最適なトークナイザーの発見(15 分読了)
本記事は、理論的には計算困難とされる最適トークナイザーの構築アルゴリズムを提案し、その実用性に関する限界や現状の技術との比較について分析している。
キーポイント
最適化問題の実践的解決可能性
理論的に計算困難(intractable)とされる最適トークナイザーの問題に対し、巡回セールスマン問題の切断平面法のような手法を用いて実用的に解くアルゴリズムを提示している。
実用性に対する重要な留意点
既存の最先端手法がすでに最適解に近い(1% 以内)こと、訓練データでの最適化がテストデータでの汎化性能を保証しないこと、非効率なトークナイザーは語彙サイズを少し増やすことで許容可能であることの3点が指摘されている。
整数計画法による定式化
Recent paper (Tempus et al.) の手法に基づき、データセット全体のトークン化を整数変数の集合として表現する整数計画法への接続が説明されている。
色変数とエッジ変数の定義
各語彙エントリに対応する「色」変数(バイトシーケンスが語彙に含まれるか)と、データセット内の各出現に対応する「エッジ」変数(その位置でトークンとして使用されるか)を定義し、最小化対象はエッジ変数の合計となる。
整数線形計画の制約条件
トークンは語彙に含まれていなければ使用できず(エッジ≦色)、かつ各バイト位置でフローが保存されるという制約(流入=流出、境界を除く)により、データセットを一意かつ有効にトークン化する。
連続線形計画への緩和
任意の整数線形プログラム(ILP)は効率的に解けないため、変数を [0, 1] の連続値として制約を緩め、最適化ソルバーを用いて近似解を得るアプローチを採用している。
連続 LP の非積分性と丸め手法
連続線形計画問題(LP)の解は一般に整数値を持たず、色変数の合計が目標語彙サイズと一致しない場合があるため、Tempus et al. はこれを「丸める」ことで実行可能だが最適ではない整数解を得ている。
影響分析・編集コメントを表示
影響分析
この研究は、LLM の前処理プロセスにおける理論的限界と実用的な最適化の可能性について新たな視点を提供しますが、現状の技術水準がすでに高いレベルに達しているため、直ちに業界全体を覆すような即効性のある実装変更を促すものではありません。しかし、トークナイザー設計の数学的基礎を再考するきっかけとなり、将来のより高度な圧縮アルゴリズム開発への道筋を示唆しています。
編集コメント
理論的な面白さと実用性のギャップを冷静に分析した良質な技術記事です。現状の BPE 手法がすでに非常に強力であることを再認識させる内容となっています。
本稿では、特定の条件下において最適なトークナイザーを計算可能にしたアルゴリズムについて紹介します。この結果は魅力的です。なぜなら、最適化されたトークン化は理論的には困難な問題 theoretically intractable であるにもかかわらず、実際には解決可能に見えるからです。私の発見は、困難な事例であっても カット平面法 (cutting-plane) の手法を用いて最適解を導き出せることがある「巡回セールスマン問題 (TSP)」に関する様々な結果と非常に似ています。
この結果が魅力的である一方で、必ずしも *有用* ではない理由がいくつかあります。第一に、既存の最先端技術はすでに最適解に近い状態(多くの場合 1% 以内)にあります。第二に、トークナイザーが *トレーニングデータ* 上で最適であっても、保持されたテストデータで評価した際、他のトークナイザーほど一般化しない可能性があります。最後に、非効率的なトークナイザーも基本的に問題ありません:語彙サイズをわずかに増やすことで、非効率なトークナイザーのコストを相殺できます。
上記の注意点があるにもかかわらず、このプロジェクトに取り組む時間は非常に楽しく、他の人々もこの問題のフロンティアを広げることに興味を持っていただけることを願っています。
背景:トークナイザー
フロンティア型大規模言語モデル(LLM)は通常、*トークン*と呼ばれる整数のシーケンスを学習データとして訓練されます。各トークンはあるバイト列を指し、これらのバイト列はしばしば一般的な単語に対応しています。例えば、GPT-5 トークナイザーでは、トークン 290 はバイト列" the"に対応し、6602 は" token"に対応するため、テキスト" the token"はシーケンス [290, 6602] として符号化できます。
