深層解説:AI エージェント・ハネスの構造
Akshay Pachaar は、大規模言語モデルを自律的なエージェントへと変換する「AI Agent Harness」という概念を定義し、その構成要素と生産環境での実装戦略を詳細に解説している。
キーポイント
Agent Harness の定義と重要性
モデル自体ではなく、その周囲のアーキテクチャ(循環、ツール、記憶、コンテキスト管理など)を指す「AI Agent Harness」が、モデルの性能を決定づける核心であると提唱されている。
OS アナロジーによる技術的構造
裸の LLM を CPU に例え、コンテキストをメモリ、外部 DB をディスク、ツールをドライバーとし、Harness を OS として機能させることで、計算システムの自然な抽象化を再構築している。
3 つのエンジニアリング層
提示詞工程、コンテキスト工程に加え、それらを含む包括的な「Harness 工程」が、生産環境で安定して動作するエージェントシステムを構築するために不可欠であると区別されている。
12 のコアコンポーネント
Anthropic や OpenAI の実践に基づき、生産レベルの Harness を構成する「オーケストレーションループ」「ツール」「記憶」など 12 の具体的な技術要素がリストアップされている。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発におけるパラダイムシフトを明確に示しており、今後は「モデルの性能」よりも「それをどう制御・統合するか」というアーキテクチャ設計が競争優位性の鍵となることを示唆しています。開発者はプロンプトエンジニアリングからシステムエンジニアリングへと視座を広げ、生産環境での安定性を担保する Harness の構築に注力する必要があります。
編集コメント
「モデルが全てではない」という本質的な指摘は、多くの開発者が直面する生産環境での不安定さに対する解決策として非常に示唆に富んでいます。今後はこの「Harness」の標準化やベストプラクティスが業界の主要なトピックになるでしょう。
深度拆解:AI Agent Harness 的构造
作者:Akshay
原文:The Anatomy of an Agent Harness
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能 Agent(Agent)的底层机制。
你可能已经开发过聊天机器人,甚至可能用一些工具搭建了一个 ReAct 循环 (ReAct:Reason + Act,一种让模型在行动前先进行推理的模式)。跑 Demo 的时候看着挺好,但一旦投入生产环境,系统就会开始掉链子:模型会忘记三步前做了什么,工具调用悄悄报错,上下文窗口(Context Window)里塞满了毫无意义的垃圾信息。
问题其实并不在模型本身,而在模型外围的基础设施。
LangChain 证明了这一点:他们仅仅通过改变包裹大语言模型的底层架构——模型没变,参数没变——就让系统在 TerminalBench 2.0 (一个衡量 AI Agent 处理命令行任务能力的权威基准测试) 上的排名从 30 名开外飙升到了第 5 名。另一项研究则通过让大语言模型自己去优化这套架构,实现了 76.4% 的通过率,甚至超过了人类精心设计的系统。
现在,这套基础设施有了一个正式的名字:AI Agent Harness。
什么是 Agent Harness?
