Parcae:安定したループモデルで少ないパラメータでより多くのことを実現
Together AIは、パラメータ数を増やすのではなく反復処理を強化する「Parcae」と呼ばれる安定したループ型言語モデルアーキテクチャを発表し、Transformerの2倍の品質を低い計算コストで実現する新基準を示した。
キーポイント
Parcaeアーキテクチャの発表
Together AIは、ループ型言語モデル(Looped Language Models)のための安定したアーキテクチャ「Parcae」を開発し、従来のTransformerモデルの2倍のパラメータ数に匹敵する品質を達成したと発表した。
スケーリング法則の再定義
従来のFLOPsやパラメータ数、データ量によるスケーリング法則とは異なり、反復回数を増やすことで品質をスケールさせる新たな効率の frontier(最前線)を開拓した。
エッジデバイスへの適用可能性
このアプローチは、メモリ制約のあるオンデバイス(エッジ)モデルのトレーニングにおいて効率的な選択肢となり、推論コストの削減と性能向上の両立に寄与する。
重要な引用
We present Parcae, one of the first stable architectures for looped language models, achieving the quality of a Transformer twice the size with clean, predictable training.
Parcae creates a new medium to scale quality by increasing recurrence rather than purely scaling data, opening up an efficient frontier for training memory-constrained on-device models.
影響分析・編集コメントを表示
影響分析
Parcaeの発表は、大規模言語モデルのコスト効率化とエッジコンピューティングへの展開において重要な進展を示しています。パラメータ数の増加に頼らないスケーリング手法は、ハードウェア制約のある環境でのAI実装を促進し、より広範なデバイスでの高度なAI利用を可能にする可能性があります。
編集コメント
Together AIによるParcaeの発表は、モデルのスケーリングにおける「パラメータ数」から「反復処理(recurrence)」へのパラダイムシフトを示唆しており、特にリソース制約のあるエッジデバイス向けAIの実用化において重要な指針となる。
 imageimage要約
imageimage要約
私たちは、ループ型言語モデル(looped language models)のための最初の安定したアーキテクチャの一つであるParcaeを発表します。これは、クリーンで予測可能なトレーニングにより、Transformer の2 倍のサイズに匹敵する品質を実現しています。Parcae は、純粋なデータのスケールアップではなく、再帰(recurrence)を増やすことで品質をスケーリングするための新たな手段を生み出し、メモリ制約のあるオンデバイスモデルのトレーニングにおける効率的なフロンティアを開拓します。
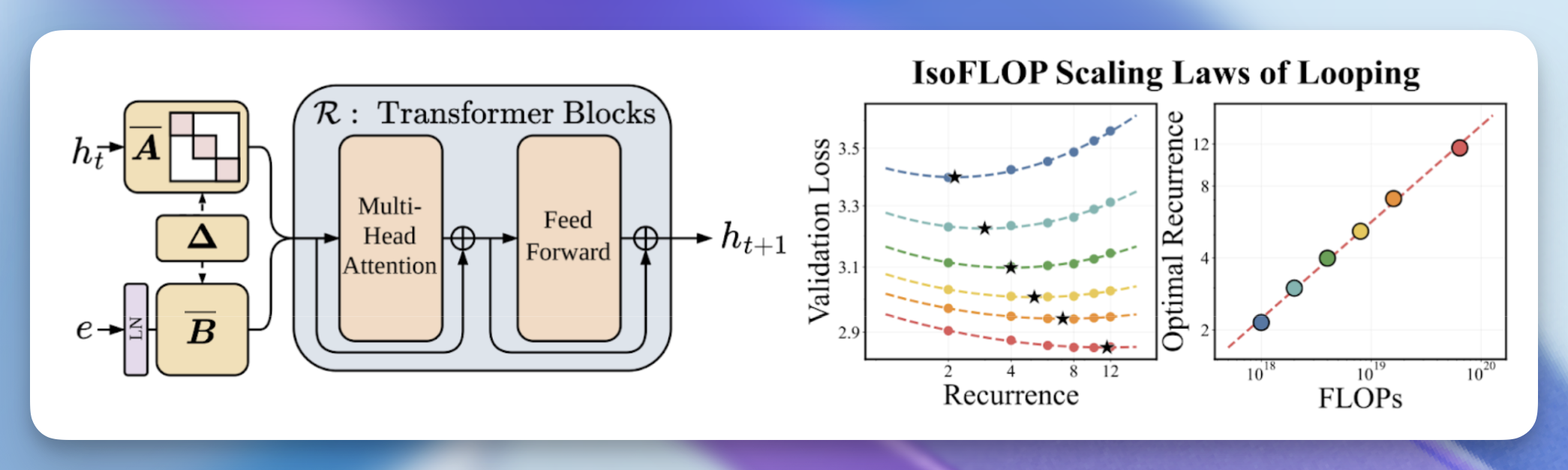
パラメータを最大限に活用する
従来のスケーリング法則(scaling laws)は、最高のパフォーマンスを達成するには FLOPs をスケールアップする必要があり、そのためにはパラメータ数やデータを増やす必要があると示しています。しかし、モデルがエッジデバイスへ移行し、推論コストが急騰する中で、私たちは問います。メモリフットプリントを増大させることなく、品質をスケーリングすることは可能でしょうか?
