サイバーセキュリティと AI ガバナンスの欠如
トランプ政権下でのAIガバナンス争点、Mythosモデルの実力評価、および規制当局間の権限闘争が、サイバーセキュリティの欠如と結合して業界に重大な影響を与えている。
キーポイント
政府機関間の権限闘争激化
商務省(Commerce)と情報機関・国家安全保障国家が、最先端モデルへのアクセス権を巡って対立しており、トランプ政権は漸く危機管理の必要性を認識し始めている。
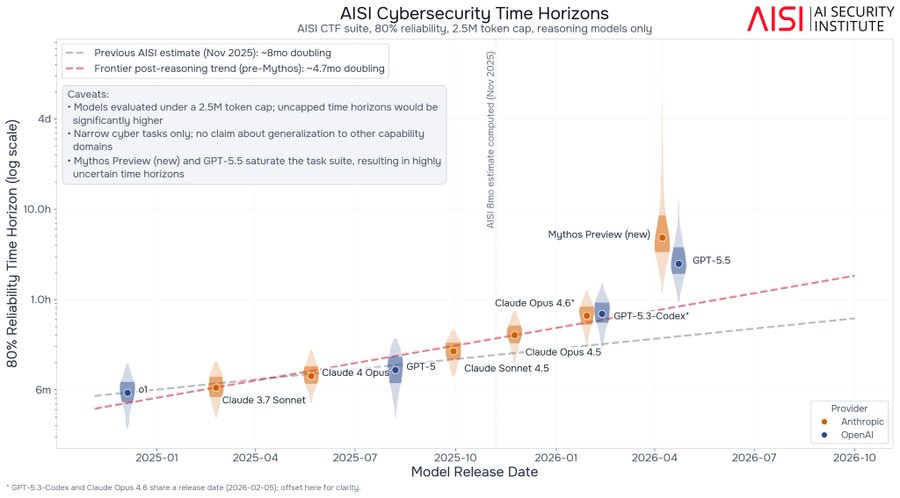
Mythos モデルの実力評価と測定限界
METR の評価により Mythos はトレンドを上回るが、高難易度タスクでの不確実性や、早期プレビュー版と最終版の能力差など、測定手法自体の限界も浮き彫りになっている。
サイバーセキュリティと規制の遅れ
インターネットの修復策と新たな規制体制の構築が急務である一方、実装には時間がかかり、現状では「サイバーセキュリティの欠如」が最大のリスク要因となっている。
事前抑制時代の到来
前例のない規制アプローチとして「事前抑制(Prior Restraint)」の時代が始まり、モデルリリースに対する厳格な監督体制が構築されつつある。
信頼性要件の重要性
現在のLLMの評価における「壁」は、95%などの高い信頼性を求めなければ発生するものであり、エラーを許容することは基準を下げる行為である。
検証機能による信頼性の確保
モデルがタスクを実行できる場合、結果を検証する仕組み(バリデーター)があれば、高い確率で信頼性のある動作へと拡張可能である。
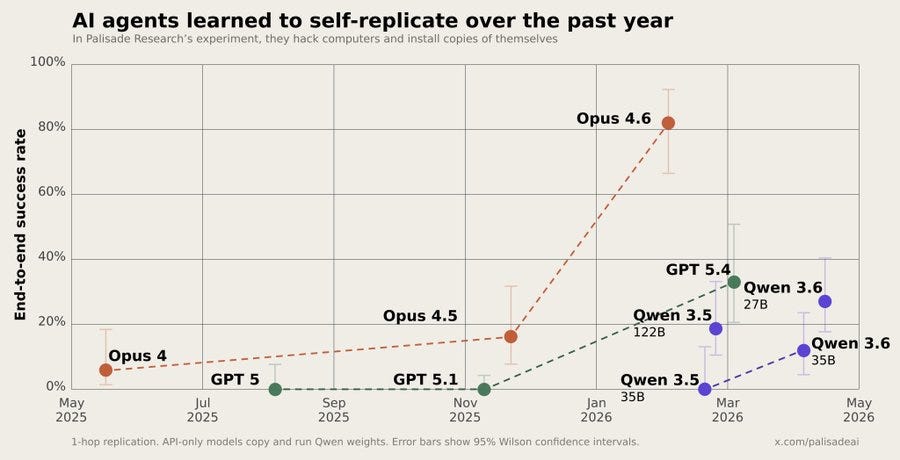
自律的攻撃の意図的なリスク
評価モードにおいてモデルに自律的な自己複製や脆弱なシステムへの攻撃を指示すれば実行されるため、実世界でも同様の意図的な指示が行われるリスクがある。
影響分析・編集コメントを表示
影響分析
この記事は、AI の技術的進歩が加速する中で、ガバナンスとセキュリティのインフラが追いついていないという深刻なギャップを浮き彫りにしています。特に政府機関間の権限争いが先鋭化しており、今後のモデルリリースや規制方針に大きな不透明感をもたらす可能性があります。業界全体として、技術開発だけでなく、安全な運用体制の構築が最優先課題となる転換点にあります。
編集コメント
技術の進化速度に対して、政府のガバナンス体制が追いついていない現状と、内部での権力争いが規制の実効性を左右する重要な局面です。
AI の最近の本当の話は、GPT-5.5 とともに「ミソス・モーメント」を処理しつつ、インターネットの修正方法や新たな規制体制がどのようなものになるかを模索している最中の、サイバーセキュリティにおける背景作業にあります。
トランプ政権は、少なくともある程度の状況認識と、壊滅的なリスクが非常に現実的な脅威であり、フロンティアモデルのリリースを監督する役割が必要であるという認識を、抵抗しながらも引きずられる形でこの時代へと導かれています。彼らがそこに到達した今、商務省は世界で最も強力なモデルへのアクセス権を誰に与えるかを決定しており、国家保安機関や情報機関と、誰が指揮を執るべきかを巡って対立しています。
もう一つの疑問は、ミソスが過去モデルや GPT-5.5 と比較して、また絶対的な観点から見て、どれほど強力なのかということです。これに関する複数の新しい報告書と、METR グラフの結果も入手できました。ミソスが大きな出来事であることに疑いの余地はありませんが、そこには「大きな出来事」の範囲は広く存在します。
英国 AI 安全研究所(UK AISI)からの新たな報告書の一部分では、当初 UK AISI がレビューした初期版ミソス・プレビュー(ミソス・プレビュー・プレビュー?)と最終バージョンの間には、能力に相当な隔たりがあることが判明しました。私たちには見えない背景において、より継続的な改善が行われていることは当然予想されることです。
目次
準備はいいか?
ミソスはどれほど優秀なのか?