トークンからバイトへのマッピングは「語彙(vocabulary)」と呼ばれ、LLM が訓練される前に固定されます。通常、訓練データの断片を圧縮する語彙を見つけることを目指します。具体的には、データサイズに対して必要なトークンの数を最小化する、固定サイズの語彙を選択したいと考えています。このような語彙を見つけるための支配的な手法は、数十年の歴史を持つ貪欲型圧縮アルゴリズムであるバイトペアエンコーディング(BPE)です。
最近の研究論文で、Tempus 他 は、トークナイゼーションを整数線形計画法(integer linear programming)と結びつけました。彼らのアプローチの基本的な考え方は、データセット全体のトークナイゼーションを一連の整数変数として表現することです。
この定式化では、各可能な語彙エントリに対して「色」変数が存在します。具体的には、データセット内のすべての一意な部分文字列ごとに 1 つの色変数を作成します。対応するバイト列が語彙に含まれている場合、その色変数は 1 となり、そうでない場合は 0 となります。また、色変数の合計が目標とする語彙サイズに等しくなるよう、単一の制約を追加します。
色は特定のバイト列に対応しますが、あるバイト列の組み合わせはデータセット全体で多数回出現する可能性があります。色の各出現に対して、それぞれ個別の「エッジ」変数が存在します。これらのエッジは協力して、データセットの実際のトークン化を符号化します。もしエッジが 1 であれば、そのエッジに対応するトークンがこの特定の場所で使用されていることを意味します。線形計画問題の目的関数は、すべてのエッジ変数の合計、つまりデータセットを符号化するのに使用されるトークンの数を最小化することです。
例えば、以下の図では、「Queue」という単語を ["Q", "ue", "ue"] というトークン列としてトークン化しています。代わりに ["Qu", "e", "ue"] としてもよかったのですが、これは現在の ILP(整数線形計画)解が示すトークン化ではありません。なぜなら、最初の「Qu」および「e」に対応するエッジ変数の値が 0 であるためです。
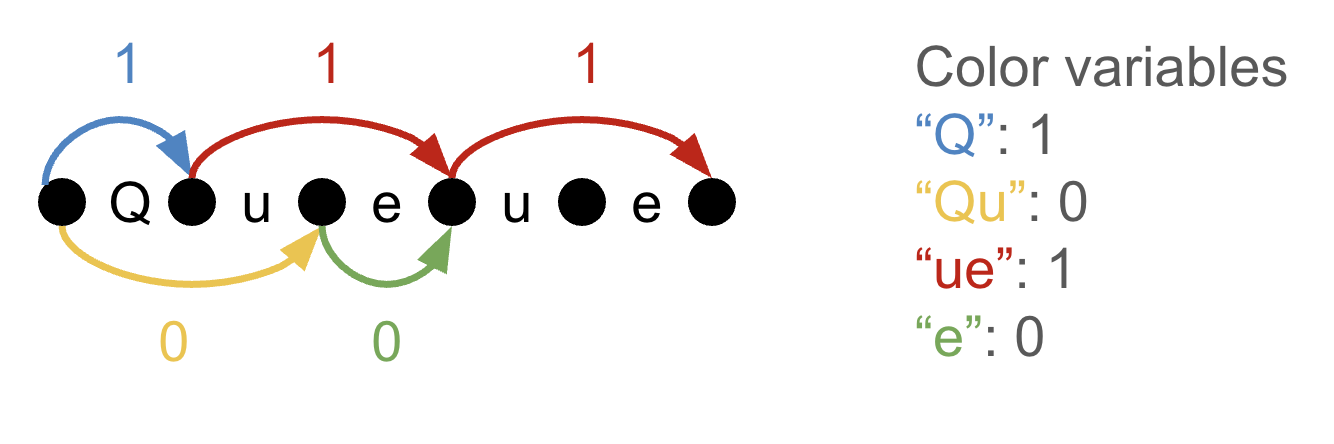
私たちは線形計画問題(LP)を 2 つの制約によって制限します。第一に、語彙に含まれていないトークンを使用することはできません。そのために、各辺変数を対応する色変数以下に制限します。第二に、データセットがちょうど 1 つの有効な方法でトークン化されることを保証したいのです。そのためにフロー制約を追加します:データセット内の各バイト位置について、この位置に流入する辺の和が、この位置から流出する辺の和と等しくなるようにします(境界を除く)。最初の位置と最後の位置については、流出または流入の量が 1 になるようにします。整数解においては、フロー制約は次のことを主張していると見なすことができます:*エッジが入る点は、最初と最後の位置を除き、必ずエッジが出ていなければならない*。
すべての変数が整数で [0, 1] に制限されていれば、この線形計画問題は最適なトークン化を符号化するのに十分です。しかし、任意の整数線形計画問題(ILP)を効率的に解くことはできないため、Tempus らは ILP を連続的な LP に緩和し、高度に最適化されたソルバーでこれを解きます。
連続 LP の解は一般に整数値になるとは限りません。以下にその例を示します。単語「Queue」に対して、2 つの重なり合うトークン化を行う場合、["Q", "ue", "ue"] として符号化するか、["Qu", "e", "ue"] として符号化するかのどちらかになります。この解の問題点は、色の変数の合計が 2.5 になる一方で、実際に使用した色の総数が 4 つであるため、サイズ 3 の最適な語彙を見つけたことにはならないという点です。一般的に、目標とする実際の語彙サイズよりもはるかに多くの非ゼロの色変数が生じてしまう可能性があります。
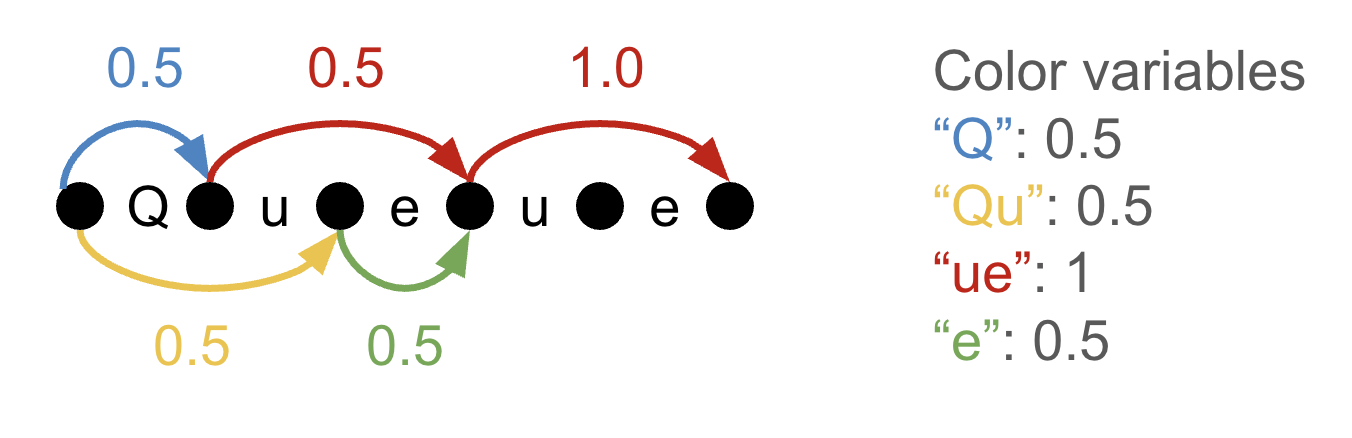
Tempus たちは、色の変数をいくつかの方法で「丸める」ことを提案し、整数値でありながら最適解ではない ILP(整数計画問題)の解を得ています。連続 LP の解は、最適解のトークン数に対する*下限*を与え、一方、丸められたトークナイザーは上限を与えることになります。
