AI の経済的合理性は根本的に成り立たない
GitHub Copilot が 2026 年 6 月より従量課金へ移行する決定は、AI 業界全体が長年にわたる過度なサブスidi(補助)モデルの限界に直面し、「次貸型 AI 危機」が現実化していることを示す重要な転換点である。
キーポイント
GitHub Copilot の課金モデル変更発表
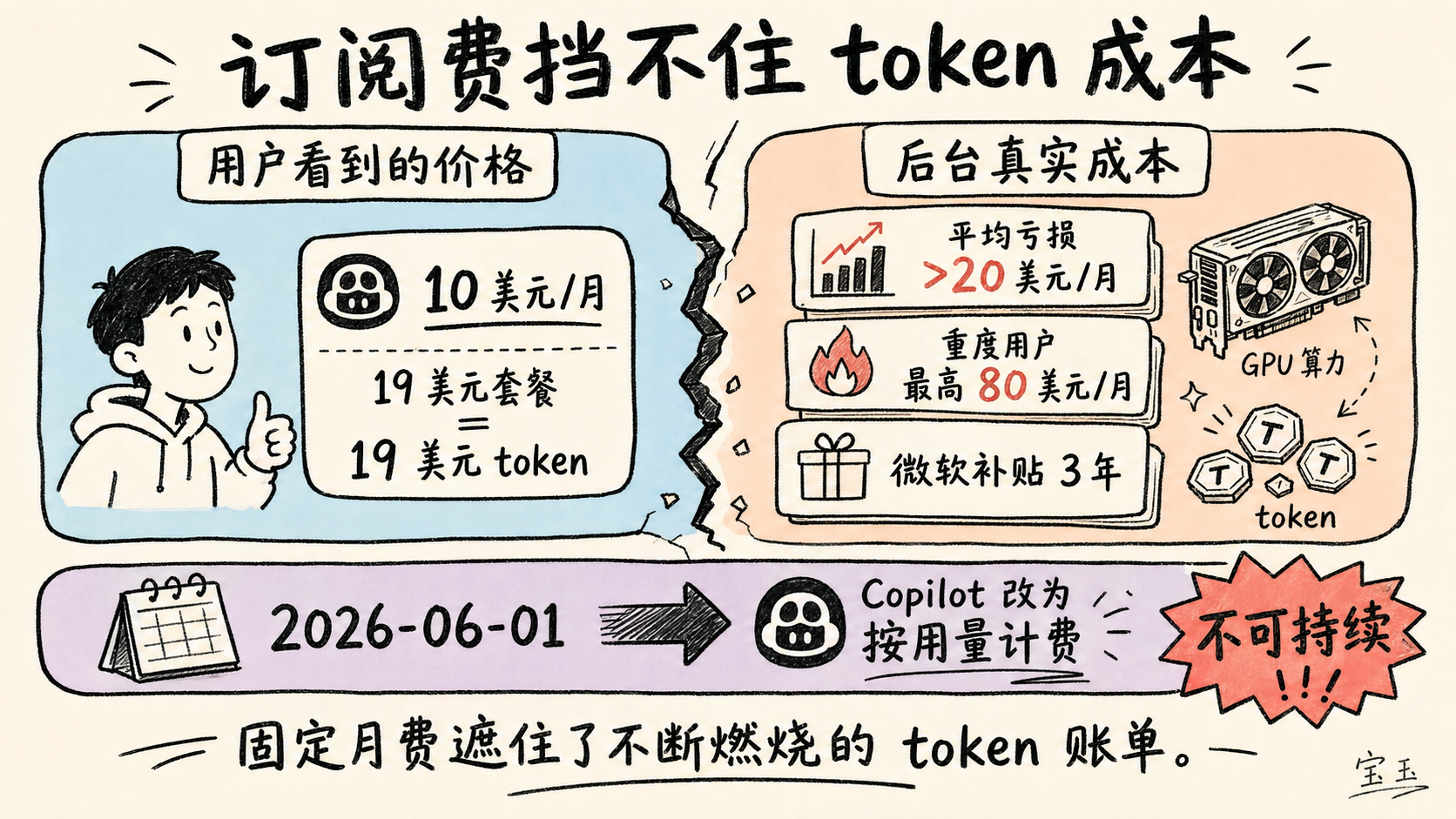
2026 年 6 月 1 日より、すべての GitHub Copilot プランが固定料金からトークンベースの従量課金へ移行し、ユーザーは実際の計算コストに基づいて支払うことになる。
サブスクリプションとコストの乖離
過去 3 年間、多くのユーザーが月額料金を遥かに超えるトークン消費を行っており、企業側は深刻な赤字を被っていたことが明らかになった。
次貸型 AI 危機の実現
記事は業界全体が低価格で技術を導入し、大企業が計算コストを巨額に負担してきた状況を「次貸型 AI 危機」と定義し、その崩壊が目前にあると警告している。
AI エージェント化によるコスト増
Copilot が単なるアシスタントから複雑な多ステップ処理を行う「インテリジェンス・プラットフォーム」へと進化し、推論コストが急騰したことが課金変更の理由として挙げられている。
影響分析・編集コメントを表示
影響分析
このニュースは、AI 業界全体が「成長のための損失」から「収益性の確保」へとパラダイムシフトを迫られていることを象徴しています。特に GitHub Copilot のような大規模な B2C/B2B ツールにおいて、サブスクリプションモデルの限界が露呈したことで、今後他の AI サービスも同様の価格改定や課金モデルの見直しを余儀なくされるでしょう。これにより、AI 導入コストが見直され、企業における AI 投資対効果(ROI)の評価基準がより厳格化されると予想されます。
編集コメント
AI の技術的進歩が著しい一方で、その経済モデルの持続可能性に根本的な疑問が投げかけられています。開発者や企業は、単なる機能追加だけでなく、コスト構造の変化を踏まえた戦略的な AI 活用計画が必要となるでしょう。
AI の経済計算は根本的に成り立たない
著者:Ed Zitron**
原文:AI's Economics Don't Make Sense
昨日の朝、GitHub Copilot ユーザーついに確認が得られました:私が一週間前に報じた事柄が現実のものとなったのです——2026 年 6 月 1 日から、すべての GitHub Copilot プランは従量課金(usage-based pricing)へ移行します。
以前は、Microsoft はユーザーに一定数の「リクエスト(requests)」を提供していました。現在は、ユーザーがモデルを実際に使用したコストに基づいて課金されます。Microsoft はこれを「……持続可能で信頼性が高く、すべてのユーザーを対象とした Copilot ビジネスと体験への重要な一歩」と呼んでいます。言い換えれば、ユーザーが GitHub Copilot の月額サブスクリプションにいくら支払うかによって、同等価値のトークン(語元、token)枠が提供されます。例えば月額 19 ドルのプランであれば、19 ドル分のトークンが付与されるのです。
要するに**:「*私たちはもはや GitHub Copilot ユーザーの計算コストを補助し続けることはできません。そうしなければ Amy Hood がバットを持って殴り始めますよ。*」
いずれにせよ、この発表自体が興味深いです。これにより、これらの値上げがどのように包装されるかが事前に示されています:
**
Copilot はもはや一年前の製品ではありません。
それはエディタ内のアシスタントから、インテリジェンスを備えたプラットフォーム(agentic platform)へと進化しました。長時間にわたる多段階のプログラミングセッションを実行し、最新モデルを使用し、コードベース全体で反復的に改善を行います。インテリジェンスを活用した利用がデフォルトとなりつつあり、これにより計算および推論(inference)の需要が著しく増加します。
今日では、簡単なチャット質問と数時間にわたる自律的なプログラミングセッションが、ユーザーに同じ価格を請求する可能性があります。GitHub はこうした利用に伴う上昇し続ける推論コストを引き受けてきましたが、現在の高度なリクエストモデルは持続不可能です。
従量課金はこの問題を解決します。これにより価格設定が実際の使用状況により適切に対応し、長期的なサービスの信頼性を維持するのに役立ちます。また、重度ユーザーを制限する必要性も減らされます。
ご覧の通り、問題は「*Microsoft が約 200 万人の計算コストをずっと補助していること*」ではなく、「*AI はあまりにも強力になり、あまりにもパワフルで複雑になったため、本質的に別の製品になってしまった!*」なのです。
Copilot が確かに「……一年前の製品ではない」かもしれませんが、根本的な経済の不整合は大きく変化していません:Microsoft は連続する *3 年間*、ユーザーが月額サブスクリプション料自体を上回るトークンコストを毎月燃焼させることを許容してきました。『ウォール・ストリート・ジャーナル』2023 年 10 月の報道によると:
個人ユーザーは、この AI アシスタントに対して月額 10 ドルを支払っています。今年最初の数ヶ月間、同社では平均してユーザーあたり月額 20 ドル以上の赤字が発生していました。関連する数字に詳しいある人物によると、一部のユーザーについては、会社にとって月額 80 ドルものコストを発生させるケースもあるそうです。
当然ながら、GitHub Copilot のユーザーたちは反発しています。彼らはこの製品が「死んだ」あるいは「完全に壊れた」と述べています。
私は 2 年前に『サブプライム AI クライシス(Subprime AI Crisis)』において、まさにこの事態を予言していました:
私は、サブプライム型 AI クライシスが進行中であると仮定しました。ほぼ全米のテクノロジー業界が、極めて低い割引率で販売されている技術を買い占めています。この技術は高度に集中しており、大手テック企業によって巨額の補助金で支えられています。いつか、生成式 AI(Generative AI)という驚異的かつ有毒な資金燃焼速度が、それらを追いつくことになるでしょう。その結果として価格引き上げが行われるか、あるいは Salesforce の「Agentforce」製品のような1 回あたり 2 ドルというあり得ない対話課金を伴う新製品や新機能が発表されることになります。最終的には、予算が豊富で最も忠実な企業顧客であっても、この支出の正当性を証明できなくなるのです。
そして今、その日がようやく訪れました。あなたが利用するあらゆる AI サービスが計算資源(Compute)を補助しているためであり、その結果として各サービスが赤字を抱えているからです:
AI スタートアップのサービスを利用するために料金を支払うとき——もちろん、OpenAI や Anthropic も含まれますが——通常は月額制で、例えば Anthropic の Claude には 20 ドル、100 ドル、または 200 ドル/月のプラン が用意されており、Perplexity には 20 ドルまたは 200 ドル/月のプラン、OpenAI には 8 ドル、20 ドル、または 200 ドル/月のサブスクリプション が存在します。企業利用の場面では、特定のタスクを完了するために使用できる「クレジット(ポイント)」が提供されます。例えば Lovable の月額 25 ドルのサブスクリプションはユーザーに「月間 100 クレジット」を提供 し、さらに 2026 年第 1 四半期終了時点までのクラウドホスティング分として 25 ドル分のクレジットが付帯しており、未使用のクレジットは翌月へ繰り越すことができます。
これらのサービスを利用する際、関連企業はあなたが呼び出した AI モデルに対して支払いを行う必要があります。彼らは AI ラボから百万トークンあたりの価格で支払うか、Anthropic や OpenAI のように、モデルを実行するために GPU を貸し出すクラウドプロバイダーに支払います。1 トークンはおよそ 3/4 単語に相当します。
ユーザーとして感じるのは、トークンの消費ではなく、入力と出力のプロセスそのものです。AI ラボは「トークン」や「メッセージ」、あるいは 5 時間のレート制限とパーセンテージ表示のプログレスバーを用いて、サービスのコストを隠蔽しています。ユーザーであるあなたは、これらの要素が実際にどれほどの価値を持つのかを知りません。一方、バックエンドでは AI スタートアップが最近まで猛スピードで資金を燃焼させていました。
Anthropic はかつて、ユーザーが 1 ドルのサブスクリプション料金を支払うごとに、8 ドルを超える計算コストを燃焼させることを許可していました。OpenAI も同様のことが起こりましたが、具体的な比率を測るのは困難です。
AI スタートアップと超巨大クラウドプロバイダー(ハイパースケイラー)は、補助金付きの赤字商品で十分な数のユーザーを引き込み、彼らにこれらのサービスへの深い依存を形成させれば、企業が大幅な値上げを行った際にもユーザーが離脱しないと信じていました。また、トークンコストは時間とともに低下すると考えていたようです。しかし現実は正反対です:_一部の_モデルの価格が下落したとしても、新しい「推論モデル(reasoning models)」はより多くのトークンを消費するため、結果として推論コストが時間の経過とともにむしろ上昇している のです。
これらの仮定はどちらも誤りです。大規模言語モデル(Large Language Model、LLM)に接続するあらゆるサービスにおいて、月額サブスクリプションモデル_根本的に不合理_だからです。
生成 AI の核心となる経済計算はすでに破綻している
こう考えてみてください。Uber(いや、この件は Uber とは全く似ていません)がタクシー料金を引き上げ始めたとき、その基盤となる経済構造は変化せず、乗客と運転手に提示される構造も変わりませんでした:ユーザーは1回の乗車に対して支払い、運転手は1回の配車に対して報酬を受け取ります。運転手は依然としてガソリン代、自動車保険、地方政府が要求する各種ライセンス費用、車両ローン関連コストを負担しており、これらのコストを Uber が補助しているわけではありません。Uber の巨額の赤字は、補助金、途切れないマーケティング支出、そして自動運転車などにおいて必然的に失敗する研究開発への投資に起因します。
生成 AI サブスクリプションと Uber は全く別物です
AI の価格設定のミスマッチの規模を説明するために、別の歴史的バージョンを想像してください。その世界では、Uber のビジネスモデルは全く異なっていました。
生成 AI のサブスクリプションとは、Uber がユーザーから月額 20 ドルを徴収し、100 回まで乗車できる権利を与え、ただし各回の走行距離が 100 マイル以内であればよいというものです。同時に、ガソリン価格はリットルあたり 150 ドル(※原文はガロン)で、*しかもその燃料費を Uber が負担する*という状況です。なぜなら、「いつか石油は計測する価値もなくなるほど安くなる」と主張する人たちがいるからです。
最終的に、Uber はユーザーに月額料金を徴収して乗車権を与え、その後消費したガソリンに応じて課金することを決定します。突然、ユーザーは「月額 20 ドルで 100 回乗車」から、「まず 20 ドルを払って運転手にアクセスし、さらに 10 マイルの走行に対して 26 ドルを支払う」というモデルに変わります。当然ながら、ユーザーは少し不機嫌になります。
これは少し誇張されているように聞こえるかもしれませんが、実際には生成 AI 業界、特に GitHub Copilot で現在起こっていることを非常に正確に描写しています。
以前の GitHub Copilot の価格設定では、ユーザーは月額 300 回の高度なリクエストを使用でき、GPT-5 mini などのモデルによる「無限のチャットリクエスト」も利用できました。各リクエストとは、マイクロソフト自身の言葉によれば、「Copilot に何かを依頼するあらゆるインタラクション」です。リクエスト制約の末期には、*より高価なモデルほど多くのリクエスト枠を消費します*(例:Claude Opus 4.6 は高度なリクエスト枠 3 つを消費)。高度なリクエスト枠を使い果たすと、Copilot は当月残りの期間中、それらの安価なモデルを無制限に使用することを許可します。
しかもこれは当初からそうだったわけではありません。2025 年 5 月まで、マイクロソフトはユーザーにモデルの無制限利用権限を与えていました。その後、わずかな制限が導入され始めただけでも、ユーザーはすでに非常に怒っていました、なぜなら彼らはこの製品に_あらゆる_制限が存在することを認めないからです。
マイクロソフトは——AI 企業である限りすべてがそうであるように——持続不可能なサービスで顧客を欺きました。LLM(大規模言語モデル)によって駆動されるサービスを月額サブスクリプション形式で販売することは、*決して、決して*合理的ではありませんでした。
トークン課金制に移行した後のサービスの価格がどれほど高くなるかを知りたいなら、GitHub Copilot のサブレディットのユーザーは、過去に高度なリクエスト 1 回あたりのトークン消費量が約 11 ドルに相当することを発見しました。その理由は、1 つのリクエストがコンテキストウィンドウ(文脈窓)内で 60,000 トークンを消費し、複数のツールを呼び出し、モデルが結果を生成するためにバックグラウンドで行う一連のステップである内部「ターン」を経る可能性があるからです。
