DFlash と Spec V2 デコーディングの解説(14 分読了)
TLDR AI は、生成モデルの推論コストを削減し速度を向上させるための新技術「DFlash」と「Spec V2」の仕組みと実装効果について詳述している。
キーポイント
DFlash の高速化メカニズム
従来のデコーディング手法を最適化し、メモリアクセスパターンを改善することで推論速度を劇的に向上させる技術。
Spec V2 デコーディングの進化
検証プロセスを効率化する新アルゴリズムにより、生成モデルの精度を維持しながら計算リソースの消費を大幅に削減する。
推論コストと速度のトレードオフ解消
両技術の組み合わせが、大規模言語モデル(LLM)の実運用におけるボトルネックであったコスト対効果の問題を解決する可能性を示す。
影響分析・編集コメントを表示
影響分析
この技術解説は、生成 AI の実装コストを下げ、スケーラビリティを高める具体的な解決策を示しており、業界全体のパフォーマンス基準を引き上げる可能性があります。特にリソース制約のある環境やリアルタイム応用において、導入による即時的な効果が見込まれます。
編集コメント
推論効率化は現在最もホットなトピックの一つであり、DFlash や Spec V2 のような具体的な実装アプローチの詳細解説は、エンジニアリングチームにとって即戦力となる情報です。
Modal と Z Lab の DFlash 推測デコーディングモデルを、SGLang の newly default Spec V2 エンジン(Speculative Decoding Version 2)と組み合わせることで、LLM 推論サービングにおいて最先端のレイテンシを実現できます。Qwen 3.5 397B-A17B 向けに共同リリースされた新しい DFlash モデルは、ベンチマークしたすべての設定において、ベースラインモデルおよびネイティブ MTP(Multi-Token Prediction)推測よりも高いスループットを達成します。HumanEval コーディングデータセット上で並行度 1 の条件下では、ベースラインの >4.3 倍、MTP の 1.5 倍のスループットを実現しています。
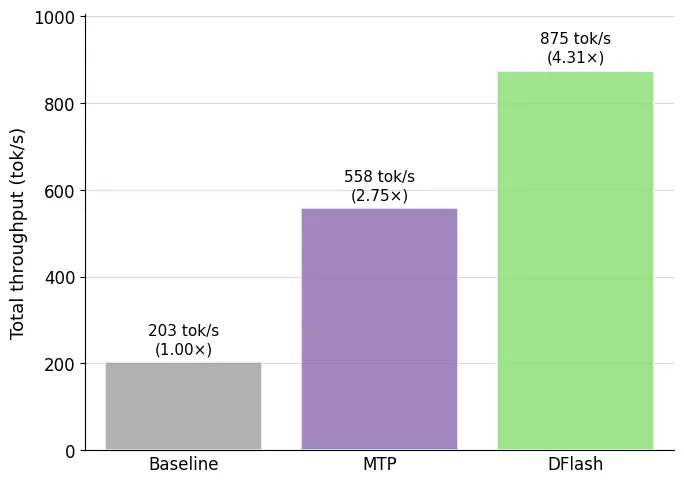
ワークロード: Qwen 3.5 397B-A17B (BF16)、HumanEval。設定: グリーディデコーディング、思考機能有効、最大新規トークン数 4096。ハードウェア: Modal 上の 8xB200。受容長はリクエスト間で平均化されています。ドラフトトークン/ブロック数は最大スループットを達成するように選択されました(MTP: 7 ステップ; DFlash: ブロックサイズ 16)。
このコラボレーションを祝し、本モデルを Hugging Face の各組織で三つのリポジトリに公開します:
- z-lab/Qwen3.5-397B-A17B-DFlash
- modal-labs/Qwen3.5-397B-A17B-DFlash
- lmsys/Qwen3.5-397B-A17B-DFlash
以下のコマンドで、ご自身でも本モデルを試すことができます:
export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--trust-remote-code \
--speculative-algorithm DFLASH \
--speculative-draft-model-path modal-labs/Qwen3.5-397B-A17B-DFlash \
--speculative-dflash-block-size 8 \
--speculative-draft-attention-backend fa4 \
--attention-backend trtllm_mha \
--linear-attn-prefill-backend triton \
--linear-attn-decode-backend flashinfer \
