernBERT does not use token type IDs, unlike some earlier BERT models. Most downstream usage is identical to standard BERT models on the Hugging Face Hub, except you can omit the token_type_ids parameter.
Introduction
BERT は 2018 年にリリースされました(AI の年次では数千年前!)ですが、今日でも広く使用されています。実際、現在 HuggingFace ハブで最もダウンロードされたモデルの第二位であり、月間ダウンロード数は 6,800 万回を超えています。これは、検索(RAG など)、分類(コンテンツモデレーションなど)、エンティティ抽出(プライバシーや規制コンプライアンスのため)といった、毎日直面する現実世界の問題に理想的なエンコーダー専用アーキテクチャを持っているからです。
ついに、6 年後の今日、その代替モデルが登場しました。Answer.AI と LightOn(そして仲間たち!)が ModernBERT をリリースします。ModernBERT は、速度と精度の両面で BERT やその若き兄弟たちに対するパレート最適化(Pareto improvement:より良い結果を犠牲なく達成する改善)を実現した新しいモデルシリーズです。このモデルは、近年の大規模言語モデル(LLM: Large Language Model)の研究から数十の進歩を取り入れ、アーキテクチャとトレーニングプロセスの更新を含む BERT スタイルのモデルに適用しています。
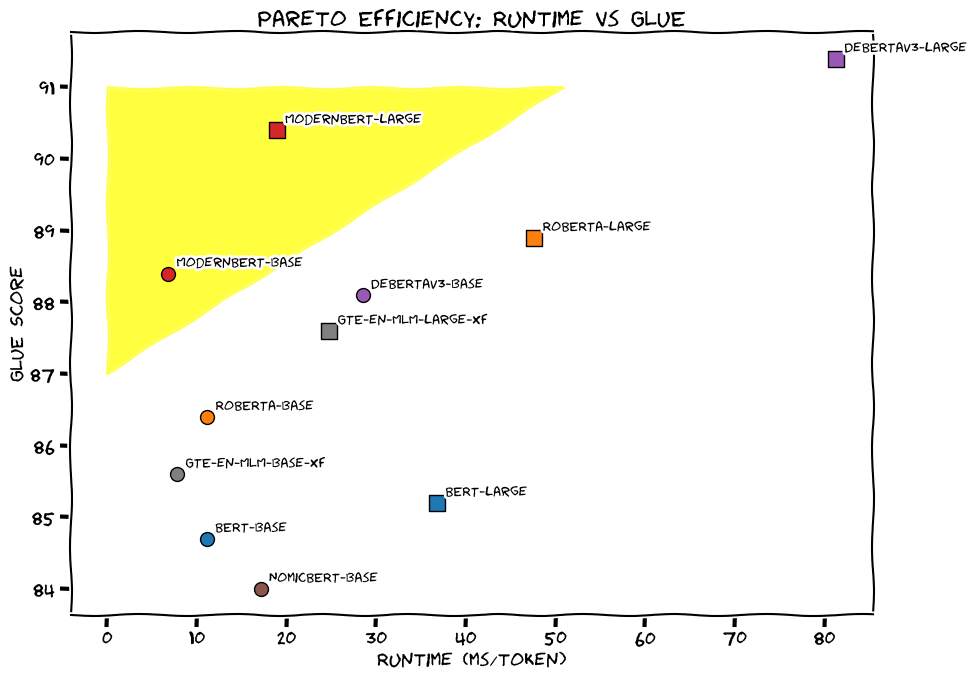
ModernBERT は、RAG パイプライン(検索拡張生成:Retrieval Augmented Generation)や推薦システムなど、現在エンコーダー専用モデルが展開されている多数のアプリケーションにおいて新たな標準となることを期待しています。
さらに、高速化と精度向上に加え、ModernBERT はコンテキスト長を 8k トークンに拡張しました(従来のエンコーダーでは通常 512 トークン程度)。また、トレーニングデータに大量のコードを含んだ初のエンコーダー専用モデルでもあります。これらの特徴により、大規模なコード検索、新しい IDE 機能、小片断ではなく文書全体に基づく検索パイプラインなど、これまでオープンモデルでは実現が難しかった新たな応用分野が開かれました。
しかし、私たちが何を行ったのかを説明するために、まずは一歩引いてこれまでの道のりを振り返ってみましょう。
デコーダー専用モデル
最近の注目すべき LLM(大規模言語モデル)の進展は、GPT、Llama、Claude などのモデルにおいて見られました。これらはデコーダー専用モデル、つまり生成モデルです。人間のようなコンテンツを生成する能力により、生成アートや対話型チャットといった驚くべき新しい GenAI(生成 AI)応用分野が実現しました。これらの目覚ましいアプリケーションは主要な投資を引きつけ、研究ブームを資金面で支え、技術的な急速な進展をもたらしました。私たちが行ったことは、本質的にこれらの進展をエンコーダー専用モデルへと移植したことです。
なぜか?多くの実用的な応用では、軽量で効率的なモデルが必要だからです。また、それが生成モデルである必要もありません。
より率直に言えば、デコーダー専用モデルは多くの業務において大きすぎ、遅すぎて、プライバシーの観点からもコスト高であり実用的ではありません。元々の GPT-1 は 1 億 1700 万パラメータを持つモデルでしたが、対照的に Llama 3.1 モデルには 4050 億パラメータが搭載されており、その技術報告書に記載されたデータ合成とキュレーションのレシピは、ほとんどの企業にとって再現するには複雑すぎ、コスト高すぎます。したがって、ChatGPT のようなモデルを利用する場合、外部の制御下にない重厚なサーバーから API 応答を得るために、セント単位で支払いを行い、秒単位で待たなければなりません。
もちろん、これらの巨大な生成モデルが持つオープンエンドな能力により、やむを得ない状況では非生成タスクや判別タスク(classification)にも使用することができます。これは、分類タスクを平易な英語で記述し、… モデルに分類させるだけで済むからです。しかし、このワークフローはプロトタイピングには素晴らしいものですが、量産段階に入ったらプロトタイプ用の価格を支払いたくはないはずです。
GenAI に関する人気の話題が、エンコーダー専用モデルの役割を覆い隠してしまっています。これらは実用的な言語処理における主力であり、多くの科学分野や商業アプリケーションで実際に現在もそのようなワークロードに使用されているモデルです。
エンコーダー専用モデル
エンコーダーモデルの出力は、数値のリスト(埋め込みベクトル)です。テキストで答えるのではなく、エンコーダーモデルはこの圧縮された数値形式に「答え」を literally 符号化していると言えます。このベクトルはモデルの入力の圧縮表現であり、そのためエンコーダー専用モデルは時として表現モデルとも呼ばれます。
