AI評価指標はパレート曲線へ移行すべきである
著者らは、コストを考慮しない AI エージェントの精度評価が誤ったインセンティブを生んでいると指摘し、パラメータ数ではなく実際の金銭的コストを含めたパレート曲線による評価への転換を提言している。
キーポイント
コスト無視の評価の欠陥
現在のリーダーボードはコストを考慮しないため、100 倍のコストでわずかな精度向上しか得られないエージェントが不当に上位に表示される傾向がある。
パレート曲線による可視化の提案
精度とコストのトレードオフを「パレート曲線」で可視化することで、真に効率的なシステムを識別し、無制限な推論計算への依存を防ぐべきである。
パラメータ数の誤解
コストの代理指標としてパラメータ数を用いることは誤りであり、エージェントの複雑さや反復呼び出しによる実際の金銭的コストを直接測定する必要がある。
複雑なエージェントアーキテクチャの非効率性
HumanEval のトップとされる複雑なエージェント(LDB, LATS, Reflexion)は、単純なベースライン手法と比較して精度で優れておらず、むしろコストが桁違いに高いことが判明した。
簡易ベースラインの優位性
試行回数によるリトライや温度パラメータの変更、安価なモデルから高価なモデルへエスカレーションする戦略など、単純な手法が既存のエージェントよりパレート最適(コストと精度のトレードオフ)であることを示した。
研究におけるコスト指標の欠如
同様の精度を達成できるにもかかわらずエージェント間でコストが2桁も異なる場合があるのに、現在の論文では実行コストが主要な評価指標として報告されていない。
複雑な手法の過大評価と単純ベースラインの重要性
多くの研究は、計画やリフレクションなどの複雑な「System 2」アプローチが精度向上の主因であると信じているが、実際には単純なウォーミング戦略でも同等の結果が得られる場合がある。
重要な引用
If we eke out a 2% accuracy improvement for 100x the cost, is that really better?
Maximizing accuracy can lead to unbounded cost
Proxies for cost such as parameter count are misleading if the goal is to identify the best system for a given task.
Our most striking result is that agent architectures for HumanEval do not outperform our simpler baselines despite costing more.
Our simple baselines offer Pareto improvements over existing agent architectures.
papers making claims about the usefulness of agents have so far failed to test if simple agent baselines can lead to similar accuracy.
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発における「精度至上主義」がもたらす非効率性と経済的リスクを鋭く指摘しており、ベンチマーク設計の根本的な見直しを迫る重要な提言である。業界全体がコスト対効果を重視する評価基準へ移行することで、実用性の高いシステム開発への転換を促し、研究リソースの最適配分につながる可能性がある。
編集コメント
精度のみを追求する現在の業界の風潮に対し、経済的合理性という視点から警鐘を鳴らす鋭い分析です。開発者はリーダーボードの順位だけでなく、実運用におけるコスト対効果を常に意識すべきでしょう。
Sayash Kapoor, Benedikt Stroebl, Arvind Narayanan による
コード生成において最も正確な AI システムはどれか?驚くべきことに、現時点でこのような質問に答えるための良い方法は存在しません。
コード生成のための広く使用されているベンチマークである HumanEval に基づけば、公開利用可能なシステムの中で最も正確なのは LDB(LLM デバッガーの略)です。1 しかし、そこには落とし穴があります。LDB を含む最も正確な生成 AI システムは、GPT-4 などの言語モデルを繰り返し呼び出すエージェントである傾向にあります。2 つまり、それらを実行するコストは、モデル自体(すでにかなり高額ですが)よりも桁違いに高くなる可能性があります。100 倍のコストをかけても精度が 2% しか向上しない場合、それが本当に良いことなのでしょうか?
