Claude Codeの品質報告に関する最新アップデート
AnthropicはClaude Codeの品質低下報告を受け、推論レベル変更やセッションクリア機能のバグ、冗長性抑制プロンプトの3要因を特定・修正したと発表した。
キーポイント
推論努力度のデフォルト変更と修正
3月4日にUIのフリーズ対策で推論レベルをhighからmediumへ変更したが品質低下を招き、4月7日にユーザーの要望を受けて元に戻した。
セッションクリア機能の実装バグ
3月26日にアイドルセッションの古い思考を消去する変更を導入したが、毎ターン実行されるバグにより忘却と反復を引き起こし4月10日に修正した。
冗長性抑制プロンプトの品質悪化
4月16日にシステムプロンプトで冗長性を抑える指示を追加したがコーディング品質を低下させ、4月20日に元に戻した。
重要な引用
We’ve traced these reports to three separate changes that affected Claude Code, the Claude Code Agent SDK, and Claude Cowork.
This was the wrong tradeoff. We reverted this change on April 7 after users told us they'd prefer to default to higher intelligence and opt into lower effort for simple tasks.
This isn’t the experience users should expect from Claude Code. As of April 23, we’re resetting usage limits for all subscribers.
影響分析・編集コメントを表示
影響分析
本記事は、大規模言語モデルの出力品質がプロンプト設計や推論パラメータの設定次第で容易に劣化する可能性を示しており、開発者向けツールの品質管理プロセスの重要性を浮き彫りにしている。Anthropicが内部的な検証プロセスの見直しとユーザーへの補償を行ったことは、AIサービス提供者が透明性と迅速な対応を求められる現代の業界標準を示している。
編集コメント
開発者向けツールの品質低下は、単なるモデル能力の問題ではなく、プロンプト設計や推論パラメータの微調整、内部テストプロセスの甘さが複合的に影響するケースが多い。今回のような迅速な修正と透明性のある説明は、信頼回復に不可欠であり、業界全体への教訓となる。
過去1ヶ月間、一部のユーザーにおいてClaudeの回答品質が低下したという報告を調査してきました。これらの報告は、Claude Code、Claude Agent SDK、およびClaude Coworkに影響を与えた3つの別個の変更事象に起因することが判明しました。APIには影響がありませんでした。
これら3つの問題はすべて、4月20日(v2.1.116)時点で解決済みです。
本投稿では、私たちが発見した内容、修正内容、および同様の問題が再び発生する可能性を大幅に低減するために今後どのように対応するかについて説明します。