デコーダー専用モデル(GPT など)はエンコーダー専用モデル(BERT など)の役割を果たすことも可能ですが、重要な制約によって足かせを付けられています。生成モデルであるため、数学的に「後続のトークンを覗き込む」ことが許されておらず、常に過去方向しか見ることができないのです。これに対し、エンコーダー専用モデルは各トークンが前後(双方向的)に参照できるように訓練されており、そのために設計されています。この構造こそが、彼らが得意とする分野において非常に効率的である理由です。
要するに、OpenAI の O1 などの最先端モデルはフェラーリ SF-23 のようなものです。明らかに工学上の偉業であり、レースで勝つために設計されたため、私たちがこれについて語るのです。しかし、タイヤを交換するためには特別なピットクルーが必要であり、個人で購入することもできません。一方、BERT モデルはホンダ・シビックのようなものです。これもまた工学上の偉業ですが、より微妙な点として、手頃な価格で、燃費が良く、信頼性が高く、極めて有用であるように設計されています。だからこそ、そこら中に溢れているのです。
これは様々な角度から見て確認できます。
生成モデルのサポート:表現モデル(エンコーダー専用)の普及を理解する一つの方法は、安全かつ効率的なシステムを構築するために、これらがデコーダー専用のモデルとどのように頻繁に併用されているかを確認することです。
明白な例として RAG が挙げられます。LLM のパラメータに学習された知識に依存するのではなく、このシステムはドキュメントストアを使用して、クエリに関連する情報を LLM に提供します。しかしもちろん、これは問題を先送りしているだけです。LLM がどのドキュメントがクエリに関連するかを知らない場合、システムはそのドキュメントを選択するための他のプロセスが必要になります。つまり、LLM を有用にするために必要な大量の情報をエンコードするために使用できるほど高速かつ安価なモデルが必要です。そのモデルは多くの場合、BERT に似たエンコーダー専用モデルです。ModernBERT などのエンコーダーが RAG パイプラインにおいてどのように重要であるかについては、Benjamin Clavié の講演をご覧ください。
もう一つの例として、生成されたテキストがコンテンツの安全性要件に違反しないことを保証するために安価な分類器を使用する監督アーキテクチャがあります。
要するに、デプロイされているデコーダー専用モデルを目にする whenever には、エンコーダー専用モデルもシステムの一部である可能性が高いです。しかし、その逆は真ではありません。
エンコーダーベースのシステム:GPT が登場する以前から、ソーシャルメディアや Netflix などのプラットフォームではコンテンツ推薦が行われていました。また、これらの場所や検索、その他様々な場所でも広告ターゲティングが実施されており、スパム検出や悪質行為検出のためのコンテンツ分類も存在していました。これらすべてのシステムは生成モデルではなく、エンコーダーのみで構成されるような表現モデルを基盤として構築されたものです。そして、これらすべてのシステムは今なお世界中に存在し、膨大な規模で稼働し続けています。1 秒間に世界中でどれほどの広告がターゲティングされているかを想像してみてください!
ダウンロード数:HuggingFace において、主要な BERT ベースモデルの一つである RoBERTa のダウンロード数は、同プラットフォーム上で最も人気のある大規模言語モデル(LLM)10 個を合わせたものよりも多くなっています。実際、現在、エンコーダーのみで構成されるモデルの月間ダウンロード合計は 10 億回を超え、3.97 億回の月間ダウンロード数を持つデコーダーのみで構成されるモデルの約 3 倍に達しています。さらに、「fill-mask」モデルカテゴリ(ModernBERT のようなエンコーダー「ベースモデル」で構成され、他の下流タスク用に微調整可能な状態にあるもの)は、全体として最もダウンロードされているモデルカテゴリとなっています。
推論コスト:上記の示唆するところは、推論単位あたりの比較において、エンコーダー専用モデルに対してデコーダー専用モデルや生成モデルの方が、1 年間に実行される推論回数が桁違いに多いということです。興味深い例として FineWeb-Edu が挙げられますが、ここではモデルベースの品質フィルタリングを 15 トリリオントークン規模で実施する必要がありました。FineWeb-Edu チームは、デコーダー専用モデルである Llama-3-70b-Instruct を用いて注釈を生成し、フィルタリングの大部分を微調整済みの BERT ベースモデルで行うことを選択しました。このフィルタリングには 6,000 H100 時間の計算リソースが必要となり、HuggingFace Inference Points の価格(1 時間あたり 10 ドル)で計算すると、合計 60,000 ドルとなりました。一方、15 トリリオントークンを人気のあるデコーダー専用モデルに投入した場合、Google の Gemini Flash を用いて最も低コストなオプション(推論コストは 100 万トークンあたり 0.075 ドル)を選んだとしても、費用は 100 万ドルを超えてしまいます!
