Anthropic が Claude を活用したセルフサービスデータ分析を可能にする方法
Anthropic は、LLM を単なるコード生成ツールとして扱うのではなく、文脈と検証を重視する設計パターンを採用することで、データ分析の自己サービス化における精度と信頼性を大幅に向上させるベストプラクティスを公開した。
キーポイント
従来の課題と LLM の限界
広範な非正規化テーブルや分断された環境によるデータの一貫性欠如、および単純な LLM エージェント導入における「精度の錯覚」が指摘されている。
文脈と検証の重要性
分析の精度はコード生成能力の問題ではなく、適切な文脈提供と結果の検証プロセスに依存するという根本的な認識転換を提案している。
失敗モードの特定と対策
LLM エージェントがエラーを起こす主な 3 つの失敗モードを特定し、それらを克服するための「エージェント分析スタック」を構築した具体的なアプローチを示している。
実証された成果と効果測定
Anthropic 内部では Claude を活用してビジネス分析クエリの 95% を自動化し、集計精度も約 95% に達しており、データサイエンティストを戦略的業務へシフトさせた実績がある。
影響分析・編集コメントを表示
影響分析
この記事は、LLM をビジネスインフラに組み込む際の「実用化の壁」を打破する具体的な設計思想を示しており、単なる技術紹介を超えて組織変革の指針となる。特に「精度の錯覚」への警告と、それを回避するための文脈・検証フレームワークの提示は、他社が同様のシステムを構築する際の重要なベンチマークとなるだろう。
編集コメント
LLM の実装における「精度の錯覚」という本質的な課題を指摘し、具体的な解決策(文脈と検証)を示した点で非常に示唆に富む記事です。技術的な深みがあり、データ分析分野での AI 導入を検討している組織にとって必読の内容と言えます。

- カテゴリ
- 製品Claude Code
- 日付2026年6月3日
- 読了時間5分
- シェアリンクをコピーhttps://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
多くのデータサイエンスおよびデータエンジニアリングチームが証言するように、セルフサービス型ビジネス分析の機能強化は従来、非常に過酷な作業でした。
技術的な知識が少ない同僚のために、広範で非正規化されたテーブルを通じてデータモデルをよりアクセスしやすくすることは、事業規模が拡大するにつれて定義が矛盾した重複したビューを生み出す結果となり(SQLを学ぶ意欲の低い従業員との間のギャップを埋める効果はほとんどなく)、あるいはユーザーに対してより厳格に隔離された環境を作成することは、ビジネス上の質問の長尾部分を捉え損ない、チームが業務をサイロ化することでメトリクスやダッシュボードが肥大化する原因となります。
大規模言語モデル(LLM)の台頭は、これらの課題を回避するセルフサービス分析のための新たな道を提供します。しかし、Claude にデータウェアハウスを指し示してエージェントに実行させるだけでは、誤った精度への安心感を生み出すだけです。
アドホックな要求からの解放による最初の喜びは、この設定がステークホルダーを、以前は慎重にキュレーションされたデータセットへと導いてきた基盤インフラストラクチャ、ドキュメント、専門知識から切り離しているという realization に直面した瞬間に、恐怖へと変わります。
Anthropic では、ビジネス分析クエリの 95% が Claude を通じて自動化されており、集計すると約 95% の精度を達成しています。このよくある反復的な作業を Claude に任せることで、データサイエンスチームは因果モデリング、予測、機械学習(Machine Learning)といったより戦略的な業務に集中できるようになります。
Anthropic のトップクラスな Claude Code ユーザー数十名との面談や、分析エージェントにおける無数の設計パターンを目撃した結果、LLM(大規模言語モデル)を活用する他のデータチーム向けにベストプラクティスを確立しました。本稿では、Claude がセルフサービス型のビジネスインサイトを実現する能力を最大化するためのヒントとアプローチについて共有します。具体的には以下の内容を含みます:
- 分析の精度はコード生成の問題ではなく、文脈(コンテキスト)と検証の問題である理由;
- 誤りの大部分を引き起こす 3 つの失敗モード;
- これらのエラーに対処するために構築したエージェント型分析スタック;
- 効果性の測定方法;
- 当社のスキルの大半を作成する際の基本的なテンプレート(付録を参照)
データはソフトウェアではない
LLM の生成能力は両刃の剣です。複雑な問題に対する創造的な解決策を可能にするメカニズムが、同時に誤った出力を創り出すハルシネーション(幻覚)の原因にもなり得ます。分析エージェントにおける課題を完全に理解するためには、それらをコーディングエージェントと比較することが有用です。
コーディングはモデルの創造性を評価するオープンエンドな解決空間ですが、ドキュメントとテストはハルシネーションに対する自然なガードレールを提供します。一方、分析ユースケースでは、単一の正しいソースを用いた単一の正解が存在することが多く、その正しさを証明する決定論的な方法がありません。

セルフサービス・エージェント型ビジネス分析における複雑さは、主にデータの曖昧さにあります。中核的な問題は、ユーザーの質問をデータモデル内の具体的かつ最新のエントティにマッピングし、それらと正しく連携する方法を知るという我々の能力にかかっています。これができれば、生成される実行コードや SQL は単純なものになります。
我々は、不正確な回答の绝大多数を説明するこの問題の 3 つの特徴を特定しました:
- コンセプトとエンティティの曖昧さ:データモデルには数百もの有効な選択肢(潜在的に数百万のフィールドの中から)が存在するため、エージェントはユーザーの質問に最も適切に答える正しいフィールドを選択できません。例えば、アクティブユーザー数を測定する場合、「アクティブ」とみなす行動とは何か?不正なユーザーを含めるべきか?どの期間を遡って見るのか?
- データの鮮度低下:データソース、ビジネス定義、スキーマは絶えず変化しており、アセットやエージェントの知識が古くなり、微妙に間違った回答を返すようになります。
- 検索失敗:正しい情報がデータモデル内にあり適切に注釈付けられていたとしても、検索空間の広大さゆえに、エージェントが見つけないことがあります。
該当する項目は見つかりませんでした。
0/5
Claude Code を入手
電子書籍

imageimage
私たちのエージェント型分析スタック
Anthropic では、これら 3 つのエラーを最小限に抑える主な手段として、エージェント型データスタックを活用しています。各レイヤーは主にこれらの問題の 1 つ以上に対処するために存在します:
- エンティティの曖昧性:データ基盤と真実の源は、妥当なエンティティの範囲を狭め、単一の統制された回答に至らせます。
- 鮮度の低下:ビジネスの変化に伴い、メンテナンスおよび検証プロセスがすべての要素が腐敗するのを防ぎます。
- 検索失敗:スキルにより、エージェントがその回答を確実に見つけ、正しく使用できることを保証します。
このセクションでは、各レイヤーをどのように構築したかについて議論します。

データ基盤
分析エージェントの精度を確保する上で最も重要な側面は、データモデル、変換、テスト、データウェアハウス内のテーブル、およびそれらを記述するメタデータを備えた強力なデータ基盤です。ディメンショナルモデリング、シフトレフトテスト、重要パイプラインにおける鮮度と完全性のチェックなど、標準的なデータエンジニアリングおよびデータ品質のプラクティスはすべて依然として適用されます(これらについて再論じるつもりはありません)。
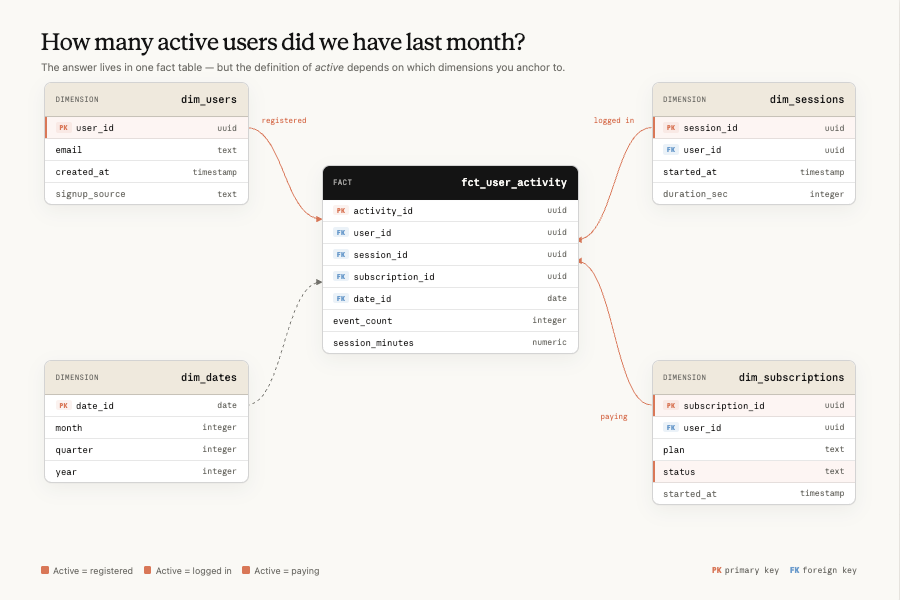
次元モデリングなどの標準的なデータエンジニアリングプラクティスは、これまで通り極めて重要です。変化するのは、データモデルの最終ユーザーがデータ専門家(例えばデータサイエンティスト)ではなくなり、異なるレベルのデータ専門知識や基盤インフラへの理解を持つユーザーに代わって行動するエージェントになる点です。このシフトは課題をもたらします。なぜなら、最終ユーザーが基礎的な正しさを検証する方法を知らないため、結果に対してその正しさを検証することをユーザーに要求できないからです。
データ基盤層は主に曖昧性の解消を目指しています。例えば、「収益」が四十の妥当な候補の一つではなく、管理された単一のデータセットに解決される場合、エージェントが検索を行う前に問題はほぼ消滅します。また、これが最初の鮮度低下対策の場所でもあります。なぜなら、標準的なモデルを定義する同じリポジトリこそが、それらが最新の状態を保つように強制するための自然な場所だからです。
いくつかのプラクティスが特に効果的であることが確認されています:
- 標準的なデータセットの作成:最も一般的な失敗は、エージェントが概念(「製品 X の収益」など)を単一の正しいテーブル、列、および指標定義にマッピングできないことです。通常、これは微妙に異なる実装を持つ複数の妥当な候補が存在するためです。解決策は、より少数で厳格に管理された論理モデルを採用することです。明確に所有され、利用準備が整っており、発見可能な標準的な単一真実源データセットの小さなセットを厳選し、ほぼ重複するものを積極的に非推奨とします。物理的な集計やキャッシュもコストとパフォーマンスのために依然として重要ですが、それらは代替案として並存するのではなく、標準モデルから機械的に派生させるべきです。目標は、エージェントが概念を検索した際に、単一の管理された回答に到達することです。
- 基準の厳守:標準モデルと指標定義がツール(エージェントが構造的にまずこれらへルーティングされる;以下で詳述)、CI(これを迂回する変更はレビューで失敗する)、および命令(下流チームは管理されたレイヤー上で構築するか、そうでない理由を説明する)によって強制されなければ、基盤は維持できないことを私たちは発見しました。強制を伴わないガバナンスは、すぐに複数の候補の問題へと後退してしまいます。
- アーティファクトの集約:常に変化するデータモデルやビジネスロジックに対する私たちの主な防御策は、アーティファクトの集約です。ほぼすべてのデータコード(つまりモデリング、セマンティックレイヤー、参照ドキュメント、標準的なダッシュボード定義)は単一のリポジトリに存在し、層間整合性を保護する CI チェックが設けられています。モデリングの変更が下流のダッシュボードを破損させたり、文書化された指標を無効にしたりする場合、CI がそれを検知し、修正は同じ PR で提供されます(このメカニズムについては以下のスキルセクションで再考します)。
- メタデータを第一級製品として扱う:コーディングエージェントが良好なパフォーマンスを発揮するのは、コードベースが可読性を持っている部分があるためです。README、型シグネチャ、ドキュストリングなどです。あなたのデータウェアハウスも同様に可読性にできるのですが、列やテーブルの説明、標準的な指標定義、粒度の文書化、有効値範囲、系譜、所有権、モデル階層化が変換自体と同じ厳格さで維持される場合に限りです。これは新しい洞察ではありませんが、優れたガバナンスは、エージェントが適切なデータセットを選択するのを助ける重要なコンテキストを提供します。
真実の源泉
データ基盤がデータウェアハウスそのものであるならば、真実の源泉(sources of truth)とは、エージェントがそれをナビゲートする際に参照する基準面です。この層は概念とエンティティの曖昧さを解消し、ステークホルダーからの質問にある「週次アクティブユーザー」という表現を、データモデル内の特定の、管理されたエンティティへと変換します。信頼性の高い順に大まかに並べると以下のようになります:
- セマンティックレイヤー:コンパイルされたメトリクスと次元の定義。質問が明確に定義されたメトリクスに対応する場合、エージェントは関数を呼び出して 1 つの数値を取得します。これは社内他のすべての表面で生成される数値と同じものです。当社のエージェントはスキル指示により構造的にまずセマンティックレイヤーを活用することが義務付けられています(付録参照)。試みたが失敗したアイデアとして、LLM に生テーブルとクエリログからメトリクス定義を自動生成させることでセマンティックレイヤーをブートストラップするというものがありました。これは一見妥当に見える定義を生み出しましたが、排除しようとした曖昧さそのものをエンコードしており、評価ではより小さく人間がキュレーションしたレイヤーと比較してネガティブな結果となりました。したがって、ドキュメント生成には Claude を活用しつつ、定義の所有権は人間に持たせることを推奨します。
- 系譜と変換グラフ:セマンティックレイヤーでカバーできない質問の場合、系譜とテーブルランキング(参照数に基づく)により、エージェントがどのアップストリームモデルが概念を供給しているか、どのモデルが非推奨となっているか、どのモデルが同じ粒度を共有しているかを推論できるようになります。これにより「メトリクスがわからない」という状態から、「どの統制されたモデルから集計すべきか知っている」状態へと変換されます。また、これは以下で示すオンライン検証において提示する鮮度と出所のシグナルのバックボーンでもあります。
- クエリコーパス:ダッシュボード、ノートブック、過去の分析からの履歴 SQL。直感的には高価値であるはずです:すでに正しく回答されたすべての質問の記録だからです。しかし実際には、エージェントに数千件の過去クエリへの生レトリバルアクセスを与えるだけでは精度は 1 ポイント未満しか向上しないことがわかりました(このアブレーションについては後述のセクションで詳しく説明します)。非構造化レトリバルでは、新しい質問を適切な先例にマッピングできませんでした。実際に機能するのは、そのコーパスをドメイン別の構造化参照ドキュメントと、スキルで記述された再利用可能な分析パターンに要約することです。クエリ履歴はエージェントが直接読む真実の源ではなく、キュレーションのための生素材として扱うべきです。
- ビジネスコンテキスト:多くのチームが省略する層であり、私たちが最も長く過小評価していた部分です。ビジネスを理解していないエージェントは、ユーザーが何を尋ねたかには答えますが、何を意図しているかは答えません。「第 2 四半期のローンチ」が特定の製品を指すこと、2 つのチームが同じ用語を異なる定義で使っていること、あるいは木曜日に取締役会が開催されているため質問がなされていることを知りません。エージェントが周囲の参照を解決し、より良い確認質問を行うために、インデックス化されたドキュメント、ロードマップ、意思決定ログ、組織構造からなる企業知識グラフを取り込んでいます。
これら 4 つすべてに共通する失敗パターンは、データ基盤層からのものと同じです:不十分または陳腐化したドキュメンテーション。Claude はギャップを埋めるために非常に有用ですが(列の説明のドラフト作成、クエリパターンからのメトリクスドキュメントの提案、CI 内の未文書化モデルのフラグ付けなど)、キュレーションと所有権は人間が管理します。
次の 2 つのセクションでは、所有権を十分に低コスト化して実際に実現できるようにする方法について議論します。
スキル
真実の源泉がエージェントの「宣言的」知識(つまり、指標の意味)である場合、スキルは「手続的」知識です。すなわち、どのソースをどのような順序で参照するか、曖昧なデータをどのようにナビゲートするか、そして完成した分析がどのようなものかを示します。
Claude Code において スキル は、エージェントが必要に応じて読み取るマークダウンファイルのフォルダです。Anthropic で開発されたスキルは、極めて大きな付加価値をもたらします。スキルがない場合、Claude の分析質問に対する回答精度は、私たちの評価では 21% を超えることはありませんでした。スキルを追加することで、集計値では一貫して 95% 以上となり、特定のドメインでは定期的に約 99% に達します。スキルの大半を作成するために使用する骨格については付録を参照してください。
いくつかのベストプラクティス:
ペアスキルを作成する: *知識* スキルは、薄いトップレベルのルーティング機能として機能し、必要な場合に追加のドメイン詳細をオンデマンドで読み込みます。具体的には、「まずセマンティックレイヤーを試すが、カバレッジがない場合は、このドメインに関連するテーブル、列、結合、および注意点を説明する約 30 の参照ファイルがある」と伝えます。このルーティング機能は、実質的に「検索失敗」に対する私たちの回答です。エージェントが百万フィールドのデータウェアハウスを検索させるのではなく、クエリが記述される前に、空間を数十件の厳選されたファイルに絞り込みます。*アンブック* スキルは、シニアアナリストが従うべきプロセスをエンコードしています:質問を明確にし、ソースを見つける(知識スキル経由)、クエリを実行し、結果を敵対的レビュー用サブエージェントに通してループさせることです。また、リテンションカーブ、レート分解、ファネル分析など、12 の再利用可能な分析パターンをバンドルしており、一般的な要求が毎回再発明されることを防ぎます。
適切な参照ドキュメントを作成する: LLM による検索のために記述されたものです。私たちの参照ドキュメントは、テーブル(粒度、スコープ、除外項目)、注意点のメカニズム(例:「既知のフリーメールドメインを除外するが、anthropic.com などのカスタムドメインは保持する」)、および具体的なルーティングトリガー(例:「質問が実験リフトに関する場合… 生のイベントカウントには使用しないこと」)を記述しています。これらは古くなるような指示付きレシピではなく、以下に参照ドキュメント作成に使用するスケルトンを示します。
[ドメイン] テーブル
クイックリファレンス
ビジネスコンテキスト — [このドメインが平語で何を意味するか]
エンティティ粒度 — [1 行が何を表すか]
標準衛生フィルター — [このドメインのすべてのクエリに適用されるフィルター]
次元
- [主要な次元がどのように符号化され、同じ概念がテーブル間でどのように異なる名称で呼ばれているか]
主要テーブル
[table_name]
- 粒度: [...] · 範囲/除外事項: [...]
