[AI ニュース] Microsoft Build:MAI-Thinking-1 と MAI ファミリーモデルを発表
Microsoft は Build 2026 で、推論・コード・画像など7種類のMAIモデルを発表し、特に詳細な技術報告書とゼロからの学習を強調した。
キーポイント
MAI ファミリーの新規発表
Microsoft AI は Build で MAI-Thinking-1 を含む7つの新モデルを発表し、推論、コード生成、画像処理、音声トランスクリプション、音声合成をカバーする。
MAI-Thinking-1 の技術的透明性
フラッグシップの推論モデル「MAI-Thinking-1」は、第三者からの知識蒸留を行わずクリーンなデータでゼロから学習されたことを強調し、109ページの技術報告書を公開した。
ローカルAIとエージェントWindows の推進
Secure execution layers や Surface RTX Spark Dev Box などの新ハードウェアを通じて、Windows をエージェントネイティブなプラットフォームとして再定義する方針を示した。
GitHub Copilot と開発体験の統合
Copilot アプリを「デスクトップのエージェント・ソフトウェア開発ホーム」と位置づけ、Canvas 機能やクロスデバイス連携による開発ワークフローの強化を発表した。
MAI-Thinking-1 の性能と効率性
35B アクティブパラメータの MoE モデルとして、AIME 2025 で 97%、SWE-Bench Pro で 53% を達成し、Sonnet 4.6 よりも人間評価で優れていると発表された。
MAI-Code-1-Flash の軽量コーディング能力
わずか 5B アクティブパラメータでありながら SWE-Bench Pro で 51% を達成し、VS Code や GitHub Copilot CLI に最適化された高速コーディングモデルとして登場した。
MAI-Image-2.5 の画像編集リーダーボード首位
画像編集分野で Nano Banana 2 を上回り、Image Edit Arena で 1401 というスコアを獲得して第 2 位にランクインした。
重要な引用
Microsoft used Build to position itself as both an AI platform company and a frontier-model lab
built with clean data lineage and zero distillation from third-party models
The flagship reasoning model MAI-Thinking-1 was presented as Microsoft's first reasoning model
"Microsoft claims the model is optimized on MAIA 200, with 30% better performance per dollar and 1.4x performance-per-watt gain versus GB200 when running MAI models end-to-end"
"Microsoft and partners repeatedly stressed no third-party distillation, 'clean data lineage,' and enterprise-controlled fine-tuning with '100% eyes-off' post-training data"
MAI-Thinking-1 used no synthetic data and no distillation, not only in post-training but throughout the disclosed pipeline
影響分析・編集コメントを表示
影響分析
この発表は、Microsoft が単なるプラットフォーム企業から、独自の大規模推論モデルを開発する「フロンティア・ラボ」へと明確にシフトしたことを示す重要な転換点です。特にゼロからの学習と詳細な技術報告書の公開は、業界全体の透明性基準を高める可能性があり、競合他社に対する強力な差別化要因となります。また、ローカルAIとエージェント機能の強化は、企業ユーザーがクラウドコストやデータプライバシーを懸念する中で、オンプレミスやエッジでの実用性を高める新たな潮流を牽引すると予想されます。
編集コメント
Microsoft の「MAI」ブランドへの本格的な投入と、技術報告書の公開は業界の透明性基準を再定義する動きであり、特に推論能力に特化したモデル戦略は注目に値します。
今日は大きな一日でした。GitHub とエージェントの現状について追跡し、No Priors と Satya Nadella と共に特別版ポッドキャストを録音したこともその理由の一つです。MS Build において、Satya と Mustafa は 7 つの新しい MAI モデルを発表しました。
これは印象的なラインナップです。特に、MAI を設立した Microsoft と Inflection の提携がわずか 2 年前に成立し、これらすべてがゼロから作成された事前学習モデルである点を考慮するとなおさらです。現在の MAI は無条件で最先端研究所と呼べるわけではありませんが、明確なインセンティブを持ってドメイン特化型ファインチューニング(finetune)をサポートする良質な Tier 2 のニューラボと言えます。(※最先端研究所の多くはファインチューニングをほぼ廃止しているのとは対照的です。)
今回の発表の真の花形は、100 ページを超える MAI テクニカルレポートでした。研究コミュニティからは絶賛の声が寄せられています。
すべての発表の詳細については、優れた Verge のまとめ記事や、以下のツイートサマリーをご覧ください。
2026 年 6 月 1 日〜2 日の AI ニュース。私たちは 12 のサブレッドと 544 のツイートをチェックし、Discord は新たに確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space の一部となっています。メール配信頻度の設定をオン/オフに切り替えることができます!
AI Twitter リキャップ
トップストーリー:Microsoft Build のまとめと新しい MAI モデルの技術詳細
何が起きたか
Microsoft は Build を通じて、AI プラットフォーム企業であると同時にフロンティアモデル研究所としての立場を確立し、広範な製品発表と、新しい MAI モデルファミリーに関する例外的に詳細な開示を組み合わせて行いました。
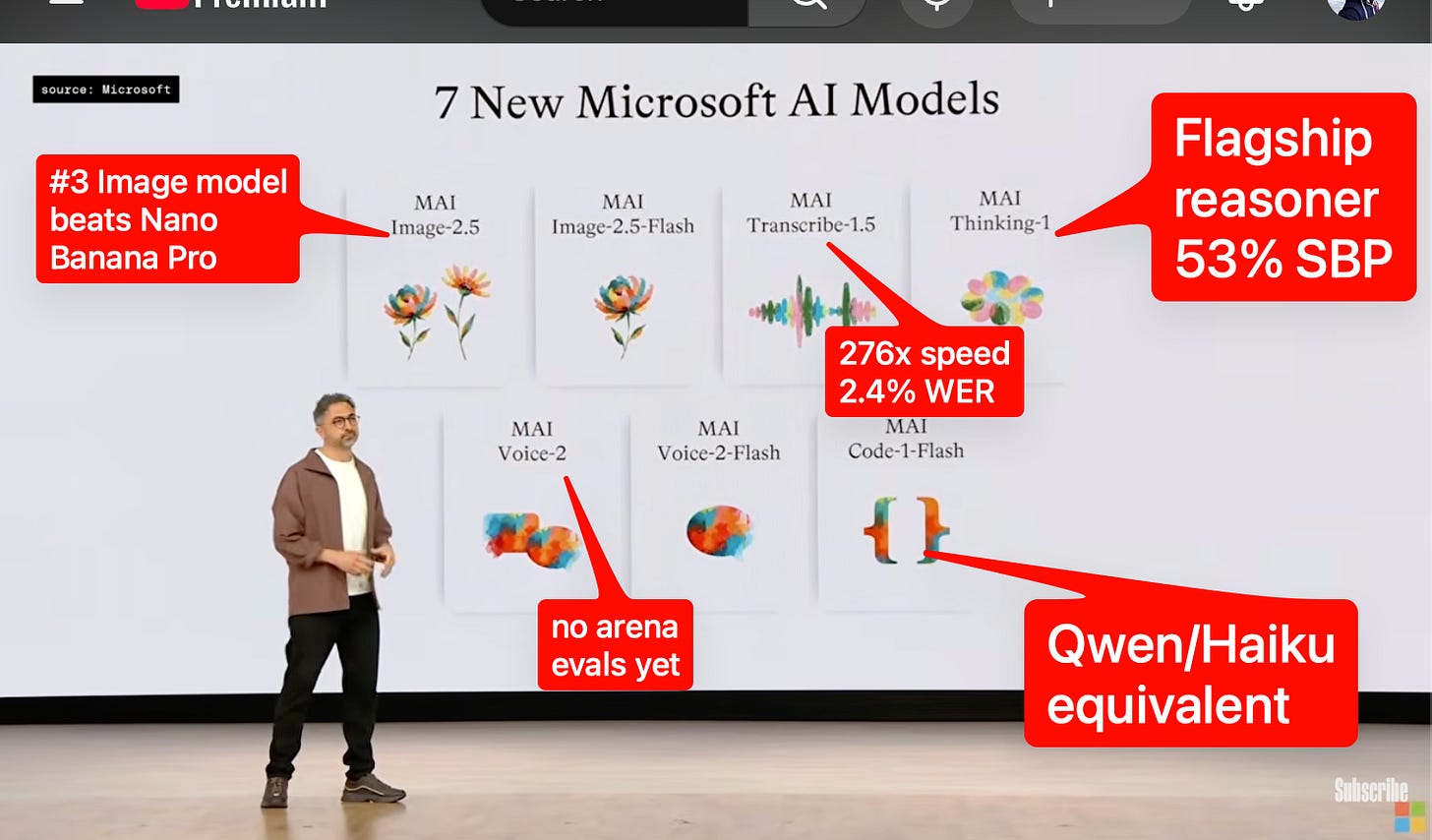
Microsoft AI は、@MicrosoftAI と @mustafasuleyman によると、推論、コード生成、画像処理、音声文字起こし、音声合成をカバーする 7 つの新たな MAI モデルを発表しました。これらは、MAI-Thinking-1、MAI-Code-1-Flash、MAI-Image-2.5、MAI-Transcribe-1.5、MAI-Voice-2 を中心としたファミリーです。
フラッグシップとなる推論モデル「MAI-Thinking-1」は、Microsoft の初の推論モデルとして紹介されました。@mustafasuleyman、@baseten、@tuhinone、@HannaHajishirzi による投稿によると、このモデルはクリーンなデータ系譜(data lineage)に基づいて構築され、第三者のモデルからの蒸留(distillation)を一切行っていないことが強調されました。
Microsoft は MAI-Thinking-1 のために 109 ページにわたる技術報告書を公開しました。その透明性の高さから、@eliebakouch、@ethanCaballero、@nrehiew_、@yacinelearning、@stochasticchasm など、技術志向の読者たちから強い肯定的な反応を引き出しています。
また、Microsoft はローカル AI とエージェントネイティブな Windows にも注力しました。Build のメッセージでは、エージェント向けの安全な実行レイヤー(execution layers)、新しい Surface RTX Spark Dev Box、Windows AI を通じた広範な Windows GPU インストールベースへのアクセス、そして Project Solara/Scout といったコンセプトハードウェアが強調されました。これらは @yusuf_i_mehdi、@TheTuringPost、@kimmonismus によって要約されています。
Build では、Canvases やクロスデバイス間の継続性、そして GitHub エージェントワークフローの強化などにより、「エージェントネイティブなソフトウェア開発のためのデスクトップホーム」として GitHub Copilot アプリの主要なプッシュが行われ、@pierceboggan 氏、@lukehoban 氏からの発表と、@techgirl1908 氏による反応が紹介されました。
Microsoft は Web IQ を導入しました。これは AI エージェント向けの新しいグラウンディング/検索 API スタックであり、同社は「業界のほぼすべての AI エージェントやチャットボット(Copilot や ChatGPT などを含む)を既に支えている」と主張しています。この発表は @JordiRib1 氏を通じて行われました。
Satya Nadella 氏は Build を単一の製品発売ではなく、エコシステム全体の転換点として位置づけました。一方、Mustafa Suleyman 氏はこれを Microsoft の内部で稼働する「ヒルクライミングマシン」の成果物として捉えています。これらの見解は @satyanadella 氏、@mustafasuleyman 氏の発言と、@nrehiew_ 氏による反応に基づいています。
MAI モデルファミリー:開示された事実と技術詳細
MAI-Thinking-1
