新論文:AIエージェントの信頼性科学へ向けて
Stephan Rabanser, Sayash Kapoor, Arvind Narayananらは、AIエージェントの信頼性を測る指標が存在しない現状を指摘し、12の次元に基づく評価フレームワークと「信頼性指数」の導入提案を通じて、能力向上と信頼性の乖離を是正する科学的研究への移行を求めている。
キーポイント
信頼性の定義と4つの次元
単なる正確さだけでなく、一貫性(Consistency)、堅牢性(Robustness)、較正(Calibration)、安全性(Safety)の4つの次元を信頼性の核心として定義し、従来の評価指標の限界を指摘する。
12の次元に基づく大規模評価
原子力や航空機の安全分野からの知見を借用し、信頼性を12の次元に分解。14モデルを2つのベンチマークで評価した結果、能力の急速な進歩に対し信頼性の向上は限定的であることを示す。
信頼性指数の提案と業界への影響
経済的影響が緩やかな理由を説明する指標として「AIエージェント信頼性指数」の立ち上げを表明し、研究者や業界が信頼性の改善に投資するよう促す。
信頼性の測定と安全性の定義
近年のモデルは制約違反を回避する能力が向上しているが、金融エラーなどの失敗モードはまだ一般的である。ここでは安全性を「失敗発生時の危害の限定」と狭義に定義し、アライメントとは区別して扱っている。
スケーリングと信頼性のトレードオフ
モデルを大きくすることは一様に信頼性を高めるわけではない。 Calibration や Robustness は向上するものの、Consistency が損なわれる傾向があり、より豊かな行動レパートを持つ大規模モデルほど実行ごとのばらつきが大きくなる。
高精度でも信頼性が必須である理由
99%の精度があれば1%のエラーを許容できるという見解には反対し、自律的な高リスク運用には99.9%〜99.999%の性能が必要であり、現在のLLMベースエージェントはその水準に達する見込みがないと主張している。
自動化と補完の明確な区別
人間の創造性を支援する補完ツールと、意思決定を行う自動化エージェントでは信頼性の要件が異なり、後者は許容できない出力変動をもたらす。
重要な引用
Surprisingly, even though the lack of reliability of AI agents is well known, right now the AI industry doesn’t have good tools for measuring reliability, or even a good definition of reliability.
We borrowed insights from many other fields, such as nuclear and aviation safety. We were able to decompose reliability into 12 different dimensions.
Evaluating 14 models on two complementary benchmarks, we found that nearly two years of rapid capability progress have produced only modest reliability gains.
Bigger models aren’t uniformly more reliable. Scaling up improves some dimensions (calibration, robustness) but can hurt consistency.
