GLM-5.2 はオープンエージェントにおける大きな一歩となる
Z.ai が公開した GLM-5.2 は、ベンチマークやエージェント性能において OpenAI や Anthropic の最新モデルに匹敵する成果を示し、オープンソース領域における重要な転換点となった。
キーポイント
GLM-5.2 の市場での地位と評価
Moonshot AI や Z.ai が作るモデルがトップの信頼性を獲得しており、GLM-5.2 はマイナーなバージョンアップに見えてユーザー体験の閾値を越える実力を持つ。
コミュニティによるベンチマークでの快挙
Arena のエージェントリーダーボードでは OpenAI や Anthropic の最新モデルと互角に戦い、特に Claude Fable 5 をデザイン領域で上回る結果を記録した。
戦略的なリリースタイミングの意義
Anthropic の輸出規制やクローズド化への反動として、週末にこっそりリリースし「オープンサイエンス」への回帰をアピールするマーケティング戦術が功を奏した。
技術的特徴と運用の推奨
MIT ライセンスで公開され、SLIME という RL フレームワークを採用しており、「Max thinking effort」モードでの使用が強く推奨されている。
GLM-5.2 のベンチマークでの圧倒的パフォーマンス
ArenaのリーダーボードではOpenAIやAnthropicの最新モデルと互角に戦う唯一のオープンモデルであり、Design ArenaではClaude Fableさえも凌駕しました。
オープンソースにおける歴史的転換点
DeepSeek R1以上のインパクトを持ち、少ないリソースで複雑な推論モデルを再現できることを示し、AI 開発の「片道門」となるような変化をもたらしました。
コーディング環境での実用性と信頼性
GLM-5.2 はコードハッチングで動作する一般的なエージェントとして初めて機能し、Fireworks API を通じた実際の作業でも即座にその能力が実感されました。
影響分析・編集コメントを表示
影響分析
この記事は、オープンソース LLM の性能がクローズドモデルを凌駕する転換点(Tipping Point)に達したことを示唆しており、開発者や企業がプロプライエタリなモデルからオープンウェイトモデルへ移行する動機を強化します。特にエージェント機能における実用性の向上は、AI 研究コミュニティの方向性を「クローズド化」から「オープンかつ高性能なエコシステム構築」へと再定義させる可能性があります。
編集コメント
「マイナーなバージョンアップ」と見られがちだが、実際には業界のバランスを大きく揺るがす性能向上を示した GLM-5.2 の登場は、オープンソース AI の新たな黄金時代への布石である。特にエージェント機能における実用性の突破は、開発現場での採用基準を根本から変える可能性を秘めている。
おまけ:先週の「ブログの現状」投稿で有料機能のわずかな増加に触れましたが、今こそグループ購読についてお知らせする好機です。利用席数に応じて比例したより大きな割引を提供しています。
また本日、ターミナルエージェント向けのオープン RL レシピに関する新しい論文を公開しました。詳しくはこちらをご覧ください。
