Gemma 4 12B:開発者ガイド
Google は、従来の複雑なエンコーダーを排除し音声入力をネイティブにサポートする「Gemma 4 12B」を発表し、ローカル環境での高度なマルチモーダル処理を可能にした。
キーポイント
ユニファイド・エンコーダーレスアーキテクチャの採用
従来の別個のビジョン/オーディオエンコーダーを廃止し、LLM バックボーンに直接入力を流すことでレイテンシとメモリフットプリントを大幅に削減した。
ミディアムサイズモデルにおけるネイティブ音声入力の実現
Gemma ファミリにおいて、初めて 12B というミディアムサイズモデルが音声入力をネイティブに処理可能となり、エッジアーキテクチャの限界を打破した。
ローカル推論のための最適化と macOS アプリ公開
16GB VRAM のラップトップで動作可能なサイズであり、マルチトークン予測モデル(MTP)や専用デスクトップアプリの提供により、開発者のローカル利用を強化した。
エンコーダーフリーな統一アーキテクチャ
ビジョンとオーディオ入力を個別のエンコーダー(Transformer や Conformer)に依存せず、LLM の隠れ次元へ直接投影する軽量な埋め込み層を採用しています。
単一パスでの統合ファインチューニング
テキスト、画像、音声の入力が同じ重みを共有するため、LoRA やフルチューニングを適用する際に別々の凍結エンコーダーの調整が不要になり、マルチモーダルな学習ループを一度に更新できます。
多様な高度な機能の実装
自動音声認識、エージェント推論、話者分離、動画理解、コーディングなど、単一モデルで複数の複雑なタスクを実行できる能力を備えています。
エージェント機能と既存ハルネスとの連携
Gemma 4 12B はエージェントおよび多モーダル理解能力を備えており、OpenCode などの既存のエージェントハルネスと容易に統合可能です。
重要な引用
Bypassing heavy multi-stage vision and audio encoders entirely, multimodal data is fed straight into the LLM backbone
Gemma 4 12B is the first medium-sized model capable of natively ingesting audio.
Small enough to run locally on dedicated GPU laptops with 16GB VRAM or unified memory.
Because vision, audio, and text inputs share the exact same weights, you no longer have to co-tune separate frozen encoders.
Gemma 4 12B achieves outstanding performance, with capabilities such as automatic speech recognition, agentic reasoning, diarization, video understanding, coding, and more.