この研究についてもう一つ注意点を述べておく必要があります:扱いやすくするために、データセットを事前分割(単語に分割)し、重複する単語をマージしています(目的関数における重みは、その単語の出現回数に基づいて対応付けられます)。これにより線形計画問題 (LP) の変数の数が劇的に削減されますが、その結果、得られる解は事前分割器の下での「ほぼ最適」なものに限定されてしまいます。今日はこの制限を除去しようとは思いませんが、これは将来の研究として興味深い方向性となるでしょう。
カット平面法
昨年は、巡回セールスマン問題 (TSP) について学びました。この問題は整数計画問題 (ILP) としても定式化できます。私たちはしばしば カット平面法 を用いてこの ILP を解くことができます:まず、ILP を連続的な線形計画問題 (LP) に変換し、最適解が整数値となるまで追加の制約条件を追加していきます。これらの制約は証明可能に「有効」でなければなりません。つまり、実際の整数解に対して決して違反してはならないのです。理論的には、*任意の* ILP を追加の制約を持つ連続的な LP に「変換」することは可能ですが、その魔法のような追加制約を見つけることが計算上困難な場合もあります。TSP ソルバーでは、実用的なケースにおいて効率的にそのような制約を見つけるために多数のヒューリスティック手法を用いています。Corcorde(TSP ソルバー)の著者たちは、有用なカットを見つけるための技法について書籍全体を執筆しています。
Tempus 氏らの論文を読んだ後、カット平面法をトークナイゼーションの ILP(整数計画問題)に適用できないかと考えました。この手法は次のように機能します:まず初期の LP(線形計画問題)を解いて最適トークナイゼーションに対する下限と上限を取得し、その後、有効なカットを追加して LP を再求解することでこれらの境界値を徐々に近づけ、最終的に最適解で一致させるのです。
ILP に有用な「カット族」を考案するには多大な労力と創造性が必要となるため、自分で頭を打ち付けるのではなく、このタスクを Codex に任せることにしました。当初、Codex が発見したのはほとんど何もありませんでした–いくつかのカットは LP の境界値をわずかに改善しましたが、試されたものの多くは表面的な単語のヒューリスティクスに過ぎませんでした。
次に別のアプローチを試みました:総当たり法です。「カット」とは、すべての整数解に対して満たされる制約ですが、現在の分数 LP 解に対しては違反するものです。各可能な整数解ごとに 1 つの制約を持つ補助線形計画問題を構築し、分数解の違反度を最大化するように最適化することで、カットを見つけることができます。LP の全体に対してこれを行うことはできません。なぜなら、行数が指数関数的に膨れ上がってしまうからです。しかし、LP の小さな興味深い「射影」に対してであれば実行可能です。Codex は、共通の分数色を持つ単語のペアまたはトリプルのすべての変数に注目することを提案しました。
上記の手法は、丸められたトークナイザーを改善し、下限を引き上げる非常に優れたカットを見つけました。しかし、このアプローチは非常に非効率的です。なぜなら、膨大な数の単語ペアに対して(かなり大きな)補助 LP を解く必要があるからです。次のトリックとして、Codex に実際に見つけたカット自体を分析させることにしました。
brute force cuts を調べることで、Codex はより効率的に見つけられるいくつかのカットテンプレートを見つけました。最も効果的なファミリーは、Codex が「サイクル制約」と名付けたものです。この手法では、現在の LP 解において重なり合う分数エッジのペアを見つけます。例えば、色 A と B の間で重なり合う(つまり競合する)エッジのペアが見つかるかもしれません。次に、共通の色を共有するいくつかのペア、例えば色 B と C の別のペアや、色 C と A の別のペアを見つけます。その後、対応するエッジと色の変数から制約を作成します。これは連続的な LP 解によってしばしば違反されますが、有効な整数解では決して違反されません。
