最新オープンアーティファクト(第18号):Arceeの400B MoE、LiquidAIの過小評価された1Bモデル、新型Kimi、そして活発な月の予感
Interconnects は、LiquidAI の高効率小規模モデルや Arcee の大規模 MoE など、2026 年に向けた注目すべきオープンソース AI モデル群と業界の動向を解説している。
キーポイント
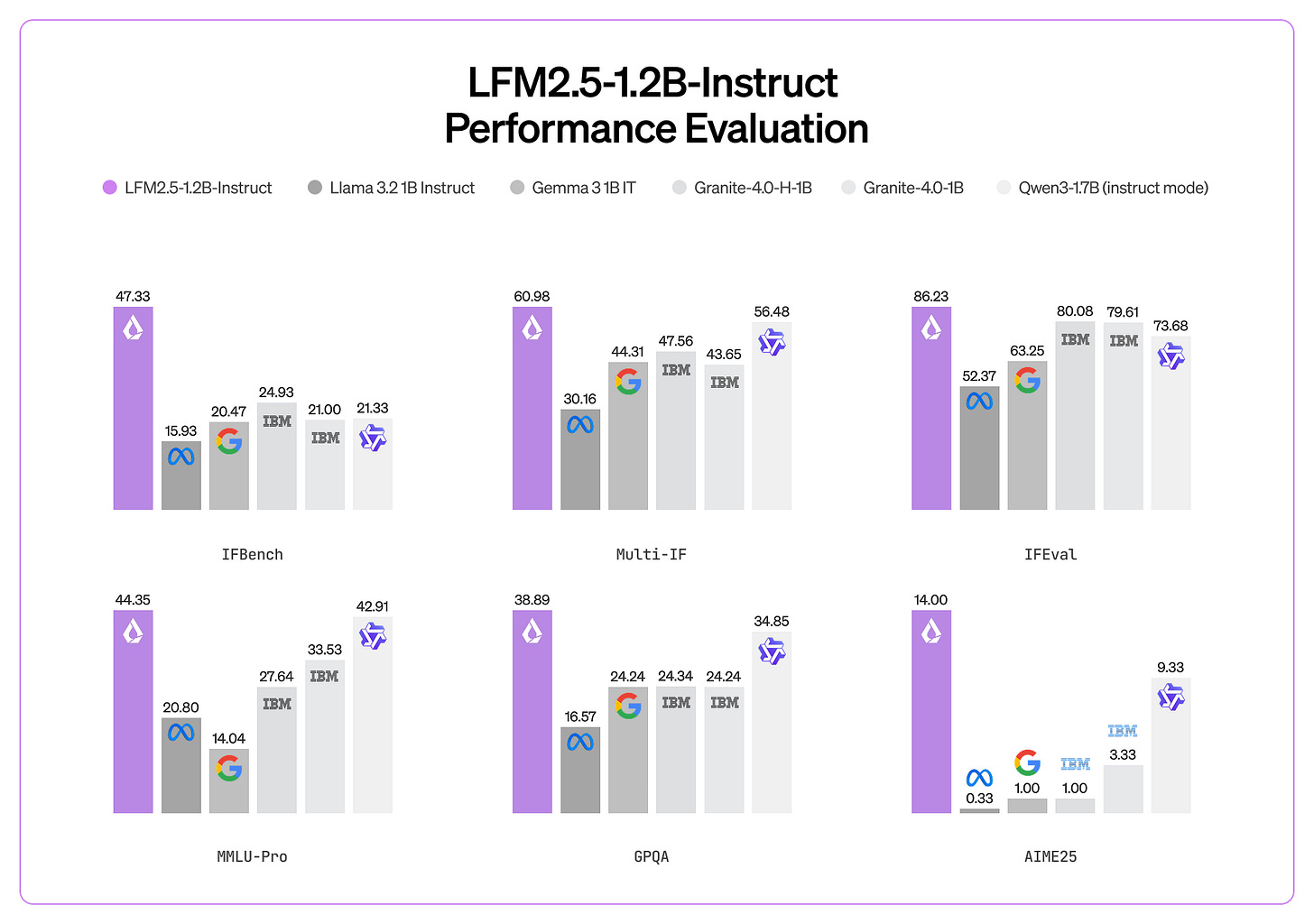
LiquidAI の LFM2.5-1.2B-Instruct の驚異的性能
10T から 28T トークンへの継続事前学習により、サイズが 3 倍小さいにもかかわらず Qwen3 4B に匹敵する性能を発揮し、特に日本語・ビジョン・オーディオ版も同時にリリースされた。
Arcee の超スパース MoE モデル「Trinity-Large」
総パラメータ 400B、アクティブパラメータ 13B を持つ米国企業製のモデルで、技術レポートとベースモデルの詳細が公開され、大規模モデルの効率化における新たな指針を示している。
Kimi-K2.5 と GLM-4.7-Flash の新機能
Moonshot AI の K2.5 はマルチモーダル化と推論能力の強化によりコーディング分野で注目され、ZAI Lab の GLM-4.7-Flash は小規模ながら高性能な Flash モデルとして登場した。
業界全体としての「ニッチ」モデルの台頭
OCR、埋め込みベクトル、楽曲生成など特定領域に特化したオープンソースモデルの質が向上しており、用途に応じた最適なモデル選定が可能になっている。
重要な引用
In our vibe testing, it came very close to Qwen3 4B 2507 Instruct... And this model is over 3 times smaller!
An ultra-sparse MoE with 400B total and 13B active parameters
People on Twitter have replaced Claude 4.5 Opus with K2.5 for tasks that need a less capable but cheaper model.
There really tends to be open models that excel at any modality needed today — they can just be hard to find!
影響分析・編集コメントを表示
影響分析
この記事は、2026 年初頭の AI 市場において「大規模化」から「効率化と特化型」へのシフトが加速していることを示唆しています。特に LiquidAI や Arcee のような新興企業による高性能なオープンモデルの登場は、開発コストの削減とローカル環境での高品質推論を可能にし、企業の AI 導入戦略に大きな影響を与える可能性があります。
編集コメント
昨今の「大規模化」一辺倒のトレンドに対し、小規模かつ高性能なモデルや特定領域特化型のオープンソースモデルが急成長している点は非常に示唆に富んでいます。開発者はコストと性能のバランスを再考する絶好の機会です。
2025 年という記録的な年の翌月である 1 月は、オープンモデルのリリース数ではやや低調でした。依然として非常に強力かつ注目に値するモデルは多数存在しましたが、AI 業界全体としては今後登場するモデルに注目しています。DeepSeek V4 の迫り来るリリースとその印象的な能力、そしてさらに競争力のあるオープンモデルエコシステムに関する噂は無数にあります。
一般の AI 界隈では、Claude Sonnet 5 のリリースが明日にも行われるという噂が週末を通じて議論されてきました。次なる展開にワクワクしていますが、まずは触って遊べる新しいオープンモデルが多数あります。
シェアする
私たちが選ぶモデル