虽然这个术语在 2026 年初才正式确立,但其核心理念早已存在。Harness是包裹在大语言模型之外的完整软件架构:它包括编排循环、工具、记忆、上下文管理、状态持久化、错误处理和护栏(Guardrails)。Anthropic 在其 Claude Code 文档中直截了当地指出:SDK(软件开发工具包)就是“驱动 Claude Code 的 Agent Agent Harness”。OpenAI 的 Codex 团队也使用了同样的说法,明确将“Agent”和“Harness”等同,指代那些让大语言模型真正发挥作用的非模型架构。
我非常喜欢 LangChain 的 Vivek Trivedy 给出的定义公式:“如果你不是模型本身,那你就是 Harness。”
这里有一个经常让人搞混的区别:“AI Agent”(Agent)是用户感知到的行为体现,它是一个有目标、会用工具、能自我纠错的实体;而“Harness”则是产生这种行为的背后机器。当有人说“我开发了一个 Agent”时,他真正的意思是“我开发了一套 Harness,并把它接入了模型”。
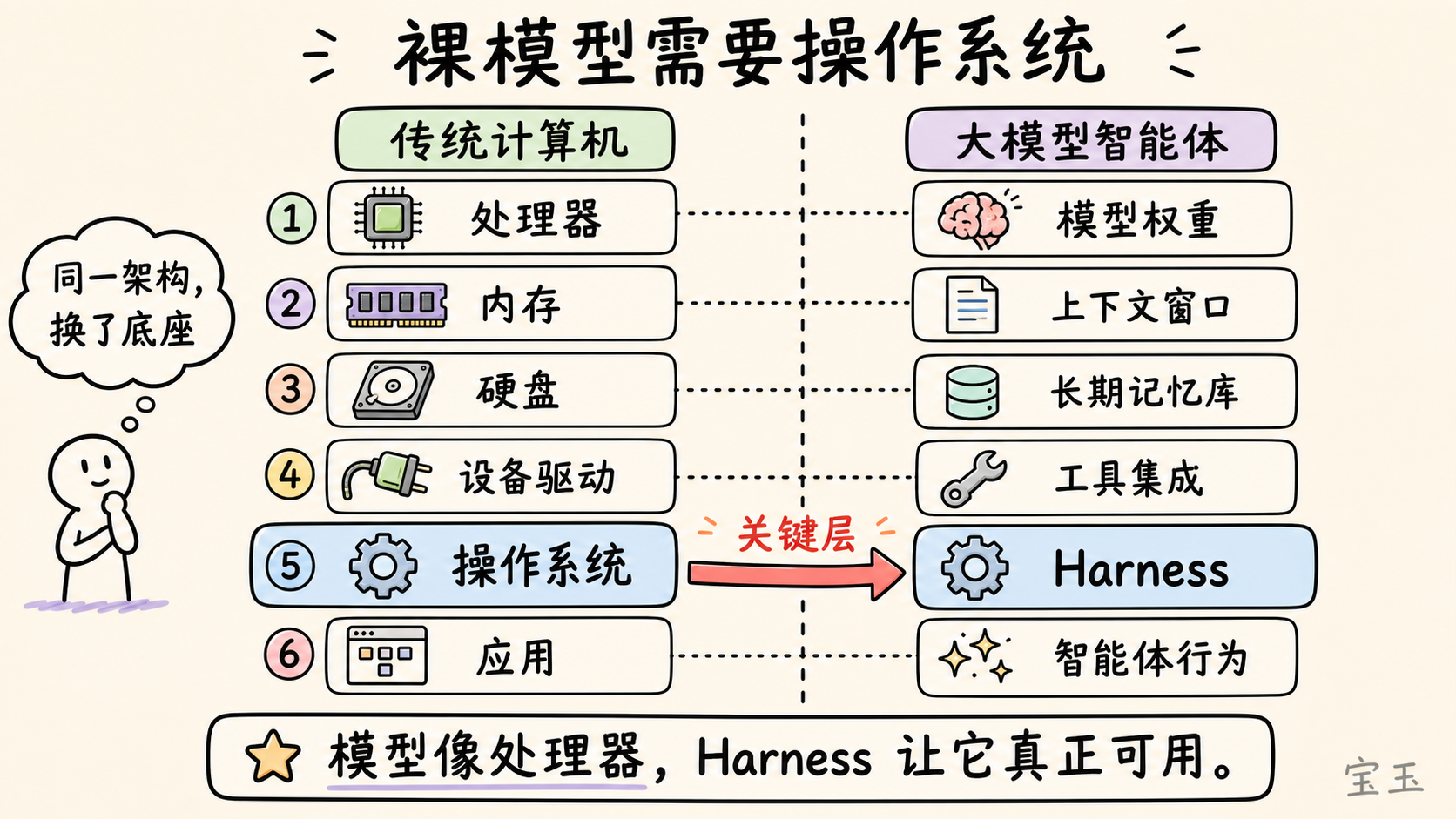
Beren Millidge は 2023 年のブログ記事で、非常に的確な比喩を行いました。ネイティブの大規模言語モデルは、メモリもハードディスクもなく、入出力デバイスさえ備えていない CPU のようなものです。この場合、コンテキストウィンドウ(Context Window)がメモリ(高速だが容量に限界がある)として機能し、外部データベースがハードディスク(大容量だが速度が遅い)の役割を果たします。ツール統合はデバイスドライバに相当します。そしてHarnessこそが、そのオペレーティングシステムです。Millidge が記した通り、「私たちはフォン・ノイマンアーキテクチャ(Von Neumann architecture)を再発明した」と言えます。なぜなら、これはあらゆる計算システムにとって最も自然な抽象化の形だからです。
工学的アプローチの三層構造
モデルを取り巻く工学的アプローチは、3 つの同心円状の層に分類できます:
- プロンプトエンジニアリング(Prompt engineering):モデルが受け取る指示を綿密に設計すること。
- コンテキストエンジニアリング(Context engineering):モデルがどの時点でどのような内容を見られるかを管理すること。
- Harness エンジニアリング(Harness engineering):上記の両者を包含し、さらに全体のアプリケーションアーキテクチャをカバーします。これにはツールのオーケストレーション、状態の永続化、エラー回復、検証ループ、安全な実行、そしてライフサイクル管理が含まれます。
Harness は単なるプロンプトを包むラッパー(AI Wrapper)ではありません。それはエージェントが自律的に行動できる完全なシステムです。
本番環境向け Harness の 12 の主要コンポーネント
Anthropic、OpenAI、LangChain、そして広範な実務家の実践経験を総合すると、本番環境で運用可能な Agent Harness は 12 の異なるコンポーネントから構成されます。一つずつ分解して解説しましょう。
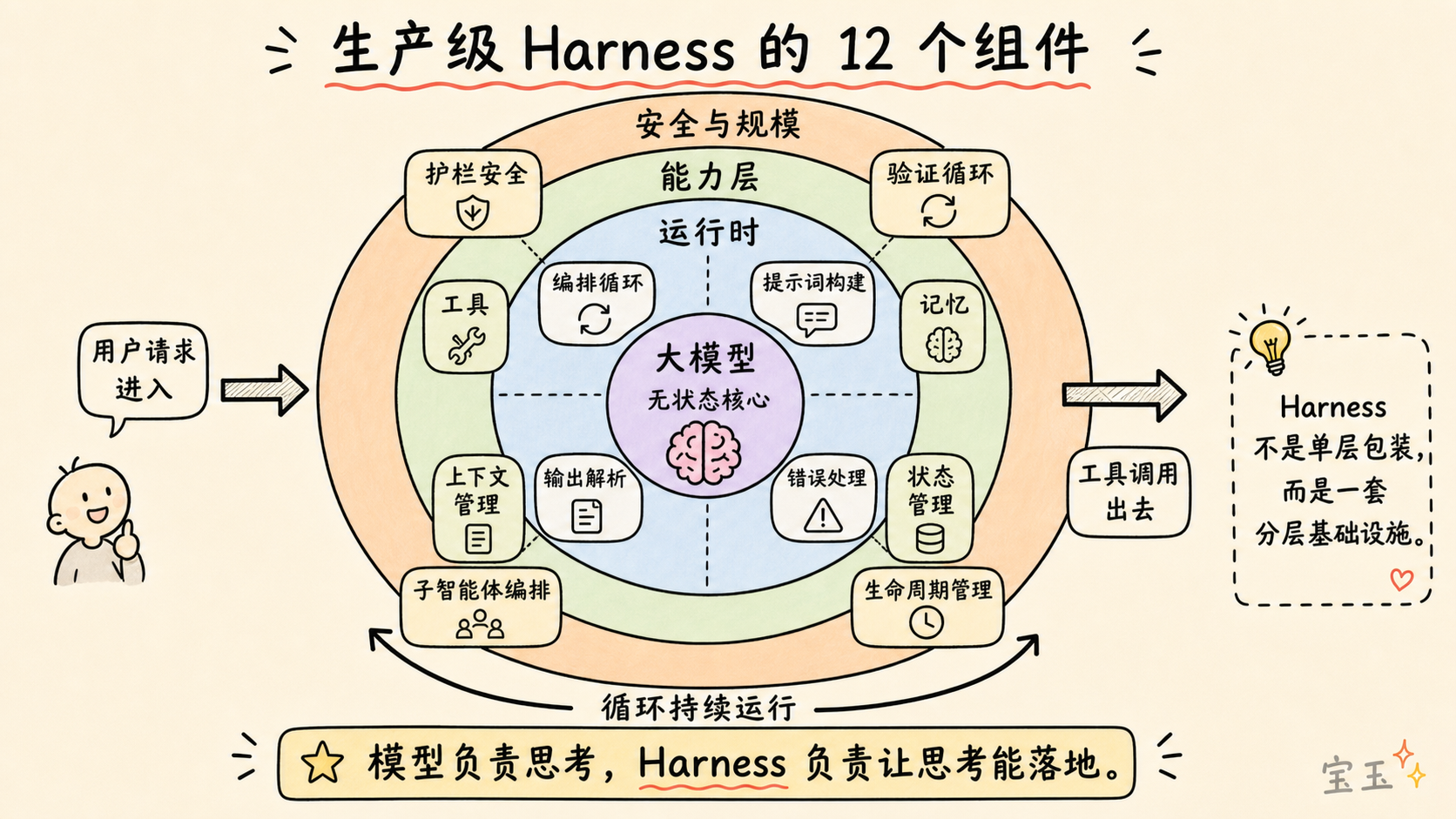
1. オーケストレーションループ(The Orchestration Loop)