さらに根本的な問題があります。大規模言語モデルは幻覚(hallucination)を起こしやすいのです。高度なリクエストが行き詰まって半壊れのコードを吐き出すのは確かに煩わしいですが、その失敗に対してユーザー自身が費用を負担する必要がある場合、そのようなミスはそう簡単に許容できるものではありません。
ユーザーもまた、トークン課金とは全く異なる方法で製品を利用するように訓練されてきました。おそらく多くの人は、自分が実際にどれほどの「トークン」を消費しているか、あるいは特定のタスクにどの程度のトークンが必要かを本当に理解していません。そしてこの数字は使用するモデルによって変動します。
これは_Uber のビジネスモデルとは全く異なります_。両者が同じだと主張する者はすべて、悪質な行為の言い訳をしているに過ぎません。Uber は価格を上げたことはありますが、プラットフォームの根本的な経済構造を根本から変える必要はありませんでしたし、ユーザーも Uber が突然ガソリン 1 ガロンあたりの課金方式に移行したからといって、製品の利用方法を根本的に変える必要はなかったのです。
AI の月額サブスクリプションはすべて AI サブシディ(補助)詐欺の一部:生成型 AI と実際の費用を意図的に切り離している
各ユーザーが_実際に消費するトークン数_に基づいて課金しない限り、LLM 駆動型のサービスを経済的に持続可能な形で提供することは、過去にも現在も未来においても決して不可能です。これらの企業はユーザーを欺く過程で、収益が虚構であり投資対効果が疑わしい製品を生み出してきました。
この点は_長年、明白に示されていました_。
経済学的に見れば、月額サブスクリプションはコストが比較的安定している事業に適しています。フィットネスジムは会員権を販売できます。なぜなら、機器の摩耗やレッスンの運営コスト、一定期間内の電気代・人件費・水道費などの経費が概算できるからです。
Google Workspace の顧客にとって、少なくとも AI が登場する以前は、コストの主な要因はドキュメントへのアクセスや保存にかかる費用、および Google Docs やその他のサービスの継続的な稼働コストでした。デジタルストレージのコストは比較的安価であり、大規模言語モデル(LLM)とは異なり、Google Workspace は計算リソースに対する要求が特に高いわけではありません。したがって、ある Google Drive ユーザーが非常に重度に利用していたとしても、その月のサブスクリプション料金の利益率を食い潰す可能性は低かったのです。
しかし、AI サブスクリプションユーザーのコストは_激しく変動する_可能性があります。あるユーザーは ChatGPT を偶発的に検索するだけかもしれませんが、別のユーザーは大量のドキュメントを読み込ませたり、コードベース全体のリファクタリングを試みたり、PowerPoint のプレゼンテーション作成を依頼したりするかもしれません。そして、サービス提供者——OpenAI や Anthropic といったモデル研究所であっても、Cursor のような新興企業であっても——製品品質を低下させる以外に、ユーザーがどのように利用するかを真正面から制御する方法はほとんどありません。例えば、使用上限を設定したり、コンテキストウィンドウを縮小したり、ユーザーをより小さく質の低いモデルへ誘導したり、GPU リクエストを大量に発生させるユーザーを価格で撃退するために料金を変更したりすることです。
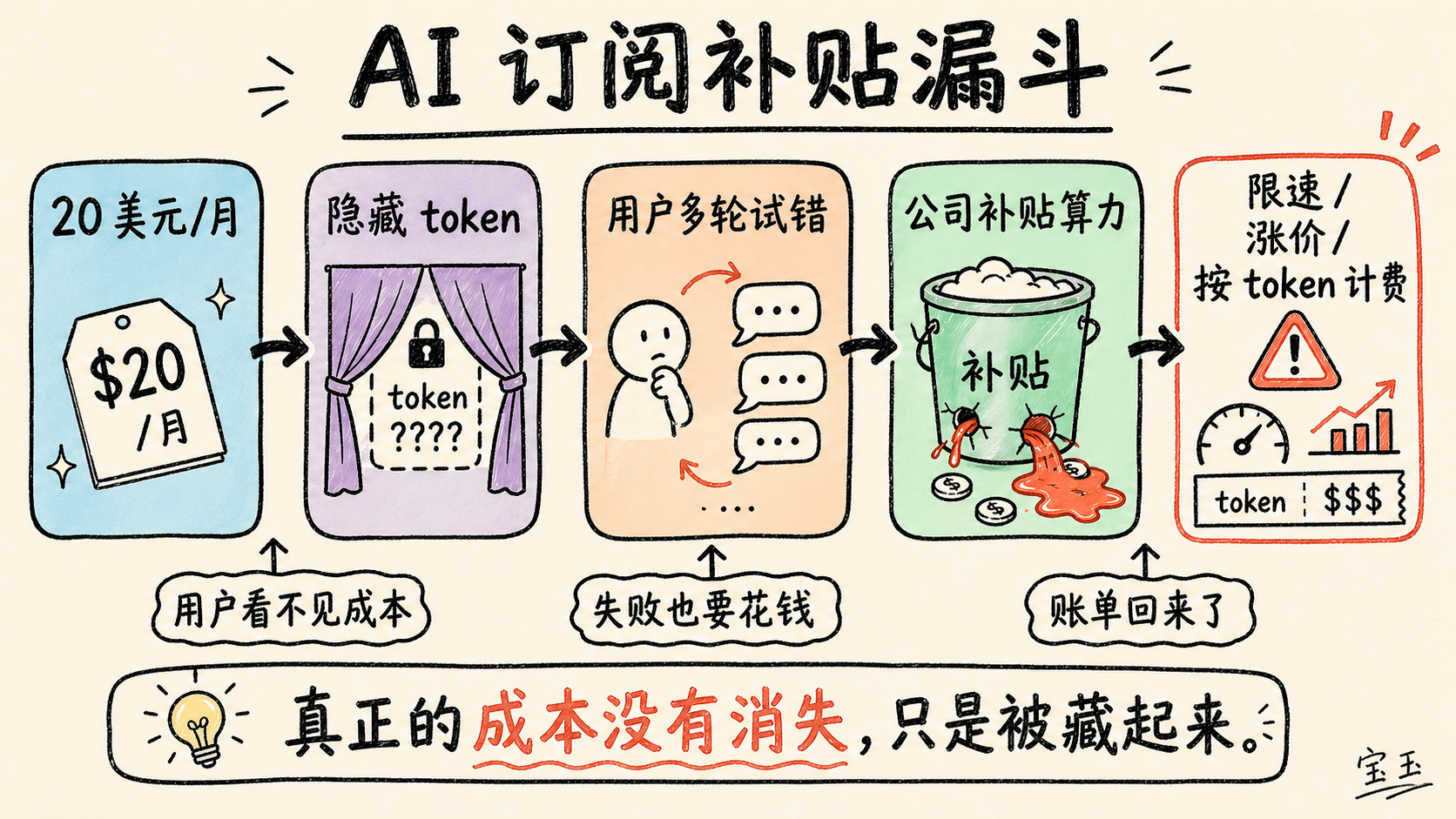
しかし、これらのサービスは意図的にトークン数を隠し、特定の活動が実際にいくらかかるかを隠しています。その結果、ユーザーはレート制限の意味を本当には理解していません。そのため、突然のレート制限の調整 があるたびに、顧客たちはパニックになりながら、自分たちがこのサービスで実際にどれだけの作業を完了できるのかを必死に理解しようとします。
これは虐待的であり、操作され、欺瞞的なビジネス手法です。これが存在する唯一の理由は、Anthropic、OpenAI、および他の AI 企業がユーザーベースを拡大したいからです。なぜなら、大多数の AI ユーザーが実感している、あるいは想像している利益は、「1 ドルのサブスクリプション料金を支払うごとに、8 ドルから 13.50 ドルまでのトークン を燃焼させている」という前提の上に成り立っているからです。
この意図的な欺瞞には一つの目的しかありません。それは、大多数の人々が生成 AI の真のコストに決して触れることがないようにすることです。『大西洋月刊』が情熱的に Claude Code を Anthropic にとっての「ChatGPT モーメント」と記述した際、彼らが議論していたのは月額 20 ドルのサブスクリプションであり、Anthropic がこのサービスを提供するために裏側で実際に燃焼させたトークンコストではありません。だからこそ、著者はモデルが犯した「軽微なエラー」や、「より複雑なプログラミングタスクでつまずくこと」を許容するのです。
もしその著者が、自分が実際に燃焼させたトークンのコストを支払っており、モデルがつまずくたびに 15 ドルのトークン請求書を受け取っていたとしたら、私は彼女がこれらの失敗に対してこれほど寛容であるとは思いません。
しかし、これが詐欺の一部なのです。
非常に、そして極めて重要な点は、主要メディアで AI について執筆する人々が決してこれらのサービスのコストを真に理解してはならないということです。ChatGPT や Claude Code といったサービスに関する主要な記事は、個々のタスクがユーザーにどれほどの費用がかかるかをほとんど知らない人によって書かれるべきなのです。
覚えておいてください:生成 AI サービスは、本質的に実験的な製品です。これらは他のどの現代ソフトウェアやハードウェアとも異なる動作をします。ChatGPT や Claude の前に立ち向かい、「さあ働いてくれ」と命令するだけで済むものではありません。
つまり、もちろんそのようなことは可能です。しかし、プロンプトの書き方が間違っていたり、その仕組みを理解していなかったり、入力データに誤りがあったり、あるいは AI 自体が誤りを犯したりすれば、満足できない結果を出力します。すると、再度プロンプトを入力し直す必要があります。LLM(大規模言語モデル)は本質的に予測不可能です。
特定の LLM が必ずしも特定の動作を実行するとは保証できませんし、現実に基づいた結果を提供するとも限りません。あるタスク——過去に何度も LLM で実行したタスクであっても——が実際にいくらかかるのかを確信することはできません。また、モデルが突然暴走して何かを削除したり、実際には何もしていないのに「やった」と主張したりするタイミングも予測できません。
トークン課金でない場合、これらの問題はより寛容に許容されがちです。なぜなら、サブスクリプションユーザーにとっては、単にチャットボットとの対話ラウンドが一つ増えるだけであり、実際のコストが発生しているわけではないと考えるからです。また、「ジグザグ知能(jagged intelligence)」——つまり AI は特定のタスクでは驚異的な性能を発揮する一方で、一見単純なタスクではなぜか失敗し、能力の境界が滑らかではないという現象**——についても、人々は厳しく批判しません。なぜなら、現在直面している問題は将来必ず解決されると考えられており、失敗しても追加料金を支払う必要がないからです。
もしユーザーが最初から実質的なレートで課金されるのであれば、多くの人がすぐにこの製品を放棄するでしょう。LLM が何ができるかをただ漠然と探索している最中に、5 ドル分のトークンをあっという間に使い果たすのは非常に容易だからです。
**
補足:** 実際には、膨大な金額を費やしても望む結果が得られない可能性があります。なぜなら LLM は真の意味での人工知能ではないからです。その限界を理解していない人は、30 ドル、50 ドル、あるいは 100 ドルもの費用を投じて、LLM に「自分自身で絶対にできる」と主張するタスクを実行させようとするでしょう。
ここに一つの用語があります:迎合(sycophancy)。LLM はしばしばユーザーの意見に同調するように設計されており、ユーザーが**
危険で制御不能な発言 をしている場合でも、その傾向は「技術的・財務的に全く実現不可能な巨大なものを望んでいますか?」というシナリオにも及ぶことがあります。「問題ありません!」と答えるのです。
これが業界全体がこれらのコストを隠蔽しようとする理由です——これはまさに強奪行為だからです!
私は、多くの AI サブスクリプションサービスがトークン課金へ移行することは避けられないと考えています。特に Anthropic や OpenAI はすでに企業顧客に対してこの方針を採用しています。
Microsoft が GitHub Copilot のサブスクリプションユーザーをトークン課金へ移行させたことも、非常に、非常に悪いシグナルです。Microsoft は資本が最も豊富で、利益率が高く、計算資源の補助を継続する条件も整っている企業と言えます。それでもなお補助を維持できないのであれば、他の企業がそれを負担できるはずがありません。
本当に注視すべきシグナル——真の蒼白の馬——は、Anthropic や OpenAI といった主要な AI ラボが、_すべての_サブスクライバーをトークン課金へ移行させることだ。(「蒼白の馬」とは『黙示録』に登場し死を象徴する馬のことで、ここでは壊滅的な転換点を指す。)**このことが起これば、すぐにわかる:営業終了の時間だ。
一般企業がトークン課金を負担できるのか?Anthropic の試算では、Claude Code ユーザーは 1 日あたり 13 ドルから 30 ドルを費やし、年間 7,000 ドル以上になる;大規模な組織では年間数十万ドル、あるいは数百万ドルに達する。
先週私が議論した通り、Uber の CTO は会議で、同社が数ヶ月のうちに 2026 年の AI 予算をすべて使い果たしたと語った。ゴールドマン・サックスも指摘しているように、一部の企業は AI トークンへの支出がすでに人件費の 10% に達しており、今後数四半期で*100%*に達する可能性がある。
これは、各 AI ユーザーに可能な限り多くのサービス利用を促しつつ、実際のコストを隠蔽しようとする試みの直接的な結果だ。「できるだけ多く AI を使え」と全従業員に求める大企業は、自社の実際のトークン消費量を根本的に無視しているか、あるいはこの現実と完全に断絶している。そして企業が_実際の費用_を支払うことを迫られたとき、私は、この技術への_いかなる_投資を経済的に正当化できるのか疑問だ。
もちろん、「エンジニアがコードをより速く納品する」などという屁理屈を言うだろうし、その意図はわかる。しかし問題は:*具体的にどれほど速くなったのか?したがって、どれだけ稼いだり、節約したりしたのか?* 人件費の 10% に相当する金額を AI トークンに支出しているなら、その追加支出を相殺できる収益を他の場所で得ているのだろうか。私はそう思わないし、多額の資金をトークンに投入する_どの_企業も、_いかなる_投資収益(ROI)を見出せているとは考えにくい。だからこそ、AI 投資に関するあらゆる研究が、その存在を証明する証拠を見つけるのが極めて困難なのである。
概して、生成 AI の多様な可能性に興奮しすぎて失態を演じている人々の多くは、その真の費用を支払ったことがありません。Twitter で長文を投稿し、「自分のエンジニアチーム全員が Claude Code を猛スピードで叩き込んでいる」と叫ぶ狂信的な人々は、月額 125 ドルの Teams サブスクリプションを利用しており、その利用制限は Anthropic の月額 100 ドルの消費者向けサブスクリプションとほぼ同等です。LinkedIn で怪物のように振る舞い、「Perplexity の製品を使えば数時間で終わる作業を数分で完了させた」と主張する人々も、Perplexity の Max サブスクリプションに月額 200 ドルしか支払っていないのがせいぜいです。
現実には、10 人のチームが月額 1,250 ドルの Teams サブスクリプションを利用している場合、API 呼び出し(API calls)で毎月 5,000 ドルから 10,000 ドル、あるいはそれ以上を燃費のように使い果たす可能性が高いです。Anthropic の成長責任者である Amol Avasare は先週、同社の Max サブスクリプションは重度のチャット利用のために設計されたものであり、Claude Code や Cowork を使って行うような用途には設計されていないと明言しました。さらに彼は、Anthropic は現在「優れた体験を提供し続けるための異なるオプションを探している」とも明確に示唆しました。つまり、「いつか価格を変更せざるを得ない」という意味です。
人々が、特に大規模なコードベースを扱い、プログラミングツールやインフラストラクチャ(infrastructure)ツールへの頻繁な呼び出しを伴うコーディングプロジェクトにおいて、これらのトークンがどれほど高価であるかを認識しているかどうかはわかりません。月額 200 ドルを支払っている人が、350 ドル、400 ドル、あるいは 500 ドルという費用を見越して負担できるでしょうか?ある月で_それ以上_の支出を耐え忍ぶことができるでしょうか?予算超過した場合どうなるのでしょうか?もし作業完了に必要な資金を本当に支払うことができない場合、どうすればよいのでしょうか。
より現実的な例を挙げましょう。4 月初めまで、Anthropic 自社の Claude Code 開発者向けドキュメント(アーカイブ)には、「Claude Code ユーザーの平均コストは、開発者あたり 1 日 6 ドルで、90% のユーザーの 1 日のコストは 12 ドル未満である」と記載されていました。しかし今週現在、ドキュメントは以下のように変更されています:
**
Claude Code は API トークンの消費量に基づいて課金されます。サブスクリプションプラン(Pro、Max、Team、Enterprise)の価格は claude.com/pricing をご覧ください。
