NVIDIA Nemotron 3 Ultra が Amazon SageMaker JumpStart で利用可能に
AWS は NVIDIA の最新大規模言語モデル「Nemotron 3 Ultra」を SageMaker JumpStart に即日公開し、自律型エージェント向けの高速推論と低コスト化を実現した。
キーポイント
SageMaker JumpStart での即日展開
NVIDIA Nemotron 3 Ultra が AWS SageMaker JumpStart でワンクリックデプロイ可能となり、企業による迅速な導入が実現した。
自律型エージェント特化のアーキテクチャ
5500億パラメータ(アクティブ 550 億)のハイブリッド Transformer-Mamba MoE 構造を採用し、百万トークンコンテキスト下でも高いスループットを維持する。
推論速度とコストの劇的改善
NVFP4 形式への最適化により、長期的なエージェントワークロードで推論が 5 倍高速化され、複雑なタスクのコストは最大 30% 削減される。
エンタープライズ向け自律型 AI の実現
計画実行、ツール呼び出し、自己修正を数百ターンにわたって行えるよう設計され、実務レベルの複雑なタスク完了率向上が期待される。
重要な引用
Nemotron 3 Ultra is an open model built for frontier reasoning and orchestration in long-running autonomous agents
delivering 5x faster inference and up to 30% lower cost for agentic workloads
Its MoE architecture activates only 55B of its 550B parameters per forward pass, keeping throughput high even at million-token context lengths
影響分析・編集コメントを表示
影響分析
この発表は、自律型 AI エージェントの実用化に向けたボトルネックであった推論コストと速度の課題を、AWS と NVIDIA の連携により解決する重要な転換点です。特に NVFP4 形式と MoE アーキテクチャの組み合わせは、大規模コンテキスト処理が必要なエンタープライズワークロードにおいて、従来のモデルよりも圧倒的な効率性を提供し、AI エージェントのビジネスへの本格導入を加速させるでしょう。
編集コメント
自律型エージェントの実用化において、推論コストと速度は最大の課題でしたが、NVIDIA の最新モデルが AWS プラットフォームで最適化された形で提供されることで、実装のハードルが劇的に下がりました。特に NVFP4 形式の採用は、大規模モデルを低コストで運用する際の新たな基準となる可能性があります。
本日、Amazon SageMaker JumpStart で NVIDIA Nemotron 3 Ultra の day-zero(リリース初日)利用が可能になったことを発表できることを嬉しく思います。
この発売により、ワンクリックデプロイメント体験で Nemotron 3 Ultra モデルをデプロイできるようになりました。Nemotron 3 Ultra は、長期実行型自律エージェントにおける最先端の推論とオーケストレーションのために構築されたオープンモデルであり、エージェントワークロードにおいて推論速度が 5 倍向上し、コストは最大 30% 削減されます。Nemotron 3 Ultra は NVFP4 形式に最適化されており、これによりホスティングが大幅に高速化され、コスト効率も向上します。
NVIDIA Nemotron 3 Ultra の概要
NVIDIA Nemotron 3 Ultra は、総パラメータ数 5,500 億(550B)、アクティブパラメータ数 550 億(55B)を備えたオープンな大規模言語モデルです。同等品質の密結合モデルと比較して計算コストを大幅に抑えながら最先端の知能を実現するために設計された、ハイブリッド Transformer-Mamba Mixture-of-Experts (MoE) アーキテクチャを採用しています。
仕様
詳細
アーキテクチャ
ハイブリッド Transformer-Mamba MoE
パラメータ数
総計 550B / アクティブ 55B
コンテキスト長
最大 1M トークン
入力/出力
テキスト入力、テキスト出力
精度
NVFP4
推論速度
長期実行型エージェントワークフローで 5 倍高速化
コスト
複雑なエージェントタスクで最大 30% コスト削減
##
エージェント型 AI に専用モデルが必要な理由
エージェントは単に一度回答するだけではありません。計画を立て、ツールを呼び出し、下位エージェントに作業を委任し、結果を確認し、何百ものターンにわたって継続します。各ステップでトークンと計算リソースが追加されるため、重要となる指標は、有用な精度でのタスク完了率、完了までの時間、およびタスクあたりのコストです。
Nemotron 3 Ultra はこれに直接対応しています。その MoE(Mixture of Experts)アーキテクチャでは、1 回の順伝播で 550B のパラメータのうち 55B だけが活性化されるため、百万トークンという長いコンテキスト長においてもスループットを高く維持できます。これにより、エージェントは数百ターンにわたる計画立案、ツール呼び出し、自己修正のループを継続しながら、一貫性を保ちつつコストを管理することが可能になります。
エンタープライズユースケース
Nemotron 3 Ultra は、持続的な多段階推論を必要とするワークロードで特に優れた性能を発揮します:
- エージェントオーケストレーター – 複数の下位エージェントの調整、長いツール呼び出しチェーンにわたる状態管理
- コーディングエージェント – 大規模なリポジトリ全体でのコード生成、テスト、デバッグ、反復処理
- ディープリサーチ – 複数ソースからの情報の統合、拡張されたコンテキストにおける一貫した推論の維持
- 複雑なエンタープライズワークフロー – 意思決定分岐とエラー回復を備えた多段階ビジネスプロセスの自動化
SageMaker JumpStart の始め方
Amazon SageMaker JumpStart を介して Nemotron 3 Ultra をデプロイできます。ワンクリックデプロイにより、インフラストラクチャの管理やサービングフレームワークの設定が不要になります。
前提条件
開始する前に、必ず以下を準備してください:
- AWS アカウント
- SageMaker JumpStart に適切にスコープされた権限
- GPU インスタンス(例:ml.p5en.48xlarge、ml.p5.48xlarge、または ml.g7e.48xlarge)に対する十分なサービスクォータ
重要: このモデルのデプロイにより、稼働中に課金が発生する SageMaker エンドポイントが作成されます。ml.p5en.48xlarge などの GPU インスタンスは、時間あたり数ドルかかる場合があります。詳細については Amazon SageMaker AI の価格設定をご覧ください。完了後はエンドポイントを削除して、継続的な課金を避けてください。
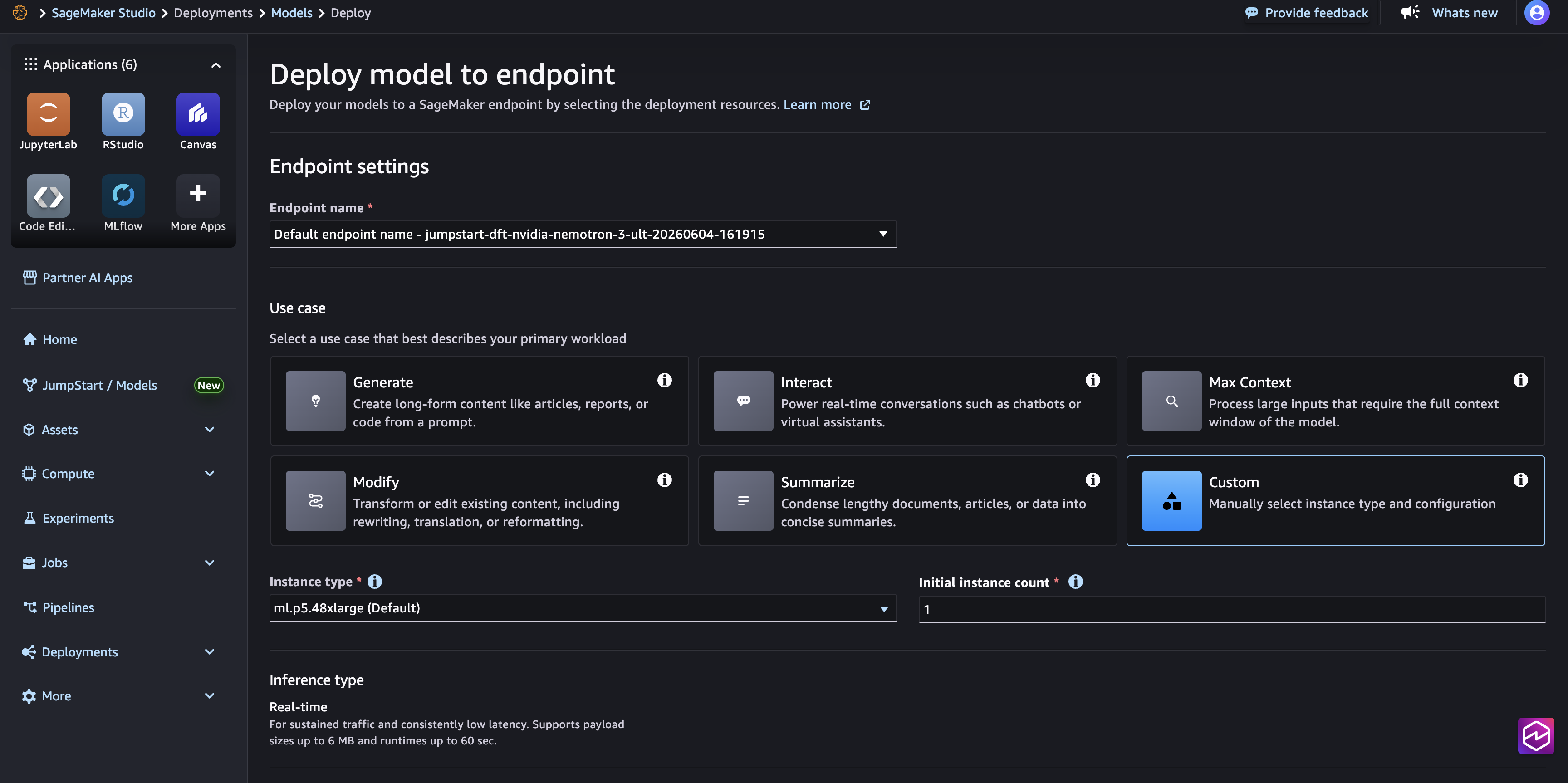
SageMaker Studio を使用してデプロイする
- Amazon SageMaker Studio を開く
- 左側のナビゲーションペインで「SageMaker JumpStart」を選択する
- Nemotron 3 Ultra と検索する
- モデルカードを選択する
- 「Deploy(デプロイ)」を選択する
- インスタンスタイプを選択する(サポートされているインスタンスタイプは ml.p5en.48xlarge、ml.p5.48xlarge、または ml.g7e.48xlarge)
- デプロイ設定を確認する(ほとんどのユースケースではデフォルト値で十分です)
- エンドポイントを作成するために「Deploy」を選択する
- 推論に進む前に、エンドポイントステータスが InService になるまで待つ
SageMaker Python SDK を使用してデプロイ
import sagemaker
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(
model_id="huggingface-reasoning-nvidia-nemotron-3-ultra-550b-a55b-nvfp4", # SageMaker JumpStart モデルカードで確認してください
role=sagemaker.get_execution_role(), # あなたの SageMaker 実行ロール ARN
)
predictor = model.deploy(accept_eula=True)
推論を実行
payload = {
"messages": [{
"role": "user",
"content": "このタスクをサブタスクに分割し、必要なツールを特定して、それらを順次実行してください。"
}],
"max_tokens": 20480,
"temperature": 0.6,
"top_p": 0.95,
}
response = predictor.predict(payload)
print(response["choices"][0]["message"]["content"])
クリーンアップ
不要な課金を避けるために、作業が完了したら SageMaker エンドポイントを削除してください:predictor.delete_endpoint()
結論
NVIDIA Nemotron 3 Ultra は、Amazon SageMaker JumpStart に最先端クラスの推論能力をもたらします。エージェントワークロードにおいて、推論速度は 5 倍高速化され、コストは最大 30% 削減されます。そのハイブリッド Transformer-Mamba MoE アーキテクチャと百万トークンのコンテキストウィンドウは、生産環境のエージェントが要求する持続的かつ多段階の推論のために特別に設計されています。
エージェントオーケストレーター、コーディングエージェント、深層研究システム、あるいは複雑な企業自動化を構築している場合でも、Nemotron 3 Ultra は今日から SageMaker JumpStart ですぐにデプロイ可能です。
Amazon SageMaker JumpStart で「Nemotron 3 Ultra」を検索して、今すぐ始めましょう。
著者について
 imageDan Ferguson氏は、米国ニューヨークを拠点とするAWSのソリューションアーキテクトです。機械学習(ML)サービスの専門家として、顧客がMLワークフローを効率的かつ効果的、そして持続可能に統合する旅をサポートしています。
imageDan Ferguson氏は、米国ニューヨークを拠点とするAWSのソリューションアーキテクトです。機械学習(ML)サービスの専門家として、顧客がMLワークフローを効率的かつ効果的、そして持続可能に統合する旅をサポートしています。
 imageMalav Shastri氏は、AWSのソフトウェア開発エンジニアであり、Amazon SageMaker JumpStartおよびAmazon Bedrockチームで活動しています。彼の役割は、顧客が最先端のオープンソースおよび独自基盤モデルを活用できるように支援することに焦点を当てています。Malav氏はコンピュータサイエンスの修士号を取得しています。
imageMalav Shastri氏は、AWSのソフトウェア開発エンジニアであり、Amazon SageMaker JumpStartおよびAmazon Bedrockチームで活動しています。彼の役割は、顧客が最先端のオープンソースおよび独自基盤モデルを活用できるように支援することに焦点を当てています。Malav氏はコンピュータサイエンスの修士号を取得しています。
 image Vivek Gangasani 氏は、SageMaker Inference のソリューションアーキテクチャにおける世界リーダーです。彼は SageMaker Inference のソリューションアーキテクチャ、技術的市場投入(GTM)およびアウトバウンド製品戦略を統括しています。また、企業やスタートアップに対し、SageMaker と GPU を活用した生成 AI モデルのデプロイと最適化、ならびに AI ワークフローの構築を支援しています。現在、アジェンティックワークフローや RAG(検索拡張生成)などのユースケースにおける推論パフォーマンスの最適化に関する戦略とコンテンツの開発に注力しています。趣味はハイキング、映画鑑賞、そして様々な料理を試すことです。
image Vivek Gangasani 氏は、SageMaker Inference のソリューションアーキテクチャにおける世界リーダーです。彼は SageMaker Inference のソリューションアーキテクチャ、技術的市場投入(GTM)およびアウトバウンド製品戦略を統括しています。また、企業やスタートアップに対し、SageMaker と GPU を活用した生成 AI モデルのデプロイと最適化、ならびに AI ワークフローの構築を支援しています。現在、アジェンティックワークフローや RAG(検索拡張生成)などのユースケースにおける推論パフォーマンスの最適化に関する戦略とコンテンツの開発に注力しています。趣味はハイキング、映画鑑賞、そして様々な料理を試すことです。
原文を表示
Today, we are excited to announce the day-zero availability of NVIDIA Nemotron 3 Ultra on Amazon SageMaker JumpStart.
With this launch, you can now deploy the Nemotron 3 Ultra model using a one-click deployment experience. Nemotron 3 Ultra is an open model built for frontier reasoning and orchestration in long-running autonomous agents, delivering 5x faster inference and up to 30% lower cost for agentic workloads. Nemotron 3 Ultra is optimized for the NVFP4 format, which makes the model much faster and cost effective to host.
Overview of NVIDIA Nemotron 3 Ultra
NVIDIA Nemotron 3 Ultra is an open large language model with 550 billion total parameters and 55 billion active parameters. It is built on a hybrid Transformer-Mamba Mixture-of-Experts (MoE) architecture, designed to deliver frontier intelligence at a fraction of the compute cost of dense models of equivalent quality.
Specification
Details
Architecture
Hybrid Transformer-Mamba MoE
Parameters
550B total / 55B active
Context length
Up to 1M tokens
Input / Output
Text in, text out
Precision
NVFP4
Inference speed
5x faster for long-running agent workflows
Cost
Up to 30% lower for complex agentic tasks
##
Why agentic AI needs purpose-built models
Agents don’t just answer once. They plan, call tools, delegate work to sub-agents, check results, and keep going across hundreds of turns. Every step adds tokens and compute, so the metrics that matter are task completion at useful accuracy, time-to-finish, and cost-per-task.
Nemotron 3 Ultra addresses this directly. Its MoE architecture activates only 55B of its 550B parameters per forward pass, keeping throughput high even at million-token context lengths. This means agents can sustain planning, tool calling, and self-correction loops that span hundreds of turns while helping maintain coherence and manage cost.
Enterprise use cases
Nemotron 3 Ultra excels in workloads that require sustained multi-step reasoning:
- Agent orchestrators – coordinate multiple sub-agents, manage state across long tool-calling chains
- Coding agents – generate, test, debug, and iterate on code across large repositories
- Deep research – synthesize information from multiple sources, maintain coherent reasoning over extended context
- Complex enterprise workflows – automate multi-step business processes with decision branching and error recovery
Getting started with SageMaker JumpStart
You can deploy Nemotron 3 Ultra through Amazon SageMaker JumpStart with one-click deployment, removing the need to manage infrastructure or configure serving frameworks.
Prerequisites
Before you begin, make sure you have:
- An AWS account
- Appropriately scoped permissions for SageMaker JumpStart
- Sufficient service quota for GPU instances (for example, ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
Important: Deploying this model creates a SageMaker endpoint that incurs charges while running. GPU instances like ml.p5en.48xlarge can cost several dollars per hour. See Amazon SageMaker AI pricing for details. Remember to delete your endpoint when finished to avoid ongoing charges.
Deploy using SageMaker Studio
- Open Amazon SageMaker Studio
- In the left navigation pane, choose SageMaker JumpStart
- Search for Nemotron 3 Ultra
- Select the model card
- Choose Deploy
- Select your instance type (supported instance types are ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
- Review deployment settings (defaults are sufficient for most use cases)
- Choose Deploy to create the endpoint
- Wait for the endpoint status to show InService before proceeding to inference
Deploy using the SageMaker Python SDK
import sagemaker
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(
model_id="huggingface-reasoning-nvidia-nemotron-3-ultra-550b-a55b-nvfp4", # Verify in SageMaker JumpStart model card
role=sagemaker.get_execution_role(), # Your SageMaker execution role ARN
)
predictor = model.deploy(accept_eula=True)Run inference
payload = {
"messages": [{
"role": "user",
"content": "Break this task into subtasks, identify which tools are needed, and run them in sequence."
}],
"max_tokens": 20480,
"temperature": 0.6,
"top_p": 0.95,
}
response = predictor.predict(payload)
print(response["choices"][0]["message"]["content"])Clean up
To avoid incurring unnecessary charges, delete the SageMaker endpoint when you are done:predictor.delete_endpoint()
Conclusion
NVIDIA Nemotron 3 Ultra brings frontier-class reasoning to Amazon SageMaker JumpStart with 5x faster inference and up to 30% lower cost for agentic workloads. Its hybrid Transformer-Mamba MoE architecture and million-token context window make it purpose-built for the sustained, multi-step reasoning that production agents demand.
Whether you are building agent orchestrators, coding agents, deep research systems, or complex enterprise automation, Nemotron 3 Ultra is ready to deploy today from SageMaker JumpStart.
Get started now by searching for Nemotron 3 Ultra in Amazon SageMaker JumpStart.
About the authors
**
Dan Ferguson** is a Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
**
Malav Shastri** is a Software Development Engineer at AWS, where he works on the Amazon SageMaker JumpStart and Amazon Bedrock teams. His role focuses on enabling customers to take advantage of state-of-the-art open source and proprietary foundation models. Malav holds a Master’s degree in Computer Science.
**
Vivek Gangasani** is a Worldwide Leader for Solutions Architecture, SageMaker Inference. He leads Solution Architecture, Technical Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy and optimize a GenAI models and build AI workflows with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and use-cases such as Agentic workflows, RAG etc. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み