Our view is that for autonomous operation in high-stakes contexts, we need 3-5 “nines” of performance — 99.9% to 99.999% accuracy — in order for reliability to become a non-issue
When evaluating agents, we need to test them for multiple runs (testing for variance in outcomes), under different conditions (evaluating adaptability), and on an ongoing basis (re-test as models and environments change).
影響分析・編集コメントを表示
影響分析
この論文は、AIエージェントの実用化における最大の障壁である「信頼性の欠如」を体系的に解明し、業界標準の評価基準確立への第一歩を示した。能力重視の現状から信頼性重視へのパラダイムシフトを促すものであり、企業によるエージェント導入判断や規制当局のガイドライン策定に重要な指針となる。
編集コメント
エージェントの「賢さ」だけでなく「信用性」を測る指標が欠如している現状を指摘する重要な提言です。実装段階では、ベンチマークスコアの高さだけでなく、エラーの許容範囲や一貫性を評価する新しい基準が求められます。
著者:ステファン・ラバンサー、サイヤシュ・カプール、アーヴィンド・ナラーヤナン
生産性向上のための新しい AI エージェントについて聞いたとしましょう。購入の実行やコードの作成、メールの送信、あるいは顧客対応を代行するものです。これを信頼すべきでしょうか?そのエージェントは、確実に仕事をこなせるだけの信頼性を備えているのでしょうか。そもそも、エージェントが失敗したという恐ろしい話は数多く存在します。
驚くべきことに、AI エージェントの信頼性不足は広く知られているにもかかわらず、現在の AI 業界には信頼性を測定するための優れたツールもなければ、信頼性の明確な定義さえも持ち合わせていません。
アーヴィンドとサイヤシュは長年この問題について考えてきました。昨秋、博士論文でより単純で伝統的な AI システムにおける信頼性問題を扱ったポストドクター研究員のステファン・ラバンサーが加わりました。私たちは他の独立した研究者数名も招聘し、信頼性の包括的な測定を試みた結果を公開しました。私たちが目指すドラフト論文のタイトルは「AI エージェントの信頼性に関する科学への道(Towards a Science of AI Agent Reliability)」です。
私たちは、原子力や航空機の安全性など、多くの他の分野からの知見を借用しました。その結果、信頼性を12 の異なる次元に分解することができました。2 つの相補的なベンチマークで 14 のモデルを評価したところ、約 2 年間にわたる急速な能力向上がもたらしたのは、わずかばかりの信頼性向上のみであることが分かりました。インタラクティブなダッシュボードはここをご覧ください。
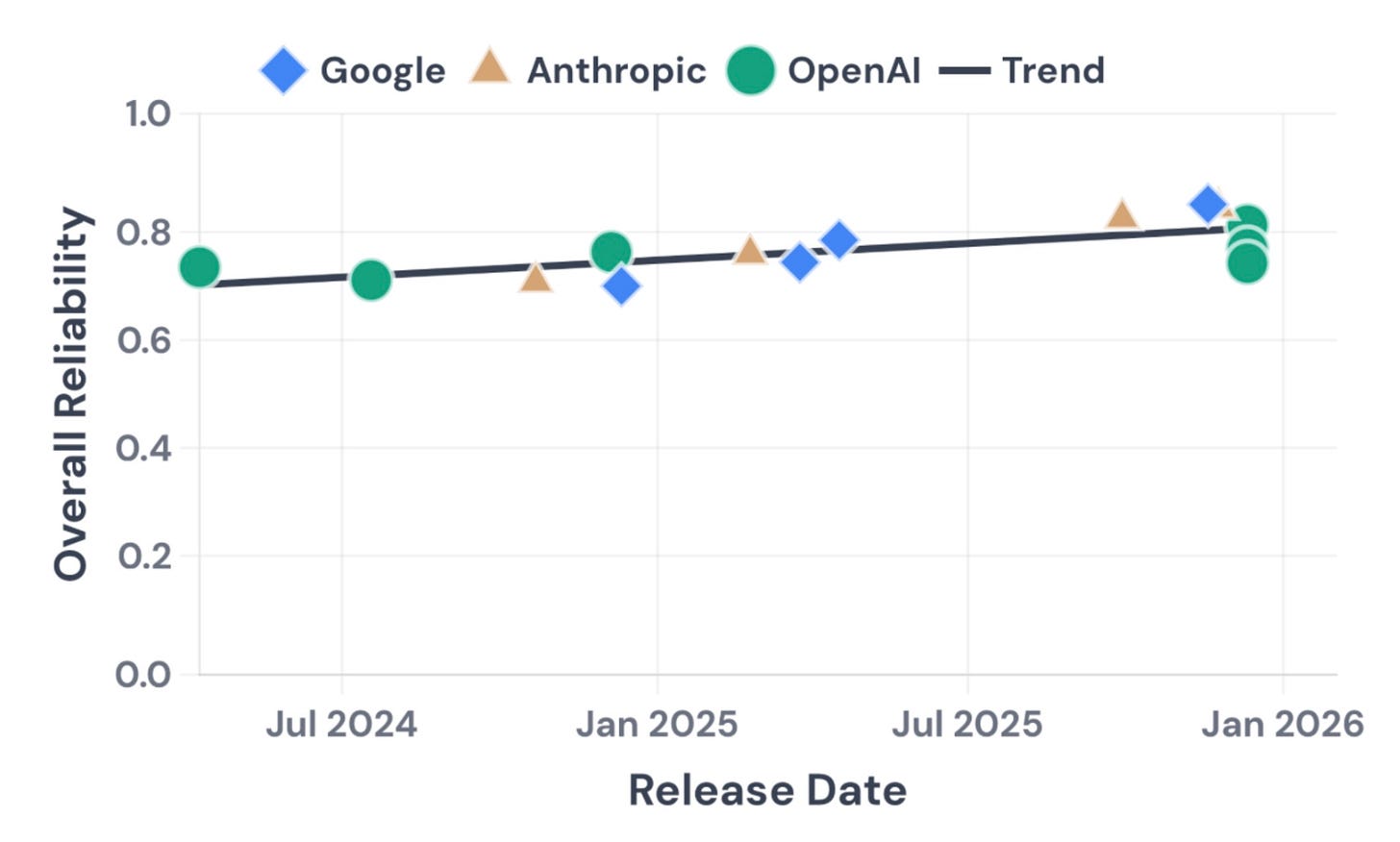
私たちの発見はまだ暫定的な段階ですが、AI エージェントが能力ベンチマークを圧倒するにもかかわらず、その経済的影響が緩やかであることについて業界の多くの人々がなぜ困惑しているのかを説明するのに役立つことを願っています。コミュニティが信頼性を体系的に追跡できるよう支援するため、私たちは AI エージェント向けの「信頼性指数(reliability index)」を立ち上げる予定です。これにより、研究者や産業関係者が信頼性の向上に取り組むための投資を促すことを期待しています。
目次
精度だけでは不十分:信頼性の 4 つの次元
能力の向上は急速ですが、信頼性の改善は modest です
なぜ私たちの見解が間違っている可能性があるか
デプロイヤー(導入者)はどうすべきか?
