共有インフラと分離テナント:Amazon Bedrock AgentCore のプール型マルチテナンシーモデル
AWS は Amazon Bedrock AgentCore の新機能を紹介し、医療 AI エージェントを例に、テナント間の完全な隔離、サービスティアの差別化、および粒度の高いコスト追跡を実現するアーキテクチャパターンを提示した。
キーポイント
階層型分離アーキテクチャの実装
Tier(サービスレベル)→ Tenant(顧客組織)→ User(個人)の 3 レベル構造を採用し、知識ベース、メモリ、モデルアクセス、コスト追跡の各レイヤーで完全なテナント隔離を強制する。
ネイティブ AWS 機能による実装
カスタムコードを最小限に抑えつつ、AWS が管理するサービス(Amazon Bedrock AgentCore)の機能を駆使して、SaaS やエンタープライズ向けマルチテナント AI アプリケーションを構築可能にする。
医療分野における実証事例
複数のクリニックや病院にサービスを提供する医療 AI エージェントを具体例として挙げ、異なる顧客組織間でのデータ漏洩リスク防止と品質保証の仕組みを実演している。
JWT ベースの統合認証モデル
AgentCore Identity は、Cognito ID トークンを用いてランタイムとゲートウェイの両境界でユーザーを検証し、ツール Lambda には別個のスコープ付き資格情報を発行することで多テナント環境を保護します。
カスタムクレームによるテナント分離
ID トークンの `custom:clinic_id` や `custom:tier` などのクレームにテナントメタデータを含めることで、知識ベース、メモリ、および DynamoDB におけるデータの厳格な分離とモデルルーティングを実現しています。
SSM パラメータとモデル構成の連携
プロジェクト ID は SSM から取得され、OpenAIModel クラスに渡されることで、プレミアムティアの推論エンドポイントへ正しく接続されるよう設定されています。
IAM レベルでのデータ分離
ターゲット Lambda は JWT を直接処理せず、ゲートウェイ経由の信頼されたテナントヘッダーに基づいて TVM ロールを仮定し、ABAC ポリシーで DynamoDB へのアクセスをテナントごとに制限します。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI の普及に伴い急増するマルチテナント環境におけるセキュリティとコスト管理の課題に対し、AWS が提供する具体的な解決策を示した点で業界に大きな影響を与える。特に、医療や金融など厳格なコンプライアンスが求められる分野において、クラウドネイティブな手法でデータ隔離を実現できる道筋を提示しており、SaaS 開発者の実装指針として即座に活用される可能性が高い。
編集コメント
マルチテナント AI アプリケーションの開発において、セキュリティとコスト管理をどう設計するかが最大の課題となっていますが、AWS のこのアプローチは実務的な解決策として非常に参考になります。特に医療分野の事例を通じて、理論だけでなく実際の運用で求められる要件(隔離・階層化・追跡)がどう満たされるかを示している点は評価できます。
マルチテナント型 AI アプリケーションの構築には、新たなアーキテクチャ上の課題が生じます。顧客間での完全なテナント分離、異なる機能を持つ異なるサービスティア、細粒度のコスト追跡、そしてテナントごとの観測性が必要です。これらが欠如すると、顧客データの漏洩リスクや、顧客への適切なサービス品質の提供不能、予期せぬコストの増大といった問題に直面する可能性があります。
本記事では、Amazon Bedrock AgentCore を用いて本番環境対応型のマルチテナントシステムを実装するためのパターンを解説します。これらは、複数の診療所や病院を対象とするヘルスケア AI エージェントを通じて具体例として示されます。記事ではヘルスケア分野を事例として取り上げていますが、ここで紹介するアーキテクチャパターンと実装技術は、多様なマルチテナント型 AI アプリケーションにも広く適用可能です。SaaS プラットフォームの構築や、複数の事業部門を対象とするエンタープライズソリューション、あるいは異なる顧客組織向けのマネージドサービスを開発する場合でも、これらのアーキテクチャパターンを活用してソリューションを構築することができます。
学ぶ内容
- AWS のネイティブ機能を活用して、エージェント型アプリケーションにおいて完全なテナント分離を実現する方法。
- カスタムコードを最小限に抑えつつ、サービスティアの差別化を行うためのパターン。
- テナントごとの細粒度なコスト配分を行うための技術手法。
- スケーラブルなマルチテナント型 AI アーキテクチャにおけるベストプラクティス。
本ブログ記事は、「Amazon Bedrock AgentCore を用いたマルチテナントエージェントの構築」というシリーズの第 2 部です。第 1 部 では、Amazon Bedrock AgentCore を活用して SaaS アーキテクチャの課題に対処するためのフレームワークとともに、マルチテナント型エージェントアプリケーションを設計する際の考慮事項について解説しています。
サンプルコードの GitHub リポジトリ: https://github.com/aws-samples/sample-agentcore-and-multitenancy-blog
ソリューション概要
