計画、分割、征服:弱モデルが長いコンテキストタスクで優れる理由
Together AIは、小規模モデルを用いた「分割統治」アプローチにより、GPT-4o単一ショット推論に匹敵する長文コンテキスト処理性能を実現するフレームワークをICLR 2026で発表し、コスト効率の高い大規模テキスト処理の可能性を示した。
キーポイント
直感的なアプローチ:分割統治の適用
1つの天才が図書館を1時間で読むのではなく、10人のインターンにそれぞれ本を読ませるという直観に基づき、タスクを分割して並列処理する戦略を採用した。
小規模モデルの性能向上
研究結果により、戦略的な「分割統治」設計を用いた小規模モデルが、GPT-4oの単一ショット推論と同等かそれ以上の性能を長文コンテキストタスクで達成できることが示された。
ICLR 2026での論文発表
この手法を体系化した「When Does Divide and Conquer Work for Long Context LLM?」という論文がICLR 2026で採択され、その有効性が学術的に裏付けられた。
重要な引用
"Don't ask one genius to read a library in an hour. Ask ten interns to read one book each."
We found that smaller models using a strategic "Divide & Conquer" design can match or beat GPT-4o single-shot on long context tasks.
影響分析・編集コメントを表示
影響分析
この研究は、長文コンテキスト処理におけるコストと性能のトレードオフを再定義する可能性を秘めている。大規模モデルへの依存を減らし、小規模モデルの並列処理で同等の結果を得られることは、推論コストの大幅な削減と、より多くのユーザーへのサービス提供を可能にする。業界全体として、アーキテクチャの最適化とアルゴリズムの革新に注力する動きを加速させるだろう。
編集コメント
大規模モデルへの依存を減らし、小規模モデルの並列処理で同等の結果を得られることは、推論コストの大幅な削減と、より多くのユーザーへのサービス提供を可能にする。業界全体として、アーキテクチャの最適化とアルゴリズムの革新に注力する動きを加速させるだろう。
 imageimageTL;DR
imageimageTL;DR
直感: 一人の天才に一時間で図書館全体を読ませるのではなく、十人の研修生に一冊ずつ読ませてください。