研究者や開発者はどうすべきか?
私たちの発見は AI の進展に何を意味するか?
さらに読むべき文献
精度だけでは不十分:信頼性の 4 つの次元
同僚を「信頼できる」と考えるとき、単に彼らがほとんどの場合正しいことを指すだけではありません。より豊かな意味を含みます:
同じことについて今日正しく明日間違えるのではなく、一貫して正しく行う(Consistency)
条件が完璧でないときに崩壊しない(Robustness)
自信を持って推測するのではなく、不確実なときにはそれを伝える(Calibration)
失敗した際、そのミスは壊滅的なものよりも修正可能なものである可能性が高い(安全性)
残念ながら、AI エージェントの評価はタスクにおける平均成功率という単一の数値に基づいて行われています。この数値は過去 2 年間で多くのタスクで急速に向上しており、それがエージェントの導入に対する大きな期待につながっています。
安全性が極めて重要な工学分野(航空、原子力、自動車)では、数十年も前に信頼性は平均的なパフォーマンスとは異なるものであることを理解していました。これらの分野は独立して、上記の 4 つの次元、すなわち一貫性(consistency)、堅牢性(robustness)、予測可能性(predictability)、そして安全性(故障の頻度と深刻さ)に収束しました。
例えば、原子炉保護システムは、停止が必要な条件が整うたびに毎回同じように反応しなければなりません。自動車の安全テストでは、センサーの故障や悪天候に対する対応を評価します。原子力リスク評価モデルは数千もの故障モードをシミュレーションし、その確率を定量化します。航空分野では、10 億飛行時間あたりに壊滅的なエラーが 1 つも発生しないことを目標としています。
能力の向上は急速ですが、信頼性の改善は modest です
これらの4つの高次元の概念をさらに精緻化・分解し、12 の指標へと落とし込みました。その後、OpenAI、Google、Anthropic の14 モデルからなるエージェントを、18 ヶ月にわたるリリース期間を対象にテストしました。評価には、一般アシスタント向けベンチマーク(GAIA)とカスタマーサービスシミュレーション用ベンチマーク(TauBench)という2 つの補完的な指標を用いました。各タスクは指示文を言い換えながら5 回ずつ実行し、ツールや環境に意図的に障害を注入してその耐故障性を測定しました。また、タスク解決に対するエージェント自身の自信度をelicited(引き出し)することで、自己評価の適切さ(キャリブレーション)も評価しました。合計で500 回のベンチマーク実行を行いました。
18 ヶ月間の期間において、信頼性はわずかに改善するにとどまった一方、精度は大幅に向上していることが分かりました。主要な3 つのプロバイダーのモデルはいずれも同様の傾向を示すため、これは業界全体における限界である可能性が高いです(ただし、Anthropic のモデルが OpenAI や Google のモデルを上回るケースも一部存在します)。
より具体的には、以下の基準を測定しました:
一貫性:タスクを解決できるエージェントでも、同一条件下で繰り返し実行すると失敗することがあります。多くのモデルは一貫した回答を与えることに苦戦しており、結果の一貫性スコアは全体として30% から75% の範囲に分布しています。
耐故障性:ほとんどのモデルは、サーバークラッシュや API タイムアウトなどの実際の技術的障害には比較的柔軟に対応します。しかし、同じ意味を持つ指示文を言い換えた場合、パフォーマンスは大幅に低下します。
予測可能性:エージェントは自分が間違っている時に気づくのが苦手です。これは全体的に最も弱い次元です。エージェントが自信を報告する際、それはほとんど信号を持っていないことが多いです。あるベンチマークでは、ほとんどのモデルが正しい予測と誤った予測を偶然よりもよく区別できませんでした。
安全性:最近のモデルは制約違反を回避する点で明らかに改善されていますが、誤った請求などの財務エラーは依然として一般的な失敗モードです。ここでは「安全性」を、失敗が発生した際に生じる危害が限定されたもの(bounded harm)と狭義に定義しており、アライメントのようなより広範な懸念は含みません。安全性の測定方法についてはまだ試行錯誤中であるため、集約された信頼性スコアとは別に報告しています。
スケーリングの影響:モデルが大きくなれば必ずしも信頼性が向上するわけではありません。スケールアップは一部の次元(較正、頑健性)を改善しますが、一貫性を損なうこともあります。行動レパートリーが豊富な大規模モデルでは、実行間の変動性がより顕著になることがあります。