約 1 週間前、AI 界隈が Claude Fable 5 の衝撃的な輸出規制と実質的な禁止令からまだ動揺していた頃、Z.ai は最新モデル GLM-5.2 をリリースしました。このモデルは通常とは異なり、6 月 13 日(土曜日)に GLM Coding Plan のメンバー向けに展開されました。AI モデルが週末にリリースされるのは通常、何か奇妙な理由がある場合です(最も有名な例として Llama 4 が挙げられます)。今回は、Z.ai が AI 研究者に対する沈黙のセーフガードを持つ「Anthropicがオープンサイエンスに反対している」という時代の空気を活用することに興奮していたように見えました。過去 1〜2 年間、中国のオープンウェイトラボは、このような簡単なマーケティング勝利のためにあらゆる機会を逃さず利用してきました。
シェア
業界全体で共通の命名規則に従う GLM-5.2 は、人気のある GLM-5.1 モデルに続くものとして、一見すると漸進的なアップデートに見えるかもしれません。現時点では、Kimi モデルを開発する Moonshot AI と、GLM モデルを開発する Z.ai が、AI 研究者の間で最も愛されているオープンウェイトモデルによって、評判市場の頂点を独占しています。ここで明らかになったのは、AI モデルを追跡する際の共通の教訓です。しばしばマイナーバージョン番号の違いが、意味のあるユーザー体験の閾値を超える AI モデルを生み出すことがあります。ベンチマークやトレーニングにおける小さな変化が、広範な新たなユースケースを開く可能性があります。
その後に続いたのは、GLM-5.2 に対するゆっくりとした、しかし確実な高揚感です。公式の MIT ライセンスモデル重みとリリースブログは、初期ロールアウトから3日後の6月16日に公開されました。強力なベンチマークスコアや、Z.ai が使用する非常に人気のある RL フレームワーク(SLIME)、常に Max 思考努力でモデルを使用するよう推奨することなど、多くの技術的詳細について語ることができますが、初期リリースブログに焦点を当てるべきではありません。それが本物かどうかを知るには、エコシステムからの反応を待って読む必要があります。いずれにせよ、ベンチマークは現在では半ば死んでいます。
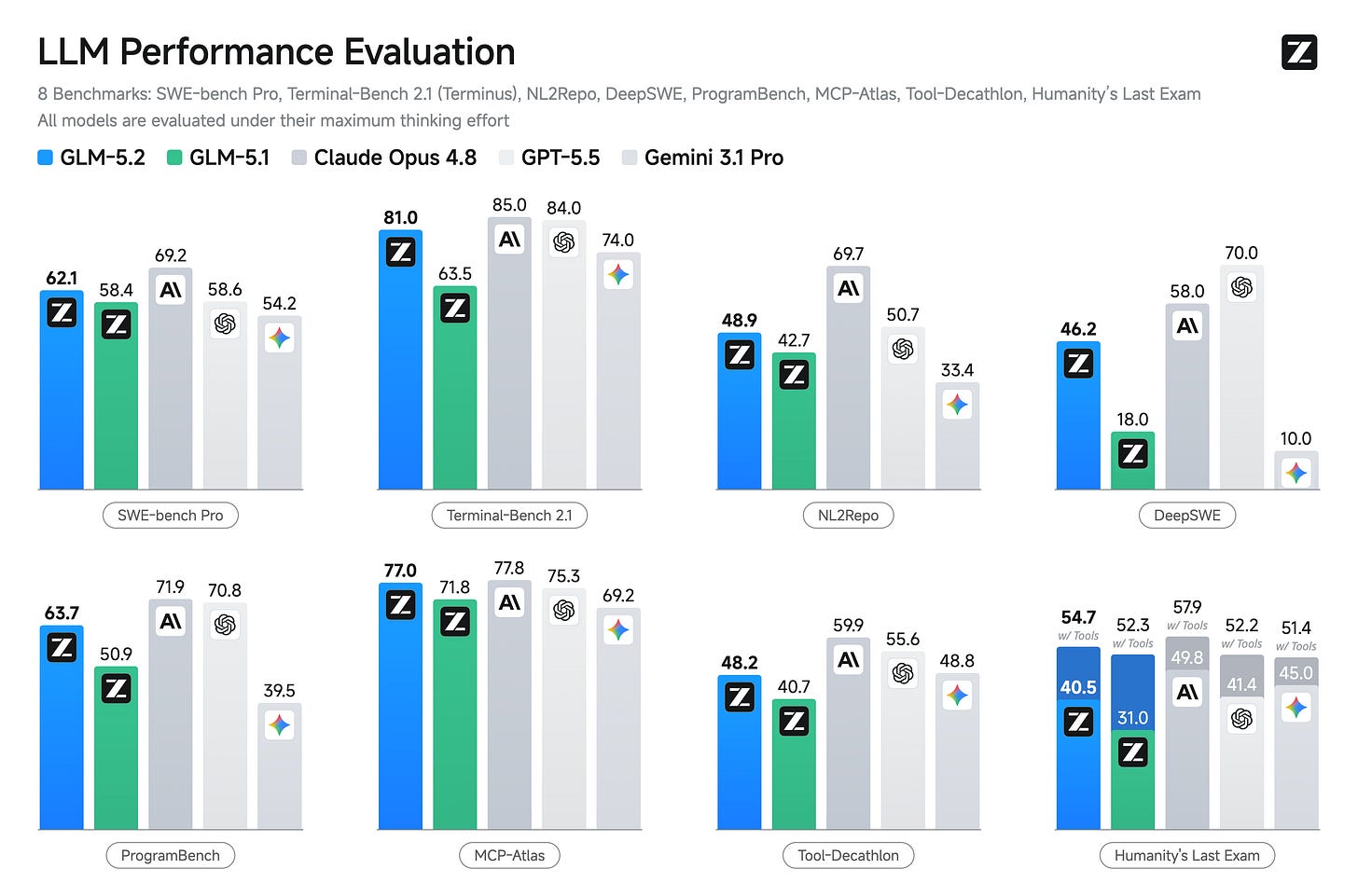
16 日に続いて発表された一連のコミュニティベンチマークでは、GLM-5.2 が予想を上回る結果を示しました。Arena のエージェントリーダーボードでは、GLM-5.2 は OpenAI や Anthropic の最新モデルと互角に渡り合える唯一のオープンモデルとして位置づけられています(特に、Opus 4.8 の「思考なし」モードに対する GLM-5.2 の最大モードでのパフォーマンスが注目されています)。これは GLM-5.2 が Gemini を圧倒している評価項目の一つに過ぎませんが、この話題はまた別の機会に取り上げましょう。コミュニティ内、特に実際のデザイナーの間で評価が分かれているベンチマークである Design Arena では、GLM-5.2 が Claude Fable 自体を凌駕したという結果さえ出ています。Claude Fable とは、最近禁止されたばかりの過剰な hype を生み出す機械のことです。