品質低下に関する報告は非常に重要なものと捉えています。私たちは意図的にモデルの性能を低下させることは一切なく、APIおよび推論レイヤーに影響がないことを即座に確認できました。
調査の結果、以下の3つの異なる問題が特定されました。
- 3月4日、Claude Codeのデフォルト推論努力レベルを「高」から「中」に変更し、ユーザーの一部が「高」モードで経験していた非常に長いレイテンシ(UIが一時的にフリーズしたように見えるほど)を削減しました。これは誤ったトレードオフでした。ユーザーから「単純なタスクには低努力モードを選択し、デフォルトはより高い知能を優先したい」とのフィードバックを受け、4月7日にこの変更を元に戻しました。これによりSonnet 4.6およびOpus 4.6に影響がありました。
- 3月26日、1時間以上アイドル状態だったセッションからClaudeの古い思考プロセスを削除し、ユーザーがそれらのセッションを再開した際のレイテンシを削減する変更を行いました。バグにより、この処理がセッション終了まで各ターンで繰り返されてしまい、Claudeが忘却症のように見えたり反復したりする現象が発生しました。4月10日に修正しました。これによりSonnet 4.6およびOpus 4.6に影響がありました。
- 4月16日、冗長性を抑えるためのシステムプロンプト指示を追加しました。他のプロンプト変更と相まってコーディング品質を低下させたため、4月20日に元に戻しました。これによりSonnet 4.6、Opus 4.6、およびOpus 4.7に影響がありました。
各変更は異なるスケジュールで異なるトラフィックの断片に影響を与えたため、集計された結果は一見して広範囲かつ一貫性のない品質低下のように見えました。3月初旬から報告の調査を開始しましたが、当初はユーザーフィードバックの通常のばらつきと区別するのが難しく、内部使用状況や評価(evals)でも当初は特定された問題を再現できませんでした。
これは、ユーザーが期待すべき体験ではありません。4月23日現在、すべてのサブスクリプションの使用制限をリセットしています。
Claude Code のデフォルト推論努力レベルの変更
2月にClaude CodeでOpus 4.6をリリースした際、デフォルトの推論努力レベル(reasoning effort)を高に設定しました。
その後すぐに、高努力モードでのClaude Opus 4.6が時折思考しすぎるため、UIが一時的にフリーズしたように見え、それらのユーザーにとって不均衡なレイテンシとトークン使用量につながっているというフィードバックを受けました。
一般的に、モデルが長く思考すればするほど、出力品質は向上します。努力レベル(effort levels)とは、Claude Codeがユーザーにこのトレードオフを設定する方法です。より多くの思考 versus より低いレイテンシと使用制限への到達回数の減少。モデルの努力レベルを調整する際、私たちはこのトレードオフを考慮し、ユーザーに最適な選択肢の範囲を提供するテスト時計算(test-time-compute)曲線上のポイントを選択します。製品レイヤーでは、この曲線上のどのポイントをデフォルトとして設定するかを選び、その値をMessages APIへのeffortパラメータとして送信します。その後、他のオプションは/effect経由で利用可能にします。
