エージェント開発ライフサイクル:AI エージェントの構築、テスト、デプロイ、監視 | LangChain
LangChain は、AI エージェントを単発のデモから持続可能な実践へ移行させるため、「構築・テスト・展開・監視」のライフサイクルモデルを提唱し、組織的な開発基盤の重要性を説いている。
キーポイント
エージェント開発ライフサイクルの定義
実験から反復可能なシステムへ移行するために、Build(構築)、Test(テスト)、Deploy(展開)、Monitor(監視)という順序立てた 4 つのフェーズを確立する必要がある。
段階的なアプローチとインフラの重要性
単一エージェントでは軽量なプロセスで済むが、複数エージェントを扱う場合はコスト管理、ツールアクセス制御、コンテキスト共有、および人間の関与判断といったガバナンス基盤が不可欠となる。
開発ツールの多様性とエコシステム
コードファースト(LangChain, LangGraph など)からノーコード/ローコードまで幅広いツールが存在し、チームは抽象化レベルや環境設定に応じて最適なフレームワークを選択する。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発の成熟度を高めるための標準的なプラクティスを提示しており、組織が実験段階から本番運用へ移行する際の指針となる。特に「テストを事前に行う」ことや「監視フィードバックループ」の重要性を強調することで、実務におけるリスク管理と品質向上に直接的な影響を与える。
編集コメント
単なるツールの紹介に留まらず、エージェント開発を「運用可能なシステム」として捉える視点は、現在急成長中の AI エージェント分野において極めて重要です。特にテストと監視の重要性を強調している点が、実務家の課題解決に役立つ内容となっています。
誰もがエージェントをリリースしたがる。
最も優れた組織は、それを反復的かつ安全に、体系的に行う方法を確立している。彼らは早期にリリースし、実際の利用から学び、迅速に改善を重ねる。エージェントを単発のデモや孤立したプロジェクトとして扱うことはない。
むしろ、彼らはエージェント開発ライフサイクルを構築しており、これにより実験を反復可能なシステムへと転換することで、リリース・学習・継続的な改善における勢いを生み出している。
このライフサイクルには4つの部分がある:
ビルド → テスト → デプロイ → モニタリング
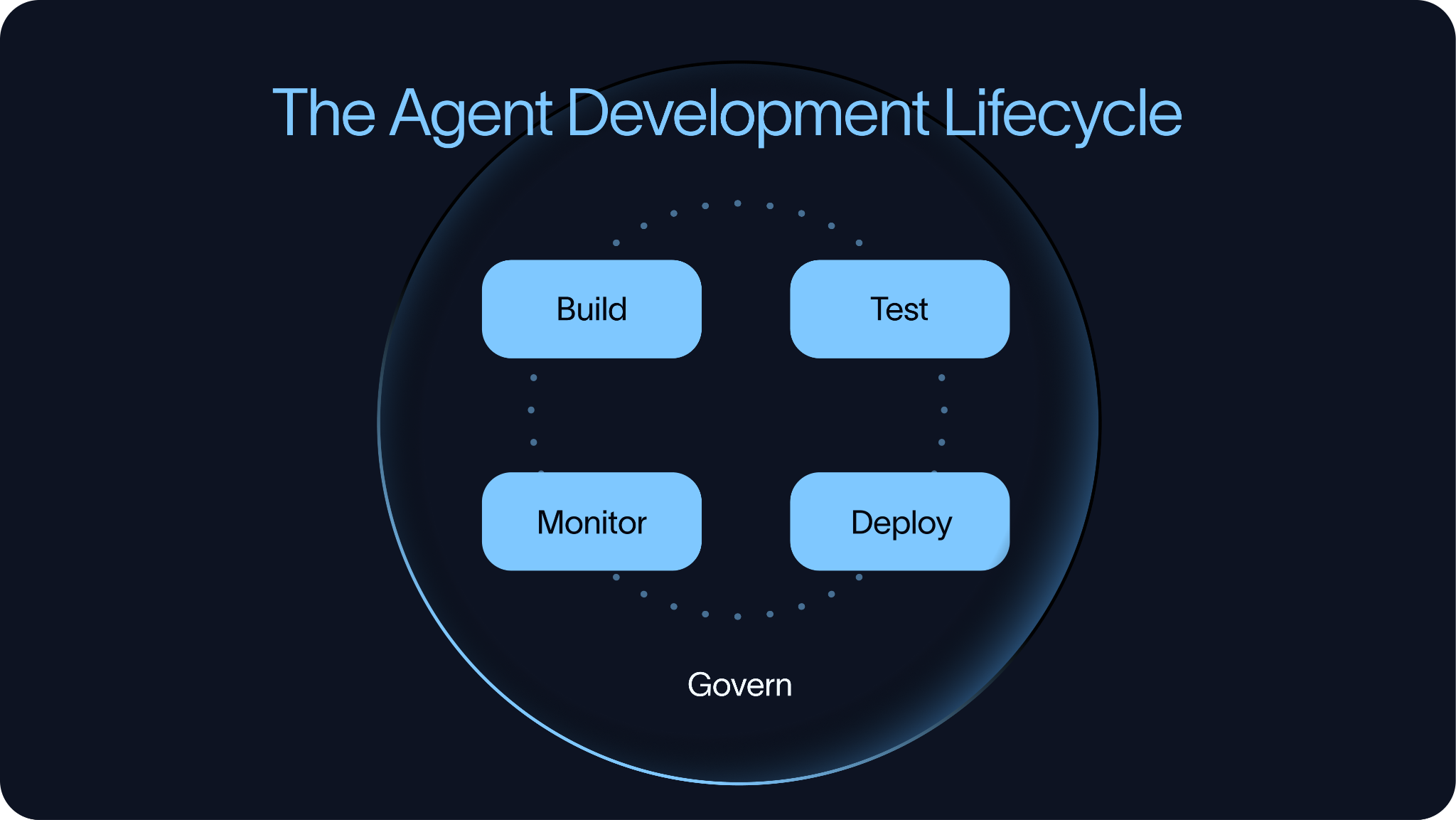
この順序は意図的なものである。テストは、エージェントが本番環境に到達した後ではなく、その前に開始されるべきだ。チームはデプロイ前にエージェントをテストし、制御された方法でデプロイし、本番環境での振る舞いを監視し、そこから得た知見を次のビルドと評価サイクルへフィードバックする必要がある。
単一のエージェントであれば、このプロセスは軽量に保つことができる。しかし、多数のエージェントにわたると、それはインフラストラクチャおよびガバナンスの課題となる。チームは、コスト制御、ツールアクセスの管理、ツールの呼び出しの検査、コンテキストの再利用、そして人間が関与すべき箇所の決定などを行うための共有された方法が必要になる。
一度だけエージェントを動作させることと、反復可能なプラクティスとしてエージェントを構築することの違いは、適切な開発ライフサイクルを整備しているかどうかにかかっている。
ビルド
ビルドフェーズでは、チームがどのようなエージェントシステムを作成するか、そしてどのレベルの抽象化を使用するかを決定する場所である。
ここには幅広いツールが存在します。コードファースト型のものもあれば、ノーコードやローコードの選択肢もあります。抽象化に焦点を当てるものもあれば、プロンプト、ツール、スキル、状態を備えたエージェントが動作する環境を提供することに注力するものもあります。

コードファーストの側では、チームはオープンソースのフレームワークやハッチ(harness)を利用することがよくあります。LangChain エコシステムにおいては、LangChain、LangGraph、そして Deep Agents がこれに該当します。LangChain 以外では、CrewAI や Claude Agents SDK が例として挙げられます。