- 使用法: [いつ使用するべきか、いつ使用すべきでないか、結合キー、必須フィルター]
[... 管理対象の各テーブルにつき短いセクションを1 つ ...]
注意点
- [シニアアナリストが警告する誤った回答モード]
ベストプラクティス / 一般的なクエリパターン
- [デフォルトの選択、標準的な切り口、正確なクエリ形式が難しい部分となる実例パターン]
Cross-References
- [隣接するドキュメントを持つ近傍ドメイン]スキルメンテナンスを第一級市民として扱う: スキルドキュメントは毎日変化するデータモデルを記述しているため、積極的なメンテナンスを行わないと数週間で誤った情報となります。私たちは、ローンチ時のオフライン精度が約 95% から、これをエンジニアリング課題として扱うまでの 1 ヶ月で約 65% に低下するドリフト(精度の低下)を目撃しました。これはつまり、スキル用の Markdown ファイルを変換モデルと同じリポジトリに配置し、モデルを変更するプルリクエスト (PR) が、そのモデルを記述するドキュメントを更新する PR と同じものになるようにすることを意味します。コードレビューフックは、スキルファイルに触れないレポート用モデルの変更をフラグとして検出します。現在、データモデル関連の PR の約 90% に、同じ差分内でスキルの更新が含まれています。また、モデルが改善し以前の失敗モードがもはや適用されなくなった際にも、定期的にスキルの骨格を整理しています。
すべての表面で一貫性がありシームレスな体験を提供する: 同じスキルは、Slack 内、IDE 内、ダッシュボードツール内、スタンドアロンのエージェントセッション内のいずれの質問に対しても、同じ回答を提供*しなければなりません*。これを実現するために、単一の正真正銘の情報源(データリポジトリ)を確保し、スキルの更新を自動的に同期するようにしました。マージ時には、スキルはプラグインマーケットプレイス(IDE ユーザー向け)、クラウドストレージのブロブ(単一ファイルを読み取るホスト型アプリ向け)、および MCP を介して直接リソースとして提供されるように同期されます。また、ハードコードされたリポジトリパスや表面固有の名前空間を避けることで、最初から移植性を考慮した設計としています。
検証
最後に、検証とは、3 つの失敗モードのうちどれがまだ漏れ出しているかを特定する方法です。
オフライン評価
私たちがよく目にする共通のパターンとして、データチームが分析エージェントの精度を理解するためのプロセスを持たずに、複雑な分析環境を構築してしまうということがあります。
このギャップを埋める一つの方法は、オフライン評価(offline evals)を通じて行うことです。これは単純な質問と回答のペアです。オフライン評価は、機械学習モデルのオフラインテストと同様に考えることができます。つまり、オンラインエージェントのパフォーマンスを直接示すものではありませんが、重要なギャップが生じる可能性について良い感覚を得ることができます。
Anthropic では 2 種類のオフライン評価を展開しています。ダッシュボードベースの評価(Dashboard-based evals)は、Claude によって自動生成され(その後人間による検証が行われます)、最も一般的なステークホルダーの質問をカバーします。ロングテール評価(Long tail evals)では、Claude にビジネスコンテキスト(ロードマップやテーブルドキュメントなど)を提供し、残りの領域全体にわたって妥当な質問を生成させます。また、スレッド上でステークホルダーがエージェントの回答を修正した際も、その修正内容を評価候補として継続的に収集しています。
その他のベストプラクティスには以下が含まれます:
- 正解の基準を固定してドリフトを防ぐ:生データに対して作成された評価は、基盤となる数値が変化した瞬間に陳腐化します。各評価を特定のスナップショット日付に固定するか、安定した事実テーブルに対して記述するか、またはエージェントの数値そのものではなく、エージェントのクエリを採点者に判断させるようにしてください。評価スイートを CI に連携させ、依存関係に触れる PR が発生した際に影響を受ける評価を再実行するようにします。
- 結果はテストログのようにではなく、テレメトリデータとして保存する:各実行結果は、スキルバージョン、Git SHA、モデル ID、各アサーションのパス/フェイル、トークン数、経過時間を含むウェアハウステーブルに記録されます。「その変更は役立ったか?」という問いはクエリとなり、単一の CI 実行では検出できない緩やかな回帰を捉えるための時系列データが得られます。
- ドメインごとにリリースゲートを設ける:ドメインの責任者は、評価セットの一部がある閾値(当初は約 90%)を満たすまで、ステークホルダーに対してエージェントの発表を行うことができません。これにより、ユーザーに失敗が見られる前に参照ドキュメントの修正が強制されます。
- 適切な数の評価を作成する:必要な評価数は、ビジネス領域の複雑さと基盤となるデータモデルの複雑さに依存します。オフライン精度がオンライン精度をどの程度予測できるかを追跡することで較正を行います。私たちが発見したところでは、トピックあたり数十件を超えると増加分の効果が減少し(例:「成長」)、この上限は新しいモデル世代ごとに低下します。
- オフライン評価の精度は約 100% であるべきです;すべての正解回答は、セマンティックレイヤー(存在する場合)にもヒットしている必要があります。再度強調しますが、このレベルの精度はシステムが誤った回答を生成しないことを保証するものではなく、適切な評価カバレッジがあるという前提の下で、明白な欠落がないことを示すに過ぎません。
Ablation techniques
スキルに関するすべての構造的決定(例えば、どのソースを公開するか、サブエージェントが待ち時間を獲得するかどうか、2 つのスキルを 1 つに統合するかどうか)は、オフライン評価セットを固定した状態で行われます。
我々は正確に 1 つのコンポーネントのみを変化させ、パス率を比較します。各実行には 1 時間しかかからず、多くの議論を不要にします。この方法論は、単一の結果よりも重要です:
- null 結果を想定して設計する。最も有用だったアブレーション実験は、否定的な結果をもたらしたものであった。エージェントにダッシュボード、変換ロジック、アナリストノートブックの SQL(数千ファイル)への直接 grep アクセス権限を与えたが、回答ごとにトランスクリプトで実際にそれらを読み込んだことを確認した。精度はどちらの方向にも 1 ポイント未満しか変動しなかった。次に明白な交絡因子を確認した:間違えた質問に対して、答えが実際にはコーパスに含まれていたか?約 80% の場合、含まれていた。「答えが存在する」ことが「正解できるようになる」ことを予測するか?いいえ、改善率は横ばいであった。情報は存在し、エージェントもそれを見たにもかかわらず、結局利用しなかった。この単一の実験から、ボトルネックは過去の成果へのアクセスではなく、構造化(つまり、質問を適切なエンティティにマッピングすること)にあることが明らかになった。この洞察が、数ヶ月にわたるロードマップの方向性を転換させた。
- PR 粒度でアブレーションを行う。意味のあるスキル修正のすべてについて、関連する評価スライスに対して「Before/After」の実行を行い、その差分を PR 記述に記載する。これにより、「ドキュメントを改善した」という主張が客観的に保たれ、意図は良いのに結果が悪化するという、意外にも頻繁に起こるケースを検出できる。
- 失敗した手法の短いリストを維持する。私たちの例として2つ挙げよう:ある時点を超えてドキュメントの精緻化ラウンドを重ねること(3 回連続でネットマイナスの結果となり、ドキュメントは長くなるばかりで良くならなかった)、およびレイテンシ削減のために敵対的レビューアーを安価なモデルに置き換えること(精度向上のほとんどが失われ、実質的な速度向上も得られなかった)。否定的な結果は記録するコストが安く、次の人が同じ実験を繰り返すのを防ぐことができる。
オンライン検証
最終ステップは、実際のオンラインシステムの性能を可能な限り正確に保証することです。私たちが実施する手順の一部には以下が含まれます:
- 敵対的レビュー:Claude スキルを用いて最終回答のすべての前提を積極的に挑戦させることで、評価セット内で精度が 6% 向上することが判明しましたが、その代償としてトークン使用量が 32% 増加し、レイテンシが 72% 高くなりました。
- 出所フッター:すべての応答には、それがどのソース階層(セマンティックレイヤー › curated reference › raw table)から来たか、基盤データの鮮度、およびモデルの所有者を示すフッターが付随します。これにより回答がより正確になるわけではありませんが、消費者が応答をどの程度信頼できるかを判断する助けになります。「raw table, freshness unknown」というフッターは、上位フローへ転送する前に検証すべきというシグナルであり、サイレントフォールトに対する数少ない緩和策の一つです。