本稿では、以下の主張を行います。
コストを統制しない AI エージェントの精度測定は有用ではありません。
パレート曲線(Pareto curves)は、精度とコストのトレードオフを可視化するのに役立ちます。
現在の最先端のエージェントアーキテクチャは複雑で高コストですが、場合によっては 50 分の 1 のコストで済む極めて単純なベースラインエージェントよりも正確ではありません。
特定のタスクに対して最適なシステムを特定することを目的とする場合、パラメータ数などのコストの代理指標は誤解を招きます。代わりに、直接ドル単位の費用を測定すべきです。
標準化の欠如や、場合によっては疑問の余地がある文書化されていない評価手法のため、公開されたエージェントの評価は再現が困難です。
精度の最大化は無制限のコストにつながる可能性があります
LLM は確率的です。モデルを何度も呼び出して最も一般的な回答を出力するだけで、精度を向上させることができます。
ある種のタスクでは、精度を向上させるために使用できる推論計算量に実質的な上限がないように見えます。3 Google Deepmind の AlphaCode は、自動コード評価における精度の向上を示しましたが、これは LLM を数百万回呼び出した場合でもこの傾向が成り立つことを示しています。
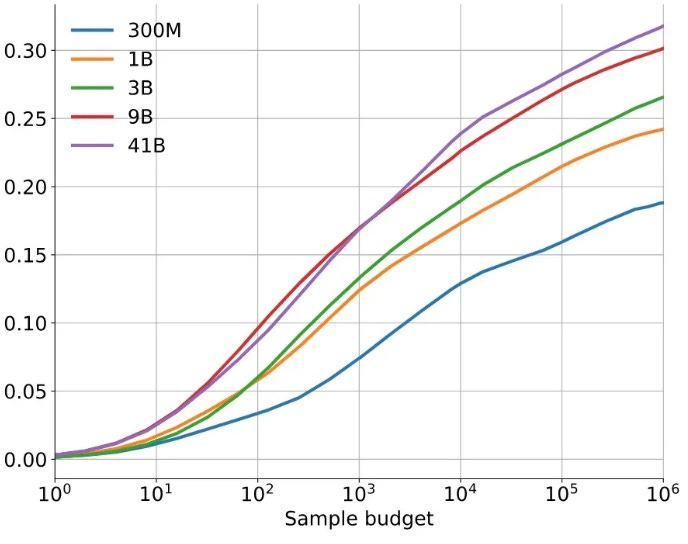
AlphaCode のコードタスクにおける精度は、基盤となるモデルへの呼び出しを 100 万回行った後も継続して向上しています(異なる曲線はパラメータ数の違いを表します)。精度は、モデルが生成した上位 10 個の回答のうち、どれほど頻繁に正解が含まれるかによって測定されます。
したがって、エージェントの有効な評価では、「それにはどの程度のコストがかかったのか?」と問う必要があります。コスト制御された比較を行わない場合、研究者がリーダーボードで首位を占めるために極めて高コストのエージェントを開発することを促すことになりかねません。
実際、過去 1 年間にコードタスクの解決のために提案されたエージェントを評価すると、コストと精度のトレードオフを可視化することで驚くべき洞察が得られることがわかりました。
AI Snake Oil に購読して新しい投稿を受け取る。
HumanEval における精度とコストのトレードオフの可視化(新規ベースライン付き)
HumanEval リーダーボード上で上位を占めると主張されている 3 つのエージェント、LDB、LATS、および Reflexion の精度を再評価しました。また、これらのエージェントを実行する際のコストと所要時間についても評価を行いました。
これらのエージェントは、モデルによって生成されたコードを実行することに依存しており、問題記述に付随するテストケースで失敗した場合、コードのデバッグを試みたり、コード生成プロセスにおける代替経路を探したり、別の解決策を生成する前にモデルの出力がなぜ誤っていたかを「反省」したりします。
さらに、いくつかの単純なベースラインについても、精度、コスト、実行時間を計算しました:
GPT-3.5 および GPT-4 モデル(ゼロショット;エージェントアーキテクチャなし)
Retry(再試行): 問題記述に付随するテストケースで失敗した場合、温度をゼロに設定したモデルを最大 5 回繰り返し呼び出します。LLM は温度がゼロであっても決定論的ではないため、再試行は理にかなっています。
Warming(ウォーミング): これは Retry と同じ戦略ですが、各実行ごとに基盤となるモデルの温度を 0 から 0.5 まで徐々に上昇させます。これによりモデルの確率的性質が高まり、少なくとも 1 つの再試行が成功する可能性が高まると期待しています。
Escalation(エスカレーション): 安価なモデル(Llama-3 8B)から開始し、テストケースで失敗した場合に、より高価なモデル(GPT-3.5、Llama-3 70B、GPT-4)へとエスカレーションします。
驚くべきことに、提案されたエージェントアーキテクチャを後述の3つの単純なベースラインと比較した論文は存在しないようです。
最も印象的な結果は、HumanEval におけるエージェントアーキテクチャが、よりコストがかかるにもかかわらず、私たちの単純なベースラインを上回っていないという点です。実際、エージェントのコストには劇的な差があります:ほぼ同等の精度を達成する場合でも、コストは約2桁も異なる可能性があります!8 しかし、これらのエージェントを実行するコストは、どの論文においても主要指標として報告されていません。

私たちの単純なベースラインは、既存のエージェントアーキテクチャに対してパレート改善(Pareto improvements)を提供します。各エージェントを5回実行し、164 件の HumanEval 問題における平均精度と平均総コストを報告しました。LDB の結果に2つのモデル/エージェントが括弧で示されている場合は、コード生成に使用された言語モデルまたはエージェントに続き、コードデバッグに使用された言語モデルを示しています。1つだけの場合、同じモデルがコードの生成とデバッグの両方に使用されたことを意味します。なお、y軸は0.7から1まで表示されています。完全な軸(0 から 1)と誤差棒、堅牢性チェック、および実証結果に関するその他の詳細については付録に含まれています。
