隠されたスキルギャップ:SQL と Python の知識だけではもはや不十分である理由
2026 年のデータサイエンティスト求人市場分析により、SQL と Python が必須要件から差別化要因へ後退し、LLM や RAG、ベクトルデータベースといった AI 実装スキルと高度なエンジニアリング能力が新たな求人の鍵となっていることが示された。
キーポイント
必須スキルの地位変化
SQL と Python は依然として上位のスキルだが、差別化要因から「最低限の前提条件(prerequisites)」へと格下げされ、これだけでは採用競争で勝てない状況になっている。
AI 実装スキルの急増
求人の約 3 分の 1 で具体的な AI 経験が求められており、LLM、RAG(検索拡張生成)、プロンプトエンジニアリング、ベクトルデータベースの知識が最も需要が高い。
エンジニアリング基盤の引き上げ
データパイプライン、オーケストレーション、クラウドプラットフォーム、データ品質管理などの基礎的なデータエンジニアリングスキルに対する期待値が劇的に上昇している。
AI・機械学習スキルの需要上昇
Python と SQL の他に、LLM、RAG、プロンプトエンジニアリング、ベクトルデータベースといった具体的な AI 技術の習得が、求人の約 3 割で必須要件となっています。
エンジニアリング基盤のハードル上昇
データパイプライン構築、クラウドプラットフォーム利用、モデル監視やドリフト検知といったデータエンジニアリングおよび MLOps のスキルが、もはやボーナスではなく中核的な期待事項となっています。
Snowflake や dbt などのツール必須化
主要な求人ボードでは、Data Scientist 役職において Snowflake、dbt、Airflow の利用や ETL パイプラインの所有権が、単なる「あれば良い」スキルから必須要件へと変化しています。
データモデリングの重要性と責任の移行
Snowflake や dbt などのツールの進化により、データスキャーマ設計や変換レイヤーの責任がデータエンジニアからデータサイエンティストに移行しており、誤ったモデルは機械学習の基盤を損なう危険がある。
影響分析・編集コメントを表示
影響分析
この記事は、データ職種の採用市場が「分析ツールを使う人」から「AI システムを構築・運用する人」へと急速にシフトしていることを示唆しており、学習戦略の見直しを迫る重要な指標となる。企業側は単なるコード記述能力よりも、生成 AI 技術をビジネスシステムに統合できる実践力を強く求めているため、データプロフェッショナルは即戦力としての AI 実装スキルを早期に習得する必要がある。