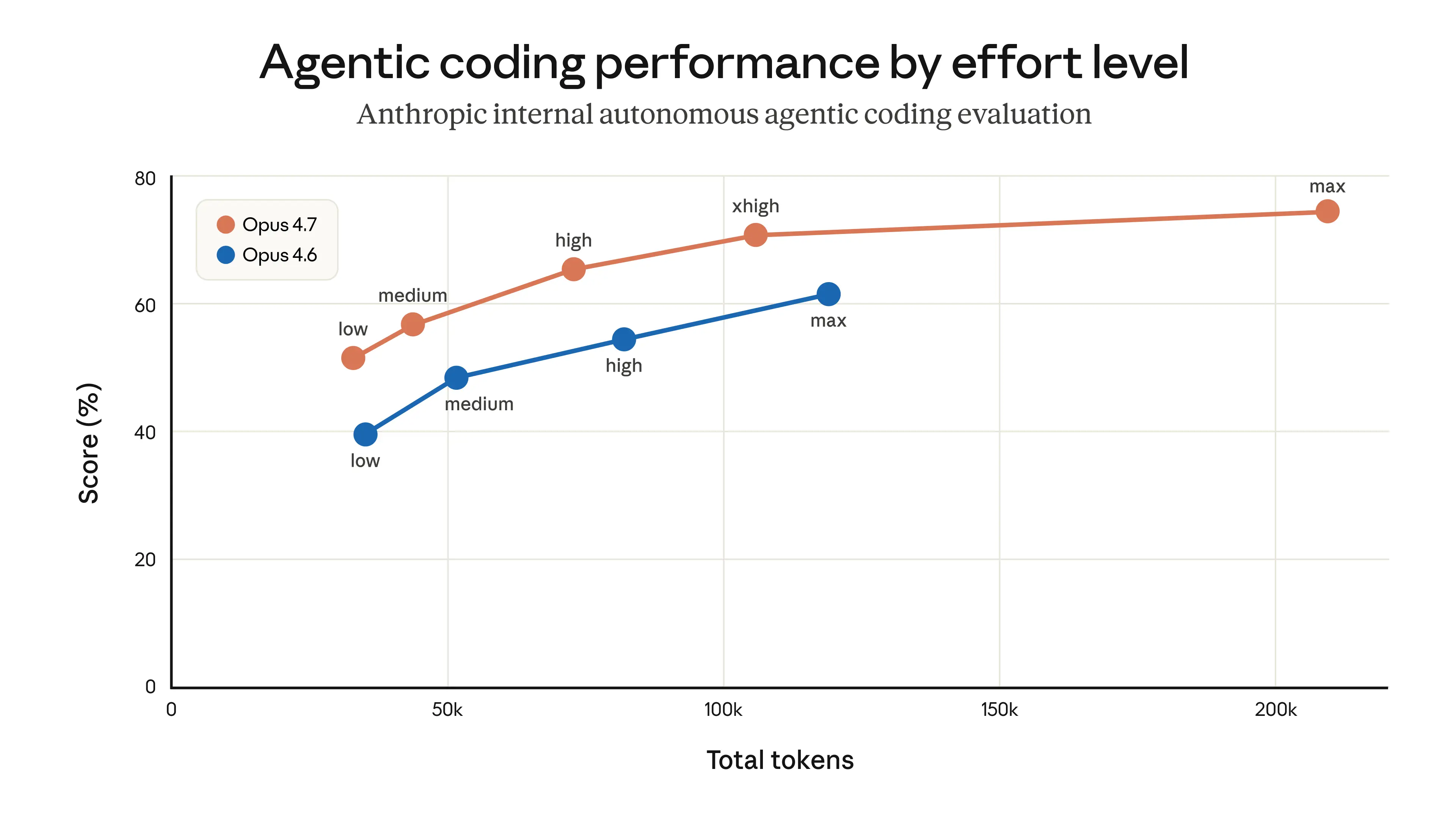
内部評価やテストでは、中程度の努力レベルは大半のタスクにおいてやや知能スコアが低くなるものの、レイテンシを大幅に短縮できました。また、思考プロセスにおける稀な長時間の遅延という問題も発生せず、ユーザーの使用制限を最大化するのに役立ちました。この結果、「medium」をデフォルトの努力レベルとする変更を展開し、その根拠を製品内のダイアログを通じて説明しました。
展開直後、ユーザーからClaude Codeが知能レベルが低いと感じられるとの報告が始まりました。私たちは現在の努力レベル設定を明確にするためのデザイン反復をいくつかリリースし、ユーザーがデフォルトを変更できることを通知しました(起動時の通知、インラインの努力レベルセレクター、および「ultrathink」機能の復活)。しかし、大多数のユーザーは中程度の努力レベルをデフォルトとして維持しました。
さらに多くの顧客からのフィードバックを聴取した後、私たちは4月7日にこの決定を取り消しました。現在、すべてのユーザーはOpus 4.7に対して「xhigh」努力レベルを、その他のモデルには「high」努力レベルをデフォルトとして適用しています。
以前の推論プロセスが削除されたキャッシュ最適化
Claudeがタスクに対して推論を行う際、その推論プロセスは通常会話履歴に保持され、以降のすべてのターンにおいてClaudeがどのような編集やツール呼び出しを行ったか、そしてなぜそれらを行ったのかを確認できるようになっています。
3月26日、私たちはこの機能に対する効率化改善として意図されたものをリリースしました。プロンプトキャッシングを活用し、連続するAPI呼び出しをユーザーにとってより安価かつ高速にしています。ClaudeはAPIリクエストを送信する際に入力トークンをキャッシュに書き込み、一定期間のアイドル状態が続くとプロンプトがキャッシュから削除され、他のプロンプトのための領域が確保されます。キャッシュの利用率は慎重に管理しています(私たちのアプローチに関する詳細はこちら)。
設計はシンプルであるべきでした:セッションが1時間以上アイドル状態の場合、古い「思考」セクションを削除することで、そのセッションの再開にかかるユーザーのコストを削減できます。リクエストはそもそもキャッシュミスになるため、APIに送信される未キャッシュトークンの数を減らすために、リクエストから不要なメッセージを削除できます。その後、完全な推論履歴の送信を再開します。これを行うために、私たちは clear_thinking_20251015 というAPIヘッダーと keep:1 を使用しました。
