出力最大化の教授——アンジニー・ミドハ氏(AMP)
Anjney Midha は、AI スケーリングのボトルネックが単なる GPU の購入ではなくシステム効率化にあると指摘し、xFU の低利用率が示すインフラの非効率性を批判している。
キーポイント
GPU アームレースの誤解とMFUの現実
業界は「より多くのGPUをどう手に入れるか」に集中しがちだが、xAI のような最前線ラボでも MFU(Model FLOPs Utilization)が 10% を下回っている現状から、既存リソースの最適化こそが真の問題であると指摘。
歴史的な効率性の推移とベストプラクティス
GPT-3 や PaLM などの過去のトレーニングでは MFU が 20〜46% であったのに対し、現在のベストインクラスは 60〜70% に達しており、10% は明らかに非効率であることを示す。
AI スケーリングの本質はシステムエンジニアリング
単なる CapEx(設備投資)の増加ではモデル性能は向上せず、スケジューリング、ネットワーク、カーネル、データパイプラインなど、理論上の FLOPs を実際のトレーニング進捗に変えるための数千の小さな意思決定が重要。
AMP のビジョンと計算資源市場の未来
Anjney Midha は AMP による独立した計算グリッドを構想し、FLOPs を電力のように流動化させることで、AI データセンターがコミュニティに受け入れられ、より効率的で責任あるインフラへ進化することを提唱。
AMP のビジョン:FLOPs を電力のように流動化
AMP は計算リソース(FLOPs)をメガワットのように流れるようにし、AI データセンターの効率とスケーラビリティを高めるグリッド構想を描いている。
DeepMind の研究隠蔽が市場失敗を生む
DeepMind などの先端研究所が未公開の研究を独占することで、業界全体に負の外部性が生じ、計算市場における非効率な状態(市場失敗)を招いていると指摘している。
AI データセンターの「出力最大化」新分野
先端システムにおいて「アウトプット・マキシミング(Outputmaxxing)」が新たな専門分野となり、組織規模拡大に伴う API や抽象化レイヤーの損失を克服する鍵となる。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界がハードウェア獲得競争からシステム最適化への転換点を迎えていることを示唆しており、インフラエンジニアリングやリソース管理の重要性が劇的に高まることを伝えています。特に MFU の数値比較を通じて、現在の多くのラボが潜在的な非効率を抱えている可能性を浮き彫りにし、投資家や開発者に対してハードウェア購入以外の領域での競争優位性獲得の必要性を強く訴求しています。
編集コメント
GPU の購入競争に明け暮れる業界に対し、システム全体の効率化という視点の転換を促す非常に示唆に富む分析です。MFU という具体的な数値指標を用いて非効率性を可視化した点は、インフラ担当者にとって即座に行動指針となる洞察と言えます。
通常チケットの完売まで残り 4 日です。これは世界最大の AI エンジニア、創業者、リーダー、研究者が集まるイベント「AI Engineer World's Fair」です。参加者には 5,000 ドル以上のスポンサークレジットが付与され、登壇内容も素晴らしいものとなっています。ぜひご参加ください!
AI のスケーリングに関する議論は常に「どうすればより多くの GPU を手に入れられるか」という点に焦点が当たりますが、より本質的な問いは「すでに持っている GPU をいかに最大限活用するか」ではないでしょうか。
xAI といった最先端研究所が、モデル FLOPs 利用率(MFU)で 10% を下回る状態で稼働しているという事実は、真の問題がどこにあるのかを示唆しています。
tweet
参考までに、過去の最先端規模のトレーニング実行では、すでに 10% をはるかに上回る数値でした。GPT-3 は MFU が約 21%、Gopher は約 32%、Megatron-Turing NLG は約 30%、PaLM は約 46% に達していました。そしてゲストの Anjney 氏によれば、現在のベストインクラスにおける MFU は 60〜70% に近いとのことです。
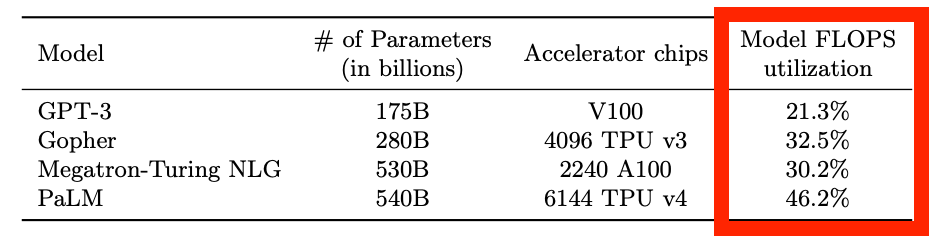
PaLM: スケーリング言語モデリングにおける Pathways の活用
必ずしも xAI が独自に無能であるというわけではなく(彼らには有能な人材がいることは明らかだ)むしろ、GPU 軍拡競争における優先順位が逆転している可能性があります。
GPU アクセスはボトルネックですが、単純に資本支出を増やしても、最先端 AI はもはやシステム全体の課題となっているため、自動的にモデルの向上につながるとは限りません。スケジューリング、利用率、ネットワーク、カーネル、フレームワーク、データパイプライン、並列処理、クラスタの信頼性、そして理論上の FLOPs を実際のトレーニング進捗に変えるかどうかを決定する千の小さな判断などです。
Discord の開発者プラットフォームの構築や、Anthropic、Mistral、Black Forest Labs、Periodic Labs といった最先端 AI 企業への支援から、現在では AMP の独立した計算グリッドの構築に至るまで、Anjney Midha は AI スケーリングにおける真のボトルネックに長年携わってきました。このエピソードでは、Anjney が swyx とともに Periodic Labs で、なぜ AI ラスが単に GPU をもっと買うことだけではないのか、なぜ 95% の利用率が Google では障害と見なされたのか、そしてなぜ AI インフラの次の時代はより整合性があり、より効率的で、より責任あるものでなければならないのかを解き明かします。
