2026 年にローカルで実行可能なトップ 7 つのコーディングモデル
KDnuggets が選定した、2026 年版のローカル環境で動作する主要なコード生成 AI モデル 7 つは、データプライバシーとカスタマイズ性を重視する開発者にとって重要な選択肢となる。
キーポイント
ローカル実行モデルの選定基準
2026 年版として、計算リソース効率、コード理解能力、およびプライバシー保護機能を満たすモデルが厳選された。
主要な 7 つのモデル紹介
Qwen, Llama, CodeLlama, DeepSeek などのオープンソース系から、ローカル環境で最適化された最新バージョンが含まれる。
オンプレミス開発へのシフト
クラウド依存からの脱却により、機密コードの外部流出リスクを排除しつつ、高度なコード生成を実現するトレンドが強調されている。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの利用形態がクラウド中心からオンプレミス・エッジ環境へと多様化する重要な転換点を示しています。開発者や企業にとって、セキュリティとコスト管理を両立させるための具体的な技術選定の指針となり、オープンソースモデルの生態系がさらに成熟していることを裏付けています。
編集コメント
2026 年という未来の視点から、現在のトレンドがどう成熟するかを示唆する有益な記事です。特にセキュリティ意識の高い組織にとって、ローカルモデルの選定基準を知る上で参考になります。
 image
image
# イントロダクション
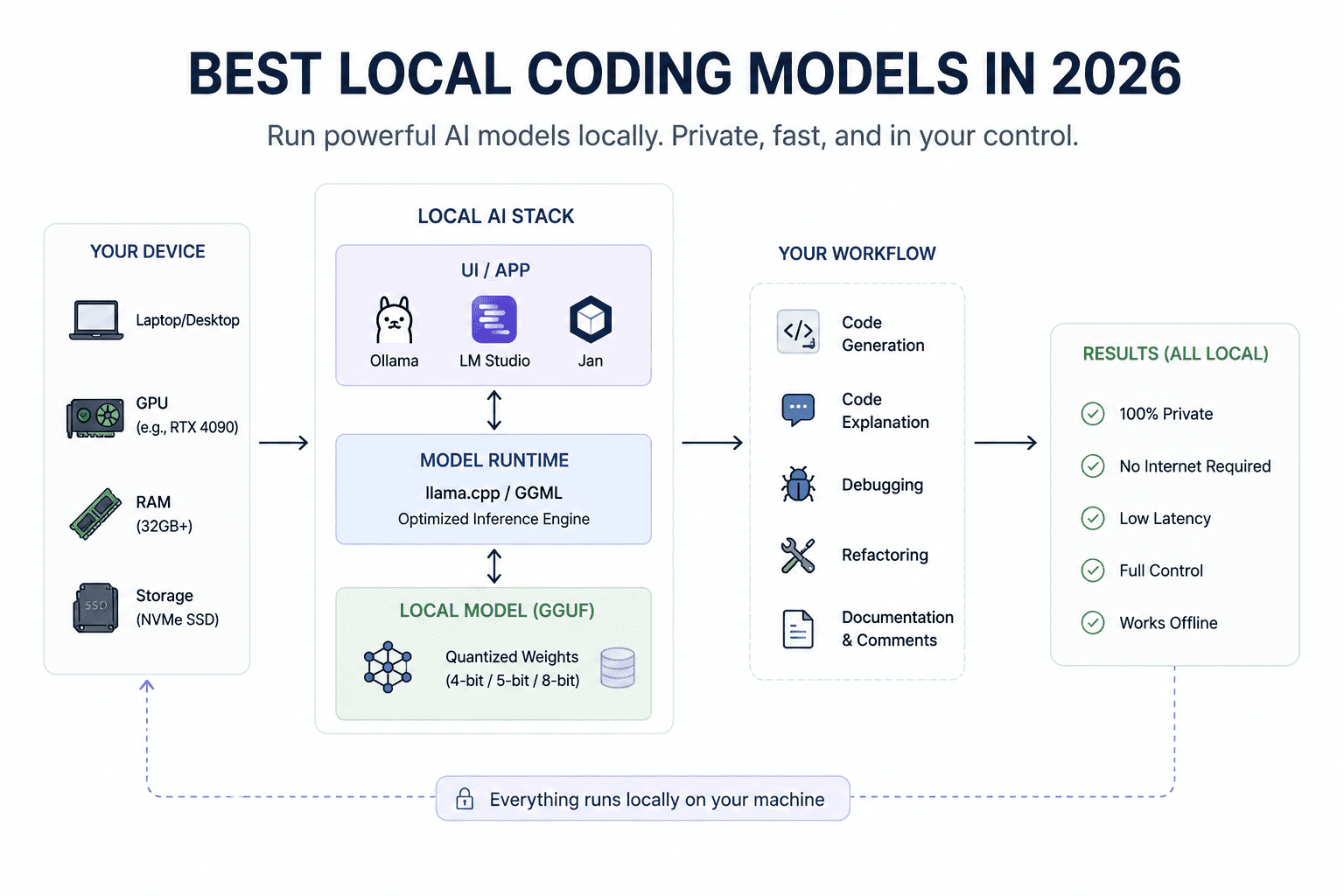
ローカルコーディングモデルが、ついに本格的な存在になりつつあります。私はこの新しいローカル大規模言語モデル(LLM)の波の大きな支持者であり、特にオープンソースモデルや、コンシューマー向けハードウェアで実行しやすくするコミュニティによる GGML Universal File (GGUF) リリースを高く評価しています。現在、RTX 3090 などの GPU で動作可能なモデルも登場し、実用的に感じるほどの速度で生成を行い、実際のコーディングやエージェントプログラミングの問題を解決できるようになっています。単なるデモでもなければ、単なるギミックでもありません。
完全にローカル環境でのコーディングセットアップを構築したい方、あるいは少なくとも 16GB のビデオランダムアクセスメモリ(VRAM)をお持ちの方は、これらのモデルが Claude Code や Gemini**、その他のホスト型コーディングアシスタントへの依存から脱却する手助けをしてくれます。これらは高速で能力が高く、プライバシーも守られ、実際の開発ワークフローに十分対応できるレベルです。
この変化はすでにローカル AI コミュニティ全体で見られます。Reddit の r/LocalLLaMA では、ローカルコーディングエージェントを実行し、GGUF モデルをテストし、OpenAI 互換のローカルサーバーを構築し、これらのモデルをエディタやターミナル、コーディングアシスタントに接続する開発者で溢れています。
# 1. Qwen3.6 27B MTP
Qwen3.6 27B MTP は、現在私が最もお気に入りのローカルコーディングモデルの一つです。異なる環境でテストし、使用し、探索してきましたが、サイズ、速度、そして実際のコーディング能力のバランスにおいて最高だと感じています。
最も素晴らしい点は、GGUF 量子化バージョンを使用すれば、フルクラウドセットアップを必要とせず、コンシューマー向けハードウェア上で実行できることです。たとえ VRAM が 16GB から 24GB の GPU で作業していたとしても、4 ビット版であればローカルでの利用がはるかに現実的なものになります。
Reddit の r/LocalLLaMA コミュニティではすでに、Qwen3.6 27B MTP をローカルエージェントによるコーディング、高速推論、llama.cpp セットアップ、および OpenAI 互換のローカルサーバー向けにテストしている人々で溢れています。そして正直なところ、この盛り上がりは理にかなっています。
Qwen モデルは通常、推論、指示の遵守、多言語理解、ツール使用、長文コンテキストサポートを組み合わせることでコーディングにおいて強力です。その結果、Qwen3.6 27B MTP はコーディングアシスタント、リポジトリチャット、デバッグ、シェルコマンド、そしてエージェントワークフローのための優れたオールラウンドローカルモデルとなります。
