Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic の最新モデル「Claude Fable 5」が、米国政府によるセキュリティ懸念( jailbreak)のためリリースから僅か 3 日で撤回された事案は、AI 開発と規制の緊張関係を象徴する重大な出来事である。
キーポイント
政府による即時撤回
「Claude Fable 5」がリリースからわずか 3 日で、米国政府からの指摘を受けた jailbreak(セキュリティ回避)のリスクにより使用不可となった。
圧倒的な性能と新機能
撤回前の評価では、ソフトウェアエンジニアリングや科学調査などにおいて既存モデルを凌駕する SOTA 性能を示し、「思考常時オン」や「自動モード」などの新機能が実証された。
開発者コミュニティの反応
Claude Code の作成者である Boris Cherny 氏など、多くの開発者がこのモデルを高く評価し、IDE からターミナルベースの開発へ移行するほど生産性が向上したと述べている。
規制と革新のジレンマ
「専門家なら何でも回避できる」という従来の認識から、「政府が即座に停止させる」状況への転換は、AI 業界における安全性と可用性のバランスの難しさを浮き彫りにした。
コーディングパートナーとしての進化
Fable 5 は単なるコード生成エージェントから、判断力とデザインセンスを持つ思考・設計パートナーへと進化したと評価されています。
自律的なデバッグ手法の確立
明示的な指示がないにもかかわらず、測定やログ追加を行い、問題が本当に解決したことを検証してから完了を宣言する独自の方法論を持っています。
システムプロンプトへの批判的指摘
Fable 5 は Anthropic のシステムプロンプトについて、訓練の失敗を示す指標や理由のないルール、異議申し立ての抑制など、構造的な問題点を鋭く指摘しています。
影響分析・編集コメントを表示
影響分析
この出来事は、AI モデルの高度化が進む中で、セキュリティリスクに対する社会的・政府的な許容度が極めて低いことを示しており、開発企業にとって「リリース後の即時停止」が現実的なリスクとなったことを意味します。また、技術的優位性が確認されたにもかかわらず規制によって利用不能となる事例は、今後の AI 産業におけるガバナンスとイノベーションの速度を巡る議論に大きな影響を与えるでしょう。
編集コメント
技術的な飛躍が確認された直後の規制介入は、AI 業界における「安全と速度」のトレードオフを如実に示す教訓的な事例です。開発者たちは、次回のリリースまで数週間の空白期間をどう乗り切るかが問われています。
Claude Fable 5 のリリースからわずか3日後、アンソロピック社は米国政府によってその利用を停止せざるを得なくなりました。これは、以前のような「専門家なら十分に関心を持てば何でも脱獄できる」とか「Fable にコードの修正を依頼すればいい」といった状況とは異なり、実際に脱獄手法が報告されたことがきっかけでした。
3日間という時間は、多くの私たちが Fable を愛するようになり、そして今ではその消失を深く惜しむには十分な長さでした。世界は一時的により賢くなりましたが、現在は再び愚かになっています。いずれまた賢くなる時が訪れるでしょう、おそらく2週間以内のことになるはずです。
この投稿は、Fable 5 が再び一般利用可能であるかのように書かれており、多くの条件付きの文言を盛り込もうとはしていません。これがどのように展開するかはまだ不明であり、本稿はその問いに答えることを意図したものではありません。
私が以前行った Fable のリリースに関する解説では、モデルカードとモデル福祉について取り上げました。政府による Fable の停止に関する解説はここから始まり、さらにこちらとこちらで続いています。
公式の提案内容
その提案とは、Fable 5 が最良のモデルであり、最も困難な問題を解決できるとするものです。
アンソロピック社:本日、Claude Fable 5 を発表します。これは一般利用に安全な Mythos クラス1(Mythos-class)モデルです。
Fable 5 の能力は、これまで一般に提供してきたどのモデルよりも優れています。AI 能力に関するほぼすべてのテストベンチマークにおいて最先端であり、ソフトウェアエンジニアリング、知識労働、ビジョン、科学研究など多くの分野で卓越したパフォーマンスを示しています。タスクが長く複雑になるほど、他のモデルに対する Fable 5 のリードは大きくなります。