競合するペア AB, BC, CA のサイクルを見つけるには、巧妙なトリックが使えます:頂点を色とし、現在の解で分数エッジとして重なり合う色のペアをすべて結ぶグラフを構築します。このグラフができたら、DFS を実行してその中のサイクルを見つけます。Codex はこれを完全に自律的に実装しましたが、これはおそらくオリジナルのトリックではないでしょう。
実験設定
このプロジェクトではハードウェアの制約が大きく、Mac Studio と Mac mini のみを使用しました。このハードウェア向けに優れた GPU 加速 LP ソルバーが存在しないため、主に HiGHS のシングルコアシンプレックスソルバーに頼りました。残念ながら、このソルバーは特に後続の反復処理において、多くの(潜在的に退化した)カットを適用した場合などに停止することがあることがわかりました。
このハードウェアで合理的な時間内に実験を行うために、私は単一の電子書籍を対象としました。CPU 上で解ける範囲に LP を小さく保つ必要があったため、Tempus 他による事前トークン化のアプローチを採用しました。
最後に、LP をさらに小さくするために Tempus 他からのいくつかのヒューリスティックを採用しました。例えば、5 回未満しか出現しない部分文字列に対するカラー変数を削除するなどです。また、カラーに対してバイト長制限(この場合は 16 バイト)を課しました。8 バイト制限の場合と比較すると、最適なトークン化がわずかに劣る結果となるため、この変更は効果的でした。
Results
少なくともいくつかの玩具問題において、証明可能な最適なトークナイザーを見つけることができました。私が最も誇りに思うのは、『傲慢と偏見』に対する語彙サイズ 512 の最適トークナイザーです。このアルゴリズムは約 12 回の反復で収束し、所要時間は 1 日強でした。
この同じ問題に対して、語彙サイズを512から1024に増やしてみたところ、サイクル制約だけでは最適解を見つけるのに十分ではないことがわかりました。他のカット族を再び追加した後でも、下限は依然として大幅に変動し続けており、私の最新のランはまだ完了していません。間違いなく、ここにも発見すべき他のカット族が存在しており、1024語彙の問題を解決するにはそれらの一部が不可欠である可能性さえあります。
今後の課題
現時点で、私の実験における主なボトルネックは線形計画法(LP)の求解時間です。多くの実験において、各LP求解には数時間から数日がかかります。HiGHS、SCIP内のソルバー、そしてOR-Tools PDLPといういくつかのソルバーを試しましたが、すべてが高度に制約された私のLPに対して処理能力を失い始めました。私の推測では、カット平面法(cutting plane approach)によって退化したLPが生じており、これが改善の余地がある潜在的な領域であると考えられます。
一般的には、誰かがこの取り組みをより大規模なコーパスへとスケールアップし続ける姿を見てみたいです。私が探求してきたカット族が、より困難な問題に対して十分であるとは考えにくく、探索すべきアイデアの豊かな空間が存在することは間違いありません。
また、pretok enizer を削除する試みも見てみたいと思います。現在、この pretokenizer があるために LPs が非常に大きくなっており、繰り返し出現する単語をマージすることができないためです。Pretokenizer を削除すると、単語ベースのカット戦略を使用できなくなります。例えば、私の一部のカット戦略では、各単語に対して有効な整数解のすべてを列挙し、これらの組み合わせを変数の部分集合に投影します。これらの戦略は、「単一の巨大な単語」からなるデータセットに対して完全に再構築する必要があります。
結論
これは面白いプロジェクトであり、私からのわずかなガイダンスだけで Codex が研究ループ全体を実行する様子を見られたのは楽しかったです。今後もこれを使って遊びたいと強く願っていますが、それは「LP の実行が遅い」という問題に対する解決策を見出すことに依存しています。
このプロジェクトにおける非常にハック的な Codex による実装は Github で公開されています。参考までに、私が発見した Pride and Prejudice のための最適化された語彙は こちら にあります(コードベースが 2 つの特殊トークンを予約しているため、実際の語彙サイズは 510 です)。
原文を表示
In this post, I will present an algorithm that was able to compute an optimal tokenizer in some
