Moebius(4 分間の読み物)
Huazhong University of Science and Technology と VIVO AI Lab が開発した軽量画像補完フレームワーク「Moebius」は、パラメータ数を 10B モデルの 2% 以下に抑えながら FLUX.1-Fill-Dev に匹敵する性能と 15 倍の推論速度を実現し、業界標準を再定義した。
キーポイント
極限の軽量化と高性能の両立
0.2B パラメータという極めて小さなモデルサイズでありながら、10B レベルの産業用汎用モデル FLUX.1-Fill-Dev と同等かそれ以上の生成品質を達成している。
LλMI ブロックによる構造再構築
Local-λ Mix Interaction (LλMI) ブロックを導入し、空間的文脈とグローバルな意味的事前知識を固定サイズの線形行列に集約することで、パラメータ削減と表現力の維持を両立させた。
潜在空間における適応的多粒度蒸留
高コストなピクセル空間での復号を避け、潜在空間内で動的に勾配ベースの損失をバランスさせる適応的多粒度蒸留戦略を採用し、高精度なアライメントを実現した。
劇的な推論速度の向上
モデルサイズの劇的な縮小と最適化により、総推論時間が 15 倍以上加速され、実用的なデプロイにおける新たな効率基準を提示している。
極限のパラメータ効率
Moebius はわずか 0.22B(226M)パラメータで動作し、大規模モデル FLUX.1-Fill-Dev の 2% 未満のサイズでありながら高品質なインペイントを実現します。
驚異的な推論速度
単一 GPU でステップあたり 26.01ms の遅延を達成し、10B レベルのモデルと比較して全体の実行時間が 15 倍加速されています。
効率的なアーキテクチャと学習戦略
提案された LλM I ブロックによる U-Net の再構築と、適応型マルチグラニュリティ蒸留戦略により、構造的圧縮による性能低下を克服しています。
影響分析・編集コメントを表示
影響分析
この研究は、大規模モデルに依存していた高品質な画像補完技術の壁を破り、リソース効率と性能のトレードオフ関係を劇的に改善した画期的な成果です。特に、10B モデルクラスのパフォーマンスを 2% のパラメータ数で実現することは、エッジデバイスやクラウドコスト削減が必要な現場における実用化への道筋を明確に示しており、今後のディフュージョンモデルのアーキテクチャ設計に大きな影響を与えるでしょう。
編集コメント
10B モデル級の性能を 2% のサイズで実現したこの技術は、AI デプロイにおけるコストと速度の課題に対する決定的な解決策となり得ます。特に「潜在空間での蒸留」という手法は、今後の軽量モデル開発において重要な指針となるでしょう。
