LangChain AI 2024年レポート
LangChain の LangSmith を利用する約 30,000 ユーザーのデータに基づき、2024 年の AI エコシステムにおけるオープンソースモデルの急成長と、RAG からマルチステップ型エージェントへのワークフロー転換という重要なトレンドが示された。
キーポイント
OpenAI の圧倒的シェア維持
利用可能な LLM プロバイダーの中で OpenAI が依然としてトップであり、2 位以下の Ollama を 6 倍以上引き離していることが確認された。
オープンソースモデルの急激な普及
Ollama(ローカル実行)と Groq(クラウド展開)がトップ 5 にランクインし、柔軟なデプロイメントオプションへの関心が高まっている。
ワークフローのパラダイムシフト
従来の検索強化生成(RAG)中心のワークフローから、多段階処理を行う AI エージェントアプリケーションへの移行が顕著に進んでいる。
影響分析・編集コメントを表示
影響分析
このレポートは、2024 年の AI 開発現場が単なるプロトタイプ作成から、より複雑で自律的なエージェントシステムの構築へと成熟したことを示しています。特にオープンソースモデルと専用ハードウェア(Groq など)の台頭は、ベンダーロックインからの脱却とコスト最適化を求める開発者の明確な意志を反映しており、今後はハイブリッドなアーキテクチャが標準となるでしょう。
編集コメント
業界の動向を裏付ける実データに基づく貴重なレポートであり、特に「RAG からエージェントへ」という転換点は、開発戦略を見直す上で重要な示唆を含んでいます。

LLM(大規模言語モデル)を用いた開発の1年が終わりつつあり、2024年は期待を裏切りませんでした。毎月約3万人のユーザーがLangSmithに登録していることから、私たちは業界で何が起きているかを最前列から間近で見守る幸運に恵まれています。
昨年と同様に、AIエコシステムおよびLLMアプリ構築の実践がどのように進化しているかを示す製品使用パターンを共有したいと考えています。LangSmith上で追跡、評価、反復を行う過程で、私たちはいくつか顕著な変化を目の当たりにしました。それには、オープンソースモデルの採用が劇的に増加したことや、主に検索強化生成(RAG)ワークフローから、マルチステップのエージェント型ワークフローを持つAIエージェントアプリケーションへとシフトしたことが含まれます。
以下の統計データを確認し、開発者が具体的に何を開発し、テストし、優先順位をつけているのかを詳しく学んでください。
インフラストラクチャの使用状況
LLMが世界を席巻する中、誰もが鏡よ鏡、壁の向こう側にある質問をしています。「その中で最も利用されているモデルはどれか?」私たちが確認した内容を紐解いてみましょう。
主要なLLMプロバイダー
昨年の結果と同様に、OpenAIはLangSmithユーザーの間で最も使用されているLLMプロバイダーとして君臨しており、次点のOllama(LangSmith組織の使用状況でカウント)よりも6倍以上使用されています。
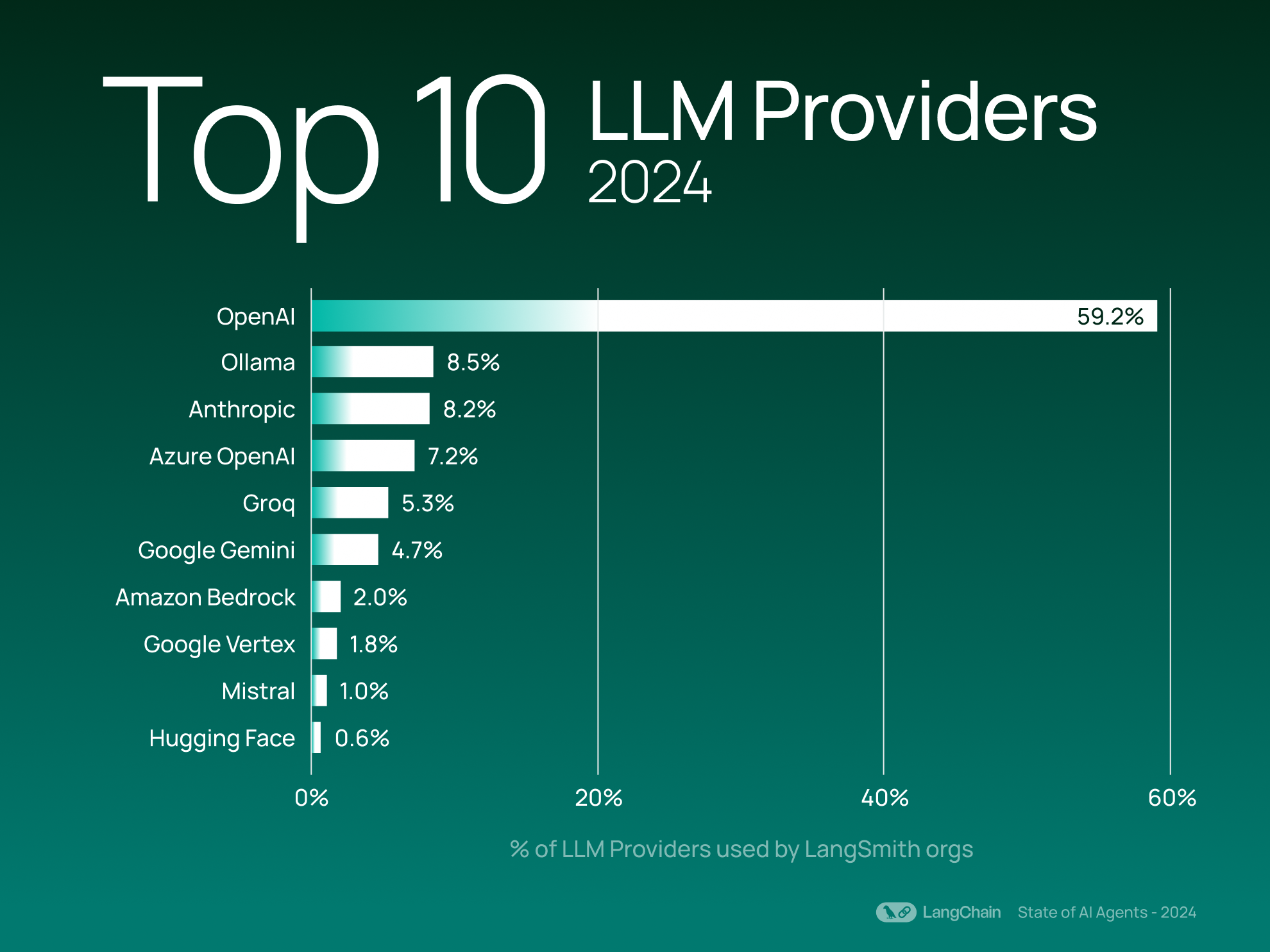
興味深いことに、Ollama および Groq(両者ともオープンソースモデルの実行を可能にし、前者はローカル実行に焦点を当て、後者はクラウド展開に重点を置いている)は今年、勢いを加速させ、トップ5入りを果たしました。これは、より柔軟な展開オプションやカスタマイズ可能なAIインフラストラクチャへの関心が高まっていることを示しています。

オープンソースモデルを提供するプロバイダーに関して言えば、トッププロバイダーは昨年と比較して比較的安定しています。Ollama、Mistral、Hugging Faceは、開発者がプラットフォーム上でオープンソースモデルを実行しやすくしています。これらのOSS(Open Source Software:オープンソースソフトウェア)プロバイダーの総使用量は、トップ20のLLM(Large Language Model:大規模言語モデル)プロバイダー全体の 20%を占めています(使用している組織数による)。
トップ検索エンジン / ベクトルストア
多くのGenAI(Generative AI:生成型人工知能)ワークフローにおいて、検索機能の実行は依然として重要です。トップ3のベクトルストアは昨年と同じままで、ChromaとFAISSが最も人気のある選択肢です。今年、Milvus、MongoDB、Elasticのベクトルデータベースもトップ10入りを果たしました。

LangChain プロダクトを活用した構築
生成 AI の利用に開発者がより多くの経験を重ねるにつれ、彼らはより動的なアプリケーションの構築を進めています。ワークフローの高度化から AI エージェントの台頭まで、私たちは革新のエコシステムが進化する方向を示すいくつかのトレンドを目にしています。

観測可能性は LangChain アプリケーションに限定されない
オープンソースフレームワークである langchain は、多くの人の LLM(大規模言語モデル)アプリ開発の中心ですが、今年 LangSmith によるトレースの 15.7% が 非 langchain フレームワーク由来となっています。これは、LLM アプリの構築にどのフレームワークを使用するかに関わらず観測可能性が必要であり、LangSmith が相互運用性をサポートしているというより広範なトレンドを反映しています。
Python が支配的でありながら、JavaScript の使用が拡大
デバッグ、テスト、モニタリングは Python 開発者の心の中で確かに特別な位置を占めており、Python SDK からの使用が 84.7% を占めています。しかし、開発者がウェブファーストのアプリケーションを追求するにつれて、JavaScript への関心も顕著かつ増加しており、今年 LangSmith の使用における JavaScript SDK の割合は 15.3% を占め、前年比で 3 倍に増加しています。
AI エージェントの普及が進む
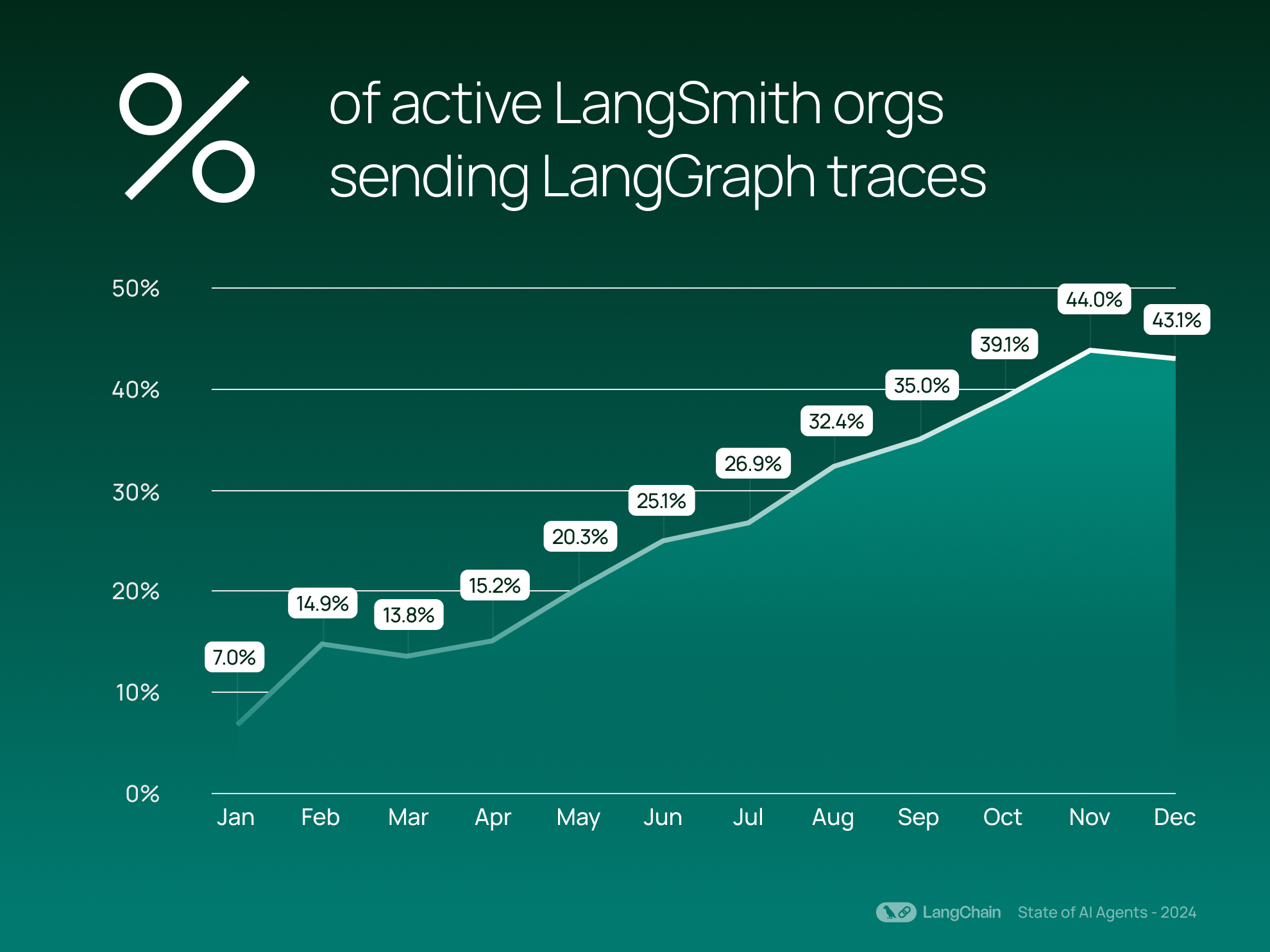
企業が さまざまな業界に AI エージェントを組み込むこと に本格的に取り組むにつれ、当社の制御可能なエージェントフレームワークである LangGraph の採用も増加しています。2024 年 3 月のリリース以来、LangGraph は着実に普及し、43% の LangSmith 組織が現在 LangGraph のトレースを送信しています。これらのトレースは、基本的な大規模言語モデル(LLM)のやり取りを超えた、複雑で調整されたタスクを表しています。
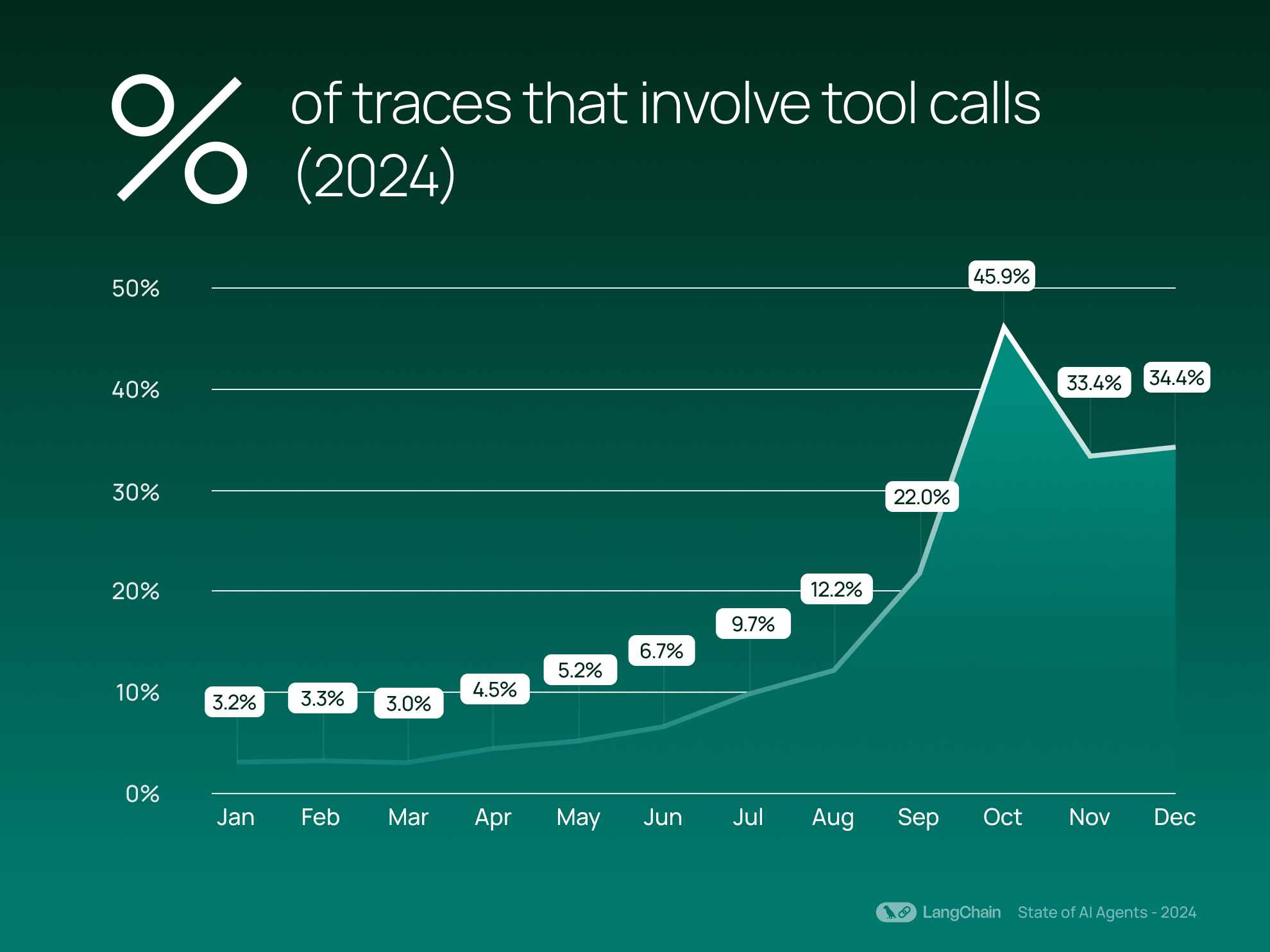
この成長は、エージェント的な振る舞いの増加と一致しています。平均して、現在トレースの 21.9% がツール呼び出し(tool calls)を含んでおり、2023 年の平均 0.5% から大幅に増加しています。ツール呼び出しにより、モデルは関数や外部リソースを自律的に呼び出すことができ、これはモデルが行動を起こすタイミングを判断するより高度なエージェント的振る舞いを示しています。ツール呼び出しの使用が増加することで、エージェントが外部システムと相互作用し、データベースへの書き込みなどのタスクを実行する能力が向上します。
パフォーマンスと最適化
速度と洗練さのバランスを取ることが、特に大規模言語モデル(LLM)のリソースを活用するアプリケーションを開発する際の主要な課題です。以下では、組織が自らのニーズの複雑さと効率的なパフォーマンスを一致させるために、どのようにアプリケーションと対話しているかを探ります。
複雑さは増大するが、タスクは効率的に処理されている
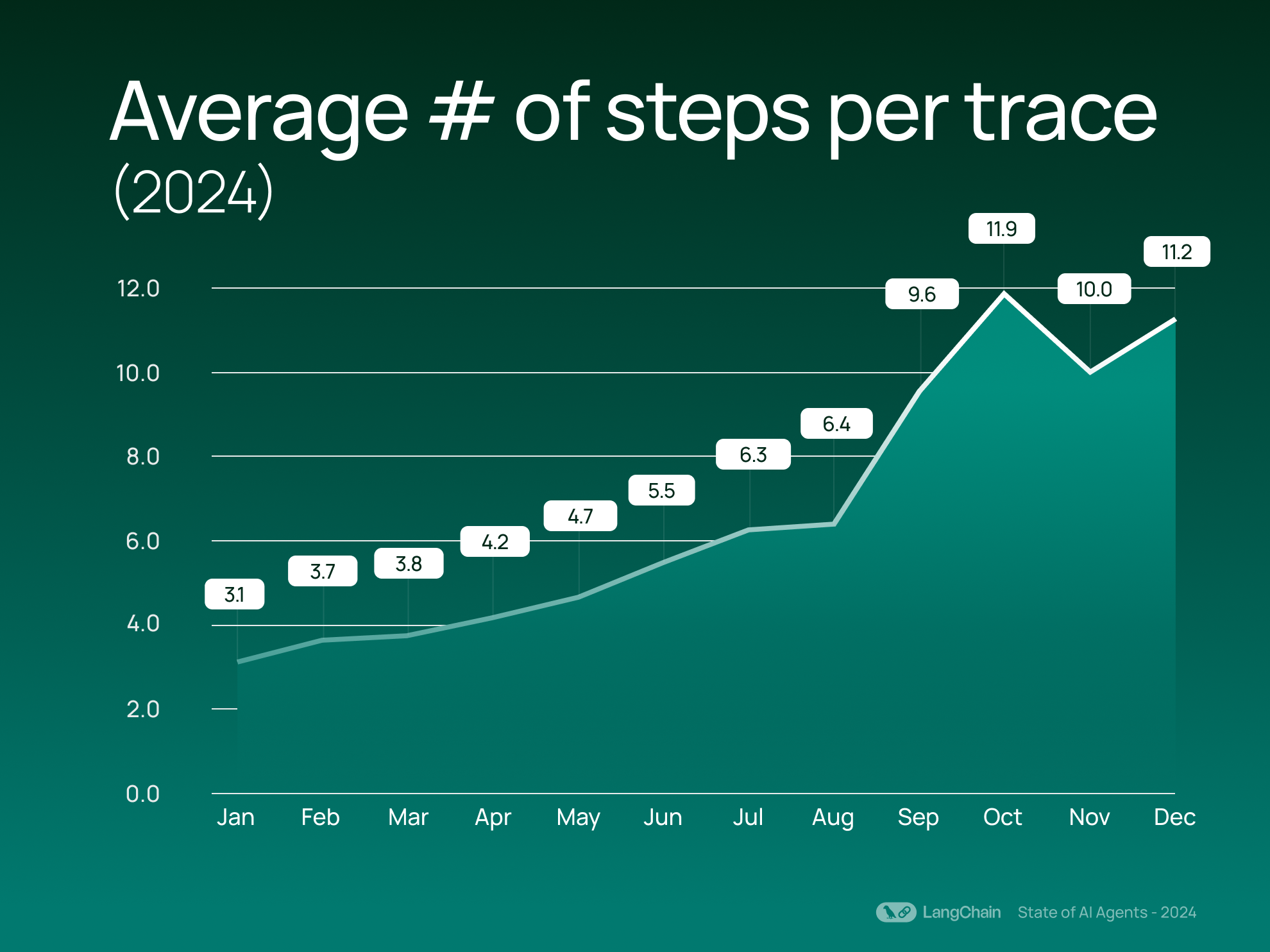
過去1年で、トレース(trace)あたりの平均ステップ数は2倍以上増加し、平均で2.8ステップ(2023年)から7.7ステップ(2024年)に上昇しました。ここでいう「ステップ」とは、LLMへの呼び出し、リトリーバー(retriever)、またはツールなどの、トレース内の個別の操作を指します。このステップ数の増加は、組織がより複雑で多面的なワークフローを活用していることを示しています。単なる質問応答のやり取りではなく、ユーザーは情報を取得し、それを処理し、実行可能な結果を生成するという複数のタスクを連鎖させるシステムを構築しています。
一方、トレースあたりのLLM呼び出しの平均数はより穏やかに増加しており、平均で1.1から1.4回のLLM呼び出しとなっています。これは、開発者がより少ないLLM呼び出しでより多くのことを実現するようにシステムを設計していることを示しており、高コストなLLMリクエストを抑えながら機能性をバランスよく保っています。
LLM テストと評価
組織は、不正確または低品質な LLM 生成応答から守るために、LLM アプリケーションをどのようにテストしているのでしょうか?LLM アプリの品質を高い状態に保つことは容易ではありませんが、LangSmith の評価機能を使用してテストを自動化し、ユーザーフィードバックループを生成して、より堅牢で信頼性の高いアプリケーションを作成している組織が見られます。
LLM-as-Judge:重要なものを評価する
LLM-as-Judge 評価者は、採点ルールを LLM プロンプトに組み込み、LLM を使用して出力が特定の基準に従っているかどうかをスコアリングします。開発者が最も頻繁にテストしている特性は次のとおりです:関連性、正確さ、完全一致、および有用性。
これらは、開発者の大多数が AI 生成の出力が完全に的外れにならないようにするために、応答品質に対する粗いチェックを行っていることを示しています。

人間のフィードバックを用いた反復開発
LLM アプリケーションを構築する際、人間のフィードバックはイテレーション(反復)プロセスの重要な要素です。LangSmith は、トレースやラン(つまりスパン)に対する 人間のフィードバックの収集と反映 のプロセスを加速し、ユーザーが改善と最適化のための豊富なデータセットを作成できるように支援します。過去 1 年間、注釈付きのランは 18 倍に増加し、LangSmith の利用拡大と線形に比例してスケールしました。
ランあたりのフィードバック量もわずかに増加し、1 ランあたり 2.28 件から 2.59 件のフィードバックエントリに上昇しました。それでもなお、1 ランあたりのフィードバックは相対的に疎です。ユーザーは包括的なフィードバックを提供することよりも、ランのレビュー速度を優先している可能性があります。あるいは、注目を必要とする最も重要または問題のあるランに対してのみコメントを行っているのかもしれません。
結論
2024 年、開発者はマルチステップエージェントの複雑さに対応し、より少ない LLM コールでより多くの処理を行うことで効率性を高め、フィードバックと評価の手法を用いてアプリケーションに品質チェックを追加しました。LLM アプリケーションがさらに作成されるにつれて、より賢明なワークフロー、パフォーマンスの向上、そして堅牢な信頼性について深く掘り下げる様子を楽しみにしています。
LagSmith について詳しくはこちら をご覧ください。ボトルネックのデバッグからレスポンス品質の評価、回帰モニタリングに至るまで、LLM アプリケーション開発の可視性を高め、時間経過に伴うパフォーマンスを改善する方法をご確認ください。
関連コンテンツ

エージェントアーキテクチャ
LangSmith
オープンソース
LangSmith と LangChain OSS が EU AI 法(EU Artificial Intelligence Act)の要件を満たすのをどう支援するか


J. Talbot,
B. Weng
2026 年 4 月 27 日
7 分

企業アナウンス
2026 年 4 月:LangChain ニュースレター

LangChain チーム
2026 年 4 月 27 日
4 分

エージェントアーキテクチャ
パートナー
エージェントエンジニアリング:AI エージェントの群れがソフトウェアエンジニアリングをどのように再定義しているか


R. Kumar、
P. Ramagopal
2026年4月17日
6分

エージェントの実際の動作を確認する
LangSmithは、当社のエージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、変更を評価(eval)し、ワンクリックでデプロイすることを支援します。
原文を表示
Another year of building with LLMs is coming to an end — and 2024 didn’t disappoint. With nearly 30k users signing up for LangSmith every month, we’re lucky to have front row seats to what’s happening in the industry.
As we did last year, we want to share some product usage patterns that showcase how the AI ecosystem and practice of building LLM apps are evolving. As folks have traced, evaluated, and iterated their way around LangSmith, we’ve seen a few notable changes. These include the dramatic rise of open-source model adoption and a shift from predominantly retrieval workflows to AI agent applications with multi-step, agentic workflows.
Dive into the stats below to learn exactly what developers are building, testing, and prioritizing.
Infrastructure usage
With Large Language Models (LLMs) eating the world, everyone’s asking the mirror-mirror-on-the-wall question: “Which model is the most utilized of them all?” Let’s unpack what we’ve seen.
Top LLM providers
Like last year’s results, OpenAI reigns as the most used LLM provider among LangSmith users — used more than 6x as much as Ollama, the next-most popular provider (counted by LangSmith organization usage).
Interestingly, Ollama and Groq (which both allow users to run open source models, with the former focusing on local execution and the latter on cloud deployment) have accelerated in momentum this year, breaking into the top 5. This shows a growing interest in more flexible deployment options and customizable AI infrastructure.
When it comes to providers that offer open-source models, the top providers have stayed relatively consistent compared to last year - Ollama, Mistral, and Hugging Face have made it easy for developers to run open source models on their platforms. These OSS providers’ collective usage represents 20% of the top 20 LLM providers (by the number of organizations using them).
Top Retrievers / Vector Stores
Performing retrieval is still critical for many GenAI workflows. The top 3 vector stores have remained the same as last year, with Chroma and FAISS as the most popular choices. This year, Milvus, MongoDB, and Elastic’s vector databases have also entered the top 10.
Building with LangChain products
As developers have gained more experience utilizing generative AI, they are also building more dynamic applications. From the growing sophistication of workflows, to the rise of AI agents — we’re seeing a few trends that point to an evolving ecosystem of innovation.
Observability isn’t limited to LangChain applications
While langchain (our open source framework) is central to many folks’ LLM app development journeys, 15.7% of LangSmith traces this year come from non-langchain frameworks. This reflects a broader trend where observability is needed regardless of what framework you’re using to build the LLM app — and that interoperability is supported by LangSmith.
Python remains dominant, while JavaScript usage grows
Debugging, testing, and monitoring certainly has a special place in our Python developers’ hearts, with 84.7% usage coming from the Python SDK. But there is a notable and growing interest in JavaScript as developers pursue web-first applications — the JavaScript SDK accounts for 15.3% of LangSmith usage this year, increasing 3x compared to the previous year.
AI agents are gaining traction
As companies are getting more serious about incorporating AI agents across various industries, adoption of our controllable agent framework, LangGraph, is also on the rise. Since its release in March 2024, LangGraph has steadily gained traction — with 43% of LangSmith organizations are now sending LangGraph traces. These traces represent complex, orchestrated tasks that go beyond basic LLM interactions.
This growth aligns with the rise in agentic behavior: we see that on average 21.9% of traces now involve tool calls, up from an average of 0.5% in 2023. Tool calling allows a model to autonomously invoke functions or external resources, signaling more agentic behavior where the model decides when to take action. Increased use of tool calling can enhance an agent’s ability to interact with external systems and perform tasks like writing to databases.
Performance and optimization
Balancing speed and sophistication is a key challenge when developing applications — especially those leveraging LLM resources. Below, we explore how organizations are interacting with their applications to align the complexity of their needs with efficient performance.
Complexity is growing, but tasks are being handled efficiently
The average number of steps per trace has more than doubled over the past year, rising from on average 2.8 steps (2023) to 7.7 steps (2024). We define a step as a distinct operation within a trace, such as a call to an LLM, retriever, or tool. This growth in steps signals that organizations are leveraging more complex and multi-faceted workflows. Rather than a simple question-answer interaction, users are building systems that chain together multiple tasks, such as retrieving information, processing it, and generating actionable results.
In contrast, the average number of LLM calls per trace has grown more modestly— from on average 1.1 to 1.4 LLM calls. This speaks to how developers are designing systems to achieve more with fewer LLM calls, balancing functionality while keeping expensive LLM requests in check
LLM testing & evaluation
What are organizations doing to test their LLM applications to guard against inaccurate or low-quality LLM-generated responses? While it’s no easy feat to keep the quality of your LLM app high, we see organizations using LangSmith’s evaluation capabilities to automate testing and generate user feedback loops to create more robust, reliable applications.
LLM-as-Judge: Evaluating what matters
LLM-as-Judge evaluators capture grading rules into an LLM prompt and use the LLM to score whether the output adheres to specific criteria. We see developers testing for these characteristics the most: Relevance, Correctness, Exact Match, and Helpfulness
These highlight that most developers are doing coarse checks for response quality to make sure AI generated outputs don’t completely miss the mark.
Iterating with human feedback
Human feedback is a key part of the iteration loop for folks building LLM apps. LangSmith speeds up the process of collecting and incorporating human feedback on traces and runs (i.e. spans) – so that users can create rich datasets for improvement and optimization. Over the past year, annotated runs grew 18x, scaling linearly with growth in LangSmith usage.
Feedback volume per run also increased slightly, rising from 2.28 to 2.59 feedback entries per run. Still, feedback is relatively sparse per run. Users may be prioritizing speed in reviewing runs over providing comprehensive feedback, or commenting on only the most critical or problematic runs that need attention.
Conclusion
In 2024, developers leaned into complexity with multi-step agents, sharpened efficiency by doing more with fewer LLM calls, and added quality checks to their apps using methods of feedback and evaluation. As more LLM apps are created, we’re excited to see how folks dig into smarter workflows, better performance, and stronger reliability.
Learn more here about how LangSmith can bring more visibility into your LLM app development and improve performance over time — from debugging bottlenecks to evaluating response quality to monitoring regressions.
Related content
Agent Architecture
LangSmith
Open Source
How LangSmith and LangChain OSS Help You Meet EU AI Act Requirements
J. Talbot,
B. Weng
April 27, 2026
7
min
Company Announcements
April 2026: LangChain Newsletter
The LangChain Team
April 27, 2026
4
min
Agent Architecture
Partner
Agentic Engineering: How Swarms of AI Agents Are Redefining Software Engineering
R. Kumar,
P. Ramagopal
April 17, 2026
6
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み