FLOPs がメガワットのように流れるような計算グリッドに関する AMP のビジョン、フルスタック AI ラボと水平プーリングの違い、AI データセンターがなぜコミュニティの支持を必要とするか、そして計算市場がどのように独立系統運営者(ISO: Independent System Operator)に近づく形で進化しうるかについて深く掘り下げていきます。Anjney はまた、DeepMind の未発表研究がなぜ市場の失敗を示唆しているのか、ライフサイクル終了予測がいかに彼が 14 年間考え続けてきた中で最も重要な AI アプリケーションの一つであるのか、そして「アウトプット・マキシマイジング(output maxing)」がフロンティアシステムにおける新たな学問分野となりうる理由についても説明します。
また、Anthropic の企業文化について、コーディングモデルにおいてなぜ「幸運は準備された心に味方するか」について、Claude がどのようにコーディングを突破したのか、なぜ早期に過剰な資本が流入すると AI ラボが脆弱化してしまうのか、Periodic Labs が科学と超伝導体を用いて何を目指しているのか、なぜ優れた研究者が優れた CEO になり得るのか、そしてシリコンバレーがいかにして深く宣教者的でありながら同時に深く利己主義的であるかについても議論します。
議論の要点:
Google で稼働率 95% が停止と見なされた理由
フロンティア・ラボ規模における AI インフラストラクチャの無駄がどのように複合的に増幅されるか
なぜ「速く動いて物を壊す」というアプローチは AI データセンターには通用しないのか
データセンターへの反発、電力グリッド、コミュニティのインセンティブがどのように AI のスケーリングを形作るか
FLOPs をメガワットのように流れるようにするための AMP のビジョン
なぜ計算資源に独立系統運営者(ISO: Independent System Operator)が必要なのか
Google 内部でどのように割り込み可能な需要と動的優先順位付けが機能したのか
DeepMind の研究の囲い込みがいかにして負の外部不経済(negative externalities)を生み出すか
AMP の 1.2GW ベースロードの野望と、6GW のスパイク容量の必要性
なぜ寿命予測が AI の最も重要な医療応用の一つになり得るのか
Frontier Systems、アウトプット・マキシマックス(出力最大化)、そしてフルスタック・アライメント
なぜ組織がスケールするにつれて API と抽象化レイヤーはロス(損失)を伴うものになるのか
超伝導体、標準規格、そしてロスレス・システムの夢
SF Compute、オープンプロトコル、そして計算市場の未来
なぜ NVIDIA 製以外のチップも NVIDIA のリファレンスアーキテクチャから恩恵を受けられるのか
信頼境界と、なぜチップスタートアップは将来のモデルアーキテクチャへの可視性を必要とするのか
なぜベンチャーキャピタリスト(VC)は研究者を CEO として過小評価しがちなのか
科学者たちは心のスターアスリートである
なぜ優れた CEO はスタック全体で上下に挑戦的である必要があるのか
「勝利」することよりも、フロンティアをリードすることがなぜ重要なのか
Anthropic がコーディングをどのように突破したか
なぜカルチャーは永続的な堀ではなく、脆いものなのか
なぜ Anthropic にとって苦難はバグではなく機能だったのか
なぜ Anthropic の P0(優先事項)は初日からコーディングであったのか
Periodic Labs、物理法則を制約として、そして技術的現実
シリコンバレーの傭兵たち、宣教師的なチーム、そしてブレイクスルー後に何が起きるか
Anjney Midha
LinkedIn: https://www.linkedin.com/in/anjney
X: https://x.com/AnjneyMidha
AMP PBC
Website: https://amppublic.com/
X: https://x.com/amppublic
タイムスタンプ
00:00:00 イントロダクション
00:00:09 なぜ AI 計算リソースが浪費されているのか
00:03:17 責任あるインフラとデータセンターへの反発
00:06:07 AMP Grid: FLOPs をメガワットのように流す
00:12:41 Foundry, Frontier Labs, and Research Hoarding
00:14:42 Gigawatt-Scale Compute and End-of-Life Prediction
00:24:08 Frontier Systems, Output Maxing, and Alignment
00:27:38 Compute Markets, SF Compute, and Non-NVIDIA Chips
00:32:57 Trust Boundaries, Co-Design, and Researcher CEOs
00:38:17 AI Coachella and First-Principles Thinking
00:42:43 Leading vs Winning in Frontier AI
00:45:54 How Anthropic Cracked Coding
00:48:25 Culture, Hardship, and Anthropic's P0
00:54:03 Periodic Labs, Physics, and Silicon Valley Mercenaries
00:56:26 Rishi Valley, Singapore, and Money as a Measure
00:58:47 Closing Thoughts
Transcript
Introduction: Anjney Midha, AMP, and Compute Waste
Swyx [00:00:00]: We're in Periodic Labs with Anjney Midha, CEO, founder of AMP. Welcome.