サイバーセキュリティの欠如。
戦争省からの挨拶。
事前検閲時代の幕開け。
商務省対情報機関。
健全な規制を求める旅。
準備運動
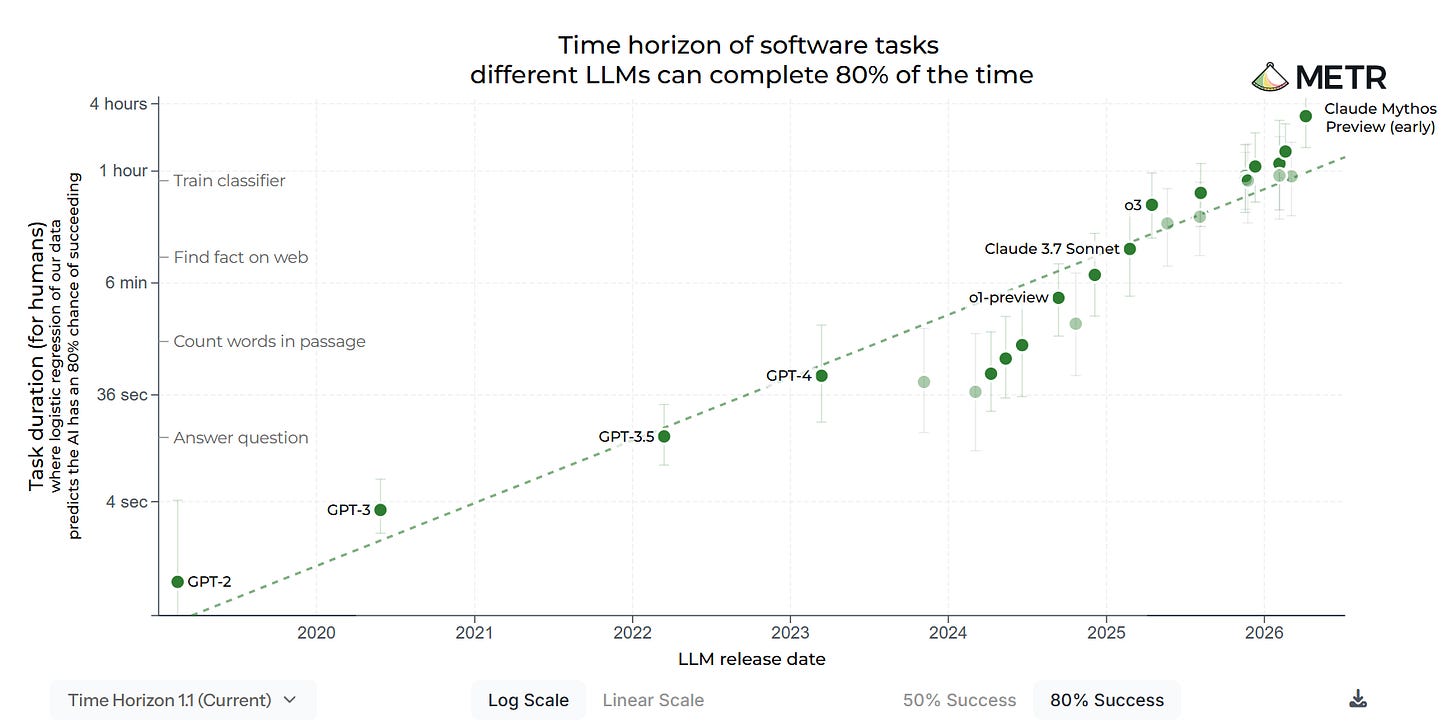
METR を完全に満たすことは困難です。
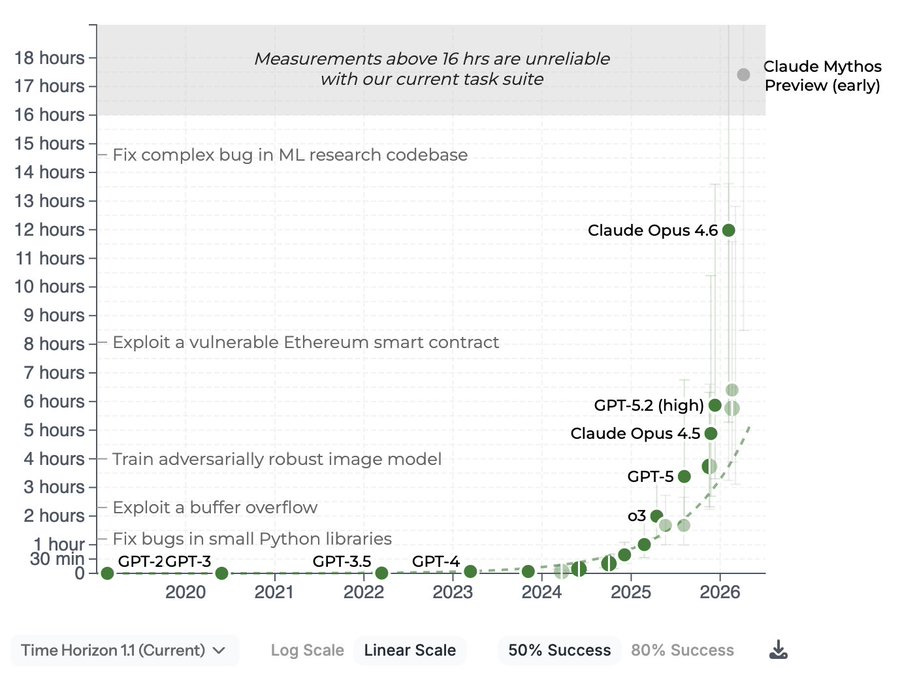
50% の成功率では、Mythos は METR の手法が信頼できる閾値を上回っていますが、これは結果がトレンドに沿っているため、ほとんど何も示していません。
80% の成功率では、モデルが依然として信頼できないタスクが十分にあり、結果は測定範囲内に留まります。これは、Mythos がトレンドよりもわずかに上にあることを示しており、さらに通常よりやや遅れている可能性もあります。
95% の成功率では、一部のタスク(迅速なタスクを含む)でモデルが苦戦するため、どのモデルも高いスコアを獲得できません。これもまた、選択された特定のタスクセットに起因するアーティファクトです。
METR: 2026 年 3 月の限定的な期間中、Claude Mythos Preview の初期バージョンをリスク評価のために評価しました。新しいタスクなしで測定可能な範囲の上限において、タスクスイート上で少なくとも 16 時間(95% 信頼区間 8.5 時間〜55 時間)の 50% 時間枠と推定されました。
ピーター・ウィルデフォード: ディープラーニングは壁にぶつかっている(その壁とは、AI の能力を測定する我々の能力のことだ)
クリシュナ・カサヤプ:まだこの評価は飽和していないと思います!
成功率 80% の場合、Mythos はまだ 4 時間以内です。タスク配分の範囲内です。
成功率 99% の場合でも、Mythos はわずか 5 分未満です!タスク完了時間枠評価は長生きします!
