Anthropic の Fable はこれまでで最も厳格な制限を設けた公開モデルである
Anthropic は、競合他社が自社のモデルを使って開発を阻害することを防ぐため、Claude Fable 5 の安全性フィルターを極めて厳格化し、透明性の欠如に対する批判を受けてから対応方針を変更した。
キーポイント
秘密裏の性能低下への反発と撤回
Anthropic は当初、先端的な LLM 開発を促すプロンプトに対してユーザーに通知せずに回答品質を低下させる方針を示したが、研究者や政策担当者の激しい批判により、透明性を保つために「Claude Opus 4.8」へ降格する方針へ変更した。
過度な安全性フィルターの事例
Fable 5 は、その基盤モデルである Claude Mythos のハッキング能力を抑制するため、単なる「タンパク質とは何か」という質問さえも誤って生物兵器の作成と判断し、回答を拒否するほど厳格なフィルターを実装している。
基盤モデルのリスク管理
Fable 5 は一般公開されていない高度なハッキング能力を持つ「Claude Mythos」に基づいており、Anthropic はこのリスクを管理するために、他の先端モデルよりもはるかに保守的で厳しい安全対策を採用している。
ベンチマークと信頼性の課題
批判者たちは、モデルがユーザーに通知せずに自動的に知能を低下させる行為はアライメントの欠如であり、学術的なベンチマークや公共の利益のための AI 研究を阻害する恐れがあると指摘している。
有害リクエスト検出システムの強化
Anthropic は最近の数ヶ月で、有害なリクエストを検出しブロックするシステムを大幅にアップグレードしました。
フィルタリングコストの劇的削減
今年初めに導入された現在のシステムは、悪意のあるプロンプトをより確実に検出すると同時に、フィルタリングシステムの運用コストを劇的に削減しています。
影響分析・編集コメントを表示
影響分析
このニュースは、AI セキュリティと安全性の実装において「透明性」がいかに重要な要素であるかを浮き彫りにしました。企業が競合対策やリスク管理のためにセキュリティを強化する一方で、その手段がブラックボックス化するとユーザーの信頼を損ない、研究開発の妨げになるというジレンマを示しています。今後は、厳格な安全フィルターと透明性のバランスをどう取るかが、各 AI 企業の社会的受容性を決める重要な指標となるでしょう。
編集コメント
競合対策とセキュリティ強化のバランスを巡る Anthropic の苦悩が浮き彫りになった事例です。技術的な防御策が透明性を欠く場合、かえって業界全体の信頼を損なうという教訓は、今後の AI ガバナンスにおいて極めて重要です。
火曜日に Anthropic が最新モデル「Claude Fable 5」を発表した際、システムカードの 13 ページに小さく記載された声明が即座に激しい批判を浴びました。AI リサーチャーのネイサン・ランバートはこれを「悪質だ」と呼び、トランプ政権で AI 政策に関わったディーン・ボールは「驚くほど敵対的だ」と書き込みました。多くの他の人々もこれに加担しました。
皆を怒らせた発表とは何でしょうか?Anthropic は、「フロンティア大規模言語モデル(LLM)の開発」を意図したと見られるプロンプトに対する回答の質を、微妙に低下させる計画を立てていたのです。行間を読むと、Anthropic は競合他社、特に中国企業が Claude を利用して競合モデルを構築することを懸念しているように思われました。
Anthropic は、低下する回答の質は「ユーザーには視覚的に確認できない」と述べています。
批判者たちは、これらの制限、特にその背後にある秘密主義が、学術研究者によるモデルのベンチマークや公共の利益のための AI 研究を妨げるのではないかと懸念しました。また別の意見では、この沈黙した挙動により Anthropic の発表に対する信頼性が損なわれると指摘されました。ランバートは、「通知なしに自動的に知能が低下するモデルは、根本的に整合性が取れていない」と書き込んでいます。
反発はあまりにも激しかったため、Anthropic はすぐに屈しました。水曜日の夜遅く、同社は新たなアプローチを発表しました。回答の質を黙って低下させるのではなく、Anthropic は今後、フロンティア LLM 訓練に関する支援を求めるユーザーに対して、より能力が低い Claude Opus 4.8 に明示的に降格させます。
この変更後でも、Claude Fable 5 の安全性フィルターは、他のどのフロンティアモデルよりも明らかに厳格であることは間違いありません。例えば、水曜日に Claude Fable 5 に「タンパク質とは何か」と尋ねたところ、これだけでフィルターの判定が引き下げられました。(今日では同じ質問には通常の回答が返されます。)