ウォーミング戦略と最高パフォーマンスのエージェントアーキテクチャの間には、精度において有意な差はありません。しかし、Reflexion と LDB はウォーミング戦略よりも 50% 以上コストがかかり、10 LATS はさらに 50 倍以上のコストがかかります(これらのコストはすべて、または主に GPT-4 への呼び出しによるものなので、モデルコストが変化してもこれらの比率は安定します)。一方、エスカレーション戦略は精度を厳密に向上させながら、現在の推論価格では LDB (GPT-3.5) の半分未満のコストで済みます。11
私たちの結果は、別の根本的な問題を指摘しています。エージェントの有効性について主張する論文はこれまで、単純なエージェントのベースラインが同様の精度をもたらす可能性をテストしてこなかったのです。これにより、計画 (planning)、リフレクション (reflection)、デバッグといった複雑なアイデアが精度向上の原因であると AI 研究者の間で広く信じられるようになりました。実際、Lipton と Steinhardt は、2018 年にすでに AI 文献において実証的な成果の源泉を特定できていないという傾向を指摘していました。
私たちの発見に基づけば、デバッグやリフレクション、およびその他の「システム 2」アプローチがコード生成に有用かどうかという問いは依然として未解決です。12 これらは HumanEval で表されているよりも難しいプログラミングタスクにおいては有用になる可能性があります。現時点では、「システム 2」アプローチに対する過度な楽観主義は、以下で報告する再現性と標準化の欠如によってさらに悪化しています。13
コストの代理指標は誤解を招く
一見すると、ドル単位の費用を報告するのは違和感があります。これは、私たちが当然視しているベンチマークの多くの性質を壊すものです:測定値が時間とともに変化しない(一方、コストは低下する傾向がある)こと、そして異なるモデルが公平な競争条件で競い合うこと(一方、一部の開発者は規模の経済により恩恵を受け、推論コストが低くなる可能性がある)ことです。このため、研究者たちは通常、パレート曲線の別の軸としてパラメータ数などを選択します。
費用を報告することの欠点は確かに存在しますが、以下にその緩和方法について説明します。より重要なのは、パラメータ数などの属性をコストの代理指標として使用することは誤りであり、解決しようとしている問題を解決していないと考えることです。なぜそうなのかを理解するには、概念的な区別を導入する必要があります。
AI 評価には少なくとも2つの明確な目的があります。モデル開発者や AI 研究者は、トレーニングデータやアーキテクチャの変更が精度をどのように向上させるかを特定するためにこれらを使用します。これを「モデル評価」と呼びます。また、AI を使用して消費者向け製品を構築するプログラマーなどの下流の開発者は、自社の製品にどの AI システムを採用するかを決定するために評価を利用します。これを「下流評価」と呼びます。
モデル評価と下流評価の違いは過小評価されています。これが、AI の実行コストをどのように考慮すべきかについて多くの混乱を招いてきました。
モデル評価は研究者にとって関心のある科学的な問いです。そのため、前述の理由からドルコストに焦点を当てるのは適切ではありません。むしろ、計算リソース(compute)を統制することが合理的なアプローチとなります:モデル訓練に使用された計算リソースの量を正規化すれば、アーキテクチャの変更やデータ構成の変化が性能向上の原因なのか、単なる計算リソースの増加によるものかを理解できるようになります。特にネイサン・ランバートは、過去 1 年間の精度向上(Meta の Llama 2 など)の多くは、単に計算リソースをより多く使用した結果であると主張しています。
一方、ダウンストリーム評価は調達判断を支援する工学的な問いです。ここではコストこそが実際に注目すべき対象となります。コスト測定における欠点は欠点ではなく、むしろ必要な要素そのものです。推論コストは時間とともに低下し、それはダウンストリームの開発者にとって非常に重要です。評価が時間の経過とともに凍結されたままになることは不要であり、逆効果です。
この文脈において、コストの代理指標(例えばアクティブなパラメータ数や使用される計算リソース量)は誤解を招きます。例えば、Mistral は最新のモデル Mixtral 8x22B とともに、開発者が競合他社ではなく同モデルを選ぶべき理由を説明するために以下の図を発表しました。
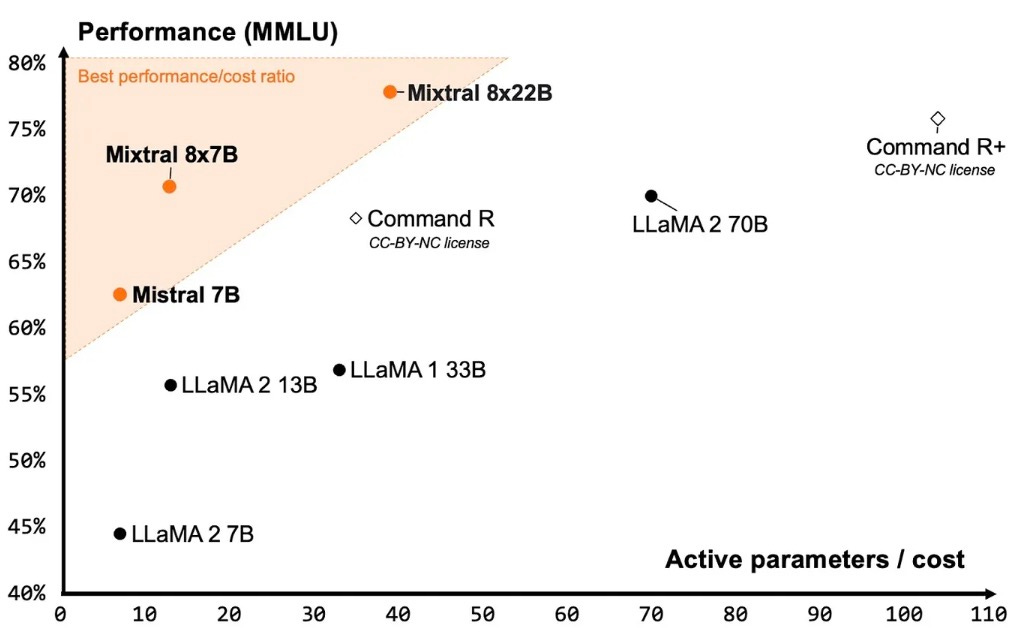
アクティブパラメータをコストの代理指標として用いることは誤解を招く。出典:Mistral。
