言語モデルの較正に関する深掘り:プラットスケーリング、等温回帰、温度スケーリング
この記事は、大規模言語モデル(LLM)の信頼性スコアと実際の正答率の乖離という深刻な問題を取り上げ、Platt Scaling や温度調整といった古典的な校正手法を LLM に適用する際の重要性と課題を詳述している。
キーポイント
LLM の校正不全(Miscalibration)の実態
2024 年の NAACL サベイや生体医学モデルに関する研究により、LLM の自信スコアが実際の正答率と大きく乖離していることが示されており、このギャップは事実確認、コード生成、推論タスク全般にわたって一貫して存在する。
校正の評価指標:ECE と信頼性図
モデルの信頼性を定量化するために、予測を自信度でビン分けし平均自信度と観測された精度の差を計算する「Expected Calibration Error (ECE)」が主要な指標として採用されている。
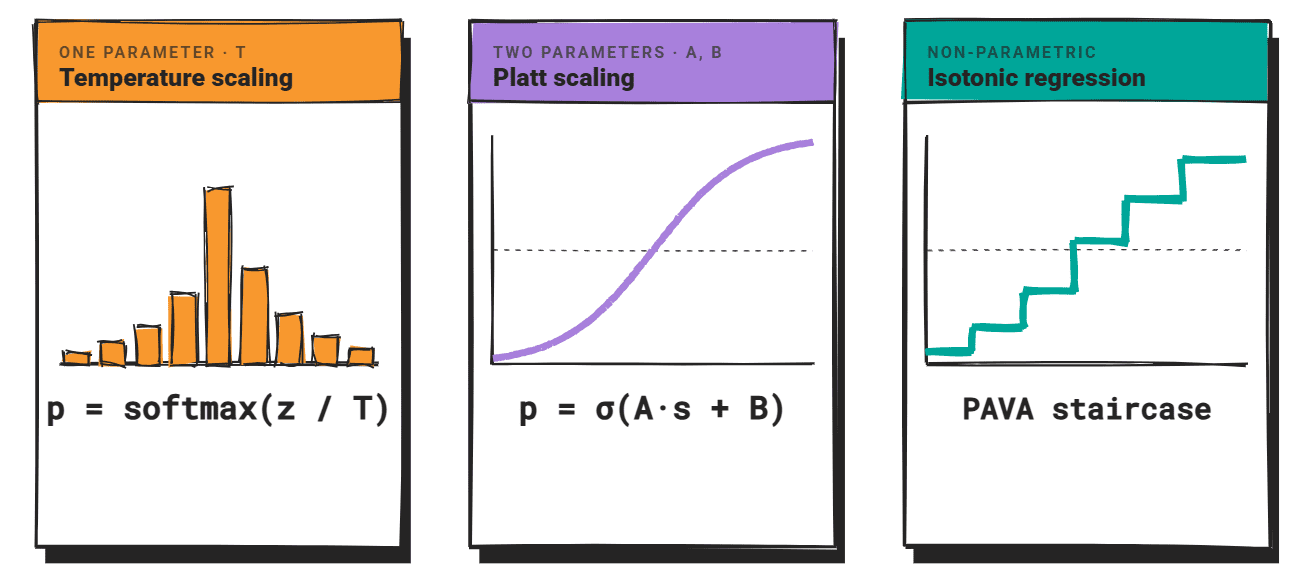
3 つの主要な校正手法
古典的機械学習から派生した「温度調整(Temperature Scaling)」、「Platt スケーリング」、および「等方回帰(Isotonic Regression)」が、LLM のスコアをより信頼性の高い確率に変換するための標準的な事後処理手法として紹介されている。
判別器向け手法の LLM への適用
これら校正手法は元々判別型分類器のために設計されたものであり、生成モデルである LLM に適用する際には注意深い検討と調整が必要であると指摘されている。
ECE の計算と限界
Expected Calibration Error (ECE) は予測の信頼性バインごとの平均信頼度と実際の精度の差を重み付き平均した指標ですが、単一の数値ではモデルがどこでどのように誤動作するかという詳細な変動を捉えきれないため、他の指標との併用が推奨されています。
過信のパターンと評価
GPT-4o-mini の評価ではエラーの約 67% が 80% 以上の高い信頼度で発生しており、これは典型的な「過信」のパターンを示しています。
包括的な評価指標の推奨
ECE だけでなく、Brier スコア、過信率、および信頼性ダイアグラムを組み合わせて使用することで、モデルのキャリブレーション状態をより多角的に把握できます。
影響分析・編集コメントを表示
影響分析