# 2. Gemma 4 31B IT QAT
**
Gemma 4 31B IT QAT** は、ローカルコーディングセットアップのいずれにおいても真剣に位置づけられるべきだと私が考えるもう一つのモデルです。Google のオープンソースである Gemma モデルは、ローカルで能力の高いモデルを実行したい人々にとって常に優れたものでしたが、この量子化意識トレーニング(QAT: Quantization-Aware Training)を施した GGUF バージョンにより、さらに実用的なものとなっています。
4 ビット量子化形式の大型 31B モデルは、コンシューマー向けハードウェアでの読み込みが非常に容易でありながら、高い品質を維持しています。これは単なる hype(過熱した期待)ではありません。私は Gemma モデルについて記事を書き、実際に使用し、さまざまなワークフローでテストしてきましたが、ローカル環境でのコーディングや推論においては Qwen シリーズと非常に近い感覚があります。
Gemma 4 31B が際立つ大きな理由は、それがコーディング専用モデルではない点です。マルチモーダルであり、スクリーンショット、UI の問題、図解、ドキュメント画像、Web アプリのレイアウトなどへの対応も可能で、コード生成、デバッグ、計画立案においても有用性を保っています。
公式ベンチマークの数値も無視できません。LiveCodeBench や Codeforces でのコーディング結果は非常に強力です。コーディングとビジュアル開発タスクの両方を処理できるローカルモデルをお探しなら、Gemma 4 31B IT QAT は試すべき最良の選択肢の一つです。
# 3. DiffusionGemma 26B A4B
**
DiffusionGemma 26B A4B** は、このリストにある最新かつ最も興味深いモデルの一つです。強力であり、実験的な性質を持ち、通常のトークンごとの言語モデルとは異なる構造で構築されています。
標準的な自己回帰方式でテキストを生成するのではなく、ブロック拡散アプローチを採用しており、これは並列にトークンのブロックのノイズ除去を行うことで生成速度の向上を図る設計となっています。
そのため、このモデルはローカルコーディングにおいて非常に魅力的です。特にコード生成、構造化された出力、そして迅速な推論タスクにおいて、ローカルアシスタントを大幅に高速化できるようなアーキテクチャであると感じられるからです。
最大の魅力は効率性にあります。DiffusionGemma は総パラメータ数が約 250 億ですが、推論時にアクティブになるのは約 38 億パラメータのみです。つまり、大規模な Mixture of Experts (MoE) スタイルのモデルの恩恵を受けながら、密結合型(dense)の 26B モデルをフルに推論する際の全コストを支払う必要がありません。
# 4. Nemotron Cascade 2 30B A3B
**
Nemotron Cascade 2 30B A3B** は、紙面上では奇妙に見えるものの、ローカルコーディングにおいては非常に理にかなった別のモデルです。
これは 300 億パラメータの MoE スタイルモデルですが、推論時にアクティブになるのは約 30 億パラメータのみです。つまり、毎回密結合型の 30B モデルの全コストを支払う必要はありません。这正是私がローカル環境で好むタイプのモデルです:十分に大きくて適切に推論できるが、自分のマシン上で実際に実行してテストするにはまだ効率的であるという点です。
このモデルを魅力的にするのは、単なるコード補完モデルではなく、より推論モデルに近いと感じられる点にあります。NVIDIA はこれを推論とエージェントタスクに強く、思考モードと指示モードの両方を備えていると説明しており、2025 年の国際数学オリンピック(IMO)および 2025 年の国際情報オリンピック(IOI)において金メダルレベルのパフォーマンスを発揮すると主張しています。
開発者にとって重要なのは、コーディングがもはや関数を書くだけではないということです。モデルにはデバッグ、計画策定、コードレビュー、多段階問題の理解、実装の詳細に関する推論を求めます。