本ソリューションは、AWS が管理するサービスを活用して完全なテナント分離を実現するための Amazon Bedrock AgentCore のネイティブ機能の使用方法を示しています。このアーキテクチャでは、「ティア → テナント → ユーザー」という 3 レベルの階層構造を実装しており、知識ベース内のドキュメント、メモリ、モデルへのアクセス権限、コスト追跡の各レイヤーで分離を強制します。ティアリング戦略は、テナントをニーズ(ベーシックとプレミアムなど)、利用パターン、または価格プランに基づいて異なるサービスティアにグループ化する SaaS アプリケーションにおける一般的なパターンです。各ティアでは、そのグループ内のテナントが利用できる機能セットとサービス品質のレベルが定義されます。このアプローチにより、SaaS プロバイダーは運用効率を維持しながら、多様な顧客基盤に対して差別化された体験を提供することが可能になります。
医療 AI アシスタンスの例
実際の動作を確認するために、本サンプルソリューションではティアベースの差別化を実現するための 2 つのサービスティアを実装しています。
- ベーシックティア:主に単純な文書検索と取得を必要とする小規模クリニックや診療所向けに設計されています。これらのタスクは小さくコスト効率の高いモデルに適しているため、このティアでは Mistral Ministral 3 8B Instruct を使用し、簡単なクエリに対して正確な結果を提供しつつ、コストを抑えます。
- プレミアムティア:複雑な臨床分析を必要とする病院や専門センター向けに設計されています。このティアでは、OpenAI GPT OSS 120B を使用し、高度な推論機能により正確なツール選択を実現します。これには、ウェブ検索ツールも含まれており、これはプレミアムティアの顧客のみが利用可能です。
各ティアにおいて、本ソリューションは プール隔離モデル を採用しており、テナントごとに専用で分断されたリソースを持つのではなく、基盤となるインフラストラクチャと計算リソースを共有します。プールモデルはリソース利用率の最大化と運用の簡素化を実現し、テナント間の隔離は、スコープ付き識別子、アクセスポリシー、データパーティショニングなどの論理的分離メカニズムを通じて強制されます。ティアリング戦略とプールモデルを組み合わせることで、コスト効率性と異なるサービスレベルを提供する柔軟性のバランスを取ることができます。
アーキテクチャ
AgentCore のプリミティブがどのように組み合わさって、これらのマルチテナント課題を解決するかを見ていきましょう。以下の図は、ソリューションのマルチテナントアーキテクチャを示しており、認証されたユーザーから階層別エージェントを経て隔離されたドキュメントストレージへリクエストが流れる様子を描いています:
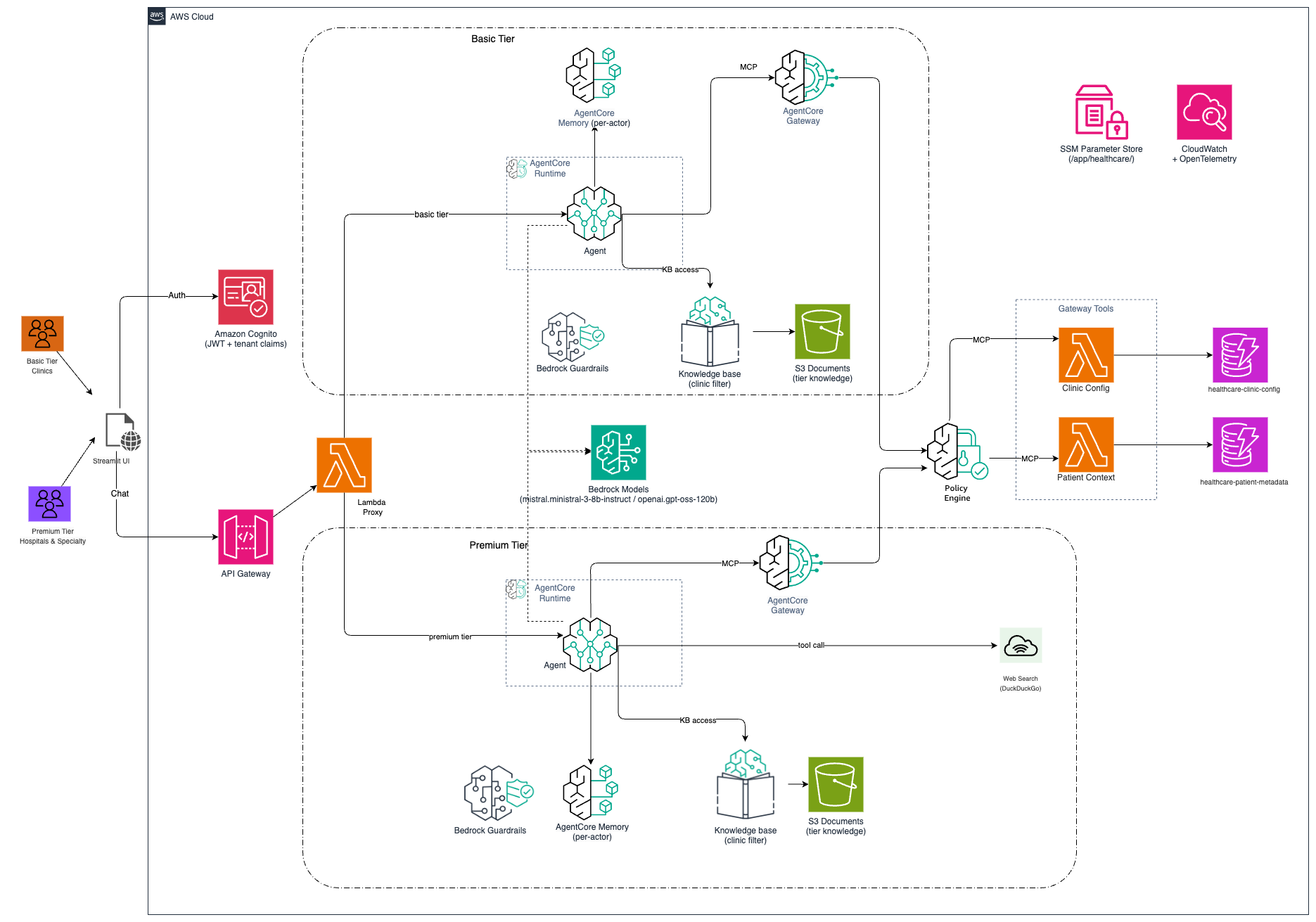
*図 1: 階層的分離(ティア→テナント→ユーザー)を備えたマルチテナントアーキテクチャ。
このソリューションは、以下の主要なコンポーネントで構成されています:
- Amazon Cognito: ユーザー認証を管理し、テナントメタデータ(ティア、clinic_id、role)を JSON Web Token (JWT) クレームに格納します。これらのクレームは抽出され、リクエストペイロードを通じてテナントコンテキストとして伝播され、各下流コンポーネントがその操作を正しいテナントにスコープできるようにします。
- Amazon API Gateway: リクエストのルーティングを行い、使用量プラン(usage plans)を介してティアベースのレート制限を適用します。
- AWS Lambda: テナントコンテキストを抽出し、対応する Amazon Bedrock AgentCore エージェントを呼び出します。
- AgentCore コンポーネント: ランタイム(エージェント実行)、メモリ(会話状態)、アイデンティティ(エージェントアイデンティティ管理)、ゲートウェイ(ツールサーバー)、ポリシー(エージェントアクションの境界)。
- Amazon Simple Storage Service (Amazon S3): クリニカルドキュメントを、テナント分離のための階層的プレフィックス構造を持つティア別バケットに格納します。
- Amazon Bedrock Knowledge Bases: メタデータフィルタリングによるセマンティック検索を提供し、クエリを発信元のテナントのドキュメントにスコープします。
- Amazon Bedrock プロジェクト:コストアロケーションタグ(cost allocation tags)を介してティアごとのコスト追跡を可能にします。
ソリューションウォークスルー
このセクションでは、ソリューションの主要な側面について説明します。このソリューションのインフラストラクチャとアプリケーションを設定するためにデプロイスクリプトを実行します。このセクションに含まれるコード抜粋は、アーキテクチャの主要な側面がソリューションのコンポーネントによってどのように対処されているかを記述するためだけに使用されます。ここで示されるコマンドの実行やコードスニペットの実行は不要です。
Amazon Bedrock AgentCore コンポーネント
本アーキテクチャは、マルチテナンシーを実装するために 6 つの主要な Bedrock AgentCore の機能を活用しています。
AgentCore Runtime: AgentCore Runtime は、このソリューションにおけるエージェントの計算リソースを提供し、各セッション実行はテナントレベルでの計算隔離のために独立したマイクロ VM で実行されます。各ティアごとに別個のエージェントインスタンスをホストし、それぞれのティアに適切なモデルと機能で構成されています。