編集コメント
データ職を目指す人々にとって、基礎言語の習得は「スタートライン」に過ぎず、現在は AI 実装とシステム構築能力が勝敗を分ける決定的な要素となっています。
 image**
image**
長年、この公式はシンプルに見えました:SQL を学び、Python を学べば、データ関連の職に就ける。特に中堅企業が「データドリブン」化し始めた頃にはなおさらでした。採用担当者は、半端な GROUP BY 文が書け、pandas DataFrame を操作して何かを壊さずに済む人材なら誰でも雇えることに満足していました。「PostgreSQL が何かわかるか?それならOK、採用だ!」という具合です。これはある程度機能していました。しかし、もうそうはいきません。
ご存知ないかもしれませんが、データ専門職の雇用市場は構造的な転換期を迎えています。もちろん、SQL と Python は依然として重要です。すべての求人票に記載されています。しかし、それらは差別化要因から必須条件へと格下げされました。
おそらく、あなたはまだ 3 年前に練習した面接対策の問題点に最適化しようとしているのでしょう。それはやめましょう。この記事は、候補者が準備していることと、企業が今実際に必要としていることの間のギャップについて述べるものです。
# 雇用市場が本当に求めているもの
**
2026 年 1 月の分析(Future Proof Data Science による、データサイエンティストの求人票 700 件以上の内訳)では、Python と SQL が依然として上位 3 つのスキルの一つであることが示されていますが、機械学習と AI のスキルはそれぞれ第 2 位と第 4 位となっています。**
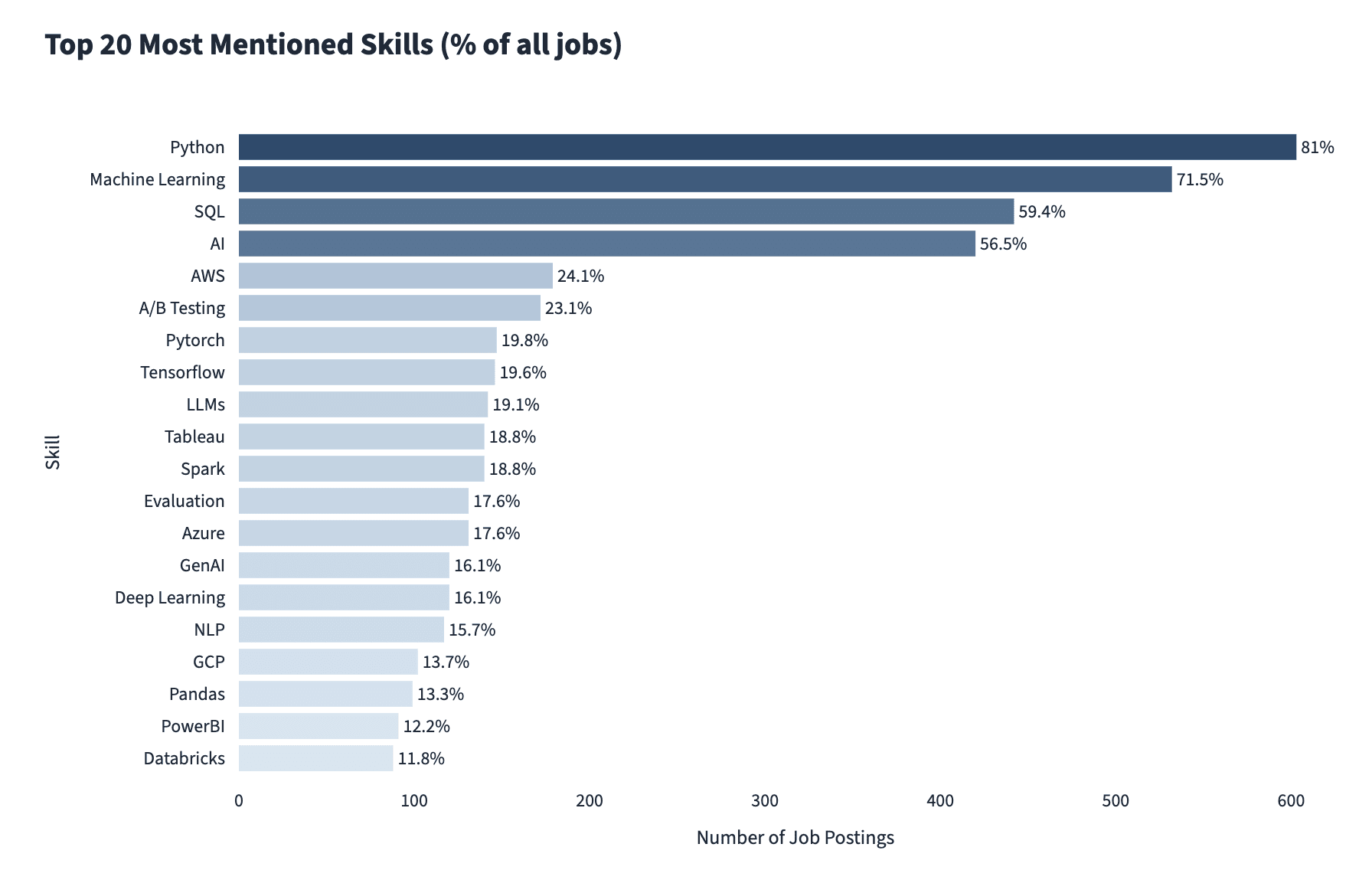 image**
image**
画像出典:Future Proof Data Science
すべての AI 関連の求人ポストが実践的な AI の専門知識を求めているわけではありませんが、そのうちの 3 分の 1 はそうしています。最も求められる具体的な AI スキル**は以下の通りです:
- 大規模言語モデル (LLM: Large Language Models)
- 検索拡張生成 (RAG: Retrieval-augmented generation)
- プロンプトエンジニアリング
- ベクトルデータベース
これは、AI システムを構築し展開できるデータ専門家に対する需要が増加していることを示しています。
