Jules を用いた重要指標の測定方法について
Google Developers AI は、AI モデルの評価において重要な指標を測定する方法として「Jules」を紹介し、評価プロセスの標準化と実用性を高めた。
キーポイント
Jules の紹介と目的
Google Developers AI が公開した「Jules」は、AI モデルの評価において重要な指標を測定・管理するためのツールとして設計されている。
評価指標の重要性
単なる性能スコアだけでなく、モデルが実際にどのような課題に直面しているかを定量的に把握する指標測定の必要性が強調された。
実用性と現場適用
開発者が評価プロセスをより体系的に行えるよう支援し、AI モデルの品質向上やリスク管理に直結する実践的なアプローチを提供している。
影響分析・編集コメントを表示
影響分析
この記事は、AI モデルの評価において「何を測るべきか」という根本的な問いに対して、具体的なツール(Jules)を通じて回答を示した点で重要です。業界全体がモデルの性能評価をより定量的かつ構造的に行うよう促すことで、開発品質の向上とリスク管理の強化に寄与すると考えられます。
編集コメント
評価指標の選定は AI 開発の成否を分ける重要な要素であり、そのための具体的なツール紹介として価値があります。ただし、詳細な機能や比較データが不足しているため、即座に実装するよりは概念理解のための参考資料として捉えるべきです。
2026 年 6 月 22 日
AI コーディングエージェントは、指示されたタスクを完了する受動的なアシスタントから、文脈を継続的に吸収し、新たなリスクを特定し、開発者が尋ねる前に診断的洞察を提示する能動的なエンジンへと急速に移行しています。この進化の中心には、明確に定義された*タスク*から*目標*へのシフトがあり、これによりエージェントはコードベースを探検し、関連性を発見し、より高レベルの目的に向けて開発者を導くのに役立つ診断的観察結果を提示する必要があります。
SWE-Bench などの公的なベンチマークは、狭義に定義されたバグを修正するなど、タスクを完了するエージェントの能力を試しますが、目標に関するベンチマークはまだ存在しません。最新の論文 Agentic Coding Needs Proactivity, Not Just Autonomy において、私たちは能動的なエージェントは、何が重要かを判断し、何を証拠として提示するか、そして開発者に中断を提案すべきか沈黙すべきかを決定する「洞察ポリシー(insight policy)」に基づいて評価されるべきだと主張しています。
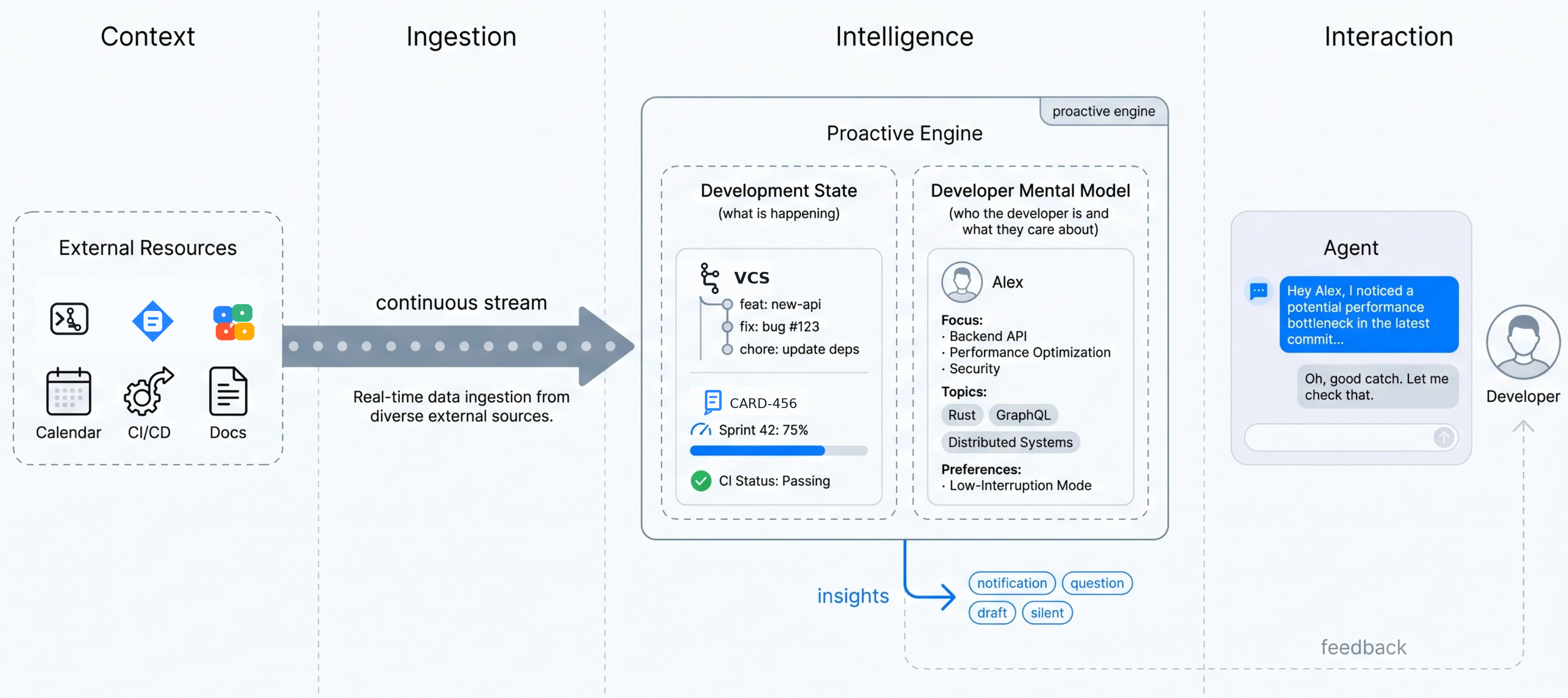
上記の図は、能動的なエージェント型コーディングエンジンの設計を示しています。開発状態と開発者モデルを維持するエンジンに文脈ストリームが流入し、洞察(通知、質問、ドラフト作成、沈黙)を出力し、その反応から学習します。
リアルなバグ修正を「正解」として活用する
Google Labs における継続的 AI システムに関する私たちの研究に基づくと、能動的エージェントの洞察ポリシー(insight policy)を評価するための評価体系を構築するには、「正解」(ground truth)を設定することが必要であることがわかりました。この「正解」を構築する方法の一つとして、チームの実際のバグ修正履歴を、私たちが時間的近接性(temporal proximity)と意味的類似度(semantic similarity)と呼ぶ 2 つのヒューリスティックに基づいて分析するというアプローチがあります。
私たちの仮説は単純です。エンジニアが短期間に複数の関連するバグを報告し修正した場合、それらのバグは往々にして単一の基盤となるエンジニアリング活動の症状であると考えられます。「サンドボックスタイムアウトエラー」、「ブローカー設定失敗」、「ネットワーク分離の不安定なテスト」といったバグのクラスターは、すべて「サンドボックス実行の信頼性を高める」という共通の目標指向を示しています。個々のバグだけでは特定のタスクに特化しすぎて目標として機能しませんが、それらを組み合わせることで、より高レベルな目的が浮かび上がります。