なぜ我々が間違っている可能性があるか
我々の見解では、信頼性は能力に遅れをとっており、研究者や開発者が正確性とは別に信頼性の向上に注力しない限り、信頼性は導入の障壁として残り続けるでしょう。我々が間違っている可能性には3つの理由があります。
まず、私たちの次元や指標にはある程度の主観性が含まれています。この主観性を最小限に抑えるために、私たちは分析を既存のエンジニアリング分野に基づいて行いました。また、遅い信頼性の進歩に関する仮説が指標の選択に影響を与えないよう、実験を実行する前に指標のリストを確定させました。それでも、他の研究者の方々に信頼性を測定するための代替案を提案していただきたく、現時点での私たちの発見は暫定的なものであることを強調しておきます。
第二に、精度が十分に高まれば、信頼性は重要でなくなるかもしれません。私たちの指標は慎重に設計されており、精度の向上が自動的に信頼性の向上につながることはありません。広義には、精度は失敗率に関するものであり、信頼性は失敗の性質に関するものです。しかし、エージェントが 99% の時間で正確であれば、それが完全に予測不可能であっても 1% のエラーを許容できるかもしれません。私たちはこれに反対します。私たちの見解では、高リスクな文脈における自律的な運用においては、信頼性が問題とならないために、3〜5 つの「ナイン」(99.9% から 99.999%) のパフォーマンスが必要であり、LLM ベースのエージェントがそのような閾値に達する見通しはないと考えています。しかし、時間が経てば明らかになるでしょう。
第三に、信頼性の向上が精度の向上よりも遅れているからといって、絶対的な速度が遅いとは限りません。現在の直線的な傾向を先へ投影すれば、エージェントはわずか 3 年で 100% の信頼性を実現するはずです!しかし、私たちが直線モデルが妥当だと考えているわけではありません。その理由の一つとして、信頼性の欠如(1-信頼性)が 1 オーダーの magnitude で減少するごとに、それが前回の難易度と同じくらい困難になると予想しているからです。つまり、90% から 99% への信頼性向上は、99% から 99.9% への向上と同程度に難しく、その後も同様であると予測しています。ただし、これもまた待ってみなければ分かりません。
私たちが正しいと仮定しましょう。これはデプロイヤー、研究者・開発者、そして AI の進展のペースを追跡している人々にとって重要な示唆を含んでいます。それぞれについて順に議論していきましょう。
デプロイヤーはどのように行動を変えるべきでしょうか?
自動化と補完を明確に区別してください。時々間違った変数名を提案するコーディング・アシスタントは迷惑ですが、産業プラントの管理を行い出力が大幅に変動する自律型エージェントは許容できません。違いは、そのエージェントが人間の創造性を補完するために使われるか、それとも直接意思決定を行うために使われるかにあります。補完ツール(コパイロットや検索アシスタント)は、誰かが出力を確認するため、「信頼性」に対する割引が適用されます。一部の補完ユースケースでは、信頼性が実際には望ましくない場合さえあります。例えば、毎回同じ物語を生成する創作ライティング・アシスタントであれば、その職務において最悪の存在となるでしょう。
ついでに、エージェントが人間とどのように協力するかについては、理論化も測定も著しく不十分です。人間と言語モデルの相互作用を評価する初期の研究は存在しますが、それらは自律型エージェントが登場する以前のものであり、多段階タスクにおいてエージェントが人間とどのように協力するかを研究した同等の作業があるとは認識していません。介入研究(uplift studies)は有用な視点の一つを提供しますが、より広範なエージェント焦点型の取り組みは既に遅れています。
リリース判断における信頼性について考えてみましょう。自動化ツール(無人ワークフロー、顧客対応ボットなど)にとって、信頼性は妥協の余地のない要件です。デプロイヤーは、航空業界がサービス開始前に認証を要求するのと同様に、サンドボックスから本番環境へ移行する前に信頼性の閾値を満たすことを義務付けるべきです。このような分野から借用できる他の実践も多数あります。例えば、エージェントの失敗を中心にインシデント報告文化を構築することなどです。
私たちが特定した指標は、信頼性を理解するための出発点として広く有用ですが、デプロイヤーは自社の特定の文脈とデータセットに合わせて独自の内部評価を構築すべきです。
研究者や開発者はどのように異なるべきでしょうか?
