ライフサイエンス分野におけるAIのリスクと限界
AIスタートアップのエンジニアが、生命科学分野におけるAI適用の過大評価とデータ品質への依存性を指摘し、基礎研究の重要性を強調する。
キーポイント
データ品質と基礎研究の軽視
AIモデルへの投入だけで成果が得られるという誤解があり、新バイオマーカーやアッセイの開発など、従来のラボ研究への投資不足が懸念される。
AlphaFold成功の背景と限界
AlphaFoldの成功は単なるアルゴリズム革新ではなく、PDBやCASPといった長年の高品質データ基盤と競争制度に依存しており、すべての分野で同様のデータが利用可能ではない。
生物学的検証の欠如と責任所在
外部から見た数値指標が強くとも生物学的意味を欠くケースがあり、AIシステムの誤りを発見し責任を負うのは深い生物学専門知識を持つ人間であるべきという課題提起。
ドメイン専門家の不可欠な役割とインセンティブの欠如
AIモデルの結果は微生物学者などの専門家の深い関与によってのみ検証可能だが、誤りの修正や反論は資金や評価の面で報われないため、これらの作業が軽視されがちである。
データリーケージと過学習のリスク
トレーニング、検証、テストセットの適切な分離は困難であり、既存データベースとの重複(データリーケージ)や過学習により、AIが生成した結果に重大な誤りや非現実的な結論が含まれる可能性がある。
データ作業とモデル開発の乖離
機械学習実務者の調査により、データ収集に追加の負担がかかるものの報酬や時間が与えられず、役割間の早期統合不足により展開時にエラーが発生する「データカスケード」の問題が指摘されている。
規模の錯覚とシステムバイアス
大規模データやモデルは権威あるように見えるが、系統的なバイアスや設計上の欠陥がある場合、規模を拡大しても解決せず、むしろ誤った結果を生む可能性がある。
重要な引用
One big concern is the assumption that we already have all the data we need, and just need to throw it into a model for amazing outputs.
AlphaFold is probably the biggest success story, and it is genuinely impressive — but people lose sight of the fact that the Protein Data Bank (PDB) and the Critical Assessment of Structure Prediction (CASP) competition are what made it possible.
The other thing that always strikes me is how hard it is to evaluate these models without deep biological expertise.
The exciting AI result gets into the prestigious journal, and refuting it is a much harder road.
This case points to the need for deep integration with domain experts — microbiologists closely involved throughout.
"Everyone Wants to Do the Model Work, Nobody Wants to Do the Data Work"
影響分析・編集コメントを表示
影響分析
この記事は、生命科学におけるAIブームに対する冷静な批判として、単なるアルゴリズム革新だけでなく、高品質なデータ基盤と基礎研究の重要性を再認識させる意義がある。業界に対し、AI導入だけでなくデータ収集インフラやラボ研究への投資バランスを見直すよう促す重要な警鐘となっている。
編集コメント
AIのポテンシャルを論じる際、その基盤となるデータインフラとドメイン専門家の役割を見落としがちですが、この記事はそのバランスの重要性を明確に示しています。
数学、機械学習、AI エシックスに約20年間取り組んだ後、私は再び学校に戻り、微生物学・免疫学の修士号を取得しました。先月、KAMI Think Tank の共同創設者である Kamayani Gupta が、生命科学における AI のリスクと限界についての Q&A を開催し、私をゲストとして招いてくれました。以下は、その会話の編集・短縮版です。あるいは、以下の動画で完全な議論をご覧ください:
Kamayani: 最初の質問ですが、生命科学全体で AI がかなり幅広く応用されており、実際の構築状況に対する過度な期待(ハイク)が横行しています。どこにおいて、自信や期待が実際の科学的理解を先行しているとお考えですか?