この変化の方向性だけでなく、その速度も重要であることを忘れないでください。これは、機械学習が 2012 年にはニッチな要件であったものが、2020 年にはほぼ普遍的な要件へと変化した様子に似ています。
二つ目の物語は目立たないかもしれませんが、多くの候補者にとっておそらくより差し迫った問題です:基礎的なエンジニアリングの基準が急激に引き上げられたのです。データエンジニアリングスキル(パイプライン、オーケストレーション、クラウドプラットフォーム、データ品質チェック)と本番環境での機械学習(モデル監視、ドリフト検出、評価設計)は、データサイエンスの求人ポストにおけるボーナス項目ではなく、もはやコアな期待事項となっています。
主要なジョブボードを少し見渡すだけで確認できます:AI スキルに加えて、「データサイエンティスト」というタイトルの役割では、Snowflake、dbt、Airflow、および ETL パイプラインの所有権が、単なる「あれば良い」項目ではなく必須要件として routinely 列挙されています。
おそらくあなたが欠いているスキルは4つあります。これらが現在の雇用市場における新たな差別化要因です。
**
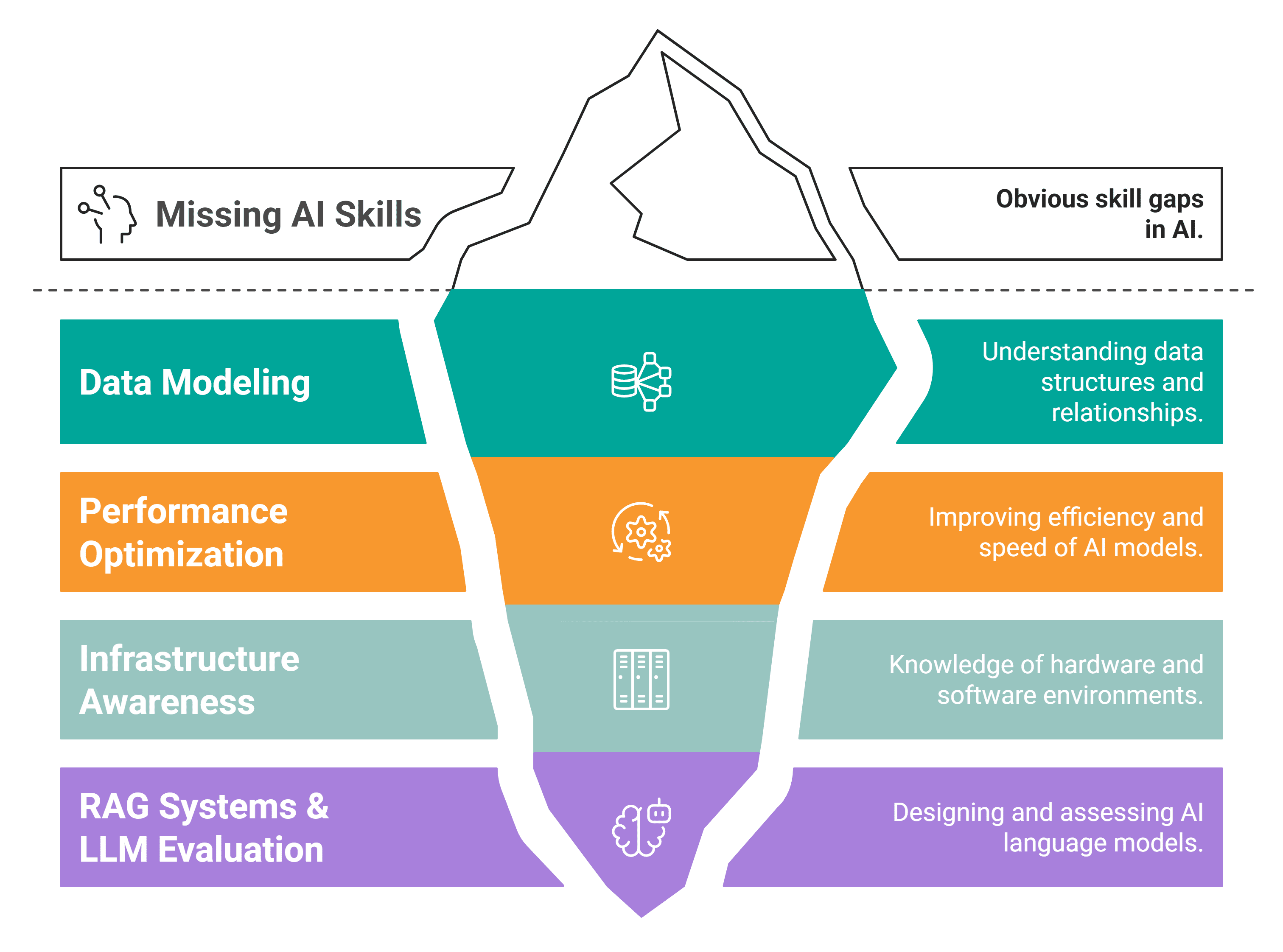
# スキル#1: データモデリング
// それとは何か
データモデリングは、データをどのように構造化し、関連付け、保存すべきかを設計する能力です。作成するテーブルを決定し、それらが何を表し、互いにどう関係するかを考えることと捉えてください。
// なぜこれが差別化要因となったのか
ツールの改善が状況を大きく変えました。Snowflake、dbt、そして BigQuery により、データサイエンティストがデータ変換レイヤーを完全に担当することが比較的容易になりました。つまり、以前はデータエンジニアの領域だったモデリングに関する決定事項が、今ではデータサイエンティストに委譲されつつあります。
データスキーマを誤って設計すると、危険な水域に入ることになります。通常、これらのエラーは直ちに明らかになるものではありません。問題が顕在化した時には手遅れです。機械学習の作業は、すでに不適切な粒度のデータに基づいて構築された特徴量エンジニアリングによって影響を受けています。これは、 improperly モデリングされた基盤の結果として生じる直接的な帰結です。
**
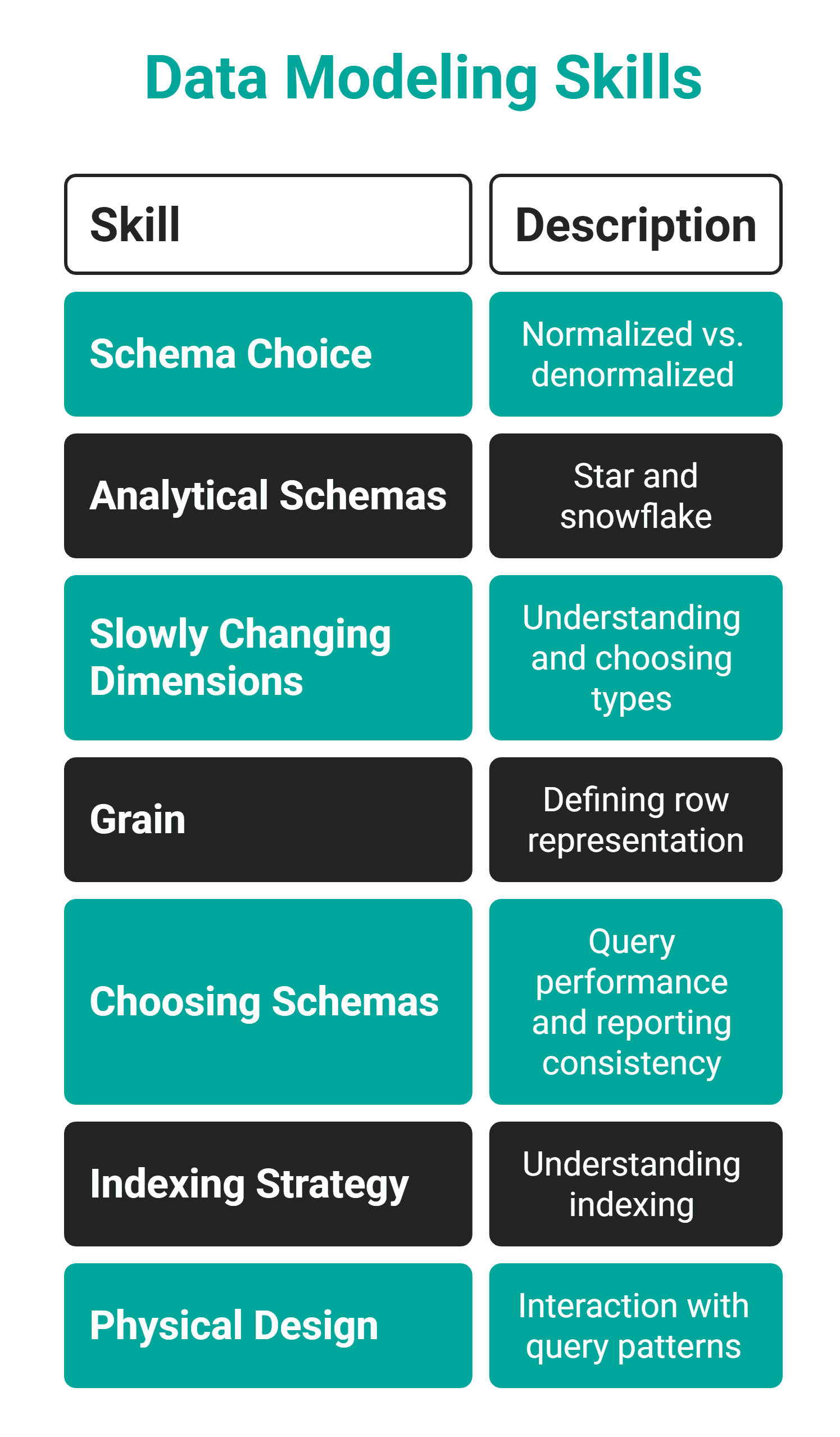
// どのように習得するか
あなたが実際に扱っているデータセットを1つ選び、そのスキーマをゼロから再設計してみてください。以下の問いに自問自答してください:
- 対象となるエンティティは何ですか?