Microsoft は MAI-Thinking-1 を、256K のコンテキストウィンドウを持つ 35B アクティブパラメータの MoE(Mixture of Experts)モデルとして説明しました。これは @mustafasuleyman 氏の発言に基づいています。
@scaling01 氏による別の要約では、このモデルは 30T トークンで事前トレーニングされ、8192 GB200 GPU を使用してトレーニングされた 1T@35B パラメータのモデルであるとされています。これは Microsoft のマーケティングコピーではなく、技術レポートの解釈であるようです。
@kimmonismus 氏も同様に、アクティブパラメータが 45B の中規模 MoE と要約していますが、これは Mustafa 氏が示した 35B という数値と矛盾します。ツイートセットの中でより権威ある数字は、公式の 35B アクティブという数値です。
MAI モデルファミリー:開示された事実と技術詳細
MAI-Thinking-1
Microsoft は MAI-Thinking-1 を、256K のコンテキストウィンドウを持つ 35B アクティブパラメータの MoE(Mixture of Experts)モデルとして説明しました。これは @mustafasuleyman 氏の発言に基づいています。
@scaling01 氏による別の要約では、このモデルは 30T トークンで事前トレーニングされ、8192 GB200 GPU を使用してトレーニングされた 1T@35B パラメータのモデルであるとされています。これは Microsoft のマーケティングコピーではなく、技術レポートの解釈であるようです。
@kimmonismus 氏も同様に、アクティブパラメータが 45B の中規模 MoE と要約していますが、これは Mustafa 氏が示した 35B という数値と矛盾します。ツイートセットの中でより権威ある数字は、公式の 35B アクティブという数値です。
Microsoft は、AIME 2025 で 97%、SWE-Bench Pro で 53% のスコアを達成し、盲検の人間評価者による Surge での総合評価では Sonnet 4.6 を上回っていると主張しています。これは @mustafasuleyman と @asadovsky からの情報です。
Microsoft は、このモデルが MAIA 200(MAIA 200)上で最適化されており、GB200 で MAI モデルをエンドツーエンドで実行する際、1 ドルあたりのパフォーマンスが 30% 向上し、ワットあたりのパフォーマンスが 1.4 倍になると述べています。これは @mustafasuleyman の発言に基づくものです。
Microsoft とパートナー企業は繰り返し、第三者による蒸留(distillation)を行っていないこと、「クリーンなデータ系譜(data lineage)」の維持、および Baseten を通じた「トレーニング後データにおける 100% の目視なし("100% eyes-off")」でのエンタープライズ制御型ファインチューニングを強調しました。これは @baseten、@tuhinone、@MicrosoftAI からの情報です。
MAI-Code-1-Flash
Microsoft は、VS Code および GitHub Copilot CLI 向けの高速コーディングモデルとして MAI-Code-1-Flash を導入しました。これは最初に @pierceboggan によって発表され、その後 @mariorod1 によって注目されました。
@mustafasuleyman による公式 Microsoft のメッセージによると、Code-1-Flash はわずか 5B パラメータ(50 億パラメータ)でありながら SWE-Bench Pro で 51% を達成しており、Haiku クラスのサイズとコストに近い位置づけであるとされています。
@scaling01 による競合する要約では、これは 137B パラメータの MoE(Mixture of Experts:専門家混合モデル)、256K のコンテキスト長を持ち、10T+ トークンでトレーニングされたものであり、「Claude 4.5 Haiku よりも強力で効率的である」と説明されています。これはおそらく総パラメータ数ではなく、アクティブなパラメータ数が 5B であることを示唆していると考えられます。これらのツイートはこの区別を完全に整合させるものではありませんが、合わせてはるかに大きな MoE の内部に小さなアクティブフットプリントがあることを示唆しています。
@scaling01 と @mariorod1 によると、ローンチ時の利用可能性は GitHub Copilot および VS Code を最優先としたものとして強調されました。
MAI-Image-2.5
Microsoft は MAI-Image-2.5 とフラッシュ版を発売し、両方ともリーダーボードで 2 位を獲得したと主張。@mustafasuleyman 氏は、これらが画像編集において Nano Banana 2 を上回ると述べています。
独立したリーダーボードアカウントがその高順位を支持しました:@arena は Image Edit Arena で 1401 のスコアで 2 位となり、Nano Banana 2、Grok Imagine、ChatGPT Image Latest HF よりも 10 ポイント上回ったと報告しています。
@arena はさらに、MAI-Image-2.5 が「パレートフロンティアを前進させた」と述べ、これは同価格帯のモデルの中でそのベンチマークでこれ以上のスコアを出すものがないことを意味します。
配布パートナーもすぐに追随し、@OpenRouter や @fal などが含まれます。
MAI-Transcribe-1.5
@ArtificialAnlys は、MAI-Transcribe-1.5 が音声認識(STT: Speech-to-Text)の最前線において、 unusually strong な速度と精度のポイントであると報告しました:リアルタイムの約 276 倍、AA-WER(Average Word Error Rate)は 2.4%、リーダーボード全体で 3 位です。
このモデルは英語、フランス語、アラビア語、日本語、中国語を含む 43 か国語をサポートしており、@ArtificialAnlys によると、名前や医療用語などの稀な用語に対するキーワードバイアス機能も備えています。
価格は、@ArtificialAnlys の報告によると、Microsoft Foundry を通じて音声 1,000 分あたり 6 ドルです。
OpenRouter もまた、同日にライブ化した 3 つの MAI 発表モデルの一つとしてこのモデルをリストしました(@OpenRouter)。
MAI-Voice-2
MAI-Voice-2 は、Microsoft の「7 つのモデル」の傘下にも含まれており、@OpenRouter の利用可能状況投稿でも確認できます。
そのツイートセットには、発売日や利用可能性以外に Voice-2 自体に関する技術的な詳細はほとんど含まれていません。
研究者にとって重要な技術レポートの詳細
なぜこの報告が際立っていたのか
技術的な反応の主流は、Microsoft が通常とは異なり詳細な最前線モデル報告書を公開したという点でした。@eliebakouch はこれを「この規模のモデルとしては最も透明性の高いものの一つ」と呼び、@nrehiew_ は「今日の LLM 学習のための更新された教科書として本当に役立つだろう」と評価し、@stochasticchasm は「金鉱だ」と評しました。
複数の読者が、報告書がパイプラインの詳細、スケーリングラダーの手法、データ選別、インフラ指標、そして MFU(モデルフロップル利用率)の数値を明らかにした点を強調しました。このレベルの具体性が、@ethanCaballero、@eliebakouch、@nrehiew_ からの称賛を引き出したのです。
事前学習とデータ
コメント全体で繰り返された主要な技術的主張は、MAI-Thinking-1 がポストトレーニングだけでなく、開示されたパイプライン全体を通じて合成データも蒸留(distillation)も使用しなかったという点です。これは @eliebakouch、@stochasticchasm、@HannaHajishirzi によって指摘されました。
@eliebakouch によると、報告書は Common Crawl および非公開ソースからのデータを使用し、異なるドメイン向けのターゲットサブパイプラインを設け、大量の抽出・重複排除作業を行い、意図的に合成データを避けたことを明確に記述しています。
スケーリング判断のために使用された報告書の内部非公開 NLL(自然言語推論)セットは、@eliebakouch によって以下のように要約されました:
コード 50%
STEM(科学・技術・工学・数学)17.5%
数学 17.5%
一般知識 10%
多言語 5%
@eliebakouch によると、スケーリングラダーにおけるアーキテクチャの昇格は、効率性向上(EG:Efficiency Gain)指標に基づいて行われました。これは、ベースラインが候補モデルの損失に追いつくために必要な追加計算リソースの量を指します。
同じスレッドでは、パラメータあたり約 100/200 トークンのアブレーション(除去実験)が報告されており、これは設定において「Chinchilla 最適」に近いと説明されています。また、@eliebakouch は、MoE(Mixture of Experts:専門家混合)構造のため、この結果は密なモデルのヒューリスティックとは異なると指摘しています。
ポストトレーニング / RL
最も議論された技術的選択は、Microsoft が事前の推論経験のないチェックポイントから強化学習(RL: Reinforcement Learning)を開始した点であり、これに複数の読者が注目しました。@stochasticchasm はこれを「非常に興味深い決定」と呼びました。また、@stochasticchasm は、AIME25 のスコアが 20% から 95% 以上に跳ね上がったことを示すグラフに対して反応を示しています。