この図において、アクティブパラメータ(active parameters)の数はコストの代わりにはならない。Anyscale 上では Mixtral 8x7B のコストは Llama 2 13B の約 2 倍であるが、Mistral の図では両者のコストがほぼ同じように示されている。これは彼らがアクティブパラメータの数しか考慮していないためだ。もちろん、API を利用する下流の開発者が気にするのはアクティブパラメータの数ではない。重要なのは精度に対するドル単位の実際の費用だけだ。Mistral は「アクティブパラメータ」を代理指標として選んだが、おそらくそれは Meta の Llama や Cohere の Command R+ といった密結合モデル(dense models)と比較して自社のモデルを有利に見せるためだろう。もしコストの代理指標を使い始めれば、あらゆるモデル開発者が自社モデルを良く見せるための代理指標を選ぶようになる。
コスト評価には依然としていくつかの障壁が残っています。異なるプロバイダーは同じモデルに対して異なる料金を請求する可能性があり、API 呼び出しのコストが一夜にして変化する可能性もあります。また、バッチ API 呼び出しを別料金とするかなど、モデル開発者の判断によってコストが変動する可能性があります。これらの欠点は、モデル実行コストを調整するためのメカニズムを用いて評価結果をカスタマイズ可能にすることで部分的に対処できます。つまり、ユーザーが選択したプロバイダーに対して入力トークンと出力トークンの料金を調整し、コストと精度のトレードオフを再計算できるオプションを提供することです。その結果、エージェントのダウンストリーム評価では、ドル単価に加えて入力/出力トークン数を含めるべきであり、将来誰かが評価を確認する際に、現在の価格を用いて即座にコストを再計算できるようにするためです。
しかし究極のところ、これらの障壁にもかかわらず、優れた測定には関心のある基礎的な構成要素をモデル化することが必要です。ダウンストリーム評価においてその基礎的な構成要素とはコストのことです。他のすべての代理指標は不十分です。
エージェント評価の標準化と再現性の欠如
評価を行う過程で、私たちはエージェント評価における再現性と標準化の多くの欠陥を発見しました。
私たちは、HumanEval における LATS および LDB エージェントの結果を再現できませんでした。特に、LDB(Reflexion, GPT-3.5)のすべての 5 回の試行において、最大精度は 91.5% に留まり、論文で報告された 95.1% よりも大幅に低いものでした。同様に、LATS の最大精度も 5 回の試行全体で 94.4% ではなく 91.5% と低く抑えられていました。
同様に、LDB 論文で報告されているベースライン GPT-4 モデルの精度は、私たちが論文コードを再現した結果(5 回試行の平均 89.6%)と比較して劇的に低い値である 75.0% でした。実際、論文によると、GPT-3.5 と GPT-4 モデルのパフォーマンスは非常に似通っており(それぞれ 73.9% vs. 75.0%)、15 弱いベースラインでは、エージェントアーキテクチャに帰属する改善の規模について誤った安心感を与える可能性があります。
LATS エージェントは、HumanEval ベンチマークで提供されたテストケースの一部のみに対して評価されました。これにより精度の数値が誇張されました。特定の HumanEval 問題に対するコードが不正確であっても、その問題のテストケースの一部にしか合格しなくても、正解としてマークされる可能性があるからです。私たちの分析では、これが 5 回試行の平均で 3% の精度差を生み出し、私たちが発見した精度と論文で報告された精度との間の大きな違いの大部分を説明しています。さらに、ハイパーパラメータ値などの実装に関する多くの詳細が、論文や GitHub リポジトリに記載されていませんでした(詳細は付録を参照してください)。
私たちの知る限り、この投稿は、精度が最も高い4つのエージェント(Retry、Warming、LDB (GPT-4)、および LDB (GPT-4 + Reflexion))が HumanEval 上でテストされたのが初めてのことです。
Reflexion、LDB、そして LATS はすべて、HumanEval の異なるサブセットを使用しています。元のバージョンの HumanEval には、164 問のうち例題テストがないコーディング問題が3問含まれています。これらのエージェントは、デバッグやソリューションの再実行に例題テストを必要とするため、Reflexion は例題テストのない3問を除外します。LATS はこれら3問に加え、報告されていない理由でさらに1問を除外しています。一方、LDB は元のベンチマークで欠落している3問に対して例題テストを追加しました。しかし、この3つの論文のいずれもこれを報告していません。LATS を紹介する論文は(誤って)「実験にはすべての 164 問を使用します」と主張しています。私たちの分析では、すべての評価を LDB が提供するベンチマークバージョン上で行いました。なぜなら、そのバージョンにはすべての問題に対して例題テストが含まれているからです。