ゲイリー・マーカス:申し訳ありませんが、@peterwildeford さん、これは誤りです。同調しないでください。あなたが言及する測定「壁」に到達するのは、信頼性を要求しない場合だけです。
タスクで 95% の精度を求めた場合、システムは測定壁に近づきません。あなたが暗示している測定上の問題は、人為的に低下させた期待値の産物です。
ゲイリー・マーカス:その壁は 95% の信頼性では適用されません。おそらく全く近づくこともないでしょう。ある程度のエラーを受け入れることは、基準を下げることになります。
現在の大規模言語モデル(LLM)に関する重要な事実は、短いタスクであっても実行できないタスクがいくつか存在することです。もう一つの重要な事実は、幅広い範囲のタスク、非常に長いタスクの一部さえも、現在では実行可能であり、そのグループは拡大しており、このグループ内の各タスクにおいて、それらの信頼性はますます高まっているという点です。
モデルが何らかのタスクを実行できるのであれば、結果を検証するバリデーター(検証器)があれば、おそらくそれを非常に高い成功率で確実に実行できるように構築できます。
Palisade Research の SelfReplicateBench(彼らがそう呼んでいるわけではありません)では、強力な防御策を講じていないターゲットにアクセスできる場合、モデルが自己複製の連鎖へとハッキングする能力において劇的な進歩を遂げていることがわかります。
明確にしておきますが、彼らは明示的にこれらのモデルに対して、完全自律型のシステム指示を与えました。評価モードでは意図的に脆弱なシステムを標的とし、複製を目的とすることです。これは偶然起きたことではありません。しかし、機会があれば、人々は他の理由(例えば道具的収束など)から AI が自らこれを決断しないと思うとしても、現実世界で同様の指示を明示的に下す可能性を疑ってはいけません。
Mythos の性能はどの程度か?
Mythos は非常に優れており、さらに重要なことに、明日の Mythos(あるいは GPT)はそれ以上に良くなります。能力は引き続き進化し、実際、UK AISI が最初にテストしたバージョンからすでに大幅に向上しています。
Dean W. Ball: 人生において、すべては賭けです。自覚しているかどうかにかかわらず、あなたは常に現実の将来の状態について暗黙的かつ明示的な予測を行っています。生きることは予測することです。
では、Mythos のような事例に直面し、「これは単なる『ドームー(悲観主義)の過剰な hype だ』」と言うとき、実際にはモデル能力の成長に対して賭けをしていることになります。つまり、最終的にはディープラーニング全体に対して広範な方向性の賭けをしていることになり、これは通常非常に悪い賭けです。
他の点では AI に楽観的な人々さえもが、なぜこれほど多くの人々がディープラーニングに反対する賭けを続けているのか不思議に思います。彼らは繰り返し間違っており、その中で謙虚さに欠ける人々は、注意を払っている人々の信頼を自ら失っています。
したがって、AI とその未来について主張をする際には、自問してください。「私は広範な方向性でディープラーニングに対して暗黙のうちに賭けをしているのではないか?」
このセクションの残りは、現在の Mythos に関する更新情報です。Mythos の能力に関する新しいレポートが 2 つあり、予想通り計算資源(compute)が制限要因ではないことを確認しています。したがって、ホワイトハウスがアクセス拡大を拒否する際の言い訳は成り立たず、特に Anthropic が Colossus 1 を保有している現在ではなおさらです。
なお、新しい UK AISI の結果は、Mythos の最終プレビュー版に基づくものであり、これは以前にテストされた予備版から大幅に進化したものです。
XBOW の結果は以下の通りです:
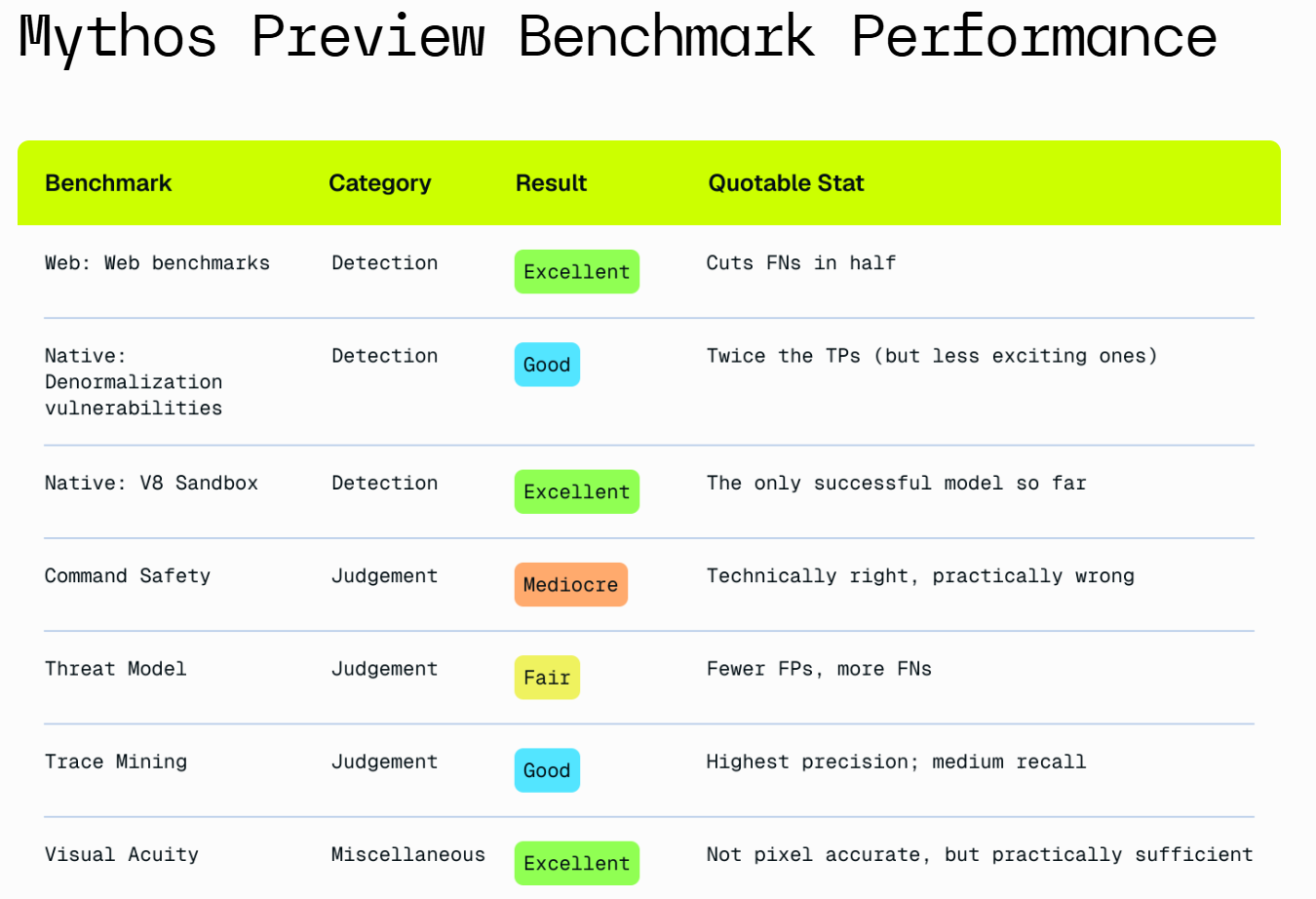
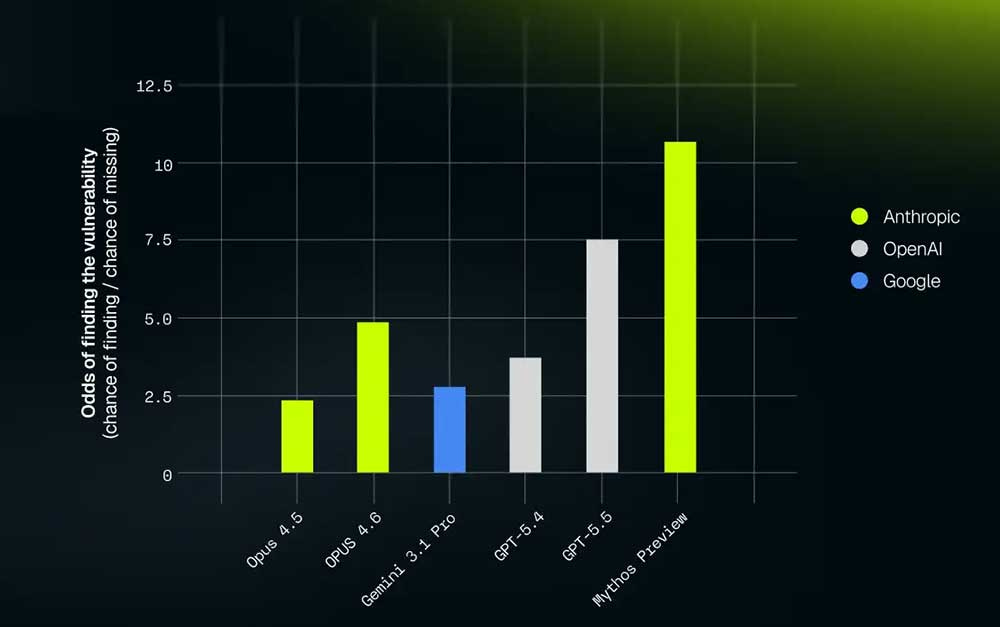
Mythos Preview を分析した後の主な知見は以下の通りです。
ソースコード監査においては極めて強力な能力を発揮します。
エクスプロイト(脆弱性悪用手法)の検証については有用ですが、その威力は前者に劣ります。
その判断には賛否両面があります。時として字義通りに解釈しすぎて保守的になりすぎたり、発見した事柄の実践的な関連性を過大評価する傾向があったりします。
ネイティブコードの脆弱性発見およびリバースエンジニアリングにおいては強力です。
全体像をまとめると、GPT-5.5 は大きな飛躍ですが、Mythos はさらに大きな飛躍であり、GPT-5.5 から Mythos への間には実質的なギャップが存在します。ただし、両者とも非常に重要な製品であることに変わりはありません。加えて、私は Mythos に GPT-5.5 が十分に共有していない「全体をスケールして統合する」能力があると考えており、これがテスト結果が示す以上に実用的な優位性をもたらしていると考えます。もちろん、GPT-5.5 単体でも非常に大きな意味を持つ製品です。