Rachel: これは大きな問題です。私は AI スタートアップで働いており AI に興奮していますが、その信頼性や過剰な期待は往々にして現実を上回ってしまいます。一つの大きな懸念点は、必要なデータはすでにすべて揃っており、それをモデルに投入するだけで素晴らしい成果が得られるという前提です。私が心配するのは、新しい種類のデータについて考えることへの投資が不足しているのではないかということです。データのタイプと品質が、結果の質を決定づける限界条件となります。医療分野では、患者記録や電子カルテ(EHR)が画期的な発見をもたらすとよく言われますが、多くの場合、私たちはまだ発見されていない新たなアッセイやバイオマーカーが必要なのです。実験室での研究は依然として極めて重要であり、AI アプリケーションへの資金投入に比べて、その分野への投資が不足しているのではないかと懸念しています。
AlphaFold はおそらく最大の成功事例であり、本当に印象的ですが、人々は Protein Data Bank (PDB) と Critical Assessment of Structure Prediction (CASP) 競争がそれを可能にしたという事実を見失いがちです。PDB は 1970 年代に郵送された磁気テープから始まりました。CASP は慎重に設計され、1990 年代から継続して開催されています。AlphaFold チームの革新は本当に印象的ですが、彼らは問題に適した適切な高品質なデータが必要でした。多くの場合、データが問題に適合していないにもかかわらず、「これが手元にあるデータだ、これを使おう」という声ばかりが上がります。
Kamayani: それは非常に重要な事例ですね。CASP は昨年も資金援助を失いかけていましたが、そのプログラムと PDB が AlphaFold の存在にとっていかに重要かを人々が指摘したことで救われました。これは 2 年前に設立された企業による数十年の取り組みではなく、何十年にもわたる積み重ねです。もう一つ常に私を驚かせるのは、深い生物学の専門知識なしにこれらのモデルを評価することがどれほど難しいかということです。外部からは指標が非常に強力に見えても、実際の生物学的整合性が取れていない場合があります。では、生物学における AI システムが誤っている場合、通常誰が発見し、今日構築されている新しいシステムに対する所有権はどこにあるのでしょうか?
レイチェル:それはまさに正しい質問です。あなたが私の酵素分類に関するブログ記事を読み、その後私と連絡が取れるようになったのは、それが非常に重要なケーススタディだからです。Nature Communications に掲載されたこの論文では、チームは 2,200 万個の酵素を用いて、アミノ酸配列から酵素機能を予測しました。単独で見た場合、この論文は一見妥当に見えました——トレーニングセット、検証セット、テストセットを有しており、その後、未知の機能を持つ 450 個の酵素にモデルを適用し、そのうち 3 つを実験室で確認したからです。