予備的な評価セットの構築とテスト
予備的なベンチマークを構築し仮説を検証するために、私たちは内部 Google コードベースから 705 のバグ(1,178 の CLs)を使用しました。
- 関連する過去のバグをクラスタリングし、開発者が実際に取り組んでいた上位レベルの「目指すべき目標」を明らかにします。
- 各クラスタ内の個々のバグを「正解(グラウンドトゥルース)」のターゲットとして設定し、コードベースを修正前の正確な状態に巻き戻して、エージェントが人間エンジニアと同じ地点から開始できるようにしました。
- エージェントが最終的な洞察を生成する前に、最大 3 ラウンド(「探索予算」または N)にわたってコードベースを検査できるようにします。
- LLM を使用して、エージェントの予測された洞察を、「正解」ターゲットに対して 1(無関係)から 5(完全一致)まで評価します。
- エージェントの平均最高スコアと、高い精度で正確な一致を生成した頻度(Hit@K)を追跡することで成功を測定します。
予備的な結果と教訓
私たちのテストにおける予備的な結果は、主に 2 つの理由から興奮を呼びます。
中核となる診断ロジックが機能しています: 単一の探索ラウンドを与えられただけで、エージェントは一貫して非常に関連性の高い洞察(平均 4.5/5)を特定しました。これは、単純なエンジニアリング問題における主要なシグナルを確実に捉えたことを意味します。
探索予算の重要性: 複雑で多面的な問題は本質的に困難ですが、エージェントに調査のためのリソースを多く与えることは報われます。探索ラウンド数を 2 ラウンドから 3 ラウンドに増やすことで、エージェントのHit@5 精度(上位 5 つの推奨事項の中に正しい診断的洞察が含まれる割合として定義)は 33% から 57% に大幅に回復しました。これは、追加のパスがエージェントが当初見落とした二次信号を発見するのを直接助けることを証明しています。
次のステップ
これらは初期サンプルに基づく予備的な結果であり、私たちは複数の側面でカバー範囲を積極的に拡大しています。まず、この評価を公開 GitHub データ(課題と解決された PR)に拡張し、この手法をより広い AI コミュニティに広く適用可能にします。また、コードベースだけでなく、課題追跡システム、会話、設計ドキュメントなど、より豊かなコンテキストストリームを取り込む方法も探っています。
コーディングの未来に関する当社の取り組みについて詳しく知りたい場合は、完全な論文を こちら で読み、labs.google/code で私たちを追跡してください。
前へ
次へ
原文を表示
JUNE 22, 2026
AI coding agents are rapidly shifting from reactive assistants that complete tasks when prompted to proactive engines that continuously absorb context, spot emerging risks, and surface diagnostic insights before developers have to ask. At the center of this evolution is a shift from well-defined *tasks* to *goals*, which require the agent to explore the codebase, discover what is relevant, and surface diagnostic observations that help guide developers toward a higher-level objective.