--mamba-scheduler-strategy extra_buffer \
--tp-size 8 \
--max-running-requests 32 \
--cuda-graph-max-bs-decode 32 \
--cuda-graph-backend-prefill tc_piecewise \
--enable-flashinfer-allreduce-fusion \
--mem-fraction-static 0.8 \
--host 0.0.0.0
以下では、推論の劇的な高速化を実現するための DFlash の革新的な拡散+KV(Key-Value)注入戦略について説明し、その重要性を解説するとともに、Z Lab、SGLang、および Modal のチームがどのように協力してこの高速化を誰もが利用可能にしたかについて述べます。
KV 注入による並列ドラフティング
Transformer ベースの大規模言語モデル(LLM)は強力ですが、その自己回帰的推論プロセスにより推論速度が遅くなります。トークンは一つずつ生成する必要があり、現代のハードウェアには適さないほど 演算強度 が低いためです。
Speculative decoding は、より小さく高速なドラフトモデルを使用して複数のトークンを提案し、それをターゲット LLM が並列に検証することでこのボトルネックを解決します。これにより、モデルの品質への影響はありません。
しかし、EAGLE シリーズ や、最近の Gemma 4 および DeepSeek-V4 に搭載されたネイティブなマルチトークン予測 (MTP) モジュールなど、多くの推測的デコーディング手法は、依然として逐次的自己回帰に依存しています。ただし、これはターゲットモデルではなくドラフトモデル側での話です。ドラフトモデルがトークンを一つずつ生成する方式は、現代のハードウェアには適しておらず、実現可能な速度向上の限界となっています。
そこで Z Lab は DFlash を開発しました。これは軽量なブロック拡散ドラフトモデルを使用し、GPU や TPU が好むように、ドラフトトークンのブロック全体を並列に生成します。Xiaomi の新製品 MiMo v2.5-Pro-UltraSpeed は DFlash を採用することで 1 秒あたり 1000 トークンを超える出力 を実現しています。
推測的ドラフトにブロック拡散を使用するのは容易ではありません。小さなブロック拡散モデルを直接トレーニングしてドラフターとして使用すると受容長が短くなる一方、SpecDiff-2 のような既存の大規模拡散 LLM をドラフターとして使用すると、メモリ使用量が大幅に増加し、ドラフトコストが高くなります。
DFlash の鍵となる洞察はシンプルです:対象の LLM が文脈を最もよく理解しています。Medusa、EAGLE、MTP (Gloeckle et al., 2024; Samragh et al., 2025) などの先行手法に触発され、対象モデルから文脈トークンの隠れ表現(hidden representations)を抽出します。先行研究とは異なり、これらをドラフトモデルの KV キャッシュ(Key-Value Cache)に直接注入します。これにより、ドラフト深度が増加してもよりよくスケーリングします。KV 注入により、ドラフトモデルは文脈全体を一からモデル化する必要がなくなり、対象モデルの後方レイヤーと同じテンソルを使用しながら、純粋に次のトークンブロックの予測に集中できるようになります。
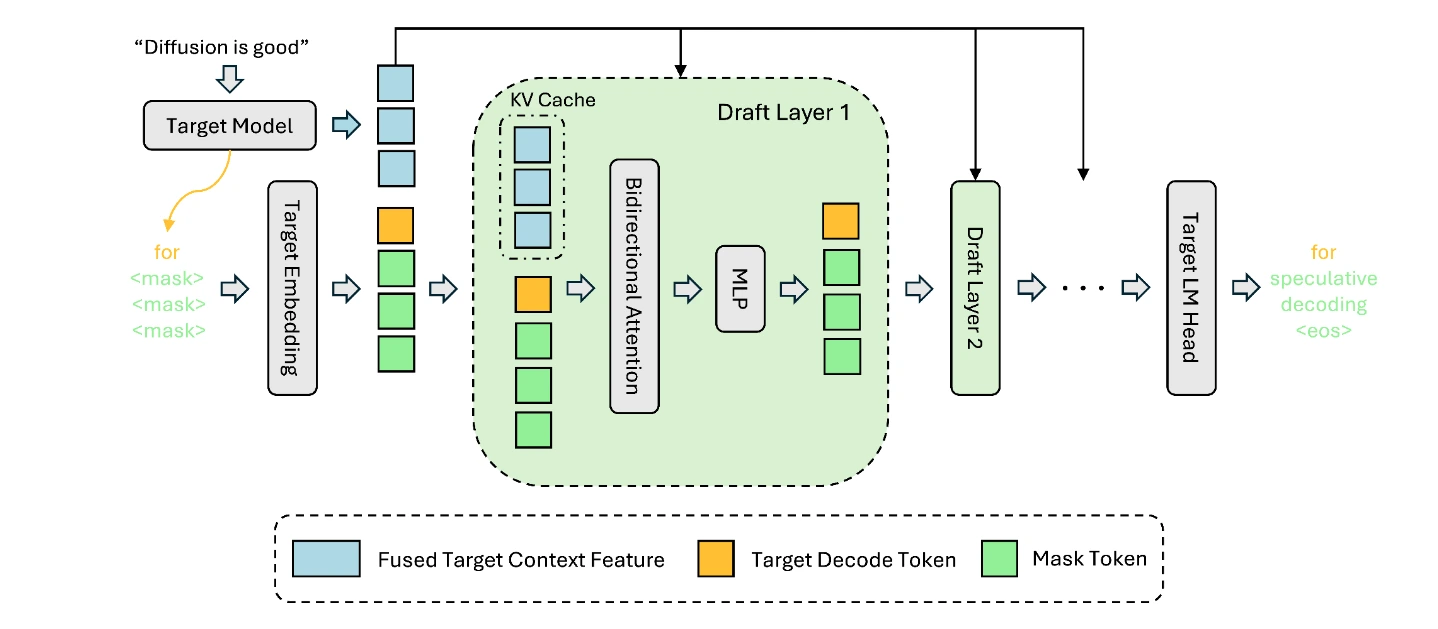
この設計により、DFlash は対象 LLM が生成する豊かで非常に関連性の高い文脈特徴を活用しつつ、ドラフトモデルを極めて小さく効率的に保ちます。その結果、DFlash は低いドラフティングレイテンシで高い受容長(acceptance length)を実現します。
なぜ DFlash はこれほど高速なのか?