パフォーマンス
概要
以下に、標準的な学術ベンチマークで測定された ModernBERT とその他のモデルの精度のスナップショットを示します。ご覧の通り、ModernBERT はあらゆるカテゴリで最高スコアを記録している唯一のモデルであり、エンコーダーベースのタスクすべてに対応できる単一のモデルとして最適です:
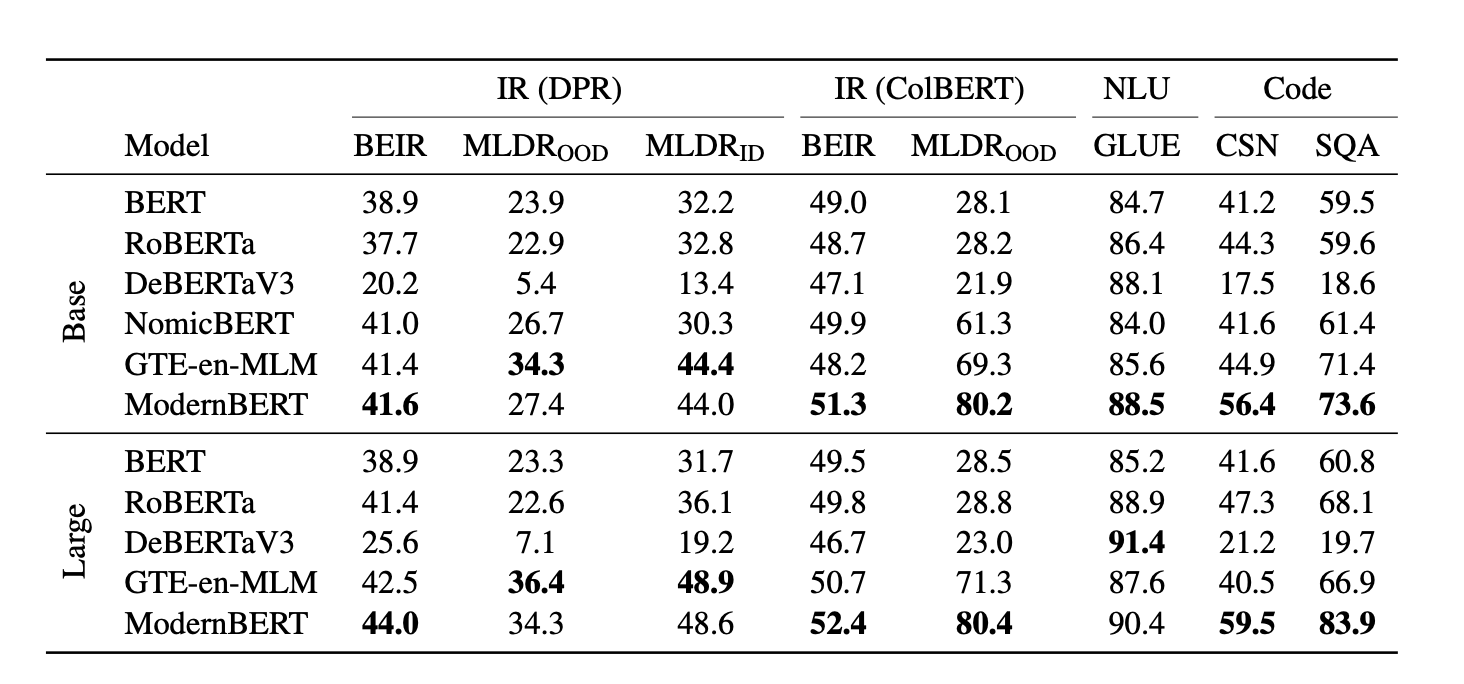
もしあなたが Kaggle で NLP コンペティションに参加した経験があれば、DeBERTaV3 が長年チャンピオンの選択となってきたことを知っているでしょう。しかしもはやそうではありません:ModernBERT は GLUE ベンチマークで DeBERTaV3 を打ち破った初のベースサイズモデルであるだけでなく、Deberta のメモリ使用量の 5 分の 1 未満しか消費しません。
もちろん ModernBERT は高速です。DeBERTa と比較して 2 倍速であり、実際には入力長が混合されているより一般的な状況では最大 4 倍も高速です。その長いコンテキスト推論は、NomicBERT や GTE-en-MLM などの他の高品質モデルと比較してほぼ 3 倍の速度を誇ります。
ModernBERT のコンテキスト長は 8,192 トークンで、既存のエンコーダーの多くよりも 16 倍以上大きくなっています。これは例えば RAG パイプラインにおいて極めて重要です。なぜなら、小さなコンテキストではセマンティック理解のためにチャンクが小さすぎる場合があるからです。ModernBERT は ColBERT と組み合わせて最良の長文コンテキスト検索器としても機能し、他の長文コンテキストモデルよりも 9 ポイント高いスコアを記録しています。さらに印象的なのは、この非常に短期間で訓練されたモデルが、単に他のバックボーンと比較するように調整されただけで、長文コンテキストタスクにおいて広く使用されている検索モデルさえも上回っていることです。
コードの検索においては、ModernBERT は唯一無二です。これと比較できるものはほとんどありません。なぜなら、これまでこのような大量のコードデータで訓練されたエンコーダーモデルは存在しなかったからです。例えば、コードと自然言語を混合したハイブリッドデータセットである StackOverflow-QA データセット(SQA)では、ModernBERT の専門的なコード理解能力と長文コンテキスト対応機能が組み合わさり、このタスクで 80 を超えるスコアを記録できる唯一のバックボーンとなっています。
これは、この能力を基盤とした全く新しいアプリケーションが構築される可能性を示しています。例えば、ModernBERT の埋め込みベクトルを用いて企業全体のコードベースをインデックス化し、すべてのリポジトリにわたって関連するコードの高速な長文脈検索を提供する AI 接続 IDE を想像してみてください。あるいは、数十の別々のプロジェクトを統合したアプリケーション機能の動作方法を説明するコードチャットサービスも考えられます。