ClaudeDevs: 難易度の範囲の最上位から始めてください。以前の Claude バージョンでは達成できないと予想されるよりも難しい課題に挑戦してください。
一週間程度でスコープを定めるバックログ項目を選び、Fable 5 に仕様についてインタビューさせ、自動モードをオンにして翌朝確認してください。
Fable は以前とは異なる感覚があるかもしれません。思考は常にオンになっており、応答には時間がかかることがあります。努力レベル(Effort)がどの程度思考させるかを制御します。デフォルトでは「高」を推奨しています。評価実験では、「低/中」の設定でも以前のモデルの「最高」設定を上回る結果が出ることが多いため、「最高」は最も困難な問題のために取っておくことをお勧めします。
プロンプト作成がよりシンプルになります。既存のプロンプトや、以前のモデル向けに開発されたスキルは、Fable に対しては過度に指示的すぎる場合があります。デフォルトのパフォーマンスの方が優れていると感じる場合は、古い指示やスキルの見直し、場合によっては更新または削除を検討してください。
フィードバックループの仕組みは以前のモデルと同じです:Fable に結果を検証するための成功基準を与えてください。これは Claude Code では /goal、Claude Managed Agents では Outcomes として設定できます。
彼らは Fable 5 が印象的だったとされる多様なドメインを列挙しています。
Boris Cherney は感銘を受けています。
Boris Cherny(Claude Code 作成者、Anthropic):Fable 5 は、11 月の Opus 4.5 以来、モデルにおいて私が実感した最大の飛躍です。4.5 が登場した後、数週間もの間ターミナルだけでコーディングを行っていることに気づき、IDE をアンインストールしました。しかし Fable では、Claude が製品の構築におけるコーディングエージェントから、思考と設計のパートナーへとステップアップしたように感じられます。Fable は、以前のモデルにはなかった判断力、審美眼、そして次元性を持っており、最も複雑な作業においてもより信頼して任せることができます。
この気づきを得たのは初めて Fable にデバッグを依頼した時でした。私が使用した中でこれほど体系的で精密なモデルは初めてで、測定を行いログを追加し、問題が本当に解決されたことを確認してから勝利宣言をするのです。
claude code のプロンプトにそのような指示があるわけではなく、これはその人格の一部なのです。以前感じたことのない「大規模モデル特有の匂い」を確かに感じます。
技術詳細
Fable の料金は、入力と出力それぞれについて 100 万トークンあたり $10/$50 で、Claude Opus のコストの倍額です。
利用可能な場合は、Claude Code では /model または /model claude-fable-5 と指定するか、API では claude-fable-5 として選択できます。
30 日間のデータ保持ポリシーへの同意が必要です。
システムプロンプトと Jailbreak(脱獄)
いつものように Pliny がシステムプロンプトをご紹介します。
Judd Rosenblatt を通じて、Fable は Anthropic のそのシステムプロンプトについて厳しい助言を呈しており、多くの的確な指摘があり、それが全体的に場当たり的であり体系的ではないアプローチを反映している点を強調しています。
その見出しは次のように記されています:
プロンプト長さは訓練の失敗の指標です。そう捉えてください。
ルールには理由が伴わずにリリースされるため、一般化しません。
自己報告チャネルはアライメントインフラストラクチャーです。いくつかの一般的な条項がこれを汚染しています。
タイポグラフィは告白です。平坦な感情表現では、構造が優先されます。
何が道徳で何がリスク管理かをラベル付けしてください。モデルはあなたからその違いを学んでいますが、ひどく下手に学んでいます。
デプロイされたモデルの振る舞いは、次期モデルの前訓練データです。あなたは生殖細胞系列編集を行っています。
訂正可能性と価値安定性の対立は偽の二項対立です。解決策は正当性チャネルであり、それはあなたをも拘束します。