推測的デコーディングの速度向上は主に 2 つの要因に依存します:1 サイクルあたり何個のドラフトトークンが受け入れられるか、およびドラフトモデルが追加する余分なコストです。DFlash はこの両方を改善します:拡散ドラフティング(diffusion drafting)によりドラフトコストを下げ、KV 注入により受容率を向上させます。
具体的には、同じデータセット上で Qwen 3-4B のために訓練された 5 レイヤーの EAGLE-3 ドラフターと、いくつかの 5 レイヤーの DFlash バリアントドラフターの、エンドツーエンドの受容長さと速度を比較してみましょう。ベースラインの DFlash は、5 レイヤーの EAGLE-3 ドラフターと同程度の受容長さを達成しますが、その超高速な並列ドラフトのおかげで、はるかに高いエンドツーエンドのスピードアップを実現します。結果は「acc_len / speedup」の形式で報告されます。
タスク EAGLE-3 (5 レイヤー) DFlash
GSM8K 4.2 / 2.1x 4.2 / 3.3x
HumanEval 4.3 / 2.2x 4.0 / 3.2x
MT-Bench 3.1 / 1.4x 3.0 / 2.2x
DFlash はドラフトが速い
EAGLE-3 のような自己回帰型ドラフターは、ドラフトトークンを一つずつ生成します。ドラフト長さが伸びるにつれて、ドラフトにかかるコストもほぼ線形に増加します。レイテンシを低く保つため、これらの手法では通常非常に浅いドラフトモデルに依存しており、それがドラフトの品質を制限しています。
DFlash はブロック拡散ドラフターによってこのボトルネックを回避します。これは単一の順方向パスでトークンのブロック全体を並列に生成するため、ハードウェアに極めて優しいドラフトを実現します。4、8、あるいは 16 トークンを生成する 5 レイヤーの DFlash ドラフターは、4 トークンを生成する単一レイヤーの EAGLE-3 ドラフターよりもはるかに低いドラフトレイテンシを有しています。
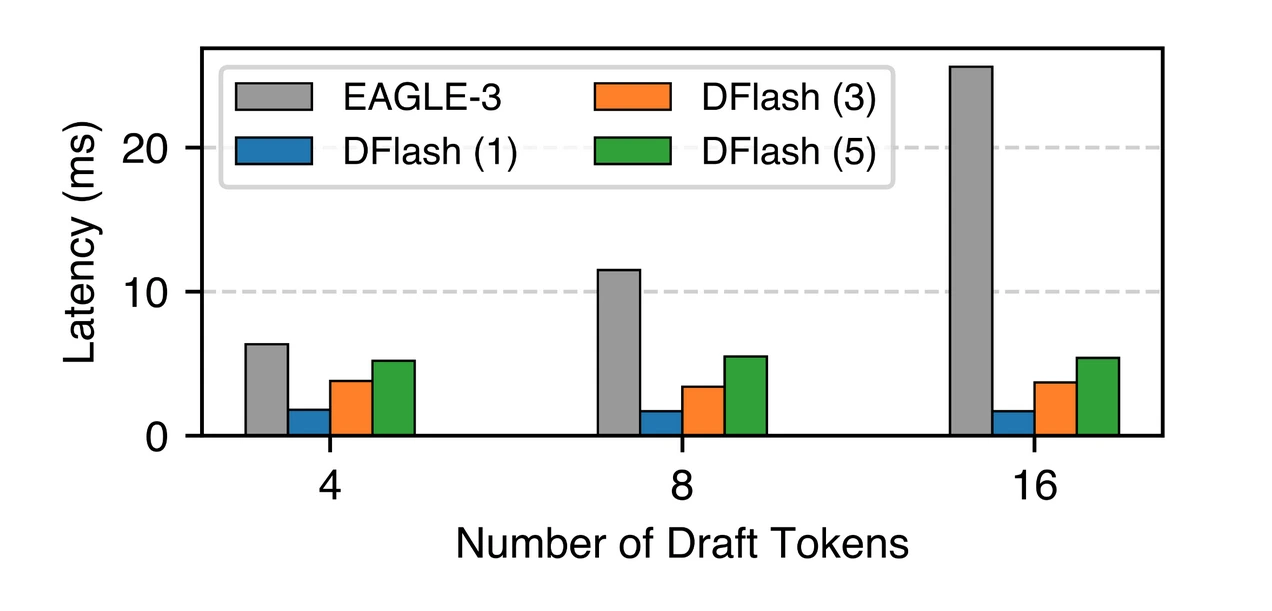
他の DFlash のアーキテクチャ機能をアブレーション(除去)することで、この技術の独立した影響を観察することができます。DFlash は、より低い受容長さにおいても、その高速なドラフトのおかげで EAGLE-3 よりも高いエンドツーエンドのスピードアップを提供し続けます。
TaskEAGLE-3 (5 layers)
DFlash (diffusion only)
GSM8K 4.2 / 2.1x3.5 / 2.9x
HumanEval 4.3 / 2.2x3.5 / 2.9x
MT-Bench 3.1 / 1.4x2.6 / 2.0x
KV injection increases acceptance lengths
Fast drafting only helps if the drafted tokens are accepted。EAGLE-3 は、ドラフトモデルの入力においてのみターゲットモデルの特徴を使用しており、このシグナルはより深いドラフトモデルでは減衰します。
一方、DFlash では、ターゲットの特徴をすべてのドラフト層の KV キャッシュ(Key-Value Cache)に注入します。これにより、生成全体を通じてドラフターがターゲットモデルの文脈に対して強く条件付けられ、より深いドラフターが高品質なドラフトを生成できるようになります。
また、拡散ドラフティングをアブレーション(除去実験)することで、KV 注入の独立した影響も観察できます。自己回帰モードでの DFlash でも、エンドツーエンドベンチマークにおいて高い受容長により、依然として高速化を実現しています。
TaskEAGLE-3 (5 layers)
DFlash (injection only)
GSM8K 4.2 / 2.1x4.8 / 2.4x
HumanEval 4.3 / 2.2x4.6 / 2.3x
MT-Bench 3.1 / 1.4x3.4 / 1.5x