主流モデルと比較して、ModernBERT は検索、自然言語理解、コード検索というほぼすべての主要タスクカテゴリにおいて優れたパフォーマンスを発揮します。自然言語理解の特定の領域では DeBERTaV3 にわずかに劣りますが、その処理速度は桁違いに高速です。なお、ModernBERT も他のベースモデルと同様、標準状態ではマスクされた単語予測のみが可能です。その他のタスクを実行するためには、これらのボイラープレートで行われているように、ベースモデルをファインチューニングする必要があります。
専門化されたモデルと比較すると、ModernBERT はほとんどのタスクにおいて同等かそれ以上の性能を示します。さらに、ModernBERT はほとんどのタスクで他のモデルよりも高速であり、最大 8,192 トークンの入力を処理可能です。これは主流モデルの約 16 倍に相当する長さです。
効率性
NVIDIA RTX 4090 における ModernBERT とその他のデコーダーモデルのメモリ(最大バッチサイズ、BS)および推論(秒間数千トークン)の効率性結果は以下の通りです:
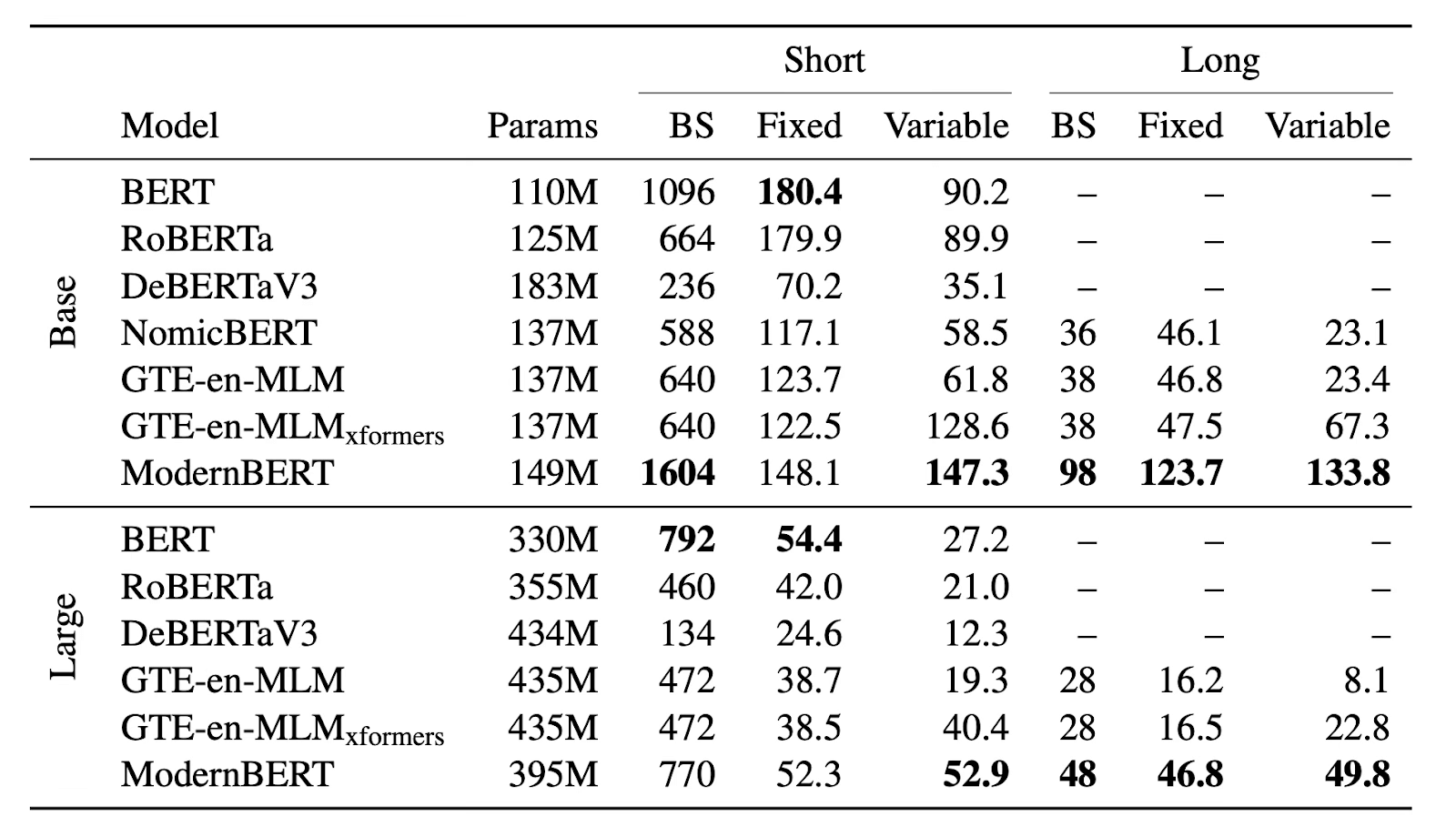
まず気づくかもしれないのは、最新の入手困難で過熱しているハードウェアではなく、手頃な価格の消費者向け GPU で効率性を分析している点です。何よりも、ModernBERT は hype(過剰な期待)ではなく実用性に焦点を当てています。
この焦点の一環として、ModernBERT がベンチマークだけでなく、実際のアプリケーションでも十分に機能するように確保しました。このようなモデルは通常、最も得意とする特定のサイズ、つまり最大コンテキスト長でのみテストされます。これが表の「固定」列で示されている内容です。しかし、現実世界では入力サイズは多様であるため、私たちが特に最適化に取り組んだのはそのパフォーマンス、すなわち「可変」列の結果です。ご覧の通り、可変長の入力を扱う場合、ModernBERT は他のすべてのモデルよりもはるかに高速です。
最も価値があり重要な将来のアプリケーションの基盤になると信じている長いコンテキスト入力においては、ModernBERT は次点のモデルよりも 2〜3 倍高速です。そして、「実用性」の観点から再び申し上げます:ModernBERT は追加の重い「xformers」依存性を必要とせず、代わりに現在では一般的になった Flash Attention(フラッシュアテンション)のみを依存関係として要求します。
さらに、ModernBERT の効率性のおかげで、ほぼ他のどのモデルよりも大きなバッチサイズを使用でき、より小さく安価な GPU でも効果的に利用可能です。特にベースサイズの効率は、ブラウザやスマートフォン上で直接動作する新たなアプリケーションの実現を可能にするかもしれません。
なぜ ModernBERT は「モダン」なのか?