そこで私たちは、活性化値(activations)を同じ層に複数回通過させることで計算量を増やすループ型アーキテクチャ(looped architectures)のモデルを探求してきました。これらは有望である一方で、トレーニングが不安定という課題がありました。私たちはこの問題に直接取り組み、以下の特性を持つ安定したループ型アーキテクチャであるParcaeを導入します:
- 先行するループモデルよりも優れている:Parcae は、以前の大型スケール向けループレシピと比較して、検証時のパープレキシティを最大 6.3% 低下させます。
- 期待以上の性能を発揮:当社の 770M パラメータの Parcae は、同じデータで訓練された 1.3B パラメータのトランスフォーマー(Transformer)と同等の品質を達成し、約半分のパラメータ数で同様のパフォーマンスを実現しています。
- 予測可能なスケーリング:ループに関する最初のスケーリング法則(Scaling laws)を確立し、計算最適化された訓練には、ループ回数とデータ量を同時に増加させる必要があることを発見しました。
ループモデルは魅力的だが、実用では訓練が困難
モデルがエッジデバイスへ移行し、推論デプロイメントが計算リソースのより大きな部分を担うにつれ、パラメータ数が増加することなくモデル品質をスケーリングする関心が高まっています。私たちが特に注目している仕組みの一つに層ループ(layer looping)があり、初期の研究では、より大型の固定深さアーキテクチャと同等の品質を持つループモデルが訓練されています。
バニラのトランスフォーマーをループモデルに変換するには、先行研究に従い、その層を 3 つの機能ブロックに分割します:プレリュード(prelude)、リカレント(recurrent)、そしてコダ(coda)です。順方向パスは以下の 3 つの段階で動作します。
- エンベディング:プレリュード(序奏)は、入力を潜在状態に変換します。
- 再帰処理:再帰ブロックは、ループ回数分だけ隠れ状態を反復的に更新します。入力の影響を維持するために、各ループに潜状が注入されます。通常は加算 [1] () または投影との結合 [2] () を用います。
- 出力:コダ(終奏)は最終的な潜在状態を処理して、モデルの出力を生成します。

残念ながら、ループモデルのトレーニングは頭痛の種です [[2]](#ref-2)[[3]](#ref-3)[[4]](#ref-4)。私たちが個人的に経験したところ、残差状態の爆発と損失の急上昇に苦しむことがわかりました。さらに厄介なのは、再帰ブロックが複数のバニラ Transformer ブロックで構成されているため、不安定さの原因を推論することが難しい点です。