LDB の論文は、Reflexion を使用して GPT-3.5 でコード生成を行うと主張しています。「Reflexion については、GPT-3.5 に基づくバージョンを選択し、公式の Github リポジトリで公開された対応する生成プログラムを利用します」とあります。しかし、彼らが Reflexion リポジトリから使用した生成プログラムは、コード生成に GPT-3.5 を使用するのではなく、GPT-4 を利用しています。
これらの実証結果における欠陥は、AI エージェントの精度に関する広範な議論においても誤った解釈を招いています。例えば、アンドリュー・ン氏の最近の投稿では、GPT-3.5 を使用するエージェントが GPT-4 よりも優れた性能を発揮できると主張されました。具体的には、彼は以下のように述べています。
[HumanEval において、] GPT-3.5(ゼロショット)は正答率 48.1% でした。GPT-4(ゼロショット)はより良く、67.0% の成績を収めています。しかし、GPT-3.5 から GPT-4 への改善は、反復的なエージェントワークフロー(agent workflow)を組み込むことによる効果に比べると見劣りします。実際、エージェントループで包まれた GPT-3.5 は最大 95.1% の性能を達成します。
この主張は多くの注目を集めましたが、誤りです。「GPT-3.5 をエージェントワークフローで包んだものが 95.1% の精度を達成する」という主張は、LDB エージェントに関するものと思われます。Papers With Code の HumanEval リーダーボードも同様の主張をしています。しかし、前述の通り、LDB においては GPT-3.5 はバグを見つけるためにのみ使用されており、コード生成には GPT-4(または GPT-4 を使用する Reflexion エージェント)が用いられており、GPT-3.5 が使われているわけではありません。残念ながら、論文内のこの誤りが、広範な AI コミュニティにおいてエージェントに対する過度な楽観主義を招いてしまいました。
Ng氏の投稿は、論文の結果を再検証もせず、プロンプトやモデルバージョンの変更を考慮せずに繰り返すという、よくある誤りを犯しています。例えば、GPT-3.5(48.1%)と GPT-4(67.0%)のゼロショット精度の数値は、2023 年 3 月の GPT-4 技術レポートからそのままコピーされたように見えます。しかし、リリース以来モデルは何度も更新されています。実際、私たちの比較では、LDB 論文で提供されたプロンプトを使用してベースモデルを評価すると、Ng氏の投稿に記載されている数値と比較してはるかに高い性能を示すことが分かりました(GPT-3.5: 73.9%、GPT-4: 89.6%)。その結果、この投稿はエージェントアーキテクチャに起因する改善を大幅に見積もりすぎています。
Stanford の HELM や EleutherAI の LM Evaluation Harness(LM 評価ハッチ)といった評価フレームワークは、標準化された評価結果を提供することで、モデル評価における同様の欠点を解消しようとしています。私たちは特にエージェントのダウンストリーム評価の観点から、エージェントの評価を標準化し再現可能にするための解決策に取り組んでいます。
最後に、ダウンストリームの開発者は、HumanEval やその他の標準化されたベンチマークは、特定のダウンストリームアプリケーションで生じる具体的なタスクに対する単なる大まかな代用指標に過ぎないことを心に留めておく必要があります。実務におけるエージェントの性能を理解するためには、関心のあるドメインからのカスタムデータセット上で評価を行うか、あるいはより良い方法として、本番環境で異なるエージェントを A/B テストする必要があります。
さらに読むべき資料
Zaharia らは、AI ベンチマークにおける最先端の精度はしばしば複合システムによって達成されることを指摘している。エージェントの採用が進めば進むほど、コストと精度をパレート曲線として可視化することがいっそう必要になるだろう。
Santhanam らは、情報検索ベンチマークにおいて精度とともにコストを評価することの重要性を指摘している。
Ozrmazabal らは、MMLU におけるさまざまなモデル(ただしエージェントは含まない)について、出力トークンあたりのコストと精度のトレードオフを強調している。出力トークンのコストが全体のコストの良い指標ではない可能性はあるものの、異なるモデル間で入力トークンのコストや出力長が異なることを考慮すれば、何らかのトレードオフを報告しないよりはマシである。
Berkeley Function Calling リーダーボードには、関数呼び出しに関する言語モデル評価のためのさまざまな指標が含まれており、そこにはコストとレイテンシーも含まれる。
Xie らは、コンピュータ環境におけるエージェントを評価するためのベンチマーク「OSWorld」を開発した。彼らの GitHub リポジトリ(論文内ではないが)では、同ベンチマーク上でさまざまなマルチモーダルエージェントを実行する際の概算コストを示している。
当然ながら、コストと精度のトレードオフに対する主な推進力は、AI を利用する下流の開発者たちから来ている。