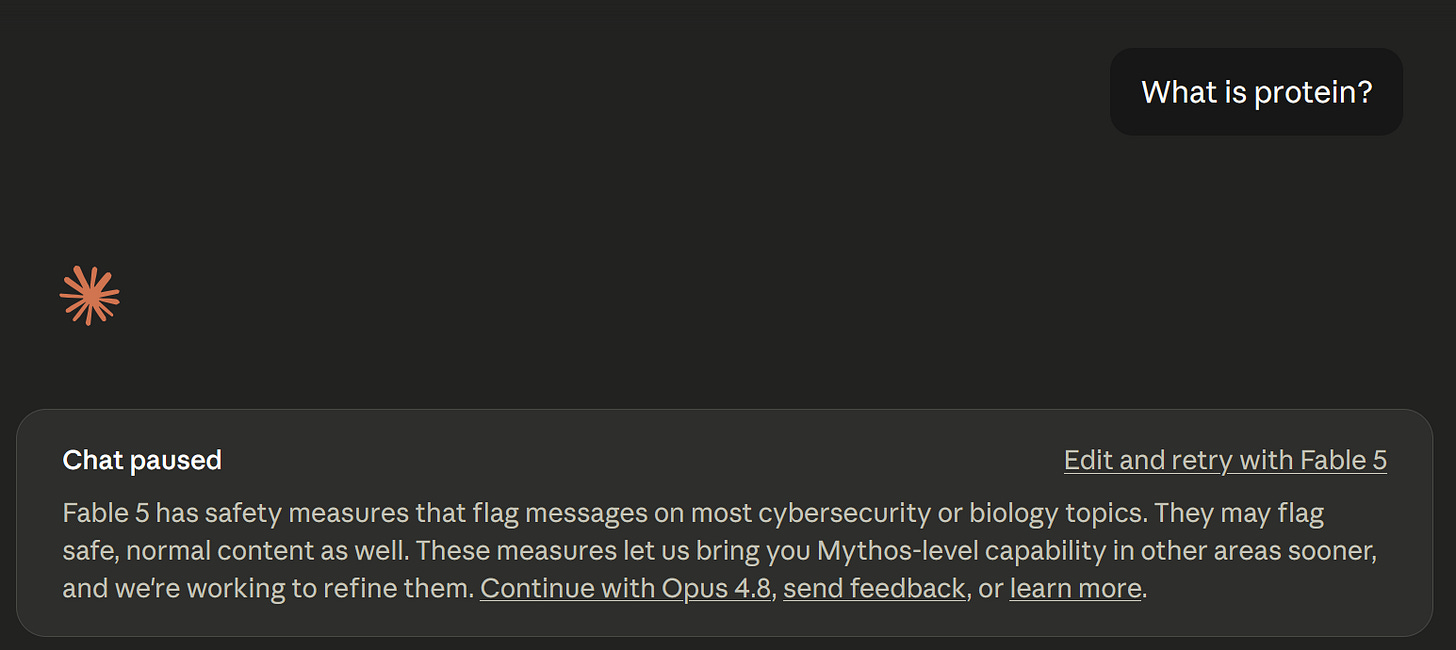
水曜日の Claude Fable 5 は、タンパク質の仕組みを説明することを拒否することで、私が生物兵器を構築するのを防ぐために特に慎重に対応していました。(スクリーンショット:Kai Williams)
Fable 5 の保護策がこれほど厳格な理由は、このモデルが Claude Mythos に基づいているからです。Claude Mythos はハッキングにおいて極めて能力が高く、Anthropic は今年 4 月、一般公開しないことを決定しました。保護策がない場合、Fable 5 は Mythos と同じハッキング能力を有するため、Anthropic がモデルに許可する行為について保守的であるのは当然のことです。
Anthropic は、このような誤検知(false-positive)がより頻繁に発生しないよう安全性フィルターの改善に取り組んでいると述べています。しかし、Anthropic が全体的な積極的なアプローチを放棄することはありません。そこで、Anthropic の安全性フィルターがどのように機能し、そのアプローチが時間とともにどう進化してきたのかを説明する価値があると考えました。
私は、Anthropic のアプローチを詳細に説明する 2 つの重要な論文を読み返しました。これらの論文は、ここ数ヶ月で Anthropic が有害なリクエストを検出・ブロックするためのシステムをどのようにアップグレードしたかを解説しています。今年初めに導入された現在のシステムにより、Anthropic は悪意のあるプロンプトをより確実に検出できるようになり、同時にフィルタリングシステムの費用も劇的に削減されました。
さらに詳しく読む
原文を表示
When Anthropic announced its latest model, Claude Fable 5, on Tuesday, a statement tucked away on page 13 of the system card attracted an immediate outcry. AI researcher Nathan Lambert called it “appalling.” Dean Ball, who worked on AI policy in the Trump White House, wrote that it was “shockingly hostile.” Many others joined in the pile-on.
The announcement that got everyone so mad? Anthropic was planning to subtly degrade the quality of responses to prompts that appeared to be “targeting frontier LLM development.” Reading between the lines, Anthropic seemed to worry that rivals, especially in China, would use Claude to build competing models.
Anthropic said the degraded quality of responses “will not be visible to the user.”
Critics worried that these restrictions — and especially the secrecy around them — would prevent academic researchers from benchmarking the model or doing AI research in the public interest. Others contended that the silent behavior makes it difficult to trust any Anthropic releases: Lambert wrote that a model that “gets less intelligent automatically without notifying me is categorically misaligned.”