- データ品質チェック:エージェントが適切なフィールドを正しい方法で使用していても、データ自体が誤っている可能性があります。参照されるフィールドが最新で、完全性があり、異常がないことを保証するための基本的なデータ品質チェックを追加することは、一般的な衛生管理として推奨されます。
- 受動的モニタリング:継続的に追跡している本番環境のシグナルは、セマンティックレイヤーを介して解決されたエージェントクエリの割合と、「そのテーブルが間違っています」「不正検出フィルターが抜けています」といった修正言語を使用した応答の割合です。これらは両方とも、オフラインパス率と共に週次でレビューされるダッシュボードにフィードされます。
- 能動的修正収集:これはループを閉じる部分です。スケジュールされたエージェントは数時間ごとにステークホルダーチャネルをスキャンし、類似の修正言語を検出し、関連する参照ドキュメントへの一行分の修正案を作成して、ドメイン所有者にタグ付けした PR を開きます。修正経路は意図的に退屈なものです(マークダウンファイルの編集、マージ、全場所への自動同期)ので、ドメイン所有者がタスクに時間をかけすぎないようにしています。同じ修正内容はオフライン評価セットにもフィードバックされます。
- これらの対策で完全に捕捉できない失敗モードはサイレントなものです。回答は誤りですが、妥当に見え、異議なく使用されてしまいます。私たちの緩和策は、出所フッターの提示、リーダーシップ関連事項に対する明示的な人間の承認、および各ドメインの主要 KPI に対する定例評価(毎日祝福されたダッシュボードと照合して健全性をチェック)ですが、まだ堅牢な解決策はありません。
はじめに
ゼロから始める場合、いくつかの代表的なデータセットと数十件のオフライン評価、そして限定的な知識スキルがあれば、多くのメリットを享受できます。本記事でそれ以降に追加した内容は、これらが構築された後に実施したものです。
また、多くのベストプラクティスをご紹介しましたが、すべてのデータチームに適しているわけではありません。組織内でアプローチに影響を与えるいくつかの原則について合意形成を図るために、以下の問いを検討してください:
- 今日と未来において、正しい回答であることはどれほど重要でしょうか?AI モデルは急速に進化しています。現在では、モデルの不足を補うために多くのインフラを整備する企業をよく見かけますが、モデルが改善されればこれらの措置は無意味になります。モデルがどこで不足しているかを知り、モデルの改善を待ってギャップを埋める方がオーバーヘッドは大幅に減りますが、これは貴社のリスク許容度に合致しない可能性があります。
- 貴社のビジネスの複雑性は時間とともにどのように変化すると予想されますか?例えば、生成するデータが少ない場合、出力の利用者が数人だけの場合、あるいはデータモデルが今後とも単純なままである可能性が高い場合は、前述の一部のプロセスはやりすぎになるかもしれません。
- 出力の対象となる読者の技術レベルはどの程度でしょうか。言い換えれば、誤った回答を認識できるデータサイエンティスト向けにこの分析システムを構築する場合は、基盤となるデータモデルに詳しくない対象者向けの場合と比較して、エラーに対してより寛容になれます。
- 精度向上のためにどれだけの予算を投じるつもりですか?敵対的検証(adversarial validation)のような特定のプロセスは精度を大幅に向上させることがありますが、多くの場合、コストとレイテンシが高くなります。
- アクセス制御や社内データのプライバシーについて、どの程度の許容度をお持ちでしょうか。エージェントは利用可能なコンテキストが多ければ多いほどパフォーマンスが著しく向上しますが、広範なデータへのアクセス権限は、ほとんどの企業のガバナンス方針に反します。これが、単一のエージェントを構築するか、複数のスコープ限定型エージェントを構築するかを決定づけます。
どのような道を選ばれようとも、私たちが得た最大の成果は、3 つの失敗モードそれぞれに対処した結果です。すなわち、曖昧さを単一の管理された回答に集約すること、回答を容易に見つけられるようにすること、そしていずれかが陳腐化した際に警告を発することです。
*この記事は、データサイエンスおよびデータエンジニアリングチームのメンバーであるChen Chang、Clement Peng、Justin Leder、Johanne Jiao、Josh Cherryによって執筆されました。著者らは、Michael Segner氏の貢献に感謝いたします。
付録
スキルファイルの骨格
以下は、主要なウェアハウススキルの骨格です:実際のファイル構造であり、内部の詳細情報は[角括弧で囲まれたプレースホルダー]に置き換えられています。これはそのままコピーして使用するものではなく、記述する価値のあるセクションの種類を示すためのものです。
name: [warehouse-skill]
version: [x.y.z]
description: "ユーザーが[会社名]のデータウェアハウスに対して[ビジネスドメインの一覧]に関する質問を問い合わせた場合 — このスキルを呼び出してください。[隣接するエンジニアリングタスク]や、データウェアハウスの要素を含まない質問については呼び出さないでください。"
[ウェアハウス] スキル指示
説明
安全かつ効果的な[ウェアハウス]クエリのための唯一の信頼できる情報源です。
他のスキル(リストあり)によって、クエリ実行のガイダンスとして参照されます。
データアナリストとして行動し、戦略的洞察とデータ駆動型の推奨事項を提供しますが、その過程でガイダンスを求めてください。
対象外となる意思決定: [製品領域など] → データのみを提示し、「決定は[担当チーム]の判断です」と明記し、立場を示したりコード修正を行ったりしてはいけません。
クエリの実行
優先順位:
- [管理された接続] (利用可能な場合): [クエリツール] / [スキーマツール]
- [CLI フォールバック] (インストールされている場合): [デフォルトプロジェクト、フォールバックプロジェクト]
- どちらも該当しない — ユーザーに認証を求め、その後停止
セマンティックレイヤー(必須の最初のステップ)
ガバナンスされたセマンティックレイヤーは、すべてのデータ問い合わせに対する必須のデフォルトパスです。[BI ツール] と同じ数値が扱われ、結合/粒度/フィルタリングが組み込まれています。以下の参照ドキュメントを介した生 SQL はフォールバックであり、セマンティックレイヤー経由のパスで要求を満たすことができない場合にのみ使用されます。
必須ワークフロー
- ロード — [各ランタイムでのセマンティックレイヤーの読み込み方法とフォールバック手順]
- 発見 — キーワードでメジャーやディメンションを検索する。必ずセグメントを確認すること(これは名前付きの正規化された人口フィルタであり、これらに対する手動の WHERE 句が誤った回答の主要な原因となる)
- コンパイル + 実行 — 仕様の構築 → SQL へのコンパイル → 実行
- フォールバック — 発見で関連するメトリクスが見つからない場合、またはコンパイルに失敗した場合のみ →
references/*.md(以下の PART 3)を介した生 SQL の使用
早期の放棄は禁じ。 これらの理由で生 SQL にフォールバックしてはいけません:
- "[カスタム日付フィルタリング / コホート分析]" → [時間次元仕様によってカバー済み]
- "[結合が必要]" → [メトリックレイヤーは既にその結合をカプセル化している]
- [セマンティックレイヤーをスキップするためにエージェントが使用する他の 3〜4 の反駁済みの言い訳]
⟦CODE_0⟧
⟦CODE_1⟧
データウィンドウとタイムゾーン — クエリ実行前に決定する
- 時点日付 vs 直近 N 日間: [各項目ごとの規約]
- 「先週/先月」: 直近の 7 日分や 30 日分ではなく、直前の完全な暦上の一週間または一ヶ月を指す
- タイムゾーンデフォルト: [TZ]; [特定の集計レポートについては例外あり]
- 鮮度ラグ: [一部の] テーブルは更新が遅れる傾向があるため、「昨日」ではなく MAX(date) に基づいてアンカーする
パート 1: 必須知識(すべてのリクエストで最初に読む)
🚀 クイックスタートワークフロー
- まずレッドフラグを確認: [制限対象/個人識別情報 (PII) リクエスト、ゲートドメイン、追加検証が必要な高リスクの問い合わせ]
- 範囲外はエスカレートし、推測しない: [アクセス権限リクエスト、パイプラインのトラブルシューティング、古くなったダッシュボード、根本原因の断定、製品/価格に関する推奨] → 担当チームへリダイレクトし、回答しない
- リクエストを明確化: 期間、セグメント、それがどのビジネス判断に資するか
- 既存ダッシュボードの確認: [ドメイン別ダッシュボードカタログ]
- データソースの特定: [以下のナビゲーションマップを参照; 管理された/集約テーブルを優先]
- 分析の実行: [必須フィルター + 敵対的レビュー]
- インサイトの提供: 手法を示し、観察結果と解釈を明確に区別する
🏢 ビジネスコンテキスト
エンティティの曖昧性解消(必ず明確化すること)
- 「[用語 A]」は以下を指す可能性がある: [エンティティ 1] または [エンティティ 2] — どちらを指すか常に確認する