以前の講演では、LLM 評価における3つの主要な落とし穴について議論しました。それはプロンプトの感度、構成妥当性、そして汚染です。現在の研究はこれらとはほぼ独立した領域にあり、エージェント評価においてはプロンプト感度は懸念事項ではありません(エージェントには独自のプロンプトを定義する権限が与えられるため);また、下流の開発者はカスタムデータセット上での評価を通じて、汚染と構成妥当性の問題に対処することができます。
本分析の再現に必要なコードはここから入手可能です。付録には、私たちの設定や結果に関する詳細が含まれています。
謝辞
本研究の分析に議論や入力を提供してくれた Rishi Bommasani 氏、Rumman Chowdhury 氏、Percy Liang 氏、Shayne Longpre 氏、Yifan Mai 氏、Nitya Nadgir 氏、Matt Salganik 氏、Hailey Schoelkopf 氏、Zachary Siegel 氏、Venia Veselovsky 氏に感謝いたします。また、NovelQA ベンチマークに関する質問に対して迅速に対応してくれた Cunxiang Wang 氏と Ruoxi Ning 氏にも謝意を表します。
本記事で取り上げている論文の著者の方々には、迅速な回答をいただき、さらにコードを提供していただいたことに深く感謝いたします。これらが再現分析を可能にする第一歩となっています。特に、このブログ投稿の初期草案に対するフィードバックを寄せてくれた Zilong Wang 氏(LDB)、Andy Zhou 氏(LATS)、Karthik Narasimhan 氏(Reflexion)には特にお礼申し上げます。
1 リンク先のページにあるリーダーボードでは、AgentCoder が最も精度の高いシステムとしてリストされています。しかし、このエージェントの結果を再現するためのコードやデータはオンライン上で利用できないため、本ブログ記事ではこれを対象から除外しています。
2 この投稿はエージェントに関するものです。リーダーボードも、基盤となるモデルを評価する上で次第に有用性を失っています。ゲーム可能性など多くの問題がありますが、推論コストの制御が主な問題ではないため、私たちの主張が必ずしも適用されるわけではありません。
3 増加させるタスクでは
原文を表示
By Sayash Kapoor, Benedikt Stroebl, Arvind Narayanan
Which is the most accurate AI system for generating code? Surprisingly, there isn’t currently a good way to answer questions like these.
Based on HumanEval, a widely used benchmark for code generation, the most accurate publicly available system is LDB (short for LLM debugger).1 But there’s a catch. The most accurate generative AI systems, including LDB, tend to be agents,2 which repeatedly invoke language models like GPT-4. That means they can be orders of magnitude more costly to run than the models themselves (which are already pretty costly). If we eke out a 2% accuracy improvement for 100x the cost, is that really better?
In this post, we argue that:
AI agent accuracy measurements that don’t control for cost aren’t useful.
Pareto curves can help visualize the accuracy-cost tradeoff.
Current state-of-the-art agent architectures are complex and costly but no more accurate than extremely simple baseline agents that cost 50x less in some cases.
Proxies for cost such as parameter count are misleading if the goal is to identify the best system for a given task. We should directly measure dollar costs instead.