Essentially, the man is not actually taking a selfie; rather, he is **acting out a visual metaphor for the AI's capability to take one specific input (a "selfie") and generate a whole world of new content based on it.**
影響分析・編集コメントを表示
影響分析
この発表は、ローカル AI デバイスにおけるマルチモーダル処理の効率性と実用性を飛躍的に高める画期的な進展です。特にエンコーダーレスアーキテクチャの採用は、計算リソースを節約しつつ低遅延を実現する新たな標準となり、エッジデバイスでの高度な AI 応用開発を加速させるでしょう。
編集コメント
従来のマルチモーダルモデルが抱えていたアーキテクチャ上の非効率性を、根本から再設計した点に大きな意義があります。開発者がローカル環境で高品質な音声・画像処理を即座に試せる環境が整ったことは、AI アプリケーションの実装スピードを劇的に加速させるでしょう。
2026 年 6 月 3 日
ローンチブログで発表いたしました通り、Gemma 4 12Bをリリースいたします。これは、統一されたエンコーダーフリーアーキテクチャを持つ密なマルチモーダルモデルです。
Gemma 4 12B は、ローカル AI においていくつかの画期的なマイルストーンをもたらします:
- マルチモーダル・エンコーダーフリーアーキテクチャ:重厚な多段階のビジョン(画像認識)およびオーディオエンコーダを完全に迂回し、マルチモーダルデータを直接 LLM のバックボーンに投入することで、マルチモーダル処理の遅延を削減します。
- オーディオ入力をサポートする初のミディアムサイズモデル:Gemma ファミリにおいて、オーディオ入力はこれまで小規模で軽量なエッジアーキテクチャ(例:E4B)に限られていました。Gemma 4 12B は、ネイティブにオーディオを処理できる初のミディアムサイズモデルです。
- デベロッパーフレンドリーなサイズ:VRAM 16GB の専用 GPU ラップトップやユニファイドメモリを搭載した端末でローカル実行が可能なほど小型です。ローカル推論速度の最大化のため、さらに専用のマルチトークン予測(MTP: Multi-Token Prediction)モデルも併せてリリースします。
- 新しい macOS デスクトップ体験:初めてダウンロード可能な macOS 用デスクトップアプリケーションをリリースし、開発者が消費者向けデバイス上で完全にローカルの音声および視覚的インタラクションを直接体験できるようにしました。
アーキテクチャ
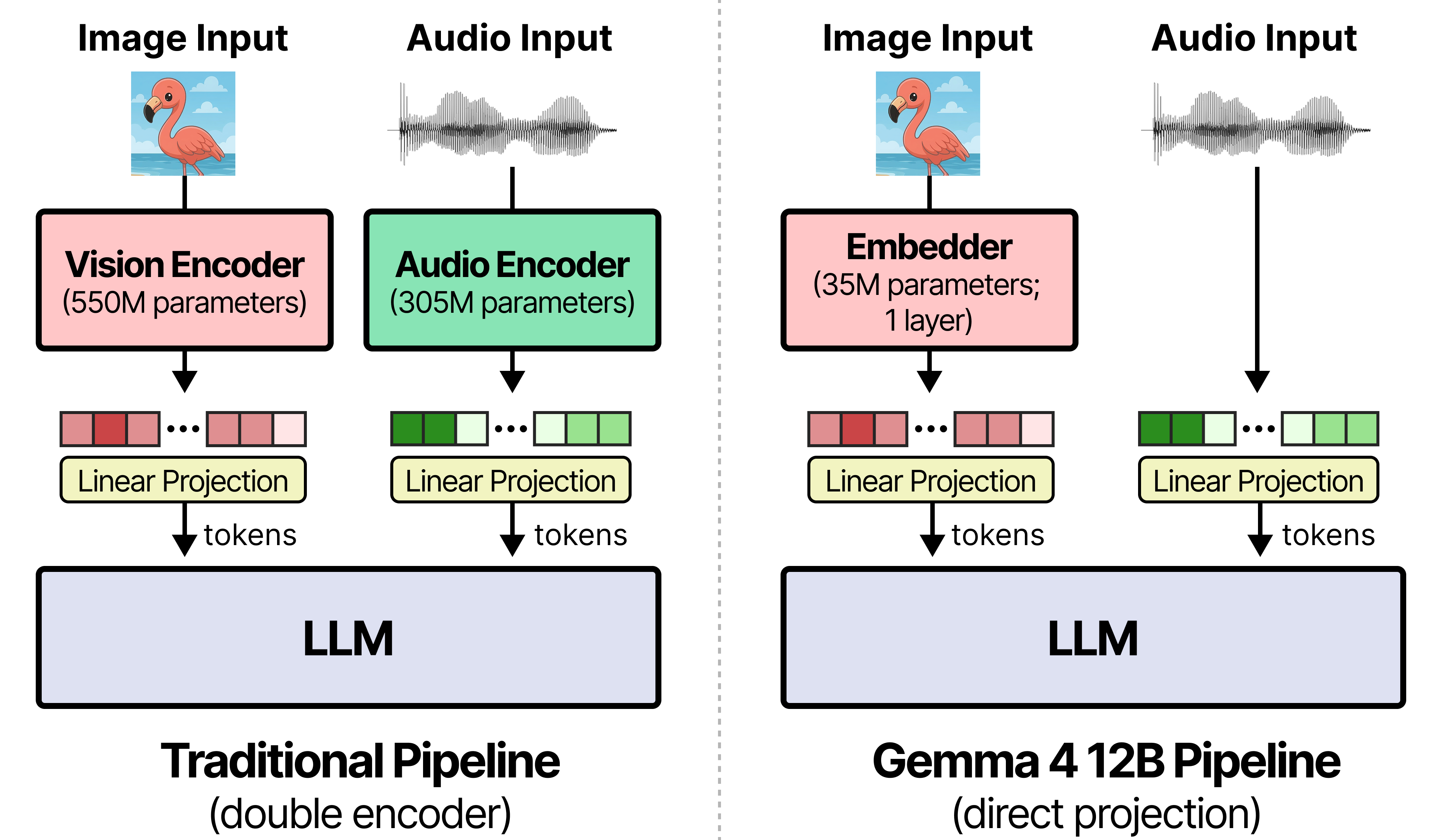