Moebius: 10B レベルのパフォーマンスを誇る 0.2B の軽量画像インペイントフレームワーク
(*) 同等貢献, (†) プロジェクトリーダー, (📧) 責任著者。
1華中科技大學
2VIVO AI Lab
投稿済み
-->
要旨
10B レベルの産業用基盤モデルは画像インペイントの境界を押し広げてきましたが、その prohibitive な計算コストが実用的な展開を著しく阻害しています。高最適化されたタスク特化型スペシャリストを構築することは有望な解決策を提供しますが、極端な構造的圧縮は必然的に深刻な表現ボトルネックを引き起こします。これを克服するため、私たちは Moebius と呼ばれる極めて効率的な軽量インペイントフレームワークを提案します。Diffusion バックボーン(拡散バックボーン)を Local-λ Mix Interaction (LλMI) ブロックの導入によって体系的に再構築しました。Local-λ モジュールと Interactive-λ モジュールから構成されるこのブロックは、空間的文脈とグローバルなセマンティック事前知識を固定サイズの線形行列にエレガントに要約し、複雑な潜在相互作用を維持しつつパラメータを劇的に削減します。さらに、この極めてコンパクトなアーキテクチャの表現能力を最大限に引き出すため、適応型マルチグラニュラリティ蒸留戦略(adaptive multi-granularity distillation strategy)と相乗的に組み合わせました。高価なピクセル空間でのデコードを避けるために潜在空間内のみで動作するこの戦略は、複数の勾配ベース損失を動的にバランスさせ、高忠実度の整合性を達成します。自然画像およびポートレートベンチマークにおける広範な実験により、この最適な相乗効果により Moebius が 10B レベルの産業用汎用モデル FLUX.1-Fill-Dev の生成品質と競合し、あるいはそれを上回ることを実証しました。驚くべきことに、Moebius はパラメータを 2% 未満(0.22B vs. 11.9B)しか使用せずに、推論時間の全体で 15 倍以上の加速を実現し、高忠実度インペイントのための新たな効率基準を設定しました。
Method
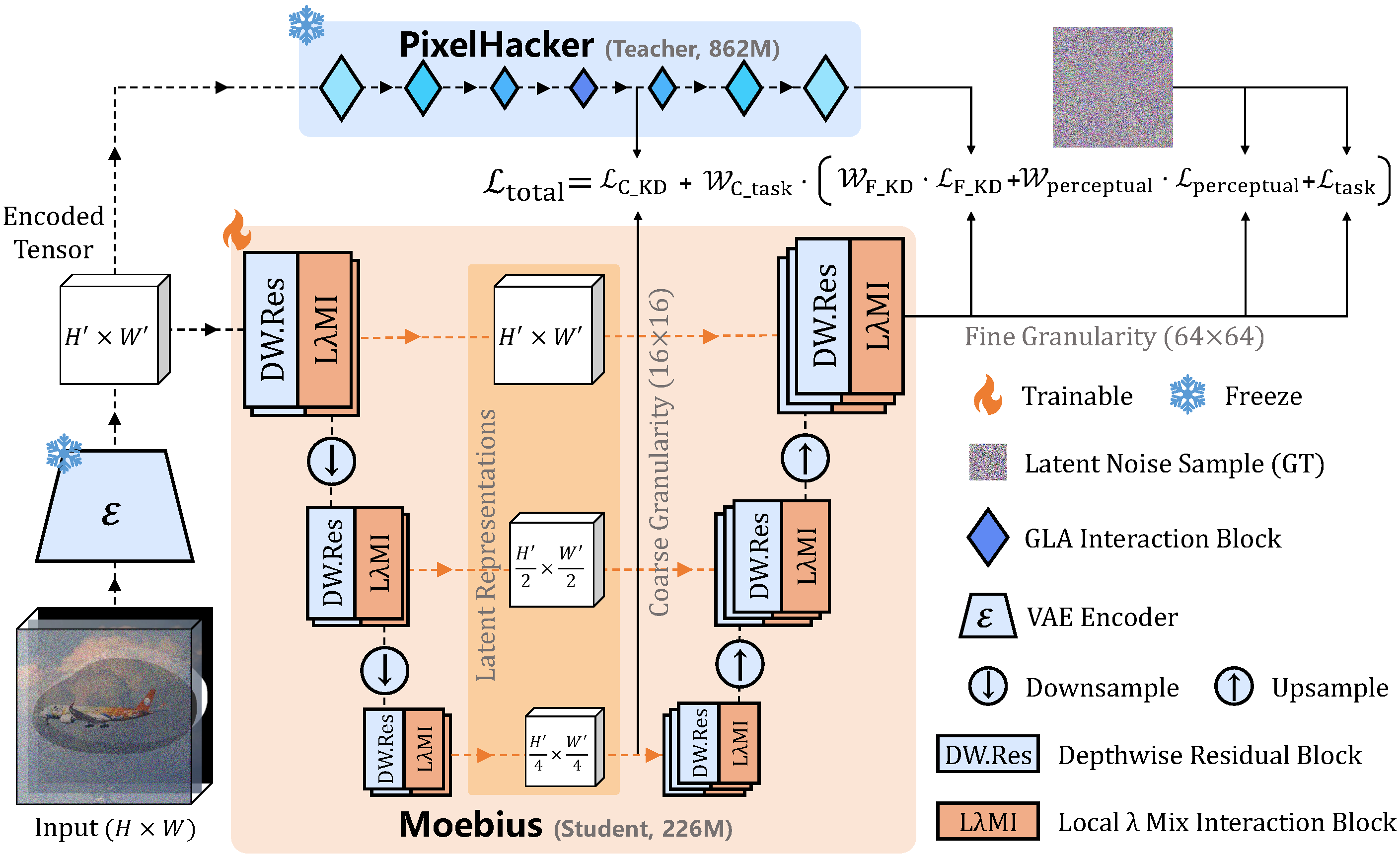 image
image
Moebius の全体パイプライン。我々は、潜在カテゴリガイダンス (Latent Categories Guidance: LCG) を備えた潜在拡散モデル (Latent Diffusion Model: LDM) フレームワークを採用しています。極限のアーキテクチャ効率を実現するため、提案する LλM I ブロック(3.2 節で詳述)を用いて、ノイズ除去用 U-Net を体系的に再構築しました。さらに、トレーニング中には適応型マルチグラニュラリティ蒸留戦略(3.3 節)を適用し、軽量な専門モデルを高容量の教師モデルと整合させることで、極限の構造的圧縮によって生じる能力低下を効果的に緩和することに成功しています。