# エージェント設定
config = TIER_CONFIG.get(tier, TIER_CONFIG["basic"])
model_id = config["default_model"]
プロジェクト ID は SSM から取得されます
project_id = get_ssm_parameter(config["project_ssm"])
OpenAIModel に渡され、推論エンドポイントを対象とします(プレミアムティア)
self.model = OpenAIModel(
client_args={"base_url": mantle_base_url, "api_key": api_key, "project": project_id},
model_id=model_id,
)
AgentCore Identity: AgentCore Identity は、統一された JWT ベースの認証モデルによりマルチテナントアーキテクチャを保護します。Cognito ID トークンは、Runtime および Gateway の境界においてユーザーを検証し、ツール Lambdas は下流データアクセスのために独自のスコープ付き資格情報を発行します。
各 AgentCore Runtime には、エージェントコード実行前に Cognito ID トークンを検証するインバウンド JWT オーサライザーが設定されています。ID トークンにはテナントメタデータがカスタムクレームとして含まれています:
クレーム
例値
目的
sub
a4589458-8011-…
ユーザー固有の識別子(Cognito UUID)
iss
https://cognito-idp.us-east-1.amazonaws.com/us-east-1_AbCdEfG
トークン発行者、AgentCore Runtime によって検証される
aud
7rfbikfsm51j…
Web クライアント ID、Runtime の allowedAudience によって検証される
token_use
id
これはアクセストークンではなく ID トークンであることを示す
exp
1745446200
有効期限のタイムスタンプ(デフォルト:発行から 1 時間後)
cognito:username
ログインユーザー名、メモリ分離のための user_id として使用される
custom:tier
premium
正しいモデル、ナレッジベース、およびゲートウェイへルーティングする
custom:clinic_id
hospital-a
これはテナント ID です。KB(ナレッジベース)、メモリ、Amazon DynamoDB にわたるデータ分離を強制します
custom:role
physician
ロールベースのアクセス制御(将来の拡張性あり)
認可者はエージェントデプロイ時に設定されます:
AUTHORIZER_CONFIG='{"customJWTAuthorizer":{"discoveryUrl":"'$COGNITO_DISCOVERY_URL'","allowedAudience":["'$COGNITO_WEB_CLIENT_ID'"]}}'
agentcore configure --entrypoint main.py \
--name healthcare_basic \
--authorizer-config "$AUTHORIZER_CONFIG" \
--request-header-allowlist "Authorization"
AgentCore Gateway は、同じ Cognito 発見 URL とオーディエンスを使用して JWT 認証も設定されています。エージェントがゲートウェイを呼び出す際、ユーザーの元の JWT を Bearer トークンとして転送して検証し、テナントコンテキストヘッダー(X-Tier, X-Clinic-ID, X-S3-Prefix)も併せて渡します。ゲートウェイはトークンを検証した後、metadataConfiguration を経由してターゲット Lambda にテナントヘッダーを伝播させます。
ターゲット Lambda はユーザーの JWT を直接受け取ったり処理したりすることはありません。代わりに、信頼できるテナントヘッダー(認証されたリクエストのみがゲートウェイのカスタム JWT 認証者 CUSTOM_JWT authorizer を通過するため信頼できる)を読み取り、それらのヘッダーから派生したセッションタグを持つ TVM (Token Vending Machine) ロールを仮定します。TVM ロールの ABAC ポリシーは、dynamodb:LeadingKeys 条件を使用して DynamoDB アクセスを制限し、テナントが IAM レベルでアプリケーションレベルのフィルタリングだけでなく、自社のクリニックデータのみを照会できるようにしています。
AgentCore Memory: 会話履歴がテナント間やテナント内の複数のユーザー間で漏洩することはありません。このソリューションは、アプリケーションレベルのスコーピングと IAM ベースの属性ベースアクセス制御 (ABAC) の 2 つのレイヤーでメモリ分離を強制します。
アプリケーション層では、AgentCore Memory は階層的ネームスペース構造を使用し、テナントごとに会話データを整理するために複合的な actor_id を使用します:
actor_id = f"{tier}-{clinic_id}-{user_id}"