さて、エンコーダーモデルにより多くの愛を注ぐべき理由について、私たちは主張してきました。信頼できる、過小評価された労働馬として、彼らは 2018 年の BERT 以来、驚くほど少ない更新しか受けていません。
さらに驚くべきことに、RoBERTa 以降、トレードオフなしに全体的な改善をもたらすエンコーダーは存在しません(これは「パレート最適化」というおしゃれな言葉で知られています)。DeBERTaV3 は GLUE や分類性能において優れていましたが、効率性と検索能力の両方を犠牲にしました。他のモデル、例えば AlBERT や、より新しい GTE-en-MLM などは、元の BERT や RoBERTa のいくつかの点では改善しましたが、別の点では後退しています。
しかし、このデュオが最初にリリースされて以来、より良い言語モデルを構築する方法について膨大な量の知識を得てきました。LLM を一度でも使用したことがある方ならご存知でしょう:エンコーダーの世界では稀ですが、デコーダーの世界ではパレート最適化は常態化しており、モデルは常にあらゆる点で向上し続けています。そして今や私たちが皆学んだように、モデルの改善は部分的には魔法のようなものですが、大部分はエンジニアリングによるものです。
(おそらく適切な名付けがされた)ModernBERT プロジェクトの目標は、非常にシンプルでした:この現代的なエンジニアリングをエンコーダーモデルに持ち込むことです。私たちはそれを 3 つのコアな方法で実現しました。
現代化されたトランスフォーマーアーキテクチャ
効率性への特別な配慮
現代的なデータスケールとソース
新しいトランスフォーマー、旧いトランスフォーマーと同じ
トランスフォーマーアーキテクチャは支配的となり、現在では大多数のモデルで使用されています。しかし、トランスフォーマーには一つではなく多数存在することを忘れないでください。それらが共有する主な点は、アテンションこそがすべて必要であるという深い信念であり、その結果、アテンションメカニズムを中心に様々な改良を施しています。
ModernBERT は、Mamba によって命名された「Transformer++」から多大なインスピレーションを得ており、これは Llama2 シリーズのモデルで初めて採用されました。具体的には、従来の BERT 風の構成要素を、その改良版に置き換えます。すなわち、以下の通りです。
古い位置エンコーディングを「回転位置埋め込み(Rotary Positional Embeddings: RoPE)」に置き換え、単語間の相対的な位置関係を理解する能力を大幅に向上させ、より長いシーケンス長へのスケーリングを可能にします。
従来の MLP 層を GeGLU 層に切り替え、オリジナルの BERT で使用されていた GeLU 活性化関数を改善します。
不要なバイアス項を削除してアーキテクチャを簡素化し、パラメータ予算をより効果的に活用できるようにします。
埋め込み層の後に追加の正規化層を追加し、トレーニングの安定性を高めます。
ホンダ・シビックのレーストラック向けアップグレードについて
これはすでに解説済みです:エンコーダーはフェラーリではなく、ModernBERT も例外ではありません。しかし、それが高速ではないという意味ではありません。ハイウェイを走行する際、通常は車を乗り換えてレーシングカーにするのではなく、信頼性の高い日常車でも速度制限を快適に達成できることを望むものです。
実際、上記で挙げたすべてのアプリケーションケースにおいて、速度は不可欠です。エンコーダーは、膨大なデータを処理する必要があり、わずかな速度の向上でもすぐに大きな効果をもたらす場合や、RAG(検索拡張生成)のようにレイテンシが極めて重要な場合に非常に人気があります。多くの状況では、エンコーダーは CPU で実行されており、合理的な時間内に結果を得るためには、ここでさらに効率性が重要になります。
研究におけるほとんどの事柄と同様に、私たちは巨人の肩の上に立って構築しており、Flash Attention 2 の速度向上を積極的に活用しています。私たちの効率化の改善は、3 つの主要なコンポーネントに依存しています:処理効率を高めるための「交互アテンション(Alternating Attention)」、計算上の無駄を減らすための「アンパディングとシーケンスパッキング(Unpadding and Sequence Packing)」、そしてハードウェア利用率を最大化するための「ハードウェア対応モデル設計(Hardware-Aware Model Design)」です。
グローバルおよびローカルアテンション
ModernBERT の最も影響力のある機能の一つは、フルグローバルアテンションではなく、交互アテンションです。技術的な用語で言えば、これは私たちのアテンションメカニズムが 3 レイヤーごとに全入力にアテンションを向ける(グローバルアテンション)一方で、他のすべてのレイヤーではスライディングウィンドウを使用し、各トークンが自分自身から最も近い 128 トークンのみにアテンションを向ける(ローカルアテンション)ことを意味します。
アテンションの計算複雑性は追加されるトークンごとに爆発的に増加するため、これにより ModernBERT は他のどのモデルよりもはるかに長い入力シーケンスを高速に処理できます。
実際の実装では、以下のようになります:
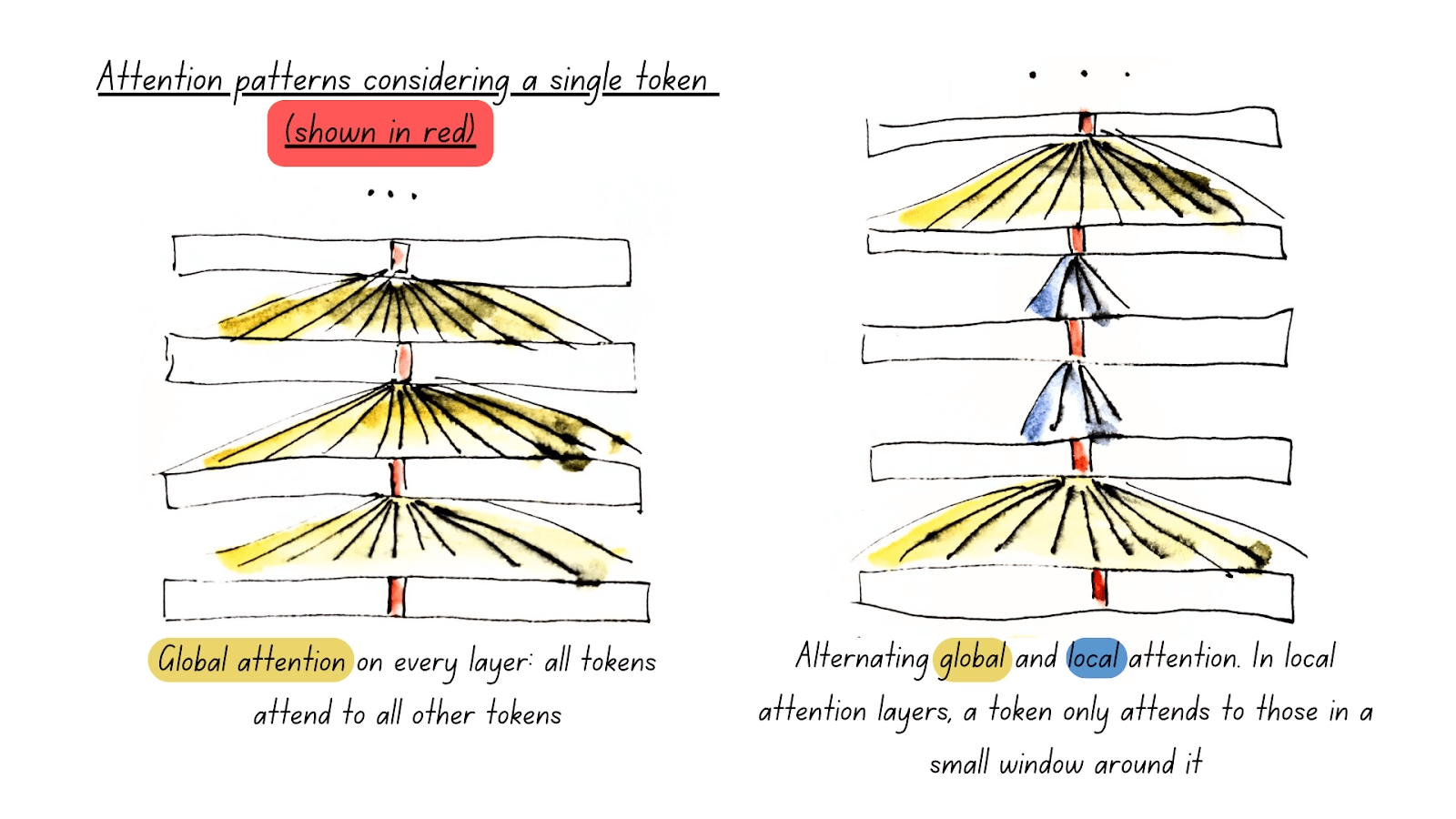
概念的には、これが機能する理由は非常にシンプルです。本を読んでいる自分を想像してみてください。あなたが読む文ごとに、その文のほとんどを理解するために、プロット全体を完全に把握する必要がありますか?
原文を表示
Finally, a Replacement for BERT
Note
This is a cross-post of the announcement blog post posted on the 🤗 HuggingFace blog.
TL;DR
This blog post introduces ModernBERT, a family of state-of-the-art encoder-only models representing improvements over older generation encoders across the board, with a 8192 sequence length, better downstream performance and much faster processing.
ModernBERT is available as a slot-in replacement for any BERT-like models, with both a base (149M params) and large (395M params) model size.
Click to see how to use these models with transformers
ModernBERT will be included in v4.48.0 of transformers. Until then, it requires installing transformers from main:
pip install git+https://github.com/huggingface/transformers.git