Compute Utilization: Node Allocation, MFU, and Alignment
Anjney [00:00:09]: Thanks for having me. At Google, there are two types of utilization usually, right? That you're measuring in these clusters. One is node allocation, and then the other's MFU. Node utilization is usually like what percentage of cards in the data center are just, used, and that, if it's not at, 95%-
Swyx [00:00:29]: There is no excuse
Anjney [00:00:29]: 言い訳はできませんよね。私の共同創業者である Seb が出身した Google では、彼は Borg や PBorg/GQM スケジューラを構築しましたが、そこでは 95% の稼働率が停止(アウトエージ)とみなされていました。つまり、ノード利用率が 96% に達することは標準であるべきです。しかし、多くのシングルテナントクラスタはそれ未満で稼働しています。これが一つ目のポイントです。次に、MFU(モデルファーストユーティリティ)については、現在のベストインクラスは 60% から 70% の間にあると考えられます。これは本質的にリーダーシップの問題であり、根本的にはアライメント(整合性)の問題です。つまり、クラスタに資金を提供する側と、実際にクラスタをデプロイする側が本当に一致しているかという問題です。理論上は一致しているように見えても、実際には、資本から始まり、クラスタ管理担当者、そして出力を測定する担当者に至るまでのサプライチェーン(供給網)における関係者の数があまりにも多く、分離の度合いが大きすぎて、
Swyx [00:01:33]: 広がっていきます。
Anjney [00:01:34]: それは広がりますよね?あるいはスケールした状態で。私が考えているのは、多くのクラスター実装やインフラストラクチャー、そしてフロンティアラボや他のチームにおいて起きていることです。彼らは計画を初期化しますが、これは「北極星」のようなもので、良いことをしたいというチームが持つものです。しかし、反復的なアプローチではなく、非常に速いスピードでスケールすることを要求されるため、スケールの段階で無駄が生じ、それが急速に複合的に積み重なってしまいます。そこで私が考える答えは、単に反復的な立ち上げを行うことです。半導体業界や DSN(データストレージネットワーク)業界で長年働いている人々と時間を過ごせば、これは新しいことではないことがわかります。AI がその理由になるべきだと私は思いません。もちろん。何が新しいのでしょうか?はい。私たちは多くの新たな能力を手に入れましたが、それが常識を捨てることを意味するわけではありません。常識は常に時代遅れになってはいけません。AI のスケールは、むしろ逆で、実際には、AI スケールは常識の価値とインフラストラクチャーの重要性にプレミアムをつけるべきです。なぜなら、現在の誤差の許容範囲が非常に狭く、無駄のコストがあまりにも高くなっているからです。ちなみに、無駄のコストは経済的なものだけではありません。私はもちろん、投資家としての背景を持っています。ここ数年、AI インフラストラクチャー事業である AMP を運営しています。この時期は能力面では異なると言えるかもしれません。私たちは以前にない種類の能力を本当に手に入れています。しかし、それが「今回はすべてが異なる」と言うための言い訳にはなりません。特にインフラストラクチャーについてはです。さて、私はハッカーの思考や hustler(努力家)の思考を愛しています。それはスタートアップの思考にとっては素晴らしいことです。しかし、Zuck が「速く動いて、ものを壊せ」から「速く-」へと発言を変えたあの瞬間を覚えておいてください。
責任あるインフラとデータセンターへの反発
Swyx [00:03:10]: 高速かつ安定したインフラ
Anjney [00:03:11]: 安定したインフラで迅速に動く。今こそ、責任あるインフラで迅速に動く必要があると思います。人々はその影響がどこにあるのかを問うようになるでしょう。昨日のクラスで、General Matter の創設者である Scott Nolan がスタンフォード大学を訪れ、エネルギーのボトルネックについて講演しました。彼は画期的なアイデアを持っていました。「計算処理 1 時間あたりの限界単位経済性を考えてみてください」と彼は言います。「例えば 1 時間あたり 4 ドルだとしましょう。新しいコミュニティに新たなデータセンターを建設しなければならない場合、なぜ 1 時間あたり 4.50 ドルと定め、その限界影響、つまり限界増加分をそのまま現金として地域コミュニティに還元しないのですか?」計算処理の顧客としてお伝えしますが、私はそれを歓迎します。スケーリングされた規模で 1 時間あたり追加 50 セントを支払うことにも満足するでしょう。
Swyx [00:03:57]: すごいね。そうだね。
Anjney [00:03:58]: なぜなら、それがデータセンターが建設されるコミュニティにとって公共の利益が明白であるならば、私はその計算処理をより信頼できるものと感じるからです。私の理解では、今年アメリカ国内のすべてのデータセンターのうち最大 20% がリスクにさらされています。
Swyx [00:04:13]: コミュニティからの反発によるものですか?