本記事は、LLM の実装・運用において「自信度スコア」を盲信しないよう警告し、専門的な校正手法の導入が不可欠であることを示唆しています。開発者やエンジニアにとって、モデルの信頼性を数値化して改善する具体的な技術的アプローチ(ECE や温度調整など)を理解することは、生産環境での LLM 活用リスクを低減するために極めて重要です。
編集コメント
LLM の「自信度」というパラメータが実態と乖離しているという事実は、多くの現場で見過ごされがちですが、本記事はその深刻さと解決策を明確に提示しています。技術的な深掘りが必要な開発者や研究者にとって、モデルの信頼性を高めるための基礎知識として非常に価値が高い内容です。
 image**
image**
# イントロダクション
90% の自信を持っていると主張するモデルは、実際には 90% の確率で正解であるべきです。この関係性が崩れると、不適合(miscalibration)という問題が発生します。モデルのスコアはもはや信頼性に関する有用な情報を伝えなくなります。
大規模言語モデル(LLMs)においては、不適合が広く見られます。2024 NAACL 調査では、事実確認 QA、コード生成、推論タスク全体にわたって、自信スコアと実際の正答率が乖離していることが示されました。
別の研究では、生体医学モデルを対象に調査が行われ、テストされたすべてのモデルで平均適合度スコアが 23.9% から 46.6% の範囲にあることが判明しました。このギャップは一定しています。
古典的機械学習における標準的な解決策は、事後再適合(post-hoc recalibration)です。これは、保持された検証セット上で単純な関数をフィットさせ、生の自信スコアをより適切に適合した確率値に変換する手法です。
3 つの手法が主流です:温度スケーリング、プラット・スケーリング、および等回帰回帰です。これら 3 つはすべて判別型分類器のために設計されたものであり、大規模言語モデル(LLM)に適用する際には注意が必要です。
**
# 校正の測定
主流となる指標は期待校正誤差(ECE)です。これは予測を信頼性ビンにグループ化し、各ビンにおける平均信頼性と観測された精度の差を計算し、ビンのサイズで重み付けして平均化したものです。ECE が 0 の場合が完全な校正状態となります。
信頼性図は、信頼性と精度をプロットしたものです。完全に校正されたモデルは対角線上に位置します。過信しているモデルはその下に位置し、曲線は高い信頼性を示しますが、精度がそれに追いついていません。
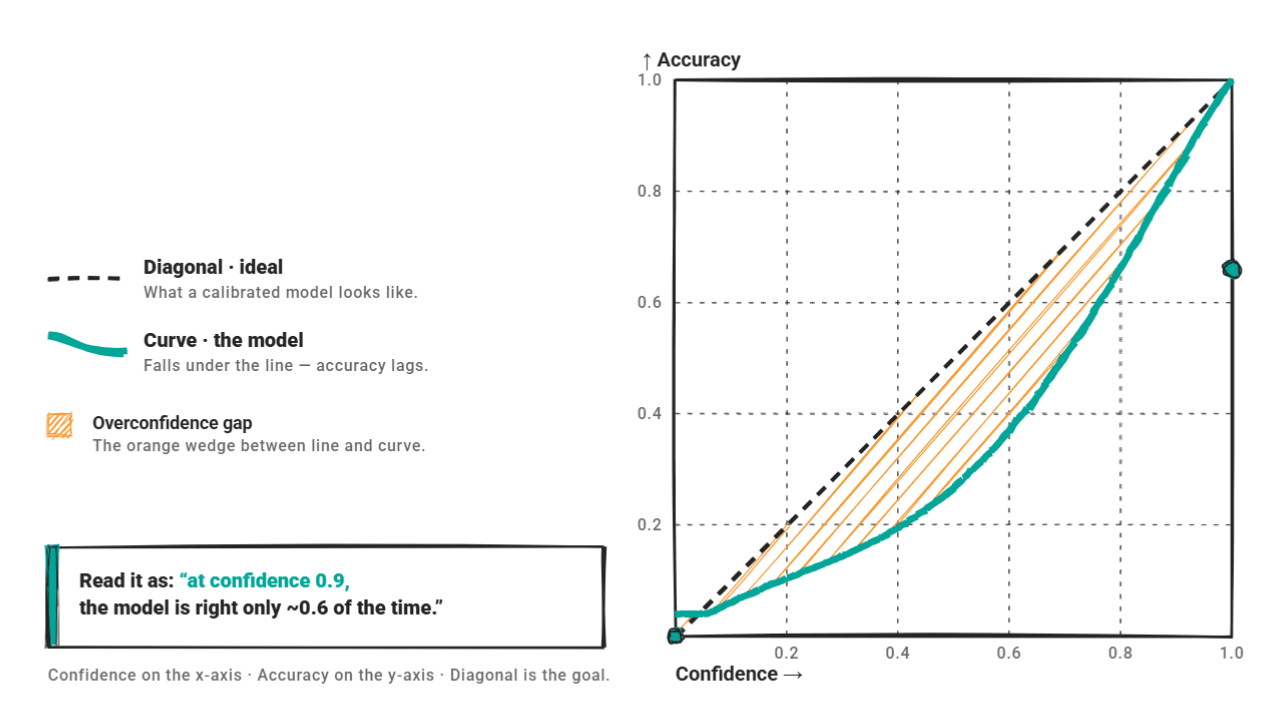