例: "basic-clinic-a-dr.smith@clinic-a.com"
ネームスペースは異なる種類のメモリを分離します:
clinic/{actor_id}/facts/{session_id} # SEMANTIC --- clinical facts
clinic/{actor_id}/preferences # PREFERENCES -- user preferences
インフラレベルでの分離を強制するため、本ソリューションは ABAC(属性ベースのアクセス制御)を活用した Token Vending Machine (TVM) パターンを採用しています。ランタイムでは、エージェントが TVM ロールを引き受け、Tier、ClinicId、UserId をセッションタグとして付与することで、テナントのネームスペースにスコープされた一時的な認証情報を取得します:
sts = boto3.client("sts", region_name=region)
response = sts.assume_role(
RoleArn=tvm_role_arn,
RoleSessionName=f"mem-{tier}-{clinic_id}-{user_id}",
DurationSeconds=900,
Tags=[
{"Key": "Tier", "Value": tier},
{"Key": "ClinicId", "Value": clinic_id},
{"Key": "UserId", "Value": user_id},
],
TransitiveTagKeys=["Tier", "ClinicId", "UserId"],
)
一時的な認証情報からスコープ付き boto3 セッションを作成
scoped_session = boto3.Session(
aws_access_key_id=response["Credentials"]["AccessKeyId"],
aws_secret_access_key=response["Credentials"]["SecretAccessKey"],
aws_session_token=response["Credentials"]["SessionToken"],
)
スコープ付き認証情報をバックエンドとする MemoryClient を構築
memory_client = MemoryClient(region_name=region)
memory_client.gmcp_client = scoped_session.client("bedrock-agentcore-control")
memory_client.gmdp_client = scoped_session.client("bedrock-agentcore")
TVM ロールの信頼ポリシーにより、エージェント実行ロールのみがこれを引き受けることが可能であり、かつすべての 3 つのセッションタグが存在することが保証されます:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
AWS: !GetAtt RuntimeAgentCoreRole.Arn
Action:
- sts:AssumeRole
- sts:TagSession
Condition:
StringLike:
aws:RequestTag/Tier: "?*"
aws:RequestTag/ClinicId: "?*"
aws:RequestTag/UserId: "?*"
AgentCore Gateway: AgentCore Gateway は、Model Context Protocol (MCP) を用いて静的な Lambda 関数を、文脈を認識する動的なエージェントツールへ変換します。Model Context Protocol(MCP)は、AI エージェントを外部ツールに接続するためのオープンソース標準規格です。
AgentCore Gateway では、カスタムツールのオーケストレーションロジックを構築する必要がなくなります。これがない場合、エージェントワークフローに API を手動で統合する必要があり、API 仕様の解析、認証処理、変換管理、エラーハンドリングの実装、テナントコンテキストの伝播を行うためのカスタムコード記述が必要となります。
Lambda 関数は、Gateway を通じて2つのツールを公開します。
- patient_context: PatientMetadata DynamoDB テーブルから患者の人口統計情報および医療履歴を取得します。
- clinic_config: ClinicConfig DynamoDB テーブルからクリニックの設定情報およびプロバイダー情報を取得します。
前述した通り、テナントID は各コンポーネント全体に伝播されます。エージェントは MCP Gateway クライアントをテナントスコープのヘッダー (X-Tier, X-Clinic-ID, X-S3-Prefix) を用いて初期化するため、ゲートウェイ経由で行われるすべてのツール呼び出しが自動的にテナントコンテキストを付与され、各ツールのフィルタリングロジックを個別に実装することなく、ゲートウェイ層でデータ分離が強制されます。gateway headers に関する詳細情報は以下のリンクをご参照ください。
Lambda を MCP ターゲットとして定義
lambda_target_config = {
"mcp": {
"lambda": {
"lambdaArn": lambda_function_arn,
"toolSchema": {"inlinePayload": api_specification}