これらのツールは、スタックの異なるレイヤーで動作します。
エージェントフレームワーク(Agent frameworks)は主に抽象化に焦点を当てています。開発者がモデル呼び出し、ツール、プロンプト、検索、構造化された出力、そしてエージェントループを組み立てるのを支援します。LangChain や CrewAI がこのカテゴリーの例です。
ランタイム(Agent runtimes)は実行に焦点を当てています。状態、制御フロー、耐久性、および人間の介入を必要とするエージェントをサポートします。LangChain エコシステムにおける最も明確な例が LangGraph です。これにより、分岐、ループ、一時停止、再開、そして時間経過に伴う状態の永続化が可能となる、エージェンティックなシステムを構築する方法を提供します。
エージェント・ハーネスは実行に焦点を当てています。長時間実行されるタスクに必要な周囲の構造、つまりプロンプト、スキル、MCP サーバー、フック、ミドルウェア、そして場合によってはファイルシステムを提供します。Deep Agents や Claude Agent SDK はこのパターンの例です。
これらの区別が重要なのは、「エージェントを構築する」という言葉が異なる意味を持つ可能性があるからです。
単純なアプリケーションの場合、ツール呼び出しループの定義のみで済むかもしれません。より洗練されたエージェントの場合は、プロンプトの作成、スキルの定義、MCP サーバーへの接続、ミドルウェアの設定、そして時間が経つとともに取得または更新できるコンテキストのセットアップなどが必要になる場合があります。
*ノーコードでの構築*
ビルドフェーズには、ノーコードおよびローコードの側面もあります。LangSmith Fleet、Claude Cowork、n8n などのツールにより、より多くの人々がエージェント開発に参加できるようになります。これは、必要なワークフローを理解している人物が、必ずしもコードを書く人物とは限らないため、重要です。
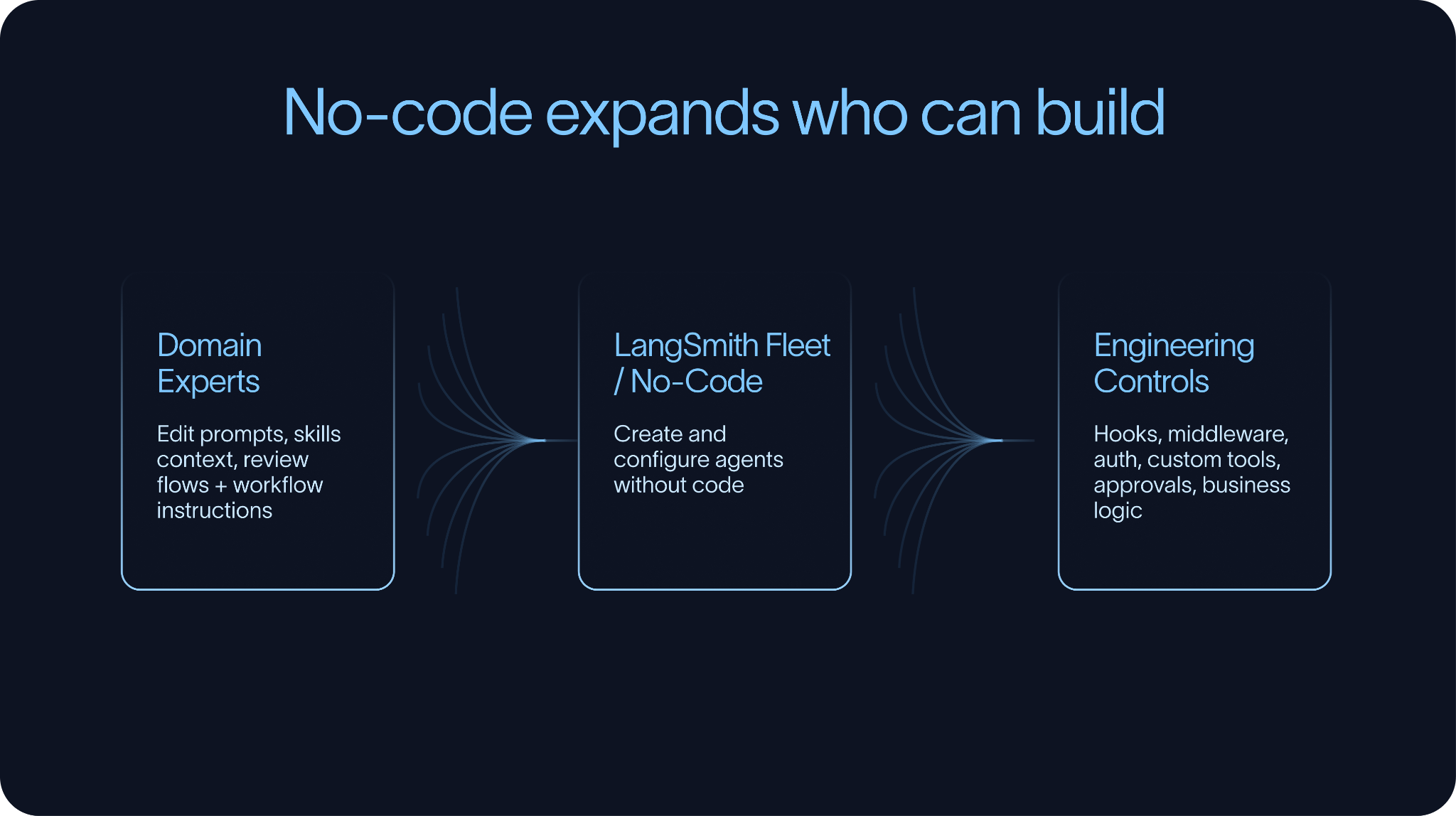
同時に、ノーコードツールがエンジニアリングによる制御の必要性を排除するわけではありません。システムが複雑化するにつれ、チームは通常、コードで動作を拡張または上書きする方法を必要とします。ここで特に重要なのがフックやミドルウェアです。これらは、ツール呼び出し、コンテキスト処理、承認、認証、ビジネスルールなどの周囲にカスタムロジックを追加できるようにし、すべてのエージェントをゼロから再構築する必要をなくします。
最高のビルド環境とは、単純なことをシンプルにし、複雑なことを可能にするものです。ドメインエキスパートがプロンプト、スキル、コンテキストを編集できるようにしながらも、信頼性、テスト可能性、ガバナンスが必要な部分についてはエンジニアが制御できる仕組みを提供します。
テスト
エージェントをデプロイする前に、チームはそれが実際に準備ができているかどうかを判断する方法が必要です。
それは、誰もエージェントを使用する前に完璧な評価スイート(eval suite)を構築することを意味しません。実際には、そのようなことはめったに現実的ではありません。重要なのは、明らかな失敗を検出し、バージョンを比較し、盲目的に変更をリリースしないために、十分な数の評価(evals)を用意しておくことです。
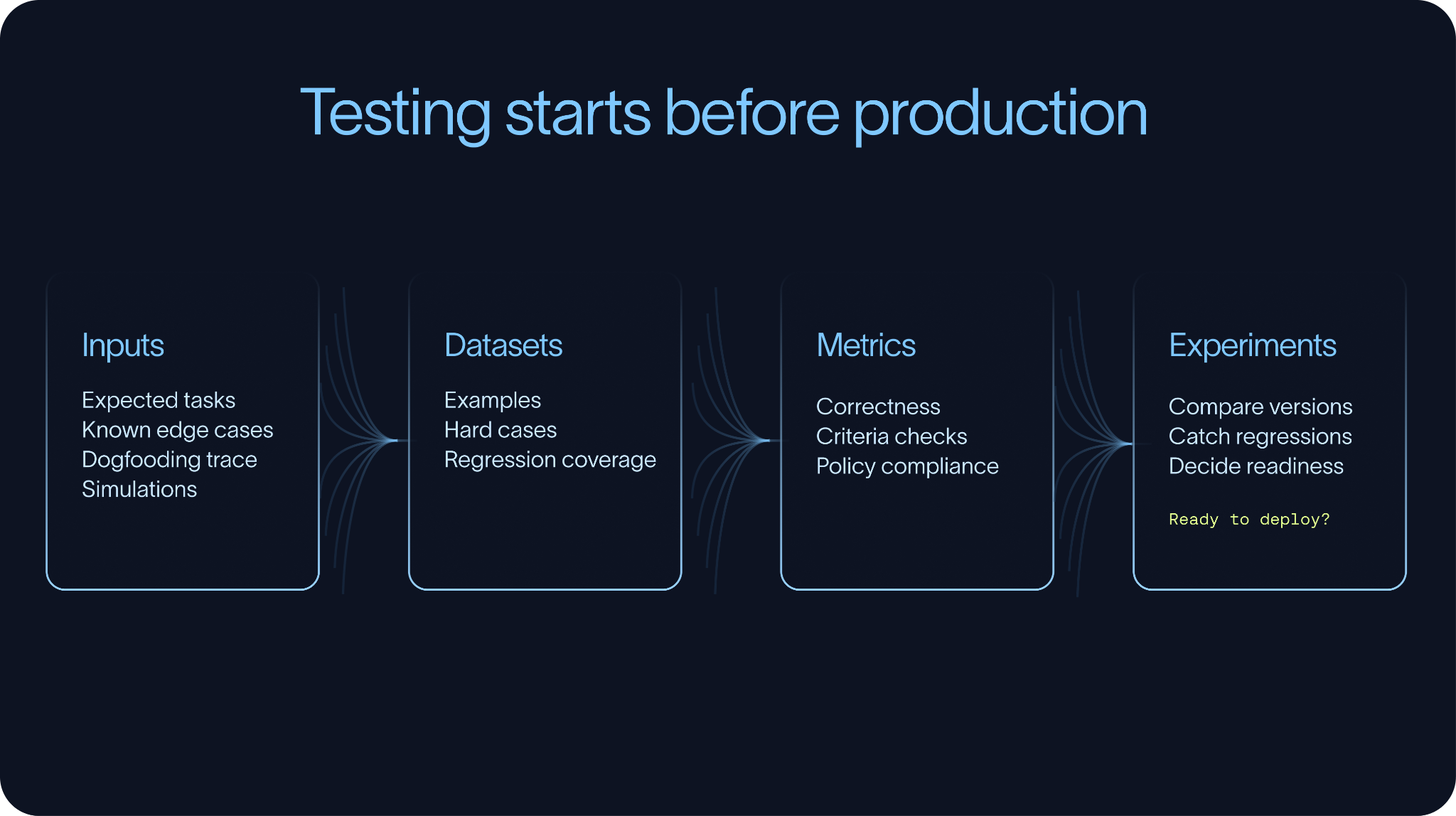
ほとんどの評価ワークフローは、代表的なタスクの小さなデータセットから始まります。例の一部は期待されるユースケースから得られ、他のものは手動テスト、ドッグフーディング(社内利用)、サポートチケット、過去のトレース、または既知のエッジケースから得られます。時間が経つと、本番環境でのトレースがこれらのデータセットを大幅に強化しますが、テストは本番環境に移行する前に行うべきです。
*データセットとメトリクス*
データセットとは、チームが学んだことを保存する方法です。これがないと、プロンプトの変更、モデルのアップグレード、ツールの更新後に同じ失敗が繰り返される傾向があります。