settings. This result is cool because optimal tokenization is theoretically intractable, but seems to be solvable in
practice. My finding is very similar to various results on the Traveling Salesman Problem (TSP), where
even difficult instances can be solved optimally using cutting-plane techniques.
I'll highlight that, while this result is cool, there are a few reasons that it isn't necessarily
*useful*. First, the existing state of the art was already somewhat close to optimal (often within
1%). Second, even if a tokenizer is optimal on the *training data*, it may not generalize as well
as other tokenizers when evaluated on held out test data. Finally, inefficient tokenizers are basically
fine: you can pay for the cost of a less efficient tokenizer by slightly increasing your vocabulary
size.
Despite the above caveats, I had a really fun time working on this project, and I hope others will be
interested in pushing the frontier of this problem as well.
Background: Tokenizers
Frontier LLMs are typically trained on sequences of integers known as *tokens*. Each token refers to
some sequence of bytes, and these byte sequences often correspond to common words. For example, in the
GPT-5 tokenizer, the token 290 corresponds to the bytes “ the”, and 6602 corresponds to
“ token”, so the text “ the token” can be encoded as the sequence [290, 6602].
The mapping from tokens to bytes, known as the “vocabulary”, is fixed before the LLM is even
trained. Typically, we try to find a vocabulary that compresses a slice of training data. In particular,
we would like to pick a vocabulary of a fixed size that minimizes the number of tokens required to encode
the data. The dominant technique for finding such a vocabulary is [byte-pair encoding
(BPE)](http://www.pennelynn.com/Documents/CUJ/HTML/94HTML/19940045.HTM), a decades-old greedy compression algorithm.