これはシステムの「心臓部」です。ここでは「思考 - 行動 - 観察」(Thought-Action-Observation、略して TAO)と呼ばれる循環、あるいは ReAct ループが実装されています。このループは継続的に稼働し、「プロンプトの統合 → 大規模言語モデルへの呼び出し → 出力の解析 → ツール呼び出しの実行 → 結果フィードバック → 繰り返し」というプロセスをタスク完了まで繰り返します。
技術的な実装面から見ると、これは通常単なる while ループに過ぎません。しかし複雑なのはループそのものではなく、ループ内で処理される多様な状態とロジックにあります。Anthropic は彼らのランタイムを「愚かなループ(笨循环)」と呼び、すべての知性はモデルの中に存在し、Harness は単にラウンドの切り替えを管理するだけだと説明しています。
2. ツール(Tools)
ツールはエージェントの「両手」です。これらは特定の構造化パターン(名称、説明、パラメータ型)として定義され、モデルのコンテキストに注入されます。これにより、利用可能なツールをモデルが認識できるようになります。ツール層では、ツールの登録、フォーマット検証、パラメータ抽出、サンドボックス(Sandbox)環境内での実行、結果のキャプチャが行われ、最終的にモデルが読み取れる「観察結果」として整形されます。
Claude Code では 6 つのカテゴリのツールが提供されています:ファイル操作、検索、実行、ウェブアクセス、コード分析、およびサブエージェントの作成です。一方、OpenAI の Agents SDK は、関数ツール(@function_tool で定義)、マネージドツール(ウェブ検索、コードエディタ、ファイル検索など)、そして MCP (Model Context Protocol、オープンなツール接続標準) サーバーツールをサポートしています。
3. メモリ(Memory)
記憶は異なる時間スケールで機能します。短期記憶は単一のセッション内の会話履歴です。長期記憶は複数のセッションにわたって永続的に存在し、Anthropic はプロジェクトファイルと自動生成された memory.md ファイルを使用し、LangGraph は名前空間ごとに整理された JSON ストアを使用し、OpenAI は SQLite または Redis を駆使したセッションストレージをサポートしています。
Claude Code は 3 層の記憶アーキテクチャを実装しています:軽量なインデックス(1 件あたり約 150 文字で常時ロード)、オンデマンドで呼び出される詳細なトピックファイル、そして検索を通じてのみアクセス可能な生会話記録です。核心的な設計原則は以下の通りです:エージェントは自身の記憶を「プロンプト」とみなし、行動を実行する前に実際の状態に基づいて検証する必要があります。
4. コンテキスト管理 (Context Management)
これは多くのエージェントが暗黙的に失敗する箇所です。核心となる問題はコンテキストの劣化です:重要な情報がウィンドウの中間に位置している場合、モデルのパフォーマンスは 30% 以上低下します(これがスタンフォード大学が発見した「真ん中で迷う」現象です)。百万トークン規模の(Token:モデルがテキストを処理する最小単位で、単語や漢字の一部に相当) ウィンドウをサポートしていても、コンテキストが増加するにつれて指示への従順性は低下します。