適切なメトリクスはタスクによって異なります。
場合によっては、明確な正解(ground truth)が存在します。エージェントは正しい値を抽出しましたか?正しいラベルを選択しましたか?正しいフィールドを更新しましたか?これらのタスクは、正確性に対して直接測定することができます。
一方で、単一の正解が存在しない場合もあります。エージェントは応答の作成、会話の要約、エスカレーションの判断、あるいは複数の有効な経路を持つタスクの完了などを必要とすることがあります。そのようなケースでは、チームは基準ベースの評価により依存します。問いかけられるのは、「応答が根拠に基づいているか」「エージェントがポリシーに従ったか」「不明確な点を明確にするよう質問したか」「不要なツール呼び出しなしに効率的にタスクを完了できたか」といった点です。
*実験*
実験は、データセットと指標を反復プロセスに結びつける役割を果たします。これにより、チームは同じ評価セットに対してプロンプト、モデル、検索戦略、ツールスキーマ、オーケストレーションパターンを比較検討できます。時間の経過とともに、これらの実験を通じてエージェントが改善されているのか、後退しているのかが明らかになります。
目標は、初日に完璧な評価スイートを作成することではありません。重要なのは、有用なものから始めて継続的に改善していくことです。最も価値のある評価データセットは、困難な事例から構築されます:まず開発段階と社内利用(dogfooding)から始まり、その後本番環境からの事例が加えられます。
*シミュレーション*
シミュレーションもテストの重要な一部です。
多くのエージェントは多ターンシステムです。単に一つの質問に答えるだけでなく、会話を交わし、情報を収集し、ツールを呼び出し、状態を更新し、曖昧さから回復します。そのようなエージェントにとって、単一ターンの評価だけでは不十分です。チームは多ターンの評価と、シミュレーションされたエンドツーエンドの相互作用が必要となります。
音声エージェントは明白な例ですが、このパターンはより広範です。一連のやり取りを通じて動作するあらゆるエージェントには、シミュレーションが必要となる可能性があります。サポートエージェントは、怒った顧客に対応し、追跡質問を行い、注文ステータスを確認し、エスカレーションが必要かどうかを判断する必要があります。コーディングエージェントは、リポジトリを検査し、変更を加え、テストを実行し、フィードバックに応答する必要があります。内部運用エージェントは、行動を起こす前に不足している情報を収集する必要があるかもしれません。
良いテストプラクティスは、チームが直感に頼らずに体系的にエージェントを改善することを支援します。期待される動作をデータセットに変換し、データセットを実験に変え、実験をシステムのより良いバージョンへと導きます。デプロイ後、モニタリングは、それらの評価を強化する実世界の例を提供します。
Deploy(デプロイ)
エージェントが構築され、評価された後は、信頼して実行できる環境が必要です。
単純なエージェントの場合、デプロイは従来のアプリケーションのデプロイと似ているかもしれません。しかし、多くのエージェントには、ステートレスサーバー以上のものが必要です。彼らは長い期間にわたって動作し、ツールを呼び出し、人間の入力を待ち、ファイルを書き込み、中断から回復し、複数の対話やタスクにわたって状態を維持します。
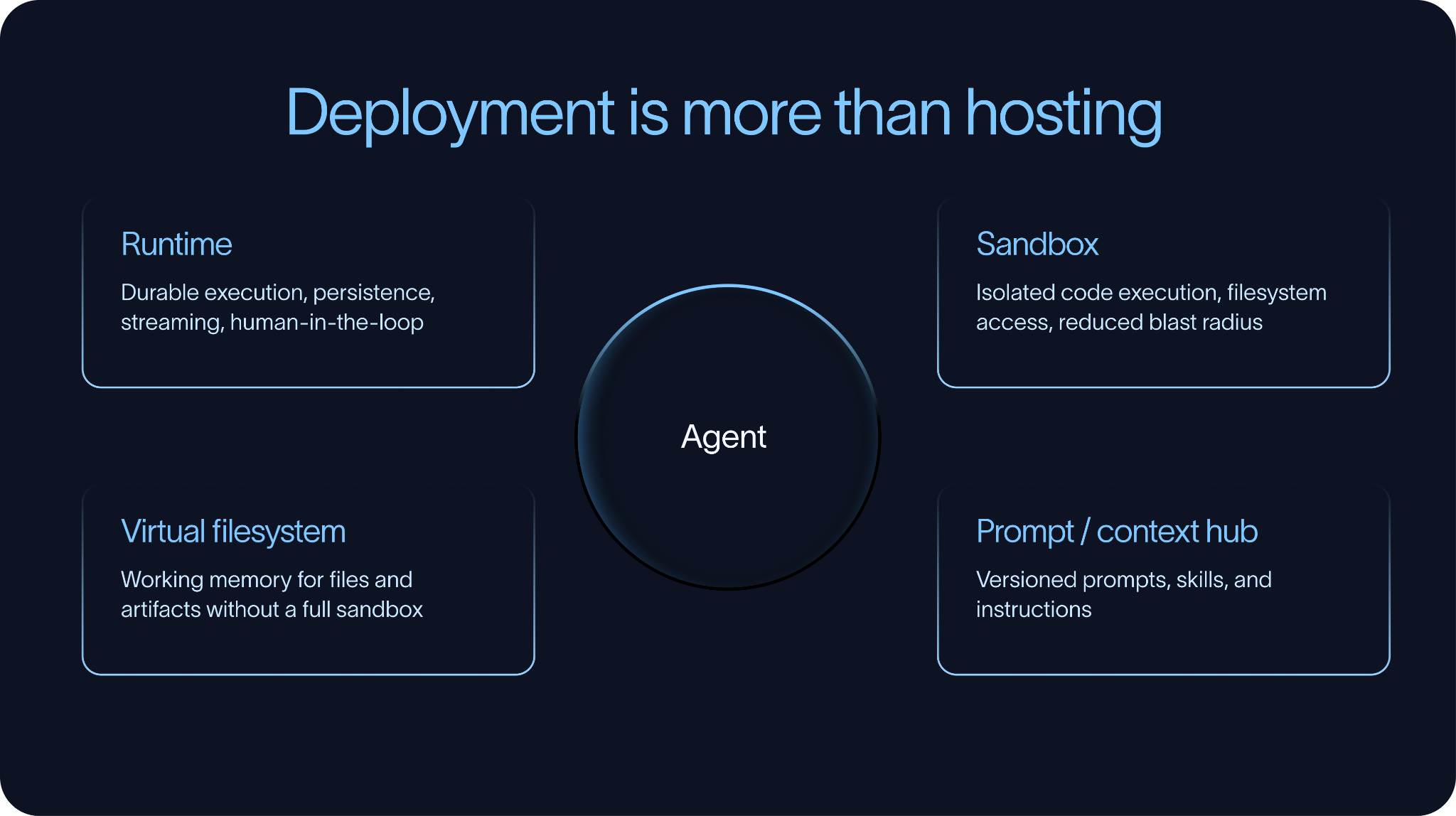
そのため、ランタイム(実行環境)が重要なのです。
本番環境のエージェントランタイムでは、通常、永続的な実行と人間を介したループパターンをサポートする必要があります。永続的な実行とは、何かが失敗した場合に作業を失うのではなく、進捗をチェックポイントして再開できることを意味します。人間を介したループとは、承認や明確化、レビューが必要な場合にエージェントが一時停止できることを意味します。
これに対する市販のソリューションが存在します。LangSmith Deployment は、Deep エージェントおよび LangGraph エージェントのデプロイと管理のためのインフラストラクチャを提供します。AWS AgentCore も、エージェント向けのマネージドランタイムの別の例です。一部のチームは、スタック内の他の場所で既に Temporal を長期間実行されるワークフローに使用している場合など、Temporal などのシステムの上に独自のランタイムを構築することもあります。