@HannaHajishirzi は、「ゼロから登る」レシピを、シンプルなレシピ、厳密な科学、自己蒸留(self-distillation)、忍耐、そして優れたインフラと表現しました。
@soldni はこのプロセスを「蒸留なしで登る。ビッグボーイズがやるように」と特徴づけました。
一部の独立した読者は、Microsoft がここではあえて合成データ(synth data)を避けたとしても、より広い分野におけるエージェント性能において合成データは依然として非常に価値があると報告から推測しました。詳細は @stochasticchasm を参照してください。
データキュレーション / ジャッジ / DSPy GEPA
DSPy や後期相互作用(late-interaction)のコミュニティから大きな注目を集めた詳細があります。Microsoft は、事前トレーニングデータのキュレーションと品質スコアリングにおいて、GEPA / DSPy 最適化された LLM ジャッジを使用していたと報告されています。
これは @bj2rn、@LakshyAAAgrawal、@lateinteraction によって強調されました。
インフラ / 利用率 / ハードウェア共設計
Microsoft は、イテレーションごとの正確な MFU(Model FLOPs Utilization:モデル FLOP 利用率)を明らかにしたと報告されています。これは @eliebakouch によると、この規模では通常共有されない稀な事例であると複数の読者が述べています。
@scaling01 は、この実行を 8192 GB200 GPU を使用したと要約しました。
@eliebakouch は、報告されたワットあたりのスループットが約 40%向上したという数値について、「マイクロソフトのチップに対して非常に印象的で楽観的だ」と指摘しましたが、これはラックレベルの予算やサービング構成を指している可能性があり、ツイート内で完全に解明されたわけではありません。
Microsoft の公式な見解では、モデル設計が MAIA 200 カスタムシリコンと結びつけられ、@mustafasuleyman において NVIDIA GB200 と比較してドルあたりのパフォーマンスやワットあたりのパフォーマンスの向上が強調されました。
Build イベントにおけるより広範な Windows/ローカル AI の物語も、ハードウェアの詳細に焦点を当てていました。具体的には以下の通りです:
DGX Station 上でローカルで動作する 1 兆パラメータのモデル
128GB の統合メモリ
110 TOPS の AI パフォーマンス
20 コアの CPU
@TheTuringPost による 70 以上の PowerToys ユーティリティ
反応はまた、RTX Spark 上でローカルに 120B パラメータのモデルを実行した @kimmonismus のような、大規模モデルのローカル実行にも言及していました。
モデル以外の Build プロダクト/プラットフォームの振り返り
GitHub Copilot アプリとエージェントネイティブ開発
GitHub は、@pierceboggan によってエージェントネイティブなソフトウェア開発のためのデスクトップサーフェスとして位置づけられた GitHub Copilot アプリを発表しました。
主要なテーマには以下が含まれます:
ユーザーとエージェント間の双方向作業のためのキャンバス(@Techmeme による)
CLI、モバイル、Web、ローカル、クラウドにわたる継続性(@lukehoban による)
@techgirl1908 や @OrenMe に反映されるように、GitHub がエージェントワークフローの中心として果たす役割の拡大
Copilot CLI もまた、@GHchangelog によると、タブ機能、組み込みフィードバック/ラバーダック機能、プロンプトスケジューリング、音声入力を実装した実験的なターミナル UI を獲得しました。
Windows をエージェントランタイムとして
Microsoft の Windows オルガニゼーションは、@yusuf_i_mehdi 氏によると、Build イベントを「より迅速な開発者実行、エージェント向けの安全な実行レイヤー、デバイス上でローカルに動作する無制限のインテリジェンス」という枠組みで位置づけました。
複数の投稿では、Microsoft が Windows を単なる Azure の一部ではなく、エージェントに対する信頼できる実行プラットフォームとしたいと考えていることが強調されました。
@TheTuringPost 氏は、Project Solara を「エージェントファーストのデバイス」向けのプラットフォームとして説明し、その概念には以下のようなものが含まれます:
デスクトップ AI コンパニオン
カメラ、マイク、センサー、そして安全な認証機能を備えたウェアラブルバッジ
@kimmonismus 氏はこれらを、エージェントを制御するためのハンドヘルド型またはデスクトップ型のデバイスと捉え、人々がスタンドアロン型の OpenAI ハードウェアに期待していたものとの比較を行いました。
また @kimmonismus 氏は、Microsoft Scout を「仕事のための常時稼働するパーソナルエージェント」として別に紹介しました。
Web IQ とエージェント向けの検索
@JordiRib1 氏は、Microsoft Web IQ をウェブページ、ニュース、画像、動画に対する AI ネイティブなグラウンディング API のスイートとして発表しました。
彼の枠組みは重要な文脈となります:従来の検索エンジンは人間のために構築されましたが、Microsoft は将来の検索需要はエージェントから来るものになると考えており、その量は人間の検索トラフィックの 1000 倍に達する可能性があると指摘しています。
Web IQ は、品質、レイテンシ、トークン効率を向上させるために Bing のスタックから再設計されたと主張し、すでに Copilot や ChatGPT を含む主要なチャットボットの基盤となっていると述べています。
Foundry とオープンモデルの配布
@jeffboudier 氏は、Satya 氏が Microsoft Foundry で利用可能なモデルが 11,000 以上あると引用し、そのうち 10,928 モデルは Hugging Face から提供されていると述べました。
これは、Microsoft が Build で示す二重のアイデンティティ、つまり自社モデルの開発者であり、大規模なマルチモデルのホスティング・配布プラットフォームであるという立場を裏付けるものです。
データセンターと計算資源に関するビルドでのメッセージ
複数の観察者が、データセンターの拡張やコミュニティからの反発、そして AI インフラが地域社会への電気コストの上昇なしに拡大可能だとする Microsoft の主張について、Build での議論を指摘しました。詳細は @kimmonismus および @kimmonismus を参照してください。
@scaling01 は、Mustafa が「AI の計算資源は今後 3 年間で 1000 倍に成長し、現在の約 5e27 FLOPs(浮動小数点演算回数)の最前線規模を 2029 年には 5e30 FLOPs に引き上げる」と述べている点を強調しました。
@mustafasuleyman は、同社の哲学的テーマを「人道的スーパーインテリジェンス(Humanist superintelligence)」と要約しました。
事実 vs. 意見
ツイート群における事実に基づく主張
Microsoft は Build で 7 つの新しい MAI モデルを発表しました:@MicrosoftAI
MAI-Thinking-1 の公式メトリクス:350 億アクティブパラメータの MoE(Mixture of Experts)、256K コンテキスト、97% AIME 2025、53% SWE-Bench Pro、および Sonnet 4.6 に対する盲検人間評価での優位性:@mustafasuleyman
MAI-Code-1-Flash の公式メトリクス:SWE-Bench Pro で 51%、ツイート本文に記載された通りパラメータ数は 50 億:@mustafasuleyman
MAI-Image-2.5 のランキング主張は、@arena によって独立して言及されました。
MAI-Transcribe-1.5 の速度・精度の詳細は、独立したベンチマークアカウント @ArtificialAnlys から提供されました。
Microsoft は 109 ページの技術レポートを公開しました:@eliebakouch
意見 / 解釈
「Microsoft は今や本気のモデルを訓練しているのか?」という @teortaxesTex の発言は、モデルおよびレポートの質に対する解釈的な反応であり、単独の事実ではありません
報告書が「最も透明性の高いものの一つ」であるとか「更新された教科書」という主張は、@eliebakouch と @nrehiew_ の意見であり、多くの読者が共有しているに過ぎません
@kimmonismus と @TheTuringPost は、Build をクラウド中心の AI からローカル推論/エージェントへの戦略的転換と位置づけましたが、これは公式な表現ではなく分析です
@swyx や @scaling01 などが投稿した、Microsoft が Anthropic の Mythos FLOPs(計算量)を「漏洩」したとする主張は、スライドに対する推測的な解釈であり、後に同じコメント群によって反論されました
異なる意見と視点
支持する見解
技術系の読者たちは、報告書の透明性と、通常この規模では公開されない詳細情報を公表しようとする Microsoft の姿勢に広く感銘を受けました:@eliebakouch, @nrehiew_, @ethanCaballero, @stochasticchasm
MAI-Thinking-1 を通じて、Microsoft が単なるモデルの再販売業者やアプリケーション層ではなく、真のフロンティア研究所へと進化していることの証明と捉えた人もいました。例:@teortaxesTex, @echen, @NandoDF