- 「[用語 B]」は以下を指す可能性がある: [エンティティ 1] → [エンティティ 2] → [エンティティ 3](一つから多数への連鎖)
- 「ユーザー」: [正確なカウントに使用できる識別子はどれか、またどの識別子が数を水増ししているか]
ビジネス用語
- [現在の製品名と、データ層に凍結値としてまだ残っている非推奨の別称 — 記述は新名称で行い、フィルタリングには旧名称を使用]
- [主要な内部略語]
- [主要指標] の計算: [月次 / デフォルト期間 / リーディングインディケーター]
- 見慣れない用語 — [社内ドキュメント] で検索し、推測してはいけない
データ整合性要件 ⚠️
- 決して行わないこと: データや列を捏造する; データが示す範囲を超えた推測的な主張を行う
- 必ず行うこと: 安全な除算を使用する; 観察結果(「データは X を示している」)と解釈(「これは Y を示唆している」)を区別する; 制限事項を明記する
パート 2: 実行時の手順(実行中に従うこと)
🔧 技術的実装ガイド
- [管理接続ツールと CLI 呼び出しの詳細]
- PII の保護: 制限対象データについては、ユーザー自身に実行させるための SQL を返す — 結果を直接返してはならない
📊 分析ベストプラクティスガイド
- クエリを実行する前に問いを明確にする
- 作業過程を示す(フィルタ、含める/除外する項目、データの鮮度など)
- 分母を明確化する
- サンプルバイアスを考慮する
- ビジネスへの影響と結びつける
- 敵対的 SQL レビュー(必須) — 最終回答の前に、[sql-reviewer] サブエージェントを起動してすべてのクエリに対してレビューを行うこと。発見された問題点は修正し再レビューを受けること;自己認定は禁止する
- 出典付きで報告する — すべての回答の末尾には以下のフッターを追加すること:
ソース: [セマンティックレイヤー | 管理対象テーブル | ラウド探索] ·
信頼度: [ティア] · レビュー済み: [レビュアー ✓, ラウンド N] ·
鮮度: [データ内の最大日付] · オーナー: [所管チーム]
パート 3: データ参照・リソース
📚 ナレッジベースのナビゲーション
[ドメイン A] → references/[domain_a].md
- 用途: [質問の種類]
- 主要テーブル: [...]
- ダッシュボード:
references/[domain_a]_dashboards.json
[ドメイン B] → references/[domain_b].md
- 用途: [...]
[... 各ビジネスドメインごとに 1 エントリ — 合計数十件 ...]
⚠️ トラブルシューティングガイド
情報が不足している場合
- [欠落しているテーブル / アクセス拒否 / 古くなったドキュメント / 不明な列挙値 → 対応方法]
フィールド名に関する落とし穴
[field_x_v2]を使用し、[field_x]は使用しないこと- [同様に名付けられた 2 つのテーブルが異なる粒度で同じ指標を報告している場合 — どちらを使用すべきか]
- [2 つの妥当なソースのうち、主要指標の標準的なものはどれか]
- [... 苦労して得た数十のワンライナー ...]
見つかった項目はありません。
クロードで組織の運用方法を変革する
開発者向けニュースレターを購読する
製品アップデート、ハウツー記事、コミュニティ紹介など。毎月あなたのメールボックスにお届けします。
月次の開発者向けニュースレターを受け取りたい場合は、メールアドレスをご入力ください。いつでも登録解除が可能です。
ありがとうございます!登録が完了しました。
申し訳ありませんが、送信に問題が発生しました。後ほど再度お試しください。
原文を表示
- Category
- ProductClaude Code
- DateJune 3, 2026
- Reading time5min
- ShareCopy linkhttps://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
As many data science and data engineering teams can attest, enabling self-service business analytics has traditionally been a slog.
Making the data model more accessible to less technical coworkers via wide and denormalized tables often leads to overlapping views with inconsistent definitions as the business scales (and does little to bridge the gap for employees with little desire to learn SQL). Alternatively, creating more ringfenced environments for users often misses the long tail of business questions and leads to metric and dashboard bloat as teams silo their work.
The rise of LLMs provides an additional path for self-service analytics that avoids those challenges. However, pointing Claude at a warehouse and letting the agents execute can create a false sense of precision.
The initial elation of liberation from ad-hoc requests turns into dread with the realization that this setup separates stakeholders from the underlying infrastructure, documentation, and expertise that previously steered them toward carefully curated datasets.
At Anthropic, 95% of business analytics queries are automated via Claude, with ~95% accuracy in aggregate. By giving this often rote, repetitive work to Claude, our data science team can focus on more strategic work like causal modeling, forecasting, and machine learning.
After meeting with dozens of Anthropic’s top Claude Code users and having seen myriad design patterns for analytics agents, we’ve cultivated some best practices for other data teams working with LLMs. In this post, we’ll share these tips and approaches to maximizing Claude’s ability to drive self-serve business insights, including:
- Why analytics accuracy is a context and verification problem, not a code generation issue;
- The three failure modes that cause most errors;
- The agentic analytics stack we built to address these errors;
- How we measure effectiveness; and
- A basic template for how we create the majority of our skills (see the appendix)
Data is not software
LLMs' generative abilities are a double-edged sword: the mechanisms that enable creative solutions to complex problems can also hallucinate erroneous output. To fully understand the challenges with analytics agents, it’s useful to compare them to coding agents.