Highlights
- 📉 極限のパラメータ効率 (< 2%): Moebius はわずか 0.22B(226M)パラメータで動作し、これは巨大な産業用モデル FLUX.1-Fill-Dev (11.9B) の規模の 2% に満たないものです。これにより、高計算リソースを必要とする従来の常識を打ち破り、消費者向けおよびエッジデバイスでも高品質なインペイントングが可能になりました。
- ⚡ 15 倍の推論速度向上 (26ms/step): 単一 GPU 上でステップあたりわずか 26.01 ms の驚異的な推論レイテンシを達成しました。最適化されたサンプリングステップと組み合わせることで、Moebius は 10B レベルのモデルと比較して全体の実行時間を 15 倍以上短縮します。
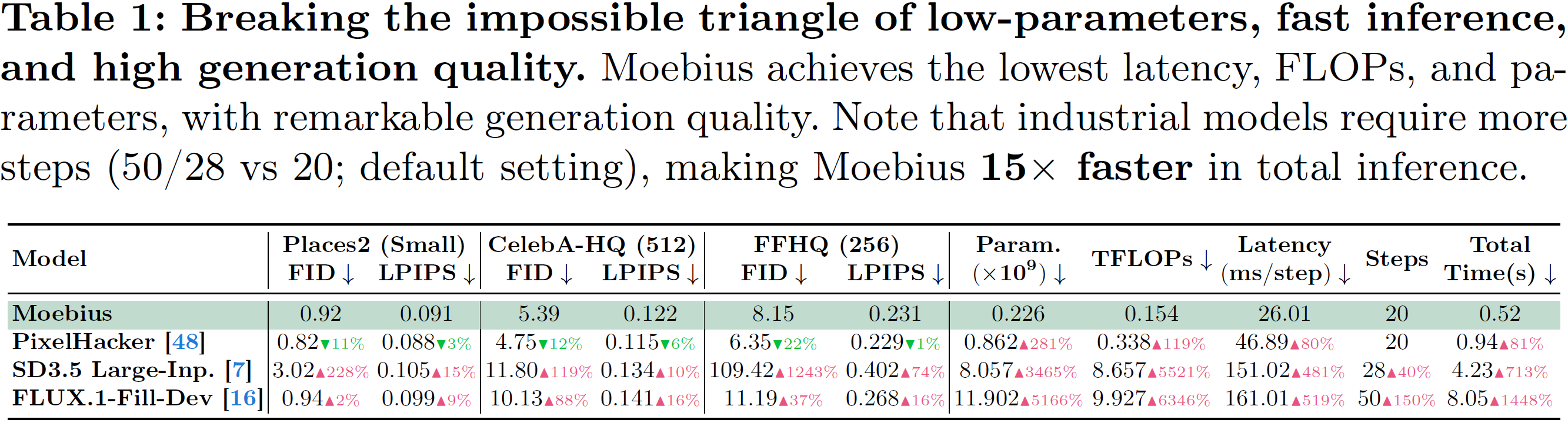 image
image
- 🏆 10B レベルのインペイント品質(6 つのベンチマークにおいて FLUX.1-Fill-Dev と同等かそれ以上):モデルサイズの縮小は表現能力の低下を意味しません。アーキテクチャと蒸留の相乗的な最適化を通じて、Moebius は自然シーン(Places2)からポートレートシーン(CelebA-HQ, FFHQ)までを含む 6 つの包括的なベンチマークにおいて、10B レベルの最先端(SOTA)汎用モデル(FLUX.1-Fill-Dev, SD3.5 Large-Inpainting)と同等のパフォーマンスを発揮し、複雑なテクスチャや顔の妥当性といった特定のシナリオではそれを超えています。
- 💡 相乗的な中核的イノベーション:
アーキテクチャ設計(LλMI ブロック):空間的文脈とグローバルなセマンティック事前知識を固定サイズの線形行列に凝縮することで、自己注意機構およびクロスアテンションの両方を再定式化し、二次計算オーバーヘッドを回避します。
- 適応的多粒度蒸留戦略:表現能力を、高価なピクセル空間でのデコーディングを避けるため、厳密に潜在空間(latent space)内で PixelHacker(教師モデル)から転移します。微視的な中間特徴量から巨視的な拡散軌跡に至るまでの多粒度監督を整列させることで巨大な容量ギャップを埋めつつ、勾配ノルム適応型損失重み付けメカニズムを通じてトレーニングを動的にバランスさせます。