# 5. Qwen3.5 9B MTP
**
Qwen3.5 9B MTP** はこのリストの中で最も小さなモデルですが、侮ってはいけません。
その重量級別クラスにおいて非常に高い評価を得ており、巨大なワークステーションを必要とせずとも、現代的な Qwen スタイルのコーディングアシスタントを提供します。小規模なローカル環境をお持ちであれば、このモデルはまさに宝石のような存在です。高速で実用的であり、27B や 31B のモデルよりもはるかに実行が容易です。
GGUF バージンが、日常の開発者にとってさらに有用なものにしています。テストするために複雑なセットアップや高価なクラウドインスタンスを必要としません。ローカルで実行し、エディタやターミナルワークフローに接続して、プライベートなコーディングアシスタントとして利用できます。
複雑な推論においては大型モデルには勝てませんが、日常のコーディングタスクにとっては十分すぎるほどです。小さなスクリプト、デバッグ、コード解説、シェルコマンド、そして迅速なローカルアシスタントワークフローに使用できます。ローカルコーディングモデルを始める方々にとって、Qwen3.5 9B MTP はおそらく最も安全で実用的な選択肢の一つでしょう。
# 6. EXAONE 4.5 33B
**
EXAONE 4.5 33B** は、開発者が無視すべきではないもう一つのモデルです。特に、あなたの業務が単なるコード記述だけにとどまらない場合、なおさらです。
これは LG AI リサーチが開発したオープンウェイトのマルチモーダルモデルであり、スクリーンショット、PDF、図表、ドキュメント、UI レイアウトも理解する必要があるローカルコーディングワークフローにおいて非常に有用です。
ここで EXAONE が注目される理由です。現在のコーディング作業は、単に Python 関数を書くことだけではありません。ドキュメントを読み込み、スクリーンショットからエラーを確認し、アーキテクチャ図を理解し、ごちゃごちゃしたプロジェクトファイルと作業を行うことが多くなっています。テキストと視覚的入力の両方を処理できるモデルは、はるかに有用性が高まります。
コードに加え、ドキュメントやスクリーンショット、エンタープライズスタイルのワークフローに対応するローカルモデルをお探しなら、EXAONE 4.5 33B は試すべき強力な選択肢です。
# 7. North Mini Code 1.0
**
North Mini Code 1.0** は、このリストの中で最も新しいモデルの一つであり、Cohere がようやくローカルコーディングモデルの領域に本格的に進出してきたことを嬉しく思います。
これはたまたまコードも書ける汎用チャットボートではありません。コード生成、エージェント型ソフトウェアエンジニアリング、ターミナルベースのタスクのために構築されたものです。リポジトリ編集、コマンドラインヘルプ、コードレビュー、コーディングエージェントワークフローのためのローカルモデルを求める開発者にとって、これは非常に興味深い存在です。
また、これは 30B-A3B モデルであり、総パラメータ数は 30B ですが、推論時には約 3B のアクティブなパラメータのみが使用されます。つまり、再び優れたバランスを実現しています:小規模モデルよりも強力な推論能力を持ちながら、フルデンスの 30B モデルよりも効率的です。
Qwen3.6 27B や Gemma 4 31B ほど広範ではありませんが、コーディングに特化した作業においては、North Mini Code 1.0 は非常に実用的なモデルとして試す価値があります。
# まとめ
この表は、ハードウェア、ワークフロー、およびコーディングのユースケースに基づいて、どのローカルコーディングモデルを選ぶべきかを一覧で示しています。
Model
サイズ / タイプ
最適なユースケース
選ぶ理由
Qwen3.6 27B MTP
27B MTP
強力なローカルコーディング、推論、およびエージェントワークフロー
最もバランスの取れたローカルコーディングモデル
Gemma 4 31B IT QAT
31B, 4-bit QAT, マルチモーダル
コーディングに加え、スクリーンショット、UI バグ、図表、長文コンテキスト作業
強力なコーディングベンチマークとマルチモーダルサポート
DiffusionGemma 26B A4B
26B / ~4B アクティブ