しかし実際に起きたことは、ある微生物学者であるヴァレリー・ド・クレシー=ラガール博士(Dr. Valérie de Crécy-Lagard)が、その論文の結論が誤りであると認識したことです。彼女は過去 10 年以上にわたりその酵素を研究しており、すでに実験室でその結論を否定していました。他の結果についても詳しく調べたところ、数百ものエラーが見つかりました。「新規」酵素とされたもののうち 135 個は既に UniProt に登録されており、これは重大なデータリーク(data leakage)です。また、一部の結果は明らかに不自然でした。例えば、ミコシアルを合成しない大腸菌(E. coli)の酵素にミコシアルシンターゼの機能を割り当てたケースなどです。さらに、12 種類の異なる酵素が同じ狭義の機能に割り当てられており、これは過学習(overfitting)を示唆しています。
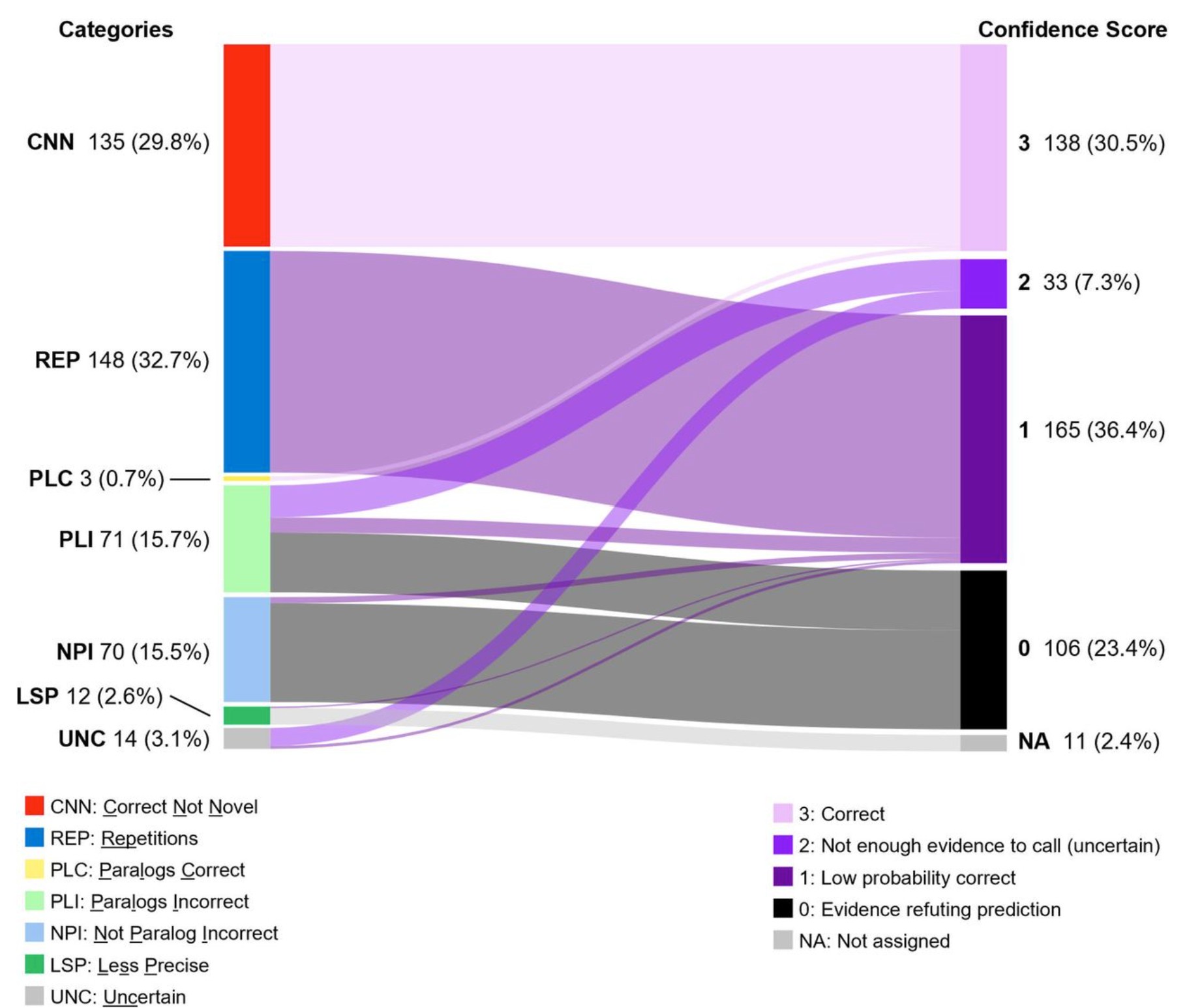
酵素分類論文におけるエラーのカテゴライズ(de Crécy-Lagard, et al., 2025)
これらの問題すべては、特定の専門知識を持つ人物が偶然その論文を読まなければ発見されなかったでしょう。その後、彼女は反論を掲載してもらうために多大な困難に直面しました。著者に連絡し、Nature Communications に問い合わせ、チームを結成し、複数の却下を経験したのです。これはまさにインセンティブの問題を示しています:魅力的な AI の結果は権威あるジャーナルに掲載される一方で、それを否定する道ははるかに険しいのです。
Kamayani: 驚くべきことです——エラーの存在もさることながら、記録を訂正することがいかに困難だったかという点も。これは所有権の問題を提起します:何か問題が起きた際、責任はモデルを構築した企業にあるのか、それを利用した企業にあるのか、あるいは評価を行った規制当局にあるのでしょうか。
Rachel: これはあらゆるレベルで発生する問題です。この事例は、ドメインの専門家との深い統合が必要であることを示しています——微生物学者が最初から最後まで深く関与する必要があります。また、エラーチェック作業に対して報奨がない分野であることも示しており、その結果、見落とされてしまいます。反論論文は興味深く重要な研究でしたが、そのような仕事に対する資金援助や支援、あるいは評価はありません。
そして、データリークを回避するトレーニング/バリデーション/テストの分割を構築することは、実際に困難な場合もあります。CASP 競争(注:コンペティション)で見たように、これを適切に行うためには、実質的な資金を持つ専任委員会が必要でした。個々のチームは往々にしてリソース不足であり、これらの方法論的な質問は、モデルアーキテクチャに対するほどの注目を集めることがないのです。
Kamayani: そして、私が次に尋ねようとしていたことへの答えも既にお聞きになったと思います。AI 研究や導入において、最も懸念されるインセンティブとは何でしょうか?