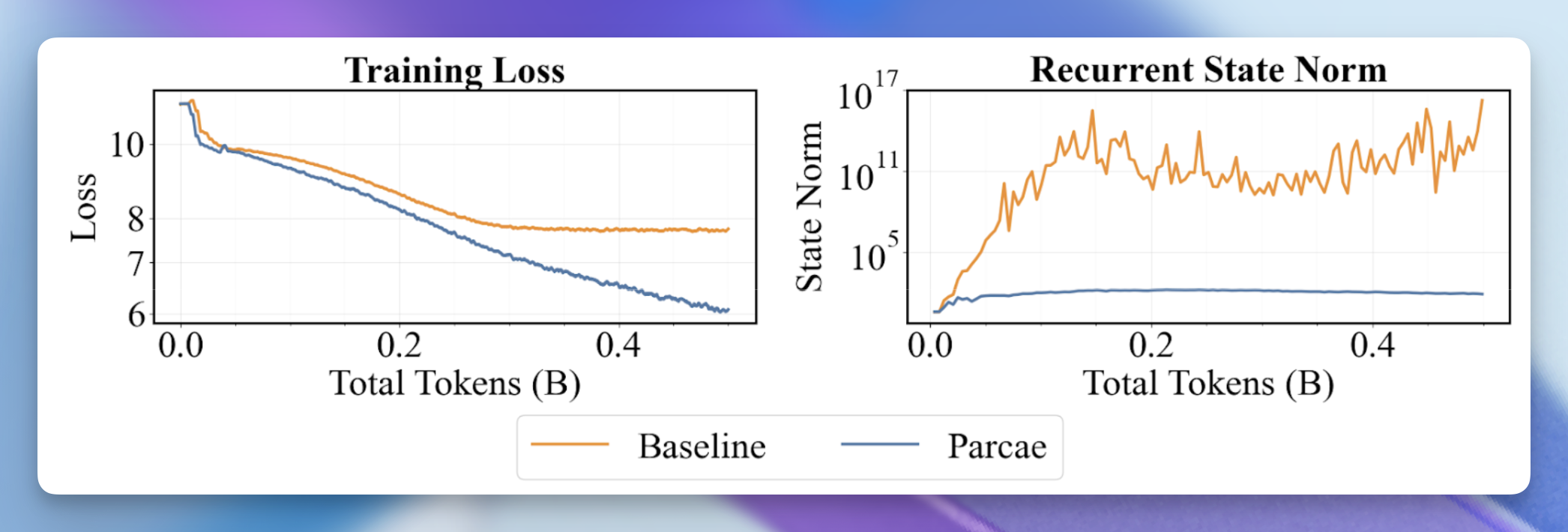
ループの不安定性を理解する
不安定さは厄介な敵ですが、単純な線形フレームワークが不安定さの主要な原因を捉えていることを観察しました。具体的には、残差に関する非線形時変動的システムとしてループを再定義し、その更新ルールは以下の通りです:
ここで、注入(injection)が行われ、はリジュードストリームへのトランスフォーマーブロックの寄与を表します。サブクォードラティックなシーケンスミキシングに熱中している方へ、非線形項を無視すれば、結果として得られるシステムは、モデル深さ全体にわたるリジュード状態に対する離散線形時不変(LTI)動力学系となります。
何が素晴らしいかといえば、離散 LTI システムにおいて、その安定性と収束性はの固有値によって決定される点です。具体的には、スペクトルノム(すなわちの絶対値最大の固有値)を用いて安定性が分類され、安定(収束する)システムは であり、不安定(発散する)システムは です。
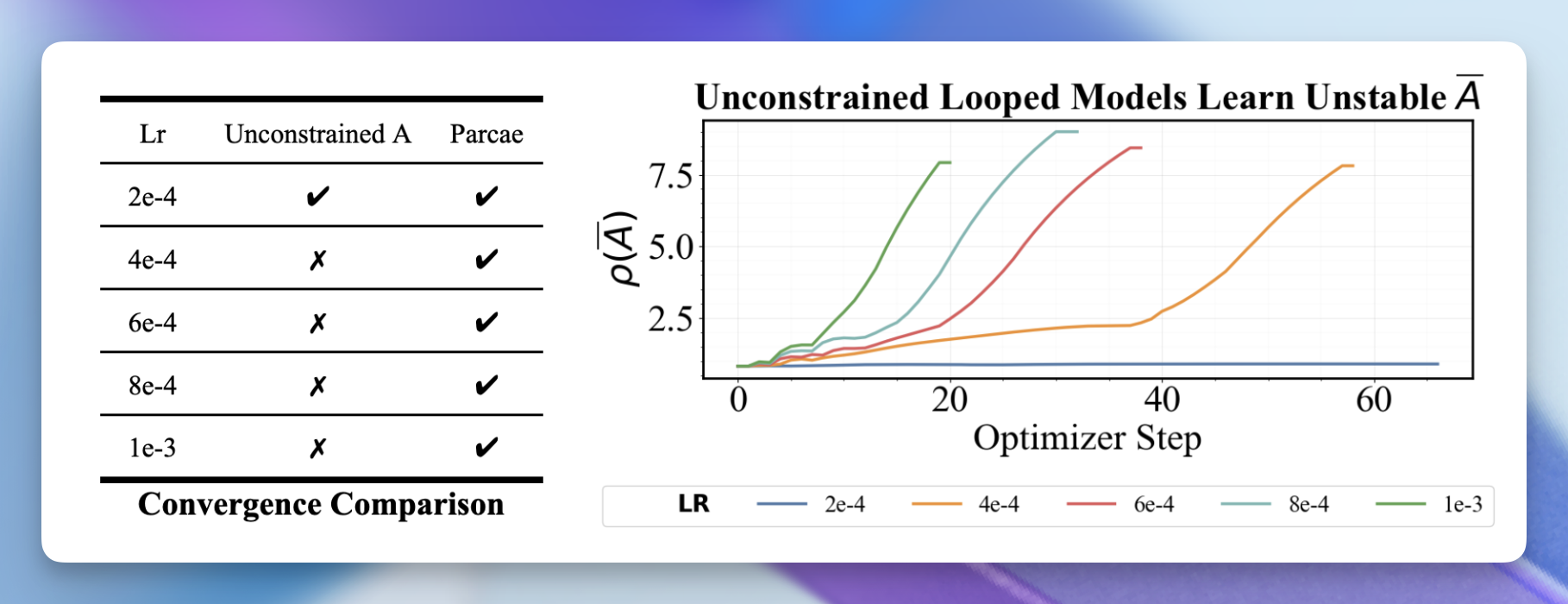
この分析はループの非線形性(例えばアテンションや MLP ユニット)を迂回するものですが、上記の表と図は、この分析が経験的に重要であることを裏付けています。発散する実行ではスペクトル半径 が学習され、収束する実行では が維持されます。Parcae で LTI 条件を維持することで、ループモデルはハイパーパラメータ選択に対して大幅に頑健になります。
Parcae: 安定した、手間のかからないループドモデル
では、どのようにして安定化させるのでしょうか?私たちは上記のセクションで観察された安定性条件を構築によって明示的に維持する新しいループドモデル「Parcae」を設計しました。具体的には、入力注入パラメータを連続的な定式化を用いてパラメータ化し、ZOH(ゼロ次ホールド)およびオイラー法則(すなわち、それぞれ $x_{k+1} = x_k + h f(x_k)$ および $u_{k+1} = u_k$)で離散化します。ここで用いる行列は学習可能なパラメータです。その後、この行列を負の対角行列として制約し、ベクトルの各要素に負の符号を強制する関数と、学習可能なベクトルを用います。これにより、安定性が保証されます!