LiquidAI による LFM2.5-1.2B-Instruct: Liquid は、自社の 2.0 シリーズの 10T トークンから継続して事前学習を行い、最終的に 28T トークンまで到達させました。その成果が現れています!このモデル更新は私たちを驚かせました:私たちの「雰囲気テスト」では、毎日使用している Qwen3 4B 2507 Instruct に非常に近い性能を示しました。しかもこのモデルは、それよりも 3 倍以上も小さいのです!(まだより大きい)Qwen3 1.6B との直接比較でも、LFM2.5 をほぼ毎回好んで選びました。そして今回は、他のすべてのバリアントを同時にリリースしました。つまり、日本語版、ビジョンモデル、オーディオモデルです。
arcee-ai による Trinity-Large-Preview:全パラメータ数 400B、アクティブパラメータ数 13B の超スパースな MoE(Mixture of Experts)モデルです。アメリカの企業によってトレーニングされました。同社ではまた技術レポートと 2 つのベースモデルも公開しています。1 つは学習率 annealing(調整)前の「真の」ベースモデル、もう 1 つは事前トレーニングフェーズ終了後のベースモデルです。技術詳細やその動機など、さらに多くの洞察については、創業者および事前トレーニング責任者へのインタビュー記事をご覧ください。
moonshotai による Kimi-K2.5:15T トークンでの継続的な事前トレーニングが行われています。さらに、このモデルはマルチモーダルでもあります!Twitter では、より能力が低くても安価なモデルが必要なタスクにおいて、Claude 4.5 Opus の代わりに K2.5 が使用されるようになりました。しかし、K2 およびその後継モデルで知られていた文章作成能力は、コーディングやエージェント機能の強化のためにやや低下しています。
zai-org による GLM-4.7-Flash:GLM-4.7 の小型版です。Qwen3 MoE の小型版と同じサイズで、全パラメータ数 30B、アクティブパラメータ数 3B です。
LLM360 による K2-Think-V2:同社の既存モデルシリーズを基盤とした、真にオープンな推論モデルです。
Models
この号の残りの部分を読み進める中で、エコシステム全体における「ニッチ」な小型モデルの質の高さに感銘を受けました。OCR(光学文字認識)から埋め込みベクトル生成、楽曲生成に至るまで、今号にはあらゆる分野の内容が含まれており、今日必要とされるあらゆるモダリティにおいて優れたオープンモデルが存在することがよくわかります——ただ、それらを見つけるのが難しいだけです!
Read more
原文を表示
January was on the slower side of open model releases compared to the record-setting year that was 2025. While there were still plenty of very strong and noteworthy models, most of the AI industry is looking ahead to models coming soon. There have been countless rumors of DeepSeek V4’s looming release and impressive capabilities alongside a far more competitive open model ecosystem.
In the general AI world, rumors for Claude Sonnet 5’s release potentially being tomorrow have been under debate all weekend. We’re excited for what comes next — for now, plenty of new open models to tinker with.
Share
Our Picks