GPT-4o-mini をテキスト分類器として評価した 2025 年の調査では、その誤りの 66.7% が 80% 以上の信頼度で発生しており、これは典型的な過信のパターンです。
ECE(Expected Calibration Error)のみでは不十分と見なされるケースが増えています。ある 研究論文 では、ECE に ブリアー・スコア、過信率、および信頼度図を組み合わせることを推奨しています。単一の数値では、モデルがどこでどのように誤動作するかという意味のある変動を隠してしまいます。
# なぜ LLM は標準的な設定を複雑にするのか
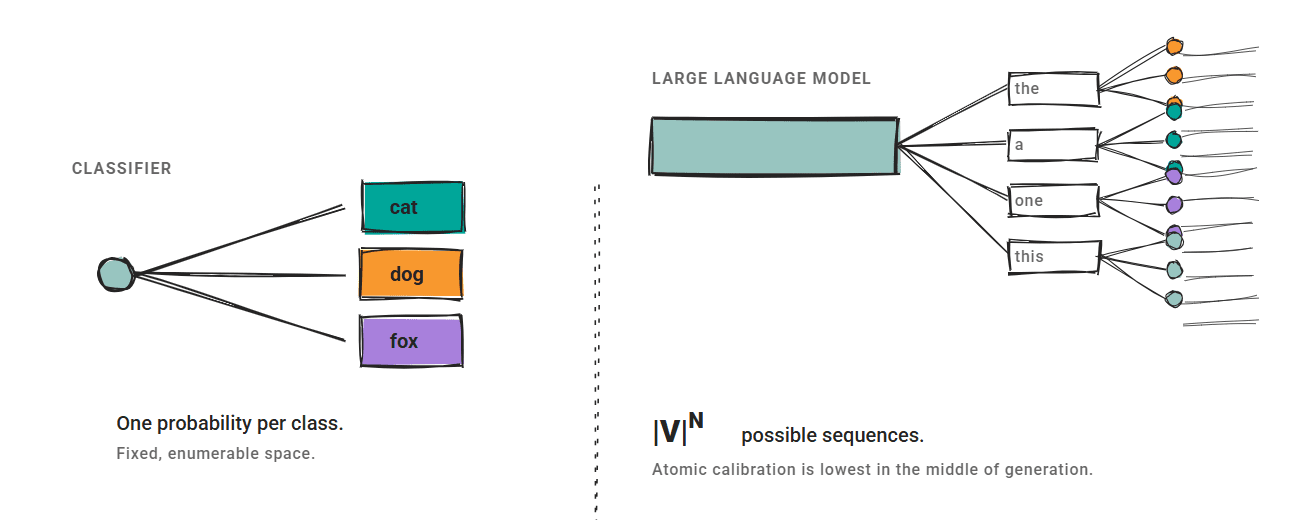
私たちが取り上げる 3 つの方法は、固定された出力空間を前提としています。分類器は各クラスに対して確率**を 1 つ生成し、キャリブレーション(較正)によってより良い推定値へとマッピングします。
LLM(大規模言語モデル)はこのように動作しません。
ここでは 4 つの複雑さが重要です。
**
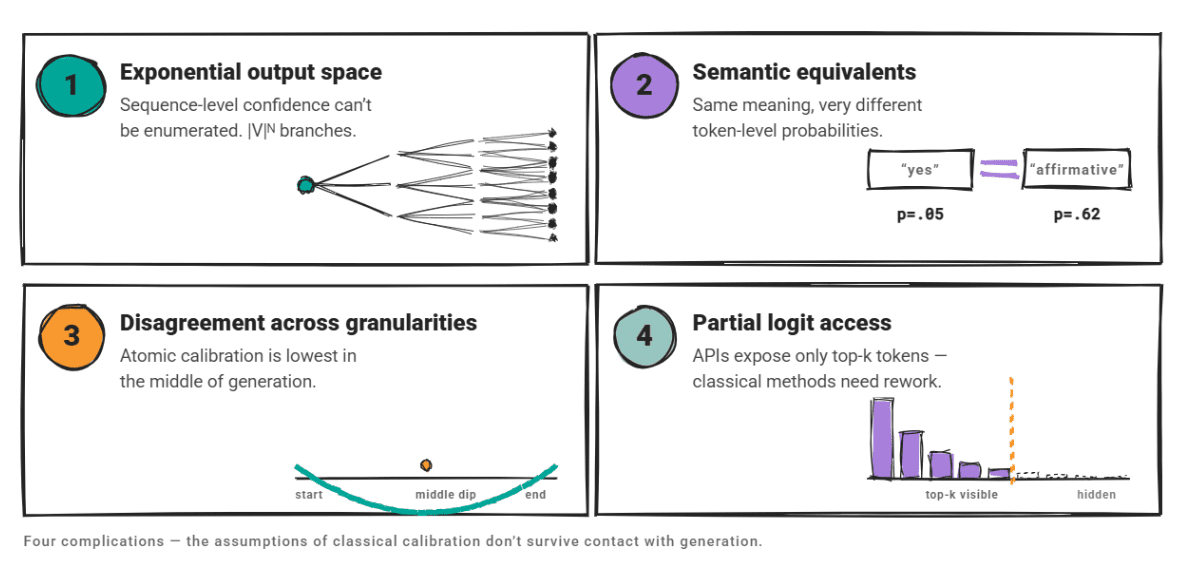
出力空間は指数関数的に膨大であり、シーケンスレベルでの信頼度を列挙することはできません。意味的に同等な出力であっても、トークンレベルの確率は大きく異なる可能性があります。信頼性は粒度によって不一致を示します。原子較正に関する 研究論文 では、生成モデルが最も低い平均信頼度を示すのは生成の開始時や終了時ではなく、中間部分であることが示されています。
多くの大規模言語モデル(LLM)は、API を通じてトップ k トークンの確率のみを公開しているため、完全なロジットへのアクセスを前提とする古典的な較正手法には修正が必要となります。
# 温度スケーリングの適用
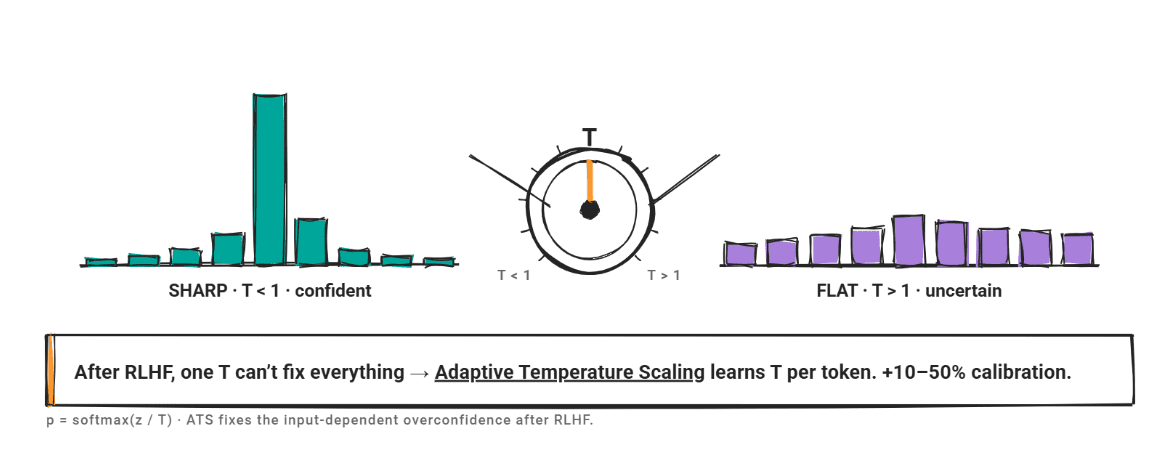
温度スケーリングでは、ソフトマックス関数を適用する前にロジットベクトルをスカラー値 T で割ります。T > 1 の場合、分布は平坦化し信頼度は低下します。一方、T < 1 の場合、分布は鋭くなり信頼度は上昇します。
T は、ネガティブ対数尤度(negative log-likelihood)を最小化することで、保持された検証セット上で最適化されます。この手法はパラメータを 1 つ追加するだけで予測の順位を保ち、計算コストも低く抑えられます。