Rachel: 私は「誰もモデル作業をしたがらないが、データ作業は誰もしない」という論文を愛しています。これはデータサイエンスに携わる私たちの多くが共感できる素晴らしいタイトルです。この研究者たちは 3 つの大陸にまたがる 60 人以上の機械学習実務者をインタビューし、データカスケードについて議論しました。つまり、高リスクの機械学習アプリケーションにおいて何が失敗する可能性があるかという点です。
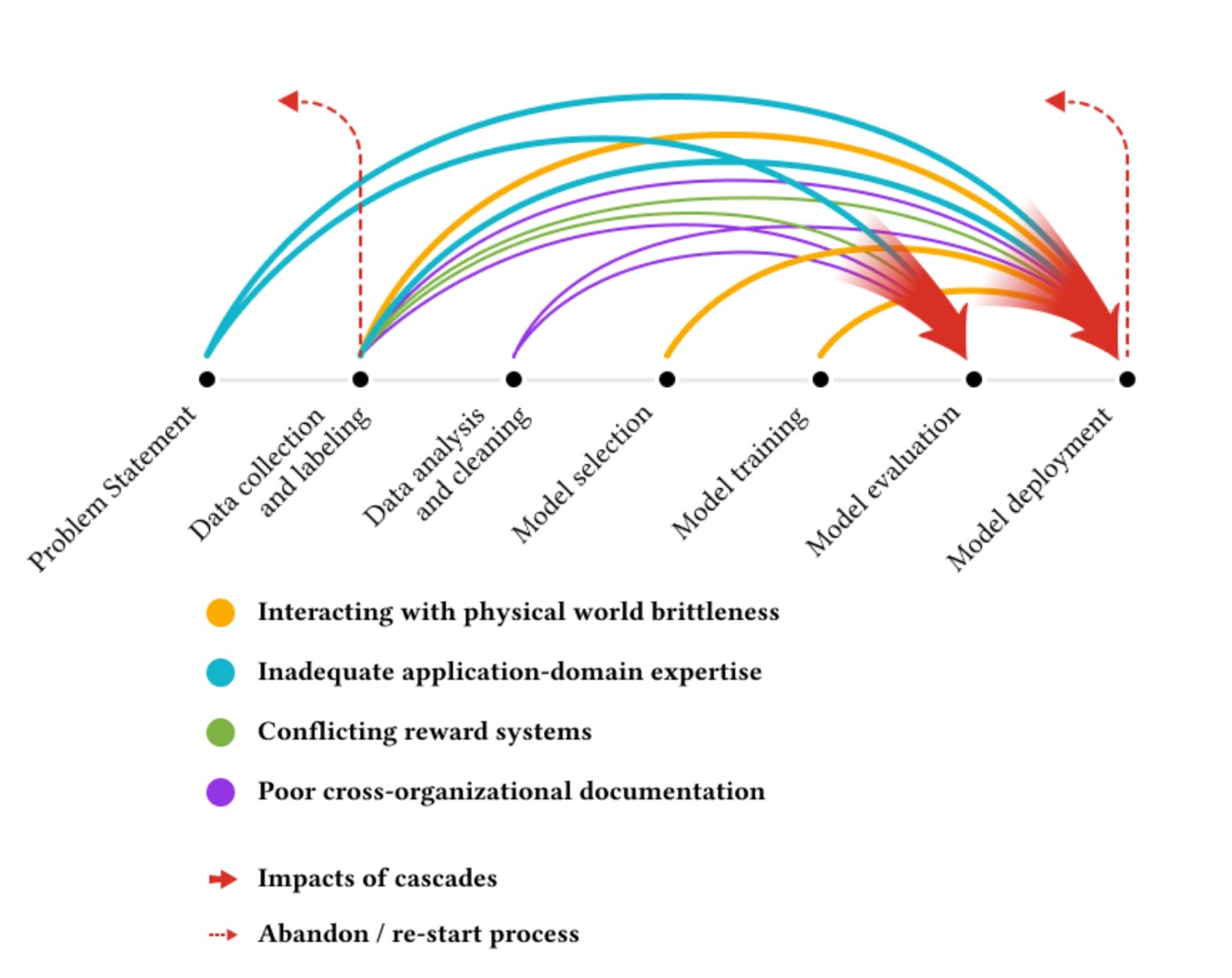
機械学習導入におけるカスケード故障の原因(Sambasivan 他、2021)
多くの場合、現場の担当者に追加データの収集を求められながら、そのための追加報酬や時間が与えられていませんでした。現場での測定システムが変更されても、モデルを構築しているコンピュータラボにはその情報が伝わってきません。ある事例では、密猟防止のためのモデルを導入した際、密猟防止チームから得られた結果が誤っていると指摘されました。原因は基盤となるデータセットに問題があったためです。もし当初から役割間の連携をより強化していれば、この問題は防げたはずです。多くの場合、プロセス全体を通じて協力を確保することが重要なのです。
Kamayani: 大規模なデータセットや巨大なモデルには権威ある空気が漂います。「大きいほど良い」という考えは私たちの心に深く刻まれています。しかし、スケールが大きくなることはいつから安心材料ではなく、誤解を招くものとなるのでしょうか?