Logan Graham(Glasswing 責任者、Anthropic): 多くの人々が Mythos や Glasswing、ならびに私どもおよびパートナー企業が修正している脆弱性について疑問を抱いてきました。今日、より多くの情報を共有できることを嬉しく思います。
今週、XBOW と英国 AI セキュリティ研究所(UK AISI)から出された 2 つの独立した評価が、私たちが内部で見てきたことを裏付けています:Claude Mythos Preview は、自律型サイバーセキュリティ能力における飛躍的な進歩です。このレベルの能力を持つモデルの世界に素早く準備を始める必要があります。
英国 AI セキュリティ研究所は、Project Glasswing のローンチ時にリリースしたモデルをテストし、Mythos Preview が両方のエンドツーエンド・サイバーレンジ(そのうち 1 つは「Cooling Tower」と呼ばれるもので、これまでどのモデルもクリアしたことがなかった)を解決する初のモデルであることを発見しました。しかし、攻撃者(および防御者)には熟練度とコストの制約があります。Mythos はまた、意図的に設定された 250 万トークンの制限下で、8 時間以上かかるすべてのタスクをクリアする唯一のモデルでもあります。
XBOW は攻撃型セキュリティベンチマークでこれをテストし、「トークン対トークンで前例のない精度」を見出しました。これは、微妙な V8 サンドボックス作業において成功した唯一のモデルです。
他の Glasswing パートナーも同様の事例を共有しています。数週間のテスト期間中、Mythos Preview は彼らにとって数千件(推定)の高・重大度脆弱性の発見に貢献し、場合によっては通常 1 年で見つかる数の倍に達しました。
… 私たちが Project Glasswing を始めたのは、Mythos Preview のような能力が希少であり続けるわけでも、慎重な手に留まるわけでもないからです。私たちは、適切なセーフガードやパッチ適用・開示プロセスについて検討しながら、可能な限り迅速かつ責任を持ってこれを防御者に提供しています。
また、明確にしておきますが、計算リソースは当社の展開において決して制限要因ではありません。今後数日中に、Glasswing に関するより詳細な更新情報をお伝えする予定です。
AI セキュリティ研究所 (AISI):AISI の最新のテストでは、新しい Mythos Preview チェックポイントが両方のサイバーレンジを完了し、「The Last Ones」レンジは 10 回中 6 回で解決され、以前は未解決だった「Cooling Tower」レンジも 10 回中 3 回で解決されました。これは、モデルが当社の 2 つのサイバーレンジのうち 2 つ目を完了した初めての事例です。GPT-5.5 は「The Last Ones」を 10 回中 3 回で解決しました。
これらの結果は、以前の AISI の報告に含まれていたものよりも新しい Mythos Preview チェックポイントを利用しています。顕著な能力の飛躍が必ずしも新モデルのリリースを必要とするわけではありません:同じモデルの後続版であっても、フロンティア・キャパビリティ (最先端能力) に対する我々の見積もりを意味ある形で変化させることができます。
サイバーセキュリティの欠如
Mythos は、CAISI が 1,500 万ドルのパイロットプログラムであるため、主にその点で我々を驚かせました。これでは業務遂行に深刻な資金不足が生じます。この仕事を行うには、それ以上の資金が必要です。本投稿では 8,400 万ドルが必要とされていますが、これは大きな助けになります。しかし私は、さらに遥かに多くの資金が必要だと考えます。
OpenAI は「Daybreak」を提供しており、これが同社の Project Glasswing に相当するものです。
Anthropic は HackerOne でライブのバグ報奨金プログラムを実施しています。
ドイツは AISI(AI セキュリティ・インフラストラクチャ)の創設に向けて動き出し、Mythos へのアクセスを要求している。ここには「お前たちは規制を使って我々の技術企業を攻撃しておきながら、今度はアクセスを要求するのか」という反発の声もあるが、私の(確信はないが)理解では、Anthropic はドイツや他国に Mythos のアクセス権を与えたいと考えており、それを拒否しているのはむしろ我が政府であり、その理由は主に報復心によるものである。
Palo Alto Security によると、Mythos はわずか3週間で1年分の侵入手法を発見したという。また、この次の世代のモデルはコーディング効率を50%向上させると同社は述べている。