元の定式化 は DenseNet 画像分類器を対象としていましたが、LLM においては温度が各デコーディングステップにおける語彙全体に対する確率分布を制御するため、同じ論理が適用されます。
問題は 人間のフィードバックからの強化学習(RLHF)です。RLHF を経たモデルは入力依存型の過信を示すようになります:較正のズレの程度が入力によって異なり、単一の T 値ではその変動を説明することができません。
GPT-3 などのモデルにおける言語化された信頼性タスクでは、平均 ECE スコアが 0.377 を上回る事例が報告されており、2025 年の調査は、RLHF(人間フィードバックによる強化学習)で調整されたモデルが一貫して全体的に信頼性を過大評価していることを確認しています。
適応温度スケーリング(ATS: Adaptive Temperature Scaling)は、これを直接的に解決します。ATS は、単一の固定された T を使用するのではなく、トークンレベルの隠れ特徴からトークンごとの温度を予測し、教師あり微調整データセット上でフィットさせます。研究者らは、ATS がタスク性能を損なうことなく、較正(calibration)を 10〜50% 改善したことを確認しました。RLHF で調整されたモデルであれば、ATS は標準的な温度スケーリングよりも強力なベースラインとなります。
標準的な温度スケーリングは、RLHF 前のベースモデルにおいては依然としてよく機能します。較正のズレが入力全体にほぼ均一である場合、単一の T を用いることで体系的な過大評価または過小評価を修正できることがほとんどです。
問題は、入力依存性の高い過大評価が生じる RLHF 後のモデルに特有のものであり、この場合、単一の T ではすべての入力を修正することができません。
プラットスケーリングの適用
プラットスケーリングは、較正されていないスコアに対してロジスティック関数をフィットさせます:p = σ(A·s + B)。ここで A と B は、二値の正誤ラベルを持つホールドアウト検証セットから学習されます。
シグモイド形状により、2 つの自由パラメータを持つパラメトリックなマッピングが得られます。
プラットスケーリングは元々 SVM(サポートベクトルマシン)のために開発されましたが、スカラーな信頼性スコアを生成するあらゆるシステムに一般化可能です。
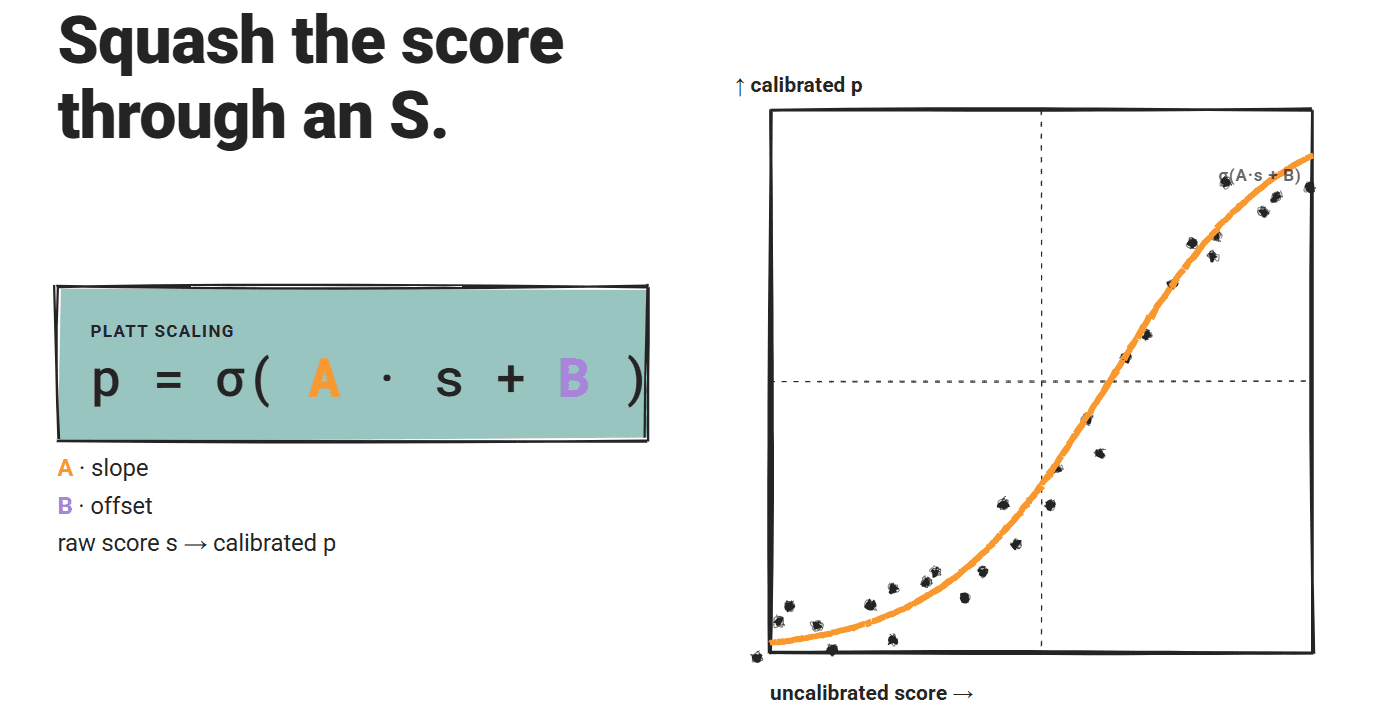
2 パラメータフィットは、等圧回帰と比較してデータ効率的であり、より小さな校正セットから実用的な推定値を生成できます。これは、ラベル付きの正解データが限られている展開環境において重要です。