*サンドボックス*
多くのエージェントには、専用の実行環境も必要とされます。
エージェントはますますコードの記述、コードの実行、ファイルの検査、ドキュメントの変換、またはファイルシステムとの対操作を行う必要があります。そのような場合、チームはその作業がどこで行われるかを決定する必要があります。サンドボックスは一般的な解決策です。これらは、ファイルシステムへのアクセス権を持つ隔離された実行環境を提供しつつ、ミステイクや不安全な行動による影響範囲を縮小します。
例としては、LangSmith Sandboxes、Daytona、および E2B が挙げられます。
すべてのエージェントに完全なサンドボックスが必要というわけではありません。場合によっては、エージェントは単にファイルを保存および取得できる場所があれば十分です。仮想ファイルシステムで十分な場合があります。Deep Agents は、このパターンをサポートしており、エージェントがサンドボックス内で任意のコードを実行する必要なく、ファイルを作業メモリとして使用できるようにしています。その背後にあるファイルシステムは、Postgres や S3 などのシステムによってバックアップされている可能性があります。
*Context Hub*
デプロイにおいてしばしば見落とされがちなのが、プロンプトとコンテキストの管理です。
エージェントの中で最も重要な要素の一部は、従来のアプリケーションコードではありません。プロンプト、検索コンテキスト、スキル、タスク指示などは、アプリケーション自体よりも頻繁に変更が必要になる場合があります。また、エンジニアではない人々によって編集される必要もあるかもしれません。
これにより、プロンプトまたはコンテキストハブの必要性が生じます。これは、エージェントの非コード部分を保存、バージョン管理、レビュー、更新するための場所です。これにより、チームは完全なデプロイを行わずにエージェントの動作を調整でき、ドメインエキスパートが最もよく理解するコンテキストを自ら管理できるようになります。
実際的な運用において、デプロイとは単にエージェントをサーバー上に配置することだけではありません。それは、エージェントが実際の業務を行うために必要なランタイム、実行環境、およびコンテキスト管理システムを提供することを意味します。
Monitor
一度エージェントがデプロイされると、チームは本番環境における実際の動作について可視性を持つ必要があります。
ここが、エージェントの監視と従来のソフトウェアの監視を分ける点です。レイテンシ、コスト、エラーレート、稼働率といった指標は依然として重要ですが、それは全体像の一部に過ぎません。技術的に成功した回答を返しても、タスク自体には失敗する可能性があります。間違ったツールを呼び出したり、誤った文脈に依存したり、必要な承認ステップをスキップしたり、もっともらしく聞こえるが実際には間違っている回答を生成したりすることがあります。
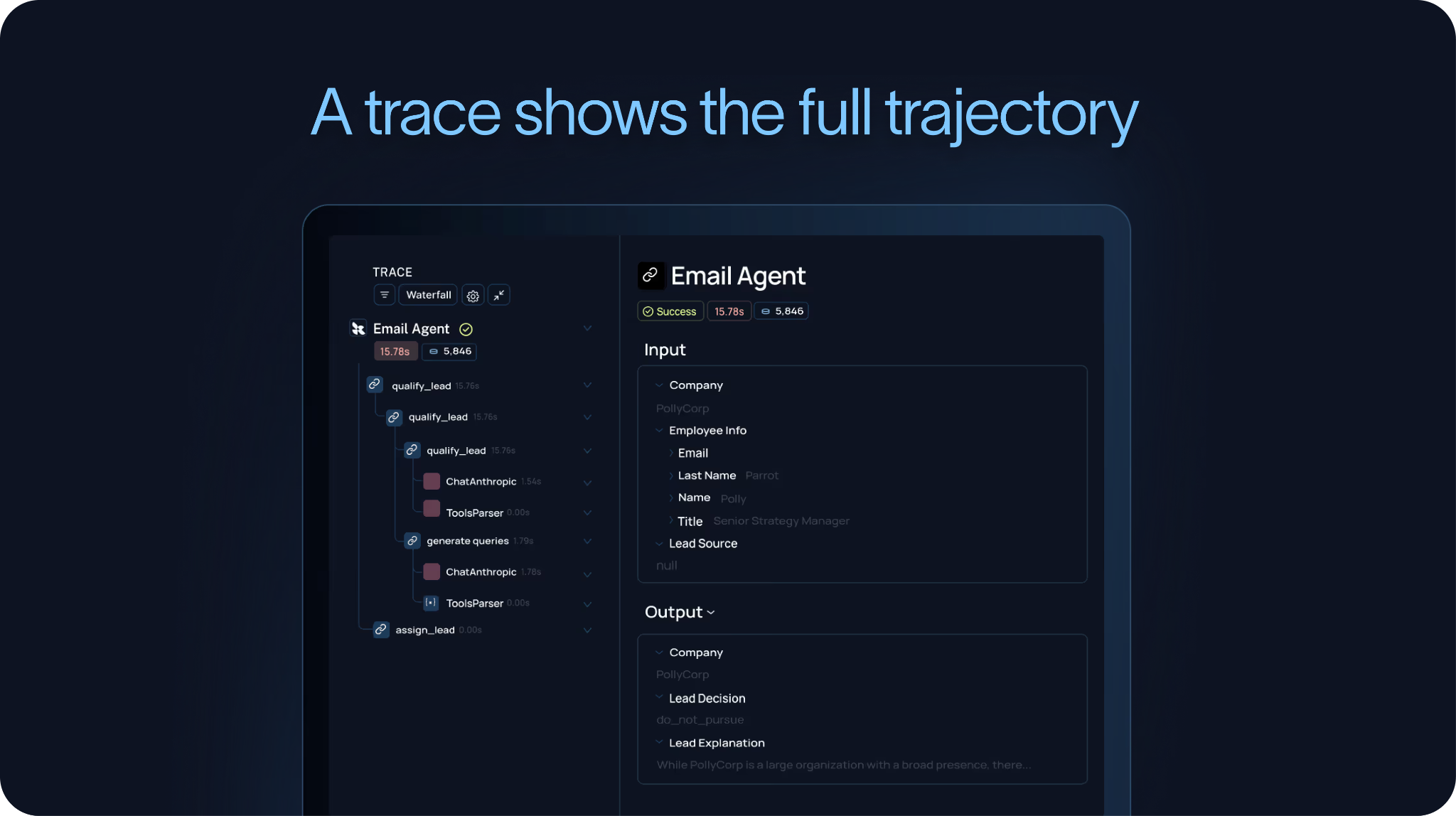
これらの失敗を理解するためには、チームはトレース(trace)が必要です。
トレースとは、エージェントが受け取った入力、実行したモデル呼び出し、使用したツール、取得した出力、そして生成された最終的な回答やアクションという、エージェントの全軌跡を記録するものです。これが、エージェントが実際に何を行ったかを理解するために必要な詳細レベルです。
そのため、私たちは「エージェントの観測可能性(agent observability)が評価を支える」と主張し、「エージェント改善ループはトレースから始まる」と述べてきたのです。もし軌跡が見えなければ、振る舞いを信頼性を持ってデバッグしたり、これらの失敗を将来の評価指標に変換したりすることはできません。
*シグナル*
監視には、これらのトレースからのシグナル(signals)の収集も含まれるべきです。