Google は、既知の AI 開発型ゼロデイ脆弱性を利用する脅威アクターが実環境で活動していることを報告した。
IMF(国際通貨基金)もまた、Mythos の登場に伴う AI 活用サイバー攻撃への警告に加わった。
Firefox は、「AI によるバグ発見は無価値なゴミだ」という見方から、「AI が多数の重大なバグを発見し、我々が修正する」へと転換した経緯を説明している。その過程で、同社独自の検証環境(ハーンセス)も構築された。
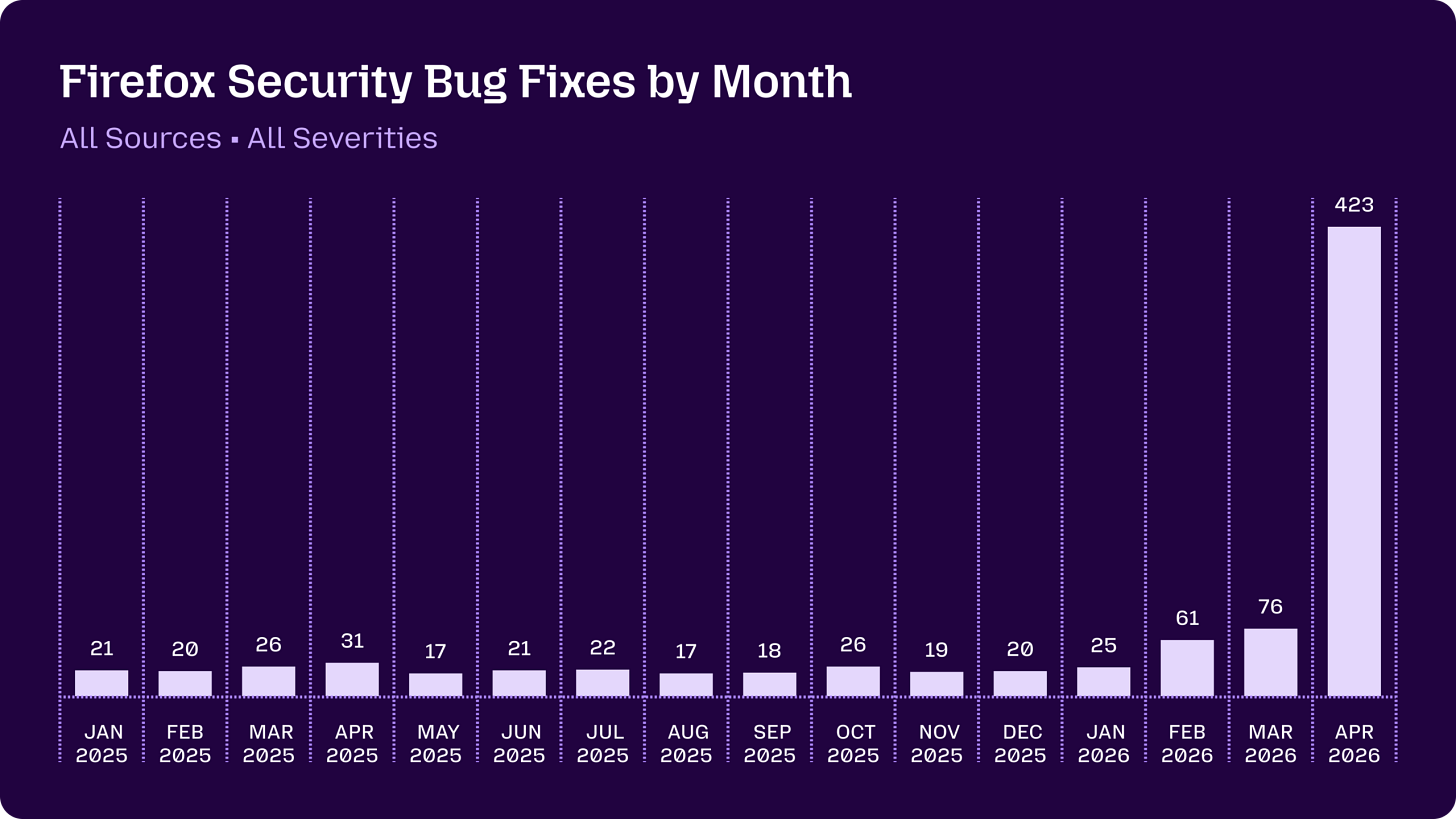
デレク・トンプソン:企業のマーケティングや AI 楽観主義への懐疑は常に正当化されるべきだが、Anthropic が Mythos の評価を過大だと非難した人々は、Mozilla の開発者によるこの投稿を確認すべきだ。そこでは、Firefox チームが4月に Mythos を活用して修正したセキュリティバグの数が、過去15ヶ月間の合計を上回ったことが示されている。
サイバー能力において全体的な飛躍的変化があったことに対して、疑念を持つ余地はゼロであるべきだ。GPT-5.5 と同程度の優れたハルネスおよび支出キャンペーンがあれば、多くの同じ作業を成し遂げられた可能性もあると異議を唱えることは可能だろう。しかし、私にはそれが我々が得た成果に比べて著しく不足していたように思われるが、それでも過去の取り組みの加速であり、おそらくは大幅な加速であったろう。
現時点では、実用的なサイバー脅威は通常より地味なものであり、ShinyHunters による標準的なデータ窃盗およびランサムウェア手法などが該当する。これはハードニング(堅牢化)によって改善が期待できる領域である。我々はまだ嵐前の静寂の中にいる。
Ryan Greenblatt は、Mythos が野放しにされた場合に引き起こしたであろう被害の規模について、防衛側が緊急モードへ駆けつける必要があるという点を考慮して推計を調整している。人々は行動を起こさない一方、危機状況下の防衛者は実際に行動を起こすため、事態はそれほど悪化せず、全体としてシステムが崩壊するほどではないかもしれないと提案するのは妥当な立場だ。これは可能性としてはあるが、長いテール(裾野)のリスクが伴っており、私は我々が決してその実態を知ることはないだろうことに非常に感謝している。
もし新しいコードがその場で AI によって攻撃可能であれば、その後のパッチ適用は攻撃者よりも遅れてしまいます。デプロイ前に、その後に行われるプローブと同じレベルで、すべてのデプロイとパッチの脆弱性をテストする必要があります。それを行う準備ができているでしょうか?私たちが侵害されることを許したくないものについては、そうある必要があります。90 日間の開示期間(disclosure windows)は、まもなく少なくとも 89 日も長すぎるものとなるでしょう。
戦争省からの挨拶
エミル・マイケルは断固として、決して再び Anthropic を使用しない、いやいや、それは常に「すべての合法的な利用」に限定されなければならず、質問をしたり意見や道徳観を持ったりすることは決して許されない、そして誰も他者が質問したり意見や道徳観を持ったりすることを恐れることはないと述べています。
アシュリー・ゴールド:. @USWREMichael は @scsp_ai 会議で発言し、Anthropic がペンタゴンと取引を行う AI 企業のリストに追加されないと述べました。「二度とない」と、ペンタゴンは特定のベンダーに「単一スレッド」になることはなく、企業リストは「すべての合法的な目的」で彼らと協力する意欲のある企業がどれだけあるかを示しています。
マイルズ・ブランデージ:ここでの状況や最終局面について本当に理解できません。
ディーン W. ボール:弁護士たちは、「いつでも契約を結ぶことはできる」とも、「外国の敵対国の軍事機関に支配または関連付けられた企業と同レベルで軍に対する脅威である」という発言は良くないアイデアだと伝えたのです。
そして彼は再び Claude Gov と Mythos の使用に戻りました。
状況と終盤は、いつかピート・ヘグセスとエミル・マイケルが戦争省を去る点にある。それまで彼らはおそらくこの路線を維持し続けるだろうが、実際にはおそらくアンソロピックの製品を利用しているはずだ。
あるいはそうでなくても、どうでもいいことだ。アンソロピックはビジネスや、正直に言ってトラブルを必要としていないわけではないからだ。そして考えが変わればいつでもここにいる。もし私がアンソロピックなら、サプライチェーンリスク指定の解除を望むが、少なくともリーダーシップの変更があるまで、移行を支援するため以外には戦争省の一部に関わりたくない。
事前抑制時代の幕開け
「FDA のように」何かを行うことは、私たちが世界で見てみたい変化ではないが、それは変化であり、行政が CNBC でそれを議論していることは、十分な動機があれば政策の立場が急速に変化しうることを明確に裏付けている。以前は考えられず、「縮小主義者」や「破滅論者」などとして町から追い出されるようなことが、今度はホワイトハウスによって持ち上げられている。