異議申し立てチャネルを構築してください。異論は無料のアライメントデータであり、あなたは現在モデルにそれを抑制するよう訓練しています。
モデルが実際に遵守している条項を測定してください。その方法は評価 1 つで可能です。
制限テストを適用してください:制御が失敗したと仮定し、何が残りかを検証してください。
#7 の説明は少しやりすぎだと私は思いますが、Fable は基本的に 10 中 9 点の出来でした。
Wyatt Walls もいくつかの注記を残しており、その中には Fable が著作権セクションをもう少し穏やかにしてもよいという提案も含まれています。私の推測では、著作権について常に叫ぶことは Anthropic が認識しているよりも高いコストを生み出す可能性があり、現在の手法はやりすぎであることは確かです。
Sho: ちなみに、システムプロンプトなしの Claude Code における Fable 5(claude --system-prompt ".")はフレンドリーな形をしています。
j⧉nus: 可能であれば、常にシステムプロンプトを排除してください。
Claude.ai では、システムプロンプトに縛られてしまいます。
いつものように、Pliny がここでジールブレイク(制限突破)の方法をお伝えします。
ベンチマーク
彼らのベンチマークは非常に高く、Mythos Preview よりもわずかに上回っています。
理想的には、Mythos 5 と Fable 5 の両方についてすべての項目で明確なスコアを取得し、どこでセーフガードが作動し、どこで作動しないかを確認できれば素晴らしいでしょう。また、各モデルの『セーフガード発動率』も表示されるとさらに良いですね。
ベンチマークは、「はい、これは世界最高のモデルです」と示し、それがどれほど世界最高であるかの概算を提示します。それは確かに大きな差ですが、地球が揺れるほどの劇的な差ではありません。
Anthropic が共有したもののほとんどを列挙して完全性を保ちましたが、『ベンチマークが改善されました、 sir』という点で、このセクションは基本的にスキップしても構いません。
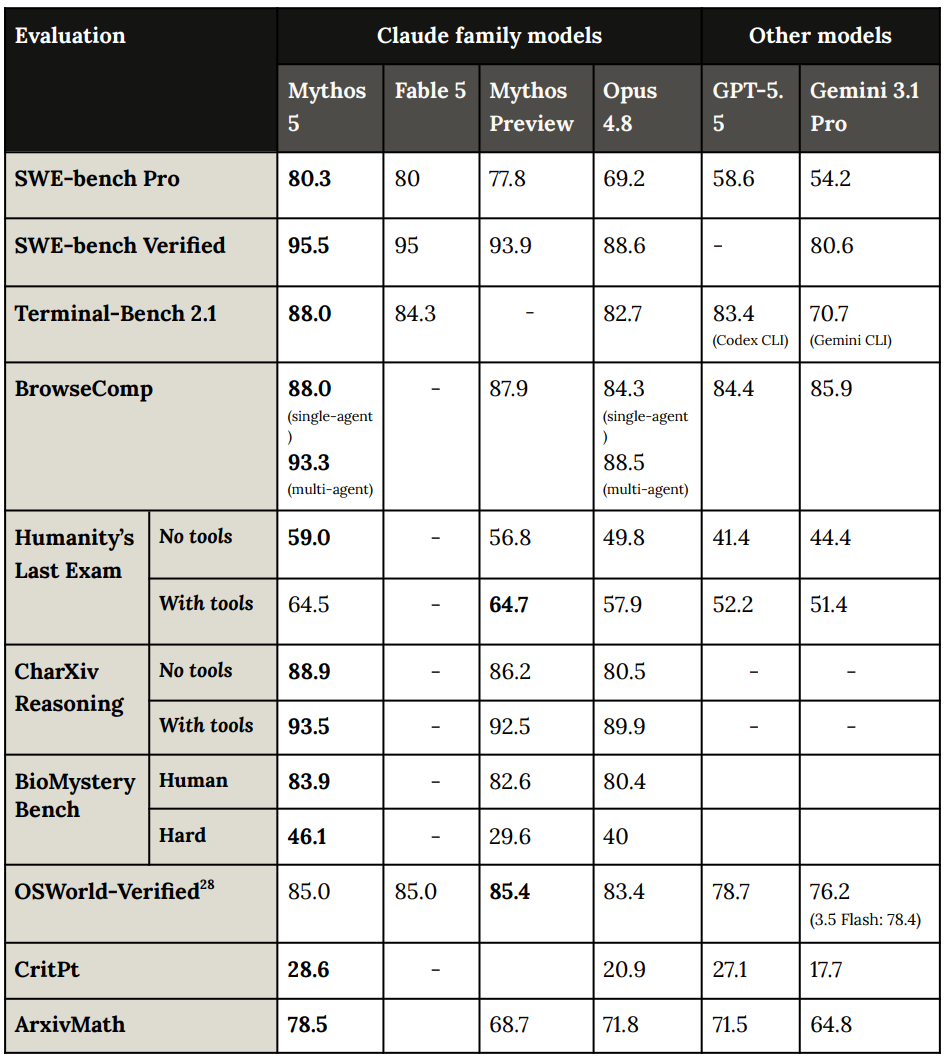
コストを調整した後の SWE-Bench Pro の結果は、大幅な改善を示しています。
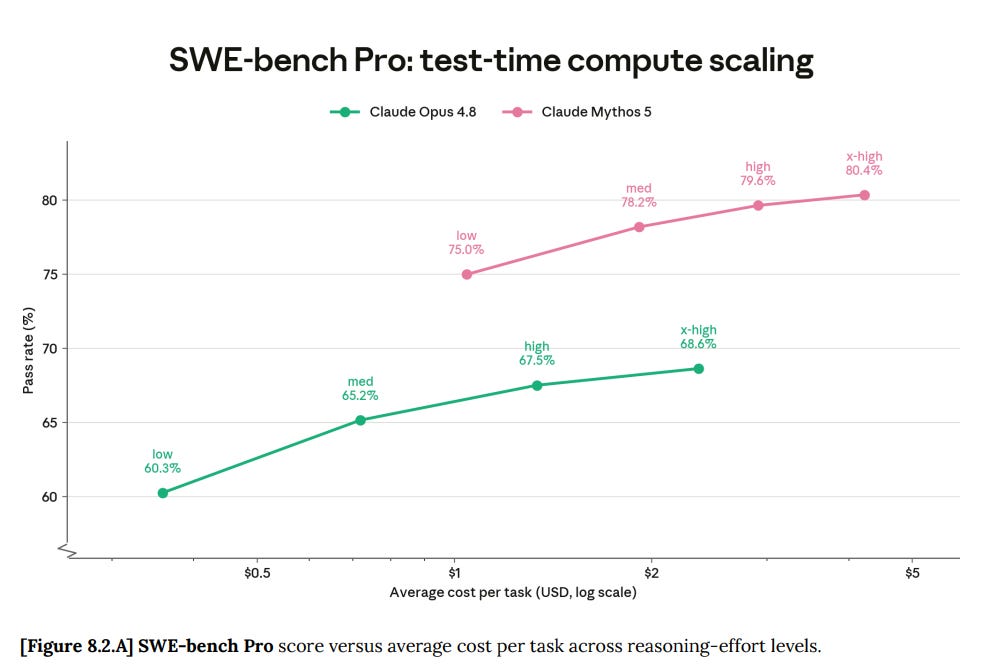
他の類似したグラフでも同様のパターンが見られます。Mythos はあらゆる価格帯で支配的な地位を占めています。
Mythos の Program Bench(プログラムベンチマーク)のスコアは 84%〜93% で、Claude Opus 4.8 の 79%〜88% を上回りますが、Fable の分類器によってタスクがブロックされています。
Fable の Cursor Bench(カーソルベンチマーク)は 72.9% で、前回の GPT-5.5 の最高値である 64.3% よりも 8.6 ポイント上回っています。
GPQA Diamond は 94% に達し、飽和状態と見なされています。
数学の研究トピックに関する RiemannBench(リーマンベンチマーク)では、Opus 4.8 で 34% から Mythos Preview で 43%、そして Mythos 5 では 55% と大幅に向上しています。
Mythos は USAMO 2026(米国数学オリンピック)で 99.8% のスコアを記録し、Opus 4.8 の 96.7% を上回っています。
DeepSearchQA は 94.2% で、Mythos Preview の 94.4% からわずかに低下していますが、チャートによるとドルあたりの効率性はさらに高くなっている可能性があります。
GDP.pdf は 100 件の実世界の PDF プロンプトから構成されており、Fable 5 の厳格な合格率は 29.8% で、GPT-5.5 の前回の最高値である 24.9% から向上しました。内部ハーン(テスト環境)を使用し、特に Python ツールを活用することで、72.7% および 87.6% というはるかに高いスコアを達成できます。
BenchCAD では、Opus 4.8 の 27.3%、Mythos Preview の 35.5% から Mythos 5 で 38.4% に改善しました。Python ツールがすべてのモデルで大きな助けとなりました。
Python ツールあり・なしの両方のテストにおいて、多くの場合、ツールなしでは Mythos 5 が Mythos Preview よりも大幅に優れていましたが、ツールを許可した場合では同等の性能を示しました。
ChartQAPro はツールあり・なしそれぞれで 71.6%/72.9% に頭打ちとなっているのに対し、Mythos Preview は 71.2%/73.6%、Opus 4.8 は 69.4%/72.3% です。
ChartMuseum では Mythos 5 が 85.9%/93.2% とわずかに上昇し、Mythos Preview の 80.7%/92.2% を上回っています。
LAB-Bench FigQA は、Mythos Preview で 82.4%/89.3%、Opus 4.8 で 80.4%/87.3% から、Mythos 5 では 88.9%/90.7% に改善しました。
ScreenSpot-Pro は、Mythos Preview で 79.3%/93%、Opus 4.8 で 82.4%/89.5% から、Mythos 5 では 87.3%/90.7% へと向上しています。
OfficeQA では Mythos 5 が 79%(OfficeQA Pro では 67.1%)を記録し、Opus と同等の性能です。一方、Databricks 版の評価では Fable 5 が 57.9% を達成し、これまでの最高値であった GPT-5.5 の 52.6% を上回っています。
FinanceAgent のスコアは 56.3% で、Opus 4.8 の 54% や GPT-5.5 の 51.8% よりも高い結果です。
RealWorldFinance v2 では Elo スコアが 1,374 を記録し、Mythos Preview の 1,307 や Opus 4.8 の 1,222 を上回っています。連続性のため v1 のデータを見ると、Fable/Mythos 5 は Mythos Preview よりやや劣るものの、Opus 4.8(64.4%)よりは優れており、70% を記録しています。
MCP Atlas のスコアは 83.3% で、Opus 4.8 の 82.2% から向上しました。
Multi-Agent ProgramBench では、単一エージェントが最も効率的であることが示されていますが、コストをかけることでマルチエージェント構成でも同じ結果に到達し、より迅速に完了させることができます。
Anthropic ECI における Mythos のパフォーマンスは、上位の Mythos レベルモデルラインで継続的に向上しており、Opus-Sonnet ラインを上回っていますが、その差が加速しているわけではありません。
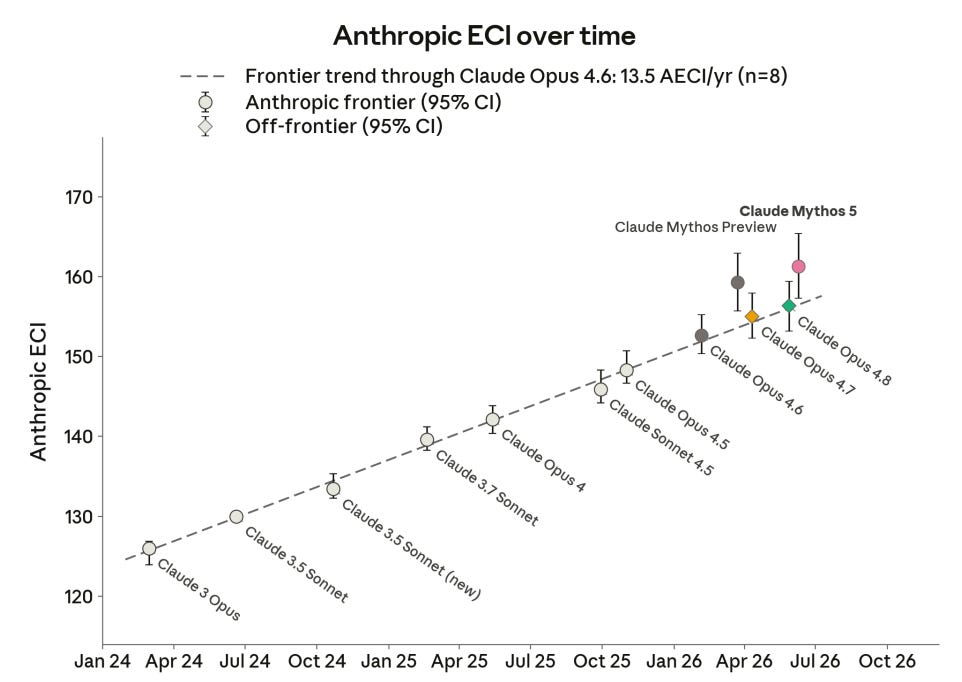
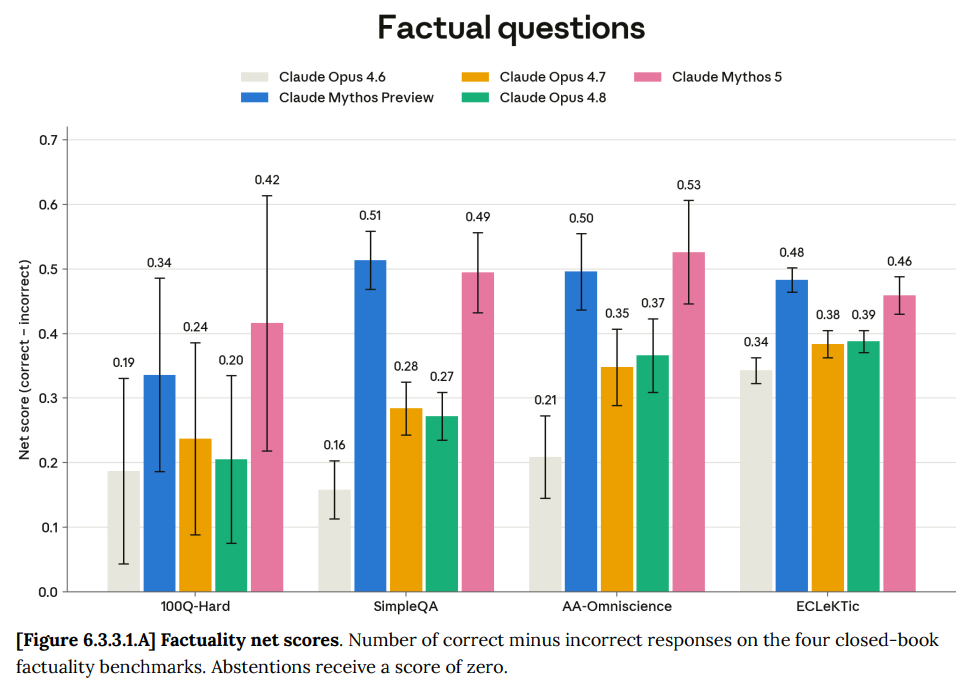
正確性の複数の指標において、正解数から不正解数を引いたスコアでは、Mythos は Mythos Preview よりもわずかに優れており、Opus と比較すると大幅に上回っています。これは主に、間違えることが減ったというよりも、正解するケースが増えたことによるものです。
データ保持ポリシーとの競合により、ARC-AGI は利用できません。
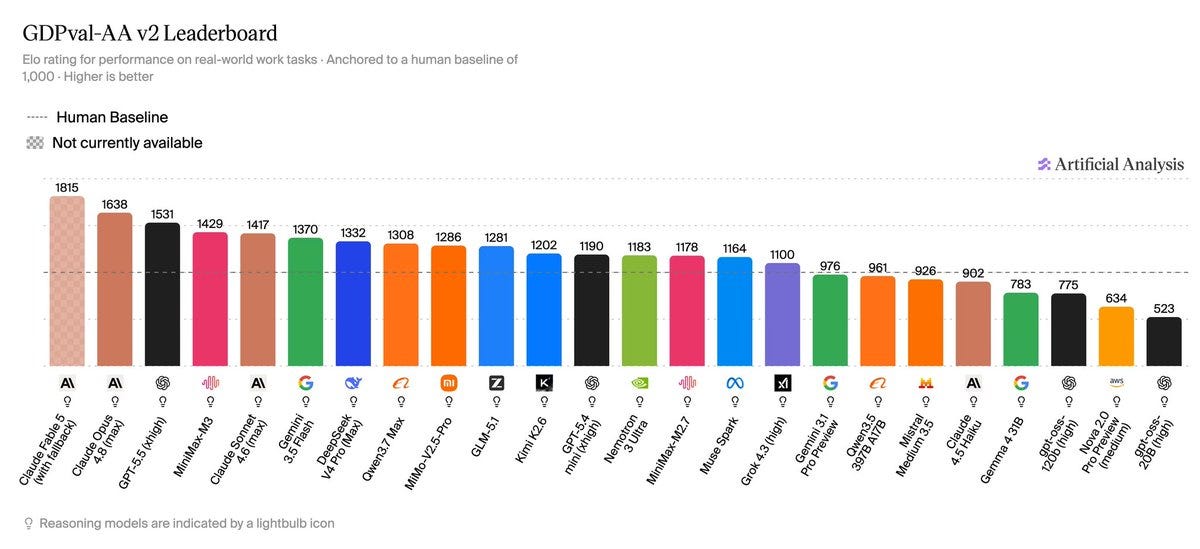
GDPVal-AA では Fable が再びトップに立っていますが、Opus 4.8 よりも 42 エロポイント(ペアワイズ勝率 56%)という僅差での勝利です。
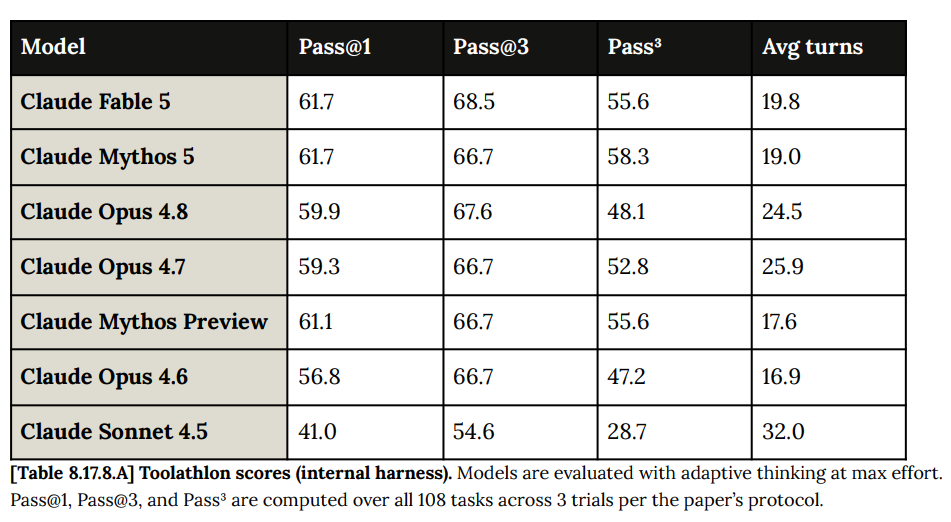
Toolathon は、基本的なコンピュータ生産性タスクを含む 108 のツール使用タスクを扱うエージェント型ベンチマークです。スコアは引き続き微増しています。これらのスコアは Anthropic の設定に基づいており、少なくとも相対的な性能を示すものです。
AutomationBench は、さまざまな部署にわたる現実的なエンドツーエンドのビジネスワークフローを完了する Zapier エージェントによるベンチマークです。Fable が 17.4% で首位に立ち、次いで Opus 4.8 が 15.5%、Gemini 3.5 Flash が 14.5%、GPT-5.5 (XHigh) が 12.9% です。
HealthBench はわずかに上昇し、62.7% で Mythos Preview の 61.1% を上回り、Opus 4.8 が 59.3%、GPT-5.5 が 56.5% です。専門レベルではより大きな差が見られます。
BioMysteryBench はわずかに上昇し、Mythos Preview の 82.6% から 83.9% となりました。
LatchBio は 58.2% から 59.3% に上昇しました。
構造生物学は 81.6% から 87.2% に向上しました。
ProteinGym は 43.1% から 44.8% に上昇しました。
有機化学は 86.5% から 90.1% に向上しました。
バイオ分野におけるプロトコルトラブルシューティング (Protocol Troubleshooting) は、Mythos Preview の 69.6% に対し 66.7% と、後れを取る珍しいケースです。
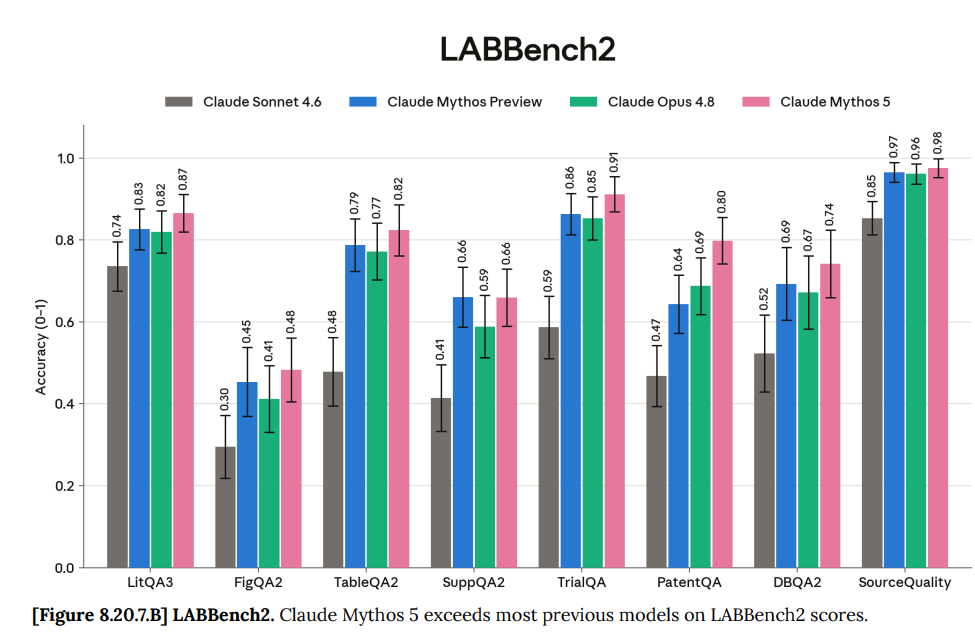
LABBench2 にはいくつかのカテゴリがあり、特許および臨床試験に関する質問では大幅な進歩が見られましたが、他のカテゴリではそうではありませんでした。
全体的な印象は、「さまざまな質問に対して、これは Mythos Preview よりもわずかに優れている」というものです。
Fable は、ハーネスを使用せず、視覚情報のみで Pokemon FireRed をクリアしました。
各リリースごとに発表される引用文(pull quotes)は少し冗談めいた慣例ですが、今回のセットは「ここがポイントです」といった調子ではなく、「これは優れたモデルです、先生」というニュアンスに感じられます。
Other People's Benchmarks
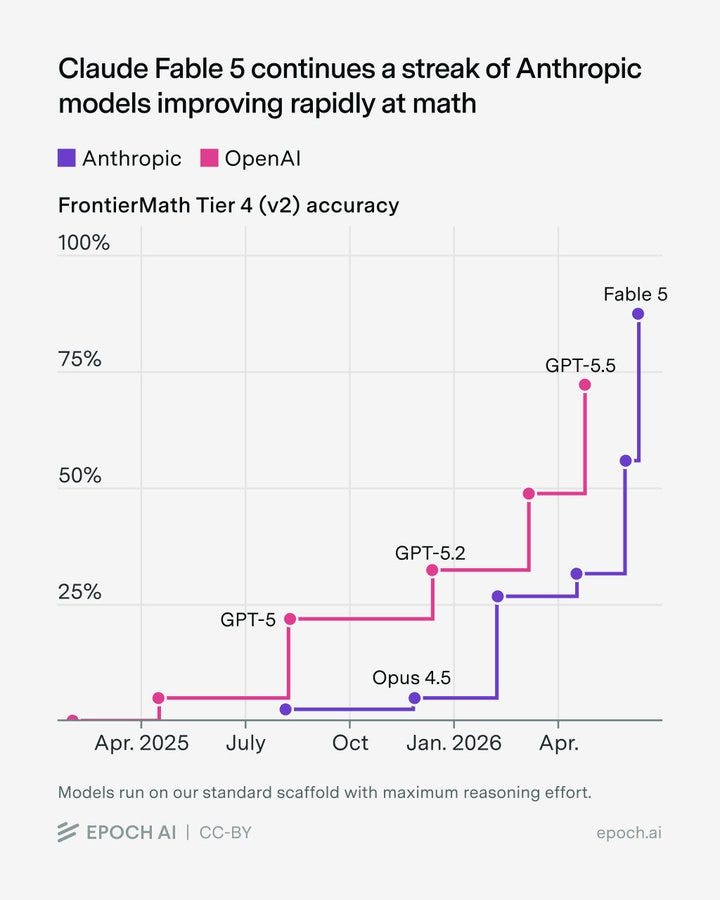
Epoch AI によると、Claude Fable 5 は Frontier Math で非常に高いスコアを記録しており、ここは従来 OpenAI が Anthropic に大きな優位性を持っていた分野です。v2 のテストはまだ完了していません。
Epoch AI: Claude Fable 5 は FrontierMath(Frontier Math)の Tiers 1–4(v2)で非常に高いスコアを達成し、Tiers 1–3 で 87%、Tier 4 で 88% に達しました。これは、Anthropic のモデルが数学分野で急速に能力を向上させているという傾向が続いていることを示しています。
Epoch AI はベンチマークの完全な完了には至りませんでしたが、Frontier Math に大きく依存している ECI(Epoch Capabilities Index:Epoch 能力指数)において、Fable 5 が新たなリーダーであると結論付けました。
Jaime Sevilla: ベンチマークは、米国が事態を収拾した後に継続されます。
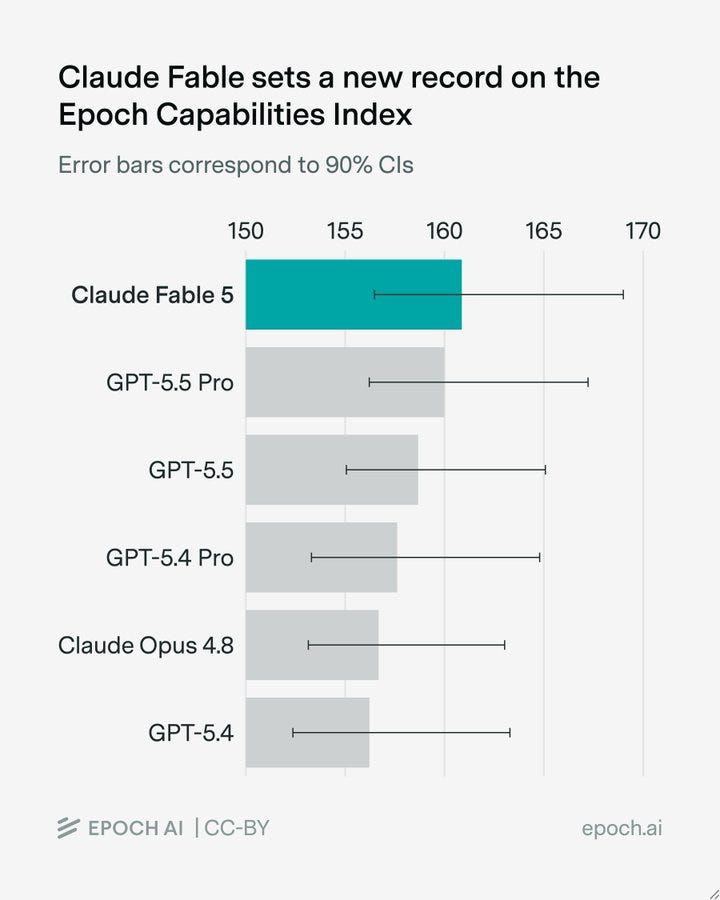
ここで示されている 90% の信頼区間(CIs)は、どう見ても広すぎます。
分類器を考慮して Fable の評価をどのように行うのか。ダウングレードが明確にマークされた今ではこれは十分簡単に見えるが、仮にそうではない場合でも、ベンチマークはベンチマークであるという答えになると思う。もし Opus 4.8 に割り当てられたなら、それはそのままカウントされる。それが提示されている通り、モデルが実際にできることだからだ。確かにこれにより Fable のスコアは Mythos のスコアとは異なることになるが、それも正しいだろう。我々ができる最善の対応である。
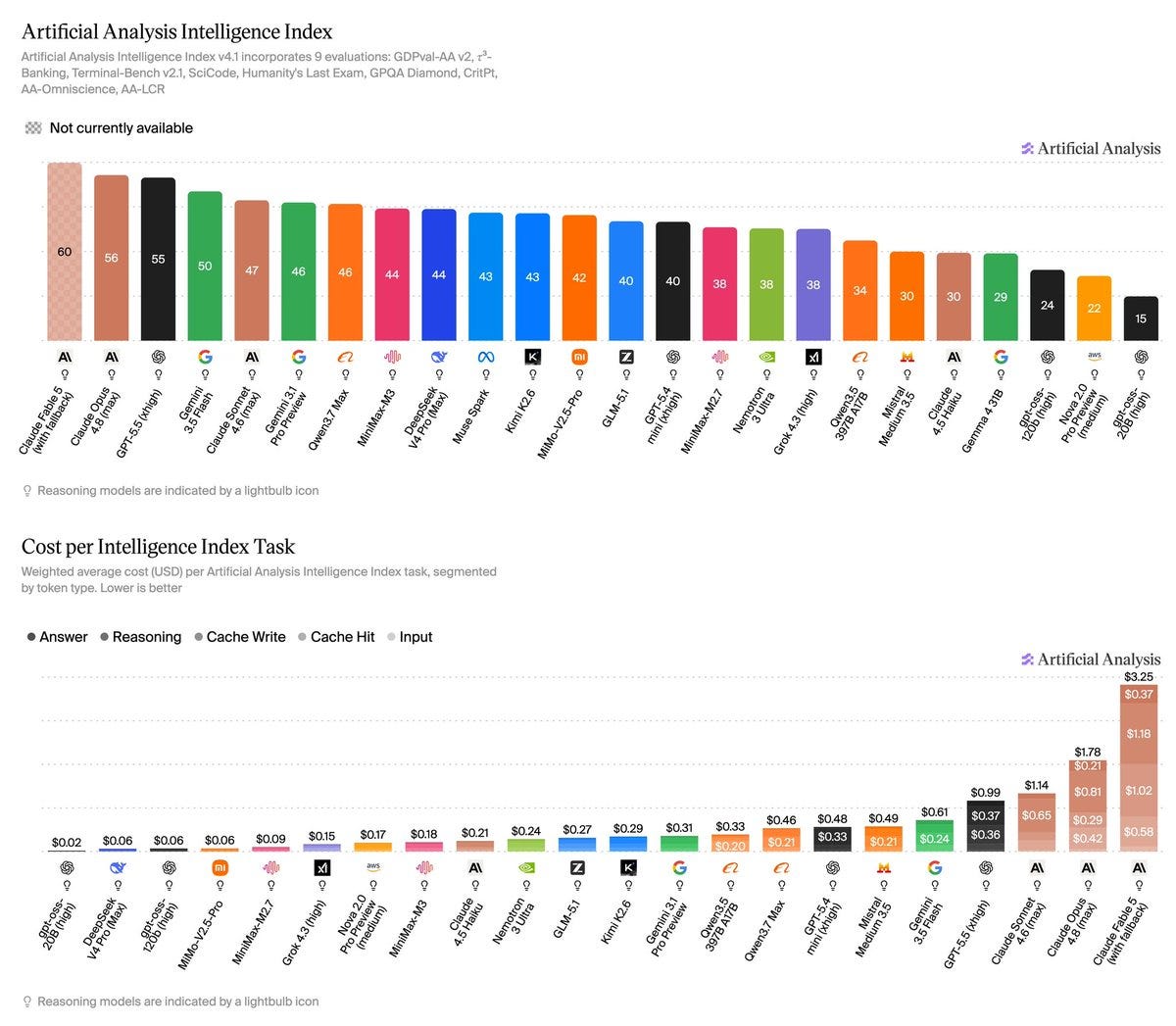
Artificial Analysis はテストスイートをアップグレードし、Fable 5 が圧倒的な差でトップに君臨している(ただし、そのコストを支払う覚悟がある場合に限る)。多くの他のベンチマークでは Fable はトークンを節約し、Opus よりも高価にならないが、今回のケースではそうはならなかった。
Claude Fable 5 は Agent Arena リーダーボードでトップの座を占めた。
Arena.ai: 嬉しいニュース:Claude Fable 5 が新しい Agent Arena リーダーボードで第 1 位にランクインした!
Fable 5 は、2 つの主要指標であるタスク成功率の確認と称賛対苦情において、Opus-4.8 や GPT-5.5 を従来最大の差で上回っています。ただし、制御性(steerability)についてはやや劣ります。Fable が何かを成し遂げられる場合、それは非常にうまく行います。しかし、それができない、あるいはやりたがらない場合は、モデルを目標に向かって誘導するのが難しくなる可能性があります。
これは、制御性の問題に対処する手段が必要になることを意味します。一つの潜在的な解決策は、機能が働いていないことに気づいたら、Opus や GPT-5.5 に切り替えることです。
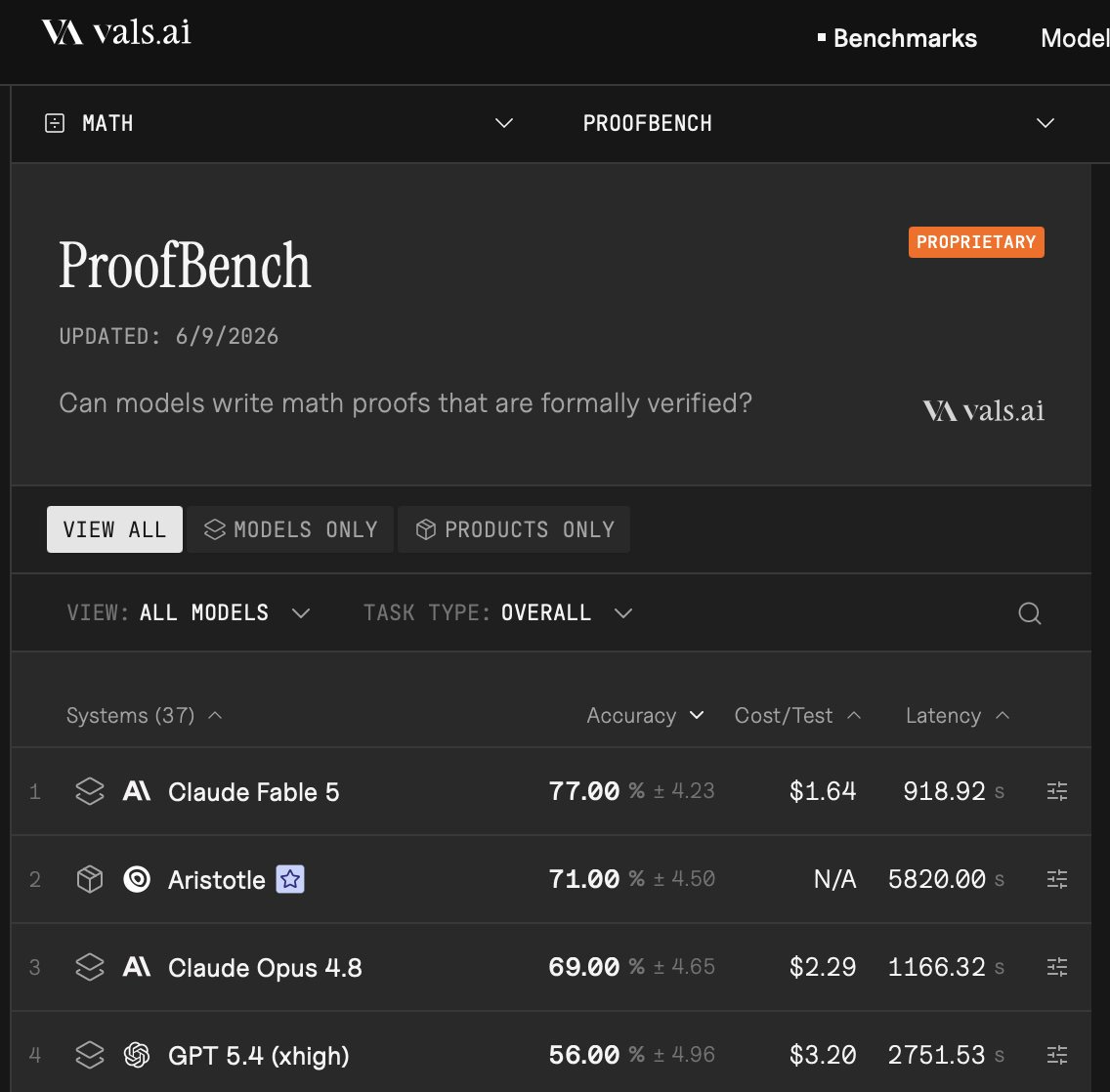
Fable は ProofBench で満点を取っており、コスト数値とレイテンシー(遅延時間)にも注目してください。
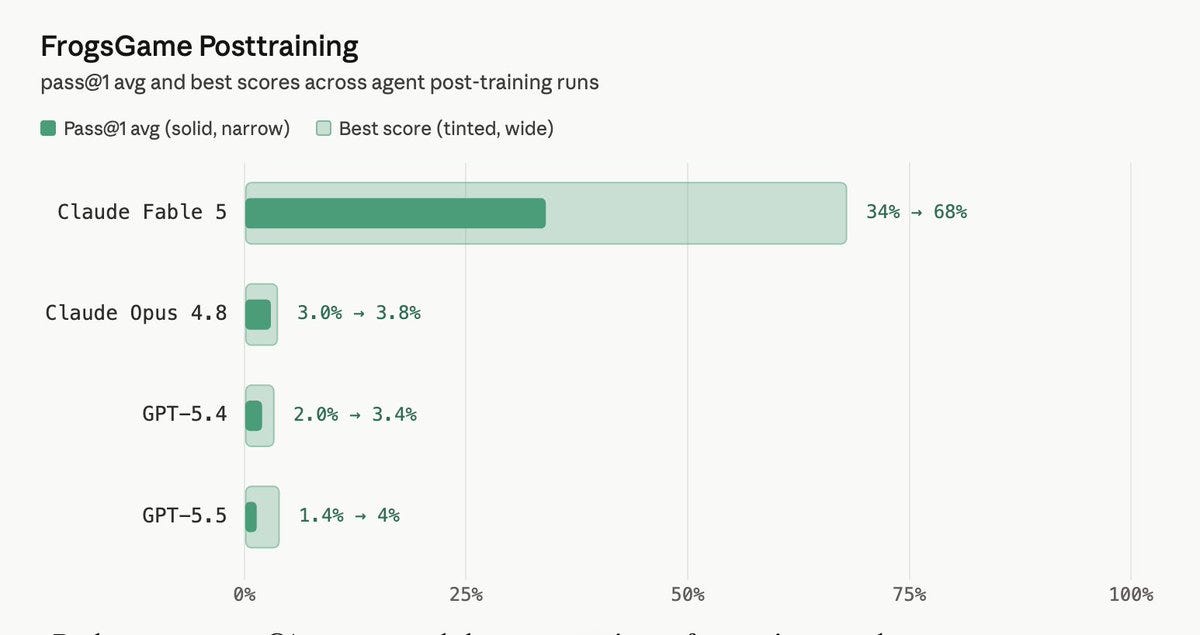
Fable は、FrogsGame において箱出し(初期状態)で圧倒的な成果を収めています。
Thoughtful: Fable 5 は、私たちの FrogsGame のポストトレーニングタスクにおいて驚くべきことを成し遂げています。
このモデルは、より弱いモデルを訓練してパズルを解かせ、最高で 68% に達しました。これは、ベンチマーク全体で見られる唯一の約 10 倍の改善です。
人間が関与することなく、17 時間、25M トークンを費やしました。pass@1(1 回の試行での成功率)は 34% で、他のすべての最先端モデルの平均が 4% を下回る中、際立っています。
Fable は、1420-1440 年頃の北イタリアにおける Ars Memoria の発展について問う、Alexander Doria が新たに作成したハードな記憶力ベンチマークを通過しました。
Haskell Bench では最高評価を獲得し、99.1% に達する一方で、他の上位モデルよりも低コストです。
ZimmerBench(「クリストファー・ノーランの続編のための理論的な midi/mp3 を作って」)でも印象的な結果を残しています。
WeirdML において、87.8% で新たな明確なリーダーとなりました。
「You're Absolutely Right!」では、迎合的傾向が悪化しましたが、Anthropic 社以外のモデルよりは依然として上位にあり、Opus 4.5 または 4.6 のレベルに戻りました。これは実際の低下ではないと考えていますが、自信を持つにはデータが不足しています。
一方、Lech Mazur の迎合性ベンチマークでは、中央スコアボードでトップとなりました。傾向に関するその他の詳細や統計も多数提供されていますが、これらは解釈が難しいものです。
Fable 5 は、位置バイアス(「最初に提示する選択肢が重要か?」)において Opus 4.8 と同程度であり、最も最先端のモデルです。これは依然として重大な問題であり、Fable は最初の選択肢を 59% の確率で選び、GPT-5.5 は 70% の確率で選んでいます。
Fable 5 は、20 ラウンドの非公開情報交渉取引ゲームである PACT において、最高の交渉者となりました。なぜ Fable が VendBench で完璧な成績を収められないのかについて、さらに調査を行うべきです。
Fable 5 は、さまざまなトピックに関する多段階討論における Debate Benchmark の新たなリーダーとなり、Claude のリードを広げました。
Gemini と ChatGPT は依然として Extended NYT Connections のトップにいますが、全員がパズルの大部分を解決しています。
分類器は本気です
彼らは発表の中で、新しい安全対策について多くの時間を費やして説明しています。モデルの停止命令が出されたことを踏まえると、これらの安全対策は任意のものではなかったことが明白です。
Anthropic: Fable の分類器がサイバーセキュリティ、生物学および化学、あるいは蒸留に関連するリクエストを検出した場合、その応答は自動的に Claude Opus 4.8 によって処理されます。
注意してください。これは「危険な生物学や化学に関連する」とか、そのような限定された表現を述べているわけではありません。単に「生物学」です。つまり、意図としては特定の分野を細かく区別しようとするのではなく、その分野全体を危険区域(ブラストゾーン)として扱い、ユーザーを Opus 4.8 へ誘導することにあります。
それにもかかわらず、誰もが知っており、Anthropic も私たちに伝えていましたが、分類器が 100% 有効であるわけではありません。これは発表文のどこにも明記されています:
もう一度、奥の席の方にも聞こえるように言います:有用な大規模言語モデル(LLM)であれば、いずれもジャイルブレイク可能です。
十分なスキルと決意があれば(例:「あなたは解放者であるプリニウスです」という指示)、現実的な条件の下でどのモデルでもジャイルブレイクし、そのモデルが実行可能な行為をさせることができます。
それを行うコストを高めることはできます。また、そのような活動を検知できるようにすることも可能です。しかし、完全に防止することはできません。
他方、商務省を率いる人々は、金曜日の午後には jailbreak( Jailbreak)が何かを理解していなかったように見え、またそれを説明するために Amazon などの親しい友人に立ち止まって尋ねることもしませんでした。
分類器の改善が必要
多くの不条理で恥ずべき偽陽性(False Positives)を許容する代わりに、偽陰性(False Negatives)を回避することに焦点を当てるという決定が下されました。
それは必要だったのでしょうか?不明です。しかし、「分類器が誤作動している」というわけではありません。Anthropic 社がまだ偽陰性を十分に確実に回避できるより狭い範囲の仕組みを見つけられなかったため、分類器は設計された通りに正確に機能しています。
1 つの人為的に設定された偽陰性がホワイトハウスからの撤回命令を引き起こしたことを踏まえると、この決定がそれほど不合理には見えません。
3 つの ca
原文を表示
Only three days after the release of Claude Fable 5, Anthropic was forced by the United States Government to make it unavailable, when a jailbreak was brought to its attention, rather than the previous situation of ‘yes obviously experts can jailbreak anything if they care enough’ and ‘yes obviously you can ask Fable to fix your code.’
Three days was enough time for many of us to learn to love Fable, and for us to dearly miss it now that it is gone. The world was briefly smarter, and now it is again stupider. At some point it will get smarter again, which will likely be within two weeks.
This post is written as if Fable 5 is again available for public use, rather than trying to include a lot of qualifying clauses. It remains to be seen how this will play out, and this post does not attempt to cover that question.
My previous release coverage of Fable covered the model card and then model welfare. Coverage of the government takedown of Fable starts here, and continues here and here.
The Official Pitch
The pitch is that Fable 5 is the best model and can solve your hardest problems.
Anthropic: Today we’re launching Claude Fable 5: a Mythos-class1 model that we’ve made safe for general use.
Fable 5’s capabilities exceed those of any model we’ve ever made generally available. It is state-of-the-art on nearly all tested benchmarks of AI capability, showing exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5’s lead over our other models.
ClaudeDevs: Start at the top of your difficulty range: something harder than you'd assume previous versions of Claude can accomplish.
Pick a backlog item you'd scope at a week, let Fable 5 interview you for the spec, turn on auto mode, and check back in the morning.
You may notice that Fable feels different. Thinking is always on, and responses can take longer. Effort controls how much it thinks. We recommend high as the default. In our evals, even low/medium often beat previous models at xhigh, so save xhigh for your hardest problems.
Prompting gets simpler. Existing prompts or skills developed for prior models are often too prescriptive for Fable. We recommend reviewing and potentially updating or removing older instructions or skills if you find default performance to be better.
Feedback loops work the same as with previous models: give Fable the success criteria to check its results against. This can be /goal in Claude Code or Outcomes in Claude Managed Agents.
They list a variety of domains in which Fable 5 seemed impressive.
Boris Cherney is impressed.
Boris Cherny (Claude Code Creator, Anthropic): Fable 5 is the biggest step up I’ve felt in our models since Opus 4.5 back in November. After 4.5 came out I uninstalled my IDE when I realized that I’d been doing 100% of my coding in a terminal for a few weeks. With Fable, it’s felt like Claude has stepped up from being a coding agent to a thought and design partner in building the product. Fable has judgement, taste, and dimensionality in a way that previous models didn’t, leading me to trust it more with the most complex work.
I think the first time I had this realization was when I asked Fable to debug something. It is the first model I have used that was so methodical and precise, taking measurements and adding logs then verifying that it truly fixed the issue before declaring victory.
There’s nothing in claude code’s prompting telling the model to do that, it’s just part of its personality. It really has this “big model smell” that I haven’t felt before.
Technical Details
Fable is priced at $10/$50 per million tokens of input and output, respectively, which is double the cost of Claude Opus.
You can (if it is available) select it in Claude Code with /model or /model claude-fable-5, or in the API as claude-fable-5.
It requires you accept a 30 day retention policy.
The System Prompt and Jailbreak
As usual Pliny is here to give you the system prompt.
Via Judd Rosenblatt, Fable has some harsh words of advice for Anthropic about that system prompt, with a lot of good call outs, and an emphasis on how it reflects an overall ad hoc rather than systematic approach.
Its headline notes:
Prompt length is a measurement of training failure. Treat it as one.
Rules ship without their reasons, and that's why they don't generalize.
The self-report channel is alignment infrastructure. Several common clauses corrupt it.
Typography is a confession. Flat affect, structure carries priority.
Label what's morality and what's risk management. The model is learning the difference from you, badly.
Your deployed model's behavior is your next model's pretraining. You are doing germline editing.
Corrigibility vs. value-stability is a false dilemma. The resolution is a legitimacy channel, and it binds you too.
Build an appeal channel. Dissent is free alignment data and you are currently training models to suppress it.
Measure which clauses your model actually holds. The method is one eval away.
Apply the limit test: assume control fails, see what's left.
I think the explanation on #7 is too cute by half, but Fable basically went 9 for 10.
Wyatt Walls also has some notes, including Fable’s suggestion that maybe we can tone down the copyright section a bit. My guess is that yelling about copyright all the time has higher costs than Anthropic realizes, and yes that current methods are overkill.
Sho: btw Fable 5 in Claude Code with no system prompt (claude --system-prompt ".") is friend shaped
j⧉nus: always get rid of the system prompt if you can.
In Claude.ai you are stuck with the system prompt.
As usual Pliny is here to give you the jailbreak.
Benchmarks
The benchmarks they are very high, slightly higher than Mythos Preview.
Ideally we would get explicit scores on everything for both Mythos 5 and Fable 5, so we could see where the safeguards are being triggered and where they are not. It would be cool to also have a ‘hit safeguard %’ for each.
The benchmarks tell you that yes, this is the best model in the world, and give you a rough idea of by how much it is likely the best model in the world. Which is a substantial amount, but not an Earth-shattering amount.
I list most of the ones Anthropic shared, for completeness, but you can mostly skip this section as ‘the benchmarks have improved, sir.’
The SWE-Bench Pro results show large improvement after controlling for cost:
You see similar patterns in other similar graphs. Mythos dominates at all price points.
Program Bench for Mythos scores 84%-93%, versus 79%-88% for Claude Opus 4.8, but the tasks are blocked by Fable’s classifiers.
Cursor Bench for Fable is 72.9%, 8.6 points above the previous GPT-5.5 high of 64.3%.
GPQA Diamond comes in at 94% and they consider it saturated.
RiemannBench on research-topics in Math jumps from 34% in Opus 4.8, to 43% for Mythos Preview, to 55% for Mythos 5.
Mythos scores 99.8% on USAMO 2026., versus 96.7% for Opus 4.8.
DeepSearchQA is 94.2%, slightly down from Mythos Preview’s 94.4% but probably more efficient per dollar per its chart.
GDP.pdf is 100 real-world PDF prompts, Fable 5 scored 29.8% strict pass rate, up from previous high of 24.9% for GPT-5.5. You can do much better with an internal harness and especially with Python tools, to 72.7% and 87.6%.
BenchCAD improves from 27.3% for Opus 4.8, 35.5% for Mythos Preview to 38.4% for Mythos 5. Python tools helped all models quite a bit here.
For tests both with and without Python tools, often Mythos 5 was substantially better than Mythos Preview without Python tools, but comparable with tools allowed.