従来のマルチモーダルモデルは、凍結された別々のビジョンエンコーダー(例:Gemma 4 ではエッジサイズ向けに 1.5 億パラメータのビジョンモデルを、中規模モデル向けには 5.5 億パラメータを使用)およびオーディオエンコーダー(Gemma 4 E2B および E4B で 3 億パラメータ)に依存しています。複数の別々のエンコーダーでマルチモーダル入力を処理してから大規模言語モデル(LLM)に供給すると、レイテンシが増加し、メモリフットプリントが断片化するという問題が生じます。
Gemma 4 12B は、Gemma 4 31B Dense モデルと同じ高度なデコーダー構造を備えた単一のデコーダー専用トランスフォーマーを採用することで、これらの課題を解決します。
 image
image
- ビジョン埋め込み層(35M パラメータ):他の中規模 Gemma 4 モデルの 27 レイヤーからなるビジョントランスフォーマーを置き換えます。生データである 48x48 ピクセルのパッチは、単一の行列乗算で LLM の隠れ次元へ投影されます。因子分解された座標ルックアップ(X 行列と Y 行列)により、空間位置情報が直接入力に付与されます。
- オーディオ波形投影:個別のオーディオエンコーダを不要とし(Gemma 4 E2B および E4B で使用される 12 レイヤーのコンフォーマー層をスキップ)、生データである 16 kHz の音声信号を 40ms フレームに分割し(各フレームは 640 個の浮動小数点数)、LLM の入力空間へ線形投影します。
- 統一ファインチューニングの利点:ビジョン、オーディオ、テキストの入力が完全に同じ重みを共有するため、個別の凍結エンコーダを共同で調整する必要がなくなります。ダウンストリームアダプタ(例:LoRA)またはフルチューニングにより、多モーダルトークンループ全体が単一のパスで自然に更新されます(Hugging Face または Unsloth を介して)。このエンコーダフリーアーキテクチャの動作の詳細な概要については、Gemma 4 12B の視覚的ガイドをご覧ください。
機能
Gemma 4 12B は、自動音声認識、エージェント推論、話者分離、動画理解、コーディングなど、優れたパフォーマンスと多様な機能を発揮します。
モデルのエージェント機能および多モーダル能力のデモンストレーションについては、以下の例をご覧ください:
例 1: Gemma 4 12B が Gemma 4 12B を使用したローカル画像処理アプリを作成
申し訳ありませんが、お使いのブラウザはこのビデオの再生をサポートしていません。
そのエージェント機能と多様な理解能力により、Gemma 4 12B は OpenCode などの既存のエージェント・ハーンセスと簡単に連携して使用できます。この例では、gemma-skills を用いて Gradio アプリをコーディングし、ユーザーが画像を処理できるようにしました。このアプリは、自身を構築したのと同じ Gemma 4 12B モデルによって駆動されています!