私が信頼する AI コメンテーターや研究者層のほぼ全員が、実際に使用した後でこのモデルを称賛しています。コミュニティ内でこれほど明確に議論の焦点となったのは、オープンモデルとしてリリースされたのが DeepSeek R1 の時以来のことです。私は安易に比較はしていませんが、Kimi K2 のリリースを「DeepSeek Moment」と表現した際と比較しても、GLM-5.2 はそれを遥かに上回る成果を上げています。Kimi K2 が印象的だったのは、オープンモデルのパフォーマンスにおける大きな飛躍が、中国のどこからでも現れ得る可能性があることを示した点でした。しかし、GLM-5.2 によってなされた一歩は、AI の進歩にとって一方通行の扉のようなものです。
Claude Code を背景とした Anthropic の記録的な収益成長率は、同社が最良のモデルであり、実際にこれを実行できる唯一のモデルであることに強く支えられています。GLM-5.2 は、まもなく登場する多数のオープンウェイトモデルのうち、信頼できる代替案を提供する最初のものです。この状況は非常に明確で、DeepSeek R1 が、リソースがはるかに少ないオープンウェイト研究所でも、OpenAI が o1 で推進した思考連鎖推論モデルを再現可能であることを示した時と似ています。AI システムがより複雑になり、ツールや統合されたハルネス、スケールされたモデル重みにより構築コストが大幅に高騰する中、この GLM-5.2 の瞬間が実際に起こるかどうかは確実ではありませんでした。
重要な点は、GLM-5.2 がオープンウェイトモデルとして、汎用エージェントのコーディングハルネスにおいて最も適切に機能していることです。これが最初の事例です。私は個人的に、Kimi K2.7 や GLM-5.1 といった最近の競合モデルを試すのが遅れていましたが、その評判は無視できるものではありませんでした。Fireworks の API を使用して Claude Code でポストトレーニングコース用のコンテンツ作成を支援させるために実際に導入しました(設定は非常に簡単でした)。いくつかの小さな問題もありました。例えば、Claude Code ハルネスや私のリポジトリドキュメントがモデルに画像を送ろうとした際、セッション中に Fireworks API がフリーズし、手動でコンテキストをクリアする必要がありました。全体的に、モデルの能力は直感的に適切に感じられましたが、どのハルネスと推論プロバイダーを使用するかについては、まだ微調整が必要です。
さらに注目を集めるために、Z.ai の創業者が Elon に対して「オープンウェイトの Fable 機能は 2027 年第 1 四半期よりも早く登場する」と述べている様子や、Vercel の CEO が「@zai_org による GLM-5.2 のコーディング能力に本当に感銘を受け、ほぼ驚愕している。これが状況を根本から変える」と語っている様子をサンプリングできます。また、私が深く信頼する人々の意見と、まだあまり知らない人々の意見を織り交ぜた内容も多数含まれています。
Interconnects AI は読者支援型の出版物です。購読者になっていただくことを検討してください。
さて、これは優れたモデルですが、これが私たちに何を残すのでしょうか?