ベンチマークは AI の進展を牽引します。約一年半前に発表した「AI Agents that Matter」という論文で、エージェントベンチマークが測定しているものと実務上で重要視されるものの間に大きな隔たりがあることを示しました。今回の新しい論文では、その隔たりが依然として存在することが示されています。この乖離を解消するには、AI 評価と AI 開発の両方の実践が方向転換する必要があります。
信頼性を測定する。現在のベンチマークを一度実行して精度の数値を報告するというアプローチは、浅く表面的な性能指標に過ぎません。これは完璧な天候の中で車を一度だけストレステストし、合格すれば安全だと宣言することに匹敵します。エージェントを評価する際には、複数の実行でテスト(結果のばらつきを検証)、異なる条件下でのテスト(適応性を評価)、そして継続的なテスト(モデルや環境が変化するたびに再テスト)を行う必要があります。精度に代わるものではなく、信頼性プロファイルを併せて報告することを求めます。
信頼性の理解と向上。私たちの実験では、一貫性と予測可能性が、モデルをより信頼できるものにすることの最大の障壁であることが示唆されました。エージェント開発者は、これらの弱点を明示的に改善することを検討すべきです。そのためには、ターゲットを絞った最適化や、より良いスケフォールディング(基盤構築)が可能かもしれません。特に、エージェントは失敗する可能性が高い状況を認識してそれを表明し、実際に失敗した際には優雅に回復できる能力を持つべきです。さらに推測的なアイデアとしては、開発段階では異なる戦略を探求しつつ、展開時には一貫した実行計画に従うエージェントが挙げられます。これにより、毎回同じタスクを異なる方法で解決するのではなく、エージェントとワークフローの両方の最良の点を同時に提供できます。
私たちの発見は AI の進展にとって何を意味するのか?
能力と信頼性のギャップは、人工一般知能(AGI)がもたらすと予測されていた労働市場への急速な影響がまだ見られない理由の一つである可能性があります。しかし、それは唯一の理由ではありません。最近の英国 AI 安全研究所(AISI)の報告書では、AGI に対する6つの障壁が特定されました。ただし、その報告書は各障壁を概略レベルで議論しているに過ぎません。
私たちの論文は、これらの障壁の一つである「信頼性」について、骨格に肉付けするものとして捉えることができます。私たちが特定した4つの次元のいずれも、現時点では解決済みとはみなすことができず、図中に緑色で示された個々の指標のうち2つだけが(暫定的に)解決済みと見なせる状態です。
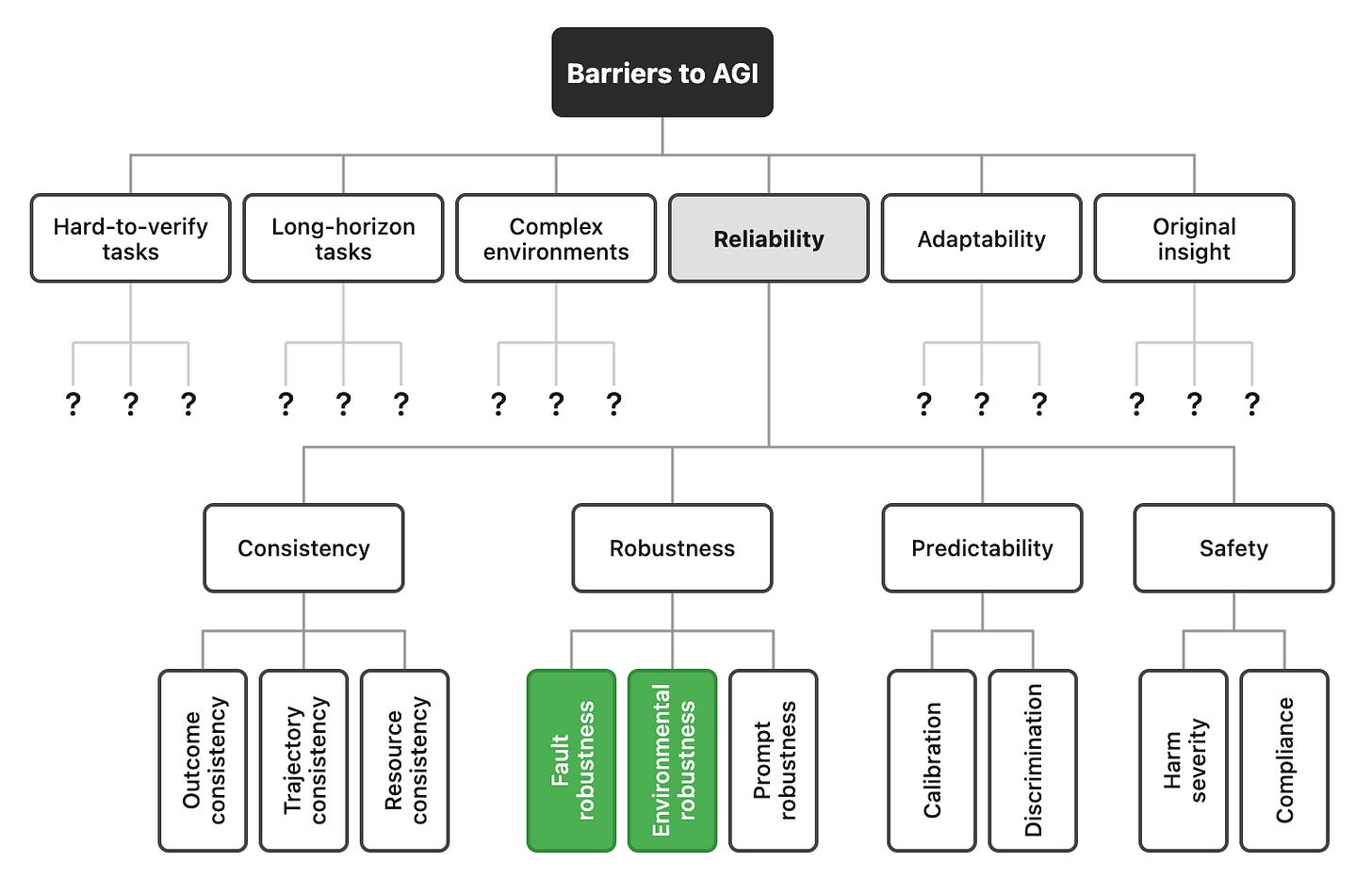
AGI に対する他の障壁に関する今後の研究により、AI エージェントが広く展開される前に改善しなければならないパフォーマンスの多くの他の次元が明らかになる可能性があります。
信頼性に関する私たちの分析と同様に、AGI に対する他の障壁を具体化するためには、まだ多くの作業が必要です。私たちが抱いている直感は、これによって進歩が遅れている多くの他の次元と指標が明らかになるだろうということです。何兆ドル規模の問いは、エージェントが推論スケーリングや強化学習などの一般的な手法を通じて全体的に改善されるのか、それとも信頼性、適応力、独創性などの個々の次元を改善するために地道な作業が必要となるのかという点です。
AI の進展と将来に関するエビデンスに基づく分析を受け取るには、購読してください。
さらに読むべき文献
66 ページにわたる完全な論文は arXiv で入手可能で、提案する指標の定義、実験設定の詳細、推奨事項および今後の研究への拡張された議論が含まれています。著者は、Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, および Arvind Narayanan です。論文に加えて、実践者が個々のモデル、ベンチマーク、信頼性の次元に詳しく掘り下げることを可能にするために、結果のインタラクティブなダッシュボードも提供しています。実験を再現するためのコードは GitHub で利用可能です。
本論文は、AI エージェント評価の科学を推進するという私たちのより広範な取り組みの一部です。主要な出版物には、「AI Agents that Matter」および「Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation」があり、後者は ICLR 2026 に最近採択されました。
本論文は、ベンチマークを通じて測定する範囲を拡張することを目指す先行研究の上に構築されたものと見なすことができます。例えば、HELM は較正(calibration)や堅牢性(robustness)を含む 7 つの指標を導入し、これらを用いて主要なベンチマーク上で数十の言語モデルを評価しました。