Since ModernBERT is a Masked Language Model (MLM), you can use the fill-mask pipeline or load it via AutoModelForMaskedLM. To use ModernBERT for downstream tasks like classification, retrieval, or QA, fine-tune it following standard BERT fine-tuning recipes. ⚠️ If your GPU supports it, we recommend using ModernBERT with Flash Attention 2 to reach the highest efficiency. To do so, install Flash Attention as follows, then use the model as normal:
pip install flash-attn
Using AutoModelForMaskedLM:
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
Predicted token: Paris
Using a pipeline:
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)
Note: ModernBERT does not use token type IDs, unlike some earlier BERT models. Most downstream usage is identical to standard BERT models on the Hugging Face Hub, except you can omit the token_type_ids parameter.
Introduction
BERT was released in 2018 (millennia ago in AI-years!) and yet it’s still widely used today: in fact, it’s currently the second most downloaded model on the HuggingFace hub, with more than 68 million monthly downloads, only second to another encoder model fine-tuned for retrieval. That’s because its encoder-only architecture makes it ideal for the kinds of real-world problems that come up every day, like retrieval (such as for RAG), classification (such as content moderation), and entity extraction (such as for privacy and regulatory compliance).
Finally, 6 years later, we have a replacement! Today, we at Answer.AI and LightOn (and friends!) are releasing ModernBERT. ModernBERT is a new model series that is a Pareto improvement over BERT and its younger siblings across both speed and accuracy. This model takes dozens of advances from recent years of work on large language models (LLMs), and applies them to a BERT-style model, including updates to the architecture and the training process.
We expect to see ModernBERT become the new standard in the numerous applications where encoder-only models are now deployed, such as in RAG pipelines (Retrieval Augmented Generation) and recommendation systems.
In addition to being faster and more accurate, ModernBERT also increases context length to 8k tokens (compared to just 512 for most encoders), and is the first encoder-only model that includes a large amount of code in its training data. These features open up new application areas that were previously inaccessible through open models, such as large-scale code search, new IDE features, and new types of retrieval pipelines based on full document retrieval rather than small chunks.
But in order to explain just what we did, let’s first take a step back and look at where we’ve come from.
Decoder-only models
The recent high-profile advances in LLMs have been in models like GPT, Llama, and Claude. These are decoder-only models, or generative models. Their ability to generate human-like content has enabled astonishing new GenAI application areas like generated art and interactive chat. These striking applications have attracted major investment, funded booming research, and led to rapid technical advances. What we’ve done, essentially, is port these advances back to an encoder-only model.