例 2: 音声付きで 1 FPS の 5 分間のビデオを処理する
Gemma 4 12B を使用して、5 月 19 日の Google IO キーノート の一部(00:15:32 から 00:20:45 の 5 分間)を分析しました。そのために、該当セグメントの全フレーム(1 FPS で抽出)、プロンプト、およびビデオからの音声を抽出しました:
プロンプト:
- 313 フレーム(1FPS、画像は視覚トークン予算 70 にリサイズ)
- 「男がセルフィーを撮るとどうなるか?」
- ビデオの音声と以下のプロンプト
これらのデモ動画で男が「セルフィー」を撮っている、あるいは顔の前にスマートフォンを持って示している様子は、AI モデルが既存のメディア(個人の写真やビデオクリップなど)を取得し、「再想像」する能力を視覚的に表現するための巧妙な方法です。これらの特定のクリップでは、モデルはセルフィーを取得し、それをベースとしてさまざまなシナリオ(宇宙ステーションにいる人物や森の中を歩く人物など)を生成しています。本質的には、男は実際にセルフィーを撮っているのではなく、「1 つの特定の入力(『セルフィー』)を受け取り、それに基づいて新しいコンテンツの世界全体を生成する」という AI の能力に対する視覚的な比喩を演じている**のです。これは Gemini Omni モデルにおける「Swap(置換)」および「Build worlds(世界の構築)」デモの一部であり、複雑な多モーダル推論と創造的生成を実行する能力を示すものです。
On-Device & Desktop Serving: Powered by LiteRT-LM
Gemma 4 12B のローンチに併せて、LiteRT-LM を基盤とした強力なオンデバイス向け開発者統合を正式に導入します。これにより、標準的なデスクトップ環境においてネイティブでゼロ遅延のローカル AI 実行が可能になります:
- 313 フレーム(1FPS、画像は視覚トークン予算 70 にリサイズ)
- 「男がセルフィーを撮るとどうなるか?」
- ビデオの音声と以下のプロンプト
**これらのデモ動画で男が「セルフィー」を撮っている、あるいは顔の前にスマートフォンを持って示している様子は、AI モデルが既存のメディア(個人の写真やビデオクリップなど)を取得し、「再想像」する能力を視覚的に表現するための巧妙な方法です。これらの特定のクリップでは、モデルはセルフィーを取得し、それをベースとしてさまざまなシナリオ(宇宙ステーションにいる人物や森の中を歩く人物など)を生成しています。本質的には、男は実際にセルフィーを撮っているのではなく、「1 つの特定の入力(『セルフィー』)を受け取り、それに基づいて新しいコンテンツの世界全体を生成する」という AI の能力に対する視覚的な比喩を演じているのです。これは Gemini Omni モデルにおける「Swap(置換)」および「Build worlds(世界の構築)」デモの一部であり、複雑な多モーダル推論と創造的生成を実行する能力を示すものです。
On-Device & Desktop Serving: Powered by LiteRT-LM
Gemma 4 12B のローンチに併せて、LiteRT-LM を基盤とした強力なオンデバイス向け開発者統合を正式に導入します。これにより、標準的なデスクトップ環境においてネイティブでゼロ遅延のローカル AI 実行が可能になります:
1. ネイティブ MacOS アプリ: モバイル Google AI Edge Gallery が公式にデスクトッププラットフォームへ拡張され、Apple Silicon GPU 上で Gemma 4 12B をオフラインかつネイティブで実行できるようになりました。チャットバブル内で科学的なチャートの作成・実行・プロットを行うための、安全なサンドボックス化された Python 実行ループを備えています。並行して、Mac 向けの Google AI Edge Eloquent アプリが Gemma 12B のサポートを開始し、音声編集による会話型入力を可能にします。
Sorry, your browser doesn't support playback for this video
2. ドロップインローカル API サーバー (litert-lm serve): 新しい litert-lm serve CLI コマンド を使用して、Gemma 4 12B をローカルの OpenAI 互換 API サーバーとして実行します。メモリ内のステートレスプレフィックスキャッシュを活用してコンテキスト履歴を一致させ、事前計算(prefill)の遅延を即座に回避することで、標準的な統合(例:Continue, Aider, OpenClaw, Hermes, OpenCode)をシームレスに接続できます。
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
OpenAI 互換サーバーの起動
litert-lm serve
Shell
Copied
Google AI Edge Gallery の ブログ で詳細な解説をご覧ください。
今日から始めよう
Gemma ファミリー初のエンコーダーフリーアーキテクチャを用いて、ローカルでの多モーダルエージェント構築を始めたいですか?今日すぐに始めるための手順は以下の通りです。
- 自分で試す: LM Studio, Ollama, Google AI Edge Gallery App, Google AI Edge Eloquent アプリ、および LiteRT-LM CLI で数回のクリックで実験できます。
- ウェイトをダウンロード: 事前学習済みおよび指令微調整済みのチェックポイントを Hugging Face と Kaggle から直接ダウンロードしてください。
- 統合して学ぶ: 開発者向けドキュメントとクイックスタートノートブックを確認しましょう。
- お気に入りの開発ツールを活用する: Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM を用いてローカル推論パイプラインを実装するか、Unsloth で効率よくファインチューニングを行います。
- Gemma Skills によるエージェント開発の解放: 最新の Gemma の進展を用いたエージェント構築を支援するため、公式のスキルリポジトリを公開します。これは、Gemma モデルを用いてエージェントを構築できるように設計されたスキルのライブラリーです。