}
}
}
AWS IAM 認証を備えたゲートウェイを作成
エージェントの Runtime 実行ロールは SigV4 を介して認証されます
gateway = gateway_client.create_gateway(
name="healthcare-basic-gw",
roleArn=execution_role_arn,
protocolType="MCP",
authorizerType="AWS_IAM",
description="Healthcare Clinical Document Processing Gateway",
)
テナントヘッダー伝播を備えた Lambda ターゲットを追加
metadata_config = {
"allowedRequestHeaders": [
"X-Tier",
"X-Clinic-ID",
"X-S3-Prefix"
]
}
credential_config = [{"credentialProviderType": "GATEWAY_IAM_ROLE"}]
create_target_response = gateway_client.create_gateway_target(
gatewayIdentifier=gateway_id,
name=f"HealthcareLambda-{tier.title()}",
targetConfiguration=lambda_target_config,
credentialProviderConfigurations=credential_config,
metadataConfiguration=metadata_config,
)
The gateway supports three authentication mechanisms:
- IAM ロール:AWS サービス統合用。
- カスタム JWT:テナント認識型ツール用(今回使用しているもの)。
- OAuth:サードパーティ製 API 統合用。
AgentCore ポリシー: AgentCore ポリシーは、Cedar の認可ポリシーを用いて、ゲートウェイツールに対してティア固有のアクション境界を強制します。このソリューションでは、基本およびプレミアム両方のゲートウェイに ENFORCE モードで共有されたポリシーエンジンが接続されます。基本ティアの場合、Cedar ポリシーはツールの入力から request_hour フィールドを評価し、患者コンテキスト(patient_context)ツールの利用を営業時間(午前 8 時~午後 6 時)に制限します。エージェントはまず current_time を呼び出して現在の時刻を取得し、その時間を渡す必要があります。ポリシーエンジンが許可された時間帯外であると判断した場合、その呼び出しを拒否します。一方、プレミアムティアでは、患者コンテキストツールの利用が無条件で許可され、病院は 24 時間 365 日アクセス可能になります。両方のティアとも、機密性の低い設定データを公開する clinic_config ツールについては明示的な許可が付与されます。このアプローチにより、アクセス制御をアプリケーションコードから分離し、ゲートウェイ層で評価される宣言型の Cedar ポリシーに移行することで、Lambda 関数が実行される前にティアごとの差別化が強制されます。
セダーポリシー:ベーシックティア --- patient_context を業務時間内に制限
permit(
principal is AgentCore::OAuthUser,
action == AgentCore::Action::"HealthcareLambda-Basic___patient_context",
resource == AgentCore::Gateway::"{gateway_arn}"
)
when {
context.input has request_hour &&
context.input.request_hour >= 8 &&
context.input.request_hour < 17
}
AgentCore 観測性: AgentCore の観測性統合は、OpenTelemetry baggage を使用して、テナントメタデータをリクエストライフサイクル全体に伝播させます。OpenTelemetry baggage はキー・バリューストアであり、トレースコンテキストと共に追加データを伝播させることができます。本ソリューションでは、AgentCore Runtime エントリーポイントでテナント識別子を baggage として設定するため、すべての下流スパンおよびログエントリがテナントの帰属情報を保持します:
原文を表示
Building multi-tenant AI applications presents new architectural challenges. You need complete tenant isolation between customers, different service tiers with different capabilities, granular cost tracking, and observability per tenant. Without these, you could risk exposing customer data, not providing appropriate quality of service to your customers or running up unforeseen costs.