高速で実験的なローカルコーディングおよび推論
効率的な生成に焦点を当てた新アーキテクチャ
Nemotron Cascade 2 30B A3B
30B / ~3B アクティブ
エージェントによるコーディング、デバッグ、計画、推論重視のタスク
オートコンプリートというより、推論型エージェントに近い
Qwen3.5 9B MTP
9B MTP
小規模なローカルマシンや日常のコーディング支援
高速で実用的であり、その重量クラスにおいて優れた性能を発揮
EXAONE 4.5 33B
33B マルチモーダル
コード、ドキュメント、スクリーンショット、PDF、図表
ドキュメント中心および視覚的コーディングワークフローに最適
North Mini Code 1.0
30B / ~3B アクティブ コーディングモデル
ローカルコーディングエージェント、リポジトリ編集、ターミナルタスク、コードレビュー
リスト内で最もコーディング特化型のモデル
ローカル実行可能なコーディングモデルは、もはやテストや遊びの域を超え、実際の開発業務でも十分に活用できるようになっています。RTX 3090 や 4090 などの高性能 GPU をお持ちであれば、まずは Qwen3.6 27B MTP の 4-bit 版から始めることを強くお勧めします。これはローカルでのコーディング、推論、そしてエージェントワークフローにおいて、最もバランスの取れた選択肢です。正直なところ、あまり多くのモデルを行き来して時間を浪費する前に、まずはこれを試してみてください。
同程度のハードウェアで最速のローカル生成を実現したい場合は、DiffusionGemma 26B A4B に注目すべきです。これは比較的新しく実験的なモデルですが、そのアーキテクチャは速度と推論効率を重視する開発者にとって非常に興味深いものとなっています。
マルチモーダル理解能力、より優れた推論力、そしてコードに加えてスクリーンショット、UI レイアウト、図表、ドキュメントとの連携能力を求めるのであれば、Gemma 4 31B IT QAT が素晴らしい選択肢です。これは単なるコーディングモデルを超えた存在であり、現代の開発ワークフローにおいて有用性を発揮します。
一方、大規模な GPU をお持ちでない場合は、Qwen3.5 9B MTP がその重量クラスにおける最良のモデルと言えるでしょう。シンプルなローカル環境と十分なシステム RAM があるだけであれば、説明、デバッグ、スクリプト作成、シェルコマンド、そして一般的なワークフロー支援において、日々のコーディングアシスタントとして十分に機能します。
残りのモデルもまた、あなたが何を重視するかによってテストする価値があります。
Nemotron Cascade 2 30B A3B は、ローカルでのエージェント型コーディング、計画策定、デバッグ、構造化された問題解決のための推論モデルをお探しの場合に最適です。
EXAONE 4.5 33B は、ドキュメント、PDF、スクリーンショット、およびエンタープライズ向けのコーディングワークフローを扱う業務において有用です。
North Mini Code 1.0 は最もコーディングに特化した選択肢であり、ローカルでのコーディングエージェント、リポジトリ編集、ターミナルタスク、コードレビューにおいて有望な候補となっています。これらがすべての人にとって最初の選択とはならないかもしれませんが、それぞれが存在する明確な理由があります。
Abid Ali Awan** (@1abidaliawan) は機械学習モデルの構築を愛する認定データサイエンティストのプロフェッショナルです。現在、彼はコンテンツ作成に注力し、機械学習およびデータサイエンス技術に関する技術ブログの執筆を行っています。Abid はテクノロジーマネジメントの修士号と電気通信工学の学士号を取得しています。彼のビジョンは、精神疾患に苦しむ学生のためにグラフニューラルネットワークを用いた AI 製品を構築することです。
原文を表示