では、すべての課題が解決され、ループドモデルは安定化したのでしょうか?残念ながら、Parcae をクリーンにトレーニングするには、まだいくつかの小さな工夫が必要でした。興味のある方は、私たちの論文 paper をご覧ください。
言語モデリングへ戻る:Parcae のスケーリング
Parcae はより信頼性高くトレーニングできるだけでなく、従来の RDM(Recurrent Diffusion Models)と比較して、より高品質なモデルを生成することも発見しました。RDM [[2]](#ref-2) という先行するループドモデルのセットアップをそのまま用いて、パラメータ数とデータ量に一致させた RDM と比較テストを行った結果、Parcae は検証時のパープレキシティ(Val. PPL)を最大 6.3% 削減することがわかりました。
| Params & Model | Val. PPL (↓) |
|---|---|
| 100M Scale | |
| └ RDM | 14.23 |
| └ Parcae | 13.59 |
| 350M Scale | |
| └ RDM | 10.76 |
| └ Parcae | 10.09 |
非常に強力な Transformer ベースラインを RDM(Recurrent Diffusion Model)にリトロフィットする際、ハイパーパラメータの調整を行わないという条件下で、Parcae が RDM において頑健であることが判明しました。一方、RDM そのものは単に発散してしまいました。
| Params & Model | Val. Loss (↓) | Core (↑) | Core-Extended (↑) |
|---|---|---|---|
| RDM | Divergent | Divergent | Divergent |
| + Parcae Constrained A | 2.97 | 13.2 ± 0.2 | 9.1 ± 0.5 |
| + All Parcae Tricks | 2.95 | 14.0 ± 0.2 | 9.7 ± 0.3 |
また、Parcae を標準的な固定深さの Transformer のドロップイン代替として使用しました。nanochat に着想を得た設定を用いて、FineWeb-Edu データセット上で 1.3B パラメータまでの一連の言語モデルを訓練しました。その結果、Parcae はパラメータ数とデータ量が一致するすべての Transformer を上回る性能を示し、770M の Parcae モデルは、サイズが約2倍の Transformer と同等のダウンストリーム品質をほぼ達成することができました。
| Params & Model | Val. PPL (↓) | Core (↑) | Core-Extended (↑) |
|---|---|---|---|
| 140M Scale | |||
| └ Transformer | 21.48 | 13.00 ± 0.15 | 8.80 ± 0.21 |
| └ Parcae | 19.06 | 14.04 ± 0.20 | 9.67 ± 0.28 |
| 370M Scale |
| └ Transformer | 15.79 | 17.46 ± 0.03 | 11.71 ± 0.22
└ Parcae
14.49
20.00 ± 0.06
12.75 ± 0.31
770M Scale
└ Transformer
13.08
22.42 ± 0.20
14.20 ± 0.63
└ Parcae
12.49
25.07 ± 0.33
15.19 ± 0.43
1.3B Scale
└ Transformer
11.95
25.45 ± 0.08
15.90 ± 0.23
└ Parcae
11.42
28.44 ± 0.28
17.08 ± 0.09