開発者あたりのコストは、モデル選択、コードベースの規模、および複数のインスタンスを実行したり自動化プロセスを運用したりする使用パターンなどによって大きく異なります。
企業向けデプロイメントでは、平均コストはアクティブな 1 日あたり開発者 1 人につき約 13 ドル、月額で 150 ドルから 250 ドルです。90% のユーザーの 1 日のコストは 30 ドル未満です。
ご自身のチームの支出を見積もる場合は、まず小規模なパイロットグループから始め、以下の追跡ツールを使用してベースラインを確立してから、より広範なデプロイメントに進んでください。
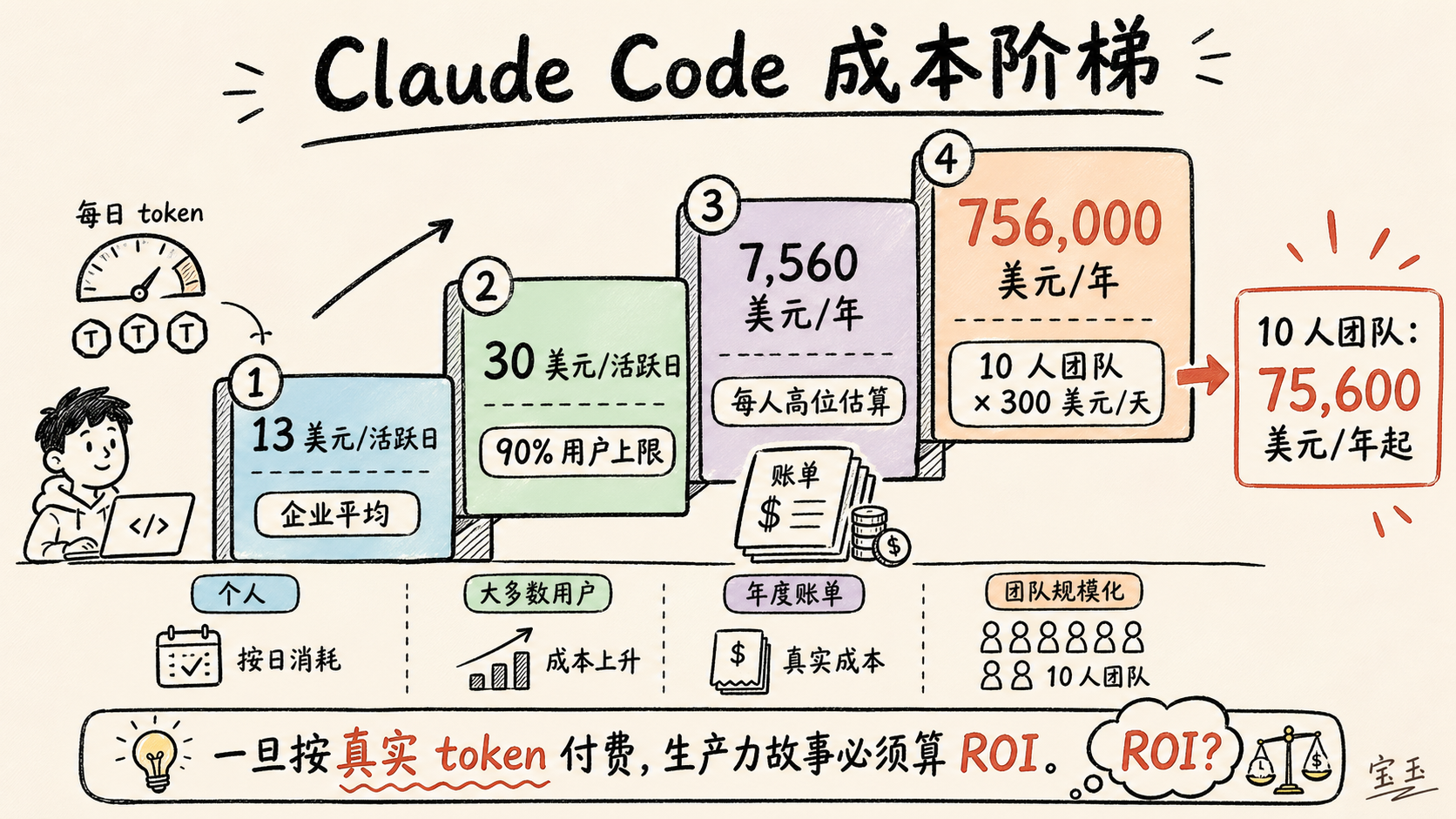
もし月平均 21 営業日と仮定すれば、Claude Code ユーザーの平均コストは月額約 273 ドル、あるいは年額 3,276 ドルとなります。1 営業日あたり 30 ドルで計算すると、月額 630 ドル、年額 7,560 ドルになります。
これらの数字は驚くべきものです。さらに驚くべきことに、*Anthropic の最新のいずれのモデルを使用する場合でも、毎日 30 ドルしか使えないことはあり得ません*。Claude Opus 4.7 の価格は、入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 25 ドルです。「100 万トークンはおよそ 50,000 行のコードに相当します」。いわゆる最先端モデルを使用する場合、少なくとも 100 万トークンを超えないわけにはいきません。特定のタスクにどのモデルを使うべきか明確でない場合、この数字はさらに大幅に上昇します。
では、毎日 30 ドルという数字をもう少し計算してみましょう。
- 10 人の開発チームの場合、これは年額 75,600 ドルとなり、しかもこれは営業日だけの計算です。
- もし 3 ヶ月間の平均費用が 1 営業日あたり 50 ドルに上昇すれば、総額は 88,200 ドルになります。
- さらに 1 ヶ月間、毎日 100 ドルを超えた場合、年間の支出は 102,900 ドルとなります。
- もし毎日 300 ドルを使うなら、10 人のチームが 1 年間にトークンだけで費やす額は 756,000 ドルに達します。
資金が潤沢なスタートアップにおける「小金庫マインドセット」や、メタ(Meta)のような「バナナ共和国」であれば、こうした状況も起こり得るかもしれません。しかし、コストを真に懸念する企業にとって、「生産性向上」のためのサービスに対して 5 桁または 6 桁の追加費用を支払う合理性を示すことは極めて困難であり、その生産性向上を実証できる人もほとんどいません。
現在、私はほとんどの企業が以下の 3 つのカテゴリーに分かれると考えています。
- Spotify や Uber のような大規模組織で、企業導入規模が巨大であり、CEO が AI に洗脳されて予算管理を放棄しているケース。
私も付け加えますが、大規模で資金に余裕のあるスタートアップもこのカテゴリーに含まれます。
- 補助付きの「Teams」サブスクリプションを利用する小規模スタートアップ。
- クラウド(Claude)やその他の AI サブスクリプションを月額利用している個人ユーザー。
大規模組織は現在なお、AI トークンにソフトウェアエンジニアのために数百万ドルを費やしたことを正当化するための免罪符を得ており、「最も優秀なエンジニアが 12 月以来コードを一行も書かなくなった」といった疑わしいメリットを理由として掲げています。
しかし、一度でも酷い決算電話会議があれば、この物語は変わってしまうでしょう。そのうち、投資家たち——AI バブルを吹き上げてきた無知な連中でさえも——が、上昇し続ける研究開発コスト(AI トークンの消費は通常ここに隠されている)に疑問を抱き始めます。特に企業の収益成長が追いつかない場合です。これにより、コスト削減のためにさらに多くの人員整理が行われる可能性があります。Meta の事例のように [1] です。そして、「これらのツールが本当に私たちの作業をより速く、より良くしてくれるのか?」という問いが投げかけられた時、最終的に縮小局面が訪れます。
また、AI トークンに人件費の 10% 以上、あるいはそれ以上に相当する金額を浪費しているスタートアップ企業は、6 ヶ月後には投資家に対して「これは必要だ」と説得するのが極めて困難になると考えます。
全員がトークン課金に移行した暁には、生成 AI を巡るこれほどまでの過熱ぶりが再び見られるかどうか、私は確信が持てません。
AI データセンターと計算資源の経済合理性も成り立たない
AI データセンターについて語られる内容は、すでに現実から完全に乖離しています。彼らはこの時代の荒唐無稽さがどれほど深刻なものか、自覚していないようです。
AI データセンターは建設にも運行にも巨額の費用がかかるが、実際の収益は極めて少ない
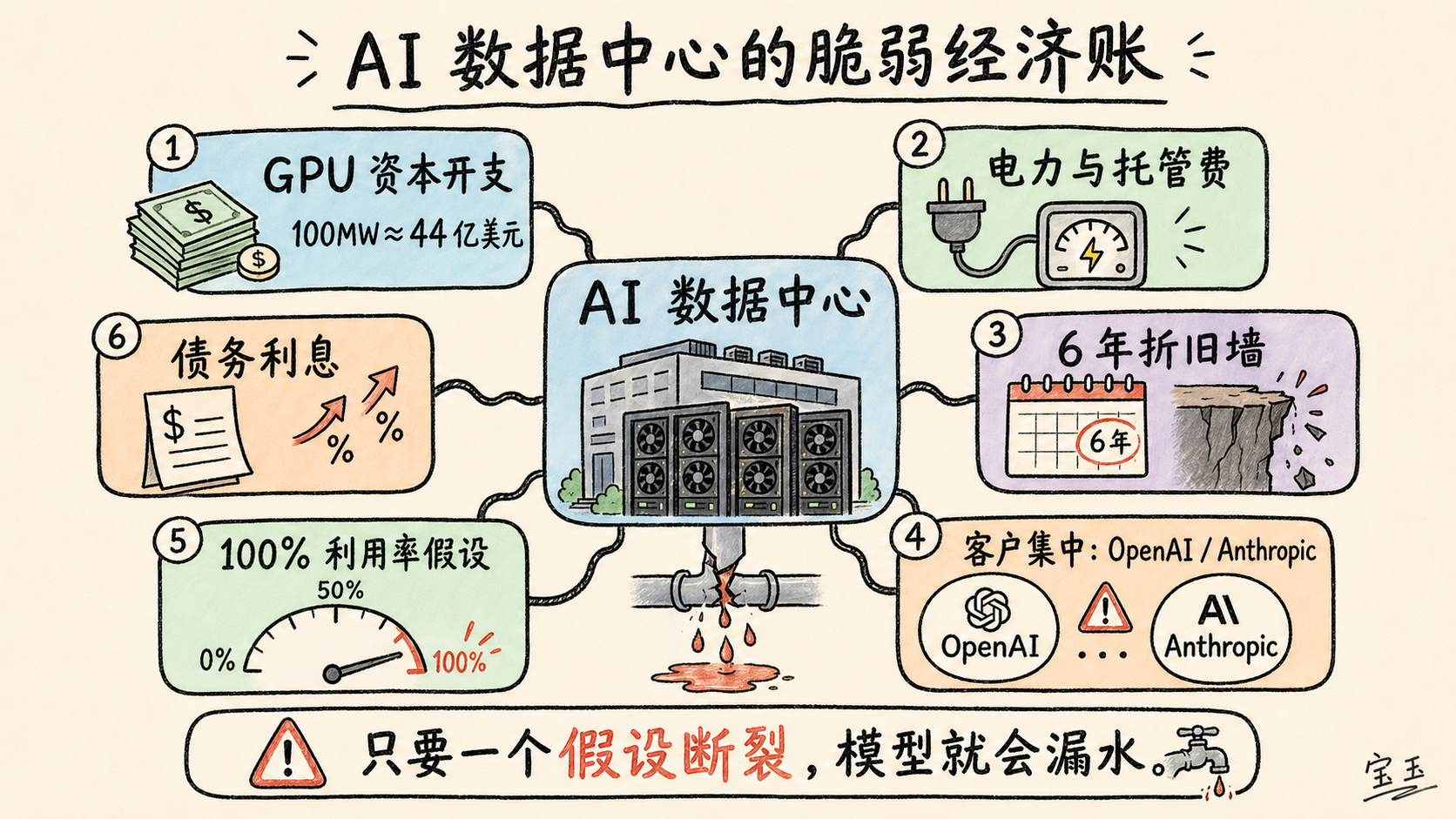
TD Cowen のジェローム・ダーリング氏によると、1 メガワットあたりのデータセンター容量には、約 3,000 万ドルの重要 IT 設備(GPU および関連ハードウェア)と、1,400 万ドルのデータセンター容量コストが必要です。データセンターの建設には規模にもよりますが 1 年から 3 年を要し、電力供給が利用可能であることを前提としています。
2028 年末までに完成予定とされる 114GW のデータセンターのうち、[実際に何らかの形で建設中なのはわずか 15.2GW に過ぎません] [2]。ここでいう「建設中」とは、単に「地面を掘り起こした状態」である可能性さえあります。これは決して、あるいはそうあるべきでもないですが、その施設がすぐに提供できる容量が直ちに稼働する意味着ではありません。
[1]: https://www.wsj.com/tech/ai/the-ai-splurge-is-costing-big-tech-its-workforce-34a88e68?ref=wheresyoured.at
[2]: https://www.wheresyoured.at/four-horsemen-of-the-aipocalypse/#nvidia-claims-to-have-1-trillion-in-sales-visibility-through-2027-but-only-285-billion-gpus-worth-of-data-centers-are-under-construction-%E2%80%94-nvidia-is-selling-years%E2%80%99-worth-of-gpus-in-advance-and-warehousing-them:~:text=for%20all%20involved.-,AI%20Compute%20Demand%20Is%20Being%20Inflated%20By%20Anthropic%20and%20OpenAI%2C%20With%20More%20Than%2050%25%20of%20AI%20Data%20Centers%20Under%20Construction%20Built%20For%20Two%20Companies%2C%20and%20Only%2015.2GW%20of%20Capacity%20Under%20Construction%20Through%20The%20End%20of%202028,-Pale%20Horse
サイドバー:もしここでより深い数学的詳細に興味があれば、私の有料ニュースレターを購読してください。そうすれば、私が構築した「バスタードデータセンターモデル」を見ることができます。このモデルは、複数のアナリストと超規模クラウドプロバイダーの情報源の協力のもとで完成しました。
まずは簡単なところから始めましょう:今後「100MW」という数字を目にしたら、それは「44 億ドル」と理解してください。そのうち相当な部分が NVIDIA GPU の購入費に充てられます。
つまり、AI データセンターは開設時点で数百万ドルの赤字を抱えてスタートすることになります。仮に 6 年間の償却期間(depreciation)を設定したとしても、採算が合うまでには_非常に長い年月_が必要です。さらに、NVIDIA の年間アップグレードサイクル により、最初の顧客契約を完了した頃には、その GPU はすでにほとんど価値を失っている可能性が高いのです。
現時点では、OpenAI と Anthropic の他に、AI 計算リソースに対して十分な規模の顧客層が存在するかどうかは不明です。現在建設中の AI データセンターの 50% が OpenAI と Anthropic の需要に支えられており、2028 年末までに建設が完了する容量はわずか 152GW に過ぎません。もしこれらの企業のいずれかが支払い能力を失えば、それは巨大なシステム上の脆弱性を生み出します。
いずれにせよ、これらのデータセンターの継続的な課金基準も明確ではありません。B200 GPU のスポット価格(spot price)は時間あたり約 4.50 ドル程度ですが、長期契約では通常はるかに低い価格が設定されます。The Information の報道によると、ある創業者は 1 年間のコミットメントに対して、GPU あたり時間あたり約 3.70 ドルで契約したと述べています。
明確にしておく必要がありますが、私たちは_スポットコスト_と_契約による計算リソース_を厳密に区別する必要があります。スポットコストとは、他社のサーバー上でランダムに GPU を起動する際の価格を指します。一方、契約による計算リソースは、データセンターの資本支出(capex)の大部分を構成しています。多くのデータセンターは_1〜2 社の大規模顧客_のために建設されており、これらの顧客はより低い総合単価について交渉する可能性が高いのです。
その結果、多くのデータセンターが時間あたり受け取る金額は 3.70 ドルを大きく下回ります。なぜなら、それらはメガワット(またはキロワット)あたりの課金方式を採用しているからです。
そして、ここから経済的な計算が崩れ始めます。
100MW データセンターが機能不全に陥った際の経済計算:時間あたり 2.55 ドル、満室時の粗利益率 16%、しかし債務により依然として黒字化せず
これは 100MW データセンターの初期コストです。100MW のデータセンターでも、実際には課金可能な設備負荷は 85MW に満たない場合があります。超大規模クラウド事業者の課金システムに詳しい人物との議論に基づくと、1MW あたり年間約 1,250 万ドルの収益が見込めるとされており、これは年間で約 10.63 億ドルに相当します。
一点補足しておきますが、多くのデータセンター企業は自らデータセンターを建設するのではなく、Applied Digital のような会社(「ホスティングパートナー」または「colocation partners」とも呼ばれます)にこの業務を委託しています。例えば、CoreWeave は Applied Digital に託児料を支払うことで、同社のノースダコタ州にあるデータセンターを利用しています。一方、CoreWeave はデータセンター内部のすべての GPU やその他の技術設備を管理・運用します。
この経済的な不整合を説明するために、私は「理論上の」例を用います:ある「理論上の」AI 計算会社へデータセンターが賃貸されるというケースです。
このデータセンター内に設置されている GPU はおそらく NVIDIA の Blackwell チップでしょう。より具体的には、8 枚の B200 GPU で構成されたポッド(pod)を採用している可能性が高く、各ポッドの定価は約 45 万ドル、つまり 1 枚あたり 56,250 ドルとなります。85MW の重要 IT 負荷を想定し、1MW あたりの包括的な資本支出(CapEx)は約 3,678 万ドル、総 IT 資本支出は約 31.26 億ドルに達します。そのうち約 26.7 億ドルが GPU の購入費として使われます。
このデータセンターはノースダコタ州の Ellendale に位置すると仮定しましょう。同地域の工業用電気料金は 1kWh あたり約 6.31 セントで、年間電気代は約 5,540 万ドルとなります。情報源との議論に基づき、保守、人件費、電源装置の交換などにかかる継続コストは収益の約 12% と推定され、これは年間約 1.28 億ドルに相当します。これにより総コストは 1.834 億ドルとなります。
待ってください、すみません。重要 IT 負荷に対してホスティング料(colocation fee)も支払う必要があります。Brightlio の情報によると、この費用は通常、設置規模や立地に応じて kW あたり月額 180〜200 ドルですが、私は 130 ドルのケースも見たことがあります。ここでは 130 ドルで計算し、年間約 1.33 億ドルとします。すると総コストは 3.164 億ドルに上昇します。
さて、これはまだ 10.6 億ドルを下回っているので、私たちはまだ大丈夫でしょうか?
いいえ、違います!IT 設備の減価償却費として 31.26 億ドルを考慮する必要があります。6 年間の償却期間と仮定すると、年間約 5.21 億ドルとなります。これにより年間総コストは 8.374 億ドルとなり、残りの利益は約 1.686 億ドル、つまり粗利益率(gross margin)で約 16.7% です……
……*前提は、あなたが常に 100% の稼働率を維持していることだけです!* ご覧の通り、データセンターでは GPU を設置し、顧客をオンラインにするまでに 1〜2 か月かかる場合があります。この期間中、あなたは収入がゼロなのに、さらに損失を被ります。なぜなら、ホスティング料や電気代、運営コストを引き続き支払わなければならないからです。ただし、電気代とホスティング/運営コストは低い割合で計算されます(私のモデルでは、電気代を 10%、ホスティング/運営コストを 15% と見積もっています)。つまり、あなたは毎日約 327 万ドルの損失を被ることになります。