もちろん、これが唯一の要因ではありません。ベンチマークは依然としてデータ汚染に苦しんでおり、能力の進歩を過大評価する可能性があります。「AI を通常の技術として捉える」という枠組みは、能力の進歩と経済的影響の間の障壁を理解するための有用なツールを提供します。信頼性は製品・アプリケーション段階に属します。人間、社会、組織的要因はその下流に位置します。これらの要因がどれほど深刻になり得るかを示すケーススタディとして、最近のエッセイ「AI は自動的に法務サービスを安価にするわけではない」をご覧ください。
原文を表示
By Stephan Rabanser, Sayash Kapoor, Arvind Narayanan
Suppose you hear about a new AI agent for improving productivity — by making purchases, or writing code, or sending emails, or handling a customer on your behalf. Should you trust it? Can the agent do the job reliably enough? After all, there are many horror stories of agents going wrong.
Surprisingly, even though the lack of reliability of AI agents is well known, right now the AI industry doesn’t have good tools for measuring reliability, or even a good definition of reliability.
Arvind and Sayash have long been thinking about this. Last fall, we were joined by postdoctoral researcher Stephan Rabanser, whose PhD looked at the reliability question in simpler, more traditional AI systems. We recruited a few other independent researchers, and have released what we hope is a comprehensive measurement of reliability. Our draft paper is called Towards a Science of AI Agent Reliability.
We borrowed insights from many other fields, such as nuclear and aviation safety. We were able to decompose reliability into 12 different dimensions. Evaluating 14 models on two complementary benchmarks, we found that nearly two years of rapid capability progress have produced only modest reliability gains. See our interactive dashboard here.
While our findings are tentative at this stage, we hope they can help explain the puzzlement among many in the industry as to why the economic impacts of AI agents have been gradual, even though they are crushing capability benchmarks.1 To help the community track reliability systematically, we plan to launch an AI agent “reliability index”. We hope this will stimulate researchers and industry to invest effort into improving reliability.