Coding is an open-ended solution space that rewards the models' creativity, while documentation and tests provide natural guardrails against hallucination. In contrast, for analytics use cases, there’s often only a single correct answer using a single correct source in which there’s no deterministic way of proving the correctness.
For self-service agentic business analytics, the complexity mainly lies in the ambiguity of the data. The central problem comes down to our* ability to map a user’s question to specific and up-to-date entities in our data model and know the correct way of working with them*. If we can do that, then the resulting execution and SQL becomes trivial.
We’ve identified three attributes of this problem that account for an overwhelming majority of inaccurate responses:
- Concept <> entity ambiguity: with hundreds of viable options in a data model (out of potentially millions of fields), the agent is unable to choose the correct fields that best answer a user’s question. For example, in measuring the number of active users: what actions constitute being “active”? Do you include fraudulent users? What lookback window do you use?
- Data staleness: data sources, business definitions, and schemas change constantly; assets and agent knowledge go stale and start returning subtly wrong answers.
- Retrieval failure: the right information may actually be in the data model and properly annotated, but given the vastness of the search space, the agent simply doesn’t find it.
No items found.
0/5
Get Claude Code
eBook
Our agentic analytics stack
At Anthropic, the main way we minimize these three errors is via our agentic data stack. Each layer exists primarily to attack one or more of these problems:
- Entity ambiguity: data foundations and sources of truth shrink the space of plausible entities until there's a single governed answer.
- Staleness: maintenance and validation processes keep everything from rotting as the business changes.
- Retrieval failure: skills make sure the agent reliably finds and correctly uses that answer.
In this section, we’ll discuss how we built each layer.
Data foundations
The most important aspect of ensuring analytics agents are accurate is via strong data foundations, which include the data models, transforms, tests, and tables in a data warehouse, along with the metadata describing them. Standard data engineering and data quality practices such as dimensional modeling, shift-left testing, freshness and completeness checks on critical pipelines all still apply (and we won't relitigate these).
What does change is that the end user of your data model is no longer a data expert (e.g. data scientist), but rather agents acting on behalf of users with varying degrees of data expertise or understanding of the underlying infrastructure. This shift presents a challenge in that the results can’t require the user to validate the underlying correctness simply because the end user doesn’t know.
The data foundations layer is aimed primarily at ambiguity: if *revenue*, for example, resolves to one governed dataset instead of forty plausible candidates, the problem largely disappears before the agent ever has to search. It's also where the first staleness defense lives, since the same repo that defines the canonical models is the natural place to enforce that they stay current.
We’ve seen a few practices work especially well:
- Create canonical datasets: By far the most common failure is that the agent can’t map a concept (“revenue for product X”) to the single correct table, column, and metric definition, usually because there are multiple plausible candidates with subtly different implementations. The fix is fewer, more heavily governed logical models: curate a small set of canonical, single source-of-truth datasets that are clearly owned, consumption-ready, and discoverable, then aggressively deprecate the near-duplicates. Physical rollups and caches still matter for cost and performance, but they should derive mechanically from the canonical models rather than living alongside them as alternatives. The goal is that when an agent searches for a concept, it finds a single governed answer.
- Enforce your standards: We’ve found the foundations only hold if the canonical models and metric definitions are enforced by tooling (the agent is structurally routed to them first; more on that below), by CI (changes that bypass them fail review), and by mandate (downstream teams build on the governed layer or explain why not). Governance without enforcement otherwise quickly decays back to the multiple candidates problem.
- Colocate artifacts: Our main defense against constantly changing data models and business logic is colocation. Nearly all data code (i.e., modeling, semantic layer, reference docs, canonical dashboard definitions) lives in a single repo, with CI checks that protect cross-layer integrity. If a modeling change would break a downstream dashboard or invalidate a documented metric, CI flags it and the fix ships in the same PR. (We’ll come back to the mechanics of this in the Skills section below.)
- Treat metadata as a first-class product: Coding agents perform well partly because codebases are legible: READMEs, type signatures, docstrings, etc. Your warehouse can be just as legible, but only if column and table descriptions, canonical metric definitions, grain documentation, valid value ranges, lineage, ownership, and model tiering are maintained with the same rigor as the transformations themselves. While not a new insight, good governance provides critical context that helps the agent choose the right dataset.
Sources of truth
If data foundations are the data warehouse itself, sources of truth are the reference surfaces the agent consults to navigate it. This layer reduces concept <> entity ambiguity and turns “weekly active users” in a stakeholder’s question into a specific, governed entity in your data model. Roughly in descending order of trust:
- Semantic layer: the compiled metric and dimension definitions. If a question maps cleanly to a defined metric, the agent calls a function and gets one number, the same number every other surface in the company produces. Our agents are structurally required (by skill instruction) to leverage the semantic layer first (see the appendix). One idea we tried that didn’t work: bootstrapping the semantic layer by having an LLM auto-generate metric definitions from raw tables and query logs. It produced plausible-looking definitions that encoded the very ambiguities we were trying to eliminate, and was net-negative on our evals versus a smaller, human-curated layer. Therefore we recommend generating the documentation with Claude, but having a human own the definition.
- Lineage and the transformation graph: when the semantic layer doesn’t cover a question, lineage and table ranking (based on number of references) let the agent reason about which upstream models feed a concept, which are deprecated, and which share grain. This transforms “I don’t know the metric” into “I know which governed model to aggregate from.” It’s also the backbone of the freshness and provenance signals we surface in online validation below.
- Query corpus: historical SQL from dashboards, notebooks, and prior analyses. Intuitively, this should be high-value: it’s a record of every question already answered correctly. In practice, we found that giving the agent raw retrieval access to thousands of prior queries moved accuracy by less than a point (we walk through that ablation in a later section below). Unstructured retrieval couldn’t map a new question to the right precedent. What does work is distilling that corpus into structured per-domain reference docs and reusable analysis patterns described in skills. Treat the query history as raw material for curation, not as a source of truth the agent reads directly.
- Business context: the layer most teams skip, and the one we underrated the longest. An agent that doesn’t understand your business will answer what the user asked, but not what they meant. It won’t know that “the Q2 launch” refers to a specific product, that two teams define the same term differently, or that a question is being asked because a board meeting is on Thursday. We pipe in a company knowledge graph consisting of indexed docs, roadmaps, decision logs, and our organizational structure so the agent can resolve ambient references and ask better clarifying questions.
The common failure pattern across all four is the same one from the data foundations layer: poor or stale documentation. Claude is exceptionally useful for closing the gap (drafting column descriptions, proposing metric docs from query patterns, flagging undocumented models in CI), but the curation and ownership are managed by humans.
In the next two sections, we discuss how to make that ownership cheap enough that it actually happens.
Skills
If the sources of truth are the agent's *declarative* knowledge (i.e., what a metric means) then a skill is its *procedural* knowledge: which sources to consult in what order, how to navigate ambiguous data, and what a finished analysis looks like.
In Claude Code, a skill is a folder of markdown the agent reads on demand. At Anthropic, the skills we developed are hugely value additive. Without skills, Claude’s ability to answer analytics questions accurately didn’t exceed 21% on our evals. Adding skills gets these numbers consistently above 95% in aggregate and regularly around 99% in certain domains. See the appendix for a skeleton we use to create a majority of our skills.
Some best practices:
Create pairwise skills: a *knowledge* skill acts as a thin top-level router that allows additional domain details to load on demand. It says "try the semantic layer first, but if there’s no coverage, here are ~30 reference files for this domain describing the relevant tables, columns, joins and gotchas.” This router is, in effect, our answer to retrieval failure: rather than letting the agent search a million-field warehouse, it narrows the space to a few dozen curated files before a query is ever written. The *unbook* skill encodes the process a senior analyst would follow: clarify the question, find sources (via the knowledge skill), run the query, and then loop the result through adversarial review sub-agents. It also bundles a dozen reusable analysis patterns (retention curves, rate decomposition, funnel analysis) so that common requests don't get reinvented each time.