私たちの研究「When Does Divide and Conquer Work for Long Context LLM?」(ICLR 2026)は、この問いを検証するためのフレームワークを導入するものです。私たちは、戦略的な「分割統治(Divide & Conquer)」設計を採用した小規模モデルが、長文コンテキストタスクにおいて GPT-4o の単一ショット性能に匹敵し、あるいは凌駕できることを発見しました。
現代の LLM(大規模言語モデル)は、128K、200K、さらには 1M トークンを超える巨大なコンテキストウィンドウをますますサポートするようになっています。これは理論上、単一のプロンプトでコードベース全体を分析したり、書籍全体を要約したりするような強力なユースケースを可能にします。
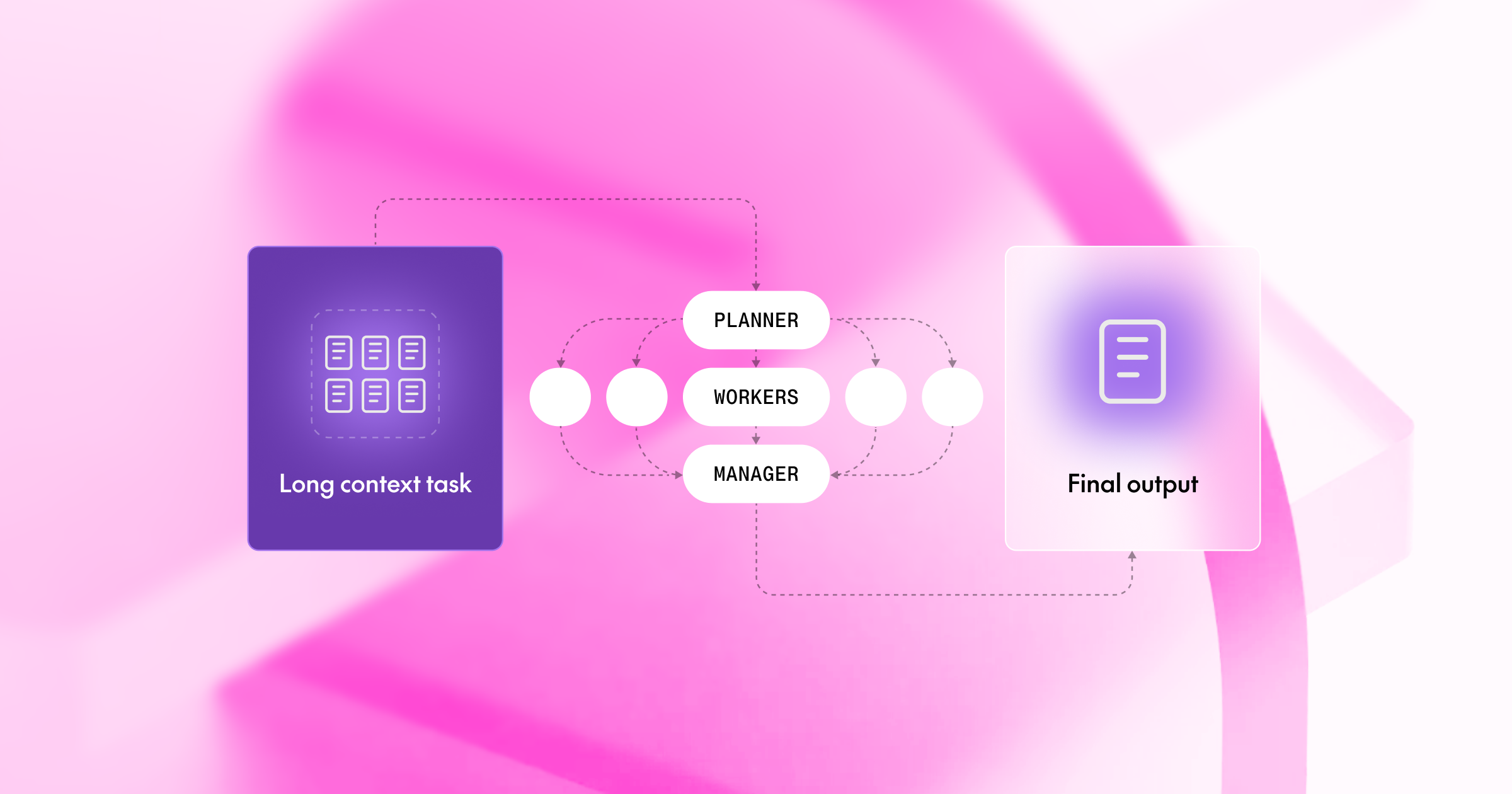
しかし、「すべてを一つのプロンプトに放り込めばよい」という約束は、実際には頻繁に失敗します。コンテキスト長が成長するにつれて、パフォーマンスは予期せぬ方法で低下します。「分割統治(Divide and Conquer)」は、以下の図に示すように、長文コンテキストタスクに対する魅力的な解決策であることがわかりました。
「分割統治」フレームワーク。プランナーはジョブ記述を再構成し、ワーカーは長文ドキュメントのサブセットをそれぞれ処理し、マネージャーは情報を集約して最終回答を提供します。
私たちの論文では、注意深く設計された「分割統治」フレームワークを用いる weaker モデルが、長文コンテキストタスクにおいて GPT-4o のシングルショットと同等かそれ以上の性能を発揮できることを発見しました。
コアとなる問題:長さによる「霧」
この「分割統治」アプローチを長文コンテキストタスクに完全に活用するにはどうすればよいでしょうか?私たちは、この課題を3 つの異なるノイズ源に分解します。
- モデルノイズ(「脳の霧」):モデルは単に線形に忘却するのではなく、圧倒されてしまいます。私たちの研究では、モデルの混乱が入力長に対して超線形的に増大することが示されています。この混乱のカウントをより短い長さの新しいチャンクごとにリセットできるため、タスクを分割する方が数学的に優れています。
- タスクノイズ(「サイロ効果」):場合によっては、あるチャンク単体では意味が通じないことがあります(例えば、前の章を指す代名詞など)。この「チャンク間依存関係」は、テキストを分割した際にノイズを生み出します。
- アグリゲーターノイズ(「悪い要約」):作業者たちが職務を果たしていても、最終的なマネージャーモデルが部分的な回答を正しくつなぎ合わせられない可能性があります。単純な「MapReduce」アプローチは、アグリゲーターノイズのためにしばしば失敗します。つまり、マネージャーが文脈を欠いているため、最終的な答えが散漫だったり一貫性がなかったりしてしまうのです。私たちのフレームワークでは、より明確な指示を通じてこのノイズを低減すれば、 weaker モデルの力を解き放つことができると予測しています。