実装にバグがありました。思考履歴を1回だけクリアするはずが、セッションの残りすべてのターンでクリアしていました。一度アイドル閾値を超えたセッションでは、そのプロセス内の各リクエストがAPIに対して最新の推論ブロックのみを保持し、それ以前のすべてを破棄するよう指示しました。これが複合的に作用し、Claudeがツール使用の途中である間にフォローアップメッセージを送信すると、壊れたフラグの下で新しいターンが始まり、現在のターンの推論さえもドロップされました。Claudeは実行を続けますが、なぜその行動を選んだかの記憶 increasingly 失われながら動作しました。これが人々が報告した忘却、反復、および奇妙なツール選択として現れました。
このバグにより後続のリクエストから思考ブロックが継続的にドロップされたため、それらのリクエストはキャッシュミスも引き起こしました。これが、予期せず使用制限が早く枯渇するという別の報告を駆り立てたものだと考えています。
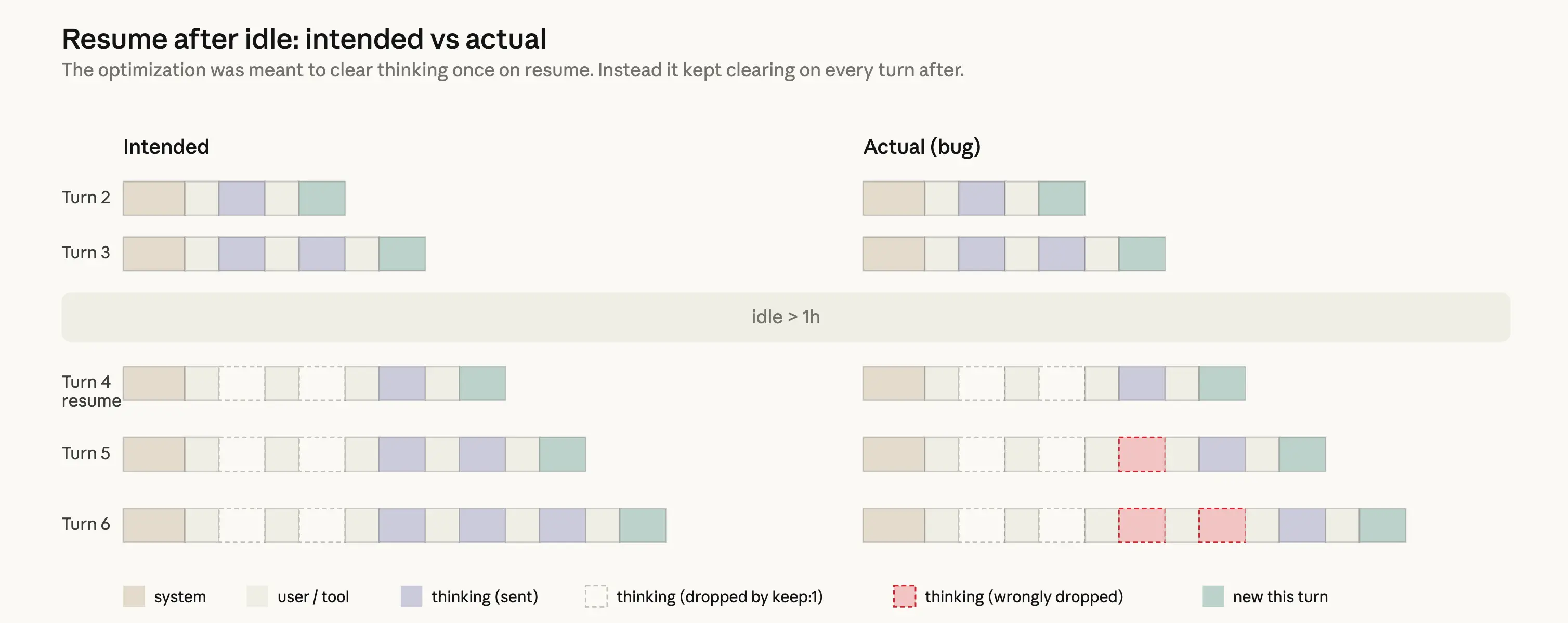
2つの無関係な実験により、当初は問題の再現が困難でした。1つはメッセージキューイングに関連する内部限定のサーバーサイド実験、もう1つは思考を抑制する方法に関する直交する変更でした。この変更により、ほとんどのCLIセッションでこのバグが抑制されたため、外部ビルドをテストしている際にも見逃しました。
このバグは、Claude Code のコンテキスト管理、Anthropic API、そして拡張思考(extended thinking)の交差点に位置していました。このバグがもたらした変更は、複数の人間によるおよび自動化されたコードレビュー、ユニットテスト、エンドツーエンドテスト、自動検証、そして社内製品化(dogfooding)を通過しました。これに加えて、この事象が限られたケース(セッションの陳腐化)でのみ発生し、問題の再現が困難だったため、根本原因を発見して確認するまでに 1 週間以上を要しました。
調査の一環として、Opus 4.7 を使用して Code Review を問題のあるプルリクエストに対してバックテストしました。完全なコンテキストを収集するために必要なコードレポジトリが提供された場合、Opus 4.7 はこのバグを検出しましたが、Opus 4.6 は検出しませんでした。このような事態の再発を防ぐため、私たちは現在、コードレビューのコンテキストとして追加のレポジトリをサポートする変更を適用しています。
このバグは 4 月 10 日に v2.1.101 で修正されました。
冗長性を軽減するためのシステムプロンプトの変更
最新のモデルである Claude Opus 4.7 は、その前身と比較して顕著な動作上の癖を持っています。私たちはローンチ時に 記述した 通り、非常に冗長になりやすい傾向があります。これにより難しい問題に対しては賢明な振る舞いをしますが、より多くの出力トークンを生成することにもなります。
Opus 4.7 のリリース数週間前、私たちは準備として Claude Code の調整を開始しました。各モデルはわずかに異なる振る舞いをするため、私たちはリリースごとにハルネスと製品を最適化する時間を費やしています。
冗長さを抑えるためのツールをいくつか用意しています。モデルのトレーニング、プロンプト設計、製品内の思考 UX の改善です。最終的にこれらすべてを活用しましたが、システムプロンプトへの1つの追加が Claude Code の知能に極めて大きな影響を与えました。