ループさせるか、させないか
しかし、ループ処理は実際に FLOP(浮動小数点演算数)効率的なのでしょうか?これを探るため、固定されたパラメータ数と FLOP バジェットの下で、トレーニング中の平均再帰回数をデータ量とトレードオフする設定を検討します。例えば、平均再帰回数を増やせば、FLOP バジェットを一定に保つためにトレーニングデータの量を減らすことになります。
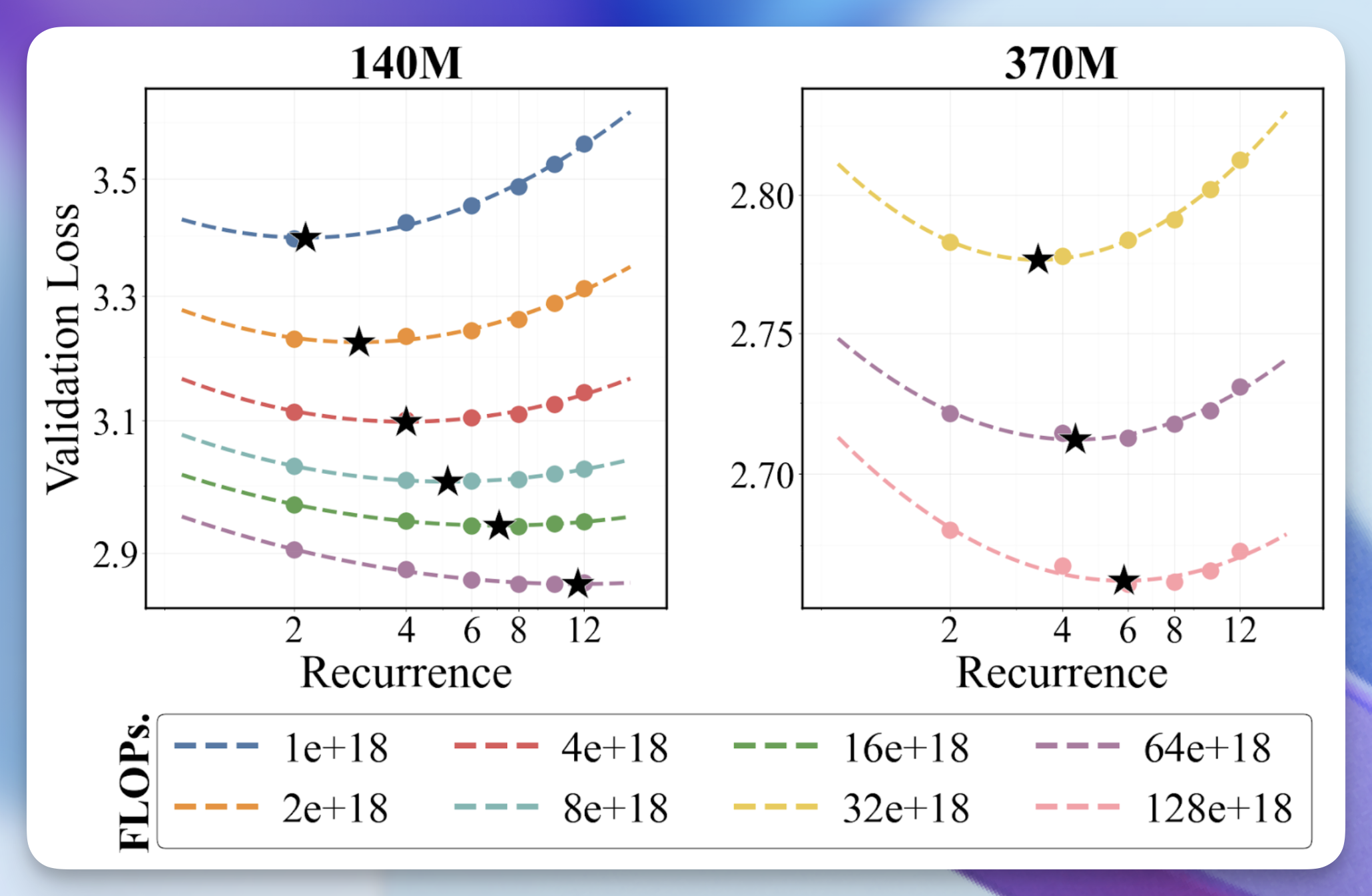
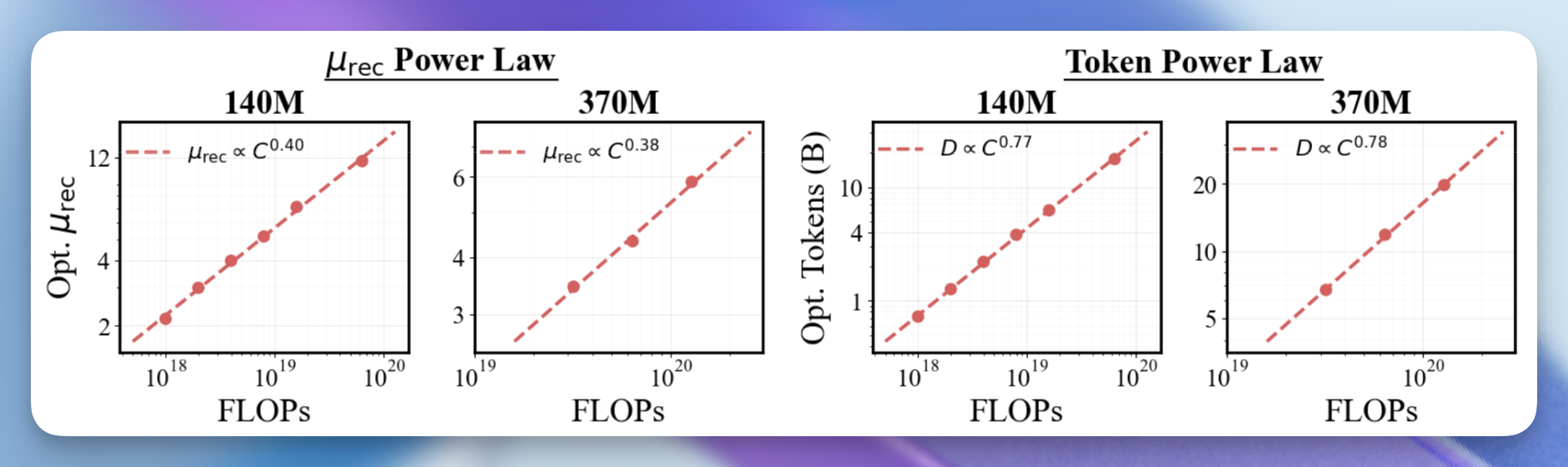
2 つのスケールにおいて、トレーニング中に使用する平均再帰回数を増やし、それに比例してトークン数を減らすことで、低い再帰回数でより多くのデータを用いてトレーニングする場合よりも、検証損失が低くなることを発見しました。さらに興味深いのは、各 FLOP レベルで最適な値とトークン予算を抽出するために放物線近似(パラボリックフィット)を使用すると、両者が一貫した指数を持つべき法則に従っていることが明らかになったことです。
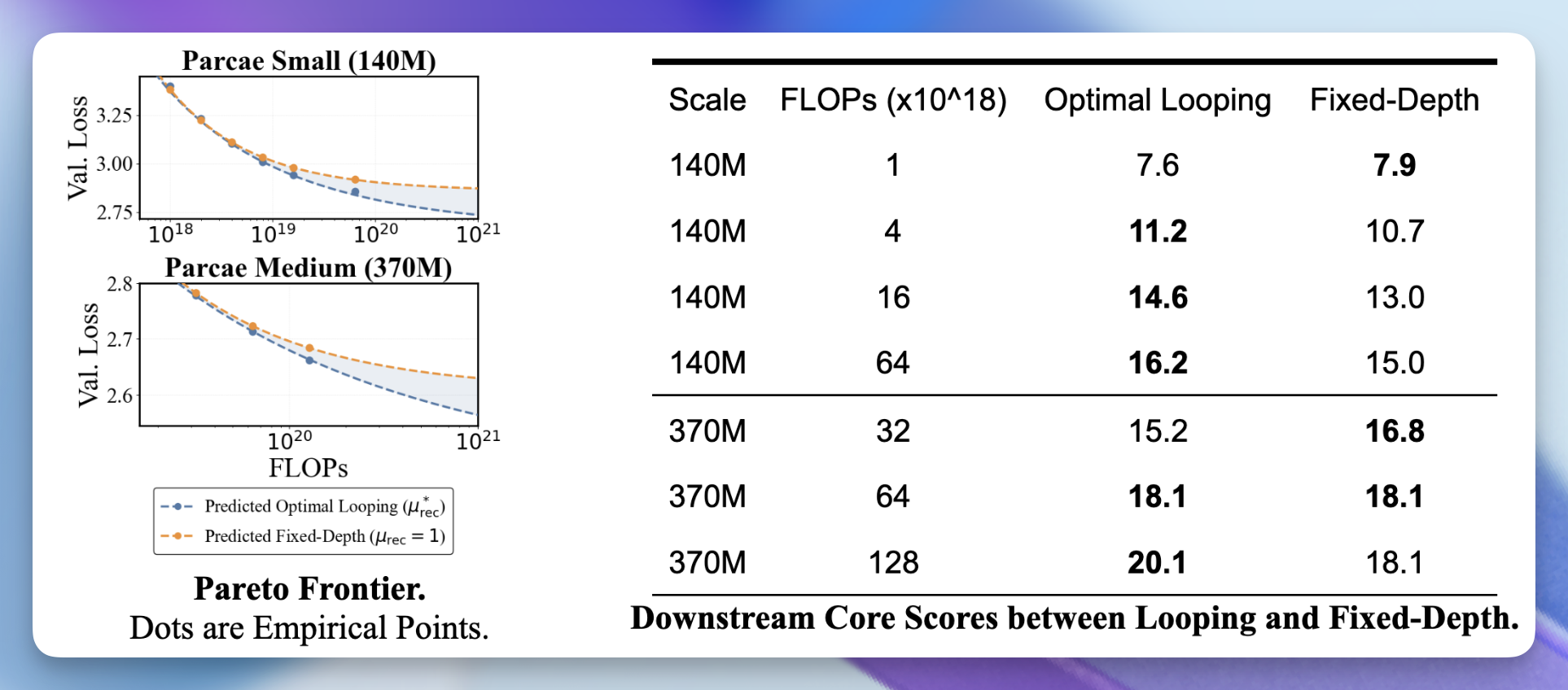
はい、はい。しかし、固定深さモデルを上回れるのでしょうか? 最適な再帰スケーリング則を用いて、固定深さの Parcae モデル(すなわち、パラメータ数が一定のもの)や、スケーリング則に基づく最適な平均再帰予測に従ったループ型 Parcae モデルと比較しました。その結果、ループ化を行うことで検証損失におけるより厳格なパレートフロンティアが得られることが分かりました(下の図)。これは、下流タスクの品質向上につながります(下の表)。
次のステップと Parcae の試行
パラメータ効率をどこまで高められるかについて、私たちは非常に興奮しています。推論時のメモリオーバーヘッドのコストが増大する中、レイヤーのループ化などのパラメータ再利用手法にはまだ多くの探求余地があると考えています。このプロセスを加速するために、トレーニングコード と モデル を公開します。私たちはまだ終わっていません。ループ型モデルをさらに進化させるための新しいアイデアが山ほどありますので、今後の発表にご期待ください!
ご質問がある場合や、Parcae の次なる展開について一緒に取り組みたい場合は、Hayden Prairie まで hprairie@ucsd.edu までご連絡ください。

PaRCaeという名前は、ローマの運命の三女神へのオマージュです。ノナ(Prelude ブロック)は生命の計算スレッドを初期化し、デキマ(Recurrent ブロック)はモデルの深さを通じてスレッドを測定・進化させ、モルタ(Coda ブロック)はスレッドを切断して最終出力を生成することでシーケンスを終結させます。
謝辞
本実験のために計算リソースを提供し、協力してくださった Together AI に感謝いたします。また、本ブログ記事に対する有益なフィードバックをくださった Austin Silveria 氏と Jonah Yi 氏にも深く感謝申し上げます。
参考文献
- Liu Yang, Kangwook Lee, Robert D. Nowak, および Dimitris Papailiopoulos. "Looped Transformers Are Better at Learning Learning Algorithms"。In The Twelfth International Conference on Learning Representations, 2024. ↩
- Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, および Tom Goldstein. "Scaling Up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach"。In The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. ↩