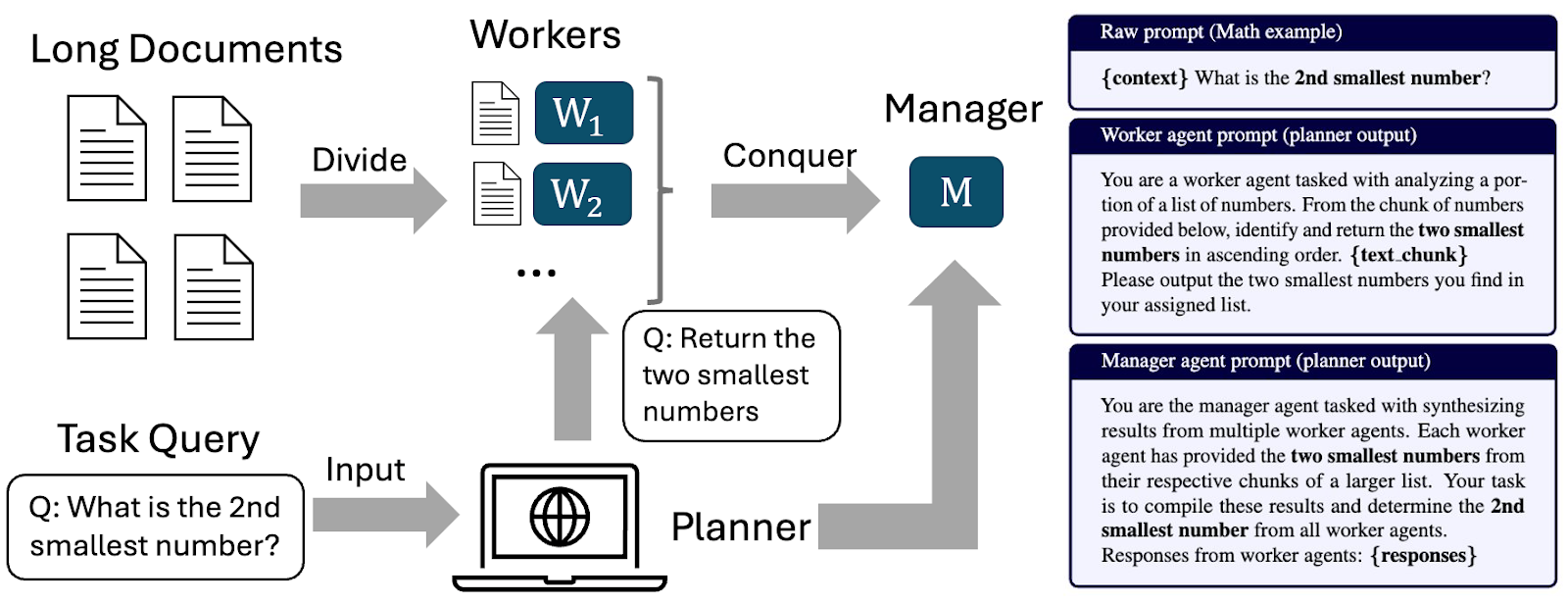
「2 番目に小さい数」の例: 作業者が巨大なリストから 2 番目に小さい数を見つけるのを手伝うタスクを考えてみましょう。単純に各チャンクに対して「2 番目に小さい数を見つけよ」と指示すると、最終的なマネージャーは失敗します。なぜなら、グローバル(全体)で 2 番目に小さい数が、特定のチャンク内では*最小の*数である可能性があるからです。
- 素朴なプロンプト:「2 番目に小さい数を見つけよ。」(失敗する)
- 計画されたプロンプト:「2 つの最も小さい数を特定し、返してください。」
単にこの集約ノイズを考慮するようにプロンプトを調整するだけで、マネージャーはグローバルな回答を計算するための適切なデータを確保できます。
実験による理論の検証
私たちは、このフレームワークの実装を多様なタスク(検索、QA、要約など)でテストしました。以下に示す通り、このフレームワークを使用する weaker モデル(例:Llama-3-70B や Qwen-72B)は、GPT-4o が全文を一括処理するよりも優れたパフォーマンスを発揮します。単一ショットモデル(赤い破線)はコンテキスト長が増加するにつれて性能が低下しますが、D&C モデル(Divide & Conquer モデル)は高いパフォーマンスを維持します。
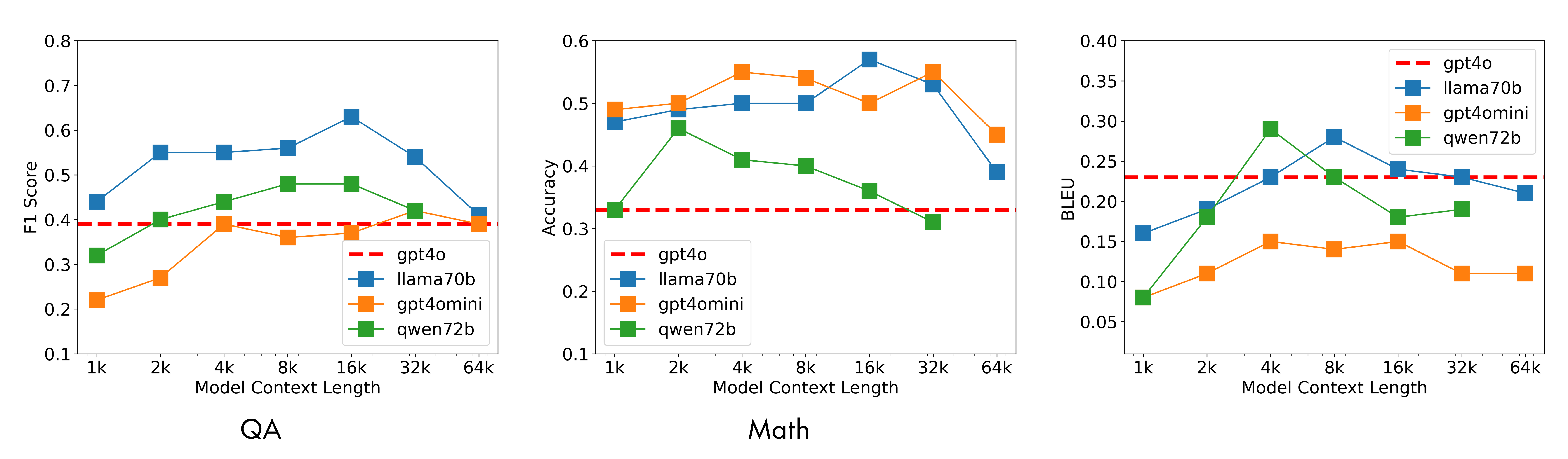
赤い破線は、GPT-4o が全文を一括処理している様子を示しています。色付きの線は、計画機能付きの Divide & Conquer(分割統治)を採用した小規模モデルです。適切なチャンクサイズを選べば、 weaker モデルが一貫して勝利することがわかります。
エンジニアリング上の利点
エンジニアリングの観点から、このフレームワークは3つの大きな実用的なメリットを提供します:
- より安価:重労働をフラッグシップトークンの支払いではなく、より小さく安価なモデル(ワーカー)に任せることで実現します。
- より高速:ワーカーは並列で実行されるため、単一のシリアルパスで巨大な 128k トークンコンテキストを処理する際の高いレイテンシーを回避できます。
- 調整が容易:ノイズカーブの予測可能性により、最適なチャンクサイズを見つけるにはランダムサンプリング 5 件を試すだけで十分であることが分かりました。データセット全体にわたる網羅的な検索を実行する必要はありません。また、当フレームワークは異なる LLM バックエンドを割り当てることでワーカーとマネージャーの結合を解離できるという柔軟性も提供します。