In this post, you will learn patterns for implementing production-ready multi-tenant systems using Amazon Bedrock AgentCore. You will see these patterns demonstrated through healthcare AI agents that serve multiple clinics and hospitals. While the post uses healthcare as the example domain, the architectural patterns and implementation techniques apply broadly to various multi-tenant AI applications. Whether you’re building SaaS platforms, enterprise solutions serving multiple business units, or managed services for different customer organizations, you can use these architectural patterns to build your solution.
What you’ll learn
- How to implement complete tenant isolation in agentic applications using native AWS capabilities.
- Patterns for service tier differentiation with minimal custom code.
- Techniques for granular cost attribution per tenant.
- Best practices for scalable multi-tenant AI architectures.
This blog post is part 2 of the series, Building multi-tenant agents with Amazon Bedrock AgentCore. Part 1 explores design considerations for architecting multi-tenant agentic applications and the framework needed to address SaaS architecture challenges with Amazon Bedrock AgentCore.
GitHub repo for the sample code: https://github.com/aws-samples/sample-agentcore-and-multitenancy-blog
Solution overview
This solution demonstrates how to use native capabilities of Amazon Bedrock AgentCore to achieve complete tenant isolation using AWS-managed services. The architecture implements a three-level hierarchy: Tier → Tenant → User, where you enforce isolation at every layer through documents in knowledge base, memory, model access, and cost tracking. A tiering strategy is a common pattern in SaaS applications where tenants are grouped into distinct service tiers based on their needs – such as Basic and Premium, usage patterns, or pricing plans. Each tier defines a set of features and quality of service available to tenants within that group. This approach allows SaaS providers to serve a diverse customer base with differentiated experiences while maintaining operational efficiency.
Healthcare AI assistant example
To see how this works in practice, the example solution implements two service tiers for tier-based differentiation:
- Basic Tier: Designed for small clinics and practices that primarily need straightforward document search and retrieval. Because these tasks are well-suited to a smaller, cost-effective model, this tier uses Mistral Ministral 3 8B Instruct, keeping costs low while still delivering accurate results for simple queries.
- Premium Tier: Designed for hospitals and specialty centers that require complex clinical analysis. This tier uses OpenAI GPT OSS 120B with advanced reasoning capabilities for accurate tool selection, including the web search tool which is only available to premium tier customers.
Within each tier, this solution uses a pool isolation model, where tenants share the same underlying infrastructure and compute resources rather than having dedicated, siloed resources per tenant. The pool model maximizes resource utilization and simplifies operations, while tenant isolation is enforced through logical separation mechanisms such as scoped identifiers, access policies, and data partitioning. Combining a tiering strategy with a pool model enables you to balance cost efficiency with the flexibility to offer differentiated service levels.
Architecture
Let’s look at how primitives from AgentCore come together to solve these multi-tenancy challenges. The following diagram illustrates the multi-tenant architecture for the solution, showing how requests flow from authenticated users through tier-specific agents to isolated document storage:
*Figure 1: Multi-tenant architecture with hierarchical isolation (Tier → Tenant → User).*
The solution consists of these key components:
- Amazon Cognito: Manages user authentication and stores tenant metadata (tier, clinic_id, role) in JSON Web Token (JWT) claims. These claims are extracted and propagated as tenant context through the request payload, enabling each downstream component to scope its operations to the correct tenant.
- Amazon API Gateway: Routes requests and enforces tier-based rate limiting via usage plans
- AWS Lambda: Extracts tenant context and invokes the corresponding Amazon Bedrock AgentCore agent
- AgentCore components: Runtime (agent execution), Memory (conversation state), Identity (agent identity management), Gateway (tool server), and Policy (agent action boundary)
- Amazon Simple Storage Service (Amazon S3): Stores clinical documents in tier-separated buckets with hierarchical prefix structure for tenant isolation
- Amazon Bedrock Knowledge Bases: Provides semantic search with metadata filtering to scope queries to the requesting tenant’s documents
- Amazon Bedrock project: Enables per-tier cost tracking via cost allocation tags
Solution walkthrough
This section describes the key aspects of the solution. You run the deploy script to set up the infrastructure and application for the solution. The code excerpts in this section are only used to describe how the key aspects of the architecture are being addressed by components of the solution. There is no need to run any commands or execute any code snippets shown here.
Amazon Bedrock AgentCore components
The architecture leverages six core Bedrock AgentCore capabilities to implement multi-tenancy:
AgentCore Runtime: AgentCore Runtime provides the compute for the agents in this solution, with each agent session execution in an isolated micro-VM for tenant-level compute isolation. It hosts separate agent instances per tier, each configured with tier-appropriate models and capabilities.