この例では、稼働開始までさらに 1 か月かかったと仮定しています。つまり、すでに約 1.02 億ドルを支払っており、これは二度と回収できないお金です。この金額を第 1 年の総コストと減価償却費に含めると、総コストは 9.394 億ドルに達し、粗利益率はわずか 6.6% となります。
待ってください、ひどい話ですが、あなたはこれらの GPU を買うために借金をしたのでしょうか?*本当にそうしましたか?* これはどれほど悲惨なことでしょうか。ああ_神様_——あなたは 6 年物の資産担保ローン(asset-backed loan)を利用し、貸付額対価値比率(loan-to-value ratio, LTV)が 80% のものです。つまり、金利 6% で 28 億ドルを借り入れたことになります。
あなたの銀行は、その永遠の寛大さをもって、あなたに以下のプランを提供しました:12 ヶ月の据え置き期間(利息のみ支払い)。これにより、利息は約 1.68 億ドルとなります。これは第 1 年の総コスト(公平を期すため、この 1 か月の遅延分は除く)を約 10.05 億ドルに押し上げます。一方、あなたの収入は 10.6 億ドルです。
粗利益率はわずか 5.19% ですが、あなたは元本の返済さえまだ始めていません。元本返済が始まると、毎月 5,410 万ドルのローン返済が必要となり、今後 5 年間は毎年約 6.49 億ドルを支払うことになります。これによりコストは約 14.8 億ドルに達し、粗利益率は約マイナス 40% となります。
そして私は強調しておきます:これはすべて、あなたが 100% の稼働率を維持し、かつ常に支払いを遅延させないテナントを持っているという前提に基づいています。

Stargate Abilene は大惨事:GPU 時間あたり 2.94 ドル、年間収益 100 億ドル、数年の遅れ、そして毎年数十億ドルを失うテナントがたった 1 つだけ
データセンター史上、経済的に最も実現可能であるはずだったプロジェクトについて語りましょう。それは世界最大の AI 企業向けに建設された大規模キャンパスであり、数十年の歴史を持つ超大规模クラウドプロバイダーに近い Oracle によって建設されました。Oracle は過去、企業や政府に対して高価なデータベースおよびエンタープライズ管理ソフトウェアを販売してきました。
はは、もちろん冗談です。この場所はまさに地獄のような悪夢です。
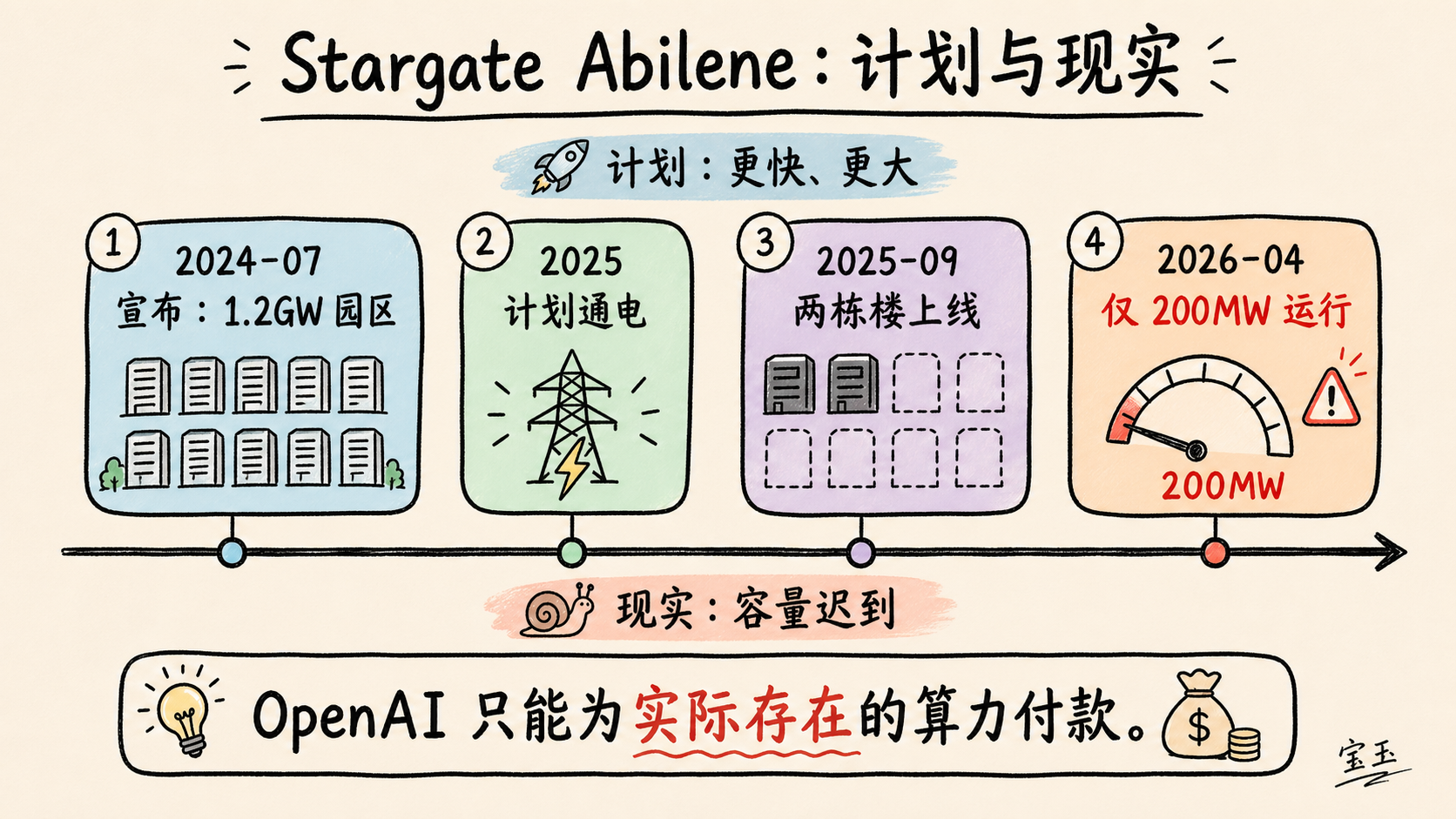
Stargate Abilene は 8 棟の建物で構成され、総規模 1.2GW、主要 IT 負荷は約 824MW のデータセンターキャンパスであり、2024 年 7 月に最初に発表されました。2026 年 4 月 27 日現在、稼働して収益を発生させているのは 2 棟のみで、3 棟目にはまだほとんど IT 設備が設置されていません。私の推計では、Stargate Abilene の総コストは約 528 億ドルに達します。
私の報道に基づくと、Oracle は Stargate Abilene が年間約 100 億ドルの収益をもたらすと予測しています。また、単一顧客である OpenAI のために建設された 7.1GW のデータセンター容量に関する総収入は約 750 億ドルと推計しています。私の報道でも触れた通り、Oracle は 2024 年時点で、Abilene のホスティング料と電気代だけで年間少なくとも 21.4 億ドルが必要であり、この費用は土地開発業者の Crusoe に支払われると見積もっていました。
さらに付け加えるなら、Oracle が Abilene の建設コストをすべて負担しているように見えます。
私の計算と報道に基づくと、Abilene が完全稼働した後の粗利益率は概ね 37.47% と推計されます:
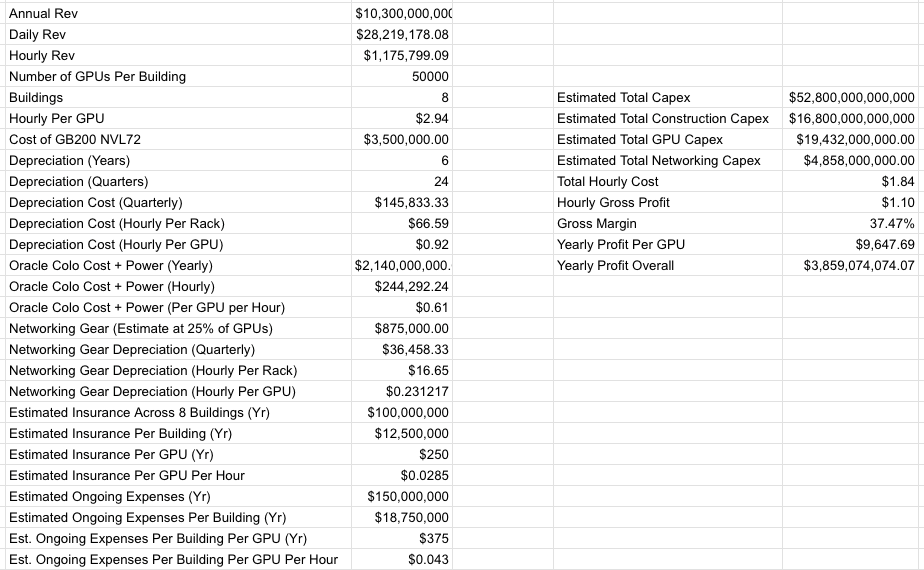
この 37.47% という粗利益率は、Oracle の実際の保険コストや人件費の正確な数値を把握していないため、おそらく過大評価されている可能性が高いことを付記しておきます。あくまで本誌で入手した文書に基づいた推計に過ぎません。また明確に言っておきますが、Oracle は_自社のすべての運命_を Stargate Abilene といったプロジェクトに賭けています。同社は前期に数十億ドルの費用を負担しており、仮に OpenAI がすべての支払いを遅滞なく行ったとしても、この事業が黒字化するまでには数年を要します。
残念なことに、Abilene の資金のうちどれほどが債務(借入金)によって賄われているかを確認することはできません。私が知っているのは、Oracle が 2025 年 9 月に約 180 億ドル規模の多様な債券を発行し、その償還期間は 7 年から 40 年まで多様であること、そして直近の四半期決算でフリーキャッシュフローがマイナス 247 億ドルであったことです。
また、開発業者の Crusoe と 15 年間の賃貸借契約を結んでいることも知っています。Oracle の未来は OpenAI が支払いを継続できる能力に大きく依存しており、OpenAI の支払い継続能力は、Oracle が Stargate Abilene を完了させる能力にかかっています。
さらに付け加えるなら、年間の 38.5 億ドルという利益が実現するのは、OpenAI が支払いを遅滞なく行い、Abilene の利用権を最速で引き渡し、すべてが計画通りに進行した場合に限られます。
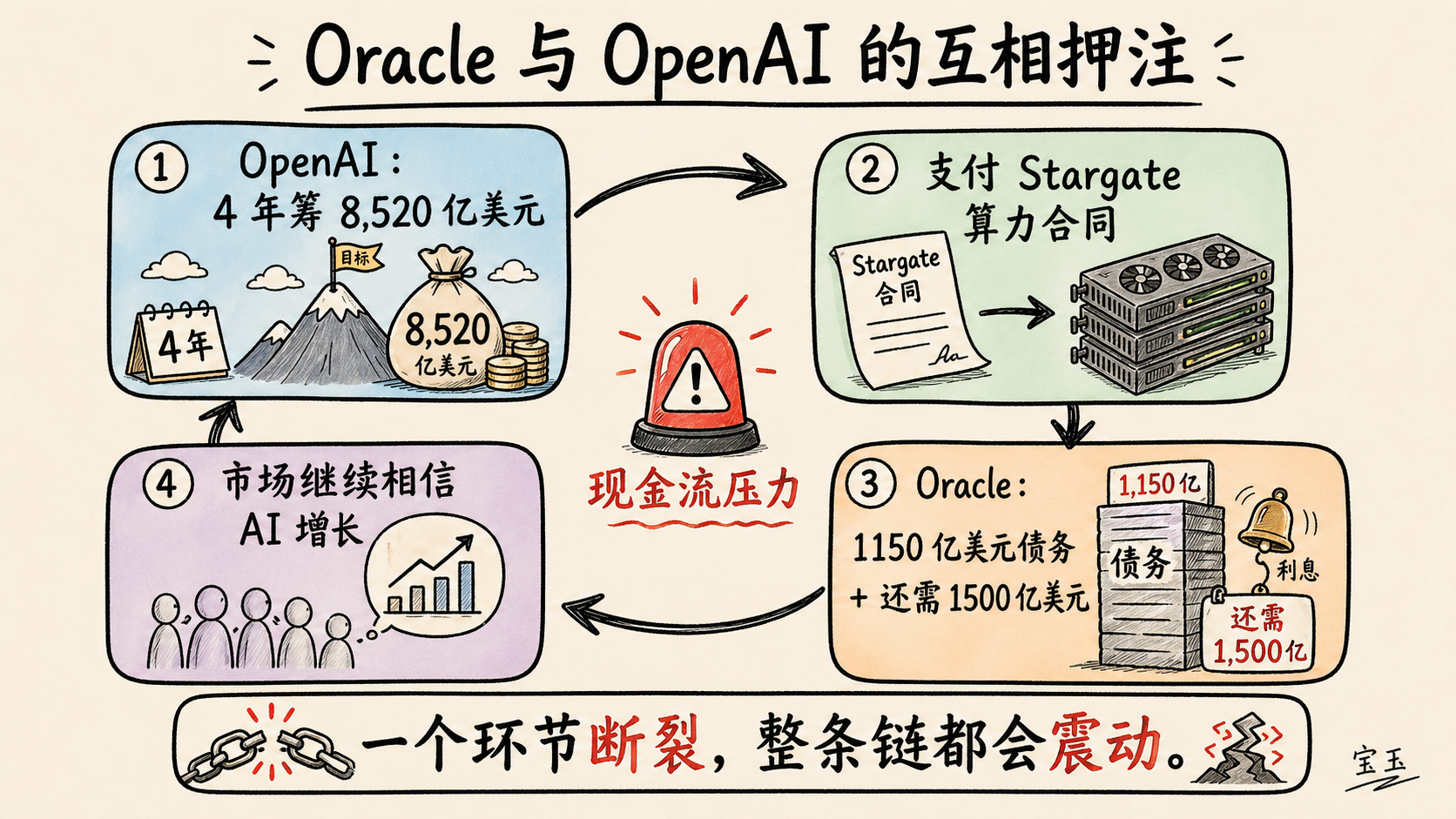
もし OpenAI が今後 4 年間で収入、資金調達、債務を通じて 8,520 億ドルを確保できない場合、Stargate データセンタープロジェクトは Oracle を破滅させる
残念ながら、実際には全く逆のことが起こっています:
**
DatacenterDynamics の報道によると、最初の 200MW の電力は当初「2025 年」に供給開始される予定でした。時が経つにつれ、入居時期は「2025 年前半」とされ、「2025 年に 1GW に達するポテンシャルがあるが「アビリーンは計画通りに進行しており、『96,000 個以上の NVIDIA Grace Blackwell GB200 が納入された』」と述べています。つまり、これは 2 棟に必要な GPU の数を指しています。
4 ヶ月後の 2026 年 4 月 22 日、
Oracle がツイート によると、「……アビリンでは 200MW が稼働しており、8棟のビルからなるキャンパスの引き渡しは予定通り進行している」とのこと。ここでいう 200MW が、重要な IT 容量を指すのか、それともアビリン・キャンパス全体の利用可能電力を指すのかは現時点では不明である。いずれにせよ、この規模では 2棟分のビルしか賄えない。つまり、Oracle の「予定通り」という主張は絶対的に成り立たない。
これは重大な問題だ。OpenAI は実際に存在する計算リソースに対してのみ支払いを行うことが可能であり、現在実際に収益を生み出している重要な IT 容量はわずか 206MW に過ぎない。3棟目のビルが稼働するには、少なくともあと1ヶ月、あるいは四半期を要する見込みである。
しかし、Stargate データセンター・プロジェクト全体には、これよりもはるかに大きく、存亡に関わる別の問題が存在する。このプロジェクトが成立するのは、OpenAI が漫画のような荒唐無稽な予測を実現した場合に限られるのだ。
念のため、これらの数値を再確認しよう。現在進行中の 7.1GW の Stargate データセンターが完成すれば、年間約 750 億ドルの収益をもたらすことになるが、総コストは 3,400 億ドルを超える見込みだ。Oracle のフリーキャッシュフローはマイナス 247 億ドルであり、他の事業セグメントは停滞傾向にあるため、低収益から中収益へと転換したクラウド事業が唯一の成長エンジンとなっている。
OpenAI が計算リソース契約(Amazon、Microsoft、CoreWeave、Google、Cerberas などのパートナー企業向けおよび Oracle 向けを含む)を本当に履行するためには、今後4年間で収入と/または資金調達を通じて合計 8,520 億ドルを確保・獲得する必要がある。これは、事業が毎年 250% を超える成長率を示し、2030 年末までにほぼ10倍規模に拡大することを意味する。さらに、その時点ではキャッシュフローの黒字化(cashflow positive)を実現する方法を見出さなければならず、初めてこれらの数値は妥当性を帯びるのだ。
明確に述べておこう。OpenAI の予測によれば、今後4年間で 6,730 億ドルの収益を上げ、そのために 2,180 億ドルを費やすことになるという。これは極めて非営利的なビジネスモデルである。仮にそれがそうではないとしても、Oracle に支払いを継続するためには、現状よりもはるかに多くの資金を稼ぎ出す必要がある。
私が 750 億ドルという数字を算出する際、Vera Rubin GPU は1メガワットあたり約 1,400 万ドルの収益を生むと仮定した(この数値はデータセンター業界に詳しい情報源と確認済みである)。そして、残りの Stargate データセンターに含まれると予測される 4.64GW の重要な IT 負荷(IT load)にこの単価を適用したものである。
OpenAI の数値は、The Information が報じた OpenAI の予想される資金燃焼速度と収益漏洩データに基づいています。これらのデータによると、同社は 2030 年末までに 6,730 億ドルの収益を達成し、そのために 8,520 億ドルを燃費(キャッシュバーン)すると予測しています。
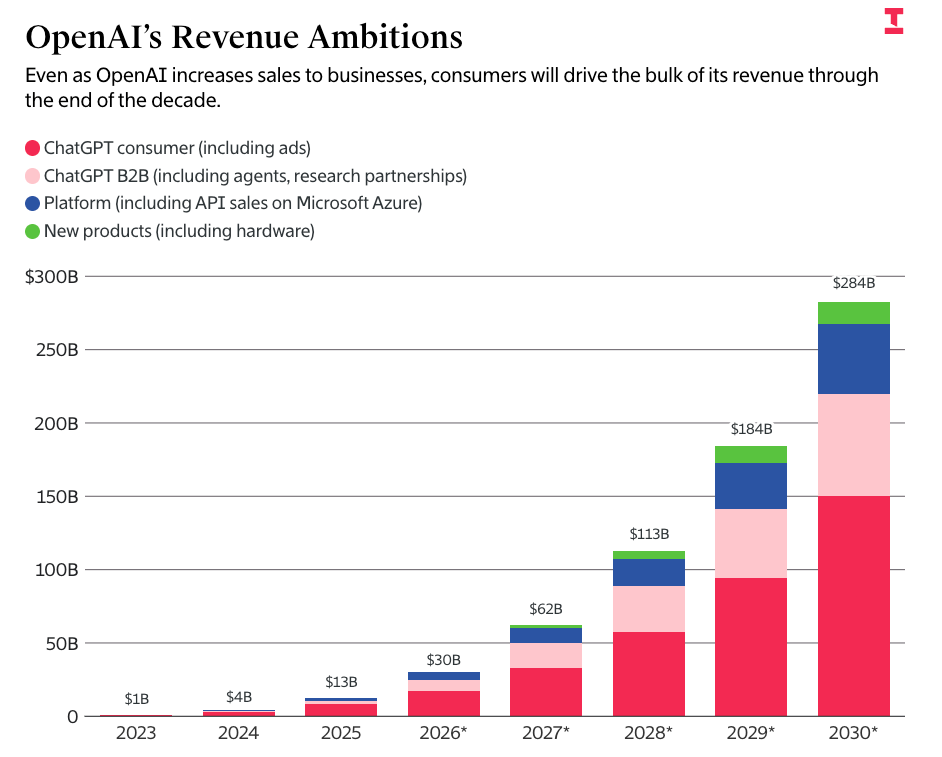
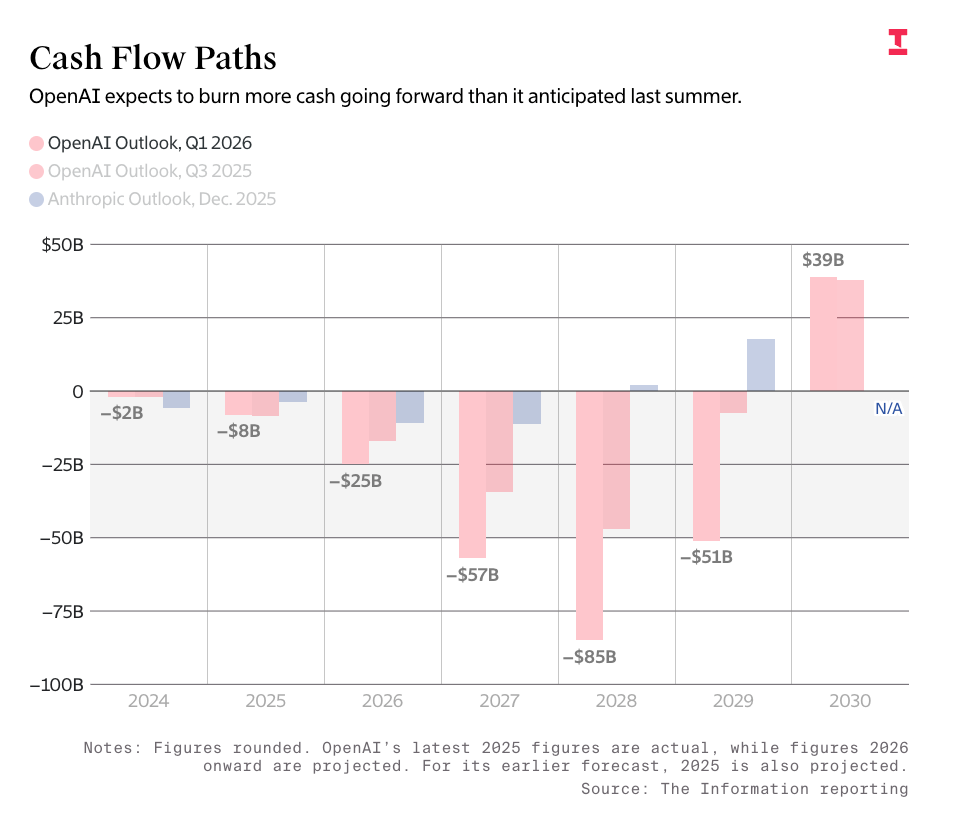
私は明確に言っておきます:これらの数字がどれほど「馬鹿げているか」を説明せずに、記者たちがこれらを繰り返すなら、少しは恥じるべきです。私が金曜日に公開した有料記事からの引用をご覧ください。
つまり、OpenAI は 2 年後の収益が TSMC を超えると予測しており、3 年後には年間の収益が Meta とほぼ同等になり、2030 年末には Microsoft の過去 12 ヶ月分の約 3,000 億ドルに匹敵する年間収益を達成すると見込んでいます。
もし OpenAI がこれらの計算資源(コンピュート)の支払いができない場合、Oracle は「死」に直面します。なぜなら、同社は Stargate データセンターの建設のためにすでに約 1,150 億ドルの債務を負っており(Stargate の完成にはさらに 1,500 億ドルが必要ですが)、その完了のためにもう 1,500 億ドルを調達する必要があるからです。
Oracle は現在、年間収益が約 640 億ドル(640 億ドル)の企業であり、直近の四半期におけるフリーキャッシュフローはマイナス 247 億ドルでした。同社は 2025 年 9 月に 180 億ドル規模の債券を発行し、2026 年 2 月には 250 億ドル規模の債券を発行しました。さらに 3 月のある時点で、時価発行による 200 億ドル規模の株式計画を完了しました。この資金調達は数ヶ月にわたり「完了済み」とされてきましたが、Stargate Wisconsin および Shackelford 向けの380 億ドル規模のプロジェクト融資は、つい最近になって完了したようです。また、Stargate Michigan に関連する140 億ドル規模のデータセンター債務もこれに含めて計算しています。
いずれにせよ、Oracle の資本力では Stargate Abilene を完了させるには不十分です。このプロジェクトを完遂するには、少なくとも追加で 1,500 億ドルが必要であり、これは他のパートナーが約 300 億ドルの費用を負担すると仮定した場合の数値です。正直なところ、実際にはこれ以上の金額が必要になる可能性さえあります。
私は明確に述べておく必要があります:*OpenAI がなければ、Oracle にこの収益を稼ぐ他の道はありません*。これらのプロジェクトはすべて、データセンター自体が将来見込むキャッシュフローによって資金調達され、支払われることになります。
私が懸念していることだけではありません。OpenAI の Sarah Friar も、同社がユーザー数および収益目標の達成に失敗した後に、同様の懸念を表明しています。『ウォール・ストリート・ジャーナル』の報道によると:
OpenAI は最近、自ら設定した新規ユーザー数および収益目標を達成できず、これらの挫折により同社の上層部は、データセンターへの巨額の支出を支える能力に疑問を抱き始めている。
事情に通じた人々の話によると、最高財務責任者(CFO)の Sarah Friar は他の企業の指導者に、収益成長が十分でなければ、将来の計算契約を支払うことができない可能性があると警告している。
ここ数ヶ月、取締役会メンバーは同社のデータセンター取引をより厳しく精査し、事業の減速にもかかわらず最高経営責任者(CEO)の Sam Altman がさらに多くの計算リソースを獲得しようとする姿勢に疑問を呈している。
これでもまだ心配が足りないなら、以下の内容でさらに不安になるかもしれない:
彼女は役員や取締役に対し、社内統制の改善が必要だと強調し、OpenAI は上場企業に求められる厳格な報告基準を満たす準備ができていないと警告した。一部の関係者によると、Altman 氏はより積極的な IPO(株式公開)スケジュールを好んでいるという。
これは確かに今世紀末までに 8,520 億ドルの収益を上げる会社のように聞こえるだろう!