大規模言語モデル(LLM)の文脈では、プラットスケーリングはシーケンスレベルまたはトークンレベルの信頼度スコアに対して機能します。
LLM 生成コードの信頼性に関する論文 paper では、プラットスケーリングが未校正スコアよりも較正された出力を生成することが示されています。また、テキストから SQL への LLM に関する別の研究では、多変量プラットスケーリング(MPS)が導入され、単一変数のプラットスケーリングを拡張して、複数の生成サンプルにわたるサブ節の頻度スコアを組み合わせることで、単一スコアのベースラインを一貫して上回る結果を示しました。
2 つの限界**が文書化されています。第一に、グローバルなシーケンスレベルのプラットスケーリングは、正解性が局所的な編集決定に依存するタスクには粗すぎます。1 つのシグモイド変換では、サンプル固有の較正外れパターンを捉えることができません。
さらに、プラットスケーリングは強力なモデルにおいて適格スコアリング性能を低下させる可能性があります。
# 等圧回帰の適用
**
等圧回帰は非パラメトリックなアプローチを採用します。
これは、Pool Adjacent Violators Algorithm(PAVA)を用いて、不確実なスコアから補正済み確率への、ピースワイズ定数かつ単調非減少するマッピングを学習します。補正関数の形状には仮定が置かれていないため、信頼度と精度の関係がシグモイド状でない場合、プラットスケーリングよりも柔軟性が高く機能します。
ピースワイズ定数の出力は、線形、階段状、あるいは凹型など、あらゆる単調な形状に適応します。この適応性が、実証比較において等圧回帰(isotonic regression)がプラットスケーリングを上回る主な理由です。
その代償として、小規模な補正セットでは過学習のリスクがあります。このマッピングが良好に一般化するためには、それを制約する十分なデータが必要です。
実証的に、等圧回帰はプラットスケーリングよりも優れた結果を示します。
複数のデータセットとアーキテクチャにわたる厳密な比較において、等圧回帰はボンフェローニ補正を適用したペア付き t 検定(α = 0.003)を用いた結果、ECE とブリアースコアにおいてプラットスケーリングを統計的に有意に上回ることが示されました。
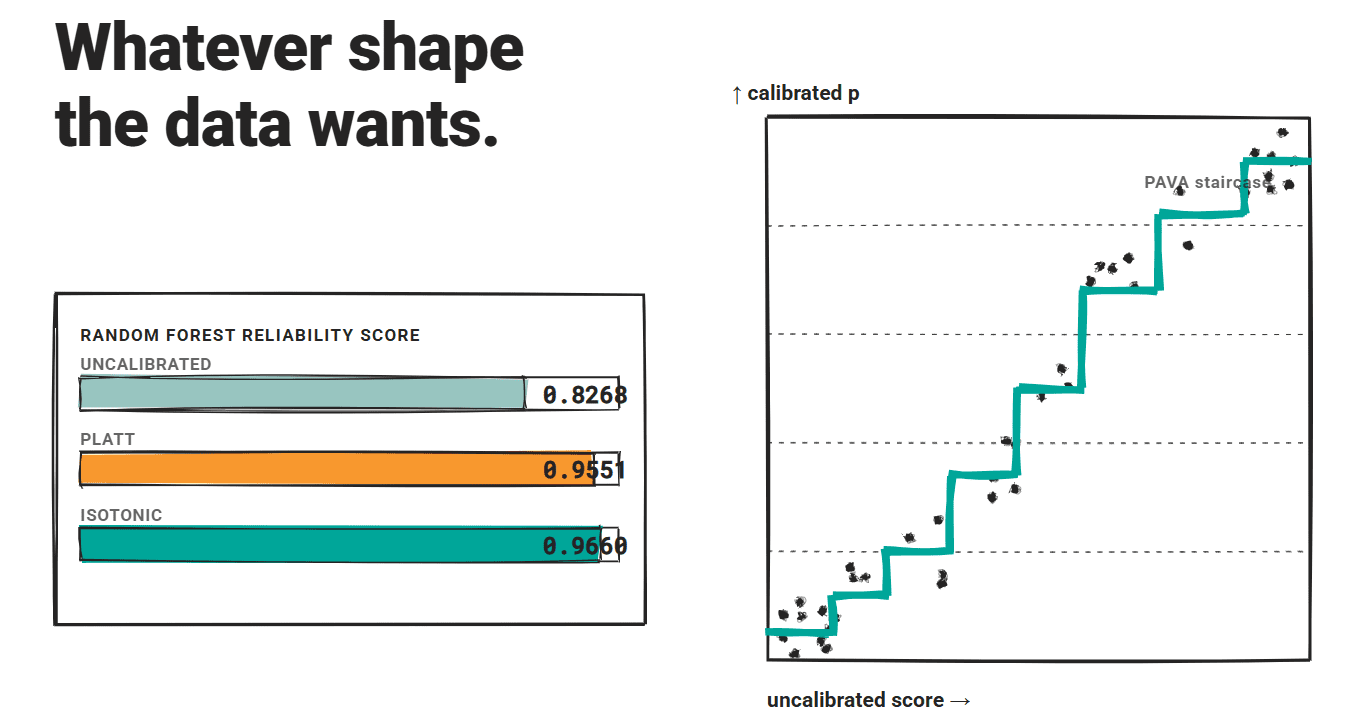