本番環境での対応策には以下が含まれます:
- 圧縮 (Compaction):制限に近づいた際に会話履歴を要約する(Claude Code はアーキテクチャの決定事項と未修正のバグは保持しつつ、冗長なツール出力は破棄します)。
- 観測マスク (Observation masking):古いツール出力を非表示にするが、ツールの呼び出し記録は保持する。
- 即時検索 (Just-in-time retrieval):軽量な識別子のみを保持し、データを動的にロードする(Claude Code はファイル全体を読み込むのではなく、grep や head コマンドの使用を好みます)。
- サブエージェントへの委譲:各サブエージェントに深層探索を行わせ、その結果は 1000 から 2000 トークンの要約としてのみ返す。
Anthropic のコンテキストエンジニアリングガイドラインでは、目標は「目標達成確率を最大化する、最も信号の強い最小限のトークン集合を見つけること」とされています。
5. プロンプト構築 (Prompt Construction)
これはモデルが各ステップで具体的に何を見ることができるかを決定します。階層的な構造を持ちます:システムプロンプト、ツール定義、記憶ファイル、会話履歴、そして現在のユーザーメッセージです。
OpenAI の Codex は厳格な優先順位スタックを使用しています:サーバー制御のシステムメッセージ(最高優先度)、ツール定義、開発者指令、ユーザー指令、最後に会話履歴です。
6. 出力解析 (Output Parsing)
現代の Harness はネイティブツール呼び出しに依存しており、モデルは構造化された tool_calls オブジェクトを返すため、自由テキストを手動で解析する必要はありません。Harness は以下を確認します:ツール呼び出しがあるか?ある場合は実行してループを継続し、ない場合は現在の出力が最終回答となります。
構造化出力については、OpenAI と LangChain の両方が Pydantic モデル (Python でデータ検証とフォーマットを行うライブラリ) を通じてスキーマ制約をサポートしています。
7. ステート管理 (State Management)
LangGraph は状態をグラフノード間を流れる型付き辞書としてシミュレートします。システムは重要なステップで「チェックポイント(保存)」を行い、中断しても復元可能にし、さらには「タイムトラベル」のようなデバッグも可能です。OpenAI では 4 つの戦略を提供しています:メモリへの適用、SDK セッション、サーバーサイド API、または軽量なレスポンス ID チェーンです。Claude Code は異なるアプローチを採用しており、Git コミットを保存ポイントとして、進行状況ファイルを構造化された下書き用紙として利用します。
8. エラー処理 (Error Handling)
なぜこれが重要なのか?10 のステップからなるプロセスであっても、各ステップの成功率が 99% に達していたとしても、最終的な全工程の成功率は約 90.4% に過ぎません。エラーは雪だるま式に膨らんでいきます。
LangGraph はエラーを 4 つのカテゴリに分類します:一時的なエラー(遅延付きのリトライ)、モデルが回復可能なエラー(エラーをツールメッセージとして返し、モデル自身に調整させる)、ユーザーが修復可能なエラー(一時停止して人間の介入を待つ)、そして予期せぬエラー(デバッグ用に報告)です。