注意点:いつ「単一ショット」方式を「分割統治」方式に代えて使うべきか
この手法は万能薬ではありません。クロスチャンク依存関係が中程度である QA(質問応答)、Retrieval(検索)、Summarization(要約)などのタスクにおいて最も効果を発揮します。しかし、タスクノイズが支配的になる場合にはその恩恵は終わります。例えば、1 ページ目の微妙な手がかりを 100 ページ目まで追跡して接続する必要があるタスク(当論文の「対話キャラクター推論」タスクなど)の場合、「分割」ステップによって必要なコンテキストが分断されてしまいます。このような高相乗効果を持つケースでは、図書館全体を読み込む「天才」モデルを使うことが唯一の解決策となります。詳細は当論文をご覧ください。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文ここに挿入(ローラム・イプサム・ドロール・サイト・アメット)
- 箇条書き項目ここに挿入(ローラム・イプサム)
- 箇条書き項目ここに挿入(ローラム・イプサム)
- 箇条書き項目ここに挿入(ローラム・イプサム)
インフラストラクチャ
最適用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- ローラム・イプサム・ドロール・サイト・アメット、コンセクテタル・アドピシシング・エリート、セド・ド・エウスム・テンポル・インシディディット。
- ローラム・イプサム・ドロール・サイト・アメット、コンセクテタル・アドピシシング・エリート、セド・ド・エウスム・テンポル・インシディディット。
- ローラム・イプサム・ドロール・サイト・アメット、コンセクテタル・アドピシシング・エリート、セド・ド・エウスム・テンポル・インシディディット。
リスト項目 #1
ローラム・イプサム・ドロール・サイト・アメット、コンセクテタル・アドピシシング・エリート、セド・ド・エウスム・テンポル・インシディディット・ウト・ラボーレ・エト・ドロレ・マグナ・アリクァ。ウト・エニム・アド・ミニム・ヴェニアム、キス・ノストル・エクセルシタティオン・ウルラムコ・ラボリス・ニシィ・ウト・アリキップ・エク・エー・コモド・コンセクワット。
構築
含まれるメリット:
- ✔ プラットフォーム利用料として最大 15,000 ドルの無料クレジット*が付与されます
- ✔ フォワードデプロイされたエンジニアリングの時間として最大 3 時間の無料利用が可能となります。
資金調達額:500 万ドル未満
Build(ビルド)
付帯特典:
- ✔ プラットフォーム利用料として最大 15,000 ドルの無料クレジット*が付与されます
- ✔ フォワードデプロイされたエンジニアリングの時間として最大 3 時間の無料利用が可能となります。