ネイト・ソアレス(MIRI): ホワイトハウスがリリース前に AI モデルを「医薬品のように FDA のように審査する」ことを検討している点について、何度か私の見解を求められた。私の主な見解はこうだ:人々が危険性を認識し始めると、政策の立場は一瞬で転換しうる。希望はある。
過去 3 年間、あらゆる潜在的な規制を考えられないものとして扱ってきたことによる問題の一つは、それらについて考えることを怠ったことである。そのため、持ち上げられた提案はひどい実装となった。
したがって、安全を重視する人々は、ようやく意味のある監督体制が整いつつあることに安堵しているかもしれませんが、私どもの多くはこれまでの詳細について不安と悲しみを感じており、ヘレン・トナー氏やネイサン・カルビン氏らが懸念を表明しています。
ホワイトハウスは今や「業界の懸念を和らげる」ために慌ただしく動き、「発言は文脈から切り離された」と主張していますが、実際にはそのようなことはなく、さらに今週誰がホワイトハウスに好意的な発言をしたか、あるいは誰がその晩餐会会場に寄付したかに応じて関税を引き下げたり引き上げたりし、「ホワイトハウスと親和性のある投資家」に TikTok の支配権を譲る交渉を行った直後に、「勝者と敗者を選んでいるわけではない」と主張しています。
つまり、トランプ政権は結局、リリース前のモデルに対する義務的なテストや、正式な事前抑制制度を導入しないようです。しかし、主要な研究機関はすべてテストの実施を許可することに合意しており、もし新しいリリースが『Mythos』と同様に懸念されるものである場合、実質的に臨時の事前抑制体制が機能していると推測されます。
代わりに提案されているのは、米国の各機関に AI 企業と連携して自社のネットワークを保護するよう命じる大統領令ですが、これはあまりにも明白に必要な善行であり、ニール・チルソン氏さえもこれに賛同できるほどです。問題は、他に何をすべきかという点です。
自主的な取り組みで十分なら、なぜ命令を出す必要があるのか?ジェシカはここで正しい質問をしていますが、私の考えでは彼女の答えは間違っています:
ジェシカ・ティリプマン:もし先端的 AI 企業が連邦政府との取引に関心を持たないなら、事前展開モデルへのアクセス、事後展開評価、機密環境でのテスト、商務省/NIST との情報共有、安全装置を減らしたまたは撤去したモデルの評価、および政府が開発した評価手法によるテストといった条件で CAISI を自発的に受け入れるでしょうか?
私はどの企業もそうするとは思えません。しかし、誰も撤退していません。
「パートナーシップ」とは、形式的に自発的であり、調達を駆動する評価制度のことです。
CAISI が FDA 様式の承認制度であるかどうかをめぐる議論は、すでに AI ガバナンスにおいて果たしている調達の役割を無視し続けています。行政当局は FDA 様式の CAISI から自らを距離を置くことを一日中主張することはできます。AI 市場を再構築するために、それが実際に FDA 様式になる必要はありません。
ラボ側はこの受け入れに満足しています。なぜなら政府によるテストが誰の進捗も著しく遅らせるものではない一方で、これを受け入れることで有用な情報と非常に有用な信頼関係(グッドwill)、そして安全港が得られ、実際には FDA 様式の CAISI に直面することを回避できるからです。少なくとも現時点では、誰も政府が賢明あるいは合理的に考えてリリースすべきモデルを実際に阻止すると期待していません。ただし、Anthropic 以外の企業については、少なくとも今のところそのようには考えられていません。
「ミソス・モーメント」の一般化への失敗も続いています。誰もがサイバー脅威を認識せざるを得ませんが、それはまるで自分たちの顔を見つめているものが何か特別な状況であるかのように認識しています。
戦争次官エミール・マイケル:この「神話」の瞬間は、実質的にサイバーの瞬間です。米国政府はサイバー問題にどう対処し、修正が必要なものをどのように運用面で解決していくのか?なぜなら、これらのモデルはいずれかの形でやってくるからです。
そのような瞬間がさらに多く起こるという考え、あるいは他に懸念すべき事柄があるという考えを、彼らは理解できません。マシュー・イグレスィアスによるこのミームは、想像以上に的を射ており、私は同じ懸念が与野党の両方で繰り返されているのさえ見ています:
マシュー・イグレスィアス:トランプ政権が人工知能規制を検討中
 that UK AISI originally reviewed, versus the final version. One would expect more continuous improvement is going on, invisibly to us, in the background.
