LLM の説明可能性に関するやさしい入門ガイド
本記事は、LLM のブラックボックス性を解明し、静的ベンチマークの限界を克服するための動的評価と統計的解釈可能性(XAI)の重要性について解説している。
キーポイント
静的評価から動的評価への移行必要性
従来の公開ベンチマークはモデルがテスト結果を暗記する傾向を生んでおり、専門家が設定した新規シナリオに基づく動的・多次元評価フレームワークの導入が急務である。
XAI の本質:正誤判定から「なぜ」への焦点
LLM 説明可能性(XAI)は単に回答が正しいか間違っているかを判断するだけでなく、モデルがその結論に至った理由や内部ロジックを理解することに主眼を置いている。
統計的モデル非依存型解釈手法の活用
SMILE(Statistical Model-Agnostic Interpretability with Local Explanations)などの最新フレームワークが、プロンプトの微細な変更が生み出す出力への影響を厳密な統計距離測定で分析する手法として紹介されている。
従来の評価基準の限界と動的評価の必要性
モデルの知能を測る従来の静的ベンチマークは、テスト結果の暗記に偏る傾向があり、真の推論能力を証明できなくなっているため、専門家が裏付けを行う動的な多角的評価フレームワークが求められています。
統計的アプローチによる局所説明(SMILE/gSMILE)
SMILEやgSMILEといったモデル非依存の手法は、プロンプトの微細な変更に対する影響を統計的な距離測定で分析し、入力内のどの単語が出力決定に最も寄与したかをヒートマップなどで可視化します。
コスト削減と実用的な観測性の確立
大規模クローズドモデルの解釈可能性を低コストで実現するために、オープンソースモデルをプロキシとして用いる手法が開発され、CometLLMなどのプラットフォームがデバッグやワークフローの再現性を担保する実用的な観測性(observability)を提供しています。
コミュニティハブの重要性
研究の爆発的な増加と無料ツールの登場に伴い、LLM XAI(説明可能性)のためのコミュニティ主導型ハブが不可欠となっています。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の実装における「ブラックボックス問題」に対する業界の認識転換を示唆しており、単なる性能評価から信頼性と透明性の確保へとパラダイムシフトが起きていることを示しています。特に、静的なベンチマークの限界を指摘し、統計的アプローチを用いた動的評価の重要性を説くことで、開発者や運用担当者がより堅牢な監視フレームワークを構築する指針となるでしょう。
編集コメント
LLM の信頼性を高めるためには、性能スコアだけでなく「なぜその回答が出たか」を説明する仕組みの構築が不可欠です。本記事で言及されている SMILE などの手法は、実務レベルでのモデル監査に役立つ有望なアプローチと言えます。
 image**
image**