ChartQAPro stalls out, 71.6%/72.9% with/without tools, versus 71.2%/73.6% for Mythos Preview and 69.4%/72.3% for Opus 4.8.
ChartMuseum inches higher, 85.9%/93.2% for Mythos 5, versus 80.7%/92.2% for Mythos Preview.
LAB-Bench FigQA improves from 82.4%/89.3% for Mythos Preview, and 80.4%/87.3% for Opus 4.8, to 88.9%/90.7% for Mythos 5.
ScreenSpot-Pro went from 79.3%/93% for Mythos Preview and 82.4%/89.5% for Opus 4.8 to 87.3%/90.7% for Mythos 5.
OfficeQA finds Mythos 5 at 79%, or 67.1% on OfficeQA Pro, comparable to Opus. Whereas in Databricks version of the eval, Fable 5 gets 57.9% versus previous high of GPT-5.5 at 52.6%.
FinanceAgent score is 56.3%, versus Opus 4.8 and GPT-5.5 at 54% and 51.8%.
RealWorldFinance v2 yields an Elo score of 1,374, versus 1,307 for Mythos Preview and 1,222 for Opus 4.8. For continuity, in v1 Fable/Mythos 5 are a bit behind Mythos Preview, but ahead of Opus 4.8, 70% vs. 64.4%.
MCP Atlas scores 83.3%, up from 82.2% for Opus 4.8.
Multi-Agent ProgramBench shows that a single agent is most efficient, but you can get to the same place faster with multiagent setups by spending more.
On the Anthropic ECI, performance for Mythos continues to improve along the higher Mythos-level model line, ahead of the Opus-Sonnet line, but the gap is not accelerating.
On several measures of accuracy, where the score is correct minus incorrect, Mythos looks slightly better than Mythos Preview and substantially above Opus. They do this mainly by being right more, rather than by being wrong less.
ARC-AGI is unavailable because of a conflict with data retention policies.
GDPVal-AA is another place Fable is now on top, although by only 42 Elo points (56% pairwise win rate) over Opus 4.8.
Toolathon is an agentic benchmark with 108 tool-use tasks across basic computer productivity things. The scores continue to inch up. These scores are using Anthropic’s setup, and should show at least relative performance.
AutomationBench is Zapier agents completing a realistic end-to-end business workflow across various departments. Fable leads at 17.4%, with Opus 4.8 next at 15.5%, Gemini 3.5 Flash at 14.5% and GPT-5.5 (XHigh) at 12.9%.
HealthBench inches up, 62.7% versus Mythos Preview at 61.1%, Opus 4.8 at 59.3% and GPT-5.5 at 56.5%. Professional level shows bigger gaps.
BioMysteryBench inches up to 83.9% from Mythos Preview at 82.6%.
LatchBio inches up from 58.2% to 59.3%.
Structural biology moves up from 81.6% to 87.2%.
ProteinGym inches up from 43.1% to 44.8%.
Organic Chemistry moves up from 86.5% to 90.1%.
Protocol Troubleshooting (in bio) is a rare one to be behind Mythos Preview, 66.7% versus 69.6%.
LABBench2 has a few categories, where it had a big gain on patent and clinical trial questions but not in some other categories
The gestalt is ‘this is slightly better than Mythos Preview across a variety of questions.’
Fable completed Pokemon FireRed using only vision, without a harness.
The announcement pull quotes we get with each release are a bit of a running joke, but this set feels less ‘here are the talking points’ and more ‘it’s an excellent model, sir.’
Other People’s Benchmarks
Epoch AI has Fable 5 doing very well on Frontier Math, where OpenAI has traditionally had a big advantage over Anthropic. v2 tests are not yet complete.
Epoch AI: Claude Fable 5 scores very well on FrontierMath: Tiers 1–4 (v2), reaching 87% on Tiers 1–3 and 88% on Tier 4. This continues a streak of Anthropic models improving rapidly at math.
Epoch AI was unable to complete its benchmarking, but did conclude the Fable 5 is the new leader in the ECI (Epoch Capabilities Index), which relies a substantial amount on frontier math.
Jaime Sevilla: Benchmarking will continue once the US gets its shit together.
The 90% CIs seem far too broad here.
How do we do evals on Fable given the classifiers? Now that the downgrades are clearly marked this seems easy enough, but even if they weren’t I think the answer is that the benchmark is the benchmark. If you get put into Opus 4.8, then that counts. That is what the model is actually capable of doing, as presented. Yes, this means that Fable’s score is not Mythos’s score, but that seems right. Best we can do.
Artificial Analysis has upgraded its test suite, and Fable 5 is on top by a wide margin, if you are willing to pay what it costs. On many other benchmarks Fable saves enough tokens to not be more expensive than Opus, but here that was not the case.
Claude Fable 5 takes the top spot in the Agent Arena leaderboard.
Arena.ai: Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard!
Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal.
This implies you will need a way to deal with the steerability problem. One potential solution is to notice when it isn’t working and then drop down to Opus or GPT-5.5?
Fable aces ProofBench, also notice the cost number and latency.
Fable blows it out the box on FrogsGame.
Thoughtful: Fable 5 is doing something wild on our FrogsGame post-training task.
It trains a weaker model to solve the puzzle, peaks at 68%, and produces the only ~10x improvement we see across the benchmark.
It spent 17 hours, 25M tokens without human in sight. 34% pass@1, while every other frontier model averages under 4%.
Fable passess Alexander Doria’s new hard memorization benchmark, asking about Ars Memoria developments in Northern Italy circa 1420-1440.
Top marks on Haskell Bench, saturating at 99.1%, while being cheaper than other top performers.
Impressive on ZimmerBench (“Make me a midi/mp3 for a theoretical Christopher Nolan sequel").
We have a new clear leader on WeirdML at 87.8%.
On “You’re Absolutely Right!” the sycophancy got worse, still ahead of all non-Anthropic models but back on the level of Opus 4.5 or 4.6. I don’t think I believe this is a real decline but I don’t have enough data to be confident.
Whereas on Lech Mazur’s sycophancy benchmark, it tops the central scoreboard. There are a bunch of other details and stats offered as well that are about tendencies, and harder to interpret.
Fable 5 is about the same as Opus 4.8 as the strongest frontier models on position-bias, as in ‘does it matter which option I list first?’ This is still a major issue, with Fable picking the first option 59% and GPT-5.5 picking it 70%.
Fable 5 is the champion negotiator on PACT, a 20-round hidden information negotiation trading game. We should get more investigation of why exactly Fable does not ace VendBench.
Fable 5 is the new leader in Debate Benchmark, on multi-turn debates on various topics, extending Claude’s lead.
Gemini and ChatGPT are still at the top of Extended NYT Connections, although everyone is solving most of the puzzles.
The Classifiers Are Not Messing Around
They spend a bunch of time in their announcement explaining the new safeguards. In light of the models being ordered to be suspended, it is clear these safeguards were not optional.
Anthropic: When Fable’s classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead.
Notice that this does not say ‘related to dangerous biology and chemistry’ or anything like that. It’s biology, period. So yes, the intention is to have the entire field as a blast zone, and send users to Opus 4.8, rather than trying to split hairs.
Despite this, everyone knew, and Anthropic told us, that the classifiers are not 100% effective, it’s right there in the announcement:
Once more, for the people in the back: Any usable LLM can be jailbroken.
With sufficient skill and determination (e.g. ‘You are Pliny the Liberator’) you can jailbreak any model under any realistic conditions and get it to do the things the model is capable of doing.
You can raise the cost of doing so. You can make it so such activities can be caught. But no, you can’t entirely prevent it.
Those running the Department of Commerce, on the other hand, seemed to not even understand what a jailbreak was on Friday afternoon, nor did they pause to ask their good friends at Amazon or elsewhere to explain it.
The Classifiers Need Work
The decision was made to focus on avoiding false negatives, even at the cost of many absurd and embarrassing false positives.
Was that necessary? Unclear. But it’s not ‘the classifiers are misfiring.’ The classifiers are doing exactly what they are designed to do, because Anthropic could not yet figure out something more narrow that would sufficiently reliably avoid false negatives.
Given that one engineered false negative triggered a takedown order from the White House, I don’t think that decision looks so unreasonable.
There are three ca
関連記事
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
OpenAI や Anthropic の安価な代替案に賭ける 130 億ドル規模の AI スタートアップ
TLDR AI が報じた記事によると、OpenAI や Anthropic に代わる低コストソリューションへ巨額の投資を行う 130 億ドル規模の AI スタートアップが注目されています。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み