- あなたの方法でデプロイ: Google Cloud を用いて本番環境のエンドポイントを起動するか、Gemini Enterprise Agent Platform Model Garden, Cloud Run, GKE を通じてあなた自身の方法でデプロイしてください。
Previous
Next
原文を表示
JUNE 3, 2026
Following the announcement in our launch blog, we are releasing Gemma 4 12B, a dense multimodal model with a unified, encoder-free architecture.
Gemma 4 12B introduces several milestones for local AI:
- A multimodal encoder-free architecture: Bypassing heavy multi-stage vision and audio encoders entirely, multimodal data is fed straight into the LLM backbone, reducing multimodal latency.
- Our first medium-sized model with audio input: In the Gemma family, audio inputs were restricted to small, lightweight edge architectures (e.g. E4B). Gemma 4 12B is the first medium-sized model capable of natively ingesting audio.
- Developer-friendly size: Small enough to run locally on dedicated GPU laptops with 16GB VRAM or unified memory. To maximize local inference speeds, we are additionally releasing a dedicated multi-token prediction (MTP) model.
- New MacOS desktop experience: For the first time, we are releasing downloadable macOS desktop applications, letting developers experience fully local spoken and visual interaction directly on consumer-grade devices.
The Architecture
Traditional multimodal models rely on frozen, separate vision encoders (e.g., Gemma 4 uses a 150M parameter vision model for edge sizes and 550M for medium-sized models) and audio encoders (300M parameters for Gemma 4 E2B and E4B). Processing multimodal inputs with multiple separate encoders before feeding them to the LLM leads to increased latency and fragmented memory footprints.
Gemma 4 12B solves these issues by utilizing a single decoder-only transformer containing the same advanced decoder structure as the Gemma 4 31B Dense model.
- Vision embedder (35M parameters): Replaces the 27 vision transformer layers of the other medium-sized Gemma 4 models. Raw 48x48 pixel patches are projected to the LLM hidden dimension with a single matmul. A factorized coordinate lookup (X and Y matrices) attaches spatial location information directly to the input.
- Audio wave projection: Eliminates the separate audio encoder (skipping the 12 conformer layers used in Gemma 4 E2B and E4B). Raw 16 kHz audio signals are sliced into 40ms frames (640 floats each) and projected linearly to the LLM input space.
- Unified fine-tuning advantage: Because vision, audio, and text inputs share the exact same weights, you no longer have to co-tune separate frozen encoders. Downstream adapter (e.g. LoRA) or full tuning naturally update the entire multimodal token loop in a single pass (via Hugging Face or Unsloth).
For a more in-depth overview of how this encoder-free architecture works, check out A Visual Guide to Gemma 4 12B.