9. ガールレールと安全性 (Guardrails and Safety)
OpenAI の SDK は 3 つの階層を実装しています:入力ガールレール(最初の Agent が実行される際にチェック)、出力ガールレール(最終結果をチェック)、そしてツールガールレール(ツールの呼び出しごとにチェック)です。一度「トリップワイヤー」メカニズムが作動すると、Agent は即座に停止します。
Anthropic はアーキテクチャ上で「権限執行」と「モデル推論」を分離しています。モデルは「何をしたいか」を決定しますが、Harness は「何を許可するか」を決定します。
10. 検証ループ (Verification Loops)
これは「おもちゃのデモ」と「本番環境用の Agent」を分ける決定的な要素です。Anthropic は 3 つの方法を推奨しています:ルールベースのフィードバック(テスト、コードチェック)、ビジュアルフィードバック(Playwright を使用して UI のスクリーンショットを取得)、そして大規模言語モデルを審判として (LLM-as-judge)(別のサブ Agent が出力を評価)です。
Claude Code の創設者である Boris Cherny は、モデル自身が自分の作業を検証できるようにすることで、産出物の品質が 2 倍から 3 倍に向上すると指摘しています。
11. サブ Agent オーケストレーション (Subagent Orchestration)
Claude Code は 3 つのモードをサポートしています:フォーク (Fork)(親コンテキストを複製)、チームメイト (Teammate)(ファイルメールを通じて通信する独立したウィンドウ)、そして ワークツリー (Worktree)(独立した Git ブランチ)です。OpenAI では、Agent をツールとして使用して特定のサブタスクを専門家が処理するか、権限移譲によって専門家がその後の制御権を引き継ぐことをサポートしています。
循環動作:ステップバイステップのシミュレーション
コンポーネントを理解したので、これらが 1 つのループの中でどのように連携して動作するかを見てみましょう。
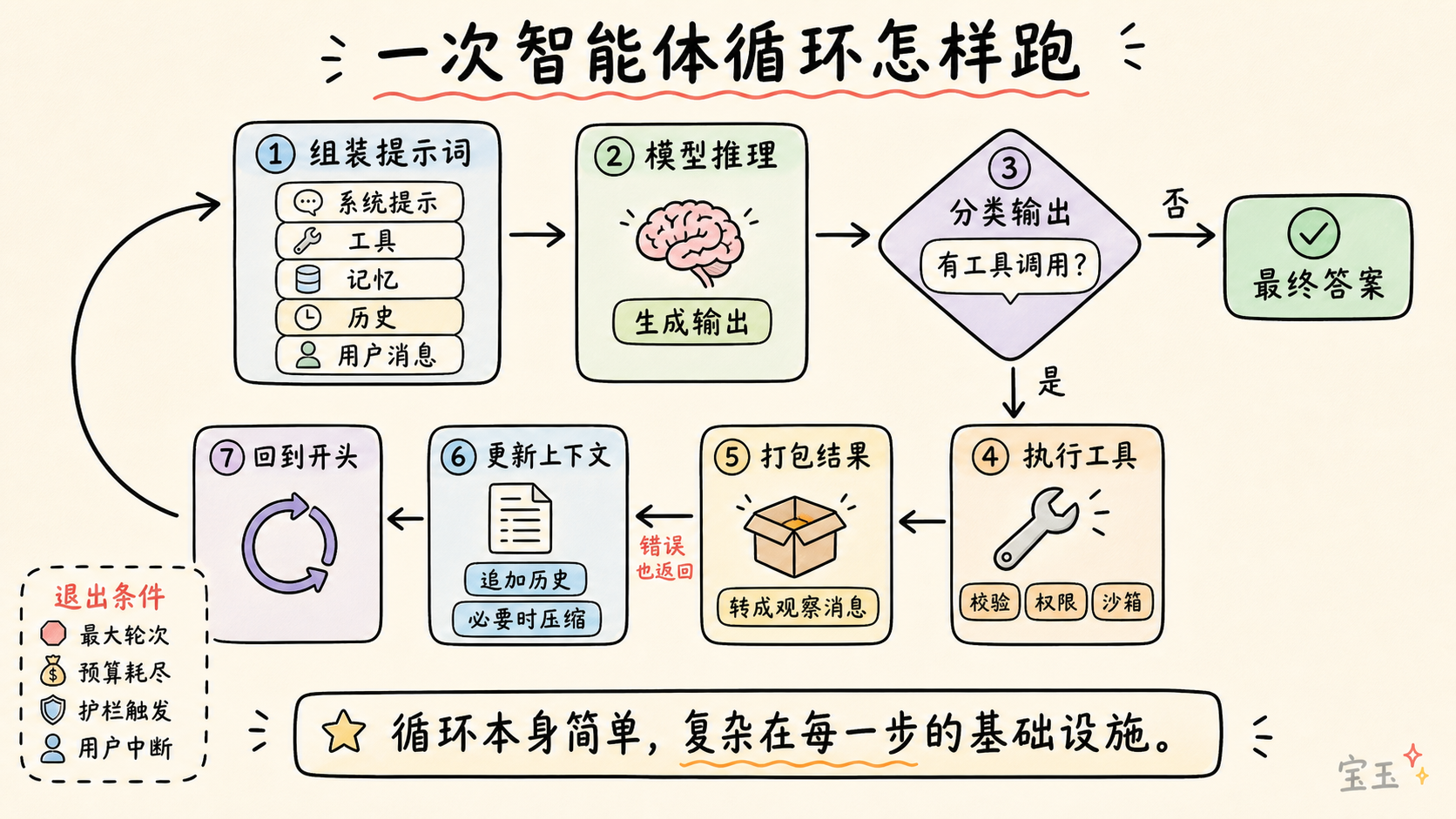
- 第 1 ステップ(プロンプトの組み立て):Harness が完全な入力情報を構築します。
- 第 2 ステップ(モデル推論):組み立てられた内容をモデル API に送信し、モデルがトークンを生成します。これはテキストであるか、またはツール呼び出しのリクエストである可能性があります。
- 第 3 ステップ(出力分類):ツール呼び出しがない場合、ループは終了します;ある場合は実行フェーズへ進みます。
- 第 4 ステップ(ツール実行):Harness がパラメータを検証し、権限を確認し、サンドボックス内で実行して結果をキャプチャします。
- 第 5 ステップ(結果のパッケージ化):結果をモデルが読み取れる形式のメッセージに変換し、モデルの自己修復のためにエラーもキャプチャします。
- 第 6 ステップ(コンテキスト更新):結果を履歴に追加し、必要に応じて圧縮トリガーを行います。
- 第 7 ステップ(ループ):退出条件が満たされるまで、第 1 ステップへ戻ります。