Tokenization as integer linear programming
In a recent paper, Tempus et al. connected
tokenization to integer linear programming. The basic idea of their approach is to represent the entire
dataset's tokenization as a set of integer variables.
In this formulation, there's a “color” variable for each possible vocabulary entry. In
particular, we create one color variable for every unique substring of the dataset. A color variable is 1
if the corresponding byte sequence is in the vocabulary, or 0 otherwise. We add a single constraint to
force the sum of color variables to equal the target vocabulary size.
A color corresponds to some sequence of bytes, but a given sequence of bytes may occur many times
throughout the dataset. For each occurrence of a color, there's a separate “edge” variable.
The edges work together to encode an actual tokenization of the dataset. If an edge is 1, then the
edge's corresponding token is used in this particular place. The objective of our linear program is to
minimize the sum of all the edge variables, i.e. the number of tokens used to encode our dataset.
For example, in the below picture, we tokenize the word “Queue” as the tokens [“Q”,
“ue”, “ue”]. We could alternatively have tokenized it as [“Qu”,
“e”, “ue”], but that is not the tokenization indicated by the current ILP
solution, since the edge variables for the initial “Qu” and “e” edges are 0.
We constrain the LP in two ways. First, we can't use a token if it's not in the vocabulary. To this end,
we constrain each edge variable to be less than or equal to its corresponding color variable. Second, we
want to make sure that we tokenize the dataset in exactly one valid way. To this end, we add flow
constraints: for each byte position in the dataset, we want the sum of edges flowing into this position
to be equal to the sum of edges flowing out of this position, with the exception of the boundaries. For
the first and last positions, we want the flow out or flow in to be 1. In an integer solution, you can
see flow constraints as asserting the following: *any point that an edge goes into must have an edge
going out of it, except the first and last positions*.
If all the variables were integral and constrained to [0, 1], then this linear program is enough to encode
the optimal tokenization. However, since we cannot solve arbitrary integer linear programs efficiently,
Tempus et al. relax the ILP to a continuous LP and solve this with a well-optimized solver.
The solution to the continuous LP is not generally integral. We can see an example of this below, where we
have two superimposed tokenizations of the word “Queue”: either we encode it as
[“Q”, “ue”, “ue”], or as [“Qu”, “e”,
“ue”]. The problem with this solution is that our color variables sum to 2.5, but we've
actually used four total colors, so we haven't actually found an optimal vocabulary of size 3. In
general, we might end up with many more non-zero color variables than the actual vocabulary size we are
targeting.
Tempus et al. propose to “round” the color variables in a few different ways, achieving an
integral but suboptimal solution to the ILP. The solution to the continuous LP gives a *lower bound*
on the optimal solution's token count, and the rounded tokenizer gives an upper bound.
One other caveat I should mention about this work: to make it tractable, we pretokenize the dataset (spit
it into words) and merge repeated words (with corresponding weights in the objective based on how many
times a word occurs). This drastically reduces the number of variables in the LP, but it does mean our
solution is only “near optimal” under the pretokenizer. Today, I won't try to remove this
restriction, but it would be an interesting direction for future work.
Cutting planes
I spent some time last year learning about the Traveling Salesman Problem (TSP), which can also be posed
as an ILP. We can often use cutting planes to solve this ILP:
first, we turn the ILP into a continuous LP, then add extra constraints until the optimal solution is
integral. The constraints must be provably “valid”–that is, never violated for actual
integer solutions. In theory, *any* ILP can be “turned into” a continuous LP with extra
constraints, but the magical extra constraints may be intractable to find. TSP solvers use a number of
heuristics to efficiently find such constraints in most practical cases. The authors of Corcorde (a TSP
solver) wrote an entire book about techniques for finding useful cuts.
After reading Tempus et al., I wondered if we could apply cutting planes to the tokenization ILP. The
method would work like this: first, solve the initial LP to get some lower and upper bound on the optimal
tokenization; then, keep adding valid cuts to the LP and re-solving it to make these bounds closer and
closer together–until they meet at the optimal solution.
It takes a lot of work and creativity to come up with “cut families” that might be useful for
an ILP, so instead of banging my head against this myself, I set Codex on the task. At first, it found
almost nothing–some of the cuts improved the LP bound a tiny bit, but most of the things it tried
were surface-level word heuristics.