# Agent configuration
config = TIER_CONFIG.get(tier, TIER_CONFIG["basic"])
model_id = config["default_model"]
# Project ID is fetched from SSM
project_id = get_ssm_parameter(config["project_ssm"])
# Passed to OpenAIModel (premium tier) targeting the inference endpoint
self.model = OpenAIModel(
client_args={"base_url": mantle_base_url, "api_key": api_key, "project": project_id},
model_id=model_id,
)AgentCore Identity: AgentCore Identity secures the multi-tenant architecture with a unified JWT-based authentication model. The Cognito ID token validates the user at both the Runtime and Gateway boundaries, while tool Lambdas mint their own scoped credentials for downstream data access.
Each AgentCore Runtime is configured with an inbound JWT authorizer that validates Cognito ID tokens before agent code execution. The ID token carries tenant metadata as custom claims:
Claim
Example Value
Purpose
sub
a4589458-8011-…
Unique user identifier (Cognito UUID)
iss
https://cognito-idp.us-east-1.amazonaws.com/us-east-1_AbCdEfG
Token issuer, validated by AgentCore Runtime
aud
7rfbikfsm51j…
Web client ID, validated by Runtime’s allowedAudience
token_use
id
Identifies this as an ID token (not access token)
exp
1745446200
Expiration timestamp (default: 1 hour from issue)
cognito:username
Login username, used as user_id for memory isolation
custom:tier
premium
Routes to correct model, knowledge base, and gateway
custom:clinic_id
hospital-a
This is tenant ID. Enforces data isolation across KB, memory, and Amazon DynamoDB
custom:role
physician
Role-based access control (future extensibility)
The authorizer is configured during agent deployment:
AUTHORIZER_CONFIG='{"customJWTAuthorizer":{"discoveryUrl":"'$COGNITO_DISCOVERY_URL'","allowedAudience":["'$COGNITO_WEB_CLIENT_ID'"]}}'
agentcore configure --entrypoint main.py \
--name healthcare_basic \
--authorizer-config "$AUTHORIZER_CONFIG" \
--request-header-allowlist "Authorization"The AgentCore Gateway is also configured with JWT authorization, using the same Cognito discovery URL and audience. When the agent calls the gateway, it forwards the user’s original JWT as a Bearer token for validation, along with tenant context headers (X-Tier, X-Clinic-ID, X-S3-Prefix). The gateway validates the token, then propagates the tenant headers to the target Lambda via metadataConfiguration.
The target Lambda never receives or processes the user’s JWT directly. Instead, it reads the trusted tenant headers (trusted because only authenticated requests pass the gateway’s CUSTOM_JWT authorizer) and assumes a TVM (Token Vending Machine) role with session tags derived from those headers. The TVM role’s ABAC policy restricts DynamoDB access using dynamodb:LeadingKeys conditions, ensuring each tenant can only query their own clinic’s data at the IAM level, not just application-level filtering.
AgentCore Memory: Conversation history cannot leak between tenants or between multiple users within a tenant. The solution enforces memory isolation at two layers: application-level scoping and IAM-backed Attribute-Based Access Control (ABAC).
At the application layer, AgentCore Memory uses a hierarchical namespace structure with a composite actor_id to organize conversation data per tenant:
actor_id = f"{tier}-{clinic_id}-{user_id}"
# Example: "basic-clinic-a-dr.smith@clinic-a.com"Namespaces separate different types of memory:
clinic/{actor_id}/facts/{session_id} # SEMANTIC --- clinical facts
clinic/{actor_id}/preferences # PREFERENCES -- user preferencesTo enforce isolation at the infrastructure level, the solution uses a Token Vending Machine (TVM) pattern with ABAC. At runtime, the agent assumes a TVM role with Tier, ClinicId, and UserId as session tags, receiving temporary credentials scoped to that tenant’s namespace:
sts = boto3.client("sts", region_name=region)
response = sts.assume_role(
RoleArn=tvm_role_arn,
RoleSessionName=f"mem-{tier}-{clinic_id}-{user_id}",
DurationSeconds=900,
Tags=[
{"Key": "Tier", "Value": tier},
{"Key": "ClinicId", "Value": clinic_id},
{"Key": "UserId", "Value": user_id},
],
TransitiveTagKeys=["Tier", "ClinicId", "UserId"],
)
# Create a scoped boto3 session from the temporary credentials
scoped_session = boto3.Session(
aws_access_key_id=response["Credentials"]["AccessKeyId"],
aws_secret_access_key=response["Credentials"]["SecretAccessKey"],
aws_session_token=response["Credentials"]["SessionToken"],
)
# Build a MemoryClient backed by scoped credentials
memory_client = MemoryClient(region_name=region)
memory_client.gmcp_client = scoped_session.client("bedrock-agentcore-control")
memory_client.gmdp_client = scoped_session.client("bedrock-agentcore")The TVM role’s trust policy ensures only the agent execution role can assume it, and that all three session tags are present:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
AWS: !GetAtt RuntimeAgentCoreRole.Arn
Action:
- sts:AssumeRole
- sts:TagSession
Condition:
StringLike:
aws:RequestTag/Tier: "?*"
aws:RequestTag/ClinicId: "?*"
aws:RequestTag/UserId: "?*"AgentCore Gateway: AgentCore Gateway transforms static Lambda functions into dynamic, context-aware agent tools using the Model Context Protocol (MCP). Model Context Protocol is an open-source standard for connecting AI agents to external tools.