Anjney [00:04:14]: はい、その通りです。必要なコミュニティの支援を得られずに建設が進められないというリスクのことです。
Swyx [00:04:19]: すごい数字ですね。
Anjney [00:04:20]: はい。さて、その数値の中身について掘り下げるべきだと思います。私は、この数字は少し過大評価されているように思えます。こうした事象は過剰に報告されがちですが、しかし-
Swyx [00:04:27]: 彼らは単に雇用に関心があるだけではありません。それを取り巻く他のすべてのことにも関心がありますよね。電力網や環境などにも関心を持っているのです-
Anjney [00:04:33]: 電力網、許認可などについてです。もし「新しい AI データセンターがあなたのコミュニティに建設される」と言われたら、その結果として電気料金の負担が軽減されると想像してみてください。そうすれば、「なるほど、これは取引になるな」という話になりますよね。地域社会も「よし、これでパートナーシップだ」と感じるはずです。しかし現状ではそれが実現されていません。監査が行われ、調査も行われます。規制当局がいつ来るかは分かりませんが、AI の進展の名の下にスピードを優先し、既存の枠組みを壊す人々は準備を整えておく必要があります。それが我们现在のコンピューティング資源の調達方法ではありません。あるいは、私たちは長期的な実績を持つパートナーとできるだけ協力しようとしています。その多くは、実は AI プロバイダーではないのです。私は「ニュークラウド」という概念が何らかの新カテゴリであるという考え方は、多くのマーケティング用語に過ぎないと思います。アメリカには 20 年以上の歴史を持つ、非常に信頼できるデータセンタープロバイダーが存在します。私は彼らを愛しています。彼らはその方法を知っています。さて、NeurIPS でハッピーアワーのスポンサーになっているでしょうか?いいえ。Build に明確に記載されているでしょうか?いいえ。私の状況認識の集まりに参加しているでしょうか?いいえ。しかし彼らは大人です。私は彼らを信頼します。
Swyx [00:05:44]: 彼らは LAN を運用できますし、電力供給も管理できます。
Anjney [00:05:45]: LAN、電力、シェルを運用できます。信用履歴も持っています。私たちは座って対話をします。彼らの多くはシリコンバレーに住んでいます。彼らはインターネットの好況と不況のサイクルに対処してきており、私はそうした人々を愛しています。彼らは安定したインフラストラクチャのパートナーであり、思考者です。そして、計算層では短期的な思考が横行しており、それがやがて私たちに跳ね返ってくるでしょう。それは良いことにはなりません。
AMP Grid: FLOPs をメガワットのように流す
Swyx [00:06:07]: インセンティブの整合性についてお話しになりましたが、インセンティブを整合させるということは、フルスタックを一つの企業にまとめることを意味すると私は考えます。それは xAI や OpenAI のようなケースですね。では、スタンドアロンのインフラストラクチャ層であるあなたが、なぜ全体を所有している人々よりもポートフォリオ企業とより整合性が高いと言えるのでしょうか?
Anjney [00:06:28]: システム設計において、アーキテクチャには二つのレジーム(体制)があります。一つは統合であり、もう一つはプール化と利用率向上です。むしろ、利用率を高める方法は、プロセスを一つのノードに集約するシステム統合を行うか、あるいはあるプロセスをノードから切り離し、それを複数の異なるノード間で共有することです。そして私たちが構築している AMP グリッド(計算グリッド)がまさにそれであり、これは電力グリッドが行っていることを計算領域で行おうとしているのです。
Swyx [00:07:02]: 電力
Anjney [00:07:02]: はい、電力網が電気に対して果たした役割と同じです。これはクラウド間におけるプール化と利用のレイヤーであり、私たちはフルスタック統合アプローチとは正反対の立場にあります。
Swyx [00:07:12]: 非常に水平方向ですね。
Anjney [00:07:13]: ここでは、はるかに水平方向の構造であり、マルチクラウドかつマルチシリコンです。目標は、FLOPs(浮動小数点演算数)がメガワットのように流れるようにすることですが、多くの理由から今日これを達成するのは非常に困難です。計算リソースの遊休プールが至るところに存在し、相互交換性がありません。そのため、現在はスケジューリングレベルで対応しており、経済層でも頻繁に対応しています。しかし、私たちが取り組んでいる内容を発表し始めると、驚くべきことに多くの人が「実は、このスタックの一部と別の部分で計算リソースの相互交換性を実現する方法に取り組んでいます」と言い始めています。グリッドとして、私たちはこれらの人々がすべてグリッドに参加することを望んでいます。多くの人から「アンジュニー、あなたは新しいクラウドですか?」と尋ねられますが、「いいえ、実際にはニュークラウドはサプライヤーです」と答えます。また、「ベンチャーキャピタル会社ですか?」と聞かれることもあります。「いいえ、彼らは需要側であり、グリッドのオフテーカーのようなものです」と答えています。私たちは「独立系統運用者(ISO: Independent System Operator)」と呼ばれる存在だと考えています。もし電力グリッドの歴史を研究すれば、多くの工場や産業参加者が、プール化が有効なアイデアであることを理解し始めたとき、各家庭に発電機を半分の容量で稼働させるのではなく、発電機をプールすべきだという結論に至ったことがわかります。これらの当事者(送電線、発電施設、送電線、工場など)を調整できる独立した組織が必要でした。そして、この中立的な調整メカニズムが非常に重要なのです。もしグリッドの歴史を研究すれば、最も持続可能なものは、自らの資産を所有していなかったものです。それらは、特定の町にある競合しない鉄鋼工場や靴工場など、需要源として相関のない長期的なアンカー(基盤)を持っていたか、あるいはそのようなものから始まったものでした。鉄鋼工場は夜間に需要が急増し、靴工場は昼間に需要が急増するといった状況です。そこでプールして共有します。各社は一定のベースロードを保障されますが、町全体のピーク利用率を最大化するために、それぞれのピーク需要をスケジュール調整します。歴史的な黄金基準と言えるのは、アメリカ北東部のPJM Interconnectのような電力会社で、長年の年月をかけて「独立系統運用者(ISO)」と呼ばれる存在へと進化しました。これが私たちの自己認識です。経済的にはまさにその通りです。技術的観点からは、スケジューリング層から始めました。ここでエンジニアリングを率いるSebとMihaiが、このレイヤーを構築したからです。
Swyx [00:09:28]: スケジューリングはどのように行いましたか?