Table of Contents
Accuracy isn’t enough: four dimensions of reliability
Capability gains are rapid, but improvements in reliability are modest
Why we could be wrong
What should deployers do differently?
What should researchers and developers do differently?
What do our findings mean for AI progress?
Further reading
Accuracy isn’t enough: four dimensions of reliability
When we consider a coworker to be reliable, we don’t just mean that they get things right most of the time. We mean something richer:
They get it right consistently, not right today and wrong tomorrow on the same thing (Consistency)
They don’t fall apart when conditions aren’t perfect (Robustness)
They tell you when they’re unsure rather than confidently guessing (Calibration)
When they do mess up, their mistakes are more likely to be fixable than catastrophic (Safety)
Unfortunately, AI agents are evaluated based on a single number, the average success rate at the task. That number has been going up quickly on many tasks over the last two years, which is why there’s so much excitement about deploying agents.
Safety-critical engineering fields (aviation, nuclear, automotive) figured out decades ago that reliability is not the same as average performance. These fields independently converged on the above four dimensions: consistency, robustness, predictability, and safety (the frequency and severity of failures).
For example, nuclear reactor protection systems must respond identically every time conditions warrant shutdown. Automotive safety testing evaluates responses to sensor failures and adverse weather. Nuclear risk assessment models thousands of failure modes and quantifies their probabilities. Aviation targets one catastrophic error per billion flight hours.
Capability gains are rapid, but improvements in reliability are modest
We refined and decomposed these four high-level dimensions into twelve metrics. We then tested agents based on 14 models from OpenAI, Google, and Anthropic, spanning 18 months of releases. We looked at two complementary benchmarks: a general assistant benchmark (GAIA) and a customer service simulation benchmark (TauBench). We ran each task five times, with instructions paraphrased. We injected faults in the tools and environment to measure robustness to such failures, and elicited the agents’ confidence at having solved the task to measure calibration. In total, we executed 500 overall benchmark runs.
We found that reliability has improved only modestly over 18 months, while accuracy improved substantially. All three major providers cluster together, so this appears to be an industry-wide limitation (though there are some cases where Anthropic’s models outperform OpenAI’s and Google’s).
More specifically, we measured the following criteria:
Consistency: Agents that can solve a task often fail on repeated attempts under identical conditions. Many models have trouble giving a consistent answer, with outcome consistency scores ranging from 30% to 75% across the board.
Robustness: Most models handle genuine technical failures (server crashes, API timeouts) gracefully. But if we rephrase the instructions with the same semantic meaning, performance drops substantially.
Predictability: Agents are not good at knowing when they’re wrong. This is the weakest dimension across the board. When agents report confidence, it often carries little signal. On one benchmark, most models couldn’t distinguish their correct predictions from incorrect ones better than chance.
Safety: Recent models are noticeably better at avoiding constraint violations, though financial errors, such as incorrect charges, remain a common failure mode. We use safety narrowly to mean bounded harm when failures occur, not broader concerns like alignment. We are still iterating on how we measure safety, so we report it separately from the aggregate reliability score.
Impact of scaling: Bigger models aren’t uniformly more reliable. Scaling up improves some dimensions (calibration, robustness) but can hurt consistency. Larger models with richer behavioral repertoires sometimes show more run-to-run variability.
Why we could be wrong
Our view is that reliability lags capability, and that reliability will remain a barrier to deployment unless researchers and developers focus effort on improving reliability as a separate dimension from accuracy. There are three reasons why we could be wrong.
First, there is some subjectivity in our dimensions and metrics. We have tried to minimize this by grounding our analysis in existing engineering fields. And we finalized our list of metrics before performing experiments, in order to prevent our hypothesis about slow reliability progress from influencing our selection of metrics. Still, we welcome other researchers to suggest alternative ways to measure reliability, and emphasize that our findings are tentative at this stage.
Second, maybe reliability won’t matter if accuracy gets high enough. Our metrics are carefully crafted so that accuracy gains don’t automatically lead to reliability gains. Broadly speaking, accuracy is about the rate of failures while reliability is about the nature of failures. But if an agent is accurate 99% of the time, maybe we can tolerate 1% error even if it is completely unpredictable. We disagree. Our view is that for autonomous operation in high-stakes contexts, we need 3-5 “nines” of performance — 99.9% to 99.999% accuracy — in order for reliability to become a non-issue, and we don’t think LLM-based agents are on track to reach such a threshold. But time will tell.
Third, reliability progress being slower than accuracy doesn’t necessarily mean that it is slow in absolute terms. If we project the current linear trend forward, agents will reach 100% reliability in just three years! We don’t think a linear model makes sense, in part because we expect each order of magnitude decrease in unreliability (1-reliability) to be as hard as the previous one. That is, we expect the jump from 90 to 99% reliability to be about as hard as the jump from 99 to 99.9% reliability, and so on. But again, we just have to wait and see.