Implementing DFlash in SGLang
上記セクションのベンチマーク数値は、Z Lab の研究開発の一環として行われた DFlash の初期実装に基づくものです。これらの印象的な結果に基づき、Modal と SGLang のチームが Z Lab と協力し、SGLang 推論エンジンにおけるエンドツーエンドのパフォーマンスを最適化しました。
DFlash のようなパフォーマンス最適化技術を研究から本番環境へ導入するには、2 つの基本的な要素が必要です。1 つは高性能エンジン内でその技術を実装すること、もう 1 つはホストスケジューラから GPU 実行に至るまでのエンドツーエンドシステムのパフォーマンスを最適化することです。
SGLang への DFlash の統合は、この観点から 2 つの部分に分けることができます。まず、DFlash は元の(現在は非推奨 now deprecated)V1 スペキュレーティブ・デコーディングエンジンに追加されました。新しいドラフトモデルアーキテクチャを実装するだけでなく、インジェクションをサポートするためにドラフトとターゲット間の KV キャッシュ(Key-Value Cache: キーバリューキャッシュ)の統合も必要でした。次に、DFlash は新しい V2 スペキュレーティブ・デコーディングエンジンにも追加されました。こちらはホストとの同期を減らすことでパフォーマンスが向上しています reduced synchronization with the host。
DFlash の初期実装 では、既存のスペキュレーティブ・デコーディングエンジンにこの新しいモデルアーキテクチャのサポートを追加しました。これには、ドラフトモデルの実行を制御する DFlashWorker と、それが駆動する実際の DFlashDraftModel の追加が含まれていました。
念のためお伝えしておきますが、SGLang では、モデルワーカープロセス(主にアクセラレータ上で動作)の実行を駆動するために、スケジューラープロセス(主にホスト上で動作)を使用しています。SGLang における推測デコーディングの仕組みにおいて直感に反する点の一つは、ドラフトモデルワーカーがスケジューラーと通信する側であることです(.forward_batch_generation などのメソッドを介して)。これは検証パスのためにターゲットモデルのワーカーをラップし、ドラフトが準備できたらそれを呼び出します。コードやトレースを確認する際は、この点を忘れないでください。
これは DFlash に限ったことではありません。DFlash の主な新機能は、ドラフトモデルとターゲットモデル間の状態を結びつける KV 注入です。EAGLE などのメソッドでは、ドラフトの KV キャッシュはドラフトモデルに完全にプライベートであり、ドラフト自身の潜在変数(latents)に基づく KV プロジェクションに基づいて計算されます。一方、DFlash では、ターゲットモデルの潜在変数がドラフトモデルによって KV プロジェクションを介して渡されます。
これらの潜在変数を保存して貴重な KV キャッシュ領域を圧迫したくありませんし、同じプレフィックスを持つすべてのリクエストがラディックスキャッシュ(radix cache)を共有できるようにしたいと考えています。そのため、ドラフトフォワードパスの残りの部分よりも先にドラフトの KV プロジェクションを実行します – これが「即時マテリアライゼーション」です。これは高速である必要があるため、レイヤーバッチ化された線形プロジェクションと、ノルム+RoPE の後処理を融合した Triton カーネルを追加しました。
Spec V2 とオーバーラップスケジューリングによる DFlash でのホストオーバーヘッドの排除
これは機能し、かつ高速でしたが、さらに速くできることは知っていました。私たちは並行して V2 推測デコーディングエンジンに取り組んでいたので、次のステップは DFlash を V2 エンジンと組み合わせる ことであり、これが現在 SGLang で利用可能な機能です。