- Optimal Synergistic Balancing: Systematically explores the mutual constraint and upper bound between compact structure and distillation. By mapping this architecture-distillation synergy frontier, we ensure our 0.22B Moebius (student) absorbs the maximum semantic reasoning of PixelHacker (teacher) without triggering representation saturation.
- 🚀 Task-Specific Specialist over Bloated Generalists: Rather than blindly scaling up, Moebius answers a fundamental question: Can a model be smarter, lighter, and faster when the task is explicitly defined? It serves as a highly optimized specialist that liberates real-world image inpainting and AI object removal from parameter bloat.
Visualizations
- Natural Scenes -



 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
## - Portrait Scenes -
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image

 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
 image
image
## 自然風景(Places2)における比較
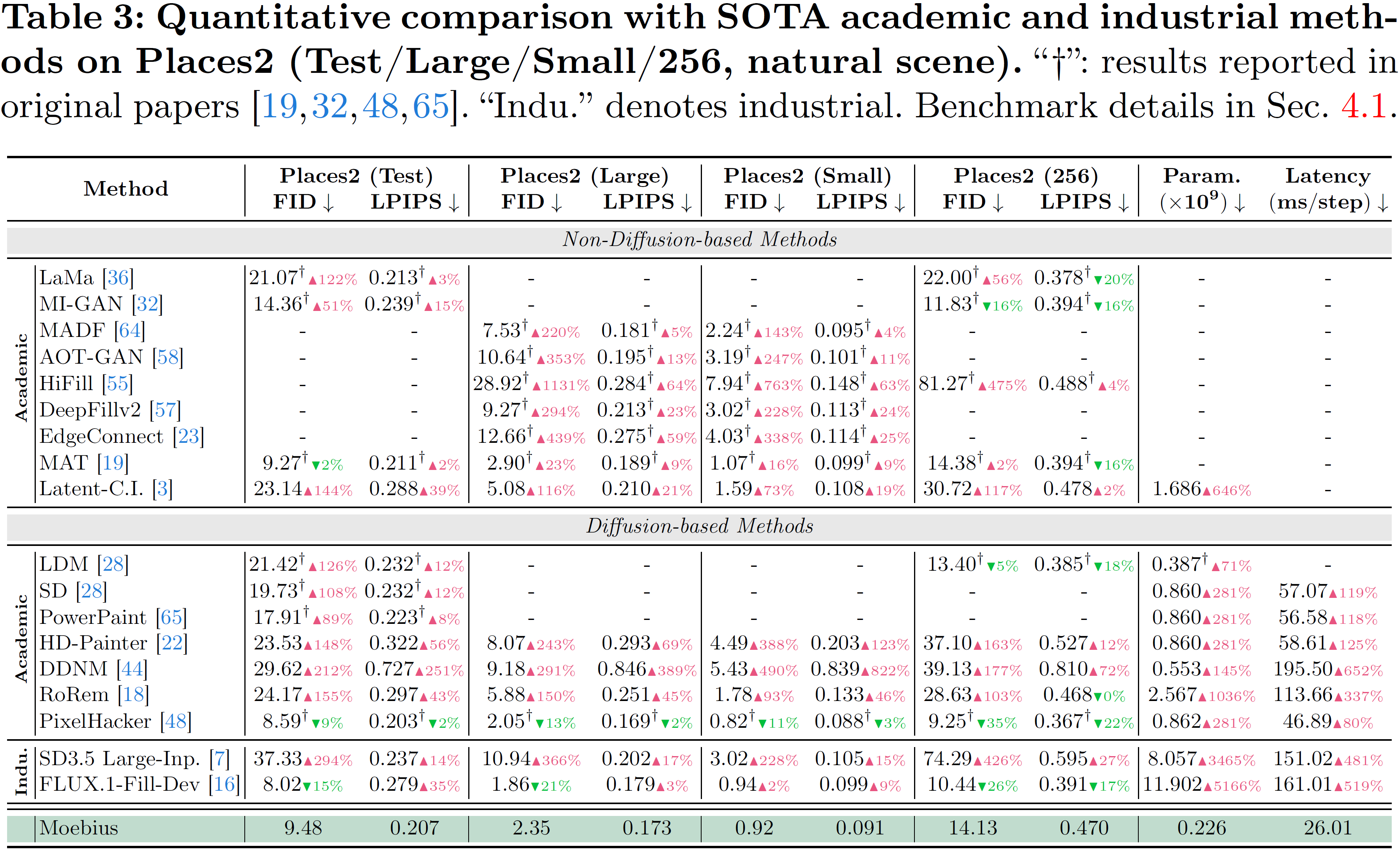
 image
image
## Portrait Scenes (CelebA-HQ, FFHQ) における比較
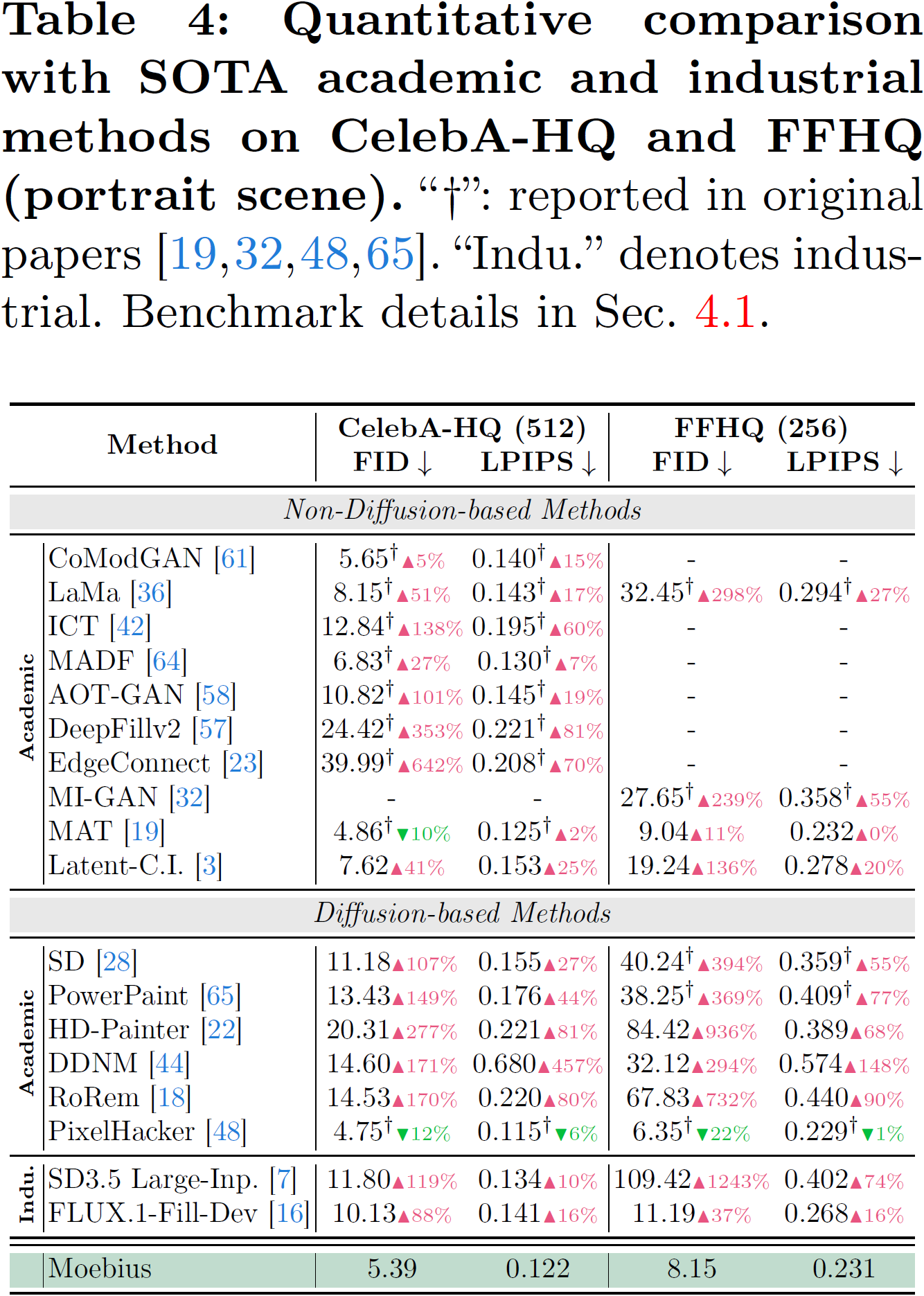 image
image
 image
image
## BibTeX
@misc{DuanAndXu2026Moebius,
title={Moebius: 10B レベルのパフォーマンスを誇る 0.2B 軽量画像インペイントフレームワーク},
author={Kangsheng Duan and Ziyang Xu and Wenyu Liu and Xiaohu Ruan and Xiaoxin Chen and Xinggang Wang},