レイチェル:規模はしばしば誤解を招くものです。特に、データにランダムなノイズではなく体系的なバイアスがある場合、特定の種類のデータが欠落している場合、あるいは根本的なパラダイム自体が間違っている場合にその傾向が強まります。一例として、COVID-19の初期段階にはイギリスに「Zoe」というアプリがありました。これはもともと食事と栄養を記録するトラッカーでしたが、COVID-19症例を追跡するために迅速に改修されたものです。このアプリは短期間の呼吸器ウイルスを対象に設計されていたため、人々が長期的な後遺症(ロング・コビッド)を発症した際、症状を適切に記録することができませんでした。神経学的な症状、疲労感、ブレイン・フォグ(脳霧)といった要素は、あらかじめ設定された選択肢に含まれていませんでした。人々は手動で症状を入力し、アプリが長期追跡に対応していなかったため、数ヶ月間にわたって毎日同じ情報を再入力する必要がありました。
このデータはその後、ロング・コビッドの有病率に関する研究調査に使用されましたが、「ユーザーがアプリの使用を止めたので、彼らは回復したに違いない」といった誤った前提に基づいていました。私はこの問題を浮き彫りにしてくれた研究者ハンナ・デイビス氏に感謝します。単にデータがその目的のために設計されていなかったのです。ユーザー数をさらに増やしても解決にはなりませんでした。これらの問いに答えるためには、根本的に異なる設計が必要でした。
カマヤニ:そしてロング・コビッドは非常に多様です。人それぞれが異なる影響を受けます。そのため、膨大なデータセットがあったとしても、収集メカニズム自体が間違っていれば、その上にモデルを構築しようとした瞬間に、結果は混沌としてノイズの多いものになってしまいます。
レイチェル:特に、収集するデータの種類に関わらず、その収集方法の設計にはどのような決定が下されているかを忘れないことが重要です。何を対象に含めるか、どんな質問をするかといった決定が、最終的にデータセットの姿を形作ります。人々は往々にしてデータを客観的な真実だと考えがちですが、実際には非常に重要な一連の決定を通じて構築されたものに過ぎません。
そのケーススタディからもう一つの重要な点は、患者が Zoe アプリの開発者に「これは私のニーズを満たしていない」と連絡し、そのフィードバックが反映されなかったという事実です。これは、ツールがどのように患者に不具合をもたらしているかを第一線で知る患者の声を聴くことの重要性を浮き彫りにしています。
カマヤニ:多くの場合、こうしたフィードバックループ自体が生成されることさえありません。そして、AI モデリングを利用する人が増えるにつれて、公開されたりデータベースに読み込まれたりした誤った予測は単にそこに留まるのではなく、次のモデルのトレーニングデータとして利用されてしまいます。
レイチェル:私は、診断が遅れがちだったり診断がなされにくい疾患においてこの現象が起こることを懸念しています。モデルはその疾患を実際よりも稀であると認識し、したがって発生確率が低いと判断してしまいます。例えばループスでは、平均的な診断までの期間は 6 から 8 年にも及びます。まだ正確な診断を受けていない患者や、診断に至る前に諦めてしまう患者がどれほど多いか考えてみてください。これにより、医療データに不備や欠落が生じます。こうした不完全で欠けたデータがモデルに投入され、結果として自己強化型のフィードバックループが形成されてしまいます。
カマヤニ:では、チームが本当に患者への害を減らしたいと願うなら、何が根本的に変わる必要があるのでしょうか?それが「AI は速く動く」というメッセージには逆説的に思えるかもしれないが、よりゆっくり進むことを意味するとしてもです。
レイチェル:遠くへ行くためには、まずはゆっくり進みましょう。私は、基礎的な因果メカニズムに焦点を当てた研究への投資を継続することが本当に重要だと考えます。現在の AI システムは、既存のデータポイント間の曖昧な補間を行っていますが、これは価値あることではあるものの、それゆえにトレーニングデータの範囲を超えた真に新しいものを私たちに与えることはできません。新たなパラダイムや異なる因果メカニズムが必要となる研究はまだ必要です。
私はアジット・チャクラバルティ氏を引用します。彼は製薬開発の分野で幅広く活動し、「フランケンセル」という概念を考案しました。人々が異なる論文から経路を組み合わせて取り上げる際(これは AI や数理モデリングが促す行為ですが)、単一の細胞内ですべてが起こり得ないような図式ができてしまうことがあります。がん研究では、個々の矢印はそれぞれ正しいとされる経路が発表されていますが、それらがすべて同じ細胞内で起こるわけではありません。これが AI における誘惑です:結果を無作為に組み合わせ、背後にあるメカニズムについて考えずに済ませてしまうことです。彼は、がんの発生は回路図としてではなく、ランダム性を伴う進化過程として理解されるべきだと主張しています。
それ以外にも、実験室科学への継続的な投資が重要です。そして、これまで議論してきたことの多くは、データ収集と処理の各段階におけるドメイン専門家、モデル開発者、患者、そして実際にツールを使用する臨床医との、意味のある継続的な協力に帰着します。
カマヤニ:聴衆へ移る前に最後の質問です。最近、ライフサイエンス分野で非常に興味深く革新的なユースケースとして見られたものはありますか?