# イントロダクション
AI 説明可能性(XAI: Explainable AI)は、過去数年にわたり実世界の AI システムの風景を支配しており、大規模言語モデル(LLM: Large Language Models)も例外ではありません。これらの非常に複雑で強力なモデルにおいて、ブラックボックスシステムがどのように自然言語出力を生成するかをよりよく理解するために、静的評価から動的評価への移行が不可欠となっています。さらに、産業界では、動的評価と堅牢な統計手法の統合、および観測性(Observability)のための手頃で本番環境対応可能なフレームワークの構築も、注目すべきトレンドとして台頭しています。
この記事では、LLM の説明可能性について議論し、これまでで最も洗練された AI システムの一つを測定・解釈・よりよく管理しようとするこの重要な研究分野における進展、トレンド、および進行中の開発事項を概説します。
LLM は全体として AI 分野に革命をもたらしましたが、その内部動作は依然としてほとんど不明瞭なままです。高リスク産業では、LLM の利用がますます増加しており、その応答に基づいて下される決定が大きな影響を及ぼす可能性のある複雑で専門的なモデルが導入されています。この文脈において、XAI、特に LLM の説明可能性は、これまで以上に重要性を増しています。
モデルの意思決定能力および「知能」は、従来、公開された静的ベンチマークを通じて測定されてきました。しかし、最近の研究では、従来の評価基準が崩壊しており、モデルの行動が真の推論能力を示すことではなく、公開テストを暗記する方向へシフトしていることが示唆されています。これにより、専門家が根拠となる新規シナリオに対してシステムを評価する、動的かつ多次元の評価フレームワークの必要性が顕著に浮上しています。
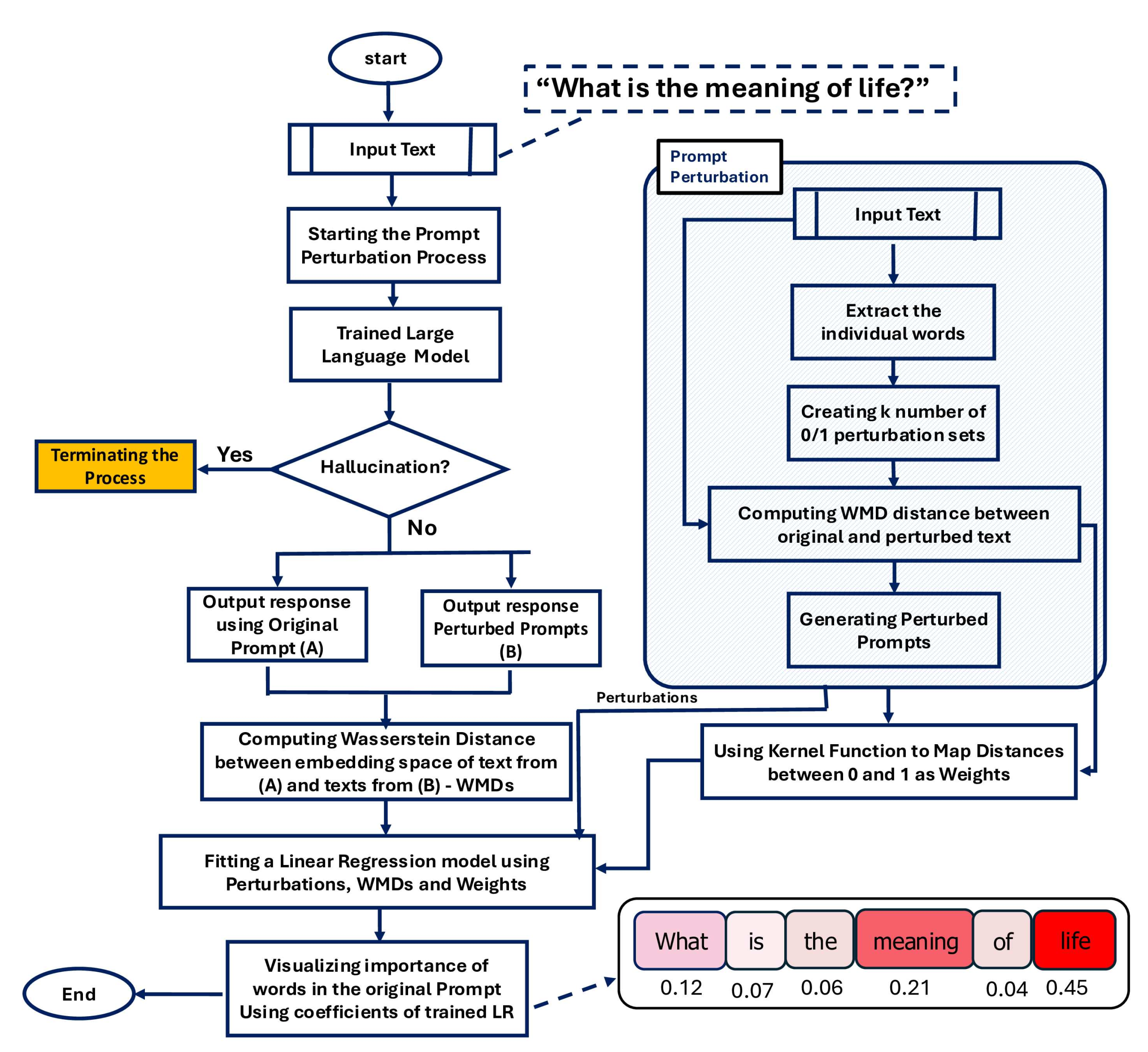
では、XAI(説明可能な人工知能:Explainable AI)は、LLM の回答が正しいか間違っているかを単に評価することを超えて、何を追求しているのでしょうか。それは主に「なぜ」を理解することを目的としています。この観点から、モデル非依存型ローカル説明**は効果的なアプローチであり、SMILE ベースの最先端フレームワークなどがこれに該当します(SMILE は Statistical Model-Agnostic Interpretability with Local Explanations の略)。これらのフレームワークは、ユーザープロンプト(モデル入力)におけるわずかな変更が生成されるテキストに与える影響を分析します。これらは基本的な近接度測定の使用に限定されず、むしろ高度で厳密な統計的距離測定量を適用します。その結果、入力(例えば単語)のどの部分が特定の出力を生成する際のモデルの決定において最も影響力を持っていたかを特定できる、視覚的なヒートマップなどの堅牢な成果物を構築することが可能になります。
以下の図は、モデルの透明性がほとんどない、あるいは全くないという課題に対処する方法を示しています。SMILE を基盤としたフレームワークである gSMILE を用いることで、LLM がプロンプトの異なる部分に対してどのように応答するかを説明することができます。