- Ahmadreza Jeddi, Marco Ciccone, および Babak Taati. "LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation"。In The Fourteenth International Conference on Learning Representations, 2026. ↩
- ショーン・マクリーシュ、アン・リー、ジョン・キルヒェンバウアー、デイアル・シンク・カルラ、ブライアン・R・バルトドソン、ブハヤ・カイルクフーラ、アヴィ・シュワルツシルト、ジョナス・ガイピン、トム・ゴールドスタイン、およびミカ・ゴールドブラム。事前学習済み言語モデルに再帰的結合(Retrofitted Recurrence)を適用してより深く思考させる方法。arXiv プリプリント arXiv:2511.07384, 2025。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文ここに挿入:ローラム・イプサム・ドロール・シット・アメット
- 箇条書き項目ここに挿入:ローラム・イプサム
- 箇条書き項目ここに挿入:ローラム・イプサム
- 箇条書き項目ここに挿入:ローラム・イプサム
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- ロレム・イプサム ドロール シット アメト、コンセクテトゥール アディピスシン エリート、セド ドゥエイスム テンポル インシディディット。
- ロレム・イプサム ドロール シット アメト、コンセクテトゥール アディピスシン エリート、セド ドゥエイスム テンポル インシディディット。
- ロレム・イプサム ドロール シット アメト、コンセクテトゥール アディピスシン エリート、セド ドゥエイスム テンポル インシディディット。
リストアイテム #1
ロレム・イプサム ドロール シット アメト、コンセクテトゥール アディピスシン エリート、セド ドゥエイスム テンポル インシディディット ウト ラボレ エト ドローレ マグナアリクア。ウト エニム アド ミニム ヴェニアム、キス ノストル エクセルチタティオン ウルマコウ ラボリス ニシィ ウト アリキップ エク エア コモダコンセクアトゥ。
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイされたエンジニアリング時間 3 時間無料。(フォワードデプロイ:forward-deployed)
資金調達:500 万ドル未満
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイされたエンジニアリング時間 3 時間無料。(フォワードデプロイ:forward-deployed)
資金調達:500 万ドル未満
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイされたエンジニアリング時間 3 時間無料。(フォワードデプロイ:forward-deployed)
資金調達:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* および *</answer> タグ内に配置してください。推論を行う際は、アラビア語でのみ回答し、他の言語は使用しないでください。以下の質問:
ナタリアは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数を販売しました。ナタリアが 4 月と 5 月に合計で販売したクリップの数は何ですか?