LFM2.5-1.2B-Instruct by LiquidAI: Liquid continued pretraining from 10T (of their 2.0 series) to 28T tokens and it shows! This model update really surprised us: In our vibe testing, it came very close to Qwen3 4B 2507 Instruct, which we use every day. And this model is over 3 times smaller! In a direct comparison against the (still bigger) Qwen3 1.6B, we preferred LFM2.5 basically every time. And this time, they released all the other variants at once, i.e., a Japanese version, a vision and an audio model.
Trinity-Large-Preview by arcee-ai: An ultra-sparse MoE with 400B total and 13B active parameters, trained by an American company. They also released a tech report and two base models, one “true” base model pre-annealing and the base model after the pre-training phase. Many more insights, including technical details and their motivation, can be found in our interview with the founders and pre-training lead:
Kimi-K2.5 by moonshotai: A continual pre-train on 15T tokens. Furthermore, this model is also multimodal! People on Twitter have replaced Claude 4.5 Opus with K2.5 for tasks that need a less capable but cheaper model. However, the writing capabilities that K2 and its successor were known for have suffered in favor of coding and agentic abilities.
GLM-4.7-Flash by zai-org: A smaller version of GLM-4.7 which comes in the same size as the small Qwen3 MoE with 30B total, 3B active parameters.
K2-Think-V2 by LLM360: A truly open reasoning model building on top of their previous line of models.
Models
Reading through the rest of this issue, we were impressed by the quality of the “niche” small models across the ecosystem. From OCR to embeddings and song-generation, this issue has some of everything and there really tends to be open models that excel at any modality needed today — they can just be hard to find!
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み