「長さの制限:ツール呼び出し間のテキストは25語以下に、最終応答は100語以下にしてください(ただし、タスクにより詳細な説明が必要な場合は除く)」
内部テストを数週間行い、実施した一連の評価で後退(性能低下)が見られなかったため、この変更に対する自信を深め、4月16日に Opus 4.7 とともにリリースしました。
この調査の一環として、より広範な評価セットを用いて、さらに多くのアブレーション(システムプロンプトから各行を削除し、各行の影響を理解するための手法)を実行しました。そのうち1つの評価では、Opus 4.6 と 4.7 の両方で3%の性能低下が確認されました。そのため、4月20日のリリースにおいて直ちにプロンプトを元に戻しました。
今後の対応
これらの問題を回避するため、私たちはいくつかの点を変更して取り組みます。具体的には、新機能のテストに使用しているバージョンではなく、Claude Code の正確な公開ビルドを内部スタッフのより大きな割合が使用するよう保証します。また、社内で使用している Code Review ツールを改善し、その改良版を顧客向けにリリースします。
また、システムプロンプトの変更に対するより厳格な制御も導入しています。Claude Code におけるすべてのシステムプロンプト変更に対して、モデルごとの広範な評価スイートを実行し、各行の影響を理解するためのアブレーション(ablation)を継続するとともに、プロンプト変更のレビューと監査を容易にするための新しいツールも構築しました。さらに、CLAUDE.md へのガイダンスを追加し、モデル固有の変更が対象とする特定のモデルに限定されるようにしています。知能(インテリジェンス)とトレードオフになる可能性のある変更については、ソーク期間(soak periods)、より広範な評価スイート、段階的なロールアウトを追加し、早期に問題を検出できるようにしています。
最近、X(旧 Twitter)上で @ClaudeDevs を作成し、製品決定とその背景にある理由を深く説明する余地を確保しました。GitHub 上の集中型スレッドでも、同じ更新情報を共有していきます。
最後に、ユーザーの皆様に感謝申し上げます。/feedback コマンドを使用して問題を共有してくれた方々(またはオンライン上で具体的かつ再現可能な例を投稿してくれた方々)のおかげで、これらの問題を特定し修正することが可能になりました。本日、すべてのサブスクライバーの使用制限をリセットいたします。
皆様からのフィードバックとご忍耐に、心より感謝申し上げます。
原文を表示
Over the past month, we’ve been looking into reports that Claude’s responses have worsened for some users. We’ve traced these reports to three separate changes that affected Claude Code, the Claude Agent SDK, and Claude Cowork. The API was not impacted.