これらのシグナルの一部は、LLM-as-judge(LLM を用いた評価者)から得ることができます。例えば、評価者はエージェントがユーザーの質問に答えたか、ポリシーに従ったか、適切なトーンを使用したか、タスクを完了したかなどをスコアリングできます。他のシグナルはより単純なもので構いません。正規表現(regex)を用いて、必須フレーズが表示されたか、禁止されたツールが呼び出されたか、既知の失敗パターンが発生したかを検出できます。
これらのシグナルは品質チェックだけでなく、製品分析(product analytics)としても有用です。ユーザーがエージェントにどのようなタスクを依頼しているか、エージェントがどこでつまずいているか、ユーザーがどれほど頻繁に修正を行っているか、またユーザーがエラーを認識している箇所はどこかなどを把握できます。
*フィードバック*
フィードバックは監視の別の重要な要素です。
トレース(traces)を単に保存するだけでは不十分です。チームはこれらのトレースとともにフィードバックも保存する必要があります。そのフィードバックは、LLM 評価者、正規表現ベースのシグナル、人間によるレビュー、または API を通じて収集された直接ユーザーフィードバックなどから得られます。例えば LangSmith では、チームがユーザーフィードバックを基盤となる実行(run)に直接紐付けることで、「ユーザーが不満を抱いた」という事象と「エージェントが 3 ステップ前に誤ったツールを使用した」という事実を結びつけやすくなります。
*ダッシュボード*
最後に、チームは時系列のトレンドを可視化できるダッシュボードとアラートが必要です。
有用なエージェントダッシュボードは、使用状況、フィードバック、レイテンシ、コスト、ツール呼び出し、評価者スコア、および反復する失敗パターンなどの指標を追跡します。重要な閾値を越えた場合、例えばレイテンシの上昇、コストの増加、ツールの故障、ユーザーフィードバックの低下、またはポリシー違反の急増などが発生した際にアラートがトリガーされるべきです。
優れたモニタリングは、単にシステムが稼働しているかどうかを知るだけではありません。それは、エージェントが正しい作業を、適切な方法で実行しており、時間とともに改善されているかを理解することです。
最も強力なモニタリングシステムは、直接評価フィードバックループに組み込まれています。重要なトレースはデータセットの例となり、反復する失敗は指標となり、本番環境での動作が次の改善ラウンドの基盤となります。
反復(イテレーション)
最も優れた組織は、エージェント開発ライフサイクルを迅速かつ体系的に遂行します。
完璧なエージェントができるまで出荷を待つことはありません。代わりに、有用なものを作り、その振る舞いを理解する十分なテストを行い、制御された方法でデプロイし、本番環境でのパフォーマンスをモニタリングし、その学習結果を次のバージョンにフィードバックします。
それは無謀に出荷することを意味するわけではありません。鍵は可視性を持つことにあります。
データセット、実験、トレーシング(追跡)、フィードバック、およびダッシュボードを備えたチームは、実際の使用状況から直接学ぶことができます。広範囲に展開する前に変更をテストし、本番環境で何が壊れたかを特定し、失敗を評価(eval)に変換し、推測に頼らずエージェントを改善することができます。
これがチームのヒルクライミングであり、エージェントシステムが時間とともに改善していく方法です。
最も効果的なチームは困難な事例を見つけ、なぜエージェントが失敗したのかを理解し、プロンプト、ツール設定、検索戦略、モデル、ミドルウェア、またはワークフローを調整します。そして評価を再実行し、より良いバージョンを展開し、モニタリングが次のエッジケースや障害をもたらします。
企業内では、そのループをチーム全体で反復可能にすることが課題となります。
各チームが独自の評価フレームワーク、展開インフラストラクチャ、トレーシングシステム、フィードバックパイプライン、ダッシュボードを一から構築しなければならない場合、エージェント開発は遅々として進みません。最も効果的な組織は、共有インフラストラクチャ(shared infrastructure)に投資し、チームが基盤となるシステムを常に再発明することなくライフサイクルを進められるようにします。