AgentCore Gateway eliminates the need to build custom tool orchestration logic. Without this, you would need to manually integrate APIs into agent workflows. This involves writing custom code to parse API specifications, handle authentication, manage transformations, implement error handling, and propagate tenant context.
The Lambda function exposes two tools through the Gateway:
- patient_context: Retrieve patient demographics and medical history from the PatientMetadata DynamoDB table.
- clinic_config: Get clinic configuration and provider information from the ClinicConfig DynamoDB table.
As mentioned previously, tenant identity is propagated throughout each component. The agent initializes its MCP Gateway client with tenant-scoped headers (X-Tier, X-Clinic-ID, X-S3-Prefix), so every tool call through the gateway automatically carries tenant context, enforcing data isolation at the gateway layer without per-tool filtering logic. This link provides more information about gateway headers.
# Define Lambda as MCP target
lambda_target_config = {
"mcp": {
"lambda": {
"lambdaArn": lambda_function_arn,
"toolSchema": {"inlinePayload": api_specification}
}
}
}
# Create gateway with AWS IAM authorization
# The agent's Runtime execution role authenticates via SigV4
gateway = gateway_client.create_gateway(
name="healthcare-basic-gw",
roleArn=execution_role_arn,
protocolType="MCP",
authorizerType="AWS_IAM",
description="Healthcare Clinical Document Processing Gateway",
)
# Add Lambda target with tenant header propagation
metadata_config = {
"allowedRequestHeaders": [
"X-Tier",
"X-Clinic-ID",
"X-S3-Prefix"
]
}
credential_config = [{"credentialProviderType": "GATEWAY_IAM_ROLE"}]
create_target_response = gateway_client.create_gateway_target(
gatewayIdentifier=gateway_id,
name=f"HealthcareLambda-{tier.title()}",
targetConfiguration=lambda_target_config,
credentialProviderConfigurations=credential_config,
metadataConfiguration=metadata_config,
)The gateway supports three authentication mechanisms:
- IAM role: For AWS service integrations.
- Custom JWT: For tenant-aware tools (what we’re using).
- OAuth: For third-party API integrations.
AgentCore Policy: AgentCore Policy enforces tier-specific action boundaries on gateway tools using Cedar authorization policies. The solution creates a shared policy engine attached to both the basic and premium gateways in ENFORCE mode. For the basic tier, a Cedar policy restricts the patient_context tool to business hours (8 AM–6 PM) by evaluating the request_hour field from the tool’s input. The agent must call current_time first and pass the current hour, and the policy engine denies the call if the hour falls outside the allowed window. For the premium tier, the policy permits patient_context unconditionally, giving hospitals 24/7 access. Both tiers get explicit permits for the clinic_config tool since it exposes non-sensitive configuration data. This approach moves access control out of application code and into declarative Cedar policies evaluated at the gateway layer, so tier differentiation is enforced before the Lambda function ever executes.
# Cedar policy: basic tier --- restrict patient_context to business hours
permit(
principal is AgentCore::OAuthUser,
action == AgentCore::Action::"HealthcareLambda-Basic___patient_context",
resource == AgentCore::Gateway::"{gateway_arn}"
)
when {
context.input has request_hour &&
context.input.request_hour >= 8 &&
context.input.request_hour < 18
};
# Cedar policy: premium tier --- 24/7 patient_context access
permit(
principal is AgentCore::OAuthUser,
action == AgentCore::Action::"HealthcareLambda-Premium___patient_context",
resource == AgentCore::Gateway::"{gateway_arn}"
)
when {
context.input has patient_id
};AgentCore Observability: AgentCore’s observability integration uses OpenTelemetry baggage to propagate tenant metadata through the entire request lifecycle. OpenTelemetry baggage is a key-value store which lets you propagate additional data alongside trace context. The solution sets tenant identifiers as baggage at the AgentCore Runtime entrypoint, so every downstream span and log entry carries tenant attribution:
関連記事
Amazon Bedrock AgentCore に Web 検索機能を導入
AWS は、学習データに依存して最新情報を取得できない AI エージェントの課題を解決するため、Amazon Bedrock AgentCore に Web 検索機能を一般提供開始した。これによりエージェントはリアルタイムの株価やニュースなどを参照可能になった。
Amazon Bedrock AgentCore を活用した AI 搭載機器修理アシスタントの構築方法
AWS は、Amazon Bedrock AgentCore を使用して、農機具の故障診断を支援する AI アシスタントを構築する方法を紹介している。これにより、部品不足による再訪問や稼働停止時間の削減が期待される。
Amazon Bedrock AgentCore のデータセット管理機能を活用し、エージェントの成長に合わせて拡張可能なテストスイートを構築する方法
AWS は Amazon Bedrock AgentCore の新機能として、バージョン管理されたテストケースをデータセットとして管理する機能を公開した。これにより、オンライン信号とオフライン基準を組み合わせた評価が可能となり、エージェントの時間経過に伴う改善を正確に把握できる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み