Anjney [00:09:28]: Google でそのようにしていました。そして、-
Swyx [00:09:32]: Discord にもインフラチームがありますよね。
Anjney [00:09:35]: はい、一部あります。
Swyx [00:09:35]: 分かりませんが、Discord が主要なアイデンティティとして機能しているのかどうかは不明ですが、とにかく-
Anjney [00:09:39]: いいえ、D-Discord は-
Swyx [00:09:40]: 有名な名前を選ぶことでした。
Anjney [00:09:42]: はい、そこで私は開発者プラットフォームを担当していました。内部インフラについては責任を持っていませんでした。それは実際、マーク・スミスという名前の人物が担当しており、彼は非常に卓越した方でした。はい、Discord はプール化されていました。つまり、Discord は実際には逆の事例です。そこではフルスタックのインフラについて多くを学ぶ機会がありました。なぜなら-
Swyx [00:09:56]: 同じことですね、はい。
Anjney [00:09:57]: それは、Discord が独自の WebRTC(Web Real-Time Communication)音声およびビデオインフラを構築したという別のアーキテクチャです。つまり、Discord は-
Swyx [00:10:08]: 通話のためにですね、はい。
Anjney [00:10:09]: はい、通信にはサードパーティのインフラ(外部インフラ)を使用しませんでした。すべて社内開発でした。そして、利用率を最大化する方法は、世界中の月間アクティブユーザーが 2 億人以上いるゲーマーからの需要をプールすることです。そうして、これらのスタックが構築されました。システム設計において再び繰り返し登場する 2 つの概念は、抽象化(abstraction)と合成(composition)です。そして-
Swyx [00:10:31]: バンドル化とアンバンドル化
Anjney [00:10:33]: バンドル化とアンバンドル化、抽象化、コンポジション、垂直統合や-
Swyx [00:10:36]: 水平化
Anjney [00:10:36]: 水平化ですね。つまりその観点から、AMP はグリッドの独立したシステムオペレーターです。私たちは信頼できる多数のパートナーから需要と供給をプールします。4 年間で約 1.3 ギガワットの規模でです。そして、世界有数の研究機関などからの需要もプールしています。私たちが相手としているのは、極めて長期的な需要を必要とする定期的なラボたちです。そのアイデアは、各ラボがグリッド上でベースロード(基幹負荷)を保証される一方で、計算リソースについては必要な場合に短期間で柔軟に増減できることです。これが私が a16z で考案した「Oxygen」というプログラムの設計の概略でした。同じく、Mihai と Seb が構築した Google における GQM、BorgX、および Borg の GQM 実装でも同様の設計が採用されていました。これは、Google 内のチームが社内インフラ上でベースワークロードに対して容量を保証される一方で、研究のために需要を急増させる必要がある場合にも、それが十分に確保されていることをどうやって保証するかという問いに対する答えでした。もちろん、このインフラ分野において約 3〜4 年前に Google で実装された(発見されたのではなく)画期的なアイデアは、「中断可能な需要」の概念です。つまり、多数のジョブをキューに積み、この一種のクレジットシステムを通じて入札メカニズムを機能させるというものです。
Swyx [00:11:53]: 優先度のようなものですね。
Anjney [00:11:54]: 要するに、これは動的な優先順位付けです。ある人が「このジョブに 10 トークン、10 クレジットを使いたい」と言うことで、他の誰かがそのジョブを中断させる可能性があります。別のチームリードや研究リードが、「Genie 3 やその他はわずか 5 クレジットの価値しかないが、NanoBanana2 は 10 クレジットの価値がある」と言う場合、NanoBanana のジョブに優先順位が与えられます。これは架空の例です。
Swyx [00
原文を表示
Last 4 days before regular tickets sell out at AI Engineer World’s Fair - this is the single biggest gathering of AI Engineers, Founders, Leaders, and Researchers in the world. Attendees get >$5000 worth of sponsor credits and talk tracks are looking FANTASTIC. Join us!
The AI scaling debate always focuses on the question of “how do we get more GPUs?” but the better question may be: how do we make the most of ones we already have.
The fact that a frontier lab like xAI could be running at sub-10% MFU (Model FLOPs Utilization) is just a hint at what the real problem may be.
tweet
For context, older frontier-scale training runs were already much higher than 10%. GPT-3 was around 21% MFU. Gopher was around 32%. Megatron-Turing NLG was around 30%. PaLM reached around 46%. And our guest Anjney says best-in-class MFU today is closer to 60–70%.
PaLM: Scaling Language Modeling with Pathways
It’s not necessarily that xAI is uniquely incompetent (it’s clear they have talented folks) but rather the priorities may be flipped in the GPU arms race.
While GPU access is a bottleneck, simply increasing CapEx won’t automatically translate to better models as frontier AI is increasingly a systems problem: scheduling, utilization, networking, kernels, frameworks, data pipelines, parallelism, cluster reliability, and the thousand small decisions that determine whether your theoretical FLOPs become real training progress.
From building Discord’s developer platform and backing frontier AI companies like Anthropic, Mistral, Black Forest Labs, and Periodic Labs to now building AMP’s independent compute grid, Anjney Midha has spent years close to the real bottlenecks of AI scaling. In this episode, Anjney joins swyx at Periodic Labs to unpack why the AI race is not just about buying more GPUs, why 95% utilization would have been considered an outage at Google, and why the next era of AI infrastructure has to be more aligned, more efficient, and more responsible.