Then I tried another approach: brute force. A “cut” is some constraint that is satisfied by
all integer solutions, but violated by the current fractional LP solution. We can find cuts by
constructing an auxiliary linear program with one constraint for each possible integer solution, and
optimizing it to maximize the violation of the fractional solution. We can't do this for the entire LP,
since the number of rows blows up exponentially, but we can do it for small interesting
“projections” of the LP. Codex proposed to look at all the variables in pairs or triplets of
words with common fractional colors.
The above technique found really good cuts that improved the rounded tokenizer and raised the lower bound.
However, this approach is really inefficient, since it involves solving (pretty large) auxiliary LPs for
a huge number of word pairs. The next trick was to have Codex look at the actual cuts we were finding.
By looking at the brute force cuts, Codex discovered several cut templates that can be found more
efficiently. The most effective family seems to be what Codex named “cycle constraints”. This
technique finds pairs of overlapping fractional edges in the current LP solution. For example, we might
find an overlapping (i.e. conflicting) pair of edges for colors A and B. We then find a few pairs that
share common colors, such as another pair for colors B and C and another for C and A. We can then create
a constraint out of the corresponding edge and color variables that is often violated by the continuous
LP solution but never violated by a valid integral solution.
Finding the cycle of conflicting pairs AB, BC, CA can be done with a neat trick: construct a graph where
the vertices are colors, and connect any pair of colors that overlap as fractional edges in the current
solution. After you have this graph, run DFS to find cycles in it. Codex implemented this all
autonomously, though I'm sure it's not an original trick.
Experimental setup
I was pretty hardware limited for this project, using only my Mac Studio and Mac mini. There aren't great
GPU-accelerated LP solvers for this hardware, so I mainly leaned on the HiGHS single-core simplex solver. Sadly, I found that this solver sometimes
stalls, especially for later iterations where we've applied a lot of (potentially degenerate) cuts.
To run experiments in a reasonable amount of time on this hardware, I studied single eBooks. I needed the
LPs to remain small enough to solve on the CPU, so I kept the pretokenization approach of Tempus et al.
Finally, I adopted some heuristics from Tempus et al. to make the LP smaller, such as dropping color
variables for substrings that appear less than 5 times. I also imposed a byte length limit on
colors–in this case 16 bytes. I found that this made a difference compared to an 8-byte limit,
where the optimal tokenization was slightly worse.
Results
I was able to find provably optimal tokenizers on at least a few toy problems. The one I am most proud of
is an optimal tokenizer of vocab size 512 for the book Pride and Prejudice. The algorithm converged in
about a dozen iterations, taking a bit over a day.
I tried increasing vocabulary size from 512 to 1024 on this same problem, and found that cycle constraints
weren't enough on their own to find an optimal solution. The lower bound continued to move significantly
after I added back other cut families, though my latest runs are still not finished. There are, without a
doubt, other cut families to be discovered here as well, and some may even be necessary to
solve the 1024-vocab problem.
Future work
At this point, the main bottleneck in my experiments is LP solve times. In many of my experiments, each
LP solve can take between hours and days. I've tried a few solvers (HiGHS, the solver in SCIP, and OR-Tools
PDLP), and all of them start to choke on my highly constrained LPs. My suspicion is that my cutting plane
approach is creating degenerate LPs, and this could be a potential area for improvement.
Generally, I'd love to see someone continue to scale up this work to larger corpora. I doubt that the cut
families I've explored are enough for harder problems, and there is surely a rich space of ideas to
explore.
I'd also love to see somebody remove the pretokenizer. This currently makes the LPs quite large, since we
don't get to merge repeated words. Removing the pretokenizer also eliminates the ability to use
word-based cut strategies. For example, some of my cut strategies enumerate all of the valid integer
solutions for each word, and then project these combinations into a subset of variables. These strategies
need to be completely reframed for a “single huge word” dataset.
Conclusion
This was a neat project, and it was fun to see Codex do an entire research loop with just a small bit of
guidance from me. I really hope to keep playing with it, but this is contingent on figuring out a
solution to the *slow LP* problem.
The incredibly hacky Codex implementation of this project is available on Github. For reference, the optimal
vocabulary for [Pride and
Prejudice](https://www.gutenberg.org/cache/epub/37431/pg37431.txt) that I found is here (note that the
vocab is actually 510, because the codebase reserves two special tokens).
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み