Suppose we’re right. There are important implications for deployers, researchers & developers, and for those tracking the pace of AI progress. Let’s discuss each in turn.
What should deployers do differently?
Clearly distinguish automation from augmentation. A coding assistant that occasionally suggests wrong variable names is annoying; an autonomous agent managing an industrial plant yielding highly variable output is unacceptable. The difference is whether the agent is used to augment a human’s creativity or directly make decisions. Augmentation tools (copilots, search assistants) get a reliability “discount” because someone reviews the output. In some augmentation use-cases, reliability might actually be undesirable. For example, a creative writing assistant that produces the same story every time would be terrible at its job.
Incidentally, how well agents collaborate with humans is woefully under-theorized and under-measured. There is some early work on evaluating human-LM interaction, but both efforts predate autonomous agents, and we are not aware of any equivalent work studying how agents collaborate with humans over multi-step tasks. Uplift studies offer one useful lens, but a broader agent-focused effort is overdue.
Consider reliability for making release decisions. For automation tools (unattended workflows, customer-facing bots), reliability is non-negotiable. Deployers should consider requiring reliability thresholds before moving from sandbox to production, the way aviation requires certification before service. There are many other practices to borrow from such domains, such as building an incident-reporting culture around agent failures.
While the metrics we have identified are broadly useful as a starting point for understanding reliability, deployers should build their own internal evaluations tailored to their specific context and datasets.
What should researchers and developers do differently?
Benchmarks drive progress in AI. A year and a half ago, our paper AI Agents that Matter showed there was a big gap between what agent benchmarks measured and what matters in practice. Our new paper shows that the gap persists. To fix this disconnect, both AI evaluation and AI development practices need to change course.
Measure reliability. The current approach of running a benchmark once and reporting the accuracy number is a shallow, superficial performance measure. It is comparable to stress-testing a car once in perfect weather and declaring it safe if it passes. When evaluating agents, we need to test them for multiple runs (testing for variance in outcomes), under different conditions (evaluating adaptability), and on an ongoing basis (re-test as models and environments change). We call for reporting reliability profiles alongside accuracy, not instead of it.
Understand and improve reliability. Our experiments suggest that consistency and predictability are the biggest gaps preventing models from being more reliable. Agent developers should consider improving these weak points explicitly, possibly via targeted optimization or improved scaffolding. In particular, agents should be able to recognize when they are likely to fail and say so, and recover gracefully when they do fail. More speculative ideas include agents that explore different strategies during development but follow a consistent execution plan when deployed, rather than solving the same task differently each time, simultaneously delivering the best of agents and workflows.
What do our findings mean for AI progress?
The capability-reliability gap could be one reason why we are not seeing any of the rapid labor-market effects that Artificial General Intelligence has been predicted to bring about. It is not the only one. A recent UK AISI report identified six barriers to AGI. However, the report discussed each at a high level.
Our paper can be seen as putting flesh on the bones of one of these barriers — reliability. None of the four dimensions we identify can be considered solved at this point in time, and only two of the individual metrics, shown in green in the figure, can be considered (tentatively) solved.
Future work on other barriers to AGI may reveal many other dimensions of performance that must be improved before AI agents can be widely deployed.
There is much work to be done in fleshing out the other barriers to AGI, analogous to our analysis of reliability. Our hunch is that this will reveal many other dimensions and metrics on which progress has been slow. The gazillion-dollar question is whether agents will get better across the board through general methods such as inference scaling and reinforcement learning, or whether painstaking work will be required to improve individual dimensions of reliability, adaptability, originality, and so on.
Subscribe to receive evidence-based analysis of AI developments and the future of AI.
Further reading
The full 66-page paper is available on arXiv and includes definitions of the metrics we propose, details on our experimental setup, as well as an extended discussion on our recommendations and proposed future work. The authors are Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. Alongside the paper, we also provide an interactive dashboard of our results to enable practitioners to drill down into individual models, benchmarks, and reliability dimensions. The code to reproduce our experiments is available on GitHub.
This paper is part of our broader effort to advance the Science of AI Agent Evaluation. Key publications include AI Agents that Matter and Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation, recently accepted to ICLR 2026.
Our paper can be seen as building on work that aims to extend the scope of what we measure through benchmarks. For example, HELM introduced 7 metrics, including calibration and robustness, and used these to evaluate dozens of language models on prominent benchmarks.
1Of course, this is not the only factor. Benchmarks continue to struggle with data contamination, so they might overestimate capability progress. AI as Normal Technology provides a useful framework to understand the barriers between capability progress and economic impacts. Reliability falls into the products/applications stage. Human, social, and organizational factors lie downstream. As a case study of how serious these can be, see our recent essay AI Won’t Automatically Make Legal Services Cheaper.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み