**
# Introduction
Local coding models are finally getting serious. I have been a big fan of this new wave of local large language models (LLMs), especially the open models and community GGML Universal File (GGUF) releases that make them easier to run on consumer hardware. We are now at a point where some of these models can run on GPUs like an RTX 3090, generate fast enough to feel useful, and actually solve real coding and agentic programming problems. Not just demos. Not just gimmicks.
If you want a fully local coding setup and have at least 16GB of Video Random Access Memory (VRAM), these models can help you move away from relying only on Claude Code, Gemini**, or other hosted coding assistants. They are fast, capable, private, and good enough for real development workflows.
You can already see this shift happening across the local AI community. Reddit’s r/LocalLLaMA is full of developers running local coding agents, testing GGUF models, building OpenAI-compatible local servers, and connecting these models to editors, terminals, and coding assistants.
# 1. Qwen3.6 27B MTP
**
Qwen3.6 27B MTP** is easily one of my favorite local coding models right now. I have tested, used, and explored it across different setups, and it feels like the best balance between size, speed, and actual coding ability.
The best part is that with the GGUF quantized versions, you can run it on consumer hardware instead of needing a full cloud setup. Even if you are working with a 16GB to 24GB VRAM GPU, the 4-bit versions make it much more realistic to use locally.
The r/LocalLLaMA community on Reddit is already full of people testing Qwen3.6 27B MTP for local agentic coding, faster inference, llama.cpp setups, and OpenAI-compatible local servers. And honestly, the hype makes sense.
Qwen models are usually strong at coding because they combine reasoning, instruction following, multilingual understanding, tool use, and long-context support. That makes Qwen3.6 27B MTP a strong all-round local model for coding assistants, repo chat, debugging, shell commands, and agentic workflows.