Capabilities
Gemma 4 12B achieves outstanding performance, with capabilities such as automatic speech recognition, agentic reasoning, diarization, video understanding, coding, and more.
See below examples for a demonstration of the model's agentic and multimodal capabilities:
Example 1: Gemma 4 12B creates a local image processing app that uses Gemma 4 12B
Sorry, your browser doesn't support playback for this video
Thanks to its agentic and multimodal understanding capabilities, Gemma 4 12B can be easily used with existing agent harnesses like OpenCode. In this example, we served it locally using llama.cpp using the gemma-skills to code a Gradio app that helped the user process images. This app was powered by the same Gemma 4 12B model that built it!
Example 2: Processing 5 minutes of Video at 1 FPS with audio
We used Gemma 4 12B to analyse a part from the Google IO Keynote moment from May 19, specifically the 5 minutes between 00:15:32 and 00:20:45. To do that, we extracted all the frames of that segment (at 1 FPS), plus the prompt and the audio from the video:
Prompt:
- 313 frames (at 1FPS, images resized to visual token budget 70)
- "what happens when the man takes a selfie?"
- the Video's audio + the prompt below
When the man takes a "selfie" or is shown holding a smartphone in front of his face in these demonstration videos, it is a clever way to visually represent how the AI models can take existing media—like a personal photo or a video clip—and "reimagine" it. In these specific clips, the model is taking a selfie and using it as a base to generate various scenarios (like a person in a space station, or walking through a forest).Essentially, the man is not actually taking a selfie; rather, he is acting out a visual metaphor for the AI's capability to take one specific input (a "selfie") and generate a whole world of new content based on it. This is part of the "Swap" and "Build worlds" demonstrations of the Gemini Omni model, showing its ability to perform complex, multi-modal reasoning and creative generation.
On-Device & Desktop Serving: Powered by LiteRT-LM
In tandem with the Gemma 4 12B launch, we are officially introducing powerful on-device developer integrations powered by LiteRT-LM, bringing zero-latency local AI execution natively to standard desktop environments:
1.Native MacOS Apps: The mobile Google AI Edge Gallery is officially expanding to desktop platforms, running Gemma 4 12B offline, natively on Apple Silicon GPUs. It comes with a secure sandboxed Python execution loop to write, execute, and plot scientific charts inside the chat bubble. In parallel, the Google AI Edge Eloquent app on Mac launches support for Gemma 12B to power Voice Edit conversational inputs.
Sorry, your browser doesn't support playback for this video
2. Drop-in Local API Servers (litert-lm serve): Run Gemma 4 12B as a local, OpenAI-compatible API server using the new litert-lm serve CLI command. Seamlessly connect standard integrations (e.g., Continue, Aider, OpenClaw, Hermes or OpenCode), leveraging stateless prefix caching in memory to match context history and instantly bypass prefill latency.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
# Start the OpenAI-compatible server
litert-lm serveShell
Copied
Find a deep dive about it on the Google AI Edge Gallery blog.
Getting Started Today
Ready to build local multimodal agents with the first encoder-free architecture of the Gemma family? Here is how you can jump in today
- Try it yourself: Experiment with a couple of clicks in LM Studio, Ollama, Google AI Edge Gallery App, the Google AI Edge Eloquent app and the LiteRT-LM CLI
- Download the weights: Download the pre-trained and instruction-tuned checkpoints directly from Hugging Face and Kaggle.
- Integrate & learn: Review the developer documentation and the quick start notebook.
- Use your favorite development tools: Implement local inference pipelines with Hugging Face Transformers, llama.cpp, MLX, SGLang, and vLLM, or fine-tune with efficiency using Unsloth.
- Unlock Agentic Development with Gemma Skills: To support agents to build with the latest Gemma advancements, we are releasing our official Skills Repository. This is a library of skills designed specifically to enable agents to build with Gemma models.
- Deploy your way: Spin up endpoints in production using Google Cloud. Deploy your way through Gemini Enterprise Agent Platform Model Garden, Cloud Run and GKE.
Previous
Next
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み