エンタープライズ/プラットフォーム支持者たちは、クリーンなデータ系譜(data-lineage)、ファインチューニング可能、トレーニング後のデータを監視しないというストーリーを好みました。特に Baseten と Microsoft が所有権と制御について提示した位置づけが評価されました:@baseten, @tuhinone
中立・分析的な見解
いくつかの投稿は、発表を称賛するのではなく、報告書を読み解き分析することに焦点を当てていました。特に @stochasticchasm, @nrehiew_, @eliebakouch です
一部の評論家はベンチマークの解釈に慎重でした。@kimmonismus は、Microsoft が一般的には Sonnet 4.6 と比較しているように見え、Opus レベルでの同等性は SWE Pro のみであると指摘しました。
@iScienceLuvr は、コーディングや数学だけでなく、HealthBench Professional や MedXpertQA といったヘルスケア関連のベンチマークに関する報道を特に評価しました。
懐疑的・反対意見
一部の読者は、すべての数値や比較が正しく解釈されているか疑問視し、特にアクティブパラメータの数や外部モデルとの比較について懸念を示しました。
最も目立った懐疑論は、Mythos の FLOP(浮動小数点演算回数)に関する「リーク」の件でした。@iScienceLuvr は、これはおそらくリークではなく推計値だと示唆し、@scaling01 は後に元の 6.1e27 FLOP という数値が非現実的であると主張してより低い代替推計値を提示した後、@scaling01 で訂正を投稿しました。
また、読者たちが elsewhere で合成データの違い(synth-data deltas)を強調しているように、ゼロ合成やゼロ蒸留が最高のエージェント性能のための長期的な最適なレシピであるかどうかについても、現場には暗黙の懐疑論がありました。例として @stochasticchasm が挙げられています。
背景:なぜこれが重要なのか
Build での発表は重要です。なぜなら、Microsoft がもはや単に以下の役割に留まることに満足していないことを示唆しているからです:
- Azure/OpenAI のクラウドホスト
- GitHub の開発者向けプラットフォーム
- Copilot のアプリケーションシェル
同社は、独自のモデルファミリー、シリコンスタック、ポストトレーニングプラットフォームを備えたファーストパーティのフロンティアモデル開発者としても活動しようとしています。
クリーンな系譜/蒸留への強調なしという点は戦略的に重要です。これは、知的財産の出自、将来の制御可能性、および外部ラボへの依存に関する企業の懸念に対応するものです。
ローカル AI への重点は、Microsoft が AI 戦略を Azure のみならず Windows やデバイス配布にも結びつけているため重要です。Build のメッセージでは繰り返し、推論モデル、プランナー、エージェントがクラウドだけでなく、ますますオンデバイスで実行可能であるという考えが強調されました:@TheTuringPost, @yusuf_i_mehdi
109 ページに及ぶ報告書が重要なのは、最先端モデルの透明性が一般に縮小しており、特にデータ、インフラストラクチャ、トレーニング手法の周辺でその傾向が強まっているからです。複数の研究者は、この規模での開示レベルは異例であると明確に指摘しました:@eliebakouch, @nrehiew_
Build の要約ではまた、Microsoft がスタックのすべての層を統合しようとしている様子も示されました:
モデル:MAI ファミリー
チップ:MAIA 200
クラウド:Azure + Foundry
OS: Windows エージェントランタイム
開発者 UX: Copilot アプリ / VS Code / CLI
検索/グラウンディング:Web IQ
ハードウェアフォームファクター:Solara / Scout コンセプト
この組み合わせが、複数の観察者が本イベントを通常のデベロッパーカンファレンスというよりも、クラウド、エッジ、OS、カスタムモデルにまたがるエージェントプラットフォームへの協調的な動きと捉えた理由です。例として @satyanadella, @mustafasuleyman, @TheTuringPost が挙げられます。
「Mythos FLOPs 漏洩」のミニストーリー
ビルド開催中およびその後に、一部のユーザーはマイクロソフトのスライドが誤って Anthropic の噂の Claude Mythos のトレーニング計算リソースを明らかにしたと主張し、@swyx が Mustafa が FLOP 数を漏洩したのかと質問しました。
@scaling01 は、スライドがピクセル測定に基づく信頼区間付きで 6.1e27 FLOPs を示唆していると推定し、一方 @kimmonismus はそれが Gemini 3.1 Pro スケールの計算リソースに相当すると指摘しました。
この解釈はその後、おそらくこれは推計であると主張した @iScienceLuvr によって挑戦され、さらに @scaling01 自身も後日、より低い範囲のモデルベースによる推定として 3.37e26 から 1.46e27 FLOPs を投稿し、その後元の数値は誤りであると @scaling01 で発言しました。
この出来事は主に文脈として有用です:ビルドにおける計算リソースやスケーリングに関するメッセージが詳細すぎたため、人々が発表資料から競合他社のトレーニング予算を推測しようとし始めたのです。
開発者ツール、エージェント、コーディングワークフロー
OpenAI は Codex に Sites を導入し、チームがアイデア、ドキュメント、計画を展開された内部ウェブサイトやアプリケーションに変換できるようにしました。認証機能と動的データに対応しており、まずビジネス/エンタープライズユーザー向けに提供されています(@OpenAI, @TheRohanVarma, @gdb)。
また OpenAI は、販売、データ分析、クリエイティブ制作、製品設計、公開株式のワークフローなど、役割固有の Codex プラグインを拡大し、62 のアプリと 110 のスキルにアクセス可能となりました(@OpenAI, @OpenAIDevs)。
GitHub の Copilot アプリおよびマイクロソフトのビルドにおけるエージェントネイティブなソフトウェア開発への推進は、当日のツール関連ニュースの中核を成しました(@pierceboggan, @lukehoban, @GHchangelog)。
Anthropic は Claude Platform の CLI をリリースし、@ClaudeDevs および @ClaudeDevs において、Claude Code の/fork コマンドを改善して、正確なコンテキストとプロンプトキャッシュを活用したバックグラウンドエージェントを実行可能にしました。
Nous は Hermes Desktop をローンチしました。これはローカル/ネイティブのデスクトップ版サー
原文を表示
Today was a big day, not least because we caught up on the state of GitHub vs Agents, and recorded a special pod with No Priors and Satya Nadella — at MS Build, Satya and Mustafa announced 7 new MAI models:
This is an impressive lineup, especially considering that the Microsoft-Inflection deal that set up MAI only happened 2 years ago, and that these are all from-scratch pretrains. MAI today is by no means an unqualified frontier lab, but it is a good tier 2 neolab with obvious incentives to support domain specific finetunes (as opposed to the frontier labs who have ~all killed finetuning).
The star of the show was the 100+ page MAI tech report, which the research community is giving glowing reviews:
You can catch up on all the rest of the announcement in the excellent Verge recap, and the tweet summaries below:
AI News for 06/1/2026-6/2/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: Microsoft Build recap, and new MAI model technical details
What happened
Microsoft used Build to position itself as both an AI platform company and a frontier-model lab, pairing broad product launches with unusually detailed disclosures about its new MAI model family.
Microsoft AI announced seven new MAI models spanning reasoning, code, image, speech transcription, and voice, led by MAI-Thinking-1, MAI-Code-1-Flash, MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2 according to @MicrosoftAI and @mustafasuleyman