We go deep on AMP’s vision for a compute grid that makes FLOPs flow like megawatts, the difference between full-stack AI labs and horizontal pooling, why AI data centers need community buy-in, and how compute markets could evolve into something closer to an independent system operator. Anjney also explains why DeepMind’s unpublished research points to a market failure, why end-of-life prediction remains one of the most important AI applications he has thought about for fourteen years, and why “output maxing” may become a new discipline for frontier systems.
We also discuss Anthropic’s culture, why “luck favors the prepared mind” in coding models, how Claude cracked coding, why too much capital too early can make AI labs fragile, what Periodic Labs is trying to do with science and superconductors, why great researchers can become great CEOs, and why Silicon Valley is both deeply missionary and deeply mercenary.
We discuss:
Why 95% utilization was considered an outage at Google
Why AI infrastructure waste compounds at frontier-lab scale
Why “move fast and break things” does not work for AI data centers
How data center backlash, power grids, and community incentives shape AI scaling
AMP’s vision for making FLOPs flow like megawatts
Why compute needs an independent system operator
How interruptible demand and dynamic prioritization worked inside Google
Why DeepMind research hoarding creates negative externalities
AMP’s 1.2GW base-load ambition and the need for 6GW of spike capacity
Why end-of-life prediction could become one of AI’s most important healthcare applications
Frontier Systems, output maxing, and full-stack alignment
Why APIs and abstraction layers become lossy as organizations scale
Superconductors, standards, and the dream of lossless systems
SF Compute, open protocols, and the future of compute marketplaces
Why non-NVIDIA chips can still benefit from NVIDIA’s reference architecture
Trust boundaries and why chip startups need visibility into future model architectures
Why VCs often underestimate researchers as CEOs
Scientists as star athletes of the mind
Why great CEOs need to be confrontational up and down the stack
Why leading the frontier matters more than “winning”
How Anthropic cracked coding
Why culture is fragile, not a permanent moat
Why hardship was a feature, not a bug, for Anthropic
Why Anthropic’s P0 was coding from day one
Periodic Labs, physics as the constraint, and technical reality
Silicon Valley mercenaries, missionary teams, and what happens after a breakthrough
Anjney Midha
LinkedIn: https://www.linkedin.com/in/anjney
X: https://x.com/AnjneyMidha
AMP PBC
Website: https://amppublic.com/
X: https://x.com/amppublic
Timestamps
00:00:00 Introduction
00:00:09 Why AI Compute Is Being Wasted
00:03:17 Responsible Infrastructure and Data Center Backlash
00:06:07 AMP Grid: Making FLOPs Flow Like Megawatts
00:12:41 Foundry, Frontier Labs, and Research Hoarding
00:14:42 Gigawatt-Scale Compute and End-of-Life Prediction
00:24:08 Frontier Systems, Output Maxing, and Alignment
00:27:38 Compute Markets, SF Compute, and Non-NVIDIA Chips
00:32:57 Trust Boundaries, Co-Design, and Researcher CEOs
00:38:17 AI Coachella and First-Principles Thinking
00:42:43 Leading vs Winning in Frontier AI
00:45:54 How Anthropic Cracked Coding
00:48:25 Culture, Hardship, and Anthropic’s P0
00:54:03 Periodic Labs, Physics, and Silicon Valley Mercenaries
00:56:26 Rishi Valley, Singapore, and Money as a Measure
00:58:47 Closing Thoughts
Transcript
Introduction: Anjney Midha, AMP, and Compute Waste
Swyx [00:00:00]: We’re in Periodic Labs with Anjney Midha, CEO, founder of AMP. Welcome.
Compute Utilization: Node Allocation, MFU, and Alignment
Anjney [00:00:09]: Thanks for having me. At Google, there are two types of utilization usually, right? That you’re measuring in these clusters. One is node allocation, and then the other’s MFU. Node utilization is usually like what percentage of cards in the data center are just, used, and that, if it’s not at, 95%-
Swyx [00:00:29]: There is no excuse
Anjney [00:00:29]: There’s no excuse, right? I think 95% at Google, which is where my co-founder, Seb, came from, he built the Borg, PBorg/GQM scheduler at Google, and there I think 95% was considered an outage, so 96% node utilization is, should be standard. And most single-tenant clusters are not running at that. So that’s one. And then MFU should be, I would say the best in class today is somewhere between 60 and 70%. I think this is a leadership question, right? Fundamentally it’s an alignment question, which is are the people who are funding the cluster and then deploying the cluster actually aligned? And sometimes theoretically they are, but in practice the number of people in the chain, the supply chain between, the capital and all the way to whoever’s managing the cluster and then whoever’s measuring what the output is, are just so many, degrees of separation away that, the, The Have you ever heard the radian metaphor, which is at the beginning of an arc, if you have two arcs that are two lines that are just off by a few degrees, that-
Swyx [00:01:33]: It spreads out