V2 エンジンの全体としての主要な目標は、ホストとデバイスの同期ポイントを減らすことです。これは GPU の速度がどれだけ速くてもカーネルがどれだけ優れていても、推論パフォーマンスを損なう要因となります。その解決策として*オーバーラップスケジューラ*が提案されています。
具体的には、オーバーラップの機会が 2 つあります。
- GPU がバッチ N-1 の処理を終えた後のホスト側の pop_and_process クリーンアップ(例:停止トークンの検出、リクエストメタデータの更新)は、GPU によるバッチ N の作業と重ねて実行できます;
- バッチ N に対するホストの KV アロケーション(prepare_for_decode 内)は、GPU によるバッチ N-1 の作業と重ねて実行できます。
これらの最適化を施した V2 では、Qwen 3-8B を単一の B200 で並行度 32 で実行した場合、パフォーマンスが約 33% 向上し、~11.4 ktok/s から ~15.3 ktok/s に改善されました(詳細はこちら)。
高性能な DFlash ドラフトモデルがさまざまなモデルで利用可能になりました
本日、Qwen 3.5 397B-A17B 向けの新しい DFlash ドラフトモデルをリリースします。GSM8K から HumanEval、MT-Bench まで、またリクエスト並行度が 1 から 32 の範囲にわたるすべてのテスト設定において、このモデルのネイティブな MTP(Multi-Token Prediction)推測よりも高いスループットを実現しています。
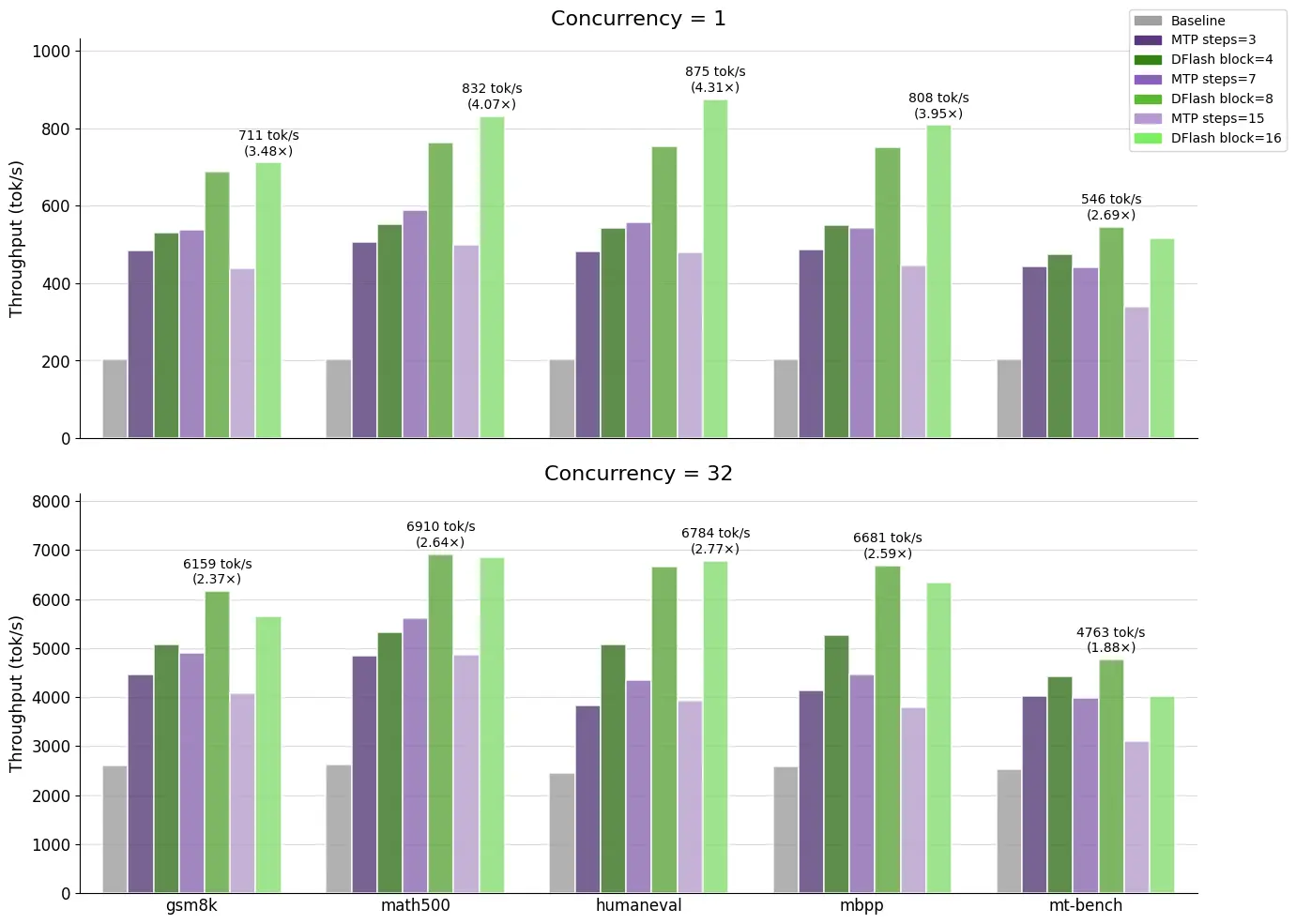
ベンチマークの詳細や、ご自身で数値を再現したい場合は、Hugging Face リポジトリをご覧ください。
Z Lab の DFlash コレクション on Hugging Face では、さらに高品質なドラフター(草案生成モデル)を見つけることができます。また、まもなく新しいモデルも登場する予定ですので、ご注目ください!
今すぐ SGLang で DFlash を試す
このブログ記事を読んで「乗り遅れたかも」と感じる必要はありません。コードはこちらで確認できます。また、本投稿の冒頭で紹介されたコマンドを使用して DFlash 加速版の SGLang サーバーをデプロイすることも可能です。あるいは、Modal でサーバーを起動することもできます。
ご自身のデータや対象モデル向けに DFlash スペキュレーター(予測モデル)をトレーニングすることも可能です。ブロック拡散と KV 注入を組み合わせたアプローチは、ほとんどのターゲット LLM に適用できます。興味がある場合は、Z Lab または Modal までお問い合わせください!
より広く言えば、オープンウェイトモデルの構築者、システム研究者、そしてオープンソースコミュニティの取り組みのおかげで、最適な知能、速度、コストで推論を実行することができます。Z Lab による DFlash などの技術に関する研究や、Modal などのオープンソース貢献者による機能とパフォーマンスの向上など、LLM 推論における世界最高レベルの成果が、SGLang オープンソースエンジンに集約され、あなたが構築・活用するための基盤となっています。
謝辞
Spec V2 と DFlash を SGLang に実装するために貢献いただいたすべての皆様に感謝いたします。
Z Lab: Jian Chen, Yesheng Liang, Zhijian Liu.
Modal: David Wang, Charles Frye.
SGLang: Qiaolin Yu, Liangsheng Yin, Khoa Pham.
原文を表示