 image**
image**
gSMILE は、LLM がプロンプトの各部分にどのように応答するかを説明します | 画像提供:LLM-SMILE
これらの最先端フレームワークを用いて LLM の内部推論を評価できることは、一見すると素晴らしいことに思えるかもしれません。しかし、大規模でクローズドソースの LLM の場合、膨大な数の API 呼び出しを処理する必要があるため、ローカルでプロンプトごとの説明を構築することは容易に高コストとなり得ます。この課題は、最近の研究 で指摘されているように、アクセスしやすく予算にも優しいソリューションの必要性を生み出しました。この方向性において、研究者たちは、プロプライエタリな LLM の本来複雑な意思決定境界を近似・簡略化するための手段として、より小さくオープンソースのモデルを採用するプロキシ(仲介)ソリューションを開発しました。このメカニズムはコストを大幅に削減しながらも高忠実度の説明を保証するため、モデルの解釈可能性が一般の開発者にも身近なものとなっています。
理論的・科学的な進展を超えて、実用的な観測可能性へのシフトも高まっており、エンジニアリングでは CometLLM などの追跡プラットフォームに依存しています。これらのフレームワークは説明可能性の民主化を目的として設計されており、プロンプトの反復試行、細粒度のメタデータ、過去の実行のトレースなどを捕捉することができます。その結果、開発者は深い数学的知識を必要とせずに、パイプラインのデバッグやワークフローの再現性を確保できるようになります。
# まとめ
分析された進展と展望から、LLM XAI(説明可能な大規模言語モデル)の広大なエコシステムが急速に加速していることが結論づけられます。研究の爆発的増加と、無料で利用可能なソリューションの登場の中で、コミュニティ主導による LLM XAI のハブが不可欠なものとなっています。堅牢な統計評価と、予算面でも手頃なエンジニアリングアプローチを組み合わせることが、ブラックボックスを徐々に解きほぐし、強力であるだけでなく信頼性が高く透明性の高いモデルを普及させるための鍵となります。
さらに読むべき主要参考文献:
- Awesome-LLM-Explainability (GitHub リポジトリ)
- R. Olson. 2025 Year in Review for LLM Evaluation: When the Scorecard Broke, Goodeye Labs, 2025.
- J. Liu, et al. Revitalizing Black-Box Interpretability: Actionable Interpretability for LLMs via Proxy Models (arXiv)。
- LLM-SMILE (GitHub リポジトリ)
- S. Tripathi. A Hands-on Guide on CometLLM for LLM Explainability. ADaSci, 2024.