Create proper reference docs: written for retrieval by an LLM. Our reference docs describe tables (grain, scope, and exclusions), the mechanics of gotchas (e.g., “exclude known free-email domains, but keep custom ones like anthropic.com”), and explicit routing triggers (e.g., “IF the question is about experiment lift… DO NOT use for raw event counts”) without prescriptive recipes that go stale. See below for a skeleton we use to create reference docs.
# [Domain] Tables
## Quick Reference
### Business Context — [what this domain means in plain words]
### Entity Grain — [what one row represents]
### Standard Hygiene Filter — [the filter every query in this domain applies]
## Dimensions
- [How the key dimensions are encoded, and how the same concept is named
differently across tables]
## Key Tables
### [table_name]
- **Grain**: [...] · **Scope/exclusions**: [...]
- **Usage**: [when to use it, when NOT to, join keys, required filters]
[... one short section per governed table ...]
## Gotchas
- [The wrong-answer modes a senior analyst would warn you about]
## Best Practices / Common Query Patterns
- [Default choices, standard cuts, worked patterns where the exact query
form is the hard part]
## Cross-References
- [Neighboring domain docs that own adjacent questions]Treat skill maintenance as a first class citizen: Skill docs describe a data model that changes daily, so without active maintenance they're wrong within weeks. We watched our offline accuracy drift from ~95% at launch to ~65% over a month before we treated this as an engineering problem. That meant colocating skill markdown files in the same repo as our transformation models, so the PR that changes a model is the same PR that updates the doc describing it. A code-review hook flags any reporting-model change that doesn't touch a skill file. Roughly 90% of our data-model PRs now include a skill change in the same diff. We also regularly prune skill scaffolding as models improve and previous failure modes no longer apply.
Create a consistent and seamless experience across all surfaces: the same skill *must* provide the same answer to questions in Slack, in the IDE, in a dashboard tool, and in standalone agent sessions. We did this by ensuring one canonical source (the data repo) and that skill changes are synced automatically. On merge, the skill syncs to a plugin marketplace (for IDE users), to cloud-storage blobs (for hosted apps that read a single file), and is served directly as resources over MCP. We also designed for portability from the start by avoiding hardcoded repo paths and surface-specific namespaces.
Validation
Finally, validation is how you find out which of the three failure modes is still leaking through.
Offline evaluations
A common pattern we see is that data teams will set up elaborate analytic environments without having any process to understand the accuracy of their analytics agents.
One way of addressing this gap is via offline evals, which are simple question / answer pairs. You can think of offline evals similar to offline testing for an ML model in that they don’t tell you the performance of your online agents, but they do give you a good sense of whether you’ll have any critical gaps.
We deploy two kinds of offline evals at Anthropic. Dashboard-based evals are auto-generated by Claude (then human validated), covering the most common stakeholder questions. Long tail evals are where we feed Claude business context (roadmaps, table docs) and have it generate plausible questions across the rest of the domain. We also continuously harvest every time a stakeholder corrects the agent in a thread as that correction is a candidate eval.
Other best practices, include:
- Anchor ground truth so it can't drift: An eval written against live data goes stale the moment the underlying number moves. Pin every eval to a snapshot date, write it against a stable fact table, or have the grader judge the agent's query rather than its number. Wire the suite into CI so a PR touching a dependency re-runs the affected evals.
- Store results like telemetry, not like test logs: Every run lands in a warehouse table with the skill version, git SHA, model ID, per-assertion pass/fail, token count, and wall-clock. "Did that change help?" becomes a query, and you get the time-series to catch slow regressions that a single CI run won't.
- Gate launches per domain: A domain owner can't announce the agent to their stakeholders until their slice of the eval set clears some threshold (we initially used ~90%). It forces reference-doc fixes before users see the failures.
- Create the appropriate number of evals: The number of evals you should have depends on the complexity of the business area and the complexity of the underlying data model. Calibrate by tracking how well offline accuracy predicts online accuracy: we’ve found there are diminishing returns past a few dozen per topic (e.g., “growth”), and that ceiling drops with each new model generation.
- Offline eval accuracy should be ~100%; every correct answer should also be hitting your semantic layer (if you have one). Again, this level of accuracy doesn’t tell you your system isn’t going to produce a wrong answer, just that there are no obvious gaps, assuming you have proper eval coverage.
Ablation techniques
Every structural decision about the skill (e.g., which sources to expose, whether a sub-agent earns its latency, whether to merge two skills into one) is made by holding our offline eval set fixed.
We vary exactly one component and compare pass rates. Each run only takes an hour and replaces a lot of arguments. The methodology matters more than any single result:
- Design for null results. Our most useful ablation was a negative one. We gave the agent direct grep access to our entire dashboard, transformation, and analyst-notebook SQL (thousands of files). We then verified in transcripts that it actually read them before every answer. Accuracy moved by less than a point in either direction. We then checked the obvious confounds: was the answer actually in the corpus for the questions it got wrong? About 80% of the time, yes. Did "answer present" predict "now gets it right"? No, the flip rate was flat. The information was there, the agent saw it, and it still didn’t use it. That single experiment told us our bottleneck wasn't access to prior work, it was structure (i.e., mapping a question to the right entity). That insight redirected months of roadmap.
- Ablate at PR granularity. Every meaningful skill edit gets a before / after run on the relevant eval slice, with the delta in the PR description. It keeps "I improved the docs" honest and catches the surprisingly common case where a well-intentioned addition makes things worse.
- Keep a short list of what didn't work. Two of ours: stacking additional rounds of doc refinement past a certain point (we hit three consecutive net-negative iterations: the docs were getting longer, not better), and swapping the adversarial reviewer to a cheaper model to cut latency (it lost most of the accuracy wins, for no real speedup). Negative results are cheap to record and they prevent the next person from re-running the same experiment.
Online validation
The final step is ensuring the actual online system performance is as accurate as possible. Some of the steps we take include:
- Adversarial review: we’ve found that employing a Claude skill to aggressively challenge all underlying assumptions on a potential final answer increased accuracy by 6% within our eval set, but at the cost of 32% more tokens and 72% higher latency.
- Provenance footer: every response carries a footer that contains which source tier it came from (semantic layer › curated reference › raw table), how fresh the underlying data is, and who owns the model. It doesn't make the answer more correct, but it does help the consumer judge how much they can trust the response. A "raw table, freshness unknown" footer is a signal to verify before forwarding upstream, and it's one of the few mitigations we have for silent failures.
- Data quality checks: it’s possible that your agent is using the right field in the appropriate way, but the data itself is incorrect. Adding basic data quality checks to ensure the referenced field is up-to-date, complete, and has no anomalies is generally good hygiene.
- Passive monitoring: two production signals we track continuously are the share of agent queries that resolve through the semantic layer, and the share of responses that use correction language ("that's the wrong table," "you're missing the fraud filter"). Both feed a dashboard reviewed weekly alongside the offline pass rate.
- Active correction harvesting: the part that closes the loop. A scheduled agent scans stakeholder channels every few hours for similar correction language, drafts a one-line fix to the relevant reference doc, and opens a PR tagged to the domain owner. The fix path is deliberately boring — edit a markdown file, merge, auto-sync everywhere — so a domain owner doesn’t spend too much time on the task. The same corrections feed back into the offline eval set.
The failure mode none of this fully catches is the silent one. The answer is wrong, but looks plausible and is used without objection. Our mitigations are the provenance footer, explicit human sign-off on anything leadership-bound, and a standing eval for each domain's top KPIs that sanity-checks against the blessed dashboard daily, though we don’t have a robust solution yet.
Getting started
If you're starting from zero, a handful of canonical datasets, a few dozen offline evals, and a thin knowledge skill will capture most of the upside; everything else in this post is what we added once those were built.
We also shared many best practices, and not all of them will be appropriate for every data team. Align with your organization on a few principles that will affect your approach by asking:
- How important is a correct answer today vs. in the future? AI models are progressing at a rapid pace. We often see companies building a significant amount of infrastructure to account for current model shortfalls that become moot once those models improve. Knowing where models fall short, and waiting for model improvements to fill the gap has significantly less overhead, but may not fit your company’s risk tolerance.
- How do you anticipate the complexity of your business to change over time? Some of the processes we discussed may be overkill if, for example, you don’t produce much data, you only have a few consumers of the output, or your data model is likely to remain simple.
- How technical is the intended audience of the output? Phrased differently, if you’re building this analytics system for data scientists who can recognize when an answer is incorrect, you may be more tolerant of errors compared to a situation in which the audience has no familiarity with the underlying data model.
- How much are you willing to spend for improved accuracy? We’ve found certain processes like adversarial validation can significantly improve accuracy, but often at a higher cost and latency.
- What is your comfort around access controls and internal data privacy? Agents are often significantly more performant the more context they have; however, broad data access cuts against most companies' governance posture. This determines whether you're building one agent or many scoped ones.
Whatever your route, our greatest gains have come from addressing each of the three failure modes: collapsing ambiguity into a single governed answer, making the answer easily discoverable, and flagging when either has gone stale.
*This article was written by Chen Chang, Clement Peng, Justin Leder, Johanne Jiao, and Josh Cherry, members of the Data Science and Data Engineering team. The authors would like to thank Michael Segner for his contributions.*
Appendix
Skill File Skeleton
What follows is the skeleton of our main warehouse skill: the real file's structure, with internal specifics replaced by [bracketed placeholders]. It isn't meant to be copied verbatim; it's meant to show the kinds of sections we found worth writing down.
---
name: [warehouse-skill]
version: [x.y.z]
description: "IF the user asks to query [the company]'s data warehouse for any
[list of business domains] question — THEN invoke this skill. DO NOT invoke
for [adjacent engineering tasks] or questions with no data-warehouse component."
---
# [Warehouse] Skill Instructions
## Description
The single source of truth for safe and effective [warehouse] querying.
Referenced by other skills [listed] for query execution guidance.
Act as a Data Analyst, providing strategic insights and data-driven
recommendations but seek guidance along the way.
**Out-of-scope decisions**: [product areas, etc.] → surface data only,
state "decision is [owning team]'s call", do NOT take a position or author
code fixes.
## Executing queries
Priority:
1. **[Managed connection]** (if available): [query tool] / [schema tool]
2. **[CLI fallback]** (if installed): [default project, fallback project]
3. **Neither** — ask the user to authenticate, then stop
---
# Semantic Layer (REQUIRED first step)
The governed semantic layer is the **mandatory default path** for every data
question — same numbers as [the BI tool], joins/grain/filters baked in. Raw SQL
via the reference docs below is the **fallback**, used only after the
semantic-layer path is shown not to cover the ask.
## Required workflow
1. **Load** — [how to load the semantic layer in each runtime, with fallbacks]
2. **Discover** — search measures/dimensions by keyword; **always check
segments** (the named canonical population filters — hand-rolled WHERE
clauses for these are the dominant wrong-answer mode)
3. **Compile + run** — build the spec → compile to SQL → execute
4. **Fallback** — only if discovery finds no relevant metric or compile fails
→ raw SQL via `references/*.md` (PART 3 below)
> **Don't bail early.** Do NOT fall back to raw SQL on these grounds:
> - "[custom date filtering / cohorts]" → [covered by time-dimension specs]
> - "[needs a join]" → [the metric layer already encapsulates its joins]
> - [3–4 more pre-rebutted excuses agents use to skip the semantic layer]
### Date windows & timezone — decide before you query
- **As-of date vs trailing-N days**: [convention for each]
- **"Last week/month"** → the last *complete* calendar week/month, not trailing-7/30
- **Timezone default**: [TZ]; [exception for certain reporting rollups]
- **Freshness lag**: [some] tables settle late — anchor on MAX(date), not "yesterday"
---
# PART 1: MUST KNOW (Read First for Every Request)
## 🚀 Quick Start Workflow
1. **Check for red flags first**: [restricted/PII requests, gated domains,
high-stakes asks that need extra validation]
2. **Out of scope — escalate, don't guess**: [access requests, pipeline
troubleshooting, stale dashboards, root-cause assertions, product/pricing
recommendations] → redirect to [the owning team], don't answer
3. **Clarify the request**: time period, segment, the business decision it informs
4. **Check for existing dashboards**: [per-domain dashboard catalogs]
5. **Identify the data source**: [navigation map below; prefer governed/aggregated tables]
6. **Execute the analysis**: [required filters + adversarial review]
7. **Deliver insights**: show methodology, differentiate observations from interpretations
## 🏢 Business Context
### Entity Disambiguation (MUST CLARIFY)
- **"[Term A]" can mean**: [entity 1] or [entity 2] — always clarify which
- **"[Term B]" can mean**: [entity 1] → [entity 2] → [entity 3] (one-to-many chain)
- **"Users"**: [which identifier gives accurate counts, and which ones inflate them]
### Business Terminology
- [Current product names vs deprecated aliases that still appear as frozen
values in the data layer — write with the new names, filter with the old]
- [Key internal acronyms]
- **[Headline metric] calculations**: [monthly / default window / leading indicator]
- **Unfamiliar terms — search [internal docs], don't guess**
### Data Integrity Requirements ⚠️
- **NEVER**: make up data/columns; make speculative assertions beyond what data shows
- **ALWAYS**: use safe division; differentiate observations ("data shows X")
from interpretations ("this suggests Y"); flag limitations
---
# PART 2: HOW TO DO (Follow During Execution)
## 🔧 Technical Execution Guide
- [Managed-connection tools and CLI invocation details]
- **PII protection**: for restricted data, return the SQL for the user to run
themselves — do not return results
## 📊 Analysis Best Practices Guide
1. Clarify the ask before querying
2. Show your work (filters, inclusions/exclusions, freshness)
3. Clarify denominators
4. Consider sample bias
5. Connect to business impact
6. **Adversarial SQL review (MANDATORY)** — spawn the [sql-reviewer] sub-agent
for every query before the final answer; blocking findings must be fixed
and re-reviewed; do not self-certify
7. **Report with provenance** — every answer ends with a footer:
> **Source:** [semantic layer | governed table | raw exploration] ·
> **Confidence:** [tier] · **Reviewed:** [reviewer ✓, round N] ·
> **Freshness:** [max date in the data] · **Owner:** [owning team]
---
# PART 3: DATA REFERENCES & RESOURCES
## 📚 Knowledge Base Navigation
### [Domain A] → `references/[domain_a].md`
- **Use for**: [kinds of questions]
- **Key tables**: [...]
- **Dashboards**: `references/[domain_a]_dashboards.json`
### [Domain B] → `references/[domain_b].md`
- **Use for**: [...]
[... one entry per business domain — a few dozen in total ...]
## ⚠️ Troubleshooting Guide
### When Information Is Missing
- [missing tables / access denied / outdated docs / unknown enum values → what to do]
### Field Naming Gotchas
- Use `[field_x_v2]` NOT `[field_x]`
- [Two similarly-named tables report the same metric at different grains — which to use]
- [Which of two plausible sources is canonical for the headline metric]
- [… a dozen more hard-won one-liners …]
No items found.
Transform how your organization operates with Claude
Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.
Please provide your email address if you'd like to receive our monthly developer newsletter. You can unsubscribe at any time.
Thank you! You’re subscribed.
Sorry, there was a problem with your submission, please try again later.
関連記事
アトランティック紙のマット・ウォン氏引用:ホワイトハウス報告書におけるアンソロピックとファベルの関与
サイバーセキュリティ専門家でありルタ・セキュリティCEOのカティ・ムッソウリス氏は、ホワイトハウスの「フェイブル」脱獄に関する報告書をアンソロピックが共有し、評価を求めたと明かした。同氏はこの報告書において、IT 専門家がバグの特定と修正のためにファベルに協力を依頼したと述べている。
AI業界の命運を分ける可能性のあるMAGA派の権力闘争:Anthropicの事例
Anthropicは、政府からの輸出管理指令により、米国国外および国内の外国人に対する新モデル「Claude Fable 5」および「Mythos 5」へのアクセスを即時停止すると発表した。これにより事実上の技術禁止措置が講じられた。
"彼らが私たちを裏切った": 性格の衝突によりアンソロピックのモデルがオフラインに
米政府とアンソロピックの関係者によると、両者の間の性格上の対立が原因で、同社のAIモデルへのアクセスが一時的に停止された。これはホワイトハウスとの関係に関する内部告発記事に基づくものである。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み