- それらは何と関連していますか?
- どの粒度(グライン)が適切でしょうか?
- 最も頻繁に実行されるクエリはどのようなものですか?
その後、次元モデリングについて読んでください。Kimball のアプローチ は、彼の著書 The Data Warehouse Toolkit に詳細に記載されており、依然として有用な参照点となっています。
# スキル#2: パフォーマンス最適化
// 何であるか
パフォーマンス最適化とは、クエリがなぜそのように実行されるのかを理解し、それをより高速に、低コストで、あるいは大規模に実行する方法を学ぶことです。SQL クエリの最適化だけでなく、Python パイプラインや一般的なデータワークフローの最適化も行うことができます。データサイエンティストは、これらのエンドツーエンドの責任をますます負うようになっています。
// なぜこれが差別化要因となったか
第一に、データの量が膨大になり、正しくても非効率なクエリが、本番環境で数百ドルのコストとタイムアウトを引き起こすに至っています。
第二に、前述の通り、データサイエンティストは以前よりもパイプラインの多くを自ら担当する必要があるようになりました。コードは Jupyter ノートブックで実行可能であるだけでなく、本番環境で運用可能な状態(プロダクション・レディ)でなければなりません。
**
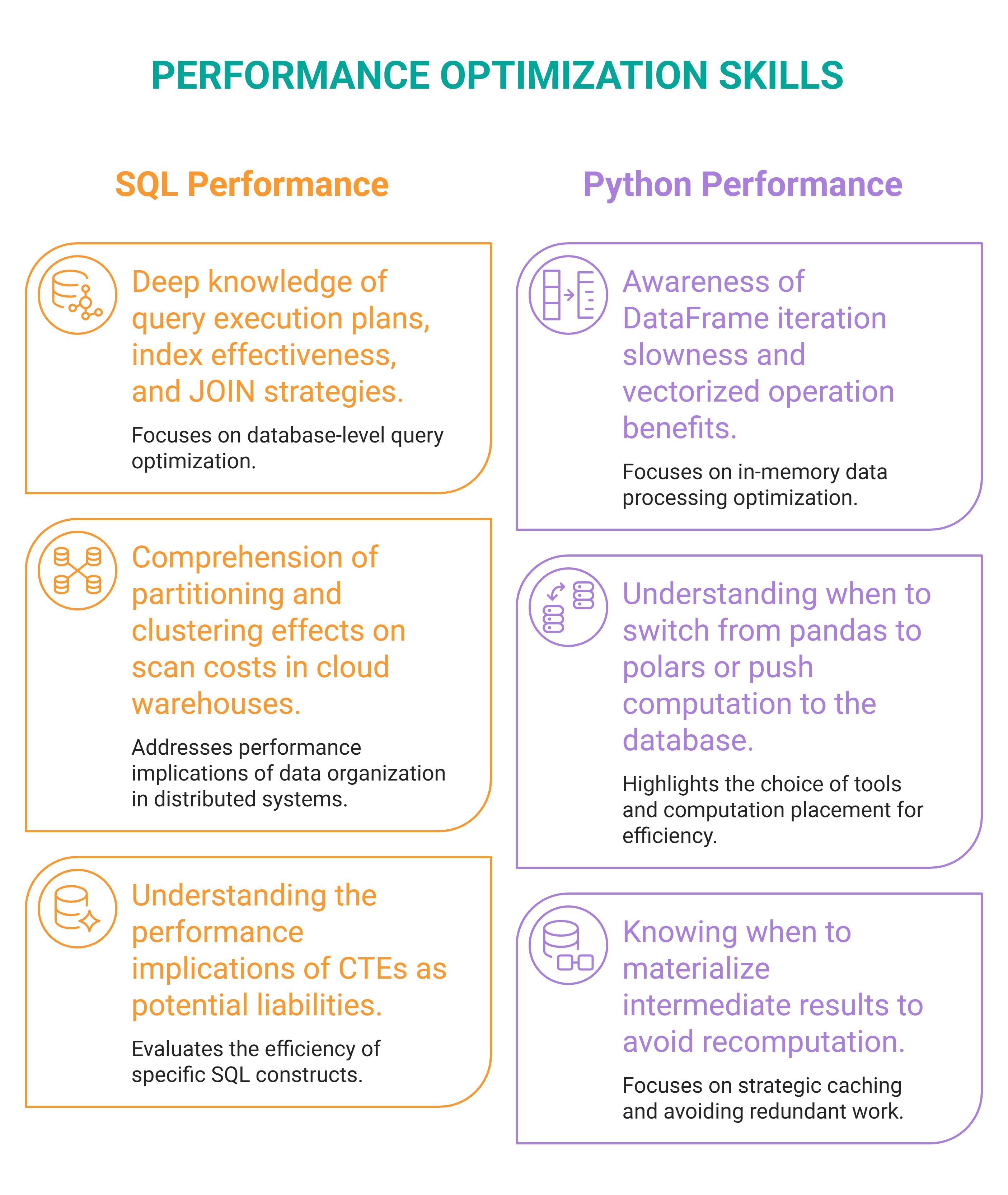
// どのように習得するか
あなたが作成した複雑な SQL クエリをいくつか選び、それらに対して EXPLAIN ANALYZE を実行し、クエリプランナーが実際に何を行ったかを読み込んでください。そして、その知見に基づいてクエリを最適化してください。おそらく、各クエリを改善するインデックスの追加、構造の再構築、あるいは書き換えの少なくとも一つが見つかるはずです。
遅い Python パイプラインの場合は、プロファイリングを行ってください。時間に関する主なツールは以下の 2 つです。
- cProfile:
python -m cProfile -s cumulative your_script.pyで実行し、出力の上部を確認して、累積時間が最も長い関数を探してください。 - line_profiler: 特定の関数内の行ごとの実行時間を表示することで、より詳細な分析を行います。cProfile でどの関数が遅いかを特定し、その理由を知る必要がある場合に使用します。
メモリについては、memory_profiler を使用してください。
ボトルネックを見つけましょう — Python のループをベクトル化するべきではないか?データを一度にすべてメモリに読み込んでいるのではなく、チャンク単位で読み込んでいないか?— 問題を解決し、その改善効果を測定してください。