Anthropic も OpenAI と同様に問題がある:Google および Amazon から最大 10GW の計算リソースを確保し、年間収益規模は 1,000 億ドル超と約束
私はしばしば OpenAI の荒唐無稽な約束を批判してきたが、Anthropic も決して後れを取っていない。同社は Google と Amazon からそれぞれ「最大」5GW の容量を確保すると約束している。この容量規模に基づいて推定すると、これらの取引には約 1,000 億ドル相当の計算リソースの実際のコミットメントが含まれていると考える。
もちろん付け加える必要があるが、Google と Amazon は Oracle よりもはるかに賢明であり、それほど絶望的でもない。つまり、Anthropic が最終的に資金不足に陥っても、両社は衝撃を耐えうるというわけだ。これらの取引における「最大」という言葉は、両社にとって急需の回旋余地を与えており、Oracle にはそのような余地が全くない。
それでも、約束を本当に履行するためには、Anthropic は 2030 年末までに毎年 250 億ドルから 1,000 億ドルを計算リソースの購入に充てる必要がある。
Anthropic の CFO は 3 月、同社の設立以来の総収益は 50 億ドルであると述べている。
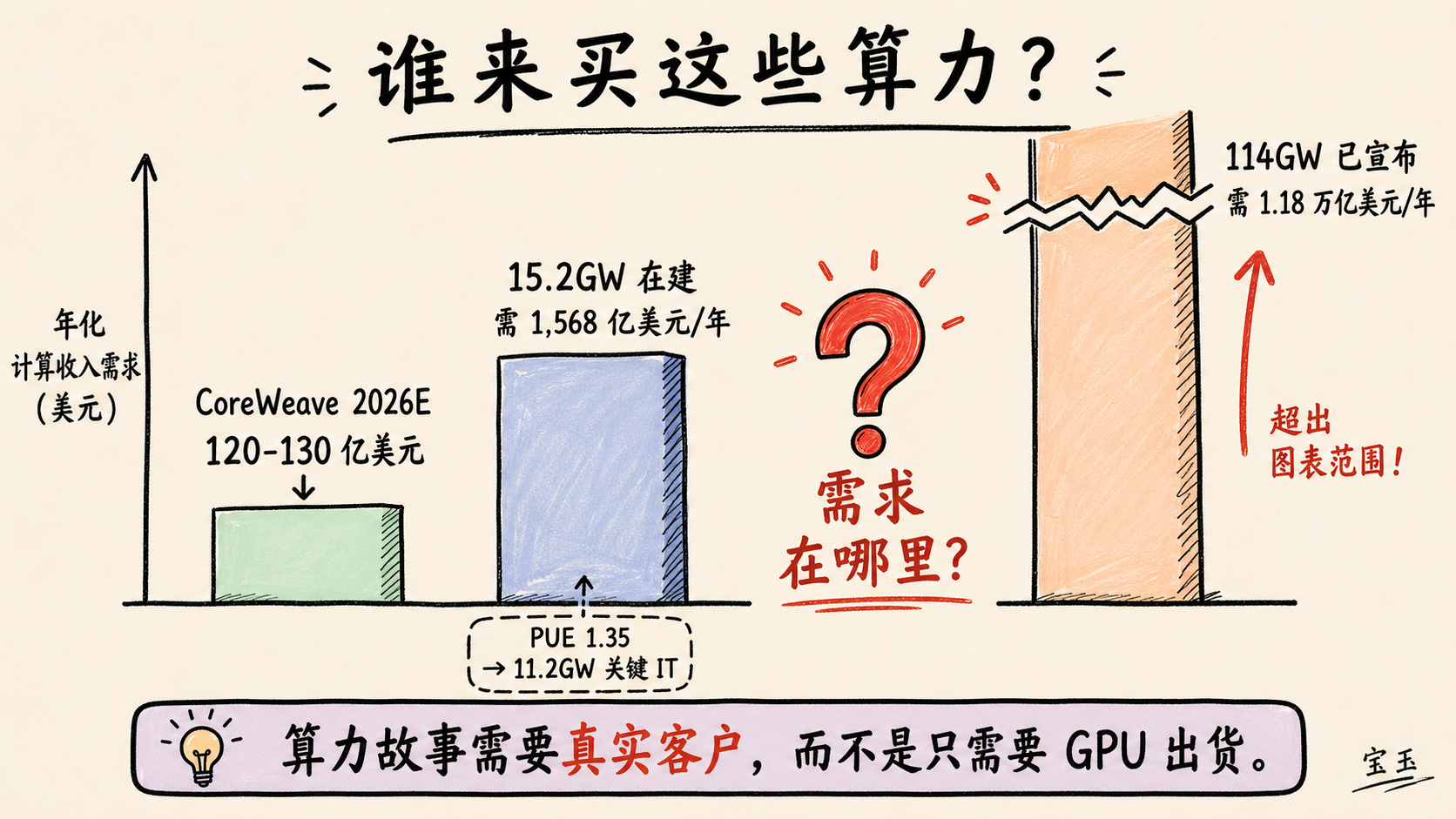
現在建設中の 15.2GW の AI データセンターを支えるには年間 1,568 億ドルの AI 計算リソース収益が必要であり、もし発表されたすべての 114GW を支えるなら、1.18 兆ドルが必要となる
ジェンセン・ファンは頻繁に、NVIDIA が数千億ドル規模の GPU を出荷していると言います。これらの数字を巡るほぼ官能的な興奮が、しばしば厄介な問題を覆い隠しています:その計算能力は実際には誰に売っているのですか?ジェンセン?
2028 年末までに建設され、引き渡しが予定されている 15.2GW のデータセンター容量を想定し、電源使用効率(PUE: Power Usage Effectiveness)が約 1.35 と仮定すると、主要な IT 負荷は約 11.2GW となります。メガワットあたり 1,400 万ドルという計算に基づけば、これらのデータセンターが建設する価値があるためには、年間約 1,568 億ドルの GPU リース収入を達成する必要があります。
もし理論上 2028 年末までに稼働予定となる 114GW の容量もすべて含めると、この数字は年間 1.18 兆ドルの収益に跳ね上がります。
背景をお伝えしましょう:CoreWeave は最大の「ニュークラウド(neocloud)」事業者であり、顧客には Meta、OpenAI、Google(OpenAI のサービス提供)、Microsoft(OpenAI のサービス提供)、Anthropic、そして NVIDIA が含まれます。同社の年間収益は約 51 億ドルと推定されており、2026 年の収益は 120 億〜130 億ドルと予測されています。
では、この膨大な計算能力の顧客は一体誰なのでしょうか?これらの容量が完成した時点で、彼らはまだ購入するのでしょうか?多くの異なるデータセンターが、建設初期からすでにテナントがいると主張していますが、それらのテナントが支払いを開始するのはデータセンターが完成した後です。*もしテナントが AI スタートアップであれば、データセンターが完成した時点でその企業は存続しているのかという疑問を持つのは妥当だと考えます。*
覚えておいてください:AI 計算能力の顧客の多くは、資本支出を貸借対照表から転嫁しようとする超大规模クラウド事業者か、あるいは黒字化していない AI スタートアップです。Anthropic と OpenAI はどちらも今後数年間で数百億ドルを燃焼させる計画を持っており、両社とも収益化への道筋はまだ見えていません。
これはつまり、AI 計算能力収入の大部分——おそらくは大多数——が、リスク資本と債務からの継続的な流入に依存していることを意味します。そしてこれら二つは、投資家が生成 AI が世界で最大かつ最も巨大で、無敵のものになると信じている間のみ成立するものです。
これがどうして成立し得るのでしょうか?誰がこのデータセンター容量に対して支払いを行うのですか?それは誰のために建てられているのでしょうか?真の需要はどこにあるのでしょうか?
もし需要が本当に存在するのであれば、*これらの顧客は一体何をもって支払うのでしょうか?*
生成 AI は黒字化せず、持続可能ではなく、ますます高騰する
OpenAI と Anthropic が 2028 年または 2029 年に黒字化を達成すると報じる複数の記事があるにもかかわらず、それらがどのようにして実際に利益を生み出すのかを私に説明できる人はいない。特に、両社の利益率が予想を下回っており、その利益率ですら数十億ドル規模のトレーニングコストを除外した上でさえあることを考慮すれば、なおさらだ。
私はこの質問を_何年も_問い続けてきた。Anthropic や OpenAI の新しいニュースが入るたびに、聞かされるのは予想以上に数十億ドルを失ったこと、利益率が悪化していること、コストが急騰していること、そしてすべてが_ますます高価になっている_ということだ。彼らが以前に約束したのはまさにその逆だった。
Cursor という企業でさえも——同社は一時的に売上総利益率(グロス・マージン)がプラスであると主張し、後に Musk の SpaceX によって近似された買収が行われた——1 月時点の_実際の売上総利益率はマイナス 23%_である。非課金ユーザーのコストを含めると、それはマイナス 31% になる。もしあなたが会計に本当にこだわっているなら、当然_この部分を計算に入れるべき_だ。不思議なことに、Cursor の利益率が「最近プラスに転じた」と報じられているが、その転換幅や転換の仕組み、そして他の詳細については一切不明で、ただ会社が売却できるかもしれないという結論だけが存在する。
これらの AI データセンターがどのようにして成立するのかも私には理解できない。仮にここ数年で確かに顧客からの支払いがあったとしても、それらの経済モデルは完璧な前提の上に成り立っており、誤差を許容する余地がない。_常に_安定した 100% の稼働率(利用率)とテナント率(tenancy)を維持し続けなければならず、そうでなければ数百万ドルが燃え尽き、技術業界で最も高価な過ちによって生み出された何年にもわたる減価償却の壁を効果的に削減することはできなくなる。
仮に奇跡的に成功したとしても、これらは利益が平凡な悪いビジネスだ——最良の場合でも売上総利益率は 70% だが、継続的な支払いと継続的なテナント契約を前提とし、_実際に回収できるまでには整整六年の減価償却が必要_となる。これはそれ自体が困難である可能性が高い。なぜなら、年次アップグレードサイクルによって、支払いが終わる頃にはシステム全体がすでにほぼ時代遅れになっているからだ。
そしてこれらにまだ加算されていないのが:ほとんどの顧客は利益を出しておらず、持続不可能なスタートアップ企業だということだ。
このすべてが最終的にどうなるのか、私は本当にわからない。
これは少し大げさに聞こえるかもしれませんが、私は心から、サブスクリプション型の AI サービスはほぼ詐欺的な欺瞞行為だと信じています。なぜなら、それは核心的な単位経済モデルを歪め、それゆえに大規模言語モデルの可能性さえも歪めているからです。Anthropic や OpenAI といった企業が月額料金で製品を販売し、製品の入手可能性を中心にユーザーの習慣を形成することは、本質的に自社のビジネスを誤解させる方法です:大多数のユーザーがこれらの製品を使用し、現在の形態では持続不可能であり維持也不可能なこれらの製品にワークフローを構築しているのです。
Anthropic の 最近の過激なレート制限調整 は、数か月にわたる過激なマーケティングキャンペーンの直後に発生しました。そのキャンペーンで描かれた体験は、現在のレート制限下ではほぼ不可能になっています。Anthropic の最近の動きによると、明らかに将来のある時点で、月額 20 ドルの低層級サブスクリプションユーザーの一部サービスを取り除く計画 です。これは吐き気を催すほど欺瞞的な経営手法です。Anthropic が製品やサービスについて語る際の曖昧さは、すべてのユーザーに対する侮辱であり、それがメディアに対して何らかの意味で恐怖を抱いていないことを示しています。
私は非常に明確に言います:最近のレート制限の変更により、Anthropic が現在提供している製品は、あなたが至る所で読んでいるその製品とは本質的に異なり、さらに大きく異なります。Anthropic は、自分が 3 ヶ月以内に消滅させることを知っている製品を、明確かつ意図的にマーケティングしています。Dario Amodei は全く気にしていません。メディアが今日彼がでっち上げた数十億ドルの年間収益について報じ続けるか、あるいは成長がすでに鈍化しているある不運な上場 SaaS 会社(Software as a Service:ソフトウェアとしてのサービス)を破壊する supposedly な新製品について報じる限りです。
メディアの皆さん、私は十分な敬意を持ってこのように言います:Anthropic は顧客を虐待しており、それは自分が罰せられないと信じているからです。この会社はあなた方を尊重していません。実際、あなた方に対して相当な軽蔑を抱いています。そのため、すぐにサービスを修復したり、論理的にサービスがなぜ壊れたのか説明したりすることはありません。
これが Anthropic が「Claude Mythos はあまりにも強力すぎてリリースできない(実際には容量の問題)」と*嘘をついている*理由です。そしてそれは単なるまた新しいことのない大規模言語モデルの空砲に過ぎません。Anthropic は、あなたが彼らが売るものを何でも買うと思い込んでおり、システムカードを素早く見ただけで、あなたや編集者が書いていることが真実だと信じてしまうような包装方法をすでに学んでいます。
また、彼らはあなたが*本物の専門家が話すのを待たずに*急いで報道することを知っています。
AI は詐欺であり、これがその詐欺が機能する仕組みです。AI は人間が可能な最速で、最も非効率的だが最もアクセスしやすい形で、我々の前に無理やり押し付けられています。この形式が持続可能なビジネスの何らかのもの ever 生み出すことができないとしても、それは強制的に押し出されます。メディアはすぐに「*これがその大きな出来事だ*」と発表するよう促されています。そこで誰もが同意します:*これが今まさにその大きな出来事だ*と、できる限り多く使用します。重要なのは、サブスクリプション形式でそれを使用することで、人々がそれを体験する際に「このものを提供するには一体いくらかかるのか?」という質問を一切しないことです。
物語は事前に焼き上げられたものだ。LLM(大規模言語モデル)の真のコストを実感している人がほとんどいないため、人々は容易に「これは Uber のようだ」と曖昧な表現を使う。確かに Uber は巨額の赤字を出しながらも倒産しなかった会社だ。「ええと、OpenAI は今年 50 億ドルの赤字を見込んでいるってどういうこと?」と言うよりも、この比喩の方がずっと言いやすい。
こう考えてみてほしい:記者、投資家、経営者、あるいは普通の LinkedIn の休憩室にいる蜥蜴人(リザードマン)として、あなたはたまに「入力トークン 100 万あたり 5 ドル」「出力トークン 100 万あたり 25 ドル」といった価格を目にしたことがあるかもしれない。しかし、そのお金がどれほど速く、あるいは遅く消えていくかを本当に体験したことは一度もないだろう。この製品を真に理解するためには、こうした実感が不可欠だ。Anthropic と OpenAI は意図的にこの実感の欠如を作り出し、2026 年に数百億ドル、2030 年には数千億ドルを燃費する事業を構築しているが、その背景には生成 AI がサブスクリプション(定期購読)モデルを通じて評価されているという事実がある。
LLM はカジノのようなものだ。あなたはディーラーの金で賭けを行いながら、他人に自らの資金で「あるモデルが生産的な成果物を出せるか」という賭けをさせるよう仕向けているのだ。
これは意図的なことだ。彼らは決してコストについて考えさせたくない。なぜなら、あなたが本当にコストについて考え始めると、*この全体が少し狂気じみて見えるから*だ。私は心から信じているが、LLM に基づくサブスクリプションサービスは完全に消滅するだろう。少なくともコード生成を行う製品については、ある程度の規模に達すればそうなる。その過程で、Amodei 氏と Altman 氏は彼らの詐欺を終了させるか、あるいは少なくとも自分がそれを終えたと思い込むことになる。
問題は、これらの人々がすでにあまりにも多くの契約を結んでしまっており、無傷で撤退することが不可能になっていることだ。
OpenAI の CFO(最高財務責任者)は何度も 表明しているが、OpenAI はまだ IPO(株式公開)の準備ができておらず、成長と継続的な義務履行能力について重大な懸念を抱いていると。前述の引用を繰り返す:
**
事情に詳しい関係者によると、首席財務官の Sarah Friar 氏は他の企業のリーダーに対し、収益成長が十分でなければ、同社は将来の計算契約を支払うことができないと懸念していると伝えた。
これは点滅する赤信号だ。理性的な市場であれば、このニュースは Oracle の株価を急落させるだろう。なぜなら、*OpenAI が年間 2,800 億ドルの収益に達できるかどうかは、Oracle が現金を枯渇させないために極めて重要だから*である。理性的なメディア環境であれば、これはあらゆるグループチャットや Slack チャンネルで不安を煽る衝撃波を引き起こすはずだ:OpenAI は果たして持ちこたえられるのか?
これが企業が死に始める前に起きることだ。OpenAI の成長は鈍化しており、それはまさに加速が必要な時期である。同社は 2030 年までに現在の事業規模を約 10 倍に拡大し、義務を果たさなければならない。OpenAI の CFO——この事実を最もよく知っている人物——がこう述べている:「収益が増えなければ、私は OpenAI があの計算契約を支払えないと懸念している」。これは巨大で点滅する警告灯だ!これは演習ではない!
しかし、私を本当に不安にさせるのは『ウォール・ストリート・ジャーナル』の別の一文である。Friar 氏は OpenAI が「上場企業に求められる厳格な報告基準を満たす準備がまだできていない」と考えているというのだ。
*これって何のことだ?* もう一度言ってくれませんか?この会社はすでに 1,220 億ドルを調達し、評価額は 8,520 億ドルに達していると言われていますが、2030 年末までに*8,520 億ドル*を燃やし尽くすと予測されています。まだ会計の整理がついていないのでしょうか?OpenAI はいったいどのような「厳格な報告基準」に達していないというのですか?