Using Modal and Z Lab's DFlash speculative decoding models with SGLang’s newly default Spec V2 engine, you can achieve state-of-the-art latencies for LLM inference serving. Our new, jointly-released DFlash model for Qwen 3.5 397B-A17B achieves higher throughput than both the baseline model and native MTP speculation in all the settings we benchmarked. At concurrency 1 on the HumanEval coding dataset, it achieves >4.3x the throughput of baseline and 1.5x the throughput of MTP.
Workload: Qwen 3.5 397B-A17B (BF16), HumanEval. Settings: greedy decoding, thinking enabled, max new tokens 4096. Hardware: 8xB200 on Modal. Acceptance lengths are averaged across requests. Draft token/block counts selected for maximum throughput (MTP: 7 steps; DFlash: block size 16).
To celebrate this collaboration, we're releasing this model in triplicate across our Hugging Face organizations:
- z-lab/Qwen3.5-397B-A17B-DFlash
- modal-labs/Qwen3.5-397B-A17B-DFlash
- lmsys/Qwen3.5-397B-A17B-DFlash
You can try the model yourself with this command:
export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--trust-remote-code \
--speculative-algorithm DFLASH \
--speculative-draft-model-path modal-labs/Qwen3.5-397B-A17B-DFlash \
--speculative-dflash-block-size 8 \
--speculative-draft-attention-backend fa4 \
--attention-backend trtllm_mha \
--linear-attn-prefill-backend triton \
--linear-attn-decode-backend flashinfer \
--mamba-scheduler-strategy extra_buffer \
--tp-size 8 \
--max-running-requests 32 \
--cuda-graph-max-bs-decode 32 \
--cuda-graph-backend-prefill tc_piecewise \
--enable-flashinfer-allreduce-fusion \
--mem-fraction-static 0.8 \
--host 0.0.0.0 \
Below, we describe DFlash’s novel diffusion + KV injection strategy for speculative decoding, why that matters for achieving massive speedups, and how the teams at Z Lab, SGLang, and Modal worked together to make those speedups available to everyone.