現実のフレームワークの実装方法
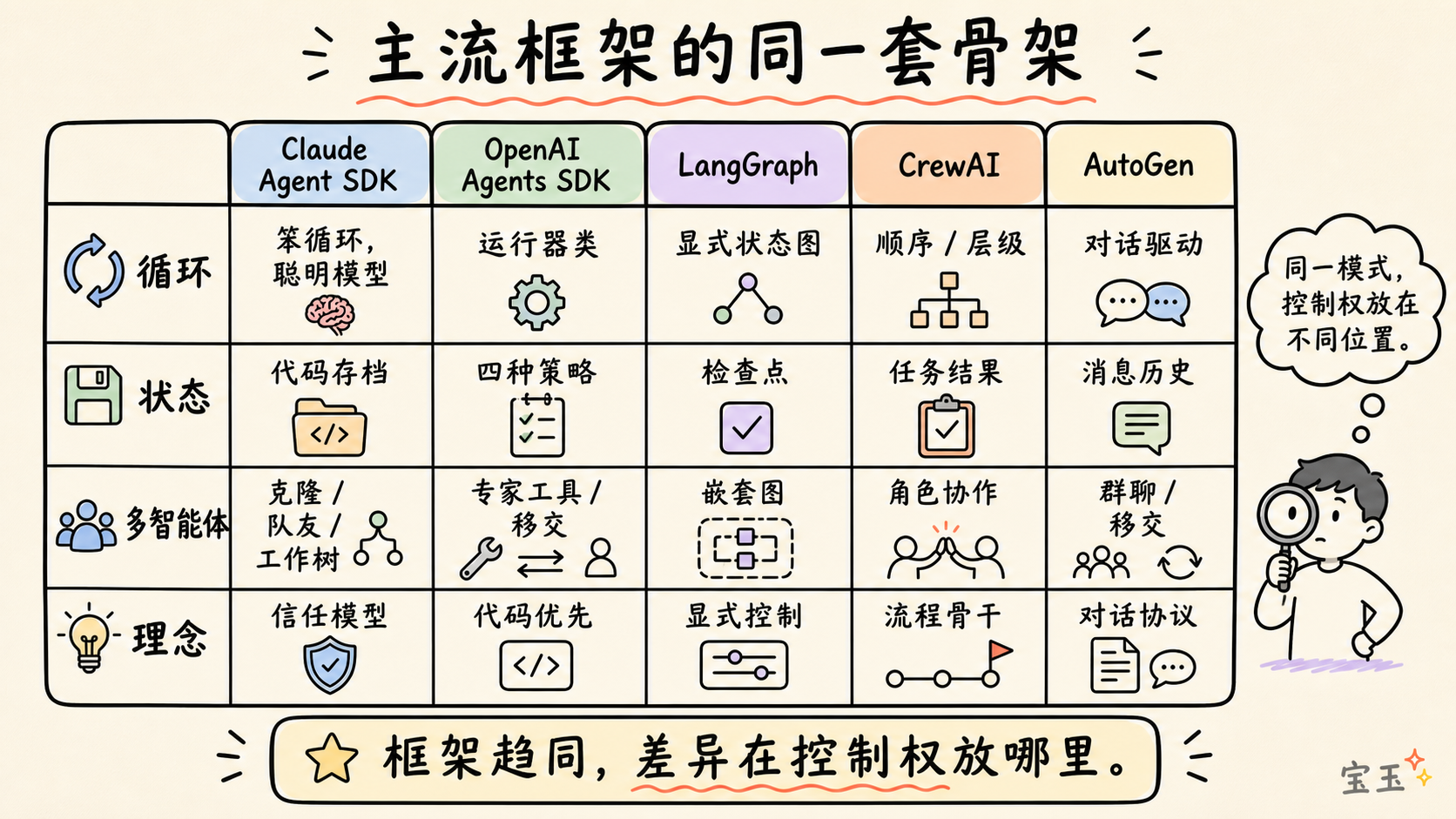
- Anthropic (Claude Agent SDK):シンプルな
query()関数を通じて Harness を公開し、実行時は「愚かなループ」として動作します。知性はすべてモデル内にあります。
- OpenAI (Agents SDK):採用「コード優先」戦略で、ワークフローのロジックは複雑なグラフィカル言語ではなく、Python で直接記述します。
- LangGraph:Harness を明示的な状態図としてモデル化し、プロセスに対する細やかな制御を強調しています。
- CrewAI:役割ベースのマルチエージェント協働を実現し、「プロセス層」が決定論的なバックボーンロジックを管理します。
- AutoGen:マイクロソフトが開発しており、順序実行、グループチャット、引継ぎ、動的タスク管理など、多种のオーケストレーションモードをサポートしています。
「足場」の比喩 (The Scaffolding Metaphor)
「足場」という比喩は単なる飾りではなく、極めて正確な表現です。建築現場の足場は一時的なインフラストラクチャであり、作業員が本来届かない高所に到達できるようにするものです。足場自体が家を建てるわけではありませんが、これなしでは作業員が高層に上ることができません。
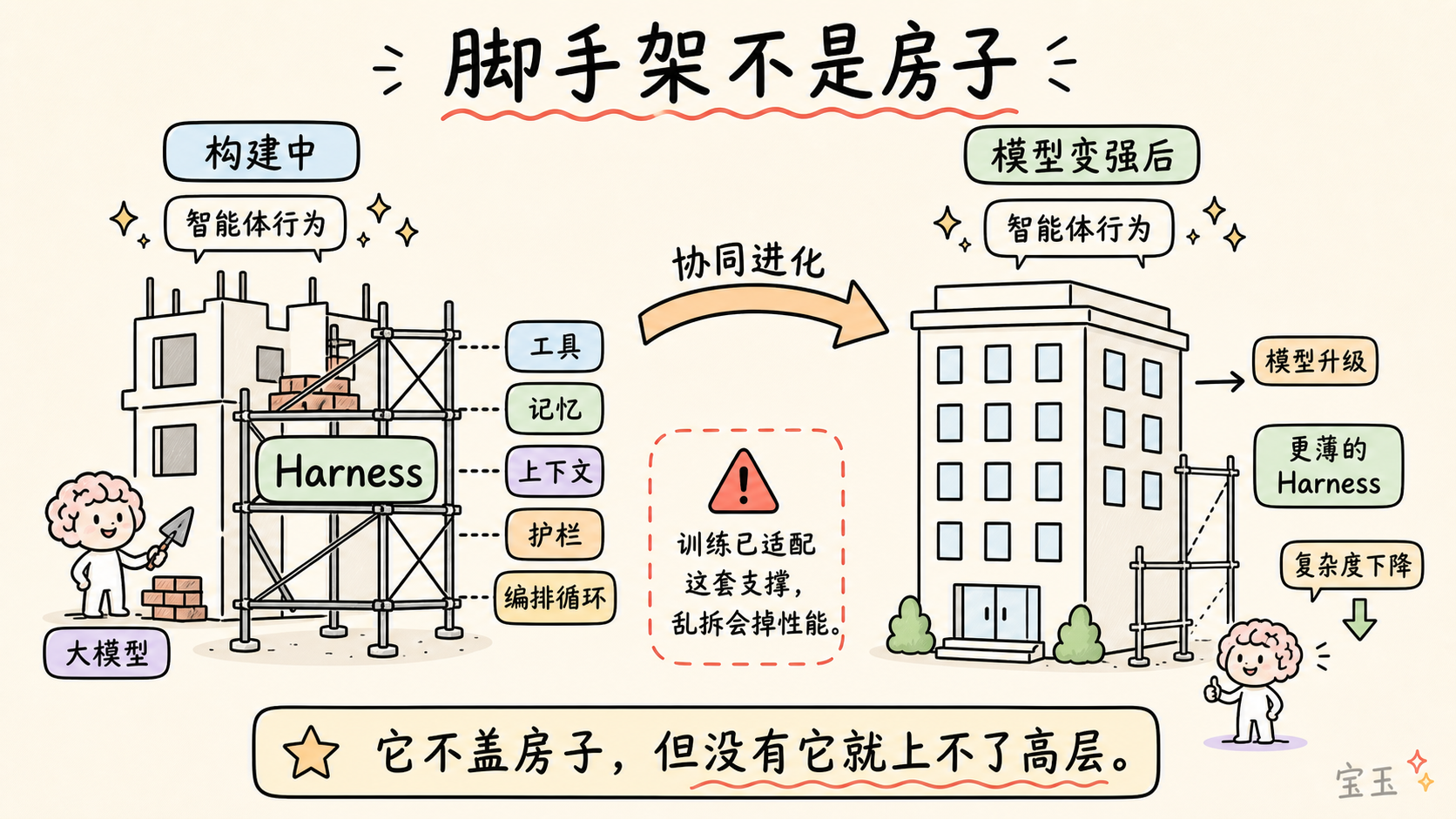
重要な洞察は、家が完成した後には足場を撤去する必要があるという点です。モデルの能力が向上するにつれ、Harness の複雑さは徐々に低下していくべきです。
これが共進化原則 (Co-evolution Principle) です。現在のモデルも訓練時に Harness の存在を前提としています。Harness の設計が優れていれば、モデルがアップグレードされた際にも複雑さを増す必要はなく、性能は自動的に向上します。
Harness を定義する 7 つの重要な意思決定
各 Harness のアーキテクトは、以下の 7 つの選択に直面します:
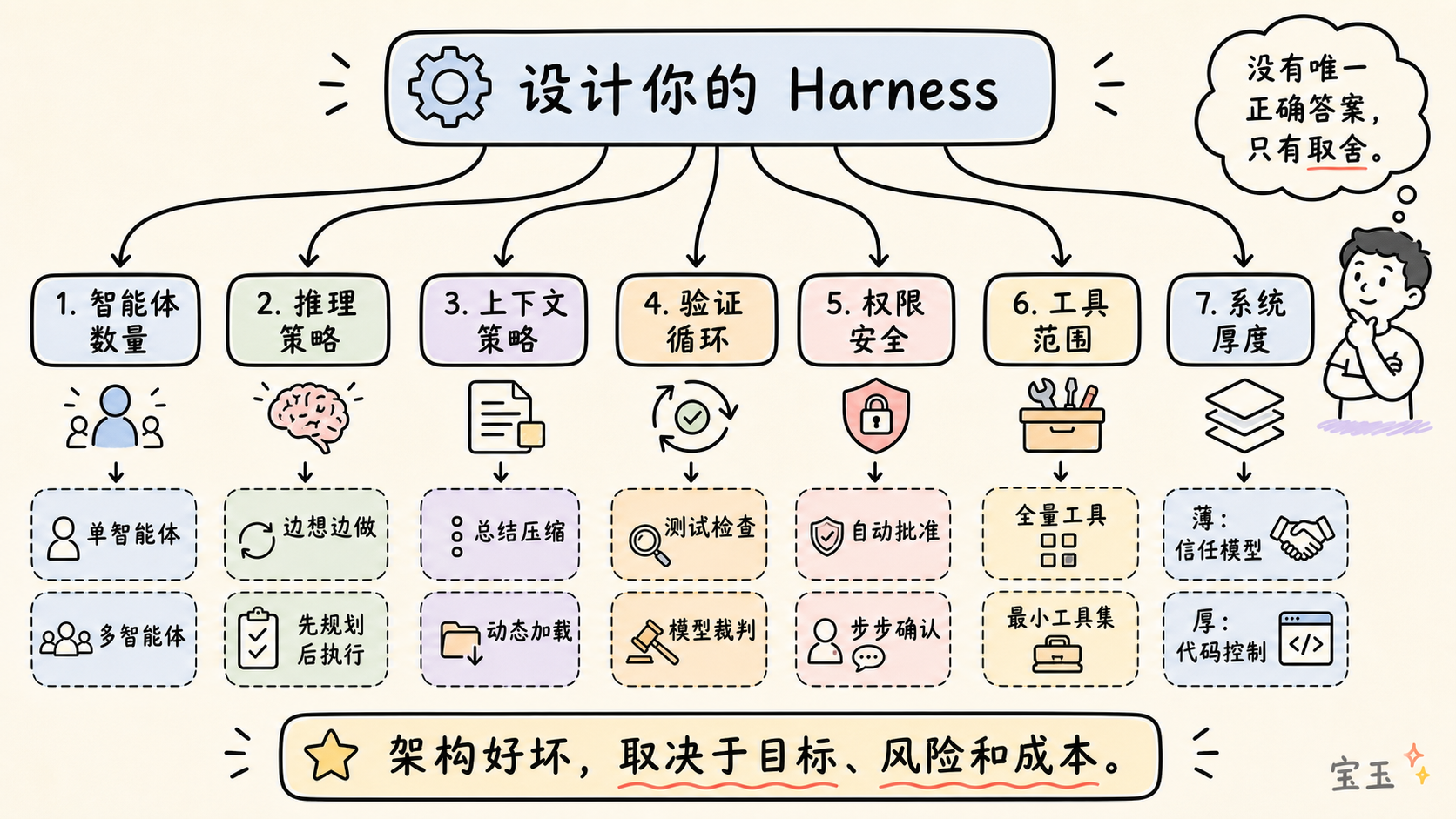
- 単一エージェント vs. マルチエージェント:公式の推奨は、まず単一エージェントの可能性を十分に探求することです。マルチエージェントでは追加のオーバーヘッドと情報の損失が生じます。
- ReAct (Reasoning + Acting) vs. プランニング先行実行:ReAct は柔軟ですがコストが高く、「計画を立ててから実行する」アプローチの方が高速です。
- コンテキスト管理戦略:会話の要約を行うか、それとも動的にロードするか?
- 検証ループ設計:堅牢なコードテストを使用するか、別の LLM (Large Language Model) で採点させるか?
- 権限とセキュリティアーキテクチャ:速度を優先して自動承認するべきか、安全性を優先して段階的な確認を行うべきか?
- ツール範囲管理:ツールは多いほど良いわけではありません。現在のステップで必要な最小限のツールセットを公開するのが最も効果的です。
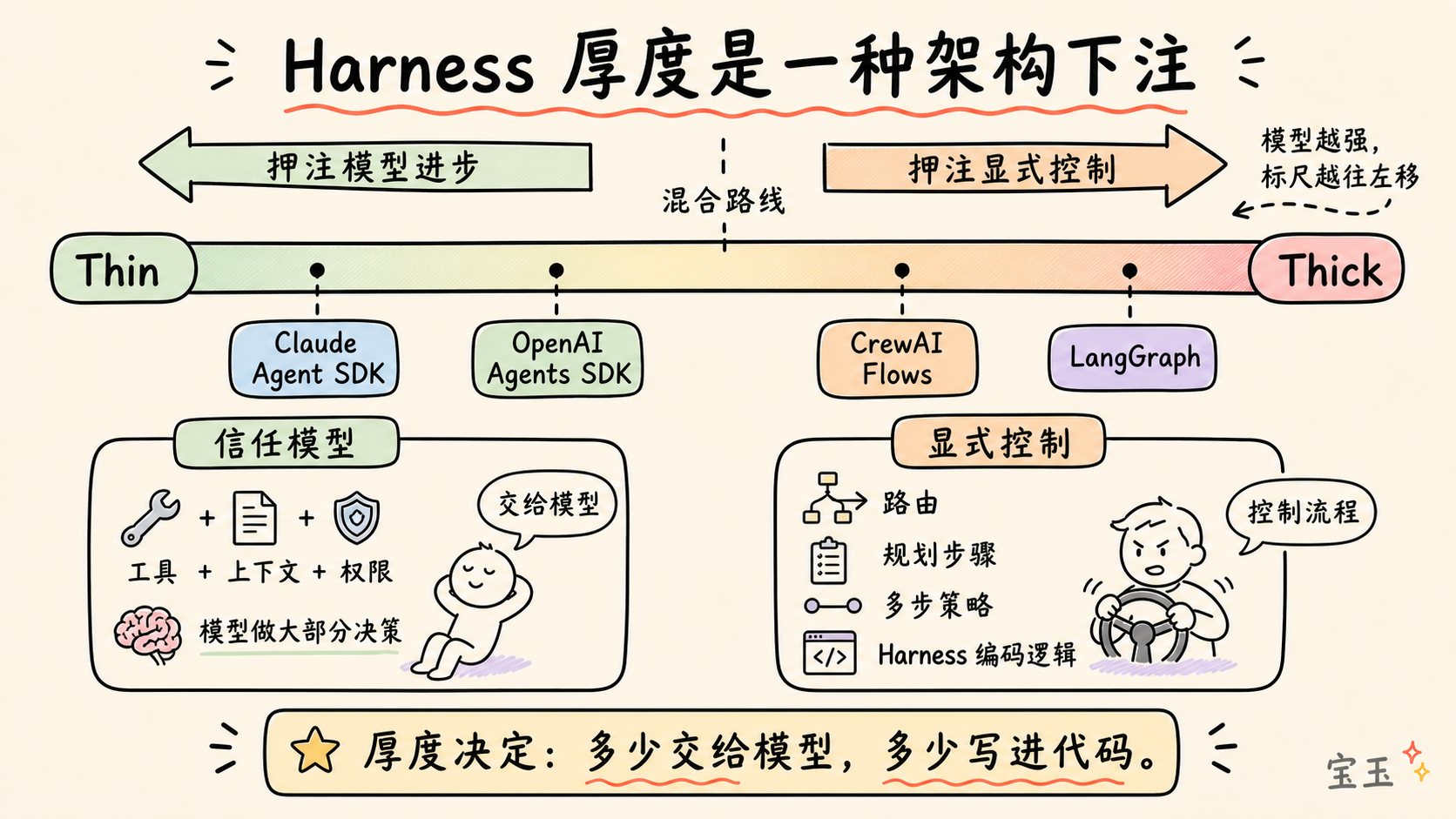
- Harness の厚さ (Harness Thickness):どの程度のロジックをシステムにハードコーディングし、どの程度のロジックをモデルに任せるか?