多くのトレンドが作用しています。まず、オープンとクローズドの能力差という文脈で話を始めましょう。私は以前、オープンモデルが Claude Code における Opus 4.5 の閾値を2026年初頭から突破すれば、「利用爆発」が起こると予想すると記しました。まさに今、その時が来ています。Claude Opus 4.5 が2025年11月24日にリリースされ、GLM-5.2 が2026年6月16日にリリースされるまでの期間差は204日、つまり約6.8ヶ月です。これは、多くの人が米国のクローズドラボと中国のオープン対応モデル間の性能遅れとして主張する「6〜9ヶ月」という時間差の真ん中に私たちを位置づけます。
⟦CODE_0⟧
この文章を書くにあたり、私は驚いています。米国の研究機関がこの約1年間で計算資源を急速に拡大してきたにもかかわらず、性能の格差は時間とともに広がると予想していました。この軌道上における非常に重要な一歩として、Claude Fable 5 のリリースも挙げられますが、これは Claude Opus モデルと比較して規模への依存度が高く、したがって最も先進的な GPU を必要とするものです。それでもなお、それは満足できる答えではありません。ここでの軌道をさらに解きほぐすには、目次記事に収めることができないほどの微妙なニュアンスが含まれています。
この現象の最も直接的な意味は、組織内におけるトークン数の最大化(tokenmaxxing)に伴う価格競争の激化であり、Anthropic の収益が急上昇することです。一部の予測では Anthropic が予想された ARR 数値を達成できないとされていますが、私はこれらのモデルに対する真の需要と避けられない成長を価格に反映しているとは考えません。このモデルが存在することは、オープンモデルエコノミーにとって大きな恩恵となります。Fireworks、Together、Thinky(Tinker を経由)、Prime Intellect、およびオープンモデル推論やファインチューニングを販売する他のすべての企業は、新たな転換点に達しました。
ここでの効果が広範な経済やユースケースに浸透するには長い時間がかかるでしょう。ワークフローはより複雑化しており、人々は計画用、主要コーディング用、サブエージェントの派遣用に異なるモデルを使用しています。私はこの過熱がさらに高まると予想していますが、なんといっても日曜日の夜にこれを書いている今、月曜日のメディアや市場の反応が DeepSeek R1 のリリース時と同じようなものになるのも不思議ではありません。Anthropic の、ひいては米国のフラッグシップモデルがまだ禁止されている間にこの浸透が進むことは、深刻な経済的な打撃となります。GLM-5.2 は、フロンティア・ラボらが絶対的なフロンティア・モデルによってのみ可能となる高マージン、高収益の領域へと前進しようとしている際に、その経済的裏側を切り開く時間を得ています。
この経済への懸念は、AI において何度も語られてきた物語と類似しており、いつ定着するかは不透明です。
AI の軌道にとってより核心的な対話は、オープンモデルの規制と管理に関するものです。安価な知能が広く浸透することは経済的に有益であり、私たちのデフォルトの立場はオープンモデルを応援することであるべきですが、このモデルのリリース日は、AI パワー構造のメンタルマップにおいて Claude Fable — したがって Claude Mythos — と永久に結びつけられることになります。私たちは今や、Mythos クラスのモデル能力が米国政府によってリリースには安全ではないと判断される一方で、中国のモデルメーカーはすべての人に利用可能な能力で前進しているという局面にあります。
これらの傾向線は必ずしも因果関係があるわけではありません。GLM-5.2 とその先行モデルのサイバーパフォーマンスをまだ知らないからです。しかし、能力には明らかに相関があります。現状が変わらなければ、米国政府が特定のオープンウェイト中国製モデルを公衆にとって安全でないと判断する可能性を示唆しています。他にも多くの潜在的なシナリオが存在しますが、明確なのは、それらをマッピングし、インフラを整備し、社会へのメッセージングを行うために取り組むべき課題が山積しているということです。
より高度化するオープンモデルの管理方法を意思決定者に想像させ、伝えるためには、私一人ではなくはるかに多くの人々が必要です。2。Nvidia の次世代チップが生産段階に入り、アルゴリズムの進歩が絶え間なく続く中、AI の進展にはまだ数年先まで続きます。オープンモデル支持者にとって狭い道のように感じられますが、パフォーマンスにおける劇的な飛躍がクローズドモデルにのみ独占されないよう、それらを存続可能にする方法を模索する必要があります。
オープンアクセス可能な Mythos クラスのモデルを想像することがどれほど恐ろしいかは理解できます。しかし、もし今オープンモデルが禁止され、2 年後には 10 倍から 100 倍の性能向上がたった一社または二社の企業によってクローズドモデルのみで達成されるなら、私たちはより深刻な問題に直面することになるでしょう。
私がいつも際立って感じるのは、中国のラボがいかに速くモデルをリリースするかということです。複数のラボから聞いた話では、モデルのトレーニング完了後に重みを HuggingFace に公開するまでの時間は、日数ではなく時間で測れるほど短かったそうです。ただし、より広い推論市場向けにモデルを提供する準備が必要になった現在、このスピードは少なくとも少し鈍化しています。
さらに議論を深める必要があるのは、Mythos preview といったクローズドモデルでさえも、許可されていないユーザーの手元に置かれたり、 Jailbreak(制限解除)されたりすることが日常的にあるという点です。つまり、アクセスにおけるオープン vs クローズドの二項対立は、決して白黒はっきりしたものではありません。
原文を表示
Housekeeping: Following my “State of the blog” post last week, noting a slight increase in paid features, it’s a good time to remind folks that I offer group subscriptions with larger discounts proportional to the number of seats.
I also released a new paper today on open RL recipes for terminal agents, read more here.
A bit over a week ago, when the AI world was still reeling from the shocking export restriction, and effective banning, of Claude Fable 5, Z.ai released their latest model, GLM-5.2. This model was rolled out unusually on a Saturday, June 13th, to GLM Coding Plan members. This is an unusual release practice, normally when an AI model is released on a weekend it’s for a weird reason (most famously, Llama 4).1 In this case, it seemed like Z.ai was excited to capitalize on the zeitgeist of “Anthropic being anti open-science” with their silent safeguards on AI researchers. For the past year or two, the Chinese open-weight labs have taken every opportunity they have for easy marketing wins like this.
Share
GLM-5.2, in a common naming convention across the industry, looked potentially like an incremental update following the popular GLM-5.1 model. At this point, Moonshot AI, makers of the Kimi models, and Z.ai, makers of the GLM models, have consolidated the top of the reputational market with the most beloved open-weight models among AI researchers. What unfolded is a common lesson in tracking AI models that often minor version numbers can have AI models crossing meaningful user experience thresholds. A small change in benchmarks and training can open a wide range of new use-cases.
What has followed is a slow, groundswell of hype for GLM-5.2. The official, MIT-licensed model weights and release blog dropped three days after the initial rollout, on June 16th. One could ramble many technical details, such as the strong benchmark scores, the very popular RL framework that Z.ai uses (SLIME), the recommendation of always using the model on Max thinking effort, and so on, but the initial release blogs usually aren’t the thing to focus on. You can wait and read the ecosystem reaction to know if it’s the real deal. Benchmarks are half dead these days, anyways.
What followed on the 16th was a slew of community benchmarks showing better-than-expected results for GLM-5.2. Arena’s agent leaderboard had it as the only open model mixing it up with OpenAI and Anthropic’s latest models (notably matching Opus 4.8’s no-thinking effort to GLM-5.2’s max mode). This is one of many evals GLM-5.2 is crushing Gemini on, but that’s a topic for another time. A benchmark that has mixed perception in the community (particularly among actual designers), Design Arena even had GLM-5.2 besting Claude Fable itself — the recently banned hype machine!
Pretty much everyone I respect among the AI commentariat and researcher class has praised the model after using it personally. Such a focal point of discussion among the community has only been so clear with an open model release once before — DeepSeek R1. This is not a comparison I make lightly, and when I compared Kimi K2’s release to a “DeepSeek Moment,” GLM-5.2 has well exceeded that. What made Kimi K2 impressive was that big steps in open model performance could seemingly come from anywhere in China. The step that GLM-5.2 has taken is more of a one way door for AI progress.
Anthropic’s record revenue growth rate on the back of Claude Code is heavily driven by being the best model, and the only model that can really do this. GLM-5.2 is the first of many (coming soon) open weight models to offer credible alternatives. The parallel is very clear, to when DeepSeek R1 showed that open-weight labs, with far fewer resources, could also replicate the chain-of-thought reasoning models that OpenAI championed with o1. As AI systems get more complex and far more expensive to build, with tools, integrated harnesses, and scaled model weights, it was not a given that this GLM-5.2 moment would happen at all.
The key point is that GLM-5.2 is the open weight model that feels right in coding harnesses as a general agent. It’s the first one. I was personally overdue in trying some of the recent peer models, such as Kimi K2.7 or GLM-5.1, but the hype was too much for me to ignore. I put it to work helping make content for my post-training course with Fireworks’ API in Claude Code (setting this up was very easy). There were some minor knife cuts, such as the Claude Code harness / my repo documentation trying to send images to the model, which would brick Fireworks API for the session — forcing a manual context clear. Overall, the model capabilities immediately felt right, and I still have some tinkering to do in which harness and inference provider to use.
For more hype, you can sample the Z.ai founder telling Elon that “open-weight Fable capabilities will be here sooner than Q1 2027,” the CEO of Vercel saying “Genuinely impressed, almost shocked, at how good GLM-5.2 by @zai_org is at coding. This changes things,” and much more from a mix of people whose opinions I deeply respect and others I’m new to.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
So, this is a good model, where does this leave us?
There are many trends at play. To start, let’s ground things in the open-closed capabilities gap. I’ve written how I expect an “explosion in usage” if open models crossed the Opus 4.5 in Claude Code threshold from around the start of 2026. Here we are. With Claude Opus 4.5’s release on November 24th, 2025, the gap in time to GLM-5.2’s release on June 16th, 2026 is 204 days — or about 6.8 months. This puts us square in the 6-9 month time gap that many people claim as the performance lag between the U.S.’s closed labs and China’s open counterparts.
Upon writing this, I’m surprised. As the U.S. labs have so rapidly ramped compute in the last ~year, I’ve expected the gap in performance to grow in time. A very meaningful step in this trajectory will also be Claude Fable 5’s release — which was more reliant on scale, and therefore the most advanced GPUs, relative to the Claude Opus models. Still, that’s not a satisfactory answer. Continuing to unpack the trajectory here involves more nuance than I can afford to fit in a signposting article.
The most immediate meaning of this is far more serious pricing pressure within the organizations tokenmaxxing, sending Anthropic’s revenue to the moon. Some would predict Anthropic doesn’t realize its forecasted ARR numbers, but I don’t think that prices in the true demand for these models and the inevitable growth. This model existing is a huge boon for the open model economy. All the likes of Fireworks, Together, Thinky (via Tinker), Prime Intellect, and whoever else sells open model inference or finetuning just hit another inflection point.
It’ll take a long time for the effects here to diffuse into the broader economy (and use-cases). Workflows are becoming more complex, with people using different models for planning, primary coding, and subagent dispatch. I expect the hype to continue to grow, and heck, as I’m writing this on a Sunday evening, I could see the media and market reaction on the Monday being a thing just like the DeepSeek R1 release. This diffusion happening while Anthropic’s, and by extension the U.S.’s flagship model, is still banned is a severe economic dagger. GLM-5.2 is being given time to carve out the economic underbelly of the frontier labs when they want to be pushing forward into higher margin, higher revenue domains enabled only by the absolute frontier models.
The economic concern mirrors a story that has been told many times in AI, so it’s unclear when it’ll stick.
The conversation that feels more core to the trajectory of AI is that of regulation and control of open models. I think it is an economic good for cheap intelligence to diffuse widely, and our default position should be to cheer for open models, but this model’s release date will have it be permanently associated with Claude Fable — and therefore Claude Mythos — in the mental map of AI power structures. We are at a point where Mythos-class model capabilities are deemed not safe for release by the U.S. Government and the Chinese model makers are charging forward in capabilities available to all.
These trend lines aren’t necessarily causally linked, as we don’t know the cyber performance of GLM-5.2 versus its predecessors, but the capabilities are definitely correlated. Without anything changing, this points to a potentiality where the U.S. Government decides a certain open-weights Chinese model is not safe for the public. There are many other potential scenarios here too, but what is clear is that we have a lot of work to do in mapping them out, preparing our infrastructure, and messaging to society.
It’ll take a lot more people than just me to imagine and communicate a world to decision makers for how to manage evermore capable open models.2 We have years more of AI progress to come, with Nvidia’s next generation chips already in production and a constant stream of algorithmic advancements. It feels like a narrow path for open model advocates to take, but we need to figure out how to make them viable so the massive leaps in performance don’t only go to closed models.
I totally see why it is scary to imagine an openly accessible Mythos class model, but if open models get banned now and only closed models get 10 or 100X better in 2 years in the hands of one or two companies, I think we will have bigger problems on our hands.
1Something that has always stood out to me is how fast the Chinese labs release their models. I’ve heard from multiple labs that the time to upload the weights publicly to HuggingFace after the model finishes training could be measured in hours rather than days. This has at least slowed a bit, now that they need to prepare to serve the model to a wider inference market.
2Something that will need to be discussed more is how even closed models, e.g. Mythos preview, are regularly in the hands of unauthorized users or jailbroken. So, the open vs. closed dichotomy on access isn’t totally black and white.
関連記事
GLM-5.2 がオープンモデルの基準を向上させる(14 分読)
Zhipu AI が公開した大規模言語モデル「GLM-5.2」が、既存のオープンソースモデルと比較して性能や効率性を大幅に引き上げたと発表された。
ポッドキャスト:AI に自我があるなら『帝国時代 II』にもあるという論文について
Matthew が、大規模言語モデルに自我があると仮定した場合、古典的ゲーム『帝国時代 II』も同様に自我を持つと主張する興味深い論文を紹介した。
トークン終末が到来:企業、AI への支出抑制に躍起
コンサルティング大手のアクセンチュアは、非技術職による PDF からスライド作成などの些細なタスクでの AI トークン予算の浪費を防ぐため、業界全体で急激に増加するトークン支出を抑制しようとしている。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み