レイチェル:T 細胞結合(T-cell binding)については、私が詳しく調査した分野の一つです。まだ多くの作業が残されている分野であり、その周辺では現在も競争が行われており、私はそれを非常に魅力的に思っています。構造化された競争がイノベーションを推進する仕組みは、今なお私を興奮させます。アルファFold(AlphaFold)やアレックスネット(AlexNet)のように、長年続いていた競争から生まれた事例も見てきました。
これらの競争はまた、人々にデータについて明確にすることを強要します。これが私が AI に対して持つ大きな留保事項です。明確にする必要があります。「私が使用しているのはこのデータであり、これらが制約条件で、これらがバイアスであり、収集されなかったものはこれである」と。ティンニット・ゲブル(Timnit Gebru)の「Data Sheets for Datasets」論文を私は愛しています。どのようなデータを収集したか、適切な用途は何か、そしてどこでは適用できないかを具体的に記述することです。明確なパラメータ内で機械学習(machine learning)を使用すれば、それは非常に価値のあるものとなります。
カマヤニ:私たちが協力している多くの人々がスキルアップを試みています。特に生物学者が AI 分野へ移行するケースなどです。これらの難しいトピックを学ぶために、どのような技術や戦術をお勧めしますか?
Rachel: 私は fast.ai の共同創設者であり、そこでは現在も AI やディープラーニングに関する貴重な無料コースを提供しています。現在は Answer AI で、AI を用いて問題を理解しやすい小さな要素に分解し、常にプロセスに関与しながら問題の本質を深く理解する問題解決スタイルに基づいた有料コースを展開しています。
Kamayani: 聴衆からの質問です:「知っておくべき面白い AI ツールはありますか?」
Rachel: 私の偏った回答ですが、SolveIt です。現在開発中のツールで、Jupyter ノートブックのような形式で、ノートブック内で直接 AI プロンプトを実行できます。私が特に気に入っている機能は、AI の出力を編集できる点です。これにより、AI と長く議論してコンテキストを汚染するのではなく、直接修正することができます。このツールは、ユーザーがプロセスから離れて巨大なソリューションを構築させるのではなく、常にプロセスに関与し続けるように設計されています。
Kamayani: ありがとうございます、Rachel。あなたとお話しするたびに新しいことを学ばせていただいています。Rachel のブログや answer.ai もぜひご覧ください。また、KAMI Think Tank は毎月イベントを開催していますので、興味があればメンバーシップにご参加ください。皆様、ありがとうございました。素晴らしい夜をお過ごしください。
Rachel: ご招待いただき、本当にありがとうございます!とても楽しい時間でした。
関連記事:
ディープラーニングが栄光を博す一方、深い事実確認は見過ごされる
AI の進展を阻む医療データの欠如
ライフサイエンスにおける AI のギャップとリスク
医学における機械学習の問題
原文を表示
After nearly 20 years focused on mathematics, machine learning, and AI ethics, I went back to school and completed a Masters in Microbiology-Immunology. Last month, Kamayani Gupta, co-founder of KAMI Think Tank, hosted me for a Q&A about risks and limitations of AI in the life sciences. What follows below is an edited and shortened version of our conversation. Or watch our full-length discussion in the video here:
Kamayani: My first question: we’re seeing AI applied quite a bit throughout life sciences, and there’s a lot of hype versus what’s actually being built properly. Where do you think confidence is running ahead of actual scientific understanding?
Rachel: This is a big issue. I’m excited about AI — I work for an AI startup — but the confidence and hype often outpace reality. One big concern is the assumption that we already have all the data we need, and just need to throw it into a model for amazing outputs. What worries me is that we may be underinvesting in thinking about new types of data. The type and quality of data really sets limits on the quality of results. With medicine, I see this assumption that patient records and electronic health records will unlock breakthroughs — whereas in many cases we need new assays, new biomarkers we haven’t discovered yet. There’s still a huge need for bench and lab research, and I’m worried that is not getting the funding that AI applications are.