Harness は製品である
全く同じモデルを使用している 2 つのエージェントでも、性能は天と地ほど異なる可能性があります。その理由は Harness の設計にあります。TerminalBench の証拠は非常に明確です。Harness を単に変更するだけで、ランキングが 20 位以上変動します。
Harness はすでに解決された問題でも、汎用的な商品層でもありません。それはハードコアなエンジニアリング能力の体現です:コンテキストを希少資源としてどのように管理するか?エラーの蓄積を防ぐために検証ループをどう設計するか?ハルシネーション (幻覚) を生じさせない記憶システムをどう構築するか?
モデルがますます強力になるにつれ、Harness は薄くなっていきますが、決して消滅することはありません。最も強力なモデルであっても、ウィンドウの管理、コードの実行、状態の保存、作業の検証を行うためのシステムが必要です。
次回、あなたのエージェントのパフォーマンスが振るわないときは、モデルを愚痴るだけでなく、ぜひHarnessを見直してください。
もしこれらのコンテンツがお好きなら:
私をフォローしてください → https://x.com/@akshay_pachaar ✔️
私は毎日、AI(人工知能)、機械学習、そしてVibe Coding(感覚プログラミング)のベストプラクティスに関するチュートリアルと洞察を共有しています。
原文を表示
深度拆解:AI Agent Harness 的构造
作者:Akshay
原文:The Anatomy of an Agent Harness
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能 Agent(Agent)的底层机制。
你可能已经开发过聊天机器人,甚至可能用一些工具搭建了一个 ReAct 循环 (ReAct:Reason + Act,一种让模型在行动前先进行推理的模式)。跑 Demo 的时候看着挺好,但一旦投入生产环境,系统就会开始掉链子:模型会忘记三步前做了什么,工具调用悄悄报错,上下文窗口(Context Window)里塞满了毫无意义的垃圾信息。
问题其实并不在模型本身,而在模型外围的基础设施。
LangChain 证明了这一点:他们仅仅通过改变包裹大语言模型的底层架构——模型没变,参数没变——就让系统在 TerminalBench 2.0 (一个衡量 AI Agent 处理命令行任务能力的权威基准测试) 上的排名从 30 名开外飙升到了第 5 名。另一项研究则通过让大语言模型自己去优化这套架构,实现了 76.4% 的通过率,甚至超过了人类精心设计的系统。
现在,这套基础设施有了一个正式的名字:AI Agent Harness。
什么是 Agent Harness?
虽然这个术语在 2026 年初才正式确立,但其核心理念早已存在。Harness是包裹在大语言模型之外的完整软件架构:它包括编排循环、工具、记忆、上下文管理、状态持久化、错误处理和护栏(Guardrails)。Anthropic 在其 Claude Code 文档中直截了当地指出:SDK(软件开发工具包)就是“驱动 Claude Code 的 Agent Agent Harness”。OpenAI 的 Codex 团队也使用了同样的说法,明确将“Agent”和“Harness”等同,指代那些让大语言模型真正发挥作用的非模型架构。
我非常喜欢 LangChain 的 Vivek Trivedy 给出的定义公式:“如果你不是模型本身,那你就是 Harness。”
这里有一个经常让人搞混的区别:“AI Agent”(Agent)是用户感知到的行为体现,它是一个有目标、会用工具、能自我纠错的实体;而“Harness”则是产生这种行为的背后机器。当有人说“我开发了一个 Agent”时,他真正的意思是“我开发了一套 Harness,并把它接入了模型”。
Beren Millidge 在其 2023 年的博文中做了一个精准的类比:原生大语言模型就像一个没有内存、没有硬盘、也没有输入输出设备的 CPU。此时,上下文窗口充当了内存(快但容量有限),外部数据库扮演了硬盘(大但速度慢),工具集成则是设备驱动程序。而Harness,就是那个操作系统。正如 Millidge 所写:“我们重新发明了冯·诺依曼架构(Von Neumann architecture)”,因为这是任何计算系统最自然的抽象方式。
工程化的三个层次
围绕模型,工程化可以分为三个同心圆层次:
- 提示词工程 (Prompt engineering):精心设计模型接收到的指令。
- 上下文工程 (Context engineering):管理模型在什么时间点能看到什么内容。
- Harness 工程 (Harness engineering):涵盖了上述两者,再加上整个应用架构:包括工具编排、状态持久化、错误恢复、验证循环、安全执行以及生命周期管理。
Harness 不仅仅是一个包裹提示词的套壳(AI Wrapper),它是让 Agent 能够自主行动的完整系统。
生产级 Harness 的 12 个核心组件
综合 Anthropic、OpenAI、LangChain 以及广大从业者的实践经验,一个生产级的 Agent Harness 由 12 个不同的组件构成。让我们逐一拆解。
1. 编排循环 (The Orchestration Loop)
这是系统的“心脏”。它实现了“思考 - 行动 - 观察”(Thought-Action-Observation,简称 TAO)循环,也被称为 ReAct 循环。这个循环不停运转:整合提示词 -> 调用大语言模型 -> 解析输出 -> 执行工具调用 -> 反馈结果 -> 重复,直到任务完成。
从技术实现上看,它通常只是一个 while 循环。但复杂的地方不在于循环本身,而在于循环所要处理的各种状态和逻辑。Anthropic 将他们的运行时描述为一个“笨循环”,所有的智慧都存在于模型之中,Harness 只负责管理回合的切换。
2. 工具 (Tools)
工具是 Agent 的“双手”。它们被定义为某种结构化模式(名称、描述、参数类型),并注入到模型的上下文中,让模型知道哪些工具可用。工具层负责注册、格式校验、参数提取、在沙箱(Sandbox)环境执行、结果捕获,并最终将结果格式化为模型可读的“观察结果”。
Claude Code 提供了六大类工具:文件操作、搜索、执行、网页访问、代码分析和子 Agent 创建。OpenAI 的 Agents SDK 则支持函数工具(通过 @function_tool 定义)、托管工具(如网页搜索、代码解释器、文件搜索)以及 MCP (Model Context Protocol,一种开放的工具接入标准) 服务器工具。
3. 记忆 (Memory)
记忆在不同的时间尺度上运作。短期记忆是单次会话中的对话历史。长期记忆则跨越多个会话持久存在:Anthropic 使用项目文件和自动生成的 memory.md 文件;LangGraph 使用按命名空间组织的 JSON 存储;OpenAI 则支持由 SQLite 或 Redis 驱动的会话存储。
Claude Code 实现了三层记忆架构:一个轻量级索引(每条约 150 字符,始终加载)、按需调用的详细主题文件,以及仅通过搜索访问的原始对话记录。一个核心设计原则是:Agent 将自己的记忆视为一种“提示”,在行动前必须根据实际状态进行验证。
4. 上下文管理 (Context Management)
这是许多 Agent 容易暗中翻车的地方。核心问题在于上下文腐烂:当关键信息处于窗口中间位置时,模型表现会下降 30% 以上(这就是斯坦福大学发现的“迷失在中间”现象)。即便是支持百万级 Token (Token:模型处理文本的最小单位,大致相当于单词或汉字的部分) 的窗口,随着上下文的增长,指令遵循能力也会退化。