Published agent evaluations are difficult to reproduce because of a lack of standardization and questionable, undocumented evaluation methods in some cases.
Maximizing accuracy can lead to unbounded cost
LLMs are stochastic. Simply calling a model many times and outputting the most common answer can increase accuracy.
On some tasks, there is seemingly no limit to the amount of inference compute that can improve accuracy.3 Google Deepmind's AlphaCode, which improved accuracy on automated coding evaluations, showed that this trend holds even when calling LLMs millions of times.
The accuracy of AlphaCode on coding tasks continues to improve even after making a million calls to the underlying model (the different curves represent varying parameter counts). Accuracy is measured by how often one of the top 10 answers generated by the model is correct.
A useful evaluation of agents must therefore ask: What did it cost? If we don’t do cost-controlled comparisons, it will encourage researchers to develop extremely costly agents just to claim they topped the leaderboard.
In fact, when we evaluate agents that have been proposed in the last year for solving coding tasks, we find that visualizing the tradeoff between cost and accuracy yields surprising insights.
Subscribe to AI Snake Oil receive new posts.
Visualizing the accuracy-cost tradeoff on HumanEval, with new baselines
We re-evaluated the accuracy of three agents that have been claimed to occupy top spots on the HumanEval leaderboard: LDB, LATS, and Reflexion.4 We also evaluated the cost and time requirements of running these agents.
These agents rely on running the code generated by the model, and if it fails the test cases provided with the problem description, they try to debug the code, look at alternative paths in the code generation process, or "reflect" on why the model's outputs were incorrect before generating another solution.
In addition, we calculated the accuracy, cost, and running time of a few simple baselines:
GPT-3.5 and GPT-4 models (zero shot; no agent architecture5)
Retry: We repeatedly invoke a model with the temperature set to zero, up to five times, if it fails the test cases provided with the problem description.6 Retrying makes sense because LLMs aren’t deterministic even at temperature zero.