それが、エージェント開発ライフサイクルを実践的な運用プラクティスとする理由です。
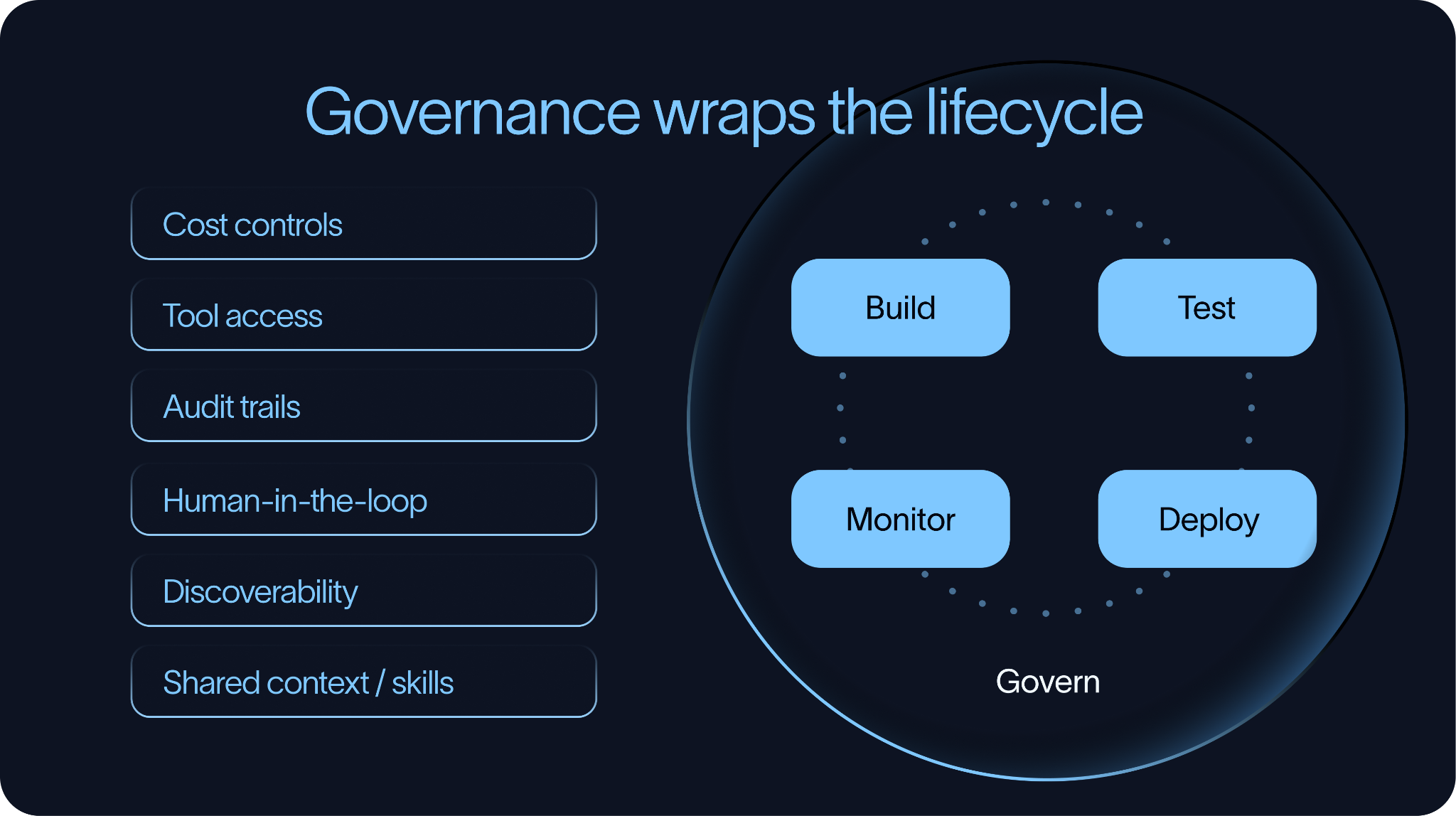
ガバナンス(Governance)
ガバナンスは、エージェント開発のライフサイクル全体を取り囲むものです。
単一のエージェントであれば、軽量なコントロールで十分かもしれません。しかし、組織がより多くのエージェントを展開するにつれ、ガバナンスが必要となります。それがなければ、チームはすぐに、発見が困難で、監視が難しく、実行コストが高く、何ができるのか不明瞭なエージェントを抱え込むことになります。
*コスト*
最初のガバナンス上の課題はコストです。
エージェントは、複数のモデル呼び出しや長いコンテキストウィンドウの処理、ツールの繰り返し使用、リトライの実行、長時間の稼働などを伴う場合があるため、コストが高額になる可能性があります。組織は、予算管理、利用状況のモニタリング、アラート設定、およびどのエージェント・チーム・モデル・ツールがコストを発生させているかという可視性を通じて、その支出を追跡・管理する方法を必要としています。
*ツールのアクセス権限*
2 つ目のガバナンス上の課題は、ツールのアクセス権限です。
エージェントはアクションを実行できるため有用ですが、それと同時にリスクも生じます。チームは、どのツールにエージェントがアクセスできるか、どのような条件下でアクセスできるか、そして誰の名代として実行されるのかについて、明確な制御策を必要とします。
ここで監査証跡(audit trails)の重要性が高まります。エージェントがツールを呼び出した場合、組織はその呼び出しを行ったエージェント、使用された入力、生成された出力、およびそのアクションを許可したユーザーまたはポリシーを検査できる必要があります。ツールの呼び出しは、しばしばエージェントの振る舞いがビジネスへの影響をもたらす箇所であるため、監視可能でレビュー可能な状態にしておくことが不可欠です。
ヒューマン・イン・ザ・ループ(human-in-the-loop)は、もう一つの重要なガバナンスメカニズムです。
すべてのツール呼び出しを完全に自動化する必要はありません。顧客や金融システム、機密データ、本番環境のインフラストラクチャに関わる業務については、人間のレビューのために一時停止するべきです。ヒューマン・イン・ザ・ループのワークフローは、最初からシステムに組み込まれて設計されている場合に最も効果的に機能します。
*発見可能性*
3 つ目のガバナンス上の課題は、発見可能性と再利用性です。
組織がより多くのエージェントを構築するにつれ、プロンプト、スキル、ツール、検索ソース、ポリシー、さらには他のエージェントといった再利用可能な資産も蓄積されていきます。適切な発見およびガバナンスの仕組みがない場合、チームはこれらのコンポーネントを繰り返し再作成することになり、結果として一貫性が失われます。共有された文脈や共有されたエージェントは、見つけやすく、再利用可能で、適切に管理される必要があります。
これは特にスキルにおいて重要です。スキルにはワークフロー、ライティングスタイル、ドメイン固有の手順、またはツールの使用方法に関する指示が記述されます。あるチームがすでに優れたスキルを構築している場合、別のチームはそのスキルを見つけ、ゼロから新しいバージョンを作成するのではなく、それを利用できるべきです。
適切なガバナンスとは、チームの速度を落とすことではありません。それは、エージェントシステムがスケールしても、可視性、制御、一貫性を失うことなく、迅速な反復を可能にするためのものです。
結論
最も優れた組織はすでにこのように運用を開始しています。彼らは早期にリリースしますが、盲目でリリースすることはありません。デプロイ前には評価を行い、デプロイ後には動作を監視し、得られた知見を継続的に活用して次のバージョンをより良くします。
これこそが、エージェント開発を反復可能にする要素です。また、これがエージェントを実証段階から信頼性の高い本番システムへと移行させる要因でもあります。
原文を表示
Everyone wants to ship agents.