資金調達額:500 万ドル未満
Build(ビルド)
付帯特典:
- ✔ プラットフォーム利用料として最大 15,000 ドルの無料クレジット*が付与されます
- ✔ フォワードデプロイされたエンジニアリングの時間として最大 3 時間の無料利用が可能となります。
資金調達額:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に記述してください。推論を行う際は、以下のルールに従ってください:推論中はアラビア語でのみ回答し、他の言語は使用できません。
ここに質問があります:
ナタリアさんは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数を販売しました。ナタリアさんが 4 月と 5 月の合計で販売したクリップの総数は何個ですか?
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文はここに lorem ipsum dolor sit amet
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と低い運用コスト
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
構築
含まれる特典:
- ✔ プラットフォームクレジット最大 15,000 ドル無料*
- ✔ フォワードデプロイされたエンジニアリング時間 3 時間無料。
資金調達:500 万ドル未満
構築
含まれる特典:
- ✔ プラットフォーム利用料として最大 15,000 ドルの無料クレジット*が付与されます
- ✔ フォワードデプロイされたエンジニアリングの時間として最大 3 時間の無料利用が可能となります。
資金調達額:500 万ドル未満
構築(Build)
付帯特典:
- ✔ プラットフォーム利用料として最大 15,000 ドルの無料クレジット*が付与されます
- ✔ フォワードデプロイされたエンジニアリングの時間として最大 3 時間の無料利用が可能となります。
資金調達額:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer>* のタグ内に記述してください。推論は以下のルールに従って行ってください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。
ここに質問があります:
ナタリアさんは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数を販売しました。ナタリアさんが 4 月と 5 月の合計で販売したクリップの数は何個ですか?