一般的に私は、これほどまでに_詮索好き_になるような人間ではありません。しかし問題は、この会社が過去 1 年間でリスク投資資金の約 20% を吸い上げてしまったことです。その一方で、私がどこへ行っても、Altman や Brockman、そして OpenAI の他のすべての男性たちが、彼らの_アイデア_について延々と高談闊論し、_一般の人々がどうすべきか_を説教しているのを聞かされます。優雅にふらつきながらゴミのようなソフトウェアをリリースし、他人のお金を浪費するのです。
Anthropic と OpenAI がどれほど多くの市場の空気(注:資金や注目度)を独占しているかを考慮すれば、これら 2 社は製品としても企業としても_完璧でなければならない_はずです。しかし現実は、両社とも自社の経済モデルと成果に関する程度の異なる欺瞞を軸に、自分たちを売り出しているのです。真実を隠蔽し、CEO たちが金銭、権力、注目を蓄積できるようにしています。これは良質なソフトウェアに対する侮辱であり、良質な品味に対する侮辱でもあります——これらは人類が作り出した中で最も高価で、最も信頼性の低いアプリケーションです。それらの誤りは許され、平庸は称賛され、インフラストラクチャーは沈黙する資本の神として崇められています。
生成 AI は侮辱そのものです。それは信頼できず、経済的な計算が成立せず、生み出される成果はその存在を正当化するに足らず、この詐欺を推進しているのは、退屈で、無礼で、貪欲で、社会と断絶し、彼らに反対する可能性のある誰とも断絶した男たちです。それは人々の芸術をすべて盗み取り、環境を破壊し、電気料金を引き上げ、経済破滅の継続的な脅威をもたらし、「今や AI のせいですべてが最悪になっている」という尽きることのないノイズをもたらします。これらすべては、基本的な金融常識か、あるいは基本的な理性を無視できる人々だけが正当化できると主張するソフトウェアを推進するためのものです。
これはすべて高価すぎますし、あまりにも_クソつまらない_です。侮辱的になるほどに退屈しています。意図的にイライラさせます。誰かが AI を大量に使っているという話を聞かされるたびに、その人は虐待的な関係にあるか、あるいはカルトに入信したように聞こえます。その言葉の奥には、微妙な絶望が響いています:「_本当に私に参加する必要があります。なぜならこれは素晴らしいからです;私がこの製品から全く楽しさを得ていないように見えるのは、それがあまりにも効率的だからです。_」AI ができることに、楽さや喜びはありません。大規模言語モデルに、愚かさや奇想天外な発想はありません。すべての対話が空虚な感覚を与えます。
意識化しているか、「より強くなっている」という手がかりを必死に見つけようとしている人々は、実は自分自身への確認を探しているだけです——彼らは何かを発見した最初の人になりたいのです。なぜなら、他者が結論に達する前に同じ結論に到達することは、彼らが生計を立てるための手段だからです。
「最初の」になること——あるいは「最先端」にいることは、内面で何かが欠けている人々が渇望することです。そして这正是詐欺師が最も好む燃料です。なぜなら LLM は_常にうなり声を上げ、まるで何か新しいことをしようとしているかのような感覚を帯びているからです。しかし実際には、数学的には他の動作の繰り返しに制限されています_。
これは深く悲しい時代です。この業界を積極的に支えようとする人々は、避けられない崩壊を単に先送りしているだけです。私が恐れているのは、私たちの市場と一部の経済が、広く受け入れられながら完全に証明されていない仮定によって支えられていることです:LLM は何らかの形で安くなり、AI 創業企業は奇跡的に黒字化し、AI 計算資源を提供することは永遠に利益を生み出し、2030 年までに現在の供給量を10倍にする必要があるというものです。
人々は AI 業界を擁護するために自らを貶めています。なぜなら、これが業界が信者に求めることだからです。「AI の専門家」になるためには、歴史上どの業界よりも最悪の経済計算を意図的に無視し続けなければなりません;製品に明白で目立つ問題を常に説明する必要があり、他人にもそうさせるよう積極的に説得しなければなりません。OpenAI と Anthropic は、自らがどのようにして利益を生むのかについて明確な説明を提供しません。なぜなら、彼らは支持者が決して追及しないことを知っているからです。「AI を完全に信じる」ためには、意図的に眼帯を装着する必要があるのです。
私はこの状況を理解しています。もし OpenAI や/または Anthropic が最終的に崩壊すると受け入れるなら、すべてが少し狂気じみて見えるでしょう。私は心からあなたに真剣に考えてほしいと願います:これらの企業のいずれか、あるいは両方が資金を枯渇させる可能性があります。
私は本当に心配しています。そして、メディアやより広い社会における一般的な懸念の欠如は、私をさらに不安にさせています。
もし私が推測するとすれば、人々は私が単に大げさに騒いでいるだけだと考え、「需要は確実にそこにある」と思うでしょう。
あなたが正しいことを願うのが良いでしょう。
少なくともラリー・エリクソンにとってはそうです。エリクソン氏はすでに保有するオラクル株式 3.46 億株を質入れしています——これは約 615 億ドルの価値があります——「特定の個人債務、各種信用枠を含む」ための担保としてです。翻訳すれば、「彼のオラクル株式を担保にした多くの大型で立派なローン」という意味です。IFR は9月に推計しました(当時オラクル株価ははるかに高かった)、保守的な貸付価値比率 20% を適用すれば、これは彼に最大で 214 億ドルの債務をもたらす可能性があり、銀行が特別に寛大でないという前提での話です。
もし OpenAI が 2030 年末までに収入と資金調達を通じて 8,520 億ドルを確保できない場合、Stargate プロジェクトを支払うことはできません。それはオラクル株式の価値を殺し、一連の追加証拠金通知(マージンコール)を引き起こします。その後エリクソン氏は株式を売却せざるを得なくなり、さらに多くの追加証拠金通知を誘発することになります。どのような救助措置があっても、ラリーの資産を救うことはできません。
つまり、エリクソンの未来は、サム・アルトマンが 4 年以内に 8,520 億ドルの資金調達と収益創出に成功できるかどうかに賭けられています。
幸運を祈ります、ラリー!あなたは本当にそれを必要とするでしょう。
原文を表示
AI 的经济账根本算不通
作者:Ed Zitron**
原文:AI's Economics Don't Make Sense
昨天早上,GitHub Copilot 用户终于得到了一个确认:我一周前报道过的那件事成真了——从 2026 年 6 月 1 日起,所有 GitHub Copilot 计划都将改为按用量计费(usage-based pricing)。
以前,微软会给用户一定数量的“请求(requests)”。现在,它要根据用户实际使用模型的成本来收费。微软把这称为“……朝着一个可持续、可靠、面向所有用户的 Copilot 业务和体验迈出的重要一步”。换句话说,用户每月订阅 GitHub Copilot 花多少钱,就得到等值的 token(词元,token)额度,比如每月 19 美元的套餐,就给你 19 美元的 token。
翻译一下:“我们不能再继续补贴 GitHub Copilot 用户的算力了,否则 Amy Hood 会拿棒球棍开始揍人。”
不管怎样,这份公告本身很有意思。它提前展示了这些涨价将会被包装成什么样:
Copilot 已经不是一年前的那个产品了。
它已经从编辑器里的助手,演变成了一个智能体式平台(agentic platform)。它能运行长时间、多步骤的编程会话,使用最新模型,并在整个代码库中反复迭代。智能体式使用正在成为默认方式,而这会带来明显更高的计算和推理(inference)需求。
今天,一个快速的聊天问题,和一次持续数小时的自主编程会话,可能让用户付出同样的价格。GitHub 一直承担了这类使用背后不断攀升的推理成本,但目前的高级请求模式已经不可持续。
按用量计费可以解决这个问题。它能让定价更好地对应实际使用情况,帮助我们维持长期服务可靠性,也减少我们限制重度用户的必要。
你看,问题并不是“*微软一直在补贴将近 200 万人的计算成本*”,而是“*AI 已经变得太强、太 powerful、太复杂了,所以它基本上已经是另一个产品了!*”
也许 Copilot 的确已经不是“……一年前的那个产品”,但底层的经济错配并没有发生太大变化:微软连续 *三年* 允许用户每个月烧掉超过订阅费本身的 token 成本。根据 《华尔街日报》2023 年 10 月的报道:
个人用户每月为这款 AI 助手支付 10 美元。今年最初几个月,该公司平均每位用户每月亏损超过 20 美元。一位熟悉相关数字的人士说,有些用户每月给公司造成的成本高达 80 美元。
很自然,GitHub Copilot 用户正在反抗。他们说这个产品已经“死了”,已经“彻底毁了”。
而我两年前就在《次贷式 AI 危机》(Subprime AI Crisis)里预言过这一点:
我假设一种次贷式 AI 危机正在酝酿:几乎整个科技行业都买进了一项以极低折扣出售的技术,而这项技术高度集中,并由大型科技公司大量补贴。总有一天,生成式 AI(Generative AI)那惊人且有毒的烧钱速度会追上它们。结果就是涨价,或者公司推出新产品和新功能时附带极其苛刻的费率——比如 Salesforce 的“Agentforce”产品那种离谱的每次对话 2 美元收费——最后连那些预算充足、最忠诚的企业客户也无法证明这笔支出是合理的。
如今,这一天终于到了。因为你使用的每一项 AI 服务都在补贴算力,也因为每一项服务都因此在亏钱:
当你付费使用一家 AI 创业公司的服务时——当然,这也包括 OpenAI 和 Anthropic——你通常是按月付费,比如 Anthropic 的 Claude 有 20 美元、100 美元或 200 美元/月的计划,Perplexity 有 20 美元或 200 美元/月的计划,OpenAI 则有 8 美元、20 美元或 200 美元/月的订阅。在一些企业使用场景中,你会拿到用于完成某些工作单位的“点数(credits)”。比如 Lovable 的 25 美元/月订阅给用户“每月 100 点”,还附带 25 美元(截至 2026 年第一季度末)的云托管额度,未用完的点数还能跨月滚存。
当你使用这些服务时,相关公司就要为你调用的 AI 模型付钱。它们要么按每百万 token 的价格向某个 AI 实验室付费,要么——像 Anthropic 和 OpenAI 那样——向出租 GPU 运行模型的云服务商付费。一个 token 大约相当于 3/4 个单词。
作为用户,你感受到的不是 token 的燃烧,而只是输入和输出的过程。AI 实验室用“token”“消息”或者 5 小时速率限制加百分比进度条来掩盖服务成本。你作为用户,并不知道这些东西到底值多少钱。而在后台,AI 创业公司正在疯狂烧钱,直到最近之前都是如此。
Anthropic 曾允许你每花 1 美元订阅费,就烧掉超过 8 美元的计算成本。OpenAI 也允许类似的事情发生,只是很难衡量具体比例。
AI 创业公司和超大规模云服务商(hyperscalers)曾以为,只要用补贴过的亏钱产品把足够多的人拉进门,让他们深度依赖这些服务,等公司大幅涨价时,用户就不会离开。我想,它们还以为 token 成本会随时间下降。但现实恰恰相反:虽然_某些_模型的价格可能下降了,新的“推理模型(reasoning models)”却会烧掉更多 token,这意味着推理成本不知怎么地反而随着时间变高了。
这两个假设都是错的。因为对于任何接入大语言模型(Large Language Model,LLM)的服务来说,按月订阅模式_根本不合理_。
生成式 AI 的核心经济账已经坏了
可以这样想。当 Uber(不,这件事一点也不像 Uber)开始提高打车价格时,它的底层经济结构并没有改变,呈现给乘客和司机的结构也没有变:用户为一次乘车付钱,司机为一次接单获得报酬。司机仍然要支付油费、车险、地方政府可能要求的各种许可证费用,以及车辆融资相关成本;这些成本并没有由 Uber 补贴。Uber 的巨额亏损来自补贴、无休止的营销支出,以及在无人驾驶汽车等方向上注定失败的研发投入。
生成式 AI 订阅和 Uber 完全不是一回事
为了说明 AI 定价错配的规模,我想让你想象另一个历史版本:在那个世界里,Uber 的商业模式完全不同。
生成式 AI 订阅就像 Uber 每月向用户收 20 美元,然后允许用户坐 100 次车,只要每次不超过 100 英里都行;与此同时,汽油价格是每加仑 150 美元,*而且油钱由 Uber 来付*,因为有人坚持认为总有一天石油会便宜到不值得计量。
最终,Uber 会决定开始向用户收取一个月费,让他们获得叫车资格,然后再按他们消耗的汽油收费。突然之间,用户从每月 20 美元坐 100 次车,变成了先付 20 美元才能接触到司机,再为一次 10 英里的车程支付 26 美元。可以理解,用户会有点不爽。
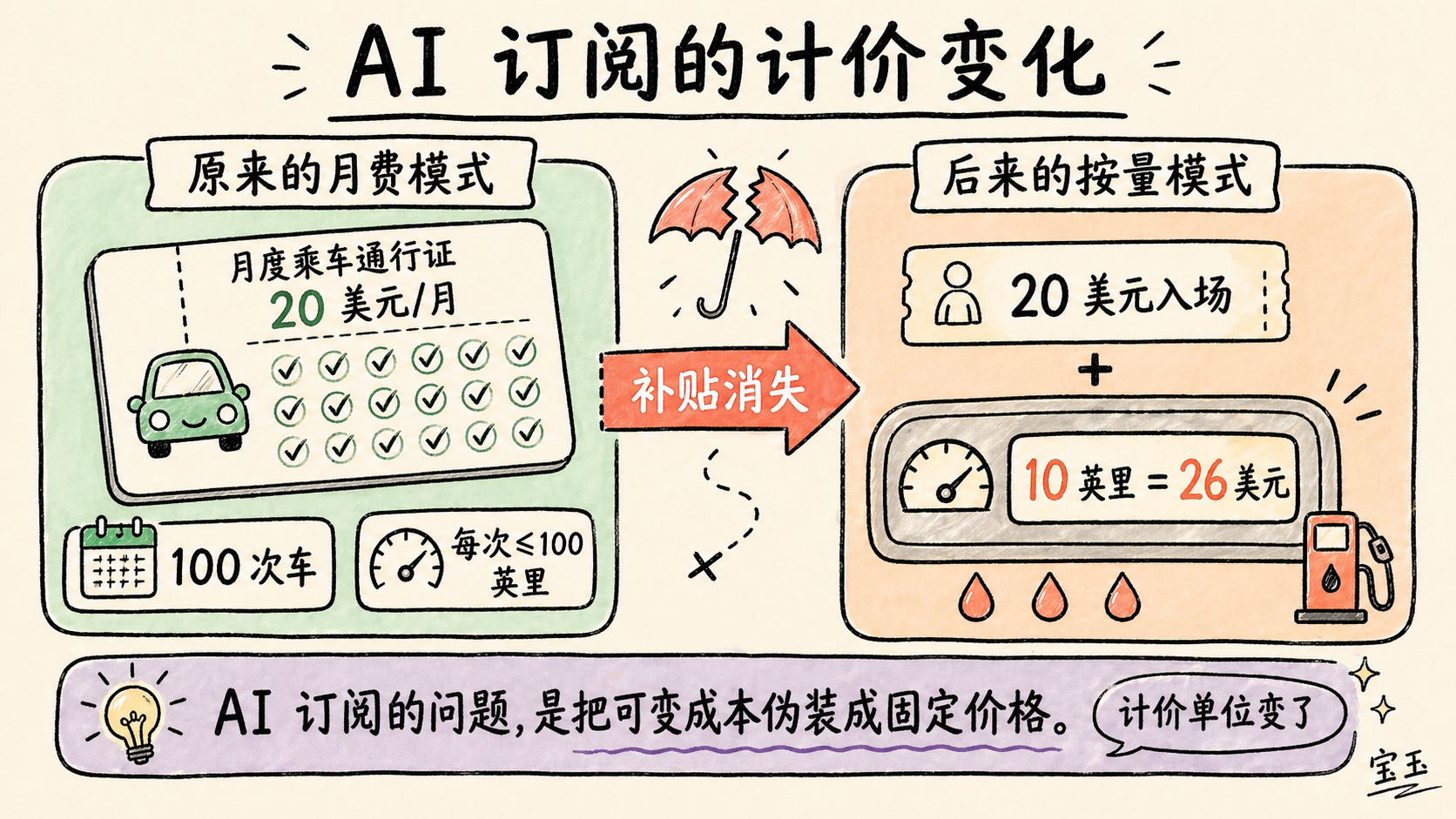
这听起来有点夸张,但其实相当准确地描述了生成式 AI 行业正在发生的事,尤其是 GitHub Copilot 正在发生的事。
GitHub Copilot 之前的定价允许用户每月使用 300 次高级请求,同时还可以使用 GPT-5 mini 之类的模型发送“无限聊天请求”。每一次请求,用微软自己的话说,就是“……你要求 Copilot 为你做某事的任何互动”。在请求制生命周期的后期,更昂贵的模型会消耗更多请求额度,比如 Claude Opus 4.6 会消耗 3 次高级请求。当你用完高级请求后,Copilot 会允许你在当月剩余时间里随便使用那些更便宜的模型。
而且这甚至还不是一开始的情况。直到 2025 年 5 月之前,微软都在给用户无限制使用模型的权限。即便后来只是开始加一点限制,用户也已经非常愤怒,因为他们不接受这个产品有_任何_限制。
微软——就像每一家 AI 公司一样——用一个不可持续的服务骗了自己的客户。因为用月费订阅来销售由 LLM 驱动的服务,*从来、从来就没有合理过*。
如果你想知道按 token 计费后服务可能会有多贵,GitHub Copilot Subreddit 上有位用户发现,过去一次高级请求的 token 消耗大约价值 11 美元。原因是一次“请求”可能会在上下文窗口(context window)里使用 60,000 个 token,调用几个工具,并经历一堆内部“轮次(turns)”——也就是模型为了生成结果在后台做的那些步骤。
这里还存在一个更底层的问题:大语言模型很容易产生幻觉(hallucination)。当一次高级请求原地打转、吐出一堆半坏不坏的代码时,这当然很烦。但如果你是自己为这次失败买单,这种失误就没那么容易原谅了。
用户也已经被训练成用一种完全不同于 token 计费的方式来使用产品。我想,很多人根本没有真正意识到自己会烧掉多少“token”,也不知道某个具体任务需要多少 token。而这个数字还会根据你使用的模型不同而变化。
这_绝对不是 Uber 那套逻辑_。任何告诉你两者相同的人,都是在为糟糕行为找借口。Uber 可能涨过价,但它并不需要彻底改变平台的底层经济结构,用户也不需要因为 Uber 突然按每加仑汽油计费,就完全改变自己使用产品的方式。
AI 月费订阅全都是 AI 补贴骗局的一部分:它们故意把生成式 AI 和真实成本切开
如果不按每个用户_实际烧掉的 token_ 来收费,基于 LLM 的服务从来就没有、也永远不会有经济上可行的提供方式。而这些公司在欺骗用户的过程中,创造出了一批收益虚幻、投资回报可疑的产品。
这一点其实_多年来都明摆着_。
从经济学上讲,月费订阅只适用于成本相对稳定的业务。健身房可以卖会员,因为它大致知道器材会有多少磨损,课程运行成本是多少,以及一定时间内电费、人工、水费等开销大概是多少。
Google Workspace 的客户——至少在 AI 进入之前——成本主要来自访问或存储文档的成本,以及 Google Docs 和其他服务的持续运行成本。数字存储成本相对低,而且不像 LLM,Google Workspace 对计算资源的需求并不特别高。所以即便某个 Google Drive 用户特别重度使用,也不太可能吃掉其月费订阅的利润率。
但 AI 订阅用户的成本可能_剧烈波动_。一个用户可能只是偶尔用 ChatGPT 搜索一下;另一个用户可能塞进大批文档,或者尝试重构整个代码库,或者让它帮自己做 PowerPoint 演示文稿。而服务提供方——无论是 OpenAI 或 Anthropic 这样的模型实验室,还是 Cursor 这样的创业公司——除了让产品变差之外,几乎没有真正办法控制用户会怎么用。比如设置使用上限、缩小上下文窗口、把用户推向更小也更差的模型,或者改变价格来吓退那些会发起大量消耗 GPU 请求的用户。
可是,这些服务有意隐藏 token 数量,也隐藏某项活动到底花了多少钱。结果就是,用户并不真正知道速率限制意味着什么。于是每一次突然调整速率限制,都会让客户手忙脚乱地试图弄清楚自己到底还能用这项服务完成多少实际工作。
这是一种虐待式、操纵式、欺骗式的做生意方式。它存在的唯一原因,就是 Anthropic、OpenAI 和其他 AI 公司要扩大用户基数。因为大多数 AI 用户感受到的真实或想象中的收益,都建立在这样一个前提上:他们每支付 1 美元订阅费,就能烧掉8 到 13.50 美元不等的 token。
这种有意的欺骗只有一个目标:确保大多数人永远不会接触到生成式 AI 的真实成本。当 《大西洋月刊》激情洋溢地把 Claude Code 描述成 Anthropic 的“ChatGPT 时刻”时,它讨论的是一个每月 20 美元的订阅,而不是 Anthropic 为提供这项服务在底层实际烧掉的 token 成本。也正因为如此,作者才会原谅模型犯下的“轻微错误”,或者原谅它在“更复杂的编程任务上卡住”。
如果那位作者支付的是自己真实烧掉的 token 成本,而且每次模型“卡住”都会带来 15 美元的 token 账单,我不认为她会对这些失败如此宽容。
但这正是骗局的一部分。
非常、非常重要的一点是:主流媒体中写 AI 的人绝不能真正理解这些服务的成本。任何关于 ChatGPT 或 Claude Code 这类服务的主流文章,都最好由那些几乎不知道单个任务会让用户花多少钱的人来写。
请记住:生成式 AI 服务在很大程度上是实验性产品。它们不像任何其他现代软件或硬件那样运行。你不能只是走到 ChatGPT 或 Claude 面前,就让它开始为你干活。
我的意思是,你_当然可以_这么做。但如果你的提示词写得不对,不理解它的工作方式,输入材料有错误,或者它自己就是弄错了,它就会吐出你不满意的结果。然后你又得重新提示它。LLM 本质上不可预测。
你无法保证某个 LLM 一定会执行某个动作,也无法保证它会给出基于现实的结果。你无法确定某个任务——哪怕是你过去用 LLM 做过很多次的任务——到底会花多少钱。你也无法确定模型什么时候会突然发疯并删除某些东西,或者根本没做某件事却声称自己做了。
如果你不是按 token 付费,这些问题会更容易被原谅。因为在订阅用户心里,这只是和聊天机器人多来一两轮,而不是正在产生真实成本。人们也不会太严厉地批评所谓的“锯齿状智能(jagged intelligence)”——(指 AI 在某些任务上表现惊人,在另一些看似简单的任务上却莫名失败,能力边界很不平滑)**——因为大家默认你现在遇到的问题未来总会被解决,而且反正你也没有为失败额外付钱。
如果用户一开始就必须按真实费率付费,我想很多人会立刻放弃这个产品。因为当你只是胡乱探索 LLM 能做什么时,非常非常容易就烧掉 5 美元的 token。
旁注:事实上,你可能花掉一大笔钱,却始终得不到想要的结果,因为 LLM 根本不是真正意义上的人工智能!一个并不了解其局限的人,很容易花掉 30 美元、50 美元,甚至 100 美元,去试图说服一个 LLM 做某件它_坚称_自己能做的事。
这里有个术语:谄媚(sycophancy)。LLM 常常被设计成会肯定用户,哪怕用户在
说一些危险而失控的话。这种倾向也可能延伸到这种场景:“你想要这个巨大到技术上或财务上都一点也不可行的东西?”没问题!