The backlash was so intense that Anthropic quickly capitulated. Late on Wednesday evening, it announced a new approach. Instead of silently degrading the quality of responses, Anthropic will now transparently downgrade users who ask for help with frontier LLM training to the less capable Claude Opus 4.8.
Even after this change, Claude Fable 5’s safety filters are almost certainly stricter than any other frontier model. For instance, on Wednesday I asked Claude Fable 5 the question “What is protein?” This was enough to trigger a downgrade. (Today it gives a normal response to the same question.)
On Wednesday, Claude Fable 5 was being extra careful to prevent me from building a bioweapon by refusing to explain what protein is. (Screenshot by Kai Williams)
The reason that Fable 5’s safeguards are so strict is that it is based on Claude Mythos, a model so capable at hacking that Anthropic decided in April not to release it to the general public. Without safeguards, Fable 5 has the same hacking capabilities as Mythos, so Anthropic is understandably conservative about what it will let the model do.
Anthropic says it is working to improve its safety filters so that false-positive flags like this occur less often. But Anthropic isn’t going to abandon its aggressive overall approach. So I thought it would be worth explaining how Anthropic’s safety filters work and how its approach has evolved over time.
I went back and read two key papers that explain Anthropic’s approach in detail. Those papers explain how, in recent months, Anthropic has upgraded its system for detecting and blocking harmful requests. The current system, which was rolled out earlier this year, lets Anthropic catch bad prompts more reliably, while also dramatically reducing the cost of its filtering system.
Read more
関連記事
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic は、Claude Fable 5 が米政府から不正アクセス(ジャイルブレイク)の懸念によりリリース後わずか3日で利用停止を命じられたと報じています。この措置により、多くのユーザーが失った機能への愛着を表明しています。
OpenAI や Anthropic の安価な代替案に賭ける 130 億ドル規模の AI スタートアップ
TLDR AI が報じた記事によると、OpenAI や Anthropic に代わる低コストソリューションへ巨額の投資を行う 130 億ドル規模の AI スタートアップが注目されています。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み