# スキル #3: インフラストラクチャの理解
// それとは何か
このスキルとは、データが存在し、移動するシステムを理解していることを意味します。これらのシステムには、クラウドプラットフォーム、分散コンピューティング、データパイプライン、ストレージフォーマット、コストモデルが含まれます。
デプロイ可能なシステムを設計するために必要なインフラストラクチャに関する知識を持っているべきです。
// なぜそれが差別化要因となったのか
再び、データエンジニアの業務の大きな部分がデータサイエンティストの手に委ねられているからです。インフラに関するすべての決定にデータエンジニアを依存している場合、あなたは実質的にボトルネックを生み出しており、それは採用担当者が求めていることではありません。
インフラへの理解には、主に以下の相互に関連する領域が含まれます。
**
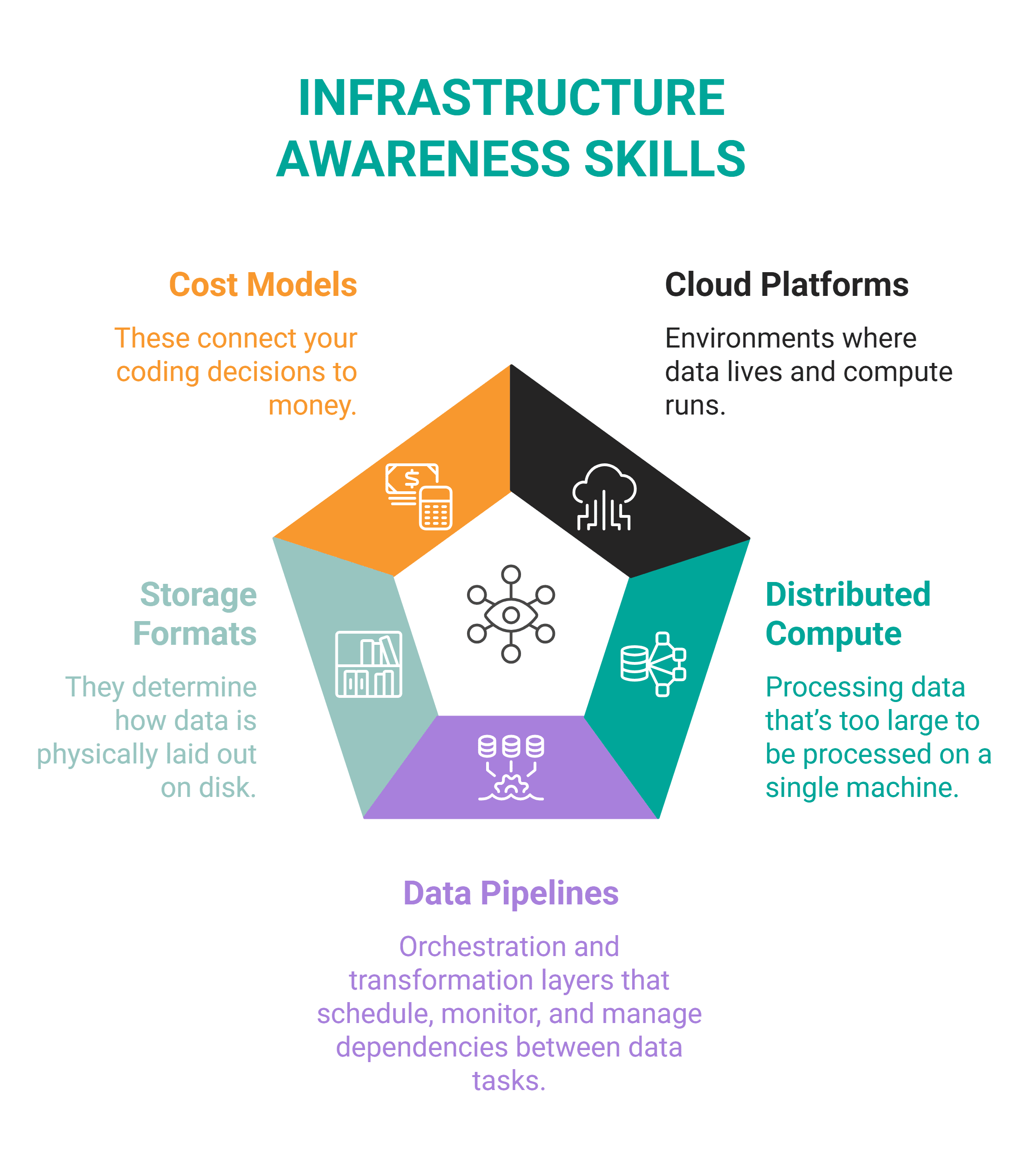
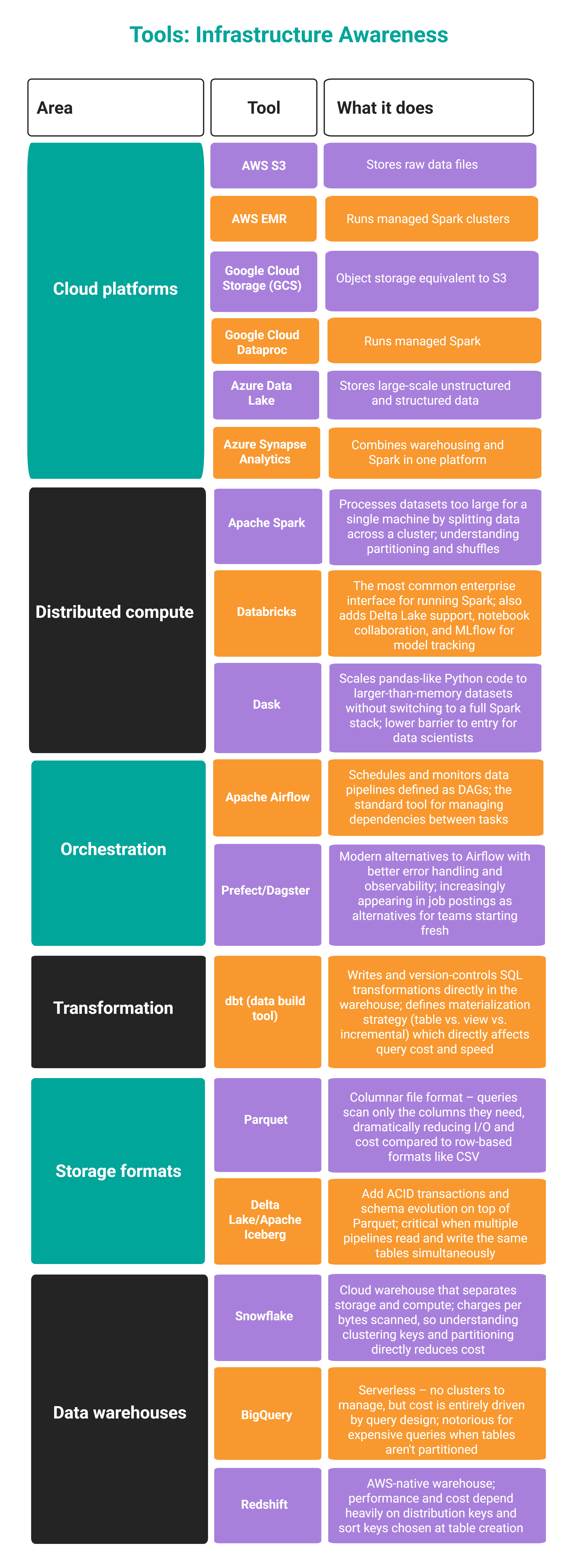
これらのツールに慣れる必要があるでしょう。
// どのように習得するか
データエンジニアリングチームとセッションを設けてください。彼らと一緒に座り、パイプラインの全体像を順を追って説明してもらいましょう。データがどこに保存されているか、どのようにパーティション分割されているか、そして何かが破綻した際に何が起きるかを理解してください。
次に、自ら小さなパイプラインを構築することでステップアップしましょう:無料クラウドティアを利用し、コストと実行メトリクスを理解した上で、意図的にパイプラインを壊して、それがどのように失敗するかを理解します。
# スキル#4: RAG システムの設計、LLM 出力の評価、および AI 実験の実行
// それとは何か
このスキル群は実践的な AI ワークに関連しています。大規模言語モデル(LLM)を実際のデータソースに接続する検索拡張生成(RAG)システムの設計方法、評価フレームワークの構築(LLM を活用した機能が実際に機能しているかを測定するためのもの)、および AI 機能に関する実験の実行方法を理解する必要があります。
// なぜそれが差別化要因となったのか
AI ツールがその理由です。これにより、広範な研究知識なしに RAG パイプラインを構築することが可能になりました。LangChain や LlamaIndex といったフレームワークと、クラウドネイティブベクトルデータベースの組み合わせが、参入障壁を大幅に低下させました。
したがって、今問われているのは「構築できるか」ではなく、「よく構築できているか」「評価できるか」「本番環境で信頼できるか」という点です。この問いに答えることができるようになることが求められます:指標の定義、実験設計、そして結果の測定です。