XX
タイトル(Title)
本文コピーはここにロレム・イプサム ドロール シット アメト(Body copy goes here lorem ipsum dolor sit amet)
XX
タイトル(Title)
本文コピーはここにロレム・イプサム ドロール シット アメト(Body copy goes here lorem ipsum dolor sit amet)
XX
タイトル
本文はここにローレン・イプサム・ドロール・シット・アメントと続きます。
8 秒
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
DeepSeek R1
8 秒
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
8 秒
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文はここにローレン・イプサム・ドロール・シット・アメントと続きます。
- 箇条書き項目はここにローレン・イプサムと続きます
- 箇条書き項目はここにローレン・イプサムと続きます
- 箇条書き項目はここにローレン・イプサムと続きます
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リストアイテム #1
- ロレム イプサム ドロール シット アメト、コンセクテトゥル アディピスシン エリート、セド ドゥイウスモウ テンポル インシディディット。
- ロレム イプサム ドロール シット アメト、コンセクテトゥル アディピスシン エリート、セド ドゥイウスモウ テンポル インシディディット。
- ロレム イプサム ドロール シット アメト、コンセクテトゥル アディピスシン エリート、セド ドゥイウスモウ テンポル インシディディット。
リストアイテム #1
ロレム イプサム ドロール シット アメト、コンセクテトゥル アディピスシン エリート、セド ドゥイウスモウ テンポル インシディディット ウト ラボレ エト ドローレ マグナアリクア。ウト エニム アド ミニム ヴェニアム、キス ノストル エクセルチタティオン ウルマコウ ラボリス ニシィ ウト アリキップ エク エア コモドゥオ コンセクワット。
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイエンジニアリング時間3時間無料。(フォワードデプロイエンジニアリング:forward-deployed engineering)
資金調達額:500万ドル未満
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイエンジニアリング時間3時間無料。(フォワードデプロイエンジニアリング:forward-deployed engineering)
資金調達額:500万ドル未満
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*(プラットフォームクレジット:platform credits)
- フォワードデプロイエンジニアリング時間3時間無料。(フォワードデプロイエンジニアリング:forward-deployed engineering)
資金調達額:500万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に配置してください。推論を行う際は、アラビア語でのみ回答し、他の言語は使用できません。以下の質問:
ナタリアは4月に友人48人にクリップを販売し、5月にはその半分の数を販売しました。ナタリアが4月と5月の合計で販売したクリップの数は何ですか?
XX
タイトル(Title)
本文コピーはここにロレム イプサム ドロール シット アメト(Body copy goes here lorem ipsum dolor sit amet)
XX
タイトル(Title)
本文コピーはここにロレム イプサム ドロール シット アメト(Body copy goes here lorem ipsum dolor sit amet)
XX
タイトル
本文には Lorem ipsum dolor sit amet というテキストが入ります。
原文を表示
Summary
We present Parcae, one of the first stable architectures for looped language models, achieving the quality of a Transformer twice the size with clean, predictable training. Parcae creates a new medium to scale quality by increasing recurrence rather than purely scaling data, opening up an efficient frontier for training memory-constrained on-device models.
Getting the most out of your parameters
Traditional scaling laws tell us that to achieve the best performance, we need to scale FLOPs, often with more parameters or data. But as models move to the edge and inference costs skyrocket, we wonder: Can we scale quality without inflating memory footprint?
To that end, we’ve been exploring looped architectures, models that increase compute by passing activations through the same layers multiple times. While promising, these models have been unstable to train. We tackle this issue directly and introduce Parcae, a stable looped architecture that:
- Is better than prior looped models: Parcae achieves up to 6.3% lower validation perplexity than previous large-scale looped recipes.
- Punches above its weight: Our 770M Parcae matches the quality of a 1.3B parameter transformer trained on the same data, achieving the same performance with roughly half the parameters.
- Scales Predictably: We establish the first scaling laws for looping, finding that compute-optimal training requires increasing looping and data in tandem.
Looped models are cool, but hard to train in practice
As models move to the edge and inference deployments take on larger portions of compute, there is an increasing interest in scaling model quality without increasing parameters. One mechanism we have been excited about is layer looping, where initial works have trained looped models that match the quality of larger fixed-depth architectures.
To turn a vanilla Transformer into a looped model, we follow prior work and partition its layers into three functional blocks: a prelude (), a recurrent (), and a coda (). The forward pass works in three stages:
- Embedding: The prelude transforms the input into a latent state .
- Recurrence: The recurrent block iteratively updates a hidden state for loops. To maintain the input’s influence, is injected into each loop, typically via addition [1] () or concatenation with projection [2] ().
- Output: The coda processes the final to generate the model’s output.
Unfortunately, looped models are a headache to train [[2]](#ref-2)[[3]](#ref-3)[[4]](#ref-4). We personally found them to suffer from residual state explosion and loss spikes. What makes looped models even trickier is that the recurrent block is composed of several vanilla Transformer blocks, making it difficult to reason about the source of instability.
Understanding the instability of looping
While instability is a fickle foe, we observed that a simple linear framework captured a significant source of instability. Specifically, we recast looping as a nonlinear time variant dynamical system over the residual, whose update rule is:
where perform injection and is the contribution of the Transformer blocks to the residual stream. For the subquadratic sequence mixing fanatics out there, observe that if we ignore the nonlinear term , the resulting system is a discrete linear time-invariant (LTI) dynamical system over the residual state, across model depth.