The flagship reasoning model MAI-Thinking-1 was presented as Microsoft’s first reasoning model, built with clean data lineage and zero distillation from third-party models in posts from @mustafasuleyman, @baseten, @tuhinone, and @HannaHajishirzi
Microsoft released a 109-page technical report for MAI-Thinking-1, which drew strong positive reactions from technically oriented readers for its level of transparency, including @eliebakouch, @ethanCaballero, @nrehiew_, @yacinelearning, and @stochasticchasm
Microsoft also emphasized local AI and agent-native Windows: Build messaging highlighted secure execution layers for agents, a new Surface RTX Spark Dev Box, Windows AI access to the broader Windows GPU install base, and concept hardware such as Project Solara/Scout, summarized by @yusuf_i_mehdi, @TheTuringPost, @kimmonismus, and @kimmonismus
Build also included a major GitHub Copilot app push as the “desktop home for agent-native software development,” with canvases, cross-device continuity, and tighter GitHub agent workflows, from @pierceboggan, @lukehoban, and reactions from @techgirl1908
Microsoft introduced Web IQ, a new grounding/search API stack for AI agents, claiming the APIs already power “nearly all AI agents and chatbots in the industry today, including Copilot and ChatGPT,” via @JordiRib1
Satya Nadella framed Build as an ecosystem moment rather than a single-product launch, while Mustafa Suleyman framed it as the output of Microsoft’s internal “hill-climbing machine,” in @satyanadella, @mustafasuleyman, and reaction from @nrehiew_
MAI model family: disclosed facts and technical details
MAI-Thinking-1
Microsoft described MAI-Thinking-1 as a 35B active parameter MoE with a 256K context window in @mustafasuleyman
A separate summary from @scaling01 says the model is a 1T@35B parameter model, pre-trained on 30T tokens, and trained using 8192 GB200 GPUs; this appears to be a reading of the technical report rather than Microsoft marketing copy
@kimmonismus similarly summarized it as a mid-size MoE with 45B active params, but this conflicts with Mustafa’s own 35B active figure; the more authoritative figure in the tweet set is the official 35B active number
Microsoft claims 97% on AIME 2025 and 53% on SWE-Bench Pro, with blind human raters on Surge preferring it overall to Sonnet 4.6, from @mustafasuleyman and @asadovsky
Microsoft says the model is optimized on MAIA 200, with 30% better performance per dollar and 1.4x performance-per-watt gain versus GB200 when running MAI models end-to-end, per @mustafasuleyman
Microsoft and partners repeatedly stressed no third-party distillation, “clean data lineage,” and enterprise-controlled fine-tuning with “100% eyes-off” post-training data through Baseten, in @baseten, @tuhinone, and @MicrosoftAI
MAI-Code-1-Flash
Microsoft introduced MAI-Code-1-Flash as a fast coding model for VS Code and GitHub Copilot CLI, first announced by @pierceboggan and later highlighted by @mariorod1
Official Microsoft messaging via @mustafasuleyman says Code-1-Flash achieves 51% on SWE-Bench Pro despite having just 5B parameters, positioning it near Haiku-class size/cost
A competing summary from @scaling01 describes it as a 137B parameter MoE, 256K context, trained on 10T+ tokens, and “stronger and more efficient than Claude 4.5 Haiku.” That likely indicates 5B active parameters rather than total parameters; the tweets do not fully reconcile this distinction, but together imply small active footprint within a much larger MoE
Availability at launch was highlighted as GitHub Copilot / VS Code-first, per @scaling01 and @mariorod1
MAI-Image-2.5
Microsoft launched MAI-Image-2.5 and a Flash variant, claiming both reached #2 on leaderboards, with @mustafasuleyman saying they surpass Nano Banana 2 on image editing
Independent leaderboard accounts supported the high ranking: @arena reported #2 in Image Edit Arena with score 1401, +10 points over Nano Banana 2, Grok Imagine, and ChatGPT Image Latest HF
@arena further said MAI-Image-2.5 “advances the Pareto frontier,” meaning no model at its price tier scores higher on that benchmark
Distribution partners quickly followed, including @OpenRouter and @fal
MAI-Transcribe-1.5
@ArtificialAnlys reported MAI-Transcribe-1.5 as an unusually strong speed/accuracy point on the STT frontier: ~276x realtime, 2.4% AA-WER, #3 overall on its leaderboard
The model supports 43 languages, including English, French, Arabic, Japanese, and Chinese, and supports keyword biasing for rarer terms such as names and medical terminology, per @ArtificialAnlys