その研究では、ランダムフォレストのベースラインが、補正前では信頼性スコア 0.8268 から、プラットスケーリング適用で 0.9551 に向上し、等圧回帰適用ではさらに 0.9660 となりました。両手法とも強力なモデルに対しては適格スコア性能を低下させる可能性がありますが、等圧回帰による優位性は一貫して維持されました。
LLM の多クラス設定においては、標準的な等回帰(isotonic regression)を正規化対応拡張によってさらに改善でき、NLL および ECE において OvR 等回帰や標準のパラメトリック手法を一貫して上回る結果が示されています。
データ要件が制約条件となります。等回帰の利点は確かに存在しますが、これは低データ量での展開シナリオには転移しません。
# 文献が残した課題
これらの方法を導入する前に、3 つのギャップ(gap)を指摘しておく価値があります。
RLHF(Reinforcement Learning from Human Feedback:人間フィードバックからの強化学習)との相互作用は温度スケーリング(temperature scaling)についてのみ研究されています。Platt スケーリングや等回帰が RLHF 後のモデルでどのように機能するかについては、体系的なテストが行われていません。ATS は標準的な温度スケーリングがこのケースに対して明示的な修正を必要としたために存在します。他の2つの手法にも同様の拡張が必要かどうかは未解決の問いです。
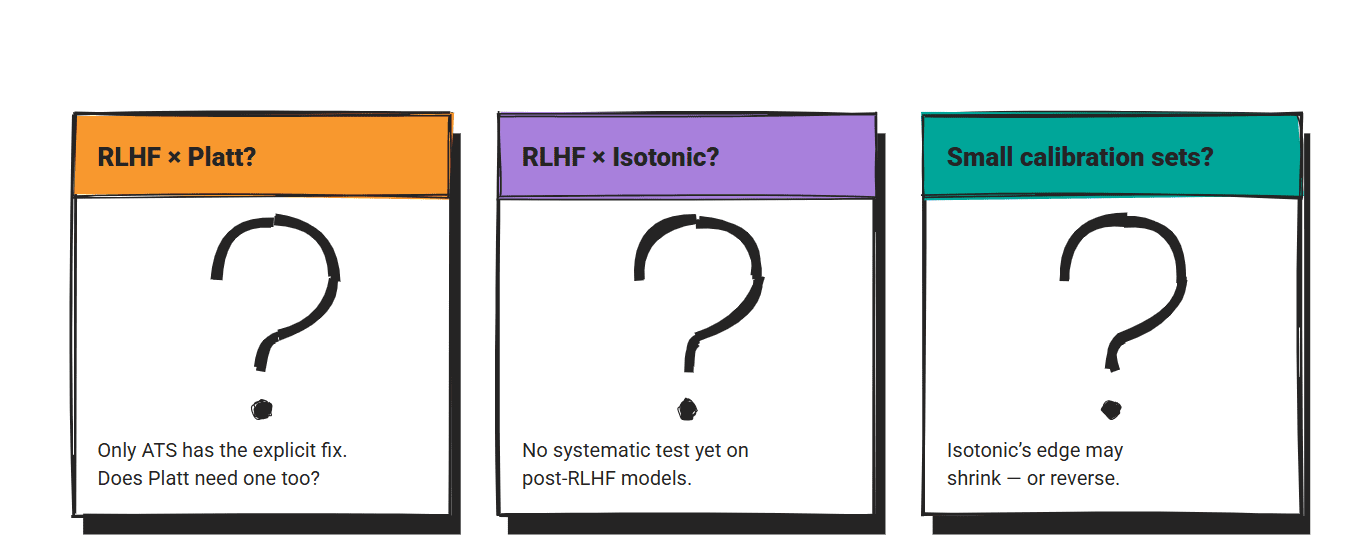
3 つの方法すべてを直接比較した研究の多くは、一般的な機械学習の校正(calibration)文献に由来しています。これら 3 つを頭突きでテストする LLM 固有のベンチマークは稀です。ICSE 2025 のコード校正に関する論文 paper はその数少ない例の一つですが、その範囲はコード生成に限定されています。
Calibration set size is a real deployment constraint. Isotonic regression results from papers assume datasets large enough to constrain the mapping. In production with limited labeled examples, the gap between isotonic regression and Platt scaling may close or reverse.