Anjney [00:01:34]: It spreads out, right? Or at scale. And I think what’s happening is a lot of cluster implementations and infrastructure, a lot of frontier labs and other teams, that’s what’s happening, is they’re, they initialize the plan, which is kind of like North Star with a team that wants to do good, but then they’re, required to scale so fast instead of iteratively that the wastage just compounds really fast at scale. And so I think we know the answer, which is just do iterative bring ups. If you spend time with people who’ve been in the semiconductor industry or the DSN industry for a long time, this is not new, and I don’t think AI should be an excuse. Sure. Something What is new? Okay. We have a lot of new capabilities, but that doesn’t mean just abandon common sense. Common sense should always be in fashion. ? AI scaling doesn’t change the in fact, if anything, AI scaling should be putting a premium on the value of common sense and infrastructure because the margin of error now is so much lower and the costs of wastage are so much higher. And the cost of wastage, by the way, is not just economic. I’m, obviously I’m, I’m an investor, or I’m an investor by background. Over the last few years now we’re running an AI infrastructure business called, AMP. And I think that it’s okay to say this time is different on the capabilities front. We are genuinely getting capabilities at, of the, of a kind we haven’t had before. That doesn’t give you an excuse to say this time is different for everything, especially infrastructure. So look, I love the hacker mindset and the hustler mindset. Now, that’s great for the startup mindset, but you remember this moment where Zuck went from saying, “Move fast, break things” to, move-
Responsible Infrastructure and Data Center Backlash
Swyx [00:03:10]: Fast and stable infrastructure
Anjney [00:03:11]: Move fast with stable infrastructure. I think now we need to move fast with, responsible infrastructure. People are going to ask where the impact is. There was a really In our class yesterday, Scott Nolan, who’s the founder of General Matter, came by at Stanford to speak about energy bottlenecks. And he had a phenomenal idea. He said, “if you look at the marginal unit economics of compute per hour,” he goes, “let’s call it, $4 an hour. If you’re having to bring up a new data center in a new community, why not just say we’re going to charge 4.50 an hour, and that marginal impact or that marginal increase, we just literally take that and give it to the local community as cash?” I can tell you as a customer of that compute, I would love that. I’d be happy to pay an additional 50 cents per hour at scale.
Swyx [00:03:57]: Wow. Yeah.
Anjney [00:03:58]: Because if that means the public benefit is so clear to the communities that the data centers are coming up in, I’m going to feel like that compute is much more reliable. Up to 20% of all data centers this year in the US, my understanding is are at risk.
Swyx [00:04:13]: Of community backlash?
Anjney [00:04:14]: Correct. Of not getting the community support they need to get brought up.
Swyx [00:04:19]: Wow. That’s a huge number.
Anjney [00:04:20]: Yeah. Now, we, I think we should dig into what that number is. I think it’s a little bit of overstated. These things can get over-reported, but it-
Swyx [00:04:27]: They don’t just care about jobs. They care about all the other stuff around it, right? They care about power grid, they care about environments-
Anjney [00:04:33]: Power grid, permitting, and so on. And imagine I think if you said there’s a new AI deal. If we’re bringing up a data center in your community, we’re actually going to reduce the cost of your electricity bill. Okay, now we’re talking. Right? The community’s going, “Okay. Now this is a deal. I feel like a partner in this.” Right now that’s not happening. There will be audits, there will be investigations, and when the, when the regulators come, I don’t know when it’s going to be, the folks who are moving fast and breaking things in the name of AI progress better be prepared. That’s certainly not how we’re procuring compute. Or we’re, we’re trying as much as we can to work with partners who have long-term track records. Many of whom, by the way, are not, AI providers. I think this whole idea of neoclouds being somehow this new category is a lot of marketing speak. There are really good, reliable, trusted data center providers in America who’ve been around 20 plus years. I love those folks. They know how to Sure. Are they sponsoring happy hours at NeurIPS? No. Are they legibly listed in Build? No. Are they hanging out in my, in, situational awareness parties? No. But they’re adults. I trust them.
Swyx [00:05:44]: They can run LAN. They can run power.
Anjney [00:05:45]: They can run LAN, power, and shell. They have credit histories. We sit down, we have a conversations. Many of them live in Silicon Valley. They’ve, they’ve had to deal with the boom and bust cycles of the internet, and I love those folks. They are stable infrastructure partners and thinkers. And I think there’s a lot of short-term thinking going on in the compute layer, and it’s going to catch up to us. It’s not going to be good.
AMP Grid: Making FLOPs Flow Like Megawatts
Swyx [00:06:07]: You talk about aligning incentives, and, I would think that aligning incentives means you have the full stack in one company, which is xAI and OpenAI, right? So you as a standalone infrastructure layer, why are you somehow more aligned to your portfolio companies than people who just own the whole thing?
Anjney [00:06:28]: In systems design, right, there’s, there’s two regimes of, architecture, right? You have integration, and then you have pooling and utilization, right? So the Or rather, the way to increase utilization often is you can do systems integration where you collapse a lot of process into one node, or you can pull out a process from a node and share that amongst various That resource amongst several different nodes. And so we see the AMP grid, which is, the, what, the system we’re building here, which is basically a compute grid. We’re trying to do for compute what the electric grid-
Swyx [00:07:02]: Power
Anjney [00:07:02]: Yeah, what the power grid did for electricity. It-- this is a pooling and utilization layer across clouds, And so we’re actually the opposite of a full stack integration like approach.
Swyx [00:07:12]: Super horizontal.