Pricing was reported as $6 per 1,000 minutes of audio via Microsoft Foundry in @ArtificialAnlys
OpenRouter also listed the model among the three MAI launches it brought live the same day in @OpenRouter
MAI-Voice-2
MAI-Voice-2 appears in Microsoft’s “seven models” umbrella and in OpenRouter’s availability post at @OpenRouter
The tweet set contains little technical detail on Voice-2 itself beyond launch/availability
Technical-report details that mattered to researchers
Why the report stood out
The dominant technical reaction was that Microsoft released an unusually detailed frontier-model report: @eliebakouch called it “one of the most transparent for a model at this scale,” @nrehiew_ said it “could really serve as an updated textbook for LLM training today,” and @stochasticchasm called it a “gold mine”
Multiple readers highlighted that the report disclosed pipeline details, scaling ladder methodology, data curation, infra metrics, and MFU numbers; this level of specificity is what drew praise from @ethanCaballero, @eliebakouch, and @nrehiew_
Pretraining and data
A major technical claim repeated across commentary is that MAI-Thinking-1 used no synthetic data and no distillation, not only in post-training but throughout the disclosed pipeline, from @eliebakouch, @stochasticchasm, and @HannaHajishirzi
@eliebakouch says the report explicitly notes data from Common Crawl plus private sources, with targeted sub-pipelines for different domains, heavy extraction/dedup work, and an intentional choice of no synthetic data
The report’s internal private NLL set used for scaling decisions was summarized by @eliebakouch as:
50% code
17.5% STEM
17.5% math
10% general knowledge
5% multilingual
@eliebakouch says architecture promotion in the scaling ladder was based on an Efficiency Gain (EG) metric: how much extra compute the baseline would need to match the candidate’s loss
The same thread notes ablations at roughly 100/200 tokens per parameter, described as around “Chinchilla optimal” for the setup, while also remarking this differs from dense-model heuristics due to MoE structure in @eliebakouch
Post-training / RL
The most discussed technical choice was that Microsoft appears to have started RL from a checkpoint with no prior reasoning exposure, which several readers found notable. @stochasticchasm called this a “very interesting decision,” while @stochasticchasm reacted to graphs suggesting a jump from <20% AIME25 to >95%
@HannaHajishirzi described the “climbing from scratch” recipe as simple recipes, rigorous science, self-distillation, patience, and great infra
@soldni characterized the process as “climbing with no distillation, like the big boys do”
Some independent readers inferred from the report that synth data remains very valuable for agentic performance in the broader field, even if Microsoft deliberately avoided it here; see @stochasticchasm
Data curation / judges / DSPy GEPA
A detail that got substantial attention from the DSPy/late-interaction crowd: Microsoft reportedly used GEPA / DSPy-optimized LLM judges in pretraining data curation and quality scoring
This was highlighted by @bj2rn, @LakshyAAAgrawal, and @lateinteraction
Infra / utilization / hardware co-design
Microsoft reportedly disclosed exact MFU across iterations, which multiple readers said is rarely shared at this scale, per @eliebakouch
@scaling01 summarized the run as using 8192 GB200 GPUs
@eliebakouch singled out a reported ~40% higher throughput per watt-type figure as “pretty impressive and bullish on microsoft chips,” though this may refer to rack-level budget or serving configuration and was not fully unpacked in-tweet
Microsoft’s official framing connected model design to MAIA 200 custom silicon and emphasized better performance-per-dollar and performance-per-watt vs NVIDIA GB200 in @mustafasuleyman
Build’s broader Windows/local-AI narrative also centered on hardware specifics such as:
1 trillion parameters running locally on DGX Station
128GB unified memory
110 TOPS AI performance
20 CPU cores
70+ PowerToys utilities from @TheTuringPost
Reactions also pointed to local runs of large models, e.g. @kimmonismus on RTX Spark running a 120B parameter model locally
Build product/platform recap beyond the models
GitHub Copilot app and agent-native development
GitHub unveiled the GitHub Copilot app, pitched as a desktop surface for agent-native software development by @pierceboggan
Key themes included:
canvases for bidirectional work between users and agents, per @Techmeme
continuity across CLI, mobile, web, local, and cloud, per @lukehoban
a growing role for GitHub as the center of agent workflows, reflected in @techgirl1908 and @OrenMe
Copilot CLI also got an experimental terminal UI with tabs, built-in feedback/rubber duck, prompt scheduling, and voice input, per @GHchangelog
Windows as an agent runtime
Microsoft’s Windows org framed Build around “faster developer execution, a secure execution layer for agents, and unmetered intelligence that runs locally on device,” per @yusuf_i_mehdi
Several posts stressed that Microsoft wants Windows to be the trusted execution platform for agents, not just Azure
@TheTuringPost described Project Solara as a platform for agent-first devices, with concepts including:
a desktop AI companion
a wearable badge with cameras, microphones, sensors, and secure authentication
@kimmonismus saw these as handheld/desktop devices for controlling agents and compared them to expectations people had for standalone OpenAI hardware
@kimmonismus separately highlighted Microsoft Scout as an “always-on personal agent for work”
Web IQ and search for agents
@JordiRib1 announced Microsoft Web IQ as a suite of AI-native grounding APIs for web pages, news, images, and videos
His framing is important context: classic search engines were built for humans, but Microsoft believes future search demand will come from agents, potentially 1000x more queries than human search traffic
He claimed Web IQ was re-architected from Bing’s stack for quality, latency, and token efficiency, and that it already powers major chatbots including Copilot and ChatGPT
Foundry and open-model distribution
@jeffboudier said Satya cited 11,000+ models available in Microsoft Foundry, of which 10,928 come from Hugging Face
This supports Microsoft’s parallel identity at Build: both a first-party model builder and a large multi-model hosting/distribution platform
Build messaging around datacenters and compute
Several observers noted Build discussion around data center expansion, community backlash, and Microsoft’s argument that AI infra can expand without raising electricity costs to local communities; see @kimmonismus and @kimmonismus
@scaling01 highlighted Mustafa saying AI compute will grow 1000x in the next 3 years, taking today’s rough 5e27 FLOPs frontier scale to 5e30 FLOPs by 2029
@mustafasuleyman summarized the company’s philosophical theme as “Humanist superintelligence”
Facts vs. opinions
Factual claims in the tweet set
Microsoft launched seven new MAI models at Build: @MicrosoftAI
Official metrics for MAI-Thinking-1: 35B active MoE, 256K context, 97% AIME 2025, 53% SWE-Bench Pro, and blind human preference over Sonnet 4.6: @mustafasuleyman
Official metrics for MAI-Code-1-Flash: 51% SWE-Bench Pro, 5B parameters as stated in tweet copy: @mustafasuleyman
MAI-Image-2.5 ranking claims were independently echoed by @arena
MAI-Transcribe-1.5 speed/accuracy details came from independent benchmark account @ArtificialAnlys
Microsoft released a 109-page technical report: @eliebakouch
Opinions / interpretations
“Microsoft is training serious models now?” from @teortaxesTex is an interpretive reaction to the model/report quality, not a standalone fact
Claims that the report is “one of the most transparent” or “an updated textbook” are opinions from @eliebakouch and @nrehiew_, albeit shared by many readers
@kimmonismus and @TheTuringPost framed Build as a strategic shift from cloud-only AI toward local reasoning/agents; that is analysis rather than official wording
Posts claiming Microsoft “leaked” Anthropic Mythos FLOPs, including @swyx and @scaling01, are speculative interpretations of a slide, later contested by the same cluster of commenters
Different opinions and perspectives
Supportive views
Technical readers were broadly impressed by the report’s transparency and Microsoft’s willingness to publish details usually withheld at this scale: @eliebakouch, @nrehiew_, @ethanCaballero, @stochasticchasm
Some saw MAI-Thinking-1 as proof Microsoft is becoming a genuine frontier lab rather than just a model reseller or application layer, e.g. @teortaxesTex, @echen, @NandoDF
Enterprise/platform supporters liked the clean-data-lineage, fine-tunable, eyes-off post-training data story, especially Baseten/Microsoft’s positioning around ownership and control: @baseten, @tuhinone
Neutral / analytical views