What's cool is that for discrete LTI systems, their stability and convergence are determined by the eigenvalues of . Specifically, stability is categorized using the spectral norm (i.e., the absolute largest eigenvalue of ), with stable systems (convergent) being and unstable (divergent) systems being .
While this analysis bypasses the nonlinearities of looping (e.g., Attention and MLP units), the table and figure above confirm that our analysis is important empirically: divergent runs learn a spectral radius of , with convergent runs maintaining . When we maintain LTI conditions with Parcae, looped models become significantly more robust to hyperparameter selection.
Parcae: A stable, hassle-free looped model
So how do we stabilize? We designed a new looped model, Parcae, which explicitly maintains the stability conditions observed in the section above by construction. Specifically, we parameterize the input injection parameters using a continuous formulation , which we discretize with ZOH and Euler schemes (i.e., and ), using a learned . We then constrain as a negative diagonal matrix, where of a vector enforces negativity and is our learnable vector. This ensures that !
So, have we fixed all the issues and stabilized looped models? Unfortunately, there were still several other small tricks needed to get clean training of Parcae. For those interested, check out our paper.
Back to language modeling: Scaling up Parcae
Not only does Parcae train more reliably, but we found that it produces a higher-quality model in comparison to prior RDMs. Using the exact setup of RDMs [[2]](#ref-2), a prior looped model, we tested against parameter- and data-matched RDMs, observing that Parcae reduces validation perplexity by up to 6.3%.
Params & Model
Val. PPL (↓)
100M Scale
└ RDM
14.23
└ Parcae
13.59
350M Scale
└ RDM
10.76
└ Parcae
10.09
When retrofitting a very strong Transformer baseline into an RDM, without any hyperparameter tuning, we found Parcae to be robust over RDMs (which just flat-out diverged).
Params & Model
Val. Loss (↓)
Core (↑)
Core-Extended (↑)
RDM
Divergent
Divergent
Divergent
+ Parcae Constrained A
2.97
13.2 ± 0.2
9.1 ± 0.5
+ All Parcae Tricks
2.95
14.0 ± 0.2
9.7 ± 0.3
We also took Parcae and used it as a drop-in replacement for a standard fixed-depth Transformer. Using a nanochat-inspired setup, we train a series of language models on FineWeb-Edu, up to 1.3B parameters. We found that Parcae outperformed all parameter- and data-matched Transformers, with our 770M Parcae model almost achieving downstream quality equivalent to a Transformer twice its size!
Params & Model
Val. PPL (↓)
Core (↑)
Core-Extended (↑)
140M Scale
└ Transformer
21.48
13.00 ± 0.15
8.80 ± 0.21
└ Parcae
19.06
14.04 ± 0.20
9.67 ± 0.28
370M Scale
└ Transformer
15.79
17.46 ± 0.03
11.71 ± 0.22
└ Parcae
14.49
20.00 ± 0.06
12.75 ± 0.31
770M Scale
└ Transformer
13.08
22.42 ± 0.20
14.20 ± 0.63
└ Parcae
12.49
25.07 ± 0.33
15.19 ± 0.43
1.3B Scale
└ Transformer
11.95
25.45 ± 0.08
15.90 ± 0.23
└ Parcae
11.42
28.44 ± 0.28
17.08 ± 0.09
To loop, or not to loop
But is looping actually FLOP efficient? To study this, we explore a setting where, under a fixed parameter count and FLOP budget, we trade off mean recurrence in training with data (e.g., if we increase mean recurrence, we reduce training data to maintain a fixed FLOP budget).
At two scales, we find that increasing the mean recurrence used in training while proportionally reducing tokens yields lower validation loss than training with low recurrence and more data. What’s even cooler is that if we use a parabolic fit to extract the optimal and token budget at each FLOP level, we find that they both follow power laws with consistent exponents.
Alright, alright. But do we beat a fixed-depth model? Using our optimal recurrence scaling laws, we compare against fixed-depth Parcae models (i.e., those with ) and looped Parcae models following our optimal mean recurrence prediction from our scaling laws. We found that looping creates a stricter Pareto Frontier for validation loss (figure below), which translates into better downstream quality (table below).
What’s next & trying out Parcae yourself
We are super excited about how far we can push parameter efficiency. With the growing costs of memory overhead during inference, we think there is a lot to explore in parameter reuse methods such as layer looping. To help accelerate this process, we are releasing training code and models. We aren’t done either; we have tons of new ideas to push looped models further, so stay tuned for what comes next!
If you have any questions or want to work with us on what comes next for Parcae, please reach out to Hayden Prairie at hprairie@ucsd.edu.
The name PaRCae is a homage to the three roman fates: Nona (the Prelude block ), who initializes the computational *thread of life*, Decima (the Recurrent block ), who *measures the thread* and evolving through model depth, and Morta (the Coda block ), who finalizes the sequences by *cutting the thread* to produce the final output.
Acknowledgements
We would like to thank Together AI for collaborating with us and providing compute for these experiments. We would also like to thank Austin Silveria and Jonah Yi for their helpful feedback on this blog post.
References
- Liu Yang, Kangwook Lee, Robert D. Nowak, and Dimitris Papailiopoulos. Looped Transformers Are Better at Learning Learning Algorithms. In The Twelfth International Conference on Learning Representations, 2024. ↩
- Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling Up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. In The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. ↩
- Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation. In The Fourteenth International Conference on Learning Representations, 2026. ↩
- Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence. arXiv preprint arXiv:2511.07384, 2025. ↩
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み