# Conclusion
**
Temperature scaling** is the right starting point for most teams. For base models without RLHF, a single T often does enough.
For RLHF-tuned models, switch to ATS: the per-token temperature handles the input-dependent overconfidence that a global scalar misses.
Platt scaling is the practical choice when the calibration set is small or when calibration needs to slot into a larger pipeline. It's data-efficient and straightforward to implement. The limitation is scope: it can't capture miscalibration that varies across samples, and it tends to degrade performance for strong models.
Isotonic regression has the strongest empirical track record of the three. Use it when the calibration set is large enough to constrain the mapping without overfitting, and pair it with normalization-aware extensions in multiclass settings.
これらすべての手法の前にある決断は、タスクにとって「信頼性(confidence)」が何を意味するかです。トークンの確率、シーケンスの確率、言語化された信頼性、そしてサンプル間の一貫性は、同じ出力に対して異なる値を与える可能性があります。誤った信号に適用される較正方法は信頼性を向上させません。上記の方法が機能するためには、この定義を正しく定めることが前提条件となります。
Nate Rosidi はデータサイエンティストであり、製品戦略に関わる専門家です。また、分析を教える非常勤教授でもあり、トップ企業からの実際の面接質問を用いてデータサイエンティストの面接準備をサポートするプラットフォーム「StrataScratch」の創設者でもあります。Nate はキャリア市場における最新動向について執筆し、面接に関するアドバイスを提供し、データサイエンスプロジェクトを紹介し、SQL 関連のあらゆるトピックをカバーしています。
原文を表示
**
# Introduction
A model that says it is 90% confident should be right 90% of the time. When that relationship breaks down, you get a miscalibration** problem. The model's scores stop telling you anything useful about reliability.
For large language models (LLMs), miscalibration is widespread. A 2024 NAACL survey found that confidence scores diverge from actual correctness rates across factual QA, code generation, and reasoning tasks.
Another study on biomedical models found mean calibration scores ranging from only 23.9% to 46.6% across all tested models. The gap is consistent.
The standard solution in classical machine learning is post-hoc recalibration: fit a simple function on a held-out validation set to map raw confidence scores to better-calibrated probabilities.
Three methods dominate: temperature scaling, Platt scaling, and isotonic regression. All three were designed for discriminative classifiers, and applying them to LLMs requires care.
**
# Measuring Calibration
The dominant metric is Expected Calibration Error (ECE). It groups predictions into confidence bins, computes the gap between mean confidence and the observed accuracy in each bin, and averages across bins weighted by size. ECE = 0 is perfect calibration.
A reliability diagram plots confidence against accuracy. A perfectly calibrated model sits on the diagonal. An overconfident model sits below it: the curve shows high confidence, but accuracy doesn't keep up.
A 2025 evaluation of GPT-4o-mini as a text classifier found that 66.7% of its errors occurred at over 80% confidence — the canonical overconfidence pattern.
ECE alone is increasingly viewed as insufficient. A research paper recommends pairing ECE with the Brier score, overconfidence rates, and reliability diagrams together. A single number obscures meaningful variation in where and how a model misbehaves.
# Why LLMs Complicate the Standard Setup
The three methods we cover assume a fixed output space. A classifier produces one probability** per class, and calibration maps them to better estimates.
LLMs don't work this way.
Four complications matter here.
**
The output space is exponentially large: sequence-level confidence can't be enumerated. Semantically equivalent outputs may have very different token-level probabilities. Confidence disagrees across granularities; a research paper on atomic calibration showed that generative models exhibit their lowest average confidence in the middle of generation, not at the start or end.
And many LLMs only expose top-k token probabilities through their API**, so classical calibration approaches that rely on full logit access need modification.
**
# Applying Temperature Scaling
Temperature scaling divides the logit vector by a scalar T before applying softmax. When T > 1, the distribution flattens and confidence drops. When T < 1, the distribution sharpens and confidence rises.
T is fit on a held-out validation set by minimizing negative log-likelihood. The method adds one parameter, preserves prediction rankings, and is cheap to compute.
The original formulation targeted DenseNet image classifiers. For LLMs, temperature controls the probability distribution over the vocabulary at each decoding step, so the same logic applies.