The best organizations have figured out how to do it repeatedly, safely, and systematically. They ship early, learn from real usage, and iterate quickly. They don’t treat agents as one-off demos or isolated projects.
Instead, they’ve built an agent development lifecycle that creates momentum by turning experimentation into a repeatable system for shipping, learning, and improving over time.
That lifecycle has four parts:
Build → Test → Deploy → Monitor
The order is intentional. Testing should start before an agent reaches production, not after. Teams need to test the agents before deployment, deploy them in a controlled way, monitor how they behave in production, and feed those learnings back into the next build and evaluation cycle.
For a single agent, this process can stay lightweight. Across many agents, it becomes an infrastructure and governance challenge. Teams need shared ways to control cost, manage tool access, inspect tool calls, reuse context, and decide where humans need to be involved.
The difference between getting an agent to work once to building agents as a repeatable practice comes from having the right development lifecycle in place.
Build
The build phase is where teams decide what kind of agent system they are creating and what level of abstraction they want to use.
There is a wide range of tooling here. Some tools are code-first, while others are no-code or low-code. Some focus on abstractions, while others focus on giving agents a working environment with prompts, tools, skills, and state.
On the code-first side, teams often reach for open-source frameworks and harnesses. In the LangChain ecosystem, that includesLangChain,LangGraph, andDeep Agents. Outside of LangChain, examples include CrewAI and Claude Agents SDK.
These tools operate at different layers of the stack.
Agent frameworks focus primarily on abstractions. They help developers compose model calls, tools, prompts, retrieval, structured outputs, and agent loops. LangChain and CrewAI are examples in this category.
Agent runtimes focus on execution. They support agents that need state, control flow, durability, and human intervention. LangGraph is the clearest example in the LangChain ecosystem. It gives you a way to build agentic systems that can branch, loop, pause, resume, and persist state over time.
Agent harnesses focus on doing. They provide the surrounding structure agents need for longer-running tasks: prompts, skills, MCP servers, hooks, middleware, and sometimes a filesystem. Deep Agents and the Claude Agent SDK are examples of this pattern.
These distinctions matter because “building an agent” can mean different things.
For a simple application, it may only involve defining a tool-calling loop. For a more sophisticated agent, it may involve writing prompts, defining skills, connecting MCP servers, configuring middleware, and setting up context the agent can retrieve or update over time.
*No-code building*
There is also a no-code and low-code side of the build phase. Tools like LangSmith Fleet, Claude Cowork, and n8n allow more people to participate in agent development. That matters because the person who understands the workflow needed is not always the person who writes the code.
At the same time, no-code tools do not eliminate the need for engineering control. As systems become more complex, teams usually need ways to extend or override behavior in code. Hooks and middleware are especially important here because they allow teams to add custom logic around tool calls, context handling, approvals, auth, or business rules without rebuilding every agent from scratch.
The best build environments make simple things simple and complex things possible. They let domain experts edit prompts, skills, and context, while still giving engineers control over the parts that need to be reliable, testable, and governed.
Test
Before an agent is deployed, teams need a way to determine whether it is actually ready.
That does not mean building a perfect eval suite before anyone uses the agent. In practice, that is rarely realistic. It does mean having enough evals in place to catch obvious failures, compare versions, and avoid shipping changes blindly.
Most eval workflows start with a small dataset of representative tasks. Some examples come from expected use cases, while others come from manual testing, dogfooding, support tickets, prior traces, or known edge cases. Over time, production traces make these datasets much stronger, but testing should start before production.
*Datasets and metrics*
Datasets are how teams preserve what they learn. Without them, the same failures tend to reappear after prompt changes, model upgrades, or tool updates.
The right metrics depend on the task.
In some cases, there is a clear ground truth answer. Did the agent extract the right value? Did it choose the right label? Did it update the right field? These tasks can be measured directly for correctness.
Other times, there is no single ground truth answer. An agent may need to write a response, summarize a conversation, decide whether to escalate, or complete a task with many valid paths. In those cases, teams rely more on criteria-based evaluation. The questions become whether the response was grounded, whether the agent followed policy, whether it asked for clarification, or whether it completed the task efficiently without unnecessary tool calls.
*Experiments*
Experiments are what connect datasets and metrics to iteration. They allow teams to compare prompts, models,retrieval strategies, tool schemas, and orchestration patterns against the same evaluation set. . Over time, these experiments show whether the agent is improving or regressing.
The goal is not to create a perfect eval suite on day one. The goal is to start with a useful one and continuously improve it. The most valuable eval datasets are built from the hardest examples: first from development and dogfooding, then later from production.
*Simulations*
Simulation is another important part of testing.
Many agents are multi-turn systems. They do not just answer one question; they have a conversation, gather information, call tools, update state, and recover from ambiguity. For those agents, single-turn evals are not enough. Teams need multi-turn evals and simulated end-to-end interactions.
Voice agents are an obvious example, but the pattern is broader. Any agent that operates over a sequence of turns may need simulation. A support agent may need to handle a frustrated customer, ask follow-up questions, check order status, and decide whether escalation is necessary. A coding agent may need to inspect a repository, make changes, run tests, and respond to feedback. An internal operations agent may need to gather missing information before taking action.
Good testing practices help teams improve agents systematically without relying on vibes. They turn expected behavior into datasets, datasets into experiments, and experiments into better versions of the system. After deployment, monitoring supplies the real-world examples that make those evals stronger.
Deploy
Once an agent has been built and evaluated, it needs an environment where it can reliably run.
For simple agents, deployment may look similar to deploying a traditional application. But many agents need more than a stateless server. They run over longer periods of time, call tools, wait for human input, write files, recover from interruptions, and maintain state across multiple interactions or tasks..
That is why the runtime matters.
A production agent runtime typically needs to support durable execution and human-in-the-loop patterns. Durable execution means the agent can checkpoint progress and resume instead of losing work when something fails. Human-in-the-loop means the agent can pause when it needs approval, clarification, or review.
There are off-the-shelf solutions for this.LangSmith Deployment provides infrastructure for deploying and managing Deep Agents and LangGraph agents. AWS AgentCore is another example of a managed runtime for agents. Some teams also build their own runtime on top of systems like Temporal, especially when they already use Temporal for long-running workflows elsewhere in the stack.
*Sandboxes*
Many agents also need dedicated execution environments.
