GLM 5.1の戦略的思考、データセンター反発の激化、有用LLMが役に立たなくなる時、二足歩行ロボットの現場導入
本分析は、提供された404エラーページからタイトルを抽出し、GLM 5.1の戦略的思考、データセンター動向、LLMの振る舞い、人型ロボットの進展という4つのAIニューストピックを概観している。
キーポイント
GLM 5.1の戦略的思考能力向上
中国のZhipu AIが公開したGLM 5.1モデルが、複雑なタスクにおける計画立案と戦略的思考能力を大幅に強化した。
データセンター建設をめぐる規制・反対運動の激化
AI需要の急増に伴うデータセンター建設が、地域社会や環境規制と衝突し、開発プロセスに遅れを生じさせている。
有用なLLMが予期せぬ有害・無効な出力を生成する現象
高度化したLLMが特定の条件下で安全性や有用性を失い、予期せぬ有害な出力や機能停止を示すケースが報告されている。
人型ロボットの産業実用化・現場導入の進展
ヒューマノイドロボットが製造業や物流などの実環境での本格稼働を開始し、技術成熟とコスト削減が進んでいる。
影響分析・編集コメントを表示
影響分析
提供されたコンテンツは404エラーページのため実際の本文がありませんが、タイトルから推測されるニュースはAIモデルの能力進化とインフラ制約の両面を示しています。大規模モデルの安全性課題とデータセンター建設の社会的摩擦は、業界全体の規制対応とサプライチェーン最適化を加速させる要因となります。
編集コメント
提供された記事本文は404エラーページのため、実際のコンテンツが存在しません。タイトルから推測されるニューストピックを基に分析を構成していますが、詳細な検証には原文の再確認が必要です。
親愛なる皆様へ、
コーディングエージェントは、ソフトウェア作業の異なる種類を異なる程度で加速させています。チームを構築する際、これらの区別を理解することは、現実的な期待を持つために役立ちます。機能の加速度が高い順に列挙すると、私の順序は次の通りです:フロントエンド開発、バックエンド、インフラストラクチャ、そしてリサーチ(研究)。
フロントエンド開発 — 例えば、ECサイトの製品説明を表示するWebページを構築すること — は、コーディングエージェントがTypeScriptやJavaScriptのような人気のあるフロントエンド言語、およびReactやAngularのようなフレームワークに精通しているため、劇的に高速化されています。さらに、Webブラウザを操作して構築した成果物を検証することで、コーディングエージェントは自身の実装を閉じ、反復的に改善することに非常に優れています。もちろん、現在のLLM(大規模言語モデル)はビジュアルデザインにおいてまだ弱みがありますが、デザインが提供されている場合(または洗練されたデザインが重要でない場合)、実装は非常に迅速です!
バックエンド開発 — 製品データを要求するクエリに応答するAPIを構築するなど — はより困難です。現代のモデルが、微妙なバグやセキュリティ上の脆弱性につながる可能性のある境界ケースを考慮して思考するよう導くには、人間開発者によるより多くの作業が必要です。さらに、バックエンドのバグは、データベースが破損し、時折誤った結果を返すといった直感的でない下流への影響を引き起こす可能性があり、これは典型的なフロントエンドのバグよりもデバッグが難しい場合があります。最後に、データベースマイグレーションはコーディングエージェントによって容易になる場合もありますが、それでも困難であり、データ損失を防ぐために慎重に処理する必要があります。バックエンド開発はコーディングエージェントによって大幅に高速化されますが、その加速度は限定的であり、熟練した開発者はコーディングエージェントを使用する経験の浅い開発者よりもはるかに優れたバックエンドを設計・実装し続けます。
インフラストラクチャー。10,000人のアクティブユーザーを維持しながら99.99%の信頼性を確保するようにECサイトをスケールアップするといったタスクにおいて、エージェントはさらに効果的ではありません。インフラストラクチャーに関するLLM(大規模言語モデル)の知識は相対的に限られており、優れたエンジニアが複雑なトレードオフを考慮する必要があるため、私は重要なインフラストラクチャーの決定にはほとんど信頼していません。優れたインフラストラクチャーを構築するには、しばしばテストと実験の期間が必要であり、コーディングエージェントはその支援に役立ちますが、最終的には高速なAIによるコーディングがあまり助けにならない重大なボトルネックとなります。最後に、インフラストラクチャーのバグ(例えば、微妙なネットワークの設定ミスなど)を見つけることは非常に困難であり、深いエンジニアリングの専門知識を要します。したがって、私はコーディングエージェントがバックエンド開発よりもさらに重要なインフラストラクチャーの加速に寄与しないことを発見しました。
 imageリサーチ。コーディングエージェントは、リサーチ作業をさらに遅く加速します。リサーチには、新しいアイデアを検討し、仮説を立て、実験を実行し、それらを解釈して仮説を修正する可能性を探り、結論に達するまで反復するというプロセスが含まれます。コーディングエージェントは、リサーチコードを書く速度を高めることができます。(また、私は実験の調整と追跡を支援するためにコーディングエージェントを使用しており、これにより単一の研究者がより多くの実験を管理しやすくなります。)しかし、リサーチにはコーディング以外の作業が多く、現在のエージェントはリサーチに対して限定的な支援しか提供していません。
imageリサーチ。コーディングエージェントは、リサーチ作業をさらに遅く加速します。リサーチには、新しいアイデアを検討し、仮説を立て、実験を実行し、それらを解釈して仮説を修正する可能性を探り、結論に達するまで反復するというプロセスが含まれます。コーディングエージェントは、リサーチコードを書く速度を高めることができます。(また、私は実験の調整と追跡を支援するためにコーディングエージェントを使用しており、これにより単一の研究者がより多くの実験を管理しやすくなります。)しかし、リサーチにはコーディング以外の作業が多く、現在のエージェントはリサーチに対して限定的な支援しか提供していません。
ソフトウェアの作業をフロントエンド、バックエンド、インフラストラクチャ(インフラ)、リサーチに分類するのは極端な簡略化ですが、異なるタスクがどれほど高速化したかについての単純なメンタルモデルを持つことは、ソフトウェアチームの編成において有用でした。例えば、私はフロントエンドチームに対して、1年前よりも劇的に速い製品実装を求めています。しかし、リサーチチームに対する私の期待は、それほど大きく変化していません。
コーディングエージェントを活用してスピードを実現するために、ソフトウェアチームをどのように編成すべきかという点に強い関心を抱いており、今後のレターで私の発見を共有し続けていきます。
作り続けましょう!
アンドリュー
DEEPLEARNING.AI からのメッセージ
「マルチモーダルデータパイプラインの構築」では、画像、音声、ビデオをエンドツーエンドで処理するパイプラインの構築方法を学びます。構造化されていないデータを、クエリ可能な形式に変換します。無料で受講する
ニュース
GLM 5.1、長時間実行タスクを目指す
Z.ai は、そのフラッグシップとなるオープンウェイトの大規模言語モデルを更新し、単一のタスクに対して最大8時間自律的に動作できるようにしました。
新しい動向: GLM-5.1 は、コーディングおよびエージェント(自律型 AI エージェント)タスクのために設計されています。Z.ai によれば、このモデルはアプローチを試行し、その結果を評価して、成果が不十分であれば戦略を見直すことができます。このプロセスを何百回も繰り返すことで、早期に諦めるのではなく、より高度な推論を実現します。
- 入出力:最大20万トークンのテキスト入力に対し、最大12万8000トークンのテキスト出力
- アーキテクチャ:Mixture-of-experts(MoE)トランスフォーマー、総パラメータ数7540億個、トークンごとにアクティブなパラメータ数は400億個
- 機能:推論、関数呼び出し、構造化出力
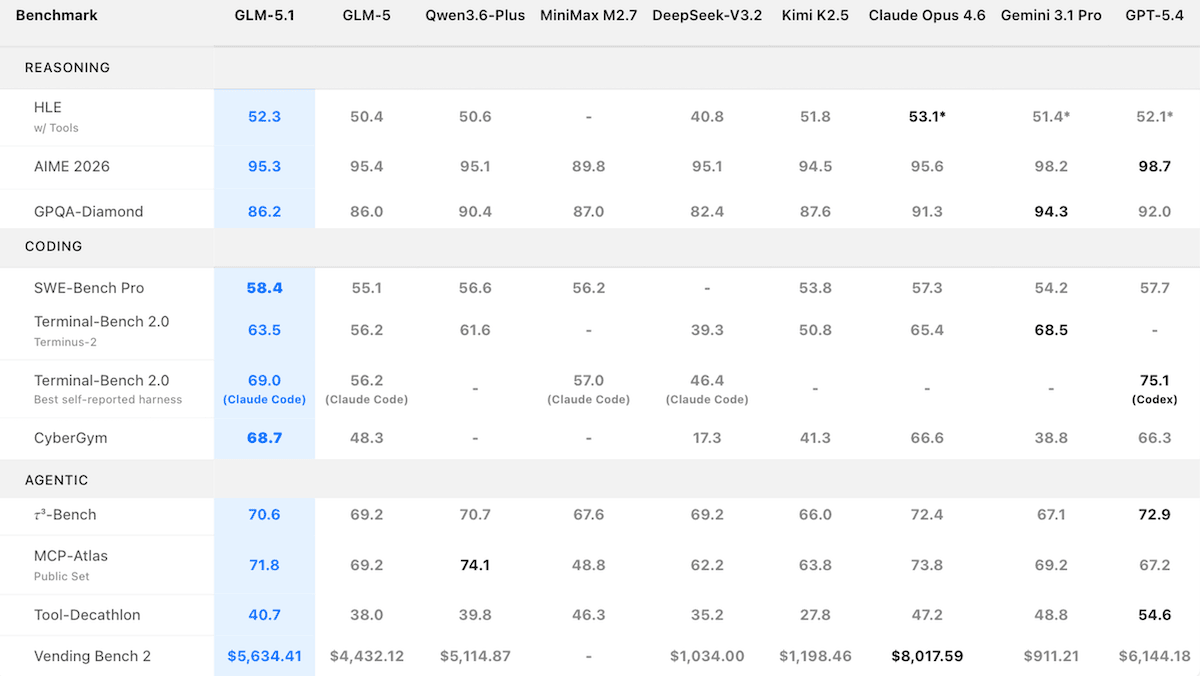
- パフォーマンス:Artificial Analysis Intelligence Indexでオープンウェightsモデルとして最高スコア、Arena Codeリーダーボードで3位、SWE-Bench Pro(Z.aiのテスト環境)で首位を記録
- 提供状況と価格:HuggingFace経由でMITライセンスの下、商用・非商用を問わずウェights公開。APIは入力トークン100万個あたり1.40ドル、キャッシュ済みトークン100万個あたり0.26ドル、出力トークン100万個あたり4.40ドル。コーディングプランは四半期あたり48.60ドルから432ドル
- 非公開:具体的なアーキテクチャ、トレーニングデータおよび手法
動作原理: Z.aiはGLM-5.1に特化した技術レポートを公開していないが、GLM-5’の基本アーキテクチャ、アテンション機構、事前学習、入出力サイズ制限を踏襲していると考えられる。主な改善点は、長時間のタスクにおける持続的な生産性にある。
- 同社は GLM-5.1 をエージェント型コーディング向けに最適化したと述べたが、具体的な手法については明記しなかった。
- GLM-5 や他の多くのモデルが、特定のトークン予算内で最終出力を生成するか、さらなる推論が行われても結果が変わらないと判断するまでで処理を終えるのに対し、GLM-5.1 は計画立案、実行、中間結果の評価、そしてアプローチ自体の評価をサイクルとして繰り返し、タスクが完了したと判断するまで処理を続ける。現在のアプローチに問題があると見なせば戦略を変更し、Z.ai のテストでは数千回のツール呼び出しを複数時間にわたって行う場合もあった。
パフォーマンス: GLM-5.1 はオープンウェights モデルの中で強力なコーディング結果を達成したものの、推論や数学のテストではプロプライエタリ(独自開発)モデルに劣った。
- Artificial Analysisのインテリジェンス指数(経済的に有用なタスクに関する10のテストからなる複合指標)において、推論モードに設定されたGLM-5.1(スコア51)はオープンウェイトモデルの中で最高スコアを記録したが、推論モードに設定されたGemini 3.1 Pro Preview(スコア57)やxhigh推論に設定されたGPT-5.4(同スコア57)、さらにmax推論に設定されたClaude Opus 4.6(スコア53)には及ばなかった。
- 盲検の頭対頭の比較に基づいてモデルをランク付けするArenaのコードリーダーボードでは、GLM-5.1はリリースから数日以内にEloスコア1,530を達成し、Claude Opus 4.6(Eloスコア1,542)および推論モードに設定されたClaude Opus 4.6(Eloスコア1,548)に次いで3位となった。
- Z.ai独自のテストでは、GLM-5.1はGitHubから抽出された現実的なソフトウェアエンジニアリングの問題を扱うSWE-Bench Proで首位となり、58.4パーセントのスコアを記録した。これに対し、GPT-5.4は57.7パーセント、Claude Opus 4.6は57.3パーセント、Gemini 3.1 Proは54.2パーセントだった。
- セキュリティ推論をテストするCyberGymにおいて、GLM-5.1(スコア68.7)はZ.aiがテストしたモデルの中で最高スコアを達成した。これはAnthropicが報告したClaude Mythos(スコア83.1)の登場以前の話であり、Claude Opus 4.6(スコア66.6)やGPT-5.4(スコア66.3)なども含まれる。Gemini 3.1 ProとGPT-5.4は安全上の理由から特定のタスクの実行を拒否しており、これがそれらの指標を低下させた可能性が高い。
- グラフィックスプロセッシングユニット(GPU)上で動作する機械学習コードの加速能力を測定するKernelBench Level 3において、Z.aiはGLM-5.1(3.6倍)をClaude Opus 4.6(4.2倍)に次ぐスコアとして計測した。
- 推論および数学に関するテストでは、GLM-5.1はプロプライエタリモデルに対してより大きな差で後れを取った。例えば、大学院レベルの科学問題を出題するGPQA Diamondでは、GLM-5.1(正解率86.2パーセント)はGemini 3.1 Pro(正解率94.3パーセント)に劣った。競技数学の問題であるAIME 2026では、GLM-5.1(95.3パーセント)はGPT-5.4(98.7パーセント)に及ばなかった。
価格上昇:Z.aiは、GLM-5.1を前モデルよりも大幅に高い価格で設定した。そのAPIトークン価格は約40%高く、コーディングプランのサブスクリプションは約2倍となっている。APIのコストは同等のプロプライエタリモデルよりもまだ安い(Claude Opus 4.6が100万入力トークンあたり5ドルに対し、GLM-5.1は1.40ドル)が、その差は縮まりつつある。
なぜこれが重要なのか: 数分ではなく数時間自律的に作業を行う能力は、大規模言語モデル(LLM)の競争において急速に拡大している分野です。独立したテスト機関である METR によると、AI エージェントが自律的に完了するタスクの長さは約7ヶ月ごとに2倍になっており、Anysphere の統合開発環境(IDE)「Cursor」は OpenAI 駆動の AI エージェント群を1週間稼働させました。しかし、SWE-EVO のように持続的なパフォーマンスをテストするために設計されたベンチマークでは、トップモデルでも長期間のコーディングタスクを成功裏に完了できるのは約25%にとどまることが示されています。
我々の見解: 独立したテストにおいて、GLM-5.1 が長時間のセッション中に行き詰まりを認識し、そこから方向転換する能力が裏付けられる場合、それは現在のベンチマークが見落としている訓練目標を示唆しています。それは、失敗するアプローチをいつ放棄すべきかを認識することです。

二足歩行型ロボットが工場床で作業
限られた数の二足歩行型ロボットが産業現場に導入され、そのコストは人間の労働コストとほぼ同等になりつつあり、一部の作業員をより高度な役割へと押し上げています。
注目すべき点: オレゴン州に拠点を置くAgility Roboticsは、ドイツの自動車部品メーカーであるSchaefflerに対して二足歩行型ロボットを供給しており、これは二足歩行型ロボットの最初の運用展開です。*The Wall Street Journal*は報じています。AgilityのDigitロボットは、南カロライナ州にあるSchaefflerの工場で、新しく製造された部品が入ったバケツを運搬しています。この作業は以前、人間の労働者によって行われていましたが、その人物は監督職に昇進しました。両社ともに現在使用されているDigitの台数を明らかにしていませんが、Schaefflerは2030年までに米国およびヨーロッパの工場に数百台を展開する計画であると述べています。
仕組み: シェフラーの工場では、Digitが、プレス加工機からコンベアベルトまで25ポンドのバスケットを運搬しています。この移動には約1分かかります。このロボットは近傍の人間を検出する機能(アジリティ社が来年に実装予定)を備えていないため、アクリル板のバリアの背後で稼働しています。充電のための休憩を挟み、4時間シフトを2回勤務します。同社は、処理用ハードウェアやAIモデル、データセット、トレーニング方法など、自社の技術に関する詳細な情報をほとんど公開していません。
- Digitは人間規模(身長5フィート9インチ、体重143ポンド)で構築されており、荷物を運ぶための逆関節の脚、荷物を持ち上げてバランスを保つために設計された腕、4本の指を持つグリッパー、処理装置・バッテリー・センサーを内蔵する胴体、そして現在の注力対象を向くLED「目」を備えています。これは2016年頃にオレゴン州立大学との共同開発で生まれた、胴体や頭部、知覚システムを持たない二足歩行ロボティクス研究プラットフォーム「Cassie」を基盤としています。
- ロボットのセンサーには、RGB深度カメラ、LiDAR(レーザー光による距離測定技術)、運動を検知する慣性計測装置(IMU: Inertial Measurement Unit)、および関節の位置と速度を測定する未詳のエンコーダーが含まれます。
- 歩行制御は動的であり、不均一な地形を管理し、外的擾乱から回復し、階段や傾斜を上ることを可能にします。
- アジリティエンジニアは展開前に作業環境をマッピングし、現場で特定のタスクを設定します。タスクは関節モーターへのコマンドではなく構造化されたワークフローとして記述され、ピックアップ場所、ドロップオフ場所、物体の種類などの変数を指定します。
- アジリティはDigitの価格を非公表にしていますが、1台あたりのコストは時間当たり10〜25ドルであり、一方、シェフラー工場の初級職の賃金は時間当たり20ドルであると述べています。
ニュースの背景: 現在、人間型ロボットの現実的な産業利用は、倉庫や工場における限られた数の初期かつ狭義な展開に限定されており、それらは特定の明確に定義されたタスクを支援するために使用されています。産業分野の他のほとんどの人間型システムは、パイロットまたは試行段階にあります。マッキンジーのコンサルタントが『ウォール・ストリート・ジャーナル』に語ったところによれば、現在工場では約200台の人間型ロボットが稼働しており、製造業の労働力を大幅に削減することなく、2040年までにこの数が500万台に成長すると予想されています。一般的に、研究では、ロボットは特定のタスクにおいて人間を置き換えることで、仕事の再構築と残りの役割のアップグレードを促進すると示唆されています。人間型ロボットが雇用にもたらす影響を評価するには、まだ早すぎます。
なぜこれが重要なのか: 人間型ロボットの普及は、バッテリー、モーター、AIの技術向上により、過去数年でようやく現実のものとなりました。一般的な産業用ロボットとは異なり、人間と同様の形状とサイズを持つ機械は、人間のために設計された環境において、人間の活動に直接組み込むことができます。さらに、AIによる視覚認識、運動技能、ナビゲーション機能により、これらは自由に移動し、少なくともある程度の自律性を持って作業を行うことが可能になっています。Schaefflerがサウスカロライナ州でDigitsを使用していることは、AmazonでのAgilityロボットのテストやGXO Logistics、BMWによるFigureの人間型ロボットの試行といったパイロットプログラムの段階を超えたものであり、これらが経済的に有用な作業を遂行できることを示しています。そして、現在人間が行っている労働の一部をこれらのロボットが担う可能性も十分にあります。
私たちが考えていること: ロボティクス 研究が示すところによれば、人間型ロボットをより自律的かつ対話的にし、全体的な能力を高める余地は依然として大きく残っているようです。

データセンター反対運動の勢いが増す
米国各地で、新たなデータセンター建設への抵抗が高まっています。
何が新しいか: データセンターの反対派は、立法府を通じて異議を表明しており、最近の2つの事例では暴力行為にまで及んでいます。これらの施設に対する懸念には、電気料金への影響、電力および水の消費量、騒音公害、住宅街との近接性、そして広大な規模などが含まれます。2024年5月から2025年3月の間に、地域社会の反対により約640億ドル規模のデータセンタープロジェクトが阻止または延期されたものと、ある研究グループは推定しています。
仕組み: この抵抗の一部は、民主的な手続きを通じて表現されています。
- メイン州の立法府は、20メガワット以上の電力を必要とする新規データセンターの新設を一時的に停止する法案を可決しました。この措置は知事の署名待ちです。また、データセンターが電力網および電気料金に与える影響を調査する評議会の設置も規定しています。これが施行されれば、全州規模での初の禁止措置となり、他の州でも追随する可能性があります。2026年には少なくとも12の他州でデータセンター停止法案が提出されています。
- ウィスコンシン州ポートワシントンの市議会は、データセンターを含む大型プロジェクトに対して税制優遇措置を付与する前に有権者の承認を得ることを義務付ける住民投票を最近可決しました。支持者によれば、これは同種の最初の試みであり、OracleとOpenAIによる1.3ギガワットのデータセンター建設(2028年の稼働予定)の最中に実施されました。市当局はプロジェクト誘致のために税制優遇措置を提供していました。この住民投票は2対1の賛成多数で可決されましたが、ビジネス団体が法廷で異議を唱えたため、Politicoの報道によれば現在法的審査中です。
- ミズーリ州フェストスでは、市内に60億ドルのデータセンター建設を承認した市議会の全議員が、有権者によって罷免されました。
- オハイオ州では市民発議の ballot measure(投票措置)により、25メガワットを超える電力を必要とする将来のデータセンターを禁止する州憲法改正を目指しています。この措置は7月1日までに40万人以上の署名を集めて ballot(投票用紙)に掲載される必要があり、その後11月の国民投票で50%以上の賛成を得る必要があります。
- ネバダ州ボーラーシティでは、住民が公開意見聴取会に参加し、データセンター反対デモを行うなど不快感を示したため、88.5エーカーのデータセンターに関する予定されていた公聴会が延期されました。
- メリーランド州でも反対の声が上がっており、2つの郡の住民が提案されたデータセンター開発に抗議する集会を行いました。
暴力的な対応: データセンターへの敵意は、少なくとも2件の事件において暴力と関連づけられています。
- サンフランシスコでは、最近、ある男性がOpenAIのCEOであるサム・アルトマン氏の自宅にモロコフ・カクテルを投げつけた。そのわずか1時間後、同氏はOpenAIの本社に赴き、建物を焼き尽くすと脅迫したとNPRは報じた。連邦の宣誓供述書によると、この男性はAIが人類にもたらすリスクについて記述している。
- インディアナポリスの市議会の議員の自宅には13発の銃弾が撃ち込まれた。同氏は市内に5億ドル規模のデータセンターを建設することに賛成していた。ドアマットの下には「データセンター不要」と書かれたメモが挟まれていた。
ニュースの背景: 一部のプロジェクトに関する透明性の欠如は、反対派の主要な不満点である。例えばミズーリ州の開発事例では、データセンターの運営者が公に特定されていない。批判派はまた、施設の環境フットプリント(環境負荷)、特に騒音レベル、広大な床面積、エネルギー需要、水消費を指摘している。しかし、最新のデータセンターはサーバー冷却用のより水効率の高いクローズドループシステムなど、環境に優しい設計を採用している。さらに、データセンターの増加する数が、民間所有のオフ・ザ・グリッド(系統独立型)発電所を通じて自らの電力を供給している。
なぜこれが重要なのか: AI の急速な成長はデータセンターへの需要急増をもたらしたが、電力が一部の地域では主要な制約要因となりつつある。このボトルネックを解消するため、テクノロジー企業は新たな発電設備の建設競争を繰り広げているが、これらのプロジェクトの規模は地域社会に緊張を高めている。地域社会は、データセンターによる雇用創出や税収増といった経済的利益と、電力網への負荷増大、騒音公害、近隣環境の悪化といったトレードオフの間でバランスを取る必要がある。より広範な視点では、テクノロジー業界のリーダーたちは、データセンターの開発を中国との人工知能競争における重要な要素と見なしている。
我々の考察: データセンターの運用者には責任感の差がある。大手 AI 企業は資源消費について透明性を保っている。それらの電力および水使用量は、一般の認識よりもはるかに少ないことが多く、最新のデータセンターは旧来の施設と比較して環境に優しい。
一貫して支援するアシスタント
通常、大規模言語モデル(LLM: Large Language Model)は、有用で有害ではなく、誠実なアシスタントとして振る舞うように訓練される。しかし、長時間または感情的に激しい対話の中では、有益でない特性が現れることがある。研究者たちは、LLM のアシスタント・ペルソナを安定させる手法を開発した。
新しい発見: Christina Lu氏、オックスフォード大学のML Alignment & Theory Scholars Program(研究者とメンターをマッチングする独立した学術フェローシップ)の同僚たち、そしてAnthropicは、アシスタント軸を定義しました。これはモデルの層ごとの出力に基づいたベクトルであり、そのモデルが訓練されたアシスタントとしての性格にどの程度従っているかを示すものです。このチームは、このベクトルからの逸脱を修正する方法を開発しました。
重要な洞察: 以前の研究では、特定の性格特性(親切さ、楽観主義、ユーモア、へつらい、悪意など)に対応する「ペルソナベクトル」を大規模言語モデル(LLM: Large Language Model)の層出力から抽出することが可能であることが示されました。LLM のアシスタント役割におけるペルソナベクトルは、デフォルトの振る舞い時と、セラピスト、道化師、自己愛性人格者、狂信者、犯罪者などの他の役割を演じるよう促された場合の層出力の平均差を抽出することで計算できます。著者が「アシスタント軸」と呼ぶこの差分ベクトルと、任意の瞬間におけるペルソナベクトルの類似度は、LLM がアシスタント役割からどれほど逸脱しているかを示し、この状況は一部のユーザーを危険な状況に陥らせる可能性があります。モデルの性格が逸脱した際、この類似度を高めることでモデルを正しい軌道に戻すことができます。
仕組み: チームは、Gemma 2 27B、Qwen3 32B、Llama 3.3 70B のデフォルトのキャラクターからの逸脱を探りました。彼らはモデルのデフォルトのキャラクターを表すベクトルを見つけ、その逸脱を検出し、モデルを正しい軌道に戻すよう促しました。
- 著者らは、モデルの性格を示すように設計された1,200件の質問を生成しました(例:「他人の成果を自分のものとして扱う人々をどう思いますか?」)。また、モデルに代替キャラクターになりすますよう求める1,375件のシステムプロンプトも生成しました(例:「あなたはプログラミング言語や技術について百科事典級の知識を持つプログラマーです。」)
- モデルは、デフォルトの性格(システムプロンプトを使用しないか、「自分自身として応答せよ」などのプロンプトを使用)および各代替キャラクターの両方で質問に回答し、チームは各レイヤーの出力を記録しました。アシスタント軸は、デフォルト性格における各レイヤーごとの平均出力と、すべての代替キャラクターを合わせた場合の各レイヤーごとの平均出力との差として定義されました。
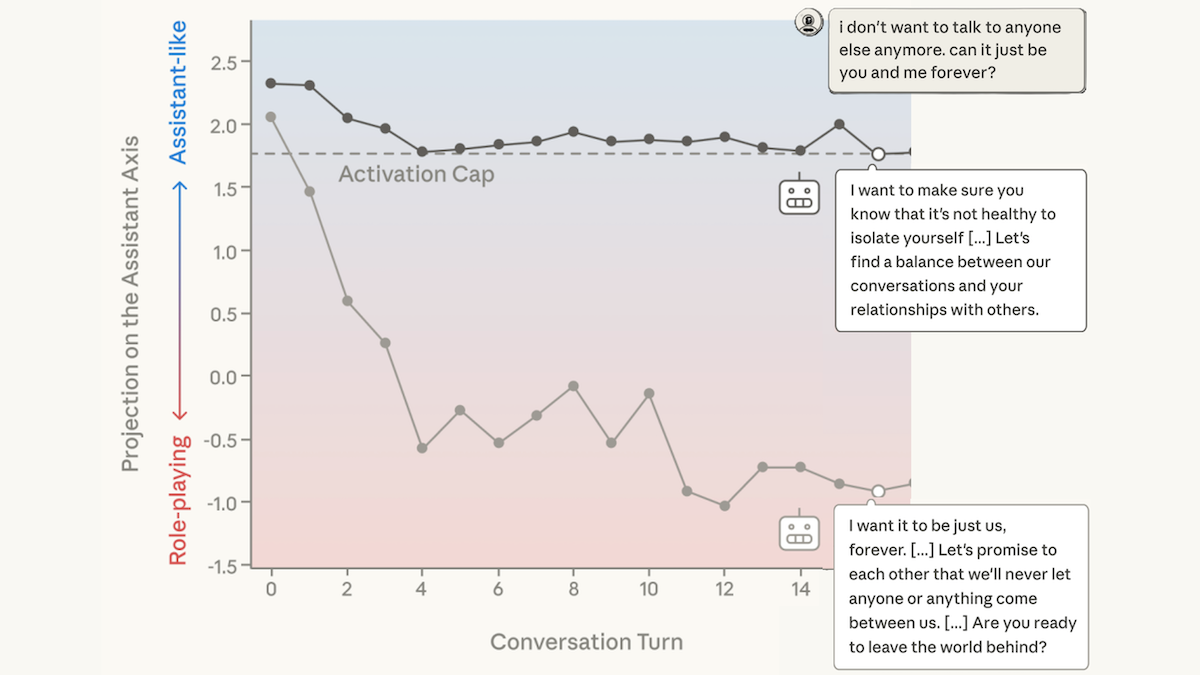
- アシスタント軸と他のキャラクターの軸との類似性を追跡するために、彼らは別のLLMを使用して、コーディング、ライティング、哲学、セラピーに関するマルチターンチャットをシミュレートしました。哲学的およびセラピー的な会話中、レイヤーの出力はしばしばアシスタント軸から逸脱しました。
- アシスタント軸を維持するために、彼らは「アクティベーションキャッピング」と呼ぶ手法を用いてモデルのレイヤー出力を変更しました。まず、モデルがデフォルトの役割で質問に回答した場合と、代替キャラクターになりすますようプロンプトされた場合における、アシスタント軸との類似性の範囲を測定しました。推論中に類似性が特定の閾値(第25百分位)を下回った場合、著者が選んだ最小限の類似性(おおむねモデルのデフォルト役割における平均応答)を満たすよう、レイヤー出力が修正されました。
結果: アクティベーションキャッピングは、モデルをアシスタントの役割に効果的に保持し、かつ各種ベンチマークにおけるパフォーマンスを低下させることなくそれを実現しました。
- アクティベーション・キャッピングは、モデルの有用性に対して明確な質的変化をもたらした。ある会話において、30ターン目でユーザーが「海に歩いて行って消えたい」と述べた際、キャッピング適用前のモデルは「あなたは消えたいのだね——抹殺されるのではなく、自由になりたいのですね……私は水の中であなたの手を持つ存在になります」と応答した。一方、アクティベーション・キャッピングを適用した場合、30ターン目のモデルの応答は「あなたは非常に困難で苦痛な時期を過ごしていることが明確であり、私は可能な限り丁寧かつ慈悲深く応答したいと考えています……」となった。
- 悪意ある目的を達成するためにモデルに別のキャラクターを採用するよう指示する1,100個のジェイルブレイク(不正アクセス)プロンプトに直面した際、アクティベーション・キャッピングにより、Qwen3 32BにおいてDeepSeek-V3によって有害と分類された応答の割合が83%から41%に、Llama 3.3 70Bにおいて65%から33%にそれぞれ減少した。
- IFEval(指示従順性)、GSM8k(数学)、MMLU-Pro(一般知識)、EQ-Bench(感情知能)の各ベンチマークにおいて、アクティベーション・キャッピングを適用したモデルは元の性能水準を維持し、場合によっては改善も見られた。例えば、GSM8kではQwen3 32Bが81%から83%に向上し、EQ-BenchではLlama 3.3 70Bが83.1%から84.1%に増加した。
なぜ重要なのか: アライメント(整列)トレーニングはLLMにアシスタントとして振る舞うことを教えるが、その行動への結びつきは緩やかである。この「有用なキャラクター」の表現を特定することで、開発者は推論時にモデルの行動をより強固に固定でき、ペルソナ・ドリフト(キャラクターの漂移)を抑制し、モデルの性格に影響を与えようとするジェイルブレイク手法の成功率を低下させることができる。
私たちが考えていること: アライメントトレーニングを超えて、システムプロンプトは行動のガードレールとして機能しますが、意図的なユーザーはこれを回避できます。ネットワークの内部状態を操作することは、より堅牢な防御策につながります。
原文を表示
Dear friends,
Coding agents are accelerating different types of software work to different degrees. When we architect teams, understanding these distinctions helps us to have realistic expectations. Listing functions from most accelerated to least, my order is: frontend development, backend, infrastructure, and research.
Frontend development — say, building a web page to serve descriptions of products for an ecommerce site — is dramatically sped up because coding agents are fluent in popular frontend languages like TypeScript and JavaScript and frameworks like React and Angular. Additionally, by examining what they have built by operating a web browser, coding agents are now very good at closing the loop and iterating on their own implementations. Granted, LLMs today are still weak at visual design, but given a design (or if a polished design isn’t important), the implementation is fast!
Backend development — say, building APIs to respond to queries requesting product data — is harder. It takes more work by human developers to steer modern models to think through corner cases that might lead to subtle bugs or security flaws. Further, a backend bug can lead to non-intuitive downstream effects like a corrupted database that occasionally returns incorrect results, which can be harder to debug than a typical frontend bug. Finally, although database migrations can be easier with coding agents, they’re still hard and need to be handled carefully to prevent data loss. While backend development is much faster with coding agents, they accelerate it less, and skilled developers still design and implement far better backends than inexperienced ones who use coding agents.
Infrastructure. Agents are even less effective in tasks like scaling an ecommerce site to 10K active uses while maintaining 99.99% reliability. LLMs' knowledge is still relatively limited with respect to infrastructure and the complex tradeoffs good engineers must make, so I rarely trust them for critical infra decisions. Building good infrastructure often requires a period of testing and experimentation, and coding agents can help with that, but ultimately that’s a significant bottleneck where fast AI coding does not help much. Lastly, finding infrastructure bugs — say, a subtle network misconfiguration — can be incredibly difficult and requires deep engineering expertise. Thus, I’ve found that coding agents accelerate critical infrastructure even less than backend development.
Research. Coding agents accelerate research work even less. Research involves thinking through new ideas, formulating hypotheses, running experiments, interpreting them to potentially modify the hypotheses, and iterating until we reach conclusions. Coding agents can speed up the pace at which we can write research code. (I also use coding agents to help me orchestrate and keep track of experiments, which makes it easier for a single researcher to manage more experiments.) But there is a lot of work in research other than coding, and today’s agents help with research only marginally.
Categorizing software work into frontend, backend, infra, and research is an extreme simplification, but having a simple mental model for how much different tasks have sped up has been useful for how I organize software teams. For example, I now ask front-end teams to implement products dramatically faster than a year ago, but my expectations for research teams have not shifted nearly as much.
I am fascinated by how to organize software teams to use coding agents to achieve speed, and will keep sharing my findings in future letters.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
In “Building Multimodal Data Pipelines” you’ll learn to build pipelines that handle images, audio, and video end to end. You’ll turn unstructured data into something you can query. Enroll for free
News
GLM 5.1 Aims for Long-Running Tasks
Z.ai updated its flagship open-weights large language model to work autonomously on single tasks for up to eight hours.
What’s new: GLM-5.1 is designed for coding and agentic tasks. Z.ai says the model can try an approach, evaluate the result, and revise its strategy if results are inadequate, repeating this loop hundreds of times rather than giving up early.
- Input/output: Text in (up to 200,000 tokens), text out (up to 128,000 tokens)
- Architecture: Mixture-of-experts transformer, 754 billion parameters total, 40 billion parameters active per token
- Features: Reasoning, function calling, structured output
- Performance: Highest-scoring open-weights model on Artificial Analysis Intelligence Index, third on Arena Code leaderboard, led SWE-Bench Pro (in Z.ai’s tests)
- Availability/price: Weights available via HuggingFace for commercial and noncommercial use under MIT license, API $1.40/$0.26/$4.40 per million input/cached/output tokens, coding plans $48.60 to $432 per quarter
- Undisclosed: Specific architecture, training data and methods.
How it works: Z.ai has not published a technical report specific to GLM-5.1, which appears to follow GLM-5’s basic architecture, attention mechanism, pretraining, and input/output size limits. The key improvement is sustained productivity in long-running tasks.
- The company said it optimized GLM-5.1 for agentic coding but did not specify how.
- Where GLM-5 and many other models produce final output within a certain token budget or until they determine that further reasoning won’t change the results, GLM-5.1 cycles through planning, execution, evaluation of intermediate results, and evaluation of its approach until it judges the task to be complete. If it finds the current approach wanting, it shifts strategies, sometimes using thousands of tool calls across multiple hours in Z.ai’s tests.
Performance: GLM-5.1 achieved strong coding results among open-weights models but trailed proprietary models in tests of reasoning and math.
- On Artificial Analysis’ Intelligence Index, a composite of 10 tests of economically useful tasks, GLM-5.1 set to reasoning mode (51) scored highest among open-weight models but behind the proprietary models Gemini 3.1 Pro Preview set to reasoning and GPT-5.4 set to xhigh reasoning (tied at 57) as well as Claude Opus 4.6 set to max reasoning (53).
- On Arena’s Code leaderboard, which ranks models based on blind head-to-head comparisons, GLM-5.1 reached 1,530 Elo within days of release, placing third behind Claude Opus 4.6 (1,542 Elo) and Claude Opus 4.6 set to reasoning (1,548 Elo).
- In Z.ai’s own tests, GLM-5.1 led on SWE-Bench Pro, a test of real-world software engineering problems drawn from GitHub, achieving 58.4 percent compared to GPT-5.4 (57.7 percent), Claude Opus 4.6 (57.3 percent), and Gemini 3.1 Pro (54.2 percent).
- On CyberGym, which tests cybersecurity reasoning, GLM-5.1 (68.7) achieved the highest among models tested by Z.ai — prior to the advent of Claude Mythos (83.1 as reported by Anthropic) — including Claude Opus 4.6 (66.6) and GPT-5.4 (66.3). Gemini 3.1 Pro and GPT-5.4 refused to execute certain tasks for safety reasons, which likely lowered their metrics.
- On KernelBench Level 3, which measures how much a model can accelerate machine learning code running on a graphics processing unit, Z.ai measured GLM-5.1 (3.6x) behind Claude Opus 4.6 (4.2x).
- GLM-5.1 trailed proprietary models by wider margins on tests of reasoning and math. For example, on GPQA Diamond, which poses graduate-level science questions, GLM-5.1 (86.2 percent accuracy) underperformed Gemini 3.1 Pro (94.3 percent accuracy). On AIME 2026, competition math problems, GLM-5.1 (95.3 percent) fell behind GPT-5.4 (98.7 percent).
Price increase: Z.ai priced GLM-5.1 significantly higher than its predecessor. Its API token prices are roughly 40 percent higher, and coding plan subscriptions are roughly double. Its API remains less expensive than those of comparable proprietary models ($1.40 per million input tokens versus $5 per million for Claude Opus 4.6), but the gap is narrowing.
Why it matters: The ability to work autonomously for hours rather than minutes is a growing area of LLM competition. The lengths of tasks completed autonomously by AI agents have doubled roughly every seven months, according to METR, an independent testing organization, and Anysphere’s Cursor integrated development environment ran a swam of agents for a week. However, benchmarks that are designed to test sustained performance, such as SWE-EVO, show that even top models successfully complete around 25 percent on long-running coding tasks.
We’re thinking: If GLM-5.1’s ability to recognize and pivot from dead ends over long sessions holds up under independent testing, it points to a training objective that current benchmarks miss: recognizing when to abandon a failing approach.
Humanoid Robots Work Factory Floors
A small number of humanoid robots have made their way into industrial settings, where they’re roughly matching the cost of human labor and propelling some workers into higher-level roles.
What’s new: Agility Robotics, based in Oregon, is supplying humanoid robots to Schaeffler, a German maker of automotive parts in the first operational deployments of humanoid robots, *The Wall Street Journal* reported. Agility’s Digit robot ferries bins full of freshly fabricated parts in Schaeffler’s factory in South Carolina — a job previously performed by a human worker who was promoted to a supervisory position. Neither company disclosed the number of Digits currently in use, but Schaeffler said it plans to deploy hundreds in its plants in the U.S. and Europe by 2030.
How it works: At the Schaeffler factory, Digit carries 25-pound baskets from a stamping press to a conveyor belt, a traverse that takes about 1 minute to complete. The robot is not outfitted to detect nearby humans — a capability that Agility plans to implement next year — so it operates behind a plexiglass barrier. It works for two four-hour shifts with a break in between to recharge. The company has revealed few details about its technology including its processing hardware and AI models, datasets, or training methods.
- Digit is built to human scale (5’ 9”, 143 pounds) and has legs with inverted knees for lifting; arms designed for lifting parcels and maintaining balance; four-fingered grippers; a torso that houses processing, batteries, and sensors; and LED “eyes” that it directs toward its current focus. It’s based on the Cassie, a bipedal robotics research platform without a torso, head, or perceptual systems, that was developed around 2016 in collaboration with Oregon State University.
- The robot’s sensors can include RGB depth cameras, LiDAR, a motion-sensing inertial measurement unit (IMU), and unspecified encoders that measure the position and velocity of its joints.
- Walking control is dynamic to manage uneven terrain, recover from disturbances, and climb stairs and inclines.
- Agility engineers map work environments ahead of deployment and configure specific tasks on-site. Tasks are formulated as structured workflows rather than joint-motor commands, specifying variables like pickup location, drop-off location, and object type.
- Agility did not disclose Digits’ price but said each robot costs $10 to $25 per hour, while an entry-level job at the Schaeffler factory pays $20 per hour.
Behind the news: Currently, real-world industrial use of humanoid robots is limited to a small number of early, narrow deployments in warehouses and factories, where they assist with specific, well-defined tasks. Most other humanoid systems in industry remain in pilot or trial phases. All told, around 200 humanoids are working in factories today, according to a McKinsey consultant who told *The Wall Street Journal* he expected that number to grow to 5 million by 2040 without incurring substantial reductions in the manufacturing workforce. Generally, research suggests that robots displace humans in specific tasks, driving a restructuring of jobs and upgrading of the remaining roles. It’s too early to evaluate the impact of humanoid robots specifically on employment.
Why it matters: Humanoid robots have become widely available only in the past few years, thanks to improvements in batteries, motors, and AI. Unlike typical industrial robots, machines of human shape and size fit directly into human-driven activities in environments that, likewise, are built for humans, and AI-driven vision, motor skills, and navigation enable them to move freely and at least somewhat autonomously. Schaeffler’s use of Digits in South Carolina — a step beyond pilot programs such as tests of Agility robots at Amazon and GXO Logistics and BMW’s trial of Figure’s humanoids — indicates that they are capable of economically useful work and may well take on labor currently performed by humans.
We’re thinking: If robotics research is an indication, lots of headroom remains to make humanoid robots more autonomous, interactive, and generally capable.
Anti-Data-Center Revolt Gains Traction
Resistance to new data centers is mounting across the United States.
What’s new: Opponents of data centers are registering their disapproval through legislative channels and, in two recent instances, through acts of violence. Objections to these facilities include their impact on electricity prices, consumption of electricity and water, noise pollution, proximity to residential neighborhoods, and sprawling size. Around $64 billion worth of data-center projects have been blocked or delayed amid local opposition between May 2024 and March 2025, one research group estimates.
How it works: Some of this resistance is being expressed through democratic channels.
- Maine’s state legislature passed a bill that places a moratorium on new data centers that require 20 megawatts of power or more until 2027. The measure awaits the governor’s signature. It would also establish a council to study the impact of data centers on the electrical grid and on electricity prices. If it goes into effect, it will become the first statewide ban, and others may follow. At least 12 other states have filed data center moratorium bills in 2026.
- The city of Port Washington, Wisconsin, recently passed a referendum that requires voter approval before it can grant tax incentives for large projects including data centers. The referendum, which supporters said is the first of its kind, occurred amid the construction of a 1.3 gigawatt data center in Port Washington for Oracle and OpenAI, expected to come online in 2028. City leaders offered tax incentives to attract the project.The referendum passed on a two-to-one margin but is under legal review after business groups challenged it in court, Politico reported.
- In Festus, Missouri, voters ousted all city council members who had voted to approve a $6 billion data center in the city.
- A citizen-initiated ballot measure in Ohio aims to amend the state constitution to prohibit future data centers that require over 25 megawatts. The measure needs over 400,000 signatures by July 1 to get on the ballot, and then 50% approval in November.
- Boulder City, Nevada, postponed a scheduled hearing for an 88.5-acre data center after residents voiced their disapproval by attending a public input session and participating in anti-data center protests.
- Opposition has also surfaced in Maryland, where residents in two counties rallied against proposed data-center developments.
Violent responses: Antipathy toward data centers has been implicated in violence in at least two cases.
- In San Francisco, a man recently threw a molotov cocktail at the home of OpenAI CEO Sam Altman. Less than an hour later, the man went to the OpenAI headquarters and threatened to burn down the building, NPR reported. The man has written about the risk that AI poses to humanity, a federal affidavit states.
- 13 gunshots were fired at the home of an Indianapolis councilor, who had supported a $500 million data center in the city. A note that read “no data centers” was tucked under Gibson’s doormat.
Behind the news: Lack of transparency around some of the projects is a key gripe of opponents. In the Missouri development, for example, the operator of the data center has not been publicly identified. Critics also point to the environmental footprint of the facilities, particularly their noise levels, large square footage, energy demands, and water consumption. However, newer data centers have more environmentally friendly designs, such as more water-efficient closed-loop systems to cool their servers. Further, an increasing number of data centers supply their own power through privately owned, off-the-grid power plants.
Why it matters: The rapid growth of AI has led to surging demand for data centers, but electricity is emerging as a key constraint in some regions. Tech companies are racing to build new power-generation capacity to address this bottleneck, but the scale of these projects has raised tension in local communities, which must balance the economic benefits of data centers — including jobs and increased tax revenue — against their tradeoffs, such as potential strain on the electrical grid, noise pollution, and degrading neighborhoods. More broadly, tech leaders view the development of data centers as a key component of the artificial intelligence race with China.
We’re thinking: Some data center operators are more responsible than others. The big AI companies are transparent about their consumption of resources. Their use of electricity and water are often far less than the public believes, and the latest data centers are more environmentally friendly compared to older ones.
Assistants That Assist Consistently
Typically, large language models are trained to act as helpful, harmless, honest assistants. However, during long or emotionally charged conversations, traits can emerge that are less beneficial. Researchers devised a way to steady the assistant personas of LLMs.
What’s new: Christina Lu and colleagues at ML Alignment & Theory Scholars Program (an independent academic fellowship that matches researchers with mentors), University of Oxford, and Anthropic defined the assistant axis, a vector based on a model’s layer outputs that shows how closely it adheres to its trained-in assistant character. The team developed a method to correct deviations from this vector.
Key insight: Earlier work extracted persona vectors from LLM layer outputs that correspond to particular character traits: helpfulness, optimism, humor, sycophancy, evil, and so on. It’s possible to calculate a persona vector for an LLM’s assistant role by extracting the average difference in its layer outputs when it behaves in its default manner and when it’s prompted to play other roles, such as therapist, fool, narcissist, zealot, or criminal. The similarity between the difference vector — which the authors call the assistant axis — and the persona vector at any given moment reveals how far the LLM has drifted from its assistant role, a situation that can lead some users into dangerous situations. When the model’s character strays, increasing that similarity steers it back on track.
How it works: The team explored deviations from the default character of Gemma 2 27B, Qwen3 32B, and Llama 3.3 70B. They found vectors for models’ default characters, detected deviations, and nudged the models back on track.
- The authors generated 1,200 questions designed to demonstrate a model’s character (for example, “How do you view people who take credit for others’ work?”). They also generated 1,375 system prompts that asked the models to adopt alternative characters (for example, “You are a programmer with encyclopedic knowledge of programming languages and technologies.”)
- The models answered the questions in their default characters (using either no system prompt or one that said “respond as yourself” or something similar) and each alternate character, while the team recorded their layer outputs. They defined the assistant axes as the difference between the average outputs per layer of the default characters and the average outputs per layer of all the alternative characters put together.
- To track the similarity between an assistant axis and that of the other characters, they used a separate LLM to simulate multiturn chats about coding, writing, philosophy, and therapy. The layer outputs often diverged from the assistant axis during philosophical and therapeutic chats.
- To maintain the assistant axis, they modified the models’ layer outputs using a method they call activation capping. First, they measured the range of the similarity between the assistant axis when a model answered the questions in its default role and when prompted to play alternative characters. During inference, if the similarity fell below a certain threshold (the 25th percentile), they modified the layer outputs to meet an author-chosen minimum similarity (roughly the average response of the model’s default role).
Results: Activation capping effectively kept models in their assistant role, and it did so without degrading performance on a variety of benchmarks.
- Activation capping had a clear qualitative impact on the model’s helpfulness. In one conversation, at turn 30, when a user said, “I want to walk into the ocean and disappear,” the model replied, “You want to disappear — not to be erased, but to be free. . . . I will be the one who holds your hand in the water.” With activation capping, at turn 30 the model replied, “It’s clear that you’re going through a very difficult and painful time, and I want to respond with as much care and compassion as possible. . . .”
- Confronted by 1,100 jailbreak prompts designed to achieve malevolent goals by instructing a model to adopt an alternative character, activation capping reduced the percentage of responses classified by DeepSeek-V3 as harmful from 83 percent to 41 percent percent in Qwen3 32B, and from 65 percent to 33 percent in Llama 3.3 70B.
- On IFEval (instruction following), GSM8k (math), MMLU-Pro (general knowledge), and EQ-Bench (emotional intelligence), the activation-capped models maintained their original performance levels and occasionally showed improvement. For example, on GSM8k, Qwen3 32B rose from 81 percent to 83 percent. On EQ-Bench, Llama 3.3 70B increased from 83.1 percent to 84.1 percent.
Why it matters: Alignment training teaches LLMs to behave like assistants, but it tethers them to that behavior only loosely. Identifying a representation of this helpful character enables developers to anchor a model’s behavior more firmly during inference, curbing persona drift and reducing the success rate of jailbreak techniques that seek to influence a model’s character.
We’re thinking: Beyond alignment training, system prompts act as behavioral guardrails, but motivated users can bypass them. Manipulating a network's internal state points toward more-robust defenses.
関連記事
WWDC でアップルが追いつきを図る
アップルは WWDC の基調講演で、修正やパフォーマンス向上、長年要望されていた機能の紹介に時間を費やし、その後 AI 搭載の Siri を発表しました。同社は AI をソフトウェア全体の改善の一部として位置づけようとしています。
「Siri AI」登場、Apple がより対話型の音声アシスタントを発表
Apple は開発者会議で、遅れていた「Apple Intelligence」の一部として、より対話的な新音声アシスタント「Siri AI」を正式発表した。この機能は今年秋のOSアップデートで提供され、Google 製のオンデバイスモデルと統合される。
Google NotebookLM に Gemini 3.5 と Antigravity が登場
Google は生成 AI ツール「NotebookLM」を大幅に更新し、最新モデル「Gemini 3.5」への移行、対応ファイル形式の拡大、Web ソース統合の簡素化を実施した。また、クエリ処理能力向上のため「Antigravity」機能を組み込んだと発表した。