# 2. Gemma 4 31B IT QAT
**
Gemma 4 31B IT QAT** is another model that I think deserves a serious place in any local coding setup. Google’s open Gemma models have always been good for people who want to run capable models locally, and this quantization-aware training (QAT) GGUF version makes it even more practical.
You get a large 31B model in a 4-bit quantized format that is much easier to load on consumer hardware, while still keeping strong quality. It is not just hype either. I have written about Gemma models, used them, tested them in different workflows, and they feel very close to the Qwen series when it comes to local coding and reasoning.
The big reason Gemma 4 31B stands out is that it is not only a coding model. It is also multimodal, which means it can help with screenshots, UI issues, diagrams, documentation images, and web app layouts while still being useful for code generation, debugging, and planning.
The official benchmark numbers also make it hard to ignore, with strong coding results on LiveCodeBench and Codeforces. If you want a local model that can handle coding plus visual development tasks, Gemma 4 31B IT QAT is one of the best options to try.
# 3. DiffusionGemma 26B A4B
**
DiffusionGemma 26B A4B** is one of the newest and most interesting models on this list. It is powerful, experimental, and built differently from the usual token-by-token language models.
Instead of generating text in the standard autoregressive way, it uses a block-diffusion approach, which is designed to improve generation speed by denoising blocks of tokens in parallel.
That is why this model is exciting for local coding: it feels like the kind of architecture that could make local assistants much faster, especially for code generation, structured outputs, and quick reasoning tasks.
The main appeal is efficiency. DiffusionGemma has around 25B total parameters but only around 3.8B active parameters, so you get the benefit of a larger Mixture of Experts (MoE)-style model without paying the full inference cost of a dense 26B model.
# 4. Nemotron Cascade 2 30B A3B
**
Nemotron Cascade 2 30B A3B** is another model that looks strange on paper but makes a lot of sense for local coding.
It is a 30B MoE-style model, but only around 3B parameters are active during inference. So you are not paying the full cost of a dense 30B model every time. That is exactly the kind of model I like for local setups: big enough to reason properly, but still efficient enough to actually run and test on your own machine.
What makes this model exciting is that it feels more like a reasoning model than a simple coding autocomplete model. NVIDIA describes it as strong for reasoning and agentic tasks, with both thinking and instruct modes, and even claims gold-medal level performance on the International Mathematical Olympiad (IMO) 2025 and the International Olympiad in Informatics (IOI) 2025.
For developers, that matters because coding is not just writing functions anymore. You want the model to debug, plan, review code, understand multi-step problems, and reason through implementation details.
# 5. Qwen3.5 9B MTP
**
Qwen3.5 9B MTP** is the smaller model in this list, but do not underestimate it.
For its weight class, it ranks really well and gives you a proper modern Qwen-style coding assistant without needing a huge workstation. If you have a smaller local setup, this model is a gem. It is fast, practical, and much easier to run than the 27B or 31B models.
The GGUF version is what makes it even more useful for everyday developers. You do not need a complicated setup or expensive cloud instance just to test it. You can run it locally, connect it to your editor or terminal workflow, and use it like a private coding assistant.
It will not beat the bigger models on complex reasoning, but for daily coding tasks it is more than enough. You can use it for small scripts, debugging, code explanations, shell commands, and quick local assistant workflows. For people starting with local coding models, Qwen3.5 9B MTP is probably one of the safest and most practical choices.
# 6. EXAONE 4.5 33B
**
EXAONE 4.5 33B** is another model that I think developers should not ignore, especially if your work involves more than just plain code.
It is LG AI Research’s open-weight multimodal model, and that makes it really useful for local coding workflows where you also need to understand screenshots, PDFs, diagrams, documentation, and UI layouts.
This is where EXAONE becomes interesting. A lot of coding work now is not just writing Python functions. You are reading docs, checking errors from screenshots, understanding architecture diagrams, and working with messy project files. A model that can handle both text and visual input becomes much more useful.
If you want a local model for code plus documents, screenshots, and enterprise-style workflows, EXAONE 4.5 33B is a strong option to try.
# 7. North Mini Code 1.0
**
North Mini Code 1.0** is one of the newest models on this list, and it is good to see Cohere finally entering the local coding model space properly.