**
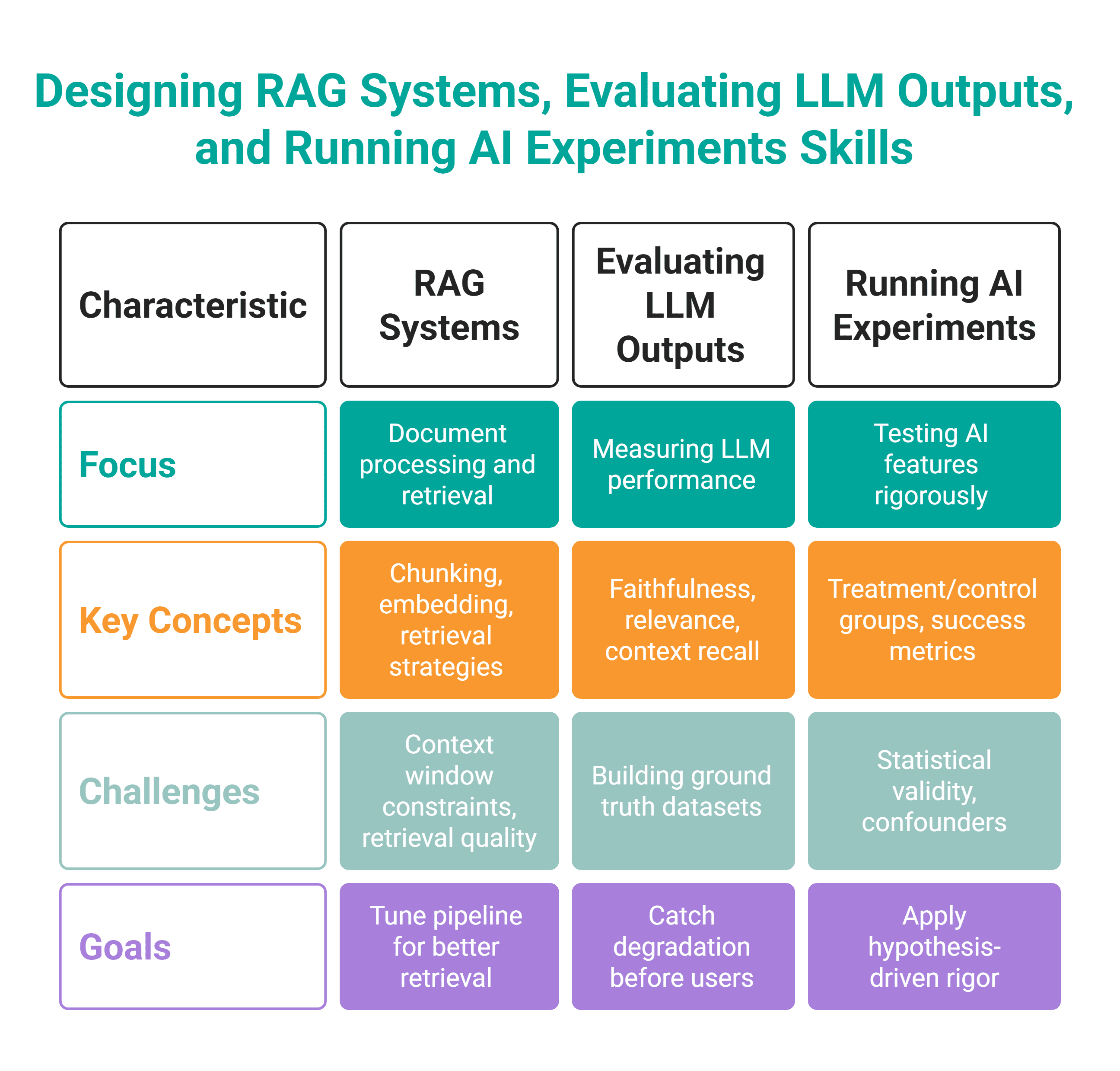
これらのスキルを適用する際、あなたはこれらのツールを使用することになります。

// どのように習得するか
AI の思考力を磨くための面接質問を探してみましょう。以下は、StrataScratch の AI Product & GenAI interview questions から抜粋した例です。
例 #1: 小売店舗における AI 機能のロールアウト測定
**
AI を活用した在庫推奨システムを小売店のサンプルに展開する際、その影響度をどのように測定しますか?また、実験をどのように設計し、店舗ごとのばらつきをどう考慮しますか?
例 #2: RAG システムアーキテクチャ
ゼロから RAG (Retrieval-Augmented Generation: 検索拡張生成) システムをどのようにアーキテクチャするか記述してください。必要なコンポーネントは何ですか?また、検索の質をどう最適化しますか?
思考プロセスを明確にした後、小さな RAG アプリケーションを構築してください**: ドメインを選択し、ドキュメントコーパスを埋め込み、検索機能を接続し、構造化された指標を用いて出力を評価します。
さらに実験も設計してください:仮説を記述し、指標を定義し、それを評価するための妥当なテスト方法を考え抜きます。
# 結論
データモデリング、パフォーマンス最適化、インフラストラクチャの理解、そして実践的な AI スキルの 4 つのスキルこそが、あなたと雇用市場との間に存在するギャップを構成しています。どうかこのギャップに陥らないでください。そのために、本記事ではそれぞれのスキルを獲得するための実践的なアドバイスを含めています。
Nate Rosidi はデータサイエンティストであり、製品戦略にも携わっています。また、分析を教える非常勤講師でもあり、トップ企業からの実際の面接質問を通じてデータサイエンティストの準備をサポートするプラットフォーム「StrataScratch」の創設者です。Nate はキャリア市場における最新動向について執筆し、面接に関するアドバイスを提供し、データサイエンスプロジェクトを紹介し、SQL 関連のあらゆるトピックをカバーしています。
原文を表示
**
For years, the formula seemed simple: learn SQL + learn Python = get a data job. Especially as mid-sized companies started becoming "data-driven." Hiring managers were happy they could get anyone who could write a half-decent GROUP BY and wrangle a pandas DataFrame without breaking something. You know what PostgreSQL is? Get in, you got the job! This worked for some time. Until it didn't.
If you haven't noticed, the data professional's job market has undergone a structural shift. Yes, SQL and Python are still important; they're on every job description. But they've been demoted from differentiators to prerequisites**.
Likely, you're still optimizing for the interview questions you practiced three years ago. Forget about it. This article is about the gap between what candidates prepare for and what companies actually need right now.
# What the Job Market Is Actually Asking For
**
A January 2026 breakdown by Future Proof Data Science of over 700 data scientist job postings found that Python and SQL are still among the top three skills, but machine learning and AI skills are second and fourth**.
**
Image Source: Future Proof Data Science
Not all AI-related postings require hands-on AI expertise, but 1 in 3 does. The most required specific AI skills** are:
- Large language models (LLMs)
- Retrieval-augmented generation (RAG)
- Prompt engineering
- Vector databases
This speaks to an increasing demand for data professionals who can build and deploy AI systems.