Why? Because many practical applications need a model that’s lean and mean! And it doesn’t need to be a generative model.
More bluntly, decoder-only models are too big, slow, private, and expensive for many jobs. Consider that the original GPT-1 was a 117 million parameter model. The Llama 3.1 model, by contrast, has 405 billion parameters, and its technical report describes a data synthesis and curation recipe that is too complex and expensive for most corporations to reproduce. So to use such a model, like ChatGPT, you pay in cents and wait in seconds to get an API reply back from heavyweight servers outside of your control.
Of course, the open-ended capabilities of these giant generative models mean that you can, in a pinch, press them into service for non-generative or discriminative tasks, such as classification. This is because you can describe a classification task in plain English and … just ask the model to classify. But while this workflow is great for prototyping, you don’t want to pay prototype prices once you’re in mass production.
The popular buzz around GenAI has obscured the role of encoder-only models. These are the workhorses of practical language processing, the models that are actually being used for such workloads right now in many scientific and commercial applications.
Encoder-only models
The output of an encoder-only model is a list of numerical values (an embedding vector). You might say that instead of answering with text, an encoder model literally encodes its “answer” into this compressed, numerical form. That vector is a compressed representation of the model’s input, which is why encoder-only models are sometimes referred to as representational models.
While decoder-only models (like a GPT) can do the work of an encoder-only model (like a BERT), they are hamstrung by a key constraint: since they are generative models, they are mathematically “not allowed” to “peek” at later tokens. They can only ever look backwards. This is in contrast to encoder-only models, which are trained so each token can look forwards and backwards (bi-directionally). They are built for this, and it makes them very efficient at what they do.
Basically, a frontier model like OpenAI’s O1 is like a Ferrari SF-23. It’s an obvious triumph of engineering, designed to win races, and that’s why we talk about it. But it takes a special pit crew just to change the tires and you can’t buy one for yourself. In contrast, a BERT model is like a Honda Civic. It’s also an engineering triumph, but more subtly, since it is engineered to be affordable, fuel-efficient, reliable, and extremely useful. And that’s why they’re absolutely everywhere.
You can see this by looking at it a number of ways.
Supporting generative models: One way to understand the prevalence of representational models (encoder-only) is to note how frequently they are used in concert with a decoder-only model to make a system which is safe and efficient.
The obvious example is RAG. Instead of relying on the LLM’s knowledge trained into the model’s parameters, the system uses a document store to furnish the LLM with information relevant to the query. But of course this only defers the problem. If the LLM doesn’t know which documents are relevant to the query, then the system will need some other process to select those documents? It’s going to need a model which is fast and cheap enough that it can be used to encode the large quantities of information needed to make the LLM useful. That model is often a BERT-like encoder-only model. For more details on how Encoders like ModernBERT are critical in RAG pipelines, see this talk by Benjamin Clavié.
Another example is supervision architectures, where a cheap classifier might be used to ensure that generated text does not violate content safety requirements.
In short, whenever you see a decoder-only model in deployment, there’s a reasonable chance an encoder-only model is also part of the system. But the converse is not true.
Encoder-based systems: Before there was GPT, there were content recommendations in social media and in platforms like Netflix. There was ad targeting in those venues, in search, and elsewhere. There was content classification for spam detection, abuse detection, etc.. These systems were not built on generative models, but on representational models like encoder-only models. And all these systems are still out there and still running at enormous scale. Imagine how many ads are targeted per second around the world!
Downloads: On HuggingFace, RoBERTa, one of the leading BERT-based models, has more downloads than the 10 most popular LLMs on HuggingFace combined. In fact, currently, encoder-only models add up to over a billion downloads per month, nearly three times more than decoder-only models with their 397 million monthly downloads. In fact, the fill-mask model category, composed of encoder “base models” such as ModernBERT, ready to be fine-tuned for other downstream applications, is the most downloaded model category overall.
Inference costs: What the above suggests, is that on an inference-per-inference basis, there are many times more inferences performed per year on encoder-only models than on decoder-only or generative models. An interesting example is FineWeb-Edu, where model-based quality filtering had to be performed over 15 trillion tokens. The FineWeb-Edu team chose to generate annotations with a decoder-only model, Llama-3-70b-Instruct, and perform the bulk of the filtering with a fine-tuned BERT-based model. This filtering took 6,000 H100 hours, which, at HuggingFace Inference Points’ pricing of $10/hour, comes to a total of $60,000. On the other hand, feeding 15 trillion tokens to popular decoder-only models, even with the lowest-cost option of using Google’s Gemini Flash and its low inference cost of $0.075/million tokens, would cost over one million dollars!
Performance
Overview
Here’s a snapshot of the accuracy of ModernBERT and other models across a range of tasks, as measured by standard academic benchmarks – as you can see, ModernBERT is the only model which is a top scorer across every category, which makes it the one model you can use for all your encoder-based tasks:
If you’ve ever done an NLP competition on Kaggle, then you’ll know that DeBERTaV3 has been the choice of champions for years. But no longer: not only is ModernBERT the first base-size model to beat DeBERTaV3 on GLUE, it also uses less than 1/5th of Deberta’s memory.
And of course, ModernBERT is fast. It’s twice as fast as DeBERTa – in fact, up to 4x faster in the more common situation where inputs are mixed length. Its long context inference is nearly 3 times faster than other high-quality models such as NomicBERT and GTE-en-MLM.
ModernBERT’s context length of 8,192 tokens is over 16x larger than most existing encoders. This is critical, for instance, in RAG pipelines, where a small context often makes chunks too small for semantic understanding. ModernBERT is also the state-of-the-art long context retriever with ColBERT, and is 9 percentage points above the other long context models. Even more impressive: this very quickly trained model, simply tuned to compare to other backbones, outperforms even widely-used retrieval models on long-context tasks!