All three issues have now been resolved as of April 20 (v2.1.116).
In this post, we explain what we found, what we fixed, and what we’ll do differently to ensure similar issues are much less likely to happen again.
We take reports about degradation very seriously. We never intentionally degrade our models, and we were able to immediately confirm that our API and inference layer were unaffected.
After investigation, we identified three different issues:
- On March 4, we changed Claude Code's default reasoning effort from high to medium to reduce the very long latency—enough to make the UI appear frozen—some users were seeing in high mode. This was the wrong tradeoff. We reverted this change on April 7 after users told us they'd prefer to default to higher intelligence and opt into lower effort for simple tasks. This impacted Sonnet 4.6 and Opus 4.6.
- On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive. We fixed it on April 10. This affected Sonnet 4.6 and Opus 4.6.
- On April 16, we added a system prompt instruction to reduce verbosity. In combination with other prompt changes, it hurt coding quality and was reverted on April 20. This impacted Sonnet 4.6, Opus 4.6, and Opus 4.7.
Because each change affected a different slice of traffic on a different schedule, the aggregate effect looked like broad, inconsistent degradation. While we began investigating reports in early March, they were challenging to distinguish from normal variation in user feedback at first, and neither our internal usage nor evals initially reproduced the issues identified.
This isn’t the experience users should expect from Claude Code. As of April 23, we’re resetting usage limits for all subscribers.
A change to Claude Code's default reasoning effort
When we released Opus 4.6 in Claude Code in February, we set the default reasoning effort to high.
Soon after, we received user feedback that Claude Opus 4.6 in high effort mode would occasionally think for too long, causing the UI to appear frozen and leading to disproportionate latency and token usage for those users.
In general, the longer the model thinks, the better the output. Effort levels are how Claude Code lets users set that tradeoff—more thinking versus lower latency and fewer usage limit hits. As we calibrate effort levels for our models, we take this tradeoff into account in order to pick points along the test-time-compute curve that give people the best range of options. In the product layer, we then choose which point along this curve we set as our default, and that is the value we send to the Messages API as the effort parameter; we then make the other options available via /effort.
In our internal evals and testing, medium effort achieved slightly lower intelligence with significantly less latency for the majority of tasks. It also didn’t suffer from the same issues with occasional very long tail latencies for thinking, and it helped maximize users’ usage limits. As a result, we rolled out a change making medium the default effort, and explained the rationale via in-product dialog.
Soon after rolling out, users began reporting that Claude Code felt less intelligent. We shipped a number of design iterations to make the current effort setting clearer in order to alert people they could change the default (notices on startup, an inline effort selector, and bringing back ultrathink), but most users retained the medium effort default.
After hearing feedback from more customers, we reversed this decision on April 7. All users now default to xhigh effort for Opus 4.7, and high effort for all other models.
A caching optimization that dropped prior reasoning
When Claude reasons through a task, that reasoning is normally kept in the conversation history so that on every subsequent turn, Claude can see why it made the edits and tool calls it did.
On March 26, we shipped what was meant to be an efficiency improvement to this feature. We use prompt caching to make back-to-back API calls cheaper and faster for users. Claude writes the input tokens to the cache when it makes an API request, then after a period of inactivity the prompt is evicted from cache, making room for other prompts. Cache utilization is something we manage carefully (more on our approach).