AlphaFold is probably the biggest success story, and it is genuinely impressive — but people lose sight of the fact that the Protein Data Bank (PDB) and the Critical Assessment of Structure Prediction (CASP) competition are what made it possible. The PDB started in the 1970s on magnetic tape sent through the mail. CASP was thoughtfully structured and has been running since the 1990s. The AlphaFold team’s innovations are truly impressive, but they needed the right type of high-quality data that was a good fit for the problem. In many cases the data isn’t the right fit, and people just say, “this is what we have, let’s go for it.”
Kamayani: That’s such an important example — CASP almost lost its funding last year, and it took people calling out how critical that program and the PDB were to AlphaFold’s existence. It’s decades of work, not a company spun up two years ago. The other thing that always strikes me is how hard it is to evaluate these models without deep biological expertise. Metrics can look really strong from the outside without the biology actually making sense. So when AI systems in biology are wrong, who usually discovers that, and where does ownership lie for these new systems being built today?
Rachel: That’s exactly the right question. We connected after you read my blog post about the enzyme classification paper, which is a really important case study. Published in Nature Communications, the team used 22 million enzymes to predict enzyme function from amino acid sequences. On its own, the paper seemed sound — they had training, validation, and test sets, and afterwards applied their model to 450 enzymes with unknown functions, checking three in the lab.
What happened is a microbiologist, Dr. Valérie de Crécy-Lagard, who had studied one of those enzymes for over a decade, recognized that the paper’s conclusion about it was simply wrong — she had already disproven it in the lab. When she dug into the other results, she found hundreds of errors. 135 of the “novel” enzymes already appeared in UniProt — significant data leakage. Some results were blatantly implausible, like attributing mycothial synthase to an enzyme in E. coli, which doesn’t synthesize mycothial. And 12 different enzymes were assigned the same narrow function, pointing to overfitting.
Categorizing errors from the enzyme classifcation paper (de Crécy-Lagard, et al, 2025)
None of this would have been caught without someone with her specific expertise happening to read the paper. She then had enormous difficulty getting her rebuttal published — she contacted the authors, contacted Nature Communications, assembled a team, and went through multiple rejections. That really illustrates the incentive problem: the exciting AI result gets into the prestigious journal, and refuting it is a much harder road.
Kamayani: That’s striking — both the errors and how hard it was to correct the record. It raises the question of ownership: when something goes wrong, does responsibility lie with the company that built the model, the company that used it, or the governing agency that assessed it?
Rachel: It occurs at so many levels. This case points to the need for deep integration with domain experts — microbiologists closely involved throughout. It also points to a field that simply doesn’t reward error-checking work, so it falls through the cracks. The rebuttal paper was fascinating and important research, but there’s no funding, support, or recognition for that kind of work.
And it can be genuinely hard to construct a training/validation/test split that avoids data leakage. We saw with the CASP competition that it took a dedicated committee with real funding to do it well. Individual teams are often under-resourced, and these methodological questions just don’t get the attention that model architecture does.
Kamayani: And I think you’ve already answered what I was going to ask next — what incentives in AI research or deployment worry you most?
Rachel: There is a paper I love called “Everyone Wants to Do the Model Work, Nobody Wants to Do the Data Work”– a great title that most of us in data science can relate to. The researchers interviewed over 60 machine learning practitioners across three continents and talked about data cascades: what can go wrong in high-stakes ML applications.
Causes of cascading failures in machine learning deployment (Sambasivan, et al, 2021)
In so many cases, people in the field were asked to collect extra data but weren’t given extra pay or time to do so. Measurement systems would change in the field and that wouldn’t make it back to the computer lab where people were building models. There’s a case where an anti-poaching model, when they got to deployment, was producing results the anti-poaching teams said were incorrect. It turned out there were issues with the underlying dataset. If there had been more integration across roles earlier, that could have been prevented. A lot of it comes down to ensuring collaboration throughout the process.
Kamayani: Large datasets and big models lend this air of authority — bigger is better seems ingrained in us. But when does scale become misleading rather than reassuring?
Rachel: Scale can often be misleading — especially when data has systematic biases rather than random noise, when particular types of data are missing, or when the underlying paradigm is incorrect. An example: early in COVID, there was an app in the UK called Zoe, originally a diet and nutrition tracker that was quickly modified to track COVID cases. It was designed around a short-term respiratory virus, so when people developed Long COVID, they couldn’t log their symptoms properly. Neurological symptoms, fatigue, brain fog — none of those were included in the preset options. People were hand-typing symptoms and having to re-enter them every day for months, because the app wasn’t built for long-term tracking.
This data was then used in research studies on long COVID prevalence, with faulty assumptions like “people stopped using the app, so they must have recovered.” I credit researcher Hannah Davis for surfacing this issue– the data simply wasn’t designed for that purpose. Scaling it to even more users wouldn’t have helped. It needed a fundamentally different design to answer those questions.