For code retrieval, ModernBERT is unique. There’s nothing to really compare it to, since there’s never been an encoder model like this trained on a large amount of code data before. For instance, on the StackOverflow-QA dataset (SQA), which is a hybrid dataset mixing both code and natural language, ModernBERT’s specialized code understanding and long-context capabilities make it the only backbone to score over 80 on this task.
This means whole new applications are likely to be built on this capability. For instance, imagine an AI-connected IDE which had an entire enterprise codebase indexed with ModernBERT embeddings, providing fast long context retrieval of the relevant code across all repositories. Or a code chat service which described how an application feature worked that integrated dozens of separate projects.
Compared to the mainstream models, ModernBERT performs better across nearly all three broad task categories of retrieval, natural language understanding, and code retrieval. Whilst it slightly lags DeBERTaV3 in one area (natural language understanding), it is many times faster. Please note that ModernBERT, as any other base model, can only do masked word prediction out-of-the-box. To be able to perform other tasks, the base model should be fine-tuned as done in these boilerplates.
Compared to the specialized models, ModernBERT is comparable or superior in most tasks. In addition, ModernBERT is faster than most models across most tasks, and can handle inputs up to 8,192 tokens, 16x longer than the mainstream models.
Efficiency
Here’s the memory (max batch size, BS) and Inference (in thousands of tokens per second) efficiency results on an NVIDIA RTX 4090 for ModernBERT and other decoder models:
The first thing you might notice is that we’re analysing the efficiency on an affordable consumer GPU, rather than the latest unobtainable hyped hardware. First and foremost, ModernBERT is focused on practicality, not hype.
As part of this focus, it also means we’ve made sure ModernBERT works well for real-world applications, rather than just benchmarks. Models of this kind are normally tested on just the one exact size they’re best at – their maximum context length. That’s what the “fixed” column in the table shows. But input sizes vary in the real world, so that’s the performance we worked hard to optimise – the “variable” column. As you can see, for variable length inputs, ModernBERT is much faster than all other models.
For long context inputs, which we believe will be the basis for the most valuable and important future applications, ModernBERT is 2-3x faster than the next fastest model. And, on the “practicality” dimension again: ModernBERT doesn’t require the additional heavy “xformers” dependency, but instead only requires the now commonplace Flash Attention as a dependency.
Furthermore, thanks to ModernBERT’s efficiency, it can use a larger batch size than nearly any other model, and can be used effectively on smaller and cheaper GPUs. The efficiency of the base size, in particular, may enable new applications that run directly in browsers, on phones, and so forth.
Why is ModernBERT, well, Modern?
Now, we’ve made our case to why we should give some more love to encoder models. As trusted, under-appreciated workhorses, they’ve had surprisingly few updates since 2018’s BERT!
Even more surprising: since RoBERTa, there has been no encoder providing overall improvements without tradeoffs (fancily known as “Pareto improvements”): DeBERTaV3 had better GLUE and classification performance, but sacrificed both efficiency and retrieval. Other models, such as AlBERT, or newer ones, like GTE-en-MLM, all improved over the original BERT and RoBERTa in some ways but regressed in others.
However, since the duo’s original release, we’ve learned an enormous amount about how to build better language models. If you’ve used LLMs at all, you’re very well aware of it: while they’re rare in the encoder-world, Pareto improvements are constant in decoder-land, where models constantly become better at everything. And as we’ve all learned by now: model improvements are only partially magic, and mostly engineering.
The goal of the (hopefully aptly named) ModernBERT project was thus fairly simple: bring this modern engineering to encoder models. We did so in three core ways:
a modernized transformer architecture
particular attention to efficiency
modern data scales & sources
Meet the New Transformer, Same as the Old Transformer
The Transformer architecture has become dominant, and is used by the vast majority of models nowadays. However, it’s important to remember that there isn’t one but many Transformers. The main thing they share in common is their deep belief that attention is indeed all you need, and as such, build various improvements centered around the attention mechanism.
ModernBERT takes huge inspiration from the Transformer++ (as coined by Mamba), first used by the Llama2 family of models. Namely, we replace older BERT-like building blocks with their improved equivalent, namely, we:
Replace the old positional encoding with “rotary positional embeddings” (RoPE): this makes the model much better at understanding where words are in relation to each other, and allows us to scale to longer sequence lengths.
Switch out the old MLP layers for GeGLU layers, improving on the original BERT’s GeLU activation function.
Streamline the architecture by removing unnecessary bias terms, letting us spend our parameter budget more effectively
Add an extra normalization layer after embeddings, which helps stabilize training
Upgrading a Honda Civic for the Race Track
We’ve covered this already: encoders are no Ferraris, and ModernBERT is no exception. However, that doesn’t mean it can’t be fast. When you get on the highway, you generally don’t go and trade in your car for a race car, but rather hope that your everyday reliable ride can comfortably hit the speed limit.
In fact, for all the application cases we mentioned above, speed is essential. Encoders are very popular in uses where they either have to process tons of data, allowing even tiny speed increments to add up very quickly, or where latency is very important, as is the case on RAG. In a lot of situations, encoders are even run on CPU, where efficiency is even more important if we want results in a reasonable amount of time.
As with most things in research, we build while standing on the shoulders of giants, and heavily leverage Flash Attention 2’s speed improvements. Our efficiency improvements rely on three key components: Alternating Attention, to improve processing efficiency, Unpadding and Sequence Packing, to reduce computational waste, and Hardware-Aware Model Design, to maximise hardware utilization.
Global and Local Attention
One of ModernBERT’s most impactful features is Alternating Attention, rather than full global attention. In technical terms, this means that our attention mechanism only attends to the full input every 3 layers (global attention), while all other layers use a sliding window where every token only attends to the 128 tokens nearest to itself (local attention).
As attention’s computational complexity balloons up with every additional token, this means ModernBERT can process long input sequences considerably faster than any other model.
In practice, it looks like this:
Conceptually, the reason this works is pretty simple: Picture yourself reading a book. For every sentence you read, do you need to be fully aware of the entire plot to understand most of i
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み