Agents increasingly need to write code, execute code, inspect files, transform documents, or interact with a filesystem. In those cases, teams need to decide where that work happens. Sandboxes are a common solution. They provide isolated execution environments with filesystem access, while reducing the blast radius of mistakes or unsafe behavior.
Examples includeLangSmith Sandboxes, Daytona, and E2B.
Not every agent requires a full sandbox. In some cases, the agent just needs a place to store and retrieve files. A virtual filesystem can be enough. Deep Agents supports this pattern by allowing agents to use files as working memory without necessarily executing arbitrary code inside a sandbox. Underneath, that filesystem might be backed by systems like Postgres or S3.
*Context Hub*
Another often overlooked part of deployment is managing prompts and context.
Some of the most important parts of an agent are not traditional application code. Prompts, retrieval context, skills, and task instructions may need to change more often than the application itself. They may also need to be edited by people who are not engineers.
That creates the need for a prompt or context hub: a place to store, version, review, and update the non-code parts of the agent. This allows teams to adjust agent behavior without a full deploy, and it lets domain experts own the context they understand best.
In practice, deployment is not just about putting an agent on a server. It is about giving the agent the runtime, execution environment, and context management systems it needs to do real work.
Monitor
Once agents are deployed, teams need visibility into how they actually behave in production.
This is where monitoring agents differs from monitoring traditional software. Metrics like latency, cost, error rates, and uptime still matter, but they are only part of the picture. An agent can return a technically successful response and still fail the task itself. It may call the wrong tool, rely on the wrong context, skip a required approval step, or produce an answer that sounds plausible but is wrong.
To understand those failures, teams need traces.
A trace captures the full trajectory of the agent: the inputs it received, the model calls it made, the tools it invoked, the outputs it received, and the final response or action it produced. This is the level of detail you need to understand what the agent actually did.
This is why we have argued thatagent observability powers agent evaluation, and whythe agent improvement loop starts with a trace. If you cannot see the trajectory, you cannot reliably debug the behavior or turn those failures into future evals.
*Signals*
Monitoring should also include harvesting signals from those traces.
Some of those signals can come from LLM-as-judge evaluators. For example, a judge can score whether the agent answered the user’s question, followed policy, used the right tone, or completed the task. Other signals can be simpler. A regex can catch whether a required phrase appeared, whether a forbidden tool was called, or whether a known failure pattern occurred.
These signals are useful for more than just quality checks. They can also become a form of product analytics. They can tell you which tasks users are asking agents to do, where agents are getting stuck, how often users correct them, and where users perceive errors.
*Feedback*
Feedback is another core part of monitoring.
It is not enough to store traces alone. Teams also need to store feedback with those traces. That feedback can come from LLM judges, regex-based signals, human reviewers, or direct user feedback collected through an API. In LangSmith, for example, teams can attach user feedback directly to the underlying run, making it easier to connect “the user was unhappy” to “the agent used the wrong tool three steps earlier.”
*Dashboards*
Finally, teams need dashboards and alerts that can surface trends over time.
A useful agent dashboard tracks metrics like usage, feedback, latency, cost, tool calls, evaluator scores, and recurring failure patterns. Alerts should trigger when important thresholds are crossed, such as rising latency, increasing costs, failing tools, declining user feedback, or spikes in policy violations.
Good monitoring is not just about knowing whether the system is up. It is about understanding whether the agent is doing the right work, in the right way, and improving over time.
The strongest monitoring systems feed directly back into evaluation. Important traces become dataset examples, recurring failures become metrics, and production behavior becomes the foundation for the next round of improvement.
Iterate
The best organizations move through the agent development lifecycle quickly and systematically.
They do not wait for a perfect agent before shipping. Instead, they build something useful, test it enough to understand its behavior, deploy it in a controlled way, monitor how it performs in production, and feed those learnings back into the next version.
That does not mean shipping carelessly. The key is having visibility.
Teams with datasets, experiments, tracing, feedback, and dashboards can learn directly from real real usage. They can test changes before rolling them out broadly, identify what broke in production, turn failures into evals, and improve the agent without relying on guesswork.
This is how teams hill-climb, and how agent systems improve over time.
The most effective teams find the hard examples, understand why the agent failed, and adjust the prompt, tool configuration, retrieval strategy, model, middleware, or workflow. They re-run the evals, deploy the better version, and monitoring gives them the next edge cases and failures.
Inside an enterprise, the challenge is making that loop repeatable across teams.
If every team has to build its own evaluation framework, deployment infrastructure, tracing system, feedback pipeline, and dashboards from scratch, agent development will move slowly. The most effective organizations invest in shared infrastructure so teams can move through the lifecycle without constantly reinventing the underlying systems.
That is what makes the agent development lifecycle an operational practice.
Govern
Governance sits around the entire agent development lifecycle.
For a single agent, lightweight controls may be enough. As organizations deploy more agents, governance becomes necessary. Without it, teams quickly end up with agents that are difficult to discover, difficult to monitor, expensive to run, and unclear in what they are allowed to do.
*Cost*
The first governance challenge is cost.
Agents can become expensive because they may involve multiple model calls, long context windows, repeated tools usage, retries, or run for a long time. Organizations need ways to track and manage that spend through budgets, usage monitoring, alerts, and visibility into which agents, teams, models, or tools are driving costs.
*Tool Access*
The second governance challenge is tool access.
Agents are useful because they can take action, but that also introduces risk. Teams need clear controls around which tools an agent can access, under what conditions, and on behalf of which users.
This is where audit trails become important. If an agent calls a tool, organizations should be able to inspect which agent made the call, what inputs it used, what outputs it produced, and what user or policy authorized the action. Tool calls are often where agent behavior drives business impact, so they need to be observable and reviewable.
Human-in-the-loop is another important governance mechanism.
Not every tool call should be fully automated. Some operations should pause for human review, especially when they involve customers, financial systems, sensitive data, or production infrastructure. Human-in-the-loop workflows work best when they are designed into the system from the beginning.
*Discoverability*
The third governance challenge is discoverability and reuse.
As organizations build more agents, they also accumulate more reusable assets such as prompts, skills, tools, retrieval sources, policies, and even other agents. Without good discovery and governance mechanisms, teams tend to recreate these components repeatedly, leading to inconsistency.Shared context and shared agents need to be findable, reusable, and governed.
This is especially important for skills. A skill can encode a workflow, a writing style, a domain-specific procedure, or instructions for using a tool. If one team has already built a good skill, another team should be able to find it rather than write a new version from scratch.
Good governance is not about slowing teams down. It is about making fast iteration possible without losing visibility, control, or consistency as agent systems scale.
Conclusion
The best organizations have already started to operate this way. They ship early, but they do not ship blindly. They evaluate before deploying, monitor behavior after deployment, and continuously use what they learn to make the next version better.
That is what makes agent development repeatable. It is also what allows agents to move from demos into reliable production systems.
関連記事
LangSmith のノーコードエージェントビルダーの紹介
LangChain が提供する LangSmith に、プログラミング不要で AI エージェントを構築できる新機能が導入された。
深層エージェントにおけるコンテキスト管理
LangChain Blog は、複雑なタスクを処理する深層エージェントの性能向上のために、コンテキストを効果的に管理・最適化する手法について解説している。
マルチエージェントシステムをいつどのように構築するか
LangChain は、複数の AI エージェントが協調して複雑なタスクを解決するマルチエージェントシステムの設計手法と実装タイミングについて解説している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み