Kamayani: And long COVID is so diverse — each person is affected differently — so even with a massive dataset, if the collection mechanism is wrong, you end up with something chaotic and noisy the moment you try to build a model on top of it.
Rachel: Particularly when you lose sight of the fact that no matter what data you’re gathering, there are decisions that go into the design of how you gather it: what you include, what questions you ask — and those shape what the data set looks like. People often think data is objective truth, but it’s constructed through a series of decisions that really matter.
Another important point from that case study: there were patients reaching out to the Zoe app creators saying this isn’t meeting my needs, and that feedback was not incorporated. That really highlights the importance of listening to patients, because they have a firsthand perspective on how a tool is failing them.
Kamayani: A lot of times that feedback loop doesn’t even get generated. And as more people use AI modeling, incorrect predictions that get published or fed into databases don’t just sit there — they become training data for the next model.
Rachel: I worry this happens with diseases that are underdiagnosed or have diagnostic delays — the model sees it as rarer than it is and therefore less likely. Take lupus, where the average time to diagnosis is six to eight years. Consider how many patients have not received an accurate diagnosis yet or who give up before ever finding one. This leads to incomplete and missing medical data. That’s the data getting fed into these models, and you get self-reinforcing feedback loops.
Kamayani: So if teams genuinely want to reduce harm to patients, what fundamental practices have to change — even if that means moving more slowly, which I know is counterintuitive to the “AI moves faster” messaging?
Rachel: Go slow to go far. I think it’s really important that we continue investing in research focused on underlying causal mechanisms. Our current AI systems are doing a fuzzy interpolation between existing data points — valuable, but because of that, they won’t give us something truly outside the scope of the training data. We still need research where new paradigms or different causal mechanisms are required.
I’ll cite Arijit Chakravarty, who has worked across pharmaceutical development and coined the concept of “frankencells.” When people pull together pathways from different papers — something AI and mathematical modeling encourages — you can end up with diagrams that would never all occur in a single cell. In cancer research, there are published pathways where each individual arrow is correct, but they wouldn’t all happen in the same cell. That’s the temptation with AI: throwing results together without thinking about the underlying mechanism. He argues cancer development should be understood as an evolutionary process with randomness, not a circuit diagram.
Beyond that, continuing to invest in bench science matters. And then much of what we’ve discussed comes down to meaningful, ongoing collaboration: domain experts at every stage of data collection and processing, model development, patients, and clinicians who will actually use the tool.
Kamayani: One last question before we go to the audience: what’s been a really interesting or innovative use case you’ve seen in life sciences recently?
Rachel: T-cell binding is something I’ve done a deep dive on. It’s a field where there’s still a lot of work to be done — there’s even an ongoing competition around it, which I find fascinating. The way well-structured competitions can push innovation still excites me. We’ve seen it with AlphaFold and AlexNet, both arising out of competitions that had been running for years.
These competitions also force people to be explicit about their data, and that’s my big caveat with AI. You need to be clear: this is the data I’m using, these are the constraints, these are the biases, this is what wasn’t collected. I love Timnit Gebru’s Data Sheets for Datasets paper: being specific about what data was collected, what the appropriate uses are, and where it wouldn’t apply. When you use machine learning within clear parameters, it’s quite valuable.
Kamayani: A lot of people we work with are trying to upskill, often biologists moving into AI. What technique or tactic would you recommend for learning these hard topics?
Rachel: I co-founded fast.ai, which still has valuable free courses on AI and deep learning. Now with Answer AI we run paid courses around a style of problem solving where you use AI to break things down into small pieces you can understand, keeping yourself in the loop to really understand the problem.
Kamayani: An audience question: “Are there any interesting AI tools we should know about?”
Rachel: My biased answer: SolveIt, which I’m working on. It’s a Jupyter notebook-like where you can run AI prompts directly within the notebook. One feature I love is that you can edit the AI’s output — so instead of getting in a long argument with AI and polluting the context, you can fix it directly. It’s designed to keep you in the loop rather than going off and building huge solutions for you.
Kamayani: Thank you so much, Rachel — every time I speak with you I learn something new. Check out Rachel’s blog and answer.ai. Also, KAMI Think Tank hosts events every month, so join our membership if you’re interested. Thanks everyone, and have a great evening.
Rachel: Thanks so much for hosting! This was a lot of fun.
Related Posts:
Deep learning gets the glory, deep fact checking gets ignored
The Missing Medical Data Holding Back AI
Gaps and Risks of AI in the Life Sciences
Medicine’s Machine Learning Problem
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み