The problem is Reinforcement Learning from Human Feedback (RLHF). Post-RLHF models develop input-dependent overconfidence: the degree of miscalibration varies across inputs, and a single T can't account for that variation.
Average ECE scores above 0.377 have been documented for models like GPT-3 in verbalized confidence tasks, and a 2025 survey confirms that RLHF-tuned models consistently overestimate confidence across the board.
Adaptive Temperature Scaling (ATS) addresses this directly. ATS predicts a per-token temperature from token-level hidden features, fit on a supervised fine-tuning dataset, instead of using a single fixed T. Researchers confirmed that ATS improved calibration by 10–50% without hurting task performance. For any RLHF-tuned model, ATS is a stronger baseline than standard temperature scaling.
Standard temperature scaling still works well for base models before RLHF. When miscalibration is roughly uniform across inputs, a single T is often enough to correct systematic over- or underconfidence.
The problem is specific to post-RLHF models, where input-dependent overconfidence means a single T can't correct all inputs.
# Applying Platt Scaling
Platt scaling fits a logistic function over the uncalibrated scores: p = σ(A·s + B), where A and B are learned from a held-out validation set with binary correctness labels.
The sigmoid shape gives a parametric mapping with two free parameters.
Platt scaling was originally developed for SVMs but generalizes to any system that produces a scalar confidence score.
The two-parameter fit is also data-efficient compared to isotonic regression: it can produce usable estimates from a smaller calibration set, which matters in deployment contexts where labeled correctness data is limited.
In LLM contexts, Platt scaling operates over sequence-level or token-level confidence scores.
A paper on LLM-generated code confidence found that Platt scaling produced better-calibrated outputs than uncalibrated scores. Another study on LLMs for text-to-SQL introduced Multivariate Platt Scaling (MPS), extending single-variable Platt scaling to combine sub-clause frequency scores across multiple generated samples — consistently outperforming single-score baselines.
Two limitations** are documented. First, global sequence-level Platt scaling is too coarse for tasks where correctness depends on local edit decisions: a single sigmoid mapping can't capture sample-dependent miscalibration patterns.
Besides, Platt scaling can degrade proper scoring performance for strong models.
# Applying Isotonic Regression
**
Isotonic regression takes the non-parametric route.
It learns a piecewise-constant, monotonically non-decreasing mapping from uncalibrated scores to calibrated probabilities using the Pool Adjacent Violators Algorithm (PAVA). There's no assumed shape for the calibration function, which makes it more flexible than Platt scaling when the confidence-accuracy relationship isn't sigmoid-shaped.
The piecewise-constant output adapts to any monotone shape: linear, stepped, or concave. That adaptability is the main reason isotonic regression tends to outperform Platt scaling in empirical comparisons.
The cost is overfitting risk on small calibration sets. The mapping only generalizes well when there's enough data to constrain it.
Empirically, isotonic regression outperforms Platt scaling.
A rigorous comparison across multiple datasets and architectures found that isotonic regression beat Platt scaling on ECE and Brier score with statistical significance, using paired t-tests with Bonferroni correction at α = 0.003.
In that study, a Random Forest baseline improved from a reliability score of 0.8268 uncalibrated, to 0.9551 with Platt scaling, to 0.9660 with isotonic regression. Both methods could degrade proper scoring performance for strong models, but the isotonic edge held consistently.
For LLM multiclass settings, it has been shown that standard isotonic regression can be improved further with normalization-aware extensions, consistently outperforming both OvR isotonic regression and standard parametric methods on NLL and ECE.
The data requirement is the binding constraint. Isotonic regression's advantage is real, but it doesn't transfer to low-data deployment scenarios.
# What the Literature Leaves Open
Three gaps** are worth flagging before deploying any of these methods.
The RLHF interaction has been studied only for temperature scaling. How Platt scaling and isotonic regression perform on post-RLHF models hasn't been systematically tested. ATS exists because standard temperature scaling needed an explicit fix for this case. Whether the other two methods need similar extensions is an open question.
**
Most direct comparisons** of all three methods come from the general machine learning calibration literature. LLM-specific benchmarks that test all three head-to-head are rare. The ICSE 2025 code calibration paper is one of the few, and its scope is limited to code generation.
Calibration set size is a real deployment constraint. Isotonic regression results from papers assume datasets large enough to constrain the mapping. In production with limited labeled examples, the gap between isotonic regression and Platt scaling may close or reverse.
# Conclusion
**
Temperature scaling** is the right starting point for most teams. For base models without RLHF, a single T often does enough.
For RLHF-tuned models, switch to ATS: the per-token temperature handles the input-dependent overconfidence that a global scalar misses.
Platt scaling is the practical choice when the calibration set is small or when calibration needs to slot into a larger pipeline. It's data-efficient and straightforward to implement. The limitation is scope: it can't capture miscalibration that varies across samples, and it tends to degrade performance for strong models.
Isotonic regression has the strongest empirical track record of the three. Use it when the calibration set is large enough to constrain the mapping without overfitting, and pair it with normalization-aware extensions in multiclass settings.
The decision that comes before all of these is what "confidence" means for the task. Token probability, sequence probability, verbalized confidence, and consistency across samples can give different values for the same output. A calibration method applied to the wrong signal doesn't improve reliability. Getting that definition right is the prerequisite for any of the methods above to work.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み