这就是为什么整个行业如此努力地掩盖这些成本——因为这他妈就是在宰人!
我认为,大多数 AI 订阅服务转向按 token 计费是不可避免的。尤其是 Anthropic 和 OpenAI 现在都已经对企业客户这么做了。
微软把 GitHub Copilot 订阅用户改成按 token 计费,同样是一个非常、非常糟糕的信号。微软可以说是资本最充足、利润最高、也最有条件继续补贴算力的公司。如果连它都负担不起继续补贴,那么其他公司也负担不起。
真正需要关注的信号——一匹真正的苍白之马——会是 Anthropic 或 OpenAI 这样的主要 AI 实验室,把_所有_订阅用户都转向按 token 计费。(“苍白之马”暗指《启示录》中象征死亡的马,这里指灾难性转折信号。)一旦那件事发生,你就会知道:打烊时间到了。
普通公司负担得起按 token 计费吗?Anthropic 估计 Claude Code 用户每天花 13 到 30 美元,每年 7,000 美元以上;大型组织每年会花几十万甚至几百万美元
正如我上周讨论过的,Uber 的 CTO 在一次会议上说,公司在几个月内就花完了 2026 年的全部 AI 预算。高盛也指出,有些公司在 AI token 上的支出,已经高达其人力成本的 10%,并且可能在接下来几个季度升至 *100%*。
这是训练每个 AI 用户尽可能多地使用这些服务、同时掩盖真实成本的直接结果。每一家要求所有员工“尽可能多用 AI”的大公司,要么从根本上忽视了自己的真实 token 消耗,要么与这件事完全脱节。而当公司被迫支付_实际成本_时,我不确定你还能如何从经济上证明对这项技术的_任何_投资是合理的。
当然,当然,你会说工程师“交付代码更快”之类的屁话,我懂。但问题是:*到底快了多少?因此你赚了多少钱,或者省了多少钱?* 如果你把相当于人力成本 10% 的钱花在 AI token 上,你是否在其他地方获得了抵消这笔额外支出的收益?我不确定你有。我也不确定_任何_一家把巨额资金投入 token 的企业,看到了_任何_投资回报。这也就是为什么每一项关于 AI 投资回报率的研究,都很难找到它存在的证据。
大体上,你读到的那些对生成式 AI 的各种可能性兴奋到失态的人,都没有支付过它的真实成本。每一个在 Twitter 上长篇大论,说自己整个工程团队都在猛敲 Claude Code 的疯子,用的都是每人每月 125 美元的 Teams 订阅,其使用限制和 Anthropic 每月 100 美元的消费者订阅相近。每一个在 LinkedIn 上像怪物一样宣称自己用某个 Perplexity 产品“几分钟完成了几个小时工作”的人,最多也只是为 Perplexity 的 Max 订阅每月支付 200 美元。
现实中,一个 10 人团队、每月 1,250 美元的 Teams 订阅,很可能每月在 API 调用上烧掉 5,000 到 10,000 美元,甚至更多。Anthropic 增长负责人 Amol Avasare 上周说,其 Max 订阅本来是为重度聊天使用而设计的,并不是为人们用 Claude Code 和 Cowork 做的那些事情设计的。他还明确表示,Anthropic 现在正在寻找“不同选项,以继续提供优秀体验”。换句话说,就是“我们迟早要改价格”。
我不确定人们是否意识到这些 token 有多贵,尤其是涉及大型代码库、并且经常调用编程工具和基础设施工具的编码项目。一个每月支付 200 美元的人,能预见性地承担 350、400 或 500 美元吗?他们能承受某个月花得_比这还多_吗?如果他们超预算了怎么办?如果他们真的付不起完成工作所必需的钱,又怎么办?
举个更实际的例子。直到 4 月初,Anthropic 自家的 Claude Code 开发者文档(存档)还写着:“Claude Code 用户的平均成本是每位开发者每天 6 美元,90% 用户的每日成本低于 12 美元。”截至本周,文档已经改成了这样:
Claude Code 按 API token 消耗量收费。订阅计划价格(Pro、Max、Team、Enterprise)请见 claude.com/pricing。每位开发者的成本差异很大,取决于模型选择、代码库大小,以及使用模式,比如运行多个实例或自动化流程。
在企业部署中,平均成本约为每位开发者每个活跃日 13 美元,每位开发者每月 150 到 250 美元;90% 用户每个活跃日成本低于 30 美元。若要估算自己团队的支出,请先从小规模试点小组开始,并使用下面的跟踪工具建立基线,再进行更广泛部署。
如果我们假设一个月平均有 21 个工作日,那么 Claude Code 用户的平均成本约为每月 273 美元,或每年 3,276 美元。如果按每个工作日 30 美元计算,就是每月 630 美元,或每年 7,560 美元。
这些数字_惊人_,更惊人的是:*如果你使用 Anthropic 最近的任何模型,你根本不可能只花每天 30 美元*。Claude Opus 4.7 的价格是每百万输入 token 5 美元、每百万输出 token 25 美元。“100 万 token 大约等于 50,000 行代码”。如果你使用所谓最先进的模型,你不可能不跑过_至少_100 万 token;如果你并不特别清楚某项任务该用哪个模型,这个数字还会大幅上升。
我们再拿每天 30 美元这个数字多算几下。
- 对一个 10 人开发团队来说,这就是每年 75,600 美元,而且我们只算工作日。
- 如果仅仅三个月的平均费用升到每个工作日 50 美元,总额就会变成 88,200 美元。
- 如果再有一个月每天超过 100 美元,你一年就要花 102,900 美元。
- 如果你每天花 300 美元,那么一个 10 人团队一年在 token 上就要花 756,000 美元。
在资金充裕的创业公司那种“小金库心态”里,或者像 Meta 这样的香蕉共和国里,这也许还能发生。但任何真正关心成本的企业,都会非常难以证明:为一个“提高生产力”的服务多花五位数或六位数成本是合理的,而这种生产力提升又似乎没人能衡量。
现在我认为大多数公司分成三类:
- 像 Spotify 或 Uber 这样的大型组织,企业部署规模巨大,CEO 已经被 AI 洗脑,允许预算失控。
我也会说,大型、资金充裕的创业公司也属于这一类。
- 使用有补贴的“Teams”订阅的小型创业公司。
- 每月付费使用 Claude 或其他 AI 订阅的个人用户。
大型组织现在仍然可以拿到一张免罪牌,说自己在 AI token 上为软件工程师烧掉几百万美元,并把理由包装成它们“最优秀的工程师”不再写一行代码这样可疑的好处。
但只要一次糟糕的财报电话会议,这个叙事就会改变。某个时候,投资者——哪怕是那些一直把 AI 泡沫吹起来的没脑子的蠢货——也会开始质疑不断上升的研发成本(AI token 消耗通常就藏在这里),尤其当公司的收入增长跟不上时。这可能会导致更多裁员,以赶上成本,就像 Meta 的情况一样。然后,当有人问出“这些玩意儿到底有没有让我们更快或更好地完成工作?”时,最终就会出现收缩。
我还认为,那些在 AI token 上烧掉相当于人力成本 10% 甚至更多的创业公司,六个月后会很难说服投资者:这么做是必要的。
一旦所有人都切换到按 token 计费,我不确定我们还能看到围绕生成式 AI 的这么多炒作。
AI 数据中心和算力的经济账也算不通
人们谈论 AI 数据中心的方式,已经完全脱离现实。我不认为他们意识到整个时代已经荒唐到什么程度。
AI 数据中心建起来很贵,运行起来也很贵,但实际收入很少
根据 TD Cowen 的 Jerome Darling 的说法,每兆瓦数据中心容量需要约 3,000 万美元的关键 IT 设备(GPU 及相关硬件),以及 1,400 万美元的数据中心容量成本。数据中心看起来需要一年到三年不等才能建成,具体取决于规模,而且前提是电力供应可用。
在据称到 2028 年底要建成的 114GW 数据中心中,只有 15.2GW 处于某种形式的建设状态。而“在建”可以只是“地上挖了个坑”。这绝不意味着、也不应该意味着该设施即将提供的容量马上就能上线。
侧栏:如果你对这里更深入的数学感兴趣,请订阅我的付费通讯,这样你就能看到我的 “混蛋数据中心模型”。这个模型是在多位分析师和超大规模云服务商消息源协助下建立的。
我们先从简单的开始:以后每当你想到“100MW”,就把它理解成“44 亿美元”,其中相当大一部分会花在 NVIDIA GPU 上。
结果就是,每个 AI 数据中心一开始就背着数百万美元的坑。即便采用 6 年折旧(depreciation)周期,也需要_很多年_才能回本。而且由于 NVIDIA 的年度升级周期,等你完成第一份客户合同后,那些 GPU 很可能已经赚不了多少钱了。
目前还不清楚,除了 OpenAI 和 Anthropic 之外,AI 算力是否真的存在足够大的客户群。OpenAI 和 Anthropic 的需求占在建 AI 数据中心的 50%。如果其中任何一家没有钱付款,就会形成巨大的系统性弱点。
无论如何,这些数据中心的持续收费标准也并不清楚。虽然 B200 GPU 的现货价格可能在每小时 4.50 美元左右,但长期合同通常价格低得多。根据 The Information 的报道,一位创始人说他们为期一年的承诺,价格约为每 GPU 每小时 3.70 美元。
必须说清楚的是,我们_必须_区分_现货_成本和合同算力。现货成本指的是你随机在别人服务器上启动 GPU 的价格;合同算力则构成了大多数数据中心资本开支(capex)。大多数数据中心都是为了拥有_一两个大客户_而建设的,这意味着这些客户很可能会谈到更低的综合价格。
结果是,很多数据中心每小时拿到的钱远低于 3.70 美元,因为它们按每兆瓦(或千瓦)收费。
而经济账就是从这里开始崩的。
一个 100MW 数据中心坏掉的经济账:每小时 2.55 美元、满租时毛利率 16%,但由于债务仍然不赚钱
这是一个 100 兆瓦数据中心的起始成本。一个 100MW 数据中心可能只有 85MW 的实际_可计费设备负载_。根据我与熟悉超大规模云服务商计费的人士的讨论,它们每兆瓦预计能带来约 1,250 万美元收入,也就是约 10.63 亿美元年收入。
我要说明一点:你知道的大多数数据中心公司其实并不亲自建设数据中心,而是把这项工作交给 Applied Digital 这样的公司,它们也被称为“主机托管合作方(colocation partners)”。例如,CoreWeave 向 Applied Digital 支付托管费,以使用其北达科他州的数据中心。CoreWeave 则负责数据中心内部所有 GPU 和其他技术设备。
为了说明这种经济错配,我会用一个_理论上的_例子:一个数据中心租给一家_理论上的_ AI 算力公司。
这个数据中心里的 GPU 很可能是 NVIDIA 的 Blackwell 芯片。更可能的是,该数据中心使用的是由 8 块 B200 GPU 组成的 pod,每个 pod 零售价约为 45 万美元,也就是每块 GPU 56,250 美元。假设有 85MW 关键 IT 负载,每兆瓦的全包资本开支约为 3,678 万美元,总 IT 资本开支约为 31.26 亿美元,其中约 26.7 亿美元花在 GPU 上。
我们假设这个数据中心位于北达科他州 Ellendale。那里的工业电价约为每千瓦时 6.31 美分,折合一年电费约 5,540 万美元。根据与消息源的讨论,我估计维护、人力、电源供应更换等持续成本约占收入的 12%,也就是每年约 1.28 亿美元。这样成本就到了 1.834 亿美元。
等等,抱歉。你还得基于关键 IT 负载支付主机托管费。根据 Brightlio 的说法,这项费用通常是每千瓦每月 180 到 200 美元,具体取决于部署规模和地点;不过我也见过低至 130 美元的价格,这里就用 130 美元计算,也就是每年约 1.33 亿美元。于是总成本上升到 3.164 亿美元。
好吧,这还是低于 10.6 亿美元,所以我们还不错,对吧?
错!你还有 31.26 亿美元的 IT 设备需要折旧。按照 6 年折旧算,每年约 5.21 亿美元。这样每年总成本就是 8.374 亿美元,剩下约 1.686 亿美元年利润,也就是约 16.7% 的毛利率(gross margin)……
……*前提是你始终 100% 满租!* 你看,数据中心可能需要一两个月才能把 GPU 装进去并让客户上线。在这段时间里,你一分钱收入都没有,却还要亏掉更多钱,因为你得继续支付托管、电费和运营成本,只是电费和托管/运营成本会以较低比例计算(我模型里按 10% 电费、15% 托管/运营成本估算)。这意味着你每天要亏约 327 万美元。
为了这个例子,我们假设你额外花了一个月才让它开始运行。这意味着你已经支付了约 1.02 亿美元,且永远拿不回来。把这笔钱算进第一年总成本和折旧后,总成本达到 9.394 亿美元,毛利率只剩 6.6%。
等等,见鬼,你该不会是借钱买这些 GPU 的吧?*你还真借了?* 这有多糟?哦_天哪_——你拿的是一笔 6 年期资产抵押贷款(asset-backed loan),贷款价值比(loan-to-value ratio,LTV)为 80%。也就是说,你以 6% 利率借了 28 亿美元。
你的银行以它永恒的慷慨给了你一个方案:12 个月宽限期,只付利息……这意味着利息约为 1.68 亿美元。这会把第一年总成本(为了公平起见,不算那一个月延迟)推到约 10.05 亿美元,而你的收入是 10.6 亿美元。
毛利率只有 5.19%,而你甚至还没开始还本金。一旦开始还本金,你每月要支付 5,410 万美元贷款,总计接下来五年每年约 6.49 亿美元。这会把成本推到约 14.8 亿美元,也就是毛利率约为负 40%。
而我必须强调:这一切的前提,是你有 100% 利用率和一个永远准时付款的租户。
Stargate Abilene 是一场灾难:每 GPU 每小时 2.94 美元、年收入 100 亿美元、进度落后数年,而且只有一个每年亏掉几十亿美元的租户
我们来谈谈本该是数据中心史上经济上最可行的项目:一个为世界上最大的 AI 公司建设的大型园区,由 Oracle 这样一家有几十年历史、接近超大规模云服务商的公司来建。Oracle 过去一直向企业和政府销售昂贵的数据库与企业管理软件。
哈哈,当然我是开玩笑的。这个地方就是一场该死的噩梦。
Stargate Abilene 是一个由 8 栋楼组成、总规模 1.2GW、关键 IT 负载约 824MW 的数据中心园区,最早在 2024 年 7 月宣布。截至 2026 年 4 月 27 日,只有两栋楼已经运营并产生收入,第三栋楼里几乎还没有多少 IT 设备。我估计 Stargate Abilene 的总成本约为 528 亿美元。
根据我自己的报道,Oracle 预计 Stargate Abilene 每年会带来约 100 亿美元收入。我还估计,它为单一客户 OpenAI 建设的 7.1GW 数据中心容量,总收入约为 750 亿美元。正如我也报道过的,Oracle 在 2024 年估计,Abilene 每年仅托管和电费就至少需要 21.4 亿美元,这笔钱要支付给土地开发商 Crusoe。
我还要补充一点:看起来 Oracle 正在支付 Abilene 的全部建设成本。
根据我的计算和报道,我估计 Abilene 完全运营后的粗略毛利率约为 37.47%:
我必须说明,这个 37.47% 的毛利率很可能偏高,因为我并不知道 Oracle 真实保险成本或人力成本的精确数字,只能基于本刊看到的文件做估算。我还要说清楚:Oracle 正在把_自己的整个该死未来_押在 Stargate Abilene 这样的项目上。它前期承担数十亿美元成本,而这个业务即便 OpenAI 每一笔款项都按时支付,也需要多年才能盈利。
遗憾的是,我无法确认 Abilene 有多少是通过债务支付的。我只知道,Oracle 在 2025 年 9 月发行了约 180 亿美元的不同规模债券,期限从 7 年到 40 年不等,并且在最近一个季度财报中自由现金流为负 247 亿美元。
我还知道,它与开发商 Crusoe 签了一份 15 年租约。Oracle 的未来在很大程度上取决于 OpenAI 持续付款的能力,而 OpenAI 持续付款的能力又取决于 Oracle 完成 Stargate Abilene 的能力。
我还需要说清楚:那 38.5 亿美元的年利润,只有在 OpenAI 按时付款、以最快速度接收 Abilene 租用权,并且一切都按计划进行时才可能实现。
如果 OpenAI 未来 4 年无法通过收入、融资和债务筹到 8,520 亿美元,Stargate 数据中心项目会杀死 Oracle
遗憾的是,实际发生的是完全相反的事:
根据 DatacenterDynamics 的报道,第一批 200MW 电力原本计划“在 2025 年”通电。随着时间推移,入驻时间被说成是 2025 年上半年;又说“有潜力在 2025 年达到 1GW”;还说要在 2026 年中前完成全部 1.2GW 容量;再说会在 2026 年中通电;还说到 2026 年底会有 64,000 块 GPU。截至 2025 年 9 月 30 日,报道称“两栋楼已上线”。截至 2025 年 12 月 12 日,Oracle 联席 CEO Clay Magouyurk 说,Abilene“按计划推进”,且“超过 96,000 块 NVIDIA Grace Blackwell GB200 已交付”,换句话说,也就是两栋楼所需的 GPU。
四个月后的 2026 年 4 月 22 日,
Oracle 发推称:“……在 Abilene,200MW 已经投入运行,八栋楼园区的交付仍按计划进行。”目前不清楚这里的 200MW 指的是关键 IT 容量,还是 Abilene 园区的总可用电力。无论哪种情况,这都只够两栋楼用。这意味着 Oracle 绝对称不上“按计划”。
这是一个巨大问题。OpenAI 只能为实际存在的算力付款,而现在实际产生收入的关键 IT 容量只有 206MW。第三栋楼至少还要一个月,甚至一个季度,才能做到这一点。
但整个 Stargate 数据中心项目还存在一个更大、更具生死意义的问题:只有当 OpenAI 实现它那荒唐到像漫画一样的预测时,这一切才说得通。
我再重复一遍这些数字:正在推进中的 7.1GW Stargate 数据中心建成后,每年会带来约 750 亿美元收入,总成本超过 3,400 亿美元。Oracle 自由现金流为负 247 亿美元,其他业务线趋于停滞,使其负利润率到低利润率的云业务成为唯一增长引擎。
为了真正支付其算力合同——包括向 Amazon、Microsoft、CoreWeave、Google、Cerberas 这样的合作伙伴,以及向 Oracle 支付的合同——OpenAI 必须在四年内通过收入和/或融资筹到或赚到 8,520 亿美元。这要求其业务每年增长超过 250%,到 2030 年底基本实现 10 倍增长。而到那时,它还必须找到方法实现现金流转正(cashflow positive),这些数字才有意义。
说清楚,OpenAI 的预测显示,它未来四年将实现 6,730 亿美元收入,并为此烧掉 2,180 亿美元。这是一门极度不盈利的生意。就算它不是,它也必须比现在赚多得多的钱,才能持续支付 Oracle。
我计算 750 亿美元这个数字时,是假设 Vera Rubin GPU 每兆瓦算力带来约 1,400 万美元收入(这个数字我已与熟悉数据中心行业的消息源确认),并应用到我预计剩余 Stargate 数据中心中包含的 4.64GW 关键 IT 负载上。
OpenAI 的数字直接来自 The Information 报道的 OpenAI 预计烧钱速度和收入泄露数据。这些数据称,该公司到 2030 年底将实现 6,730 亿美元收入,并为此烧掉 8,520 亿美元:
我必须明确说:任何记者在重复这些数字时,如果不说明它们有多_离谱到犯蠢_,都应该有点羞愧。引用我周五的付费文章:
换句话说,OpenAI 预计两年后收入会超过 TSMC,三年后年收入几乎和 Meta 一样多,到 2030 年底,年收入会达到 Microsoft 过去 12 个月约 3,000 亿美元的水平。
如果 OpenAI 无法为这些算力付款,Oracle 就_死了_。因为它仅仅为了建设 Stargate 数据中心,就已经承担了约 1,150 亿美元债务,而且还需要另外 1,500 亿美元才能完成它们:
Oracle 是一家目前年收入约 640 亿美元的公司,最近一个季度自由现金流为负 247 亿美元。它在 2025 年 9 月发行了 180 亿美元债券,在 2026 年 2 月发行了 250 亿美元债券,又在 3 月某个时候完成了一次 200 亿美元的市价发行股票计划。尽管这笔融资几个月来一直被称为“已关闭”,它似乎直到最近才完成了用于 Stargate Wisconsin 和 Shackelford 的380 亿美元项目融资。我还把与 Stargate Michigan 有关的140 亿美元数据中心债务算了进去。
不管怎样,Oracle 的资本不足以完成 Stargate Abilene。它至少还需要另外 1,500 亿美元才能把这件事做完,而且这还是假设其他合作伙伴承担约 300 亿美元成本。老实说,可能还不止这个数。
我真的需要说清楚:*如果没有 OpenAI,Oracle 没有其他路径能赚到这些收入*。这些项目完全是用数据中心自身预计现金流来融资和支付的。
而且并不是只有我担心这件事。OpenAI 的 Sarah Friar 在公司未能达到用户和收入目标后,也表达了类似担忧。根据 《华尔街日报》的报道:
OpenAI 最近没有达到自己设定的新用户和收入目标,这些挫折让公司一些领导层开始担心,它是否有能力支撑在数据中心上的巨额支出。
据熟悉情况的人士称,首席财务官 Sarah Friar 已经告诉其他公司领导,她担心如果收入增长不够快,公司可能无法支付未来的计算合同。
近几个月,董事会成员也更加仔细地审查公司的数据中心交易,并质疑首席执行官 Sam Altman 在业务放缓的情况下仍努力获取更多算力的做法。
如果这还不能让你担心,也许下面这段可以:
她向高管和董事强调,公司需要改善内部控制,并警告称,OpenAI 还没有准备好达到上市公司所要求的严格报告标准。一些人士称,Altman 倾向于更激进的 IPO 时间表。
这听起来确实像一家能在本十年结束前赚到 8,520 亿美元的公司,对吧!