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
原文を表示
TL;DR
The Intuition: Don't ask one genius to read a library in an hour. Ask ten interns to read one book each.
Our research, "When Does Divide and Conquer Work for Long Context LLM?" (ICLR 2026), introduces a framework to study this. We found that smaller models using a strategic "Divide & Conquer" design can match or beat GPT-4o single-shot on long context tasks.
Modern LLMs increasingly support massive context windows like 128K, 200K, even 1M+ tokens. This theoretically unlocks powerful use cases like analyzing entire codebases or summarizing full books in a single prompt.
However, the promise of "just throw everything into one prompt" frequently fails in practice. As context length grows, performance degrades in unexpected ways. “Divide and Conquer” turns out to be an attractive solution to long context tasks, as shown in the figure below.
In our paper, we found that weaker models using a carefully designed "Divide & Conquer" framework can match or beat GPT-4o single-shot on long context tasks.
The core problem: The "fog" of length
How can we fully leverage the power of such a “Divide and Conquer” approach for long context tasks? We break the challenge down into three distinct sources of noise:
- Model Noise (The "Brain Fog"): Models don't just forget linearly; they get overwhelmed. Our research shows that model confusion grows superlinearly with input length. It is mathematically better to split the task because you reset that confusion counter with every new chunk in a shorter length
- Task Noise (The "Silo Effect"): Sometimes, a chunk doesn't make sense on its own (e.g., a pronoun referring to a previous chapter). This "Cross-Chunk Dependence" creates noise when the text is split.
- Aggregator Noise (The "Bad Summary"): Even if the workers do their jobs, the final manager model might fail to stitch the partial answers together correctly.
Naive "MapReduce" approaches often fail because of Aggregator Noise i.e. the final answer is messy or inconsistent because the manager lacks context. Our framework predicts that if you reduce this noise through clearer instructions, you can unlock the power of weaker models.
The "2nd Smallest Number" Example: Consider a task where workers must help find the 2nd smallest number in a massive list. If you naively ask workers to "Find the 2nd smallest number" in their specific chunk, the final manager will fail because the global 2nd smallest number might be the *smallest* number in a specific chunk.
- Naive Prompt: "Find the 2nd smallest number." (Fails)
- Planned Prompt: "Identify and return the two smallest numbers."
By simply adjusting the prompt to account for this aggregation noise, we ensure the Manager has the right data to calculate the global answer.
Validating the theory with experiments
We tested this framework implementation across diverse tasks (retrieval, QA, summarization, etc.). As shown below, a weaker model using this framework (e.g., Llama-3-70B or Qwen-72B) outperforms GPT-4o reading the whole text in one shot. While the single-shot model (red dashed line) degrades as context length increases, the D&C models maintain high performance.
The engineering wins
From the engineering perspective, this framework offers three massive practical benefits:
- Cheaper: You move the heavy lifting to smaller, cheaper models (Workers), rather than paying for flagship tokens.
- Faster: Workers run in parallel. You avoid the high latency of processing a massive 128k token context in a single serial pass.
- Easy to tune: We found that testing just 5 random samples is sufficient to find the optimal chunk size due to the predictability of the noise curve. You don't need to run an exhaustive search over your whole dataset. The other flexibility our framework offers to decouple the worker and manager by assigning different LLM backends.
The catch: When to use single-shot instead of divide and conquer
This method is not a silver bullet. It works best for tasks like QA, Retrieval, and Summarization where cross-chunk dependency is moderate. The benefits end when Task Noise dominates. If your task requires tracking a subtle clue from Page 1 that connects to Page 100 (like the "Dialogue Character Inference" task in our paper), the "Divide" step breaks the necessary context. In these high-synergy cases, the 'genius' model reading the whole library is still the only way to go. Please find more details in our paper.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み