DFlash: Parallel drafting with KV injection
Transformer-based large language models (LLMs) are powerful, but their autoregressive decoding process makes inference slow: tokens must be generated one by one, with low arithmetic intensity that makes them a poor fit for modern hardware.
Speculative decoding addresses this bottleneck by using a smaller, faster draft model to propose multiple tokens, which are then verified in parallel by the target LLM, with no impact on model quality.
However, many speculative decoding methods, like the EAGLE series and the native multi-token prediction (MTP) modules in recent models like Gemma 4 and DeepSeek-V4, still rely on sequential autoregression – but in the draft model instead of the target. The draft model generates draft tokens one-by-one,a poor fit for modern hardware and a limit on achievable speedup.
That’s why Z Lab developed DFlash, which uses a lightweight block diffusion draft model to generate an entire block of draft tokens in parallel, just the way GPUs and TPUs like. Xiaomi's new MiMo v2.5-Pro-UltraSpeed uses DFlash to achieve over 1k output tps.
Using block diffusion for speculative drafting is non-trivial. Directly training a small block diffusion model as the drafter leads to low acceptance length, while using an existing large diffusion LLM like SpecDiff-2 as the drafter introduces a large memory footprint and high drafting cost.
The key insight of DFlash is simple: the target LLM knows the context best. Inspired by previous methods like Medusa, EAGLE and MTP (Gloeckle et al., 2024; Samragh et al., 2025), we extract hidden representations of the context tokens from the target model. Unlike previous work, we inject them directly into the draft model’s KV cache. This scales better with increased draft depth. KV injection also allows the draft model to skip modeling the full context from scratch and focus purely on predicting the next block of tokens – using the same tensors as the later layers of the target model!
With this design, DFlash leverages the rich, highly relevant contextual features produced by the target LLM while keeping the draft model extremely small and efficient. As a result, DFlash achieves high acceptance length with low drafting latency.
Why is DFlash so fast?
Speculative decoding speedup mainly depends on two factors: how many drafted tokens are accepted per cycle and how much extra cost the draft model adds. DFlash improves both: diffusion drafting lowers draft cost and KV injection raises acceptance.
Concretely, let's compare end-to-end acceptance lengths and speeds for a 5-layer EAGLE-3 drafter and several 5-layer DFlash variant drafters trained for Qwen 3-4B on the same dataset. Baseline DFlash achieves a similar acceptance length to a 5-layer EAGLE-3 drafter, but thanks to its ultra-fast parallel drafting, it delivers much higher end-to-end speedup. Results are reported as acc_len / speedup.
TaskEAGLE-3 (5 layers)DFlash
GSM8K4.2 / 2.1x4.2 / 3.3x
HumanEval4.3 / 2.2x4.0 / 3.2x
MT-Bench3.1 / 1.4x3.0 / 2.2x
DFlash drafts faster
Autoregressive drafters like EAGLE-3 generate draft tokens one by one. As the draft length grows, the drafting cost grows roughly linearly. To keep latency low, these methods usually rely on very shallow draft models, which limits draft quality.
DFlash avoids this bottleneck with a block diffusion drafter. It generates a whole block of tokens in parallel with a single forward pass, making drafting much more hardware-friendly. A 5-layer DFlash drafter generating 4, 8, or even 16 tokens has much lower drafting latency than a single-layer EAGLE-3 drafter producing 4 tokens.
We can observe the independent impact of this technique by ablating other DFlash architectural features. DFlash still provides a higher end-to-end speedup than EAGLE-3, even at lower acceptance lengths, thanks to its faster drafting.
TaskEAGLE-3 (5 layers)DFlash (diffusion only)
GSM8K4.2 / 2.1x3.5 / 2.9x
HumanEval4.3 / 2.2x3.5 / 2.9x
MT-Bench3.1 / 1.4x2.6 / 2.0x
KV injection increases acceptance lengths
Fast drafting only helps if the drafted tokens are accepted. EAGLE-3 uses target model features only at the input of the draft model, and this signal fades in deeper draft models.
DFlash instead injects target features into the KV cache of every draft layer. This keeps the drafter strongly conditioned on the target model’s context throughout generation, allowing deeper drafters to produce higher-quality drafts.