year={2026},
eprint={2606.19195},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.19195},
}
原文を表示
Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
(*) Equal Contribution, (†) Project Leader, (📧) Corresponding Author.
1Huazhong University of Science and Technology
2VIVO AI Lab
Abstract
While 10B-level industrial foundation models have pushed the boundaries of image inpainting, their prohibitive computational costs severely hinder practical deployment. Constructing a highly optimized task-specific specialist offers a promising solution; however, extreme structural compression inevitably triggers a severe representation bottleneck. To conquer this, we propose Moebius, a highly efficient lightweight inpainting framework. We systematically reconstruct the diffusion backbone by introducing the Local-λ Mix Interaction (LλMI) block. Comprising Local-λ and Interactive-λ modules, it elegantly summarizes spatial contexts and global semantic priors into fixed-size linear matrices, preserving complex latent interactions while drastically shedding parameters. Furthermore, to unlock the full representational capacity of this highly compact architecture, we synergistically pair it with an adaptive multi-granularity distillation strategy. Operating strictly within the latent space to avoid expensive pixel-space decoding, this strategy dynamically balances multiple gradient-based losses to achieve high-fidelity alignment. Extensive experiments across natural and portrait benchmarks demonstrate that this optimal synergy enables Moebius to rival or even surpass the generation quality of the 10B-level industrial generalist FLUX.1-Fill-Dev. Remarkably, Moebius achieves this using less than 2\% of the parameters (0.22B vs. 11.9B) while delivering a >15× acceleration in total inference time, setting a new efficiency standard for high-fidelity inpainting.
Method
Overall pipeline of Moebius. We adopt the Latent Diffusion Model (LDM) framework equipped with Latent Categories Guidance (LCG). To achieve extreme architectural efficiency, the denoising U-Net is systematically restructured using our proposed LλM I blocks (detailed in Sec. 3.2). Furthermore, an adaptive multi-granularity distillation strategy (Sec. 3.3) is applied during training to align our lightweight specialist with the high-capacity teacher, successfully mitigating the capacity drop caused by extreme structural compression.