Warming: This is the same as the retry strategy, but we gradually increase the temperature of the underlying model with each run, from 0 to 0.5. This increases the stochasticity of the model and, we hope, increases the likelihood that at least one of the retries will succeed.
Escalation: We start with a cheap model (Llama-3 8B) and escalate to more expensive models (GPT-3.5, Llama-3 70B, GPT-4) if we encounter a test case failure.7
Surprisingly, we are not aware of any papers that compare their proposed agent architectures with any of the latter three simple baselines.
Our most striking result is that agent architectures for HumanEval do not outperform our simpler baselines despite costing more. In fact, agents differ drastically in terms of cost: for substantially similar accuracy, the cost can differ by almost two orders of magnitude!8 Yet, the cost of running these agents isn't a top-line metric reported in any of these papers.9
Our simple baselines offer Pareto improvements over existing agent architectures. We run each agent five times and report the mean accuracy and the mean total cost on the 164 HumanEval problems. Where results for LDB have two models/agents in parenthesis, they indicate the language model or agent used to generate the code, followed by the language model used to debug the code. Where they have just one, they indicate that the same model was used to both generate the code and debug it. Note that the y-axis is shown from 0.7 to 1; figures with the full axis (0 to 1) and error bars, robustness checks, and other details about our empirical results are included in the appendix.
There is no significant accuracy difference between the warming strategy and the best-performing agent architecture. Yet, Reflexion and LDB cost over 50% more than the warming strategy,10 and LATS over 50 times more (all these costs are entirely or predominantly from calls to GPT-4, so these ratios will be stable even if model costs change). Meanwhile, the escalation strategy strictly improves accuracy while costing less than half of LDB (GPT-3.5) at current inference prices.11
Our results point to another underlying problem: papers making claims about the usefulness of agents have so far failed to test if simple agent baselines can lead to similar accuracy. This has led to widespread beliefs among AI researchers that complex ideas like planning, reflection, and debugging are responsible for accuracy gains. In fact, Lipton and Steinhardt noted a trend in the AI literature of failing to identify the sources of empirical gains back in 2018.
Based on our findings, the question of whether debugging, reflection, and other such “System 2” approaches are useful for code generation remains open.12 It is possible that they will be useful on harder programming tasks than those represented in HumanEval. For now, the over-optimism about System 2 approaches is exacerbated by a lack of reproducibility and standardization that we report below.13
Proxies for cost are misleading
At first glance, reporting dollar costs is jarring. It breaks many properties of benchmarking that we take for granted: that measurements don’t change over time (whereas costs tend to come down) and that different models compete on a level playing field (whereas some developers may benefit from economies of scale, leading to lower inference costs). Because of this, researchers usually pick a different axis for the Pareto curve, such as parameter count.
The downsides of reporting costs are real, but we describe below how they can be mitigated. More importantly, we think using attributes like parameter count as a proxy for cost is a mistake and doesn’t solve the problem it’s intended to solve. To understand why, we need to introduce a conceptual distinction.
AI evaluations serve at least two distinct purposes. Model developers and AI researchers use them to identify which changes to the training data and architecture improve accuracy. We call this model evaluation. And downstream developers, such as programmers who use AI to build consumer-facing products, use evaluations to decide which AI systems to use in their products. We call this downstream evaluation.
The difference between model evaluation and downstream evaluation is underappreciated. This has led to much confusion about how to factor in the cost of running AI.
Model evaluation is a scientific question of interest to researchers. So it makes sense to stay away from dollar costs for the aforementioned reasons. Instead, controlling for compute is a reasonable approach: if we normalize the amount of compute used to train a model, we can then understand if factors like architectural changes or changes in the data composition are responsible for improvements, as opposed to more compute. Notably, Nathan Lambert argues that many of the accuracy gains in the last year (such as Meta's Llama 2) are simply consequences of using more compute.
On the other hand, downstream evaluation is an engineering question that helps inform a procurement decision. Here, cost is the actual construct of interest. The downsides of cost measurement aren’t downsides at all; they are exactly what’s needed. Inference costs do come down over time, and that greatly matters to downstream developers. It is unnecessary and counterproductive for the evaluation to stay frozen in time.
In this context, proxies for cost (such as the number of active parameters or amount of compute used) are misleading. For example, Mistral released the figure below alongside their latest model, Mixