GPT 5.4はCodexにとって大きな一歩
Interconnectsの著者は、GPT-5.4がCodex環境において単なるベンチマーク上の進歩ではなく、エージェントタスクにおける正確性、使いやすさ、速度、コストの4つの軸で実用的な飛躍を示し、Claudeとの競争力を回復させたことを報告している。
キーポイント
エージェント評価指標の多軸化
従来の単一スコアによるベンチマークでは捉えきれない、エージェント作業に必要な「正確性」「使いやすさ」「速度」「コスト」の4つの要素が、GPT-5.4でバランスよく改善された。
実運用における「摩擦」の除去
Git操作やパッケージ管理など、以前は頻繁に失敗していた(「死の千切り」)小規模プロジェクトやデータ分析タスクにおいて、GPT-5.4は安定して動作し、ユーザーのフラストレーションを大幅に軽減した。
Claudeとの差別化と競争回復
GPT-5.4はClaudeのような「親しみやすさ」や「個性」こそないものの、緻密で機械的な処理能力において優れており、「特定のTODOリストの処理」という用途に最適化されることで、エージェント戦争においてOpenAIが再び強力なプレイヤーとなった。
ClaudeとGPT 5.4の哲学の違い
Claudeは意図を汲み取る「意見」を求める用途に適している一方、GPT 5.4は指示に厳密に従う「機械的」な性質を持ち、複雑なタスクを分散処理するエージェントコーディネーターに適している。
推論効率とコストの向上
OpenAIのモデルはピークパフォーマンスに必要なトークン数が削減されており、これは推論効率の高さを示す。その結果、高速モードと高いレート制限により、Claudeプランで頻繁に制限に達するユーザーにとってCodexの方が実用的である。
優れたコンテキスト管理
GPT 5.4は推論効率の高さにより、コンテキストウィンドウをより効果的に活用し、ユーザーが「コンテキストの壁」や不安を感じる頻度が大幅に減少している。
複数タスク処理における忘却の懸念
Claude Opus 4.6とGPT 5.4の両方で、計画モード外の単一メッセージ内に複数のTODOを指定すると、モデルがタスクを見落としたり古い問題に固執したりする軽微な忘却現象が発生することが報告されている。
重要な引用
GPT 5.4 in Codex, always on fast mode and high or extra-high effort, is the first OpenAI agent that feels like it can do a lot of random things you can throw at it.
Prior to GPT 5.4, I always churned off of OpenAI’s agents due to a death by a thousand cuts.
Where Claude is a super smart model, with character... OpenAI’s models in Codex feel meticulous, slightly cold, but deeply mechanical.
Claude, in some domains, you come to see has an excellent model for your intent. GPT 5.4 just does what you say to do.
This 2D (or more) benchmark picture is exactly where the world is going.
All in, I see GPT 5.4 as an agentic model that brings a ton more simple usability and “agentness” to the very strong software foundation of GPT 5.3 Codex.
影響分析・編集コメントを表示
影響分析
この記事は、LLMの性能評価が単なる正答率から「実務での使い勝手」へシフトしつつあることを示唆しており、特にエージェント機能を持つプロダクトの競争優位性は、モデルの知能だけでなくエラーハンドリングやUX設計に依存することを示しています。OpenAIがClaudeの成長勢いに対抗するために、Codexのような統合環境での実用性向上に注力している戦略が確認できます。
編集コメント
ベンチマークスコアだけでなく、実際の開発ワークフローにおける「エラーの発生頻度」や「作業の中断リスク」が、次世代エージェントモデルの競争力を決定する重要な指標となりつつある。
私はこのモデルレビューに少し遅れて参加しましたが、そのおかげでエージェントにとって重要な軸について考える時間がより持てました。従来のベンチマークは、モデルの性能を正しさという単一のスコアに還元します。それが常にそうであるのは、単純であり、パフォーマンスを素早く評価するために使いやすく、といった理由からです。これはまた、優れたベンチマークを構築しようとする人々にも私がアドバイスしていることです——それは解釈可能な一つの数値に収約される必要があります。おそらく今後 1〜2 年してもこの傾向は続くでしょうし、エージェント向けのベンチマークもより良くなるでしょうが、現時点では、私たちが感じていることにはあまり対応していません。なぜなら、エージェントタスクとは正しさ、使いやすさ、速度、コストの混合体だからです。将来的には、これらの要素を個別に扱うベンチマークが登場するようになるでしょう。
GPT 5.4 はいくつかの紙上のベンチマークでは別の漸進的なモデルのように感じられるかもしれませんが、実際にはそれら 4 つの特性すべてにおいて意味のある一歩と感じられます。Codex における GPT 5.4(常に高速モードで、高または超高エフォート設定)は、投げかけられるあらゆるランダムなタスクを多くこなせるように感じる、最初の OpenAI エージェントです。
Interconnects AI は読者支援型の出版物です。購読をご検討ください。
ここ数ヶ月、私はソフトウェアエンジニアリングに深く携わってきたわけではありません。そのため、エージェントとの作業は主に小規模なプロジェクト(完全に一発屋ではありませんが、設計を数週間にわたって自ら構築・管理できるほど小さなもの)、データ分析、および研究タスクに限られていました。エージェントネイティブであることを受け入れると、このスタイルの作業には、多くの定期的な API 呼び出し、バックグラウンドパッケージ(LateX バイナリや ffmpeg、マルチメディア変換ツールのインストールと管理など)、git 操作、ファイル管理、検索などが伴います。
GPT 5.4 以前は、OpenAI のエージェントに対して「千切り殺し」のような状況に直面して常に離脱していました。まるで怒りによる即時撤退(rage quit)のように感じられました。GPT 5.2 Codex に近づいているかと思っても、git 操作で失敗し、私自身(または Claude)がリセットを余儀なくされるという結末でした。しかし、そのような硬直した壁はもはや存在しません。
GPT 5.4 の親しみやすさにおけるもう一つの微妙な変化、つまり OpenAI が再びエージェント戦争に本格的に参入したと私が考える最大の理由は、それが少しだけ「正しい」ように感じられる点にあります。私はこれを上記で議論した定型タスクとは異なるカテゴリーに分類しており、これは製品(つまりモデル・ハネス)がユーザーであるあなたに対してモデルの出力やリクエストなどをどのように提示するかに関係しています。また、いかに容易に深く入り込めるかという点にも関連します。これは常に Claude の最大の強みであり、その驚異的な成長の要因でした。Claude は非常に有用であるだけでなく、新規ユーザーを引きつけて留めておくための魅力と娯楽的価値も備えています。GPT 5.4 も同様の要素を少し持っていますが、根本的なモデルの強さにおいては Claude の方がまだ温かみを感じさせます。
Claude は性格があり、議論での言い回しも巧みで、時には何かを忘れるような超賢いモデルですが、Codex における OpenAI のモデルは、細部まで注意深く、やや冷たく、しかし非常に機械的な印象を受けます。私は Claude を、より多くの意見が必要とされるタスクに使い、GPT 5.4 は圧倒的に具体的な TODO リストを処理させるために利用します。GPT 5.4 の指示従順性はあまりにも正確なため、Claude と長時間過ごした後は、モデルとの対話方法を学び直す必要があります。Claude は特定のドメインにおいて、あなたの意図に対する優れたモデルであることがわかってきます。一方、GPT 5.4 は言われたことをただ実行するだけです。これらは「エージェントにとって最適なモデルとは何か」という点で非常に異なる哲学です。Claude はおそらく新規参入者にアピールするでしょうが、GPT 5.4 は分散タスクに AI 軍団を解放したいマスターエージェントコーディネーターにアピールすることになるでしょう。
魅力や、あえて言えば品味を除けば、多くの使いやすさの要素は OpenAI の側の方が実際には優れています。Codex アプリは魅力的です——必ずしも常に使うわけではありませんが、時には完全に気に入ります。これらのアプリの外観については、将来的に大きな革新が起きると予想しています。個人的には、最終的には Slack のようなものになるだろうと考えています(複数のエージェントが互いに通信する必要がある場合など、私の監視下で)。
Share
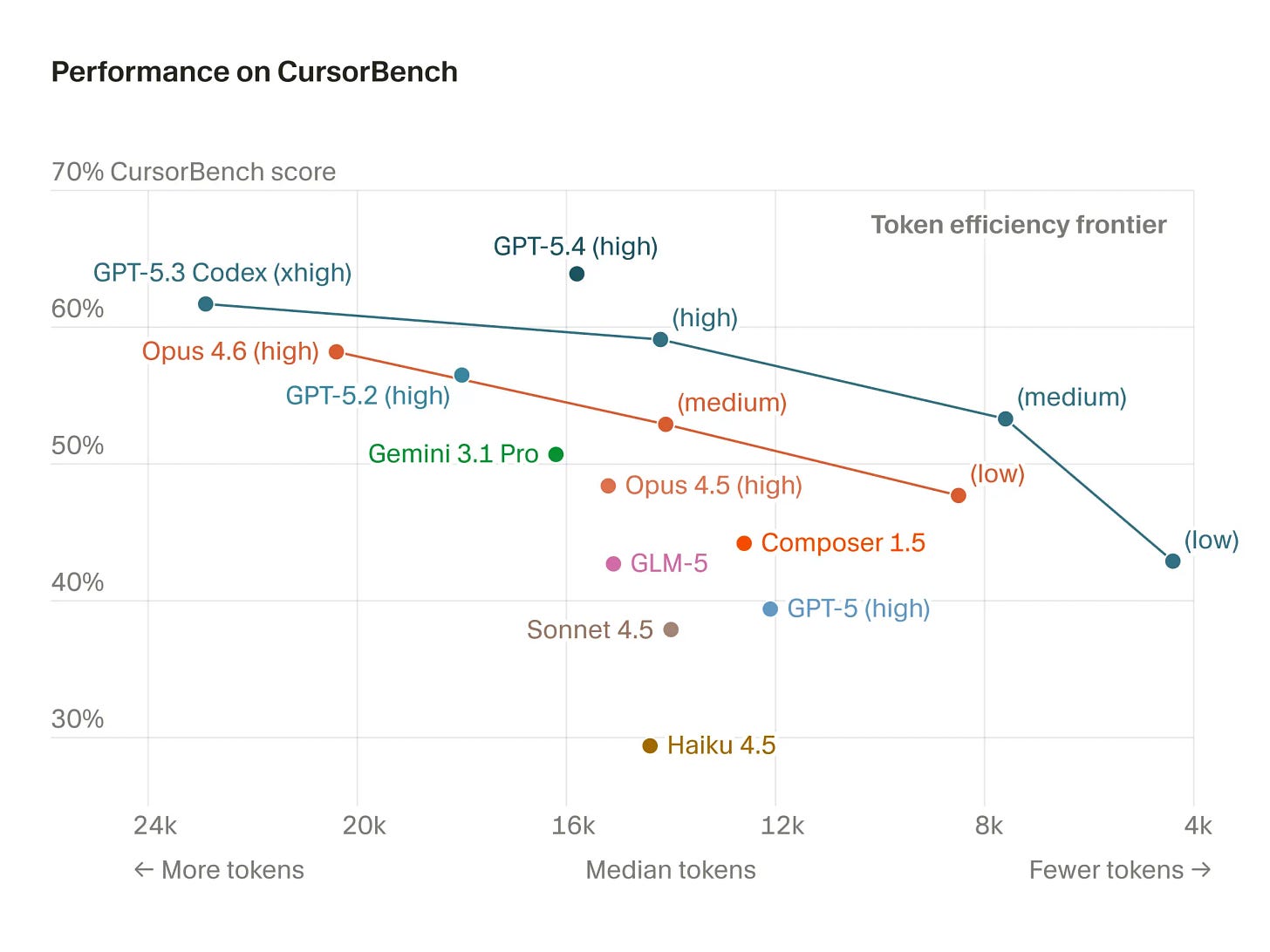
OpenAI は、サブスクリプション契約により、自社のモデルに対してネイティブの高速モードと非常に大きなレート制限も提供しています。私は長期間にわたり、月額 100 ドルの Claude プランと月額 200 ドルの ChatGPT プランを利用してきましたが、高速モードと xhigh(超高)推論設定において Codex の利用制限にほぼ達したことは一度もなく、Claude の制限には時々遭遇します。これには明確なモデル側の理由があります——OpenAI が公開するリリースブログのほとんどは、各反復的なモデルがピークベンチマーク性能を達成するために必要なトークン数が劇的に削減されていることを示しています。これは推論効率の指標です。この 2 次元(あるいはそれ以上)のベンチマークの状況こそが、世界が進もうとしている方向そのものです。
Cursor から提供されたグラフがありますが、残念ながら GPT 5.4 のすべての推論設定が含まれていないものの、第三者による評価においてこの点を裏付けています。モデルファミリー全体に共通して欠けているのは、そこに到達するための速度と価格(使用される総計算資源の代理指標)です。
GPT 5.4 の最終的な利点、そしてその文脈における OpenAI のエージェント型モデル全般に言えることは、はるかに優れたコンテキスト管理です。現在これらを定期的に使用していますが、コンテキストの壁やコンテキスト不安の限界に達したと感じたことはありません。推論効率が高まっていることが上記のような状況をもたらしていると考えられ、それによりモデルが初期状態の空のコンテキストウィンドウでより多くの処理を行えるようになっています。そして GPT 5.4 がコンパクション(圧縮)を実行する際にも、その変化は以前よりも目立たなくなっています。
私が Claude Opus 4.6 と GPT 5.4 の両方で経験している唯一の問題は、軽度の忘却です。計画モード外で単一のメッセージ内に複数の TODO リストをモデルに与えると、それらをしばしば見落としてしまうことがわかります。時にはモデルがバグを起こしたかのように感じられ、直近の課題ではなく過去の課題を解決しようとする場合があります。モデル内部やその実行環境(ハネス)のどこに正確な原因があるのかは不明ですが、時折、モデルが何か作業中であることを確認しながら複数のメッセージをキューイングしてタスクを洗練させたいと思うことがあります。しかし現在では、最も単純なユースケースを除き、これはかなりリスクの高い結果をもたらす傾向があります。
最近では、気分に左右されつつも GPT と Claude の両方を幅広く活用しており、これまで以上に多くの成果を得ています。GPT 5.4 Pro を Codex に直接統合し(例えば \ultrathink のような形)、OpenAI が他社との決定的な差別化要因とすることは大きな意味を持ちます。これらのモデルは本当に素晴らしいものです。
総括すると、私は GPT 5.4 を、GPT 5.3 Codex の非常に強力なソフトウェア基盤に、はるかにシンプルな使いやすさと「エージェント性」をもたらすアジェンシーモデルと捉えています。これは大きな一歩であり、次なるアップデートをどちらの企業が発表するかについて、私は信じられないほど興奮しています。紙面上では、GPT 5.4 の強みを、より優れたトップエンドのコーディングパフォーマンス、より高速な処理、より良いコンテキスト管理、より良いレート制限として列挙することは、モデル選択がいかに微妙でニュアンスに富んだものであるかを証明するものです。私は実際には、ベンチマークでは決して現れないような点において、まだ Claude を少しだけ好んで使っています。そのため、一日の始まりにターミナルに入力するのは Codex ではなく、Claude です。
原文を表示
I’m a little late to this model review, but that has given me more time to think about the axes that matter for agents. Traditional benchmarks reduce model performance to a single score of correctness – they always have because that was simple, easy to quickly use to gauge performance, and so on. This is also advice that I give to people trying to build great benchmarks – it needs to reduce to one number that is interpretable. This is likely still going to be true in a year or two, and benchmarks for agents will be better, but for the time being it doesn’t really map to what we feel because agentic tasks are all about a mix of correctness, ease of use, speed, and cost. Eventually benchmarks will individually address these.
Where GPT 5.4 feels like another incremental model on some on-paper benchmarks, in practice it feels like a meaningful step in all four of those traits. GPT 5.4 in Codex, always on fast mode and high or extra-high effort, is the first OpenAI agent that feels like it can do a lot of random things you can throw at it.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
I haven’t been particularly deep in software engineering over the last few months, so most of my working with agents has been smaller projects (not totally one-off, but small enough where I’ve built the entire thing and manage the design over weeks), data analysis, and research tasks. When you embrace being agent-native, this style of work entails a lot of regular APIs, background packages (like installing and managing LateX binaries, ffmpeg, multimedia conversion tools, etc), git operations, file management, search etc. Prior to GPT 5.4, I always churned off of OpenAI’s agents due to a death by a thousand cuts. It felt like rage quits. I’d feel like I was getting into GPT 5.2 Codex, but it would fail on a git operation and have me (or Claude) need to reset it. Those hard edges are no longer there.
The other subtle change in GPT 5.4’s approachability – the biggest reason I think OpenAI is much more back in the agent wars – is that it just feels a bit more “right.” I classify this differently to the routine tasks I discussed above, and it has to do with how the product (i.e. the model harness) presents the model outputs, requests, and all that to you the user. It has to do with how easy it is to dive in. This has always been Claude’s biggest strength in its astronomical growth. Not only has Claude been immensely useful, but it has a charm and entertainment value to it that’ll make new people stick around. GPT 5.4 has a bit of that, but the underlying model strengths of Claude still leave it feeling warmer.
Where Claude is a super smart model, with character, a turn of phrase in a debate, and sometimes forgetting something, OpenAI’s models in Codex feel meticulous, slightly cold, but deeply mechanical. I’d use Claude for things I need more of an opinion on and GPT 5.4 to churn through an overwhelmingly specific TODO list. The instruction following of GPT 5.4 is so precise that I need to learn to interact with the models differently after spending so much time with Claude. Claude, in some domains, you come to see has an excellent model for your intent. GPT 5.4 just does what you say to do. These are very different philosophies of “what will make the best model for an agent”, Claude will likely appeal to the newcomers, but GPT 5.4 will likely appeal to the master agent coordinator that wants to unleash their AI army on distributed tasks.
Share
Outside of charm, and dare I say taste, a lot of the usability factors are actually better on OpenAI’s half of the world. The Codex app is compelling – I don’t always use it, but sometimes I totally love it. I suspect substantial innovation is coming in what these apps look like. Personally, I expect them to eventually look like Slack (when multiple agents need to talk to eachother, under my watch).
OpenAI also natively offers fast mode for their models with a subscription and very large rate limits. I’ve been on the $100/month Claude plan and $200/month ChatGPT plan for quite some time. I’ve never been remotely close to my Codex limits with fast mode and xhigh reasoning effort, where I hit my Claude limits from time to time. There’s definitely a modeling reason to this – most of OpenAI’s release blogs showcase each iterative model being substantially more concise in the number of tokens it takes to get peak benchmark performance. This is a measure of reasoning efficiency. This 2D (or more) benchmark picture is exactly where the world is going.
Here’s a plot from Cursor, which sadly doesn’t have all the GPT 5.4 reasoning efforts, but it confirms this point in a third party evaluation. What is missing across model families is the speed and price (a proxy for total compute used) to get there.
The final benefit of GPT 5.4, and OpenAI’s agentic models in general for that matter, is much better context management. In using them regularly now I feel like I’ve never hit the context wall or context anxiety point. The reasoning efficiency I suspect is the case above just lets the model do way more with its initially empty context window. Then, when GPT 5.4 does compact, it’s been less noticeable.
The one problem I’ve been having with both Claude Opus 4.6 and GPT 5.4 is a light forgetfulness. If you give the models multiple TODOs in a single message outside of planning mode, I find them often dropping them. Sometimes it feels like the models glitch and try to solve a previous problem rather than the recent ones. I’m not sure what in the model or the harness is the exact cause, but sometimes I like to queue up a few messages as I see the model working on something, to refine the task, but currently this tends to be a pretty risky outcome except in the simplest use-cases.
These days I’ve been using both GPT and Claude extensively, mostly based on my mood, and have been getting more done than ever. Having a GPT 5.4 Pro integration directly with Codex, e.g. like \ultrathink, would be a big differentiator for OpenAI. Those models have been incredible.
All in, I see GPT 5.4 as an agentic model that brings a ton more simple usability and “agentness” to the very strong software foundation of GPT 5.3 Codex. It’s a big step, and I’m unbelievably excited for which of these two companies releases an update next. On paper, listing the strengths of GPT 5.4 across better top end coding performance, better speed, better context management, better rate limits, it’s a testament to how nuanced choosing a model is. I genuinely still enjoy Claude a bit more for ways that’ll never show up on benchmarks. This makes me type claude into my terminal at the start of my day, rather than codex.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み