Highlights
- 📉 Extreme Parametric Efficiency (< 2%): Moebius operates with a mere 0.22B (226M) parameters, which represents less than 2% of the size of the colossal industrial giant FLUX.1-Fill-Dev (11.9B). It shatters the heavy-compute narrative, making high-quality inpainting accessible on consumer-grade and edge devices.
- ⚡ 15× Inference Speedup (26ms/step): Achieves a blistering inference latency of only 26.01 ms per step on a single GPU. Combined with optimized sampling steps, Moebius delivers an overall >15× total runtime acceleration compared to 10B-level models.
- 🏆 10B-Level Inpainting Quality (on-par-with/surpass FLUX.1-Fill-Dev across 6 benchmarks): Size contraction does not mean representation degradation. Through the synergistic optimization of architecture and distillation, Moebius performs on par with, and in certain scenarios (such as complex textures and facial plausibility), surpasses 10B-level state-of-the-art (SOTA) generalist models (FLUX.1-Fill-Dev, SD3.5 Large-Inpainting) across 6 comprehensive benchmarks spanning both natural scenes (Places2) and portrait scenes (CelebA-HQ, FFHQ).
- 💡 Synergistic Core Innovations:
Architecture Design (LλMI Block): Reformulates both self- and cross-attention by condensing spatial context and global semantic priors into fixed-size linear matrices, bypassing quadratic computational overhead.
- Adaptive Multi-Granularity Distillation Strategy: Transfers the representational capacity from our PixelHacker (teacher) strictly within the latent space (avoiding expensive pixel-space decoding). It bridges the giant capacity gap by aligning multi-granularity supervision—ranging from microscopic intermediate features to macroscopic diffusion trajectories—while dynamically balancing training via a gradient norm adaptive loss weighting mechanism.
- Optimal Synergistic Balancing: Systematically explores the mutual constraint and upper bound between compact structure and distillation. By mapping this architecture-distillation synergy frontier, we ensure our 0.22B Moebius (student) absorbs the maximum semantic reasoning of PixelHacker (teacher) without triggering representation saturation.
- 🚀 Task-Specific Specialist over Bloated Generalists: Rather than blindly scaling up, Moebius answers a fundamental question: Can a model be smarter, lighter, and faster when the task is explicitly defined? It serves as a highly optimized specialist that liberates real-world image inpainting and AI object removal from parameter bloat.
Visualizations
- Natural Scenes -
- Portrait Scenes -
Comparison on Natural Scenes (Places2)
Comparison on Portrait Scenes (CelebA-HQ, FFHQ)
BibTeX
@misc{DuanAndXu2026Moebius,
title={Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance},
author={Kangsheng Duan and Ziyang Xu and Wenyu Liu and Xiaohu Ruan and Xiaoxin Chen and Xinggang Wang},
year={2026},
eprint={2606.19195},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.19195},
}関連記事
DFlash、NVIDIA Blackwell で最大 15 倍のスループット向上を実現する並列トークンブロックドラフト方式を提案
研究チームが開発した DFlash は、推論のボトルネックである逐次生成を改善し、小規模モデルで未来のトークンを並列にドラフトして大規模モデルが検証する手法により、NVIDIA Blackwell 上で最大 15 倍のスループット向上を実現しました。
Claude Code を用いてブラウザ上で動作する Moebius 0.2B 画像インペイントモデルの移植
Simon Willison は、Hacker News で紹介された軽量な画像インペイントモデル「Moebius」を、Claude Code を活用してブラウザ環境で実行可能な形に移植した。これにより、大規模な計算リソースを必要とせず、ローカル環境で画像の特定領域を除去・補完する処理が可能となった。
開発者向け高スループットテキスト生成のために NVIDIA で DiffusionGemma を実行する
NVIDIA は、開発者が NVIDIA のプラットフォーム上で DiffusionGemma モデルを実行し、高速なテキスト生成を実現する方法を公開した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み