Keep in mind that the direction *and* the velocity of this change matter. This reminds me of how machine learning went from a niche requirement in 2012 to a near-universal one by 2020.
The second story is less visible but arguably more immediate for most candidates: the foundational engineering bar has risen sharply. Data engineering skills — pipelines, orchestration, cloud platforms, data quality checks — and machine learning in production — model monitoring, drift detection, evaluation design — are now core expectations rather than bonuses in data science job postings.
A glance at any major job board confirms it: along with AI skills, roles titled "Data Scientist" routinely list Snowflake, dbt, Airflow, and ETL pipeline ownership as requirements, not nice-to-haves.
There are four skills that you are probably missing. These are the new differentiators in the current job market.
**
# Skill #1: Data Modeling
// What It Is
Data modeling is the ability to design how data should be structured, related, and stored**. Think of it as deciding what tables to create, what they represent, and how they relate to each other.
// Why It Became a Differentiator
Tooling improvements changed the landscape. Snowflake, dbt, and BigQuery all made it relatively easy for data scientists to own the data transformation layer. In other words, modeling decisions that used to belong to data engineers are now being handed over to data scientists.
Get a data schema wrong, and you're in dangerous waters. Typically, these errors are not obvious immediately. Once they become obvious, it's too late. Your machine learning work has already been impacted by feature engineering built on data of the wrong granularity — a direct consequence of a badly modeled foundation.
**
// How to Acquire It
Take a real dataset you work with and redesign its schema from scratch. Ask yourself these questions:
- What are the entities?
- What do they relate to?
- What grain makes sense?
- What queries will run most frequently?
After that, read about dimensional modeling. Kimball's approach**, detailed in his book The Data Warehouse Toolkit, remains a useful reference point.
# Skill #2: Performance Optimization
// What It Is
Performance optimization is understanding why a query runs the way it does and how to make it run faster, cheaper, or at greater scale. You can optimize SQL queries, but also Python pipelines and data workflows in general — data scientists increasingly own them end-to-end.
// Why It Became a Differentiator
First, data volumes have grown to the point where a correct but inefficient query can cost hundreds of dollars and time out in production.
Second, as mentioned earlier, data scientists now have to own much more of the pipeline than they did before. Your code has to be production-ready, not just runnable in Jupyter notebooks.
**
// How to Acquire It
Pick several complex SQL queries you've written, run EXPLAIN ANALYZE on them, and read what the query planner actually did. Then use that to optimize the query**. You'll likely find at least one index, restructuring, or rewrite that improves each query.
For a slow Python pipeline, profile it. There are two main tools for time:
- cProfile: Run it with python -m cProfile -s cumulative your_script.py and look at the top of the output to see the functions consuming the most cumulative time.
- line_profiler: Goes deeper by showing execution time line by line within a specific function. Use it once cProfile has told you which function is slow and you need to know why.
For memory, use memory_profiler.
Find the bottleneck — is it slow because a Python loop should be vectorized? Is data loaded into memory all at once instead of in chunks? — fix it, and measure the difference.
# Skill #3: Infrastructure Awareness
// What It Is
This skill means you understand the systems data lives in and moves through. These systems include cloud platforms, distributed compute, data pipelines, storage formats, and cost models.
You should know enough about the infrastructure to design systems that are deployable into it.
// Why It Became a Differentiator
Again, because a good chunk of a data engineer's job has fallen into a data scientist's lap. If you're dependent on data engineers for every infrastructure decision, you're effectively creating a bottleneck — and that's not something hiring managers are looking for.
Infrastructure awareness includes these main interconnected areas.
**
You'll most likely have to familiarize yourself with these tools.
// How to Acquire It
Arrange a session with your data engineering team. Sit with them and ask them to walk you through a pipeline end-to-end. Understand where data lives, how it's partitioned, and what happens when something breaks**.
Then step up by building a small pipeline yourself: use a free cloud tier, understand the cost and execution metrics, then deliberately break the pipeline to understand how it fails.
# Skill #4: Designing RAG Systems, Evaluating LLM Outputs, and Running AI Experiments
// What It Is
This cluster of skills relates to practical AI work. You have to know how to design retrieval-augmented generation (RAG) systems (connecting LLMs to real data sources), build evaluation frameworks (measuring whether an LLM-powered feature is actually working), and run experiments on AI features.
// Why It Became a Differentiator
AI tools are the reason. They made it possible to build a RAG pipeline without extensive research knowledge. Frameworks like LangChain and LlamaIndex, combined with cloud-native vector databases, lowered the barrier significantly.
So the question is no longer whether it can be built — yes, it can be. But can it be built well, evaluated, and trusted in production? Answering that question is what you must be able to do: define metrics, design experiments, and measure outcomes.
**
In applying these skills, you will use these tools.
// How to Acquire It
Find some interview questions to help you refine your AI thinking. Here are some examples from AI Product & GenAI interview questions** on StrataScratch.
Example #1: Measuring AI Feature Rollout in Retail Stores
How would you measure the impact of an AI-powered inventory recommendation system being rolled out to a sample of retail stores? How would you design the experiment and account for store-level variation?
Example #2: RAG System Architecture
Describe how you would architect a RAG system from scratch. What components are needed, and how would you optimize retrieval quality?
After you've made your thinking clear, build a small RAG application: choose a domain, embed a document corpus, wire up retrieval, and evaluate the outputs using a structured metric.
Also, design an experiment: write out a hypothesis, define the metrics, and think through a valid test to evaluate it.
# Conclusion
The four skills — data modeling, performance optimization, infrastructure awareness, and practical AI skills — are what comprise the gap between you and the job market. Hopefully you won't fall into it. To ensure you don't, this article has included practical advice on how to acquire each one.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み