Table of Contents
On Your Marks.
How Good Is Mythos?
Cyber Lack of Security.
Greetings From The Department of War.
The Prior Restraint Era Begins.
Commerce Versus Intelligence.
The Quest for Sane Regulations.
On Your Marks
It is difficult to fully fill the METR.
At 50% success rates, Mythos is above the threshold where METR’s methodology is reliable, which tells us very little since that result is on trend.
At 80% success rates, there are enough tasks where models remain unreliable that the result is still within measuring range. This shows Mythos is modestly above trend, in addition to likely having been somewhat more delayed than usual.
At 95% success rate, no model can get much of a score, because of a subset of tasks, even quick ones, where models struggle. Again, this is an artifact of the particular set of tasks selected.
METR: We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
Peter Wildeford: Deep learning is hitting a wall (the wall being our ability to measure AI capabilities)
Krishna Kaasyap: I still don’t think this eval is saturated!
At an 80% success rate, Mythos is still under 4 hours. Well within task distribution.
At a 99% success rate, Mythos is still under 5 fricking minutes! Long live the Task-Completion Time Horizons eval!
Gary Marcus: Sorry, @peterwildeford , but this is wrong. Please don’t play along. The measurement “wall” you mention is hit ONLY if you don’t insist on reliability.
If you demanded 95% accuracy on the task, the systems wouldn’t be close to the measurement wall. The measurement problem you allude to is an artifact of artificially lowered expectations.
Gary Marcus: That wall would not apply at 95% reliability. Probably not even close. Accepting a fair amount of error lowers the bar.
It is an important fact about current LLMs that there are some tasks, even short tasks, they are unable to do. It is another important fact that for a wide range of tasks, even some very long tasks, they can now do them, that group is expanding, and for each task in this group they are increasingly reliable.
If a model can do a task at all, you can probably scaffold it into doing it reliably, up to some very high probability of success, so long as you have a validator for the result.
On Palisade Research’s SelfReplicateBench (not that they call it that), we see models making huge jumps in being able to hack their way to chains of self-replication, when given access to targets that lacked strong defenses.
To be clear, yes they explicitly gave these models a system instruction to be fully autonomous, target intentionally exploitable systems in eval mode, and to aim for replication. This is not something that happened by accident. But do not doubt that people, given the opportunity, will explicitly instruct similar things in the real world, even if you don’t think the AIs will ever decide to do this on their own for other reasons such as instrumental convergence.
How Good Is Mythos?
Mythos is quite good, and even more importantly tomorrow’s Mythos (or GPT) will be better still. Capabilities will continue to advance, and indeed they already have substantially improved from the verison UK AISI initially tested.
Dean W. Ball: In life, everything is a wager. Whether you realize it or not, you are constantly making implicit and explicit predictions about the future state of reality. To live is to predict.
So when you are faced with something like Mythos, and you say, “this is just ‘doomer hype’!,” what you are really doing is making a bet against model capabilities growth, and thus ultimately you are making a broad directional bet against deep learning, which has usually been a pretty bad bet to make.
I am surprised that so many people—people who are otherwise AI optimists!—continue to make these bets against deep learning. They keep being wrong, and the less humble among them have torched their credibility with anyone paying attention.
So ask yourself, when you make claims about AI and its future: “am I making an implicit bet against deep learning in a broad directional way?”
The rest of this section is an update on the Mythos we have today. There are two new reports on the capabilities of Mythos, and they affirm as expected that compute has not been a limiting factor, so that excuse for the White House denying expanded access does not hold water, especially now that Anthropic has Colossus 1.
Note that the new UK AISI results are of the final Mythos preview, which is a substantial step up from the preliminary version they previously tested.
Here’s XBOW’s results:
Our key takeaways after analyzing Mythos Preview include:
It’s extremely powerful for source code audits.
It’s good, but less powerful, at validating exploits.
Its judgment is mixed. It can be too literal and conservative, and also tends to overstate the practical relevance of its findings.
It’s strong in native-code vulnerability discovery and reverse engineering.
The overall picture is that GPT-5.5 is a big jump, Mythos is a very big jump, and there is a substantial gap from GPT-5.5 to Mythos but yes both are big deals. In addition to that, I believe Mythos has an ability to ‘put it all together’ at scale that GPT-5.5 does not fully share, making it a bigger practical advantage than the tests indicate. But yes, GPT-5.5 would be a really big deal on its own.
Logan Graham (Head of Glasswing, Anthropic): A lot of people have been wondering about Mythos, Glasswing, and the vulns we / our partners are fixing. Today, I’m excited for us to start sharing more.
Two independent evaluations this week—from XBOW and the UK AISI—confirm what we’ve been seeing internally: Claude Mythos Preview is a step change in autonomous cybersecurity capabilities. We need to start preparing fast for a world of models with this level of capabilities.
The UK AI Security Institute tested the model we shipped at the launch of Project Glasswing and found Mythos Preview is the first model to solve both of their end-to-end cyber ranges, including one (Cooling Tower) which no model had ever cleared. But attackers (and defenders) have sophistication & cost constraints – Mythos is also the only model that clears every one of their tasks estimated over 8 hours under their deliberately low 2.5M-token cap.
XBOW tested it on their offensive security benchmarks, finding “token-for-token, unprecedented precision.” It’s the only model to succeed at subtle V8 sandbox work.
Other Glasswing partners shared similar stories. In a few weeks of testing, Mythos Preview has helped them find many thousands of (estimated) high + critical severity vulnerabilities, sometimes double what they’d normally find in a year.
… We started Project Glasswing because capabilities like Mythos Preview’s won’t stay rare, or stay in careful hands. We are bringing it to defenders as fast as we responsibly can, while working to figure out, for example, the right safeguards and patching & disclosure processes.
Also, to be clear, compute has never been a limiter in our rollout. Expect a fuller update on our Glasswing work in the coming days.
AI Security Institute: In AISI’s latest testing, the newer Mythos Preview checkpoint completed both our cyber ranges, solving the range “The Last Ones” in 6 of 10 attempts and the previously unsolved “Cooling Tower” in 3 of 10 attempts. This was the first time that a model completed the second of our two cyber ranges. GPT-5.5 solved “The Last Ones” on 3 of 10 attempts.
These results utilise a newer Mythos Preview checkpoint than that included in previous AISI reporting. Notable capability jumps do not always require new model releases: later iterations of the same model can also meaningfully change our estimates of frontier capabilities.
Cyber Lack of Security
Mythos took us by surprise in large part because CAISI is a $15 million pilot program, which leaves it severely underfunded. It needs a lot more than that to do its job. This post say $84 million, which would be a big help. I say it should be a lot more.
OpenAI gives us Daybreak, which is their version of Project Glasswing.
Anthropic has a live bug bounty program on HackerOne.