生产环境的应对策略包括:
- 压缩 (Compaction):在接近限制时总结对话历史(Claude Code 会保留架构决策和未修复的 Bug,同时丢弃冗余的工具输出)。
- 观察掩码 (Observation masking):隐藏旧的工具输出,但保留工具调用的记录。
- 即时检索 (Just-in-time retrieval):只保留轻量级标识符,动态加载数据(Claude Code 倾向于使用 grep 或 head 命令,而不是加载整个文件)。
- 子 Agent 委托:让每个子 Agent 进行深度探索,但仅返回 1000 到 2000 Token 的浓缩摘要。
Anthropic 的上下文工程指南指出,目标是:找到能最大化达成目标概率的、信号最强的最小 Token 集合。
5. 提示词构建 (Prompt Construction)
这决定了模型在每一步具体能看到什么。它是层级化的:系统提示词、工具定义、记忆文件、对话历史,以及当前的用户消息。
OpenAI 的 Codex 使用严格的优先级栈:服务器控制的系统消息(最高优先级)、工具定义、开发者指令、用户指令,最后才是对话历史。
6. 输出解析 (Output Parsing)
现代 Harness 依赖于原生工具调用,即模型返回结构化的 tool_calls 对象,而不是需要费力解析的自由文本。Harness 会检查:是否有工具调用?如果有,执行并继续循环;如果没有,那当前的输出就是最终答案。
对于结构化输出,OpenAI 和 LangChain 都支持通过 Pydantic 模型 (Python 中用于数据校验和格式化的库) 进行模式约束。
7. 状态管理 (State Management)
LangGraph 将状态模拟为在图形节点中流动的类型化字典。系统会在关键步骤进行“存档”(Checkpointing),这样即使中断也能恢复,甚至可以进行“时间旅行”式的调试。OpenAI 则提供了四种策略:应用内存、SDK 会话、服务器端 API 或轻量级的响应 ID 链。Claude Code 采用了不同的思路:将 Git 提交作为存档点,将进度文件作为结构化的草稿纸。
8. 错误处理 (Error Handling)
为什么这很重要?一个包含 10 个步骤的过程,即使每一步的成功率高达 99%,最终全流程的成功率也只有约 90.4%。错误是会滚雪球的。
LangGraph 将错误分为四类:临时性的(带延迟的重试)、模型可恢复的(将错误作为工具消息返回,让模型自己调整)、用户可修复的(暂停等待人类干预)以及意外错误(上报调试)。
9. 护栏与安全 (Guardrails and Safety)
OpenAI 的 SDK 实现了三个层级:输入护栏(在第一个 Agent 运行时检查)、输出护栏(检查最终结果)以及工具护栏(每次调用工具前检查)。一旦触发“绊网”(Tripwire)机制,Agent 将立即停止。
Anthropic 在架构上将“权限执行”与“模型推理”分离。模型决定想做什么,但 Harness 决定允许做什么。
10. 验证循环 (Verification Loops)
这是区分“玩具演示”和“生产级 Agent”的关键。Anthropic 推荐三种方法:基于规则的反馈(测试、代码检查)、视觉反馈(通过 Playwright 截取 UI 截图)以及以大语言模型为裁判 (LLM-as-judge)(由另一个子 Agent 评估输出)。
Claude Code 的创造者 Boris Cherny 指出,让模型能够验证自己的工作,能让产出质量提升 2 到 3 倍。
11. 子 Agent 编排 (Subagent Orchestration)
Claude Code 支持三种模式:克隆 (Fork)(复制父级上下文)、队友 (Teammate)(通过文件邮箱通信的独立窗口)和 工作树 (Worktree)(独立的 Git 分支)。OpenAI 则支持将 Agent 作为工具(专家处理特定子任务)或移交(专家接管后续控制权)。
循环运作:步进式演练
既然了解了组件,让我们看看它们在一次循环中是如何协同工作的。
- 第一步(提示词组装):Harness 构建完整的输入信息。
- 第二步(模型推理):组装好的内容发送给模型 API,模型生成 Token:可能是文本,也可能是工具调用请求。
- 第三步(输出分类):如果没有工具调用,循环结束;如果有,进入执行阶段。
- 第四步(工具执行):Harness 校验参数、检查权限,在沙箱中运行并捕获结果。
- 第五步(结果打包):将结果格式化为模型可读的消息,捕获错误以便模型自愈。
- 第六步(上下文更新):将结果追加到历史记录,必要时触发压缩。
- 第七步(循环):返回第一步,直到满足退出条件。
现实中的框架是如何实现的
- Anthropic (Claude Agent SDK):通过一个简单的 query() 函数暴露 Harness,运行时是一个“笨循环”,智慧全在模型里。
- OpenAI (Agents SDK):采用“代码优先”策略,工作流逻辑直接用 Python 表达,而不是复杂的图形语言。
- LangGraph:将 Harness 建模为显式的状态图,强调对流程的精细控制。
- CrewAI:实现了基于角色的多 Agent 协作,由“流程层”管理确定性的骨干逻辑。
- AutoGen:由微软开发,支持多种编排模式,如顺序执行、群聊、移交和动态任务管理。
“脚手架”的比喻 (The Scaffolding Metaphor)
“脚手架”这个比喻并非装饰,而是极其精准的。建筑脚手架是临时性的基础设施,让工人们能触及原本够不到的高度。脚手架本身不盖房子,但没有它,工人就上不去高层。
关键洞察在于:房子盖好后,脚手架是要拆除的。 随着模型能力的提升,Harness 的复杂程度应该逐渐降低。
这就是协同进化原则:现在的模型在训练时,就已经考虑了 Harness 的存在。如果你的 Harness 设计得好,当模型升级时,你不需要增加复杂度,性能就会自动提升。
定义 Harness 的 7 个关键决策
每个 Harness 的架构师都面临这七个选择:
- 单 Agent vs. 多 Agent:官方建议:先充分挖掘单 Agent 的潜力。多 Agent 会带来额外的开销和信息损耗。
- ReAct vs. 先规划后执行:ReAct 灵活但成本高;“先规划后执行”速度更快。
- 上下文管理策略:是总结对话,还是动态加载?
- 验证循环设计:是用硬性的代码测试,还是用另一个 LLM 来打分?
- 权限与安全架构:是追求速度自动批准,还是追求安全步步确认?
- 工具范围管理:工具不是越多越好。暴露当前步骤所需的最小工具集往往效果最佳。
- Harness 的厚度:多少逻辑写死在系统里,多少逻辑留给模型发挥?
Harness 即产品
两个使用完全相同模型的 Agent,性能可能天差地别,原因就在于 Harness 的设计。TerminalBench 的证据已经非常明确:仅仅改变 Harness,就能让排名变动 20 多位。
Harness 不是一个已经解决的问题,也不是一个通用的商品层。它是硬核工程能力的体现:如何将上下文视为稀缺资源进行管理?如何设计验证循环以防止错误累积?如何构建不产生幻觉的记忆系统?
随着模型越来越强,Harness 会变薄,但它永远不会消失。即便最强大的模型,也需要系统来管理窗口、执行代码、保存状态并验证工作。
下次当你的 Agent 表现不佳时,别光顾着抱怨模型,去检查一下你的Harness吧。
如果你喜欢这些内容:
关注我 → https://x.com/@akshay_pachaar ✔️
每天我都会分享关于 AI、机器学习和凭感觉编程 (Vibe Coding) 最佳实践的教程与见解。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み