Anjney [00:07:13]: Where it’s much more horizontal and it’s, it’s multi-cloud, it’s multi-silicon. The goal is to try to make FLOPs flow like megawatts, and that is very hard to do today for many reasons. There’s stranded pools of compute all over the place and there’s no fungibility. And so right now we do it at the level of scheduling, and we often do it at the economic layer. But as we start to announce what we’re working on, it’s extraordinary like how many folks are coming out of the woodworks and saying, “Hey, I’m actually working on a way to make compute fungible at this part of the stack and that part of the stack.” And as a grid, we’d like all of these folks to participate on the grid. There’s, people often ask me, “Andra, are you a new cloud?” And I go, “No, actually neoclouds are suppliers.” sometimes they’ll ask, “Are you a venture capital firm?” I go, “No, actually they are, they are demand like sort of off-takers of the grid.” We see ourselves as what’s called an independent system operator. So if you study the history of the electric grid, once it became legible to a lot of factories and industrial sort of participants that, hey, actually it turns out pooling is a good idea. We should pool our generators instead of all having a generator running at half capacity in our backyard. There was a need for an independent entity who could coordinate all these parties. Transmission line, power generation, facilities, transmission lines, factories, and that neutral coordination mechanism is very critical. In order-- If you study like the history of grids, the most enduring ones were those that never owned their own assets. They were ones that had, or often started with long-term anchors who are uncorrelated sources of demand, a steel factory, a shoe mill or whatever in a particular town who weren’t competitive, where the steel factory want to spike up at night, the shoe mill wanted to spike up during the day. So then you pool and you share, right? So each of you is guaranteed some base load, but then you kind of schedule your spikes to drive a peak utilization across the town. The gold standard, so to speak, historically, has been these utility companies like PJM Interconnect in the northeast of America, where they, over many years became this what’s called an ISO, an independent system operator of the grid. So that’s how we see ourselves. Economically, that’s what we are. From a technical perspective, we started at the scheduling layer because Seb and Mihai, who, run engineering here, built that at-
Swyx [00:09:28]: Did your scheduling
Anjney [00:09:28]: They did that at Google. And, -
Swyx [00:09:32]: And you have infra shops from Discord as well.
Anjney [00:09:35]: I have some.
Swyx [00:09:35]: I don’t know, I don’t know if Discord is like the primary identity, but what-whatever, I’m just kind of-
Anjney [00:09:39]: No, D-Discord was-
Swyx [00:09:40]: Choosing a well-known name.
Anjney [00:09:42]: Well, I So I was running the developer platform there. The internal infrastructure I was not responsible for. That was actually a guy by the name of Mark Smith, who was extraordinary. And yes, Discord did pool So Discord is actually a counter example. I had the chance to learn a lot about fully, full stack infra there because-
Swyx [00:09:56]: It’s the same thing, yeah
Anjney [00:09:57]: It’s the, it’s the other architecture which is, Discord built its own WebRTC vo-voice and video infra. So like Discord did not use-
Swyx [00:10:08]: For the calls, yeah.
Anjney [00:10:09]: Yeah, did not For communication, Discord did not use third party infra. It was all built in-house. And then the way you maximize utilization was you pool demand from the world’s 200 million plus monthly active gamers, right? And so that’s, that’s how those stacks were constructed. Again, in systems design, the two concepts that keep coming up over and over again are abstraction and composition, right? And-
Swyx [00:10:31]: Bundling and unbundling
Anjney [00:10:33]: Bundling and unbundling, abstraction, composition, like verticalization and-
Swyx [00:10:36]: Horizontal
Anjney [00:10:36]: Horizontalization. So in that sense, AMP is an independent system operator of the grid. We pool demand, we pool supply from a number of partners we trust At about 1.3 gigawatt scale over four years. And then we pool demand from some of the world’s best, research labs and so on. We’re sitting at one, periodic labs who need extraordinary long-term demand. And the idea is that, each of them is guaranteed base load on the grid, but they can spike up and down flexibly on, for compute, with much shorter timelines as needed. That was roughly the design of the program I came up with at a16z called Oxygen. The same-- That was the same design of the GQM, BorgX, Borg GQM implementation at Google that Mihai and Seb had built. Which was that how do you allow, teams inside of Google, on the internal infrastructure to be guaranteed capacity, for their base workloads? But when they need to spike up on research, how could they ensure that was sufficiently there? And of course, the big innovation that was not discovered, but kind of implemented in the space, this infra space maybe three, four years ago at Google was the idea of interruptible demand, right? Where you just queue up a bunch of jobs and through this like sort of credit system, there can be a bidding mechanism.
Swyx [00:11:53]: Like priorities.
Anjney [00:11:54]: It’s a dynamic prioritization Basically. And jobs can get interrupted based on somebody else who’s saying, “what? I have 10 tokens, 10 credits I want to spend on this job.” Another like team lead, research lead is “Genie 3 or whatever is only worth five, credits, and NanoBanana2 is worth 10 credits,” and so the NanoBanana job gets priority. That’s a, that’s a made up example.
Swyx [00
関連記事
テック企業は安価な AI モデルを愛せるようになるか?(4 分読了)
TLDR AI は、コスト削減のために安価な AI モデルを採用する動きが業界全体に広がりつつある現状と、その技術的・経済的な課題について分析している。
BGP AS_PATH の最初の AS を強制する仕組みの導入
Cloudflare は、Spamhaus が報告したルート乗っ取り事案を踏まえ、不正なアクターが未使用の自律システム番号(ASN)を利用して偽の AS_PATH を作成しトラフィックを誤誘導する手口に対処するため、BGP の経路情報において最初の AS 番号の検証を強化する措置を発表した。
生産環境向け AI パイプラインのための Mistral Search ツールキット(4 分読了)
Mistral が、生産環境の AI パイプラインで検索機能を統合するためのツールキットを公開した。これにより開発者は検索能力を容易に実装できる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み