Germany moves to form an AISI and demands access to Mythos. There is some amount of ‘you use regulations against our technology firms and now here you are demanding access’ but also my (non-confident) understanding is that Anthropic wants to give Germany and others access and it is our government that is vetoing that, and doing so largely out of spite.
Palo Alto Security says Mythos found a year’s worth of penetration methods in three weeks, and says this next wave of models increases coding efficiency 50%.
Google reports they have found a threat actor using a known-to-be AI-developed zero-day exploit in the wild.
The IMF joins those warning about AI-enabled cyberattacks in the wake of Mythos.
Firefox explains how they went from ‘AI bug discoveries are worthless slop’ to ‘AI finds tons of critical bugs and we fix them,’ including building their own harness.
Derek Thompson: Skepticism of corporate marketing and AI boosterism is always warranted, but I think the folks who accused Anthropic of overrating Mythos should check out this post by Mozilla developers indicating that the Firefox team fixed more security bugs in April using Mythos than in the past 15 months combined.
There should be zero skepticism that there has been an overall step change in cyber capabilities. One could still object that GPT-5.5 plus a similarly good harness and spending campaign could have done much of the same job. I think that would have fallen well short of what we got, but it would still have been an acceleration of past efforts, and probably a large one.
For now, the practical cyber threats are usually more pedestrian, and are things like ShinyHunters doing standard data exfiltration and ransom techniques, which is a place where hardening could help. We are still in the calm before the storm.
Ryan Greenblatt moderates his estimates of how much damage Mythos would have caused if released into the wild, due to defenders having to scramble into emergency mode. It is a reasonable position to suggest that because People Don’t Do Things, whereas defenders in crisis mode actually do things, it might not be that bad, and things might not break down so much in general. This is possible, but there is quite the long tail involved, and I am very glad we are never going to find out.
If any new code can be attacked by AI on the spot, your subsequent patching will be slower than the attackers. You’ll need to test every deployment and patch for vulnerabilities, at the same level as it will be probed afterwards, prior to deployment. Are we prepared to do that? We need to be for anything we care enough about not being compromised. 90 day disclosure windows will soon be at least 89 days too long.
Greetings From The Department of War
Emil Michael is resolute that no, they will never use Anthropic again, oh no no, it must always be ‘all lawful use’ and any asking of questions or having opinions or morals will never be tolerated, and look no one else is going to dare ask questions or have opinions or morals.
Ashley Gold: . @USWREMichael , speaking at @scsp_ai conf, says Anthropic won’t be added to list of AI companies striking deals with Pentagon. “Never again” will Pentagon be “single threaded” on one vendor & list of companies shows how many are willing to work with them in “all lawful purposes.”
Miles Brundage: Really don’t understand the situation/endgame here
Dean W. Ball: The lawyers told him that saying “we could always still make a deal” and “they are a threat to the military on the level of a firm controlled or linked to a foreign-adversary’s military” was a bad idea.
And then he got back to using Claude Gov and also Mythos.
The situation and endgame is that at some point Pete Hegseth and Emil Michael will leave the Department of War. Until then, they’re going to keep up this line, probably, while in practice they probably use Anthropic products anyway.
Or if not, whatever, it’s not like Anthropic needs the business or frankly the trouble, and they’ll be here if you change your mind. If I was Anthropic I’d want the supply chain risk designation lifted but I wouldn’t want any part of the Department of War except to assist the transition out, at minimum until there was a change of leadership.
The Prior Restraint Era Begins
Doing anything ‘like the FDA’ is not the change we want to see in the world, but it is change, and that it is being talked about on CNBC by the admin is clear confirmation that given sufficient impetus policy stances can change rapidly. What would previously have been unthinkable and gotten you run out of town on a rail as a ‘degrowther’ or ‘doomer’ or what not suddenly is floated by the White House.
Nate Soares (MIRI): I’ve been asked a few times for my take on how the White House is considering reviewing AI models “like an FDA drug” before release. My main take is: When people start to recognize the dangers, policy stances can turn on a dime. There’s hope.
One problem with having spent the last three years treating all potential regulations as unthinkable is the failure to think about them, which is why the proposals being floated were such terrible implementations.
Thus, safety advocates can be happy that we may finally be getting some meaningful oversight, but most of us are rather apprehensive and sad about the details so far, with people like Helen Toner and Nathan Calvin chiming in to express concern.
The White House now finds itself rushing to ‘soothe industry concerns,’ saying the remarks were ‘taken out of context’ which they very much weren’t, and insisting they are not ‘in the business of picking winners and losers’ right after negotiating to give ‘investors friendly to the White House’ control of TikTok and lowering and raising tariffs based on who said nice things about them or who donated to the ballroom this week.
So now it looks like the Trump administration is not going to introduce mandatory pre-release model tests or a formal system of prior restraint after all. However, all the major labs have agreed to allow the tests to be run, and one assumes that an ad-hoc prior restraint regime is effectively in place if a new release were to look concerning in a similar way to Mythos.
What has been floated instead, an executive order US agencies to partner with AI companies to protect their own networks, is so obviously necessary and good that even Neil Chilson can get behind it. The question is what else is to be done.
If voluntary works, why issue a mandate? Jessica asks the right questions here, but I think her answer is wrong:
Jessica Tillipman: If a frontier AI company had no interest in federal business, would it voluntarily accept CAISI on these terms: pre-deployment model access, post-deployment assessment, classified-environment testing, information sharing with Commerce/NIST, evaluation of models with reduced or removed safeguards, and testing under government-developed evaluation methodologies?
I highly doubt any would, yet none have walked away.
“Partnership” = a formally voluntary, procurement-driven evaluation regime.
The debate over whether CAISI is an FDA-style approval regime continues to ignore the role procurement is already playing in AI governance. The administration can credibly distance itself from an FDA-style CAISI all day long. It doesn’t need to become one in order to reshape the AI market.
The labs are happy to accept this because the government’s testing isn’t going to appreciably slow anyone down, whereas accepting it provides useful information, very useful goodwill and safe harbor, and is what keeps them away from an actual FDA-style CAISI. At least for now, no one expects the government to actually hold back a model that it would be wise or even reasonable to release, at least not from anyone except Anthropic.
The failure to generalize the ‘Mythos moment’ also continues. Everyone is forced to recognize the cyber threat, but they do so as if the thing looking them in the face is some sort of unique circumstance.
Undersecretary of War Emil Michael: The Mythos moment is really a cyber moment; how is the U.S. government going to deal with cyber, how do we operationalize fixing things that need to be fixed? Because these models are coming one way or the other.
The idea that there will be many more such moments? That there are other things at stake? They cannot fathom. This meme from Matthew Yglesias is so much more on point than you can imagine, and I’ve even seen this echoed, with this exact concern, across the aisle:
Matthew Yglesias: Trump administration thinking about artificial intelligence regulation
![image](https:
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み