Anthropic 和 OpenAI 一样糟糕:承诺从 Google 和 Amazon 获得最高 10GW 算力,每年收入规模超过 1,000 亿美元
虽然我经常抨击 OpenAI 的荒唐承诺,但 Anthropic 也没落后太多。它承诺从 Google 和 Amazon 各获取“最高”5GW 容量。以这个容量规模估算,我认为这些交易包含约 1,000 亿美元的实际算力承诺。
当然,我要补充一点:Google 和 Amazon 比 Oracle 精明得多,也没那么绝望。这意味着如果 Anthropic 最终没钱了,它们也能承受冲击。这些交易里的“最高”二字,给了它们一些急需的回旋空间,而 Oracle 根本没有这种空间。
尽管如此,为了真正履行承诺,Anthropic 到 2030 年底每年必须同意花费 250 亿到 1,000 亿美元购买算力。
Anthropic 的 CFO 在 3 月说,该公司从成立至今总收入为 50 亿美元。
为支撑正在建设的 15.2GW AI 数据中心,每年需要 1,568 亿美元 AI 算力收入;如果支撑全部已宣布的 114GW,则需要 1.18 万亿美元
Jensen Huang 经常说 NVIDIA 正在出货多少几千亿美元的 GPU。围绕这些数字的近乎色情式兴奋,常常遮住了一个棘手问题:这些算力到底卖给_谁_,Jensen?
如果我们假设正在建设、预计到 2028 年底交付的 15.2GW 数据中心容量,其电源使用效率(PUE)约为 1.35,那么关键 IT 负载大约是 11.2GW。按每兆瓦 1,400 万美元计算,这意味着这些数据中心必须实现约 1,568 亿美元的年度 GPU 租赁收入,才真正值得建设。
如果你把理论上到 2028 年底上线的 114GW 容量也算进去,这个数字会飙升到每年 1.18 万亿美元收入。
给你一点背景:CoreWeave 是最大的“新云厂商(neocloud)”,客户包括 Meta、OpenAI、Google(服务 OpenAI)、Microsoft(服务 OpenAI)、Anthropic 和 NVIDIA。它营收约为 51 亿美元,并预计 2026 年收入为 120 亿到 130 亿美元。
那么,这么多算力的客户到底是谁?等这些容量建成时,他们还想买吗?很多不同的数据中心声称自己在最初几年已有租户,但这些租户只有在数据中心建成后才开始付款。*如果租户是一家 AI 创业公司,我认为有理由问一句:等数据中心建成时,它还存在吗?*
请记住:AI 算力的客户,大多要么是试图把资本开支从资产负债表上转移出去的超大规模云服务商,要么是不盈利的 AI 创业公司。Anthropic 和 OpenAI 都计划在未来几年烧掉数百亿美元,而且两者都没有通往盈利的路径。
这意味着,AI 算力收入的很大一部分——甚至可能是大多数——依赖于风险投资和债务的持续流入。而这两者又都只会在投资者仍然相信生成式 AI 会成为世界上最大、最巨大、最无敌的东西时才成立。
这到底怎么可能成立?谁来为这些数据中心容量付钱?它是为谁建的?真实需求在哪里?
如果需求真的存在,*这些客户到底拿什么付钱?*
生成式 AI 不盈利、不可持续,而且只会越来越贵
尽管有多篇报道称 OpenAI 和 Anthropic 会在 2028 年或 2029 年实现盈利,但没人能向我解释它们到底如何真正盈利。尤其考虑到两家公司的利润率都低于预期,而这些利润率甚至已经剔除了数十亿美元级别的训练成本。
我已经问这个问题_很多年_了。每当我们得到 Anthropic 或 OpenAI 的新消息,听到的都是它们亏掉了比预期更多的几十亿美元,利润率在恶化,成本在飙升,一切都_越来越贵_。而它们曾承诺的恰恰相反。
即使是 Cursor 这家公司——它曾短暂声称自己毛利率为正,后来被 Musk 的 SpaceX 以近似收购的方式拿下——截至 1 月实际毛利率为负 23%。如果把非付费用户的成本也算进去,那就是负 31%。如果你真的在乎会计,你当然_应该_把这部分算进去。神奇的是,报道称 Cursor 的利润率“最近转正”,但又神奇地不知道转正了多少、不知道怎么发生的,也不知道任何其他细节,只知道这样一个可能帮助公司卖掉的结论。
我也看不出这些 AI 数据中心到底怎么说得通。哪怕它们前几年确实有客户付款。它们的经济模型建立在完美假设上,没有任何容错空间。它们_必须_始终保持稳定的 100% 利用率和租用率(tenancy),否则就会烧掉数百万美元,并无法有效削减由科技行业最昂贵错误制造出的多年折旧墙。
即便它们奇迹般成功,这些也是利润平庸的烂生意——最好情况下毛利率 70%,而且还要假设持续付款、持续租用,并且需要_整整六年折旧才真正回本_。这本身就可能很困难,因为年度升级周期会让整套东西在你付完钱时几乎已经过时。
而这还没算进去:大多数客户都是不盈利、不可持续的创业公司。
我真的不知道这一切最终怎么收场。
LLM 是宰客,客户一直被欺骗
我知道这听起来可能有点过头,但我真心相信,订阅制 AI 服务是一种近乎欺诈的欺骗行为。因为它歪曲了核心单位经济模型,也因此歪曲了大语言模型的可能性。Anthropic 和 OpenAI 这样的公司以月费出售产品,并围绕产品可得性塑造用户习惯,本质上是在以一种方式误导自己的业务:大多数用户正在使用、并围绕这些产品搭建工作流,而这些产品在当前形态下不可持续,也不可能维持。
Anthropic 近期激进的速率限制调整,发生在多轮激进营销活动之后仅仅几个月。而那些营销活动描绘的体验,在当前速率限制下几乎已经不可能实现。根据 Anthropic 最近的动作,很明显它打算在未来某个时间开始移除低层级 20 美元/月订阅用户的某些服务。这是一种令人作呕且具有误导性的经营方式。Anthropic 讨论产品和服务时的含糊其辞,是对每一位用户的侮辱,也表明它并不以任何有意义的方式害怕媒体。
我需要非常明确地说:由于最近的速率限制变化,Anthropic 现在提供的产品,已经和你在各处读到的那个产品有了实质差异,而且差得多。Anthropic 清楚地、有意识地营销一个它知道三个月内就会消失的产品。Dario Amodei 根本不在乎,只要媒体继续报道他今天编出来的几十亿美元年化收入,或者报道某个据说要摧毁某家倒霉上市 SaaS 公司的新产品就行——而那家公司本来增长就已经放缓。
媒体朋友们,我带着充分尊重说这句话:Anthropic 正在虐待自己的客户,而且它这么做,是因为它相信自己可以逃脱惩罚。这家公司不尊重你们。事实上,它对你们怀有相当明显的轻蔑。所以它不会很快修好自己的服务,也不会以任何有逻辑的方式解释服务为什么坏了。
这就是为什么 Anthropic *他妈的撒谎*,声称 Claude Mythos 因为太强大而不能发布(实际上是容量问题),而事实上它只是又一个该死的、毫无新意的大语言模型空包弹。它认为你会买下它卖的任何东西,而且它已经学会了如何包装,让你和你的编辑只要快速扫一眼系统卡,就会相信你们正在写的东西。
它们也知道你们会_急着报道它_,而不是等真正的专家说完话。
AI 是一场骗局,而这就是骗局运作的方式。AI 以人类所能做到的最快速度,被匆忙推到我们面前,而且是以最低效却最容易接触的形式出现。即使这种形式永远无法产生任何类似可持续业务的东西,它也被强推出来。媒体被催促着立刻宣布:*这就是那件大事*。于是每个人都同意:*这现在就是那件大事了*,并尽可能多地使用它。关键是,以订阅制形式使用它,让人们在体验它时从不问:提供这个东西到底要花多少钱。
叙事是预先烤好的。因为很少有谈论 LLM 的人体验过它们的真实成本,所以他们非常容易含糊地说“这就像 Uber”。毕竟 Uber 是一家亏了很多钱但没死的公司。说这个比说“等等,你说 OpenAI 今年预计要亏 50 亿美元是什么意思?”容易多了。
可以这样想:作为记者、投资者、高管,或者一个普通的 LinkedIn 休息室蜥蜴人,你可能偶尔读到过输入 token 每百万 5 美元、输出 token 每百万 25 美元这样的价格。但你从未真正体验过这笔钱流失得有多快或多慢。要真正理解这个产品,这种体验很重要。Anthropic 和 OpenAI 有意掩盖这种体验,并创造出预计在 2026 年烧掉数百亿美元、到 2030 年烧掉数千亿美元的业务,而这一切都因为大多数人是基于订阅制体验来评价生成式 AI 的。
LLM 就像赌场。你一直在用庄家的钱赌博,同时鼓励别人拿自己的钱下注,赌某个模型是否能产出一个工作单位。
这是有意为之。它们从来不想让你思考成本,因为一旦你真的开始思考成本,*整个事情就会显得有点疯狂*。我真心相信,基于 LLM 的订阅服务将会彻底消失,至少对于任何生成代码的产品,只要做到一定规模,就会消失。而在这个过程中,Amodei 和 Altman 会结束他们的骗局,或者至少相信自己已经结束了。
问题在于,这些人现在已经签下了太多协议,不可能全身而退。
OpenAI 的 CFO 已经多次表示,她不认为 OpenAI 已经准备好 IPO,并且对其增长和继续履行义务的能力有重大担忧。重复前面引用过的一句话:
据熟悉情况的人士称,首席财务官 Sarah Friar 已经告诉其他公司领导,她担心如果收入增长不够快,公司可能无法支付未来的计算合同。
这是一个闪着红灯的该死警报。在一个理性的市场里,这会让 Oracle 股价一路暴跌。因为 *OpenAI 能否升到超过 2,800 亿美元年收入,对 Oracle 不耗尽现金至关重要*。在一个理性的媒体环境里,这会在每一个群聊和 Slack 频道里引发令人不安的冲击波:OpenAI 到底能不能撑下去?
这就是一家公司开始死亡前会发生的事情。OpenAI 的增长正在放缓,而这恰恰是它最需要加速的时候。它必须在 2030 年前把当前业务基本做大 10 倍,才能履行义务。OpenAI 的 CFO——字面意义上最清楚这件事的人——正在说:如果收入不增长,她担心 OpenAI 无法支付那些该死的算力合同。 这是一个巨大且闪烁的警告灯!这不是演习!
不过,真正让我担心的是《华尔街日报》的另一句话:Friar 认为 OpenAI“还没有准备好达到上市公司所要求的严格报告标准”。
*这他妈是什么意思?* 你再说一遍?这家公司据称已经筹集了 1,220 亿美元,据称估值 8,520 亿美元,并预计到 2030 年底烧掉 *8,520 亿美元*。它的账目还没理顺吗?OpenAI 到底达不到什么“严格报告标准”?
一般来说,我不会这么该死地_爱打听_。但问题是,这家公司过去一年吸走了大约 20% 的全部风险投资资金。与此同时,无论我走到哪里,都得听 Altman、Brockman,以及 OpenAI 的其他每个男人没完没了地高谈阔论他们的_想法_,他们要告诉_普通人该怎么做_,一边优雅地四处晃荡,一边发布垃圾软件、花别人的钱。
考虑到 Anthropic 和 OpenAI 吸走了多少空气,这两家公司无论作为产品还是作为企业,都应该是_无可挑剔_的。可现实是,它们都通过围绕自身经济模型和效果的不同程度欺骗来销售自己。它们掩盖真相,好让首席执行官们积累金钱、权力和注意力。这既是对好软件的侮辱,也是对好品味的侮辱——这些是人类发明过的最昂贵、最不可靠的应用。它们的错误被原谅,平庸被庆祝,基础设施则被奉为一尊沉默的资本之神。
生成式 AI 是一种侮辱。它不可靠,经济账算不通,产出结果无法证明其存在合理性,而推动这场骗局的人,是一群无聊、粗鲁、贪婪、与社会脱节、也与任何可能反对他们的人脱节的男人。它需要偷走每个人的艺术,破坏环境,提高我们的电费,带来经济毁灭的持续威胁,以及“现在一切都因为 AI 变得糟透了”的无尽噪音。所有这些,只是为了推动一种软件,而它只能被那些愿意无视基本金融常识或基本理智的人证明合理。
这一切都太贵了,也太他妈无聊了。它无聊到冒犯人。它主动让人烦躁。每一个有人告诉你自己如何大量使用 AI 的故事,听起来都像这个人处在一段虐待关系里,或者加入了邪教。那种话语里回荡着一种微妙的绝望:“*你真的需要加入我,因为这太好了;至于我看起来完全没有从这个产品中获得任何快乐,这只是说明它太高效了。*”AI 能做的事情没有任何轻松或快乐之处。大语言模型没有任何傻气或奇思妙想。每一次互动都让人感到空洞。
那些拼命寻找它正在变得有意识、或者“更强大”线索的人,其实只是在寻找对自己的确认——他们想成为最早发现某件事的人,因为赶在别人得出结论之前到达同一个结论,就是他们赖以为生的东西。
成为“第一批”——或者说站在“前沿”——是某些人在内心找不到东西时会渴望的东西。而这正是骗子最喜欢的燃料。因为 LLM *总是嗡嗡作响,带着一种好像马上要做出新东西的感觉,尽管它们在数学上被限制为重复其他动作*。
这是一个深深令人悲伤的时代。那些如此积极地合力支撑这个行业的人,只是推迟了它不可避免的坠落。让我恐惧的是,我们的市场和部分经济,正在被一个被广泛接受却完全未经证明的假设支撑着:LLM 会以某种方式变得更便宜,AI 创业公司会神奇地盈利,而提供 AI 算力会永远盈利,以至于到 2030 年有必要把当前供给增加十倍。
人们已经贬低自己来捍卫 AI 行业,因为这正是这个行业要求信徒做的事。要成为“AI 专家”,你就必须主动忽视历史上任何行业中最糟糕的经济账;必须不断为产品中明显而刺眼的问题找解释;必须积极说服别人也这么做。OpenAI 和 Anthropic 不提供清晰解释,说明自己将如何盈利。因为它们知道,支持者永远不会追问——因为要完全“相信 AI”,就必须主动戴上眼罩。
我理解这一点。如果你接受 OpenAI 和/或 Anthropic 最终会崩溃,那么所有这一切都会显得有点疯狂。我真诚地请求你认真考虑:这两家公司中的一家,或者两家,都可能会耗尽资金。
我真的很担心。而媒体和更广泛社会中普遍缺乏担忧,只让我更担心。
如果让我猜,人们大概会认为我只是危言耸听,并且认为“需求绝对会在那里”。
你最好希望自己是对的。
至少为了 Larry Ellison 是这样。Ellison 已经质押了自己持有的 3.46 亿股 Oracle 股票——价值约 615 亿美元——“用于担保某些个人债务,包括各种信用额度”。翻译过来,就是“用他的 Oracle 股票抵押出来的许多大而漂亮的贷款”。IFR 在 9 月估计(当时 Oracle 股价高得多),按 20% 的保守贷款价值比计算,这可以让他获得高达 214 亿美元债务,而且这还是假设银行没有特别慷慨。
如果 OpenAI 到 2030 年底无法通过收入和融资筹到 8,520 亿美元,它就无法支付 Stargate。那会杀死 Oracle 股票的价值,引发一连串追加保证金通知(margin calls)。随后 Ellison 将不得不卖出股票,进一步引发更多追加保证金。无论有没有什么救助,都救不了 Larry 的资产。
我的意思是:Ellison 的未来,押在 Sam Altman 能否在 4 年内筹资并创造 8,520 亿美元收入这件事上。
祝你好运,Larry!你真的会需要它。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み