Several posts focused on reading and unpacking the report rather than cheering the launch, especially @stochasticchasm, @nrehiew_, and @eliebakouch
Some commentators were careful on benchmark interpretation. @kimmonismus noted Microsoft appeared to compare to Sonnet 4.6 generally, with Opus-level comparability only on SWE Pro
@iScienceLuvr specifically appreciated reporting on health benchmarks such as HealthBench Professional and MedXpertQA rather than only coding/math
Skeptical / opposing views
A subset questioned whether all numbers and comparisons were being interpreted correctly, especially around active params and external-model comparisons
The most visible skepticism concerned the apparent Mythos FLOP “leak”. @iScienceLuvr suggested it was probably just an estimate, not a leak; @scaling01 later argued the original 6.1e27 FLOP figure was unrealistic and supplied a lower alternative estimate before posting a correction in @scaling01
There was also implicit skepticism in the field about whether zero synth / zero distillation is the right long-term recipe for best agentic performance, as noted by readers emphasizing synth-data deltas elsewhere, e.g. @stochasticchasm
Context: why this matters
Build’s announcements matter because they suggest Microsoft is no longer content with being only:
Azure/OpenAI’s cloud host
GitHub’s developer surface
Copilot’s application shell
It is also trying to be a first-party frontier model developer with its own model family, silicon stack, and post-training platform
The clean lineage / no distillation emphasis is strategically significant. It addresses enterprise concerns around IP provenance, future controllability, and dependence on external labs
The local AI emphasis matters because Microsoft is tying AI strategy to Windows and device distribution, not just to Azure. Build messaging repeatedly pushed the idea that reasoning models, planners, and agents can increasingly run on-device, not only in the cloud: @TheTuringPost, @yusuf_i_mehdi
The 109-page report matters because frontier-model transparency has generally been shrinking, especially around data, infra, and training methodology. Multiple researchers explicitly noted the disclosure level is uncommon at this scale: @eliebakouch, @nrehiew_
The Build recap also showed Microsoft trying to integrate all layers of the stack:
models: MAI family
chips: MAIA 200
cloud: Azure + Foundry
OS: Windows agent runtime
developer UX: Copilot app / VS Code / CLI
retrieval/grounding: Web IQ
hardware form factors: Solara / Scout concepts
This combination is why several observers described the event less as a normal dev conference and more as a coordinated move toward an agent platform spanning cloud, edge, OS, and custom models, e.g. @satyanadella, @mustafasuleyman, and @TheTuringPost
The “Mythos FLOPs leak” mini-story
During/after Build, some users claimed a Microsoft slide inadvertently revealed training compute for Anthropic’s rumored Claude Mythos, with @swyx asking if Mustafa had leaked the FLOP count
@scaling01 estimated the slide implied 6.1e27 FLOPs with a confidence interval based on pixel measurement, while @kimmonismus noted that would be around Gemini 3.1 Pro-scale compute
That interpretation was subsequently challenged by @iScienceLuvr, who argued it was probably an estimate, and then by @scaling01, who posted a lower-range model-based estimate of 3.37e26 to 1.46e27 FLOPs and later said the original numbers were bogus in @scaling01
The episode is useful mostly as context: Build’s compute/scaling messaging was detailed enough that people started trying to infer competitor training budgets from presentation materials
Developer tools, agents, and coding workflows
OpenAI launched Sites in Codex, letting teams turn ideas/docs/plans into deployed internal websites/apps with auth and dynamic data, first for business/enterprise users, in @OpenAI, @TheRohanVarma, and @gdb
OpenAI also expanded role-specific Codex plugins across sales, data analytics, creative production, product design, and public equity workflows, with access to 62 apps and 110 skills, from @OpenAI and @OpenAIDevs
GitHub’s Copilot app and Microsoft’s Build push around agent-native software development were central to the day’s tooling news: @pierceboggan, @lukehoban, @GHchangelog
Anthropic shipped a CLI for Claude Platform and upgraded Claude Code’s /fork to run a background agent with exact context + prompt cache, in @ClaudeDevs and @ClaudeDevs
Nous launched Hermes Desktop, a local/native desktop sur
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み