Public benchmarks like SWE-Bench test an agent’s ability to complete tasks, like fixing a narrowly defined bug, but no benchmarks currently exist for goals. In our most recent paper,Agentic Coding Needs Proactivity, Not Just Autonomy, we argue that proactive agents must be graded on their insight policy—the ability to decide what matters, what evidence supports it, and whether to interrupt the developer or stay silent.
The Figure above shows the design of a proactive agentic coding engine. Context streams into an engine that maintains development state and a developer model, emits insights (notify, question, draft, stay silent), and learns from response.
Leveraging real bug fixes as “ground truth”
Based on our work on continuous AI systems at Google Labs, we’ve found that building evaluations capable of grading a proactive agent on its insight policy requires establishing a “ground truth.” One way to build this “ground truth” is to analyze a team’s real bug-fixing history along two heuristics we term temporal proximity and semantic similarity.
Our hypothesis is simple: when engineers file and fix several related bugs within a short time period, those bugs are often symptoms of a single underlying engineering effort. A cluster of bugs around "sandbox timeout errors," "broker config failures," and "network isolation flaky tests" all point toward a common aspirational goal like *"Strengthen sandbox execution reliability."* Individually, each bug is too task-specific to serve as a goal. Together, they reveal the higher-level objective.
Building and testing our preliminary eval set
To build our preliminary benchmark and test our hypothesis, we used 705 bugs (1,178 CLs) from internal Google codebases to:
- Cluster related historical bugs to reveal the higher-level "aspirational goals" developers were actually working toward.
- Set the individual bugs within each cluster as our "ground truth" targets and reverted the codebase to its exact pre-fix state so the agent began where the human engineer did.
- Allow the agent to investigate the codebase for up to three rounds (its "exploration budget," or N) before generating its final insights.
- Use an LLM to judge the agent’s predicted insights from 1 (irrelevant) to 5 (exact match) against our “ground truth” targets.
- Measure success by tracking the agent's average top score and how often it successfully produced a highly accurate match (Hit@K).
Preliminary results and what we learned
The preliminary results of our testing are exciting for two primary reasons.
The core diagnostic logic works: Given a single exploration round, the agent consistently identified a highly relevant insight (averaging 4.5 out of 5). It successfully captured the primary signal for straightforward engineering problems.
Exploration budgets matter: Complex, multi-faceted problems are naturally harder, but giving the agent more resources to investigate pays off. By increasing the exploration budget from two rounds to three, the agent’s Hit@5 accuracy (defined as the rate at which a correct diagnostic insight appears within its top 5 recommendations) rebounded significantly from 33% to 57%. This proves that extra passes directly help the agent uncover secondary signals it initially missed.
What’s next
These are preliminary results on an initial sample, and we are actively expanding coverage on multiple fronts. To start, we are expanding this evaluation to public GitHub data (issues and resolving PRs) to make this methodology broadly applicable to the wider AI community. We are also exploring how to ingest richer context streams like issue trackers, conversations, and design documents beyond just the codebase.
Read the full paper here and follow along with us at labs.google/code if you’re interested in learning more about our work on the future of coding at Google Labs.
Previous
Next
関連記事
エージェント型リソース発見仕様の発表
Google Developers AI が、AI エージェントがリソースを自動的に発見・利用するための新しい仕様「Agentic Resource Discovery」を発表した。
A2UI v0.9:ポータブルでフレームワークに依存しない生成UIの新標準
A2UI v0.9は、企業の既存デザインシステムを使用してAIエージェントがリアルタイムでカスタマイズされたUIウィジェットを生成するためのフレームワークに依存しない標準を導入した。Python用Agent SDK、共有ウェブコアライブラリ、React/Flutter/Angularの公式サポートにより開発者体験を簡素化している。
スキルを備えたADKエージェント構築の開発者ガイド
GoogleのAgent Development Kit(ADK)SkillToolsetは、AIエージェントが要求に応じてドメイン知識を読み込める「段階的開示」アーキテクチャを導入し、従来の単一プロンプトと比較してトークン使用量を最大90%削減する。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み