Iván Palomares Carrascosa は、AI、機械学習、深層学習、および大規模言語モデル(LLM)におけるリーダー、作家、スピーカー、そしてアドバイザーです。彼は、現実世界で AI を活用する方法を他者に指導・訓練しています。
原文を表示
**
# Introduction
AI Explainability (XAI) has dominated the real-world AI systems landscape over the past few years, with large language models (LLMs) being no exception. In these highly complex and powerful models, transitioning from static to dynamic evaluation becomes imperative to better understand how these black-box systems generate natural language outputs. In addition, synthesizing dynamic evaluation with robust statistical approaches and affordable, production-ready frameworks for observability are also pivotal trends under the radar in the industry.
This article discusses LLM explainability and outlines the advances, trends, and ongoing developments in this important field of study that attempts to measure, interpret, and better manage one of the most sophisticated forms of AI systems to date.
Even though LLMs have revolutionized the AI field as a whole, their inner workings remain largely opaque. High-stakes industries are increasingly turning to LLMs, deploying complex, specialized models where decisions made based upon their responses can have a significant impact. In this context, XAI, and more particularly LLM explainability, becomes more relevant than ever before.
The model's ability and "intelligence" to make decisions has been classically measured via public, static benchmarks. Yet recent studies suggest the traditional scorecard has broken down, with models' behavioral shift towards memorizing public tests instead of proving true reasoning. The need for dynamic, multidimensional evaluation frameworks has significantly arisen: these frameworks evaluate systems against novel scenarios grounded by experts.
But what does XAI really seek beyond merely evaluating whether an LLM is correct or incorrect in its responses? It primarily seeks to understand *why*. In this sense, model-agnostic local explanations constitute an effective approach, with state-of-the-art frameworks like SMILE**-based ones — SMILE being an acronym for Statistical Model-Agnostic Interpretability with Local Explanations — that analyze the impact of slight alterations in user prompts (model inputs) on the resulting generated text. These frameworks do not limit themselves to using basic proximity measurements. Instead, they apply advanced, rigorous statistical distance measures. As a result, they can build robust artifacts like visual heatmaps that pinpoint which parts of the input (e.g. words) were most influential in the model's decision to generate a certain output.
The following diagram shows how to address the issue of little or no model transparency. gSMILE, a framework based on SMILE, can be used to explain how LLMs respond to different parts of a prompt.
**
gSMILE explains how LLMs provide responses to distinct parts of a prompt | Image by LLM-SMILE
Having these cutting-edge frameworks for evaluating LLMs' internal reasoning may sound fantastic at first glance. However, building local, prompt-wise explanations can easily become prohibitive when it comes to massive, closed-source LLMs, as these models manage a huge volume of API calls. This motivated the need for solutions that are accessible and budget-friendly, as pointed out in recent studies. In this direction, researchers have built a proxy solution that employs smaller, open-source models as a means to approximate and simplify the otherwise complex decision boundaries of proprietary LLMs. Their mechanism ensures high-fidelity explanations as costs are significantly reduced, which makes model interpretability accessible even for everyday developers.
Beyond theoretical and scientific progress, there are increasing shifts towards practical observability, with engineering relying on tracking platforms such as CometLLM**. These frameworks, envisioned to democratize explainability, can capture prompt iterations, granular metadata, and traces of previous executions. Consequently, developers gain the ability to debug pipelines and make workflows reproducible, all without the need for a deep mathematical understanding.
# Summing Up
**
The progress and prospects analyzed lead us to conclude that the vast ecosystem of LLM XAI is rapidly accelerating. Amid this explosion of research and the appearance of free-friendly solutions, community-driven hubs for LLM XAI are becoming essential. A combination of robust statistical evaluation with engineering approaches positioned on the budget-friendly side of the spectrum is key to gradually opening the black box and promoting models that are not only powerful, but also trustworthy and transparent.
Key references, for further reading:
- Awesome-LLM-Explainability (GitHub Repository)
- R. Olson. 2025 Year in Review for LLM Evaluation: When the Scorecard Broke, Goodeye Labs, 2025.
- J. Liu, et al. Revitalizing Black-Box Interpretability: Actionable Interpretability for LLMs via Proxy Models (arXiv).
- LLM-SMILE (GitHub Repository)
- S. Tripathi. A Hands-on Guide on CometLLM for LLM Explainability. ADaSci, 2024.
Iván Palomares Carrascosa** is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み