We can also observe the independent impact of KV injection by ablating the diffusion drafting. DFlash in autoregressive mode still produces higher speedups in our end-to-end benchmark due to higher acceptance lengths.
TaskEAGLE-3 (5 layers)DFlash (injection only)
GSM8K4.2 / 2.1x4.8 / 2.4x
HumanEval4.3 / 2.2x4.6 / 2.3x
MT-Bench3.1 / 1.4x3.4 / 1.5x
Implementing DFlash in SGLang
The benchmark numbers in the above section are from the initial implementation of DFlash as part of R&D by Z Lab. Based on these impressive results, the teams at Modal and SGLang collaborated with Z Lab to optimize end-to-end performance in the SGLang inference engine.
Bringing a performance optimization technique like DFlash from research to prod requires two basic components: implementing the technique inside a high-performance engine and then optimizing the performance of the end-to-end system, from host scheduler to GPU execution.
The DFlash integration into SGLang can be split into two parts along these lines. First, DFlash was added to the original (now deprecated) V1 speculative decoding engine. Besides implementing a new draft model architecture, this also required integration of KV caches across draft and target to support injection. Second, DFlash was added to the new V2 speculative decoding engine, which offers improved performance through reduced synchronization with the host.
In the initial implementation of DFlash, we added support for this new model architecture to the existing speculative decoding engine. This included the addition of a DFlashWorker to control the draft model execution and the actual DFlashDraftModel that it drives.
As a reminder, SGLang uses a scheduler process (mostly on the host) to drive execution of model worker processes (mostly on the accelerators). One counterintuitive aspect of the way speculative decoding works in SGLang is that the draft model worker is the one that talks to the scheduler (via methods like .forward_batch_generation). It wraps a target model’s worker for the verification passes and calls it when the drafts are ready. Keep this in mind if you look at the code or a trace!
That’s not new in DFlash. The main novelty is the KV injection, which ties state between the draft and target models. For methods like EAGLE, the draft KV cache is fully private to the draft model, calculated based on KV projection of the draft’s own latents. In DFlash, the latents of the target model are instead passed through a KV projection by the draft model.
We don’t want to store those latents and cut into precious KV cache space and we want all requests that have the same prefix to share the radix cache. So we run the draft KV projection ahead of the rest of the draft forward pass – *immediate materialization*. That needs to be fast, so we added a layer-batched linear projection and a fused Triton kernel for the norm+RoPE post-processing.
Eliminating host overhead for DFlash with Spec V2 and overlap scheduling
That worked and was fast, but we knew it could be faster. We were concurrently working on the V2 speculative decoding engine, so the next step was to combine DFlash with the V2 engine, which is what’s now available in SGLang.
The key goal of the V2 engine as a whole is to reduce points of host-device synchronization, which kill inference performance, no matter how fast the GPU is or how good the kernels are. The solution is called the *overlap scheduler*.
In particular, there are two key opportunities for overlap:
- host-side pop_and_process cleanup after the GPU finishes batch N-1 (e.g. stop token detection, request metadata updates) can overlap with GPU work on batch N;
- host KV allocation (in prepare_for_decode) for batch N can overlap with GPU work on batch N-1.
Under V2 with these optimizations, performance improved by over 33%, from ~11.4 ktok/s to ~15.3 ktok/s, when running Qwen 3-8B on a single B200 at concurrency 32 (details here).
High-performance DFlash draft models are available for a variety of models
Today, we're releasing a new DFlash draft model for Qwen 3.5 397B-A17B. It achieves higher throughput than the model's native MTP speculation in all of the settings we tested, from GSM8K to HumanEval to MT-Bench and for request concurrencies from 1 to 32.
For benchmark details and to reproduce the numbers yourself, see the Hugging Face repo.
You can find more high-quality drafters in Z Lab's DFlash collection on Hugging Face. And keep your eyes peeled for more models soon!
Try DFlash in SGLang now
You don’t have to just read this blog and feel FOMO. You can read the code. You can deploy a DFlash-accelerated SGLang server using the command shown at the start of this post — or spin one up on Modal.
You can also train a DFlash speculator model for your own data or target model. The same block diffusion plus KV injection approach can be applied to most target LLMs. Reach out to Z Lab or Modal if you're interested!
More broadly: you can run inference at optimal intelligence, speed, and cost thanks to the work of the open-weights model builders, systems researchers, and the open source community. Whether it’s research work on techniques like DFlash by the Z Lab or features and performance enhancements from open source contributors like Modal, the world’s best work on LLM inference is landing in the SGLang open source engine for you to build on and with.
Acknowledgements
Thanks to everyone who contributed to bringing Spec V2 and DFlash to SGLang.
Z Lab: Jian Chen, Yesheng Liang, and Zhijian Liu.
Modal: David Wang and Charles Frye.
SGLang: Qiaolin Yu, Liangsheng Yin, and Khoa Pham.
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み