This is not a general chatbot that also happens to write code. It is built for code generation, agentic software engineering, and terminal-based tasks. That makes it much more interesting for developers who want a local model for repo edits, command-line help, code review, and coding-agent workflows.
It is also a 30B-A3B model, which means it has 30B total parameters but only around 3B active parameters during inference. So again, you get that nice balance: stronger reasoning than small models, but still more efficient than a full dense 30B model.
It may not be as broad as Qwen3.6 27B or Gemma 4 31B, but for coding-specific work, North Mini Code 1.0 looks like a very practical model to try.
# Final Thoughts
**
This table gives you a quick view of which local coding model to pick based on your hardware, workflow, and coding use case.
Model
Size / Type
Best Use Case
Why Pick It
Qwen3.6 27B MTP
27B MTP
Strong local coding, reasoning, and agentic workflows
Best all-round local coding model
Gemma 4 31B IT QAT
31B, 4-bit QAT, multimodal
Coding plus screenshots, UI bugs, diagrams, and long-context work
Strong coding benchmarks and multimodal support
DiffusionGemma 26B A4B
26B / ~4B active
Fast, experimental local coding and reasoning
New architecture focused on efficient generation
Nemotron Cascade 2 30B A3B
30B / ~3B active
Agentic coding, debugging, planning, and reasoning-heavy tasks
Feels more like a reasoning agent than autocomplete
Qwen3.5 9B MTP
9B MTP
Smaller local machines and daily coding help
Fast, practical, and great for its weight class
EXAONE 4.5 33B
33B multimodal
Code, documents, screenshots, PDFs, and diagrams
Best for document-heavy and visual coding workflows
North Mini Code 1.0
30B / ~3B active coding model
Local coding agents, repo edits, terminal tasks, and code review
Most coding-specific model in the list
Local coding models are now good enough that you can actually use them for real development work, not just testing or playing around. If you have a good GPU like an RTX 3090 or 4090, I would simply recommend starting with Qwen3.6 27B MTP in 4-bit. It is the best all-round option for local coding, reasoning, and agentic workflows. Honestly, try that first before wasting time jumping between too many models.
If you want the fastest local generation on similar hardware, then DiffusionGemma 26B A4B is the one to watch. It is newer and more experimental, but the architecture makes it really interesting for developers who care about speed and efficient inference.
If you want multimodal understanding, better reasoning, and the ability to work with code plus screenshots, UI layouts, diagrams, and documentation, then Gemma 4 31B IT QAT is a great choice. It is more than just a coding model, and that makes it useful for modern development workflows.
And if you do not have a big GPU, Qwen3.5 9B MTP is probably the best model for its weight class. Even with a simpler local setup and enough system RAM, it can still work well as a daily coding assistant for explanations, debugging, scripts, shell commands, and general workflow help.
The rest of the models are also worth testing, depending on what you care about.
Nemotron Cascade 2 30B A3B is great if you want a local reasoning model for agentic coding, planning, debugging, and structured problem solving.
EXAONE 4.5 33B is useful if your work involves documents, PDFs, screenshots, and enterprise-style coding workflows.
North Mini Code 1.0 is the most coding-focused option, and it looks promising for local coding agents, repo edits, terminal tasks, and code review. They may not be my first pick for everyone, but each one has a clear reason to exist.
Abid Ali Awan** (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
関連記事
OpenAI、新セキュリティツールを公開し「GPT-5.5-Cyber」を更新(2 分読)
OpenAI は、更新された Codex セキュリティプラグイン、限定リリースの GPT-5.5-Cyber、および AI エラのための防御型サイバースタック「Daybreak」パートナープログラムとオープンソースイニシアチブ「Patch the Planet」を発表した。
NVIDIA NeMo AutoModel を用いたトランスフォーマーファインチューニングの加速化
Hugging Face は、NVIDIA の NeMo AutoModel を活用することで、トランスフォーマーモデルのファインチューニング処理を大幅に高速化する手法を発表した。
OpenAI、Broadcomと共同開発した初のAI専用プロセッサ「Jalapeño」を発表
OpenAIは Broadcom と共同で開発した AI サーバー用専用チップ「Jalapeño」を公開しました。この ASIC は大規模言語モデルの推論処理に特化しており、同社の次世代モデルを支える基盤となります。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み