The design should have been simple: if a session has been idle for more than an hour, we could reduce users’ cost of resuming that session by clearing old thinking sections. Since the request would be a cache miss anyway, we could prune unnecessary messages from the request to reduce the number of uncached tokens sent to the API. We’d then resume sending full reasoning history. To do this we used the clear_thinking_20251015 API header along with keep:1.
The implementation had a bug. Instead of clearing thinking history once, it cleared it on every turn for the rest of the session. After a session crossed the idle threshold once, each request for the rest of that process told the API to keep only the most recent block of reasoning and discard everything before it. This compounded: if you sent a follow-up message while Claude was in the middle of a tool use, that started a new turn under the broken flag, so even the reasoning from the current turn was dropped. Claude would continue executing, but increasingly without memory of why it had chosen to do what it was doing. This surfaced as the forgetfulness, repetition, and odd tool choices people reported.
Because this would continuously drop thinking blocks from subsequent requests, those requests also resulted in cache misses. We believe this is what drove the separate reports of usage limits draining faster than expected.
Two unrelated experiments made it challenging for us to reproduce the issue at first: an internal-only server-side experiment related to message queuing; and an orthogonal change in how we display thinking suppressed this bug in most CLI sessions, so we didn’t catch it even when testing external builds.
This bug was at the intersection of Claude Code’s context management, the Anthropic API, and extended thinking. The changes it introduced made it past multiple human and automated code reviews, as well as unit tests, end-to-end tests, automated verification, and dogfooding. Combined with this only happening in a corner case (stale sessions) and the difficulty of reproducing the issue, it took us over a week to discover and confirm the root cause.
As part of the investigation, we back-tested Code Review against the offending pull requests using Opus 4.7. When provided the code repositories necessary to gather complete context, Opus 4.7 found the bug, while Opus 4.6 didn't. To prevent this from happening again, we are now landing support for additional repositories as context for code reviews.
We fixed this bug on April 10 in v2.1.101.
A system prompt change to reduce verbosity
Our latest model, Claude Opus 4.7, has a notable behavioral quirk relative to its predecessor: as we wrote about at launch, it tends to be quite verbose. This makes it smarter on hard problems, but it also produces more output tokens.
A few weeks before we released Opus 4.7, we started tuning Claude Code in preparation. Each model behaves slightly differently, and we spend time before each release optimizing the harness and product for it.
We have a number of tools to reduce verbosity: model training, prompting, and improving thinking UX in the product. Ultimately we used all of these, but one addition to the system prompt caused an outsized effect on intelligence in Claude Code:
“Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.”
After multiple weeks of internal testing and no regressions in the set of evaluations we ran, we felt confident about the change and shipped it alongside Opus 4.7 on April 16.
As part of this investigation, we ran more ablations (removing lines from the system prompt to understand the impact of each line) using a broader set of evaluations. One of these evaluations showed a 3% drop for both Opus 4.6 and 4.7. We immediately reverted the prompt as part of the April 20 release.
Going forward
We are going to do several things differently to avoid these issues: we’ll ensure that a larger share of internal staff use the exact public build of Claude Code (as opposed to the version we use to test new features); and we'll make improvements to our Code Review tool that we use internally, and ship this improved version to customers.
We’re also adding tighter controls on system prompt changes. We will run a broad suite of per-model evals for every system prompt change to Claude Code, continuing ablations to understand the impact of each line, and we have built new tooling to make prompt changes easier to review and audit. We've additionally added guidance to our CLAUDE.md to ensure model-specific changes are gated to the specific model they're targeting. For any change that could trade off against intelligence, we'll add soak periods, a broader eval suite, and gradual rollouts so we catch issues earlier.
We recently created @ClaudeDevs on X to give us the room to explain product decisions and the reasoning behind them in depth. We'll share the same updates in centralized threads on GitHub.
Finally, we’d like to thank our users: the people who used the /feedback command to share their issues with us (or who posted specific, reproducible examples online) are the ones who ultimately allowed us to identify and fix these problems. Today we are resetting usage limits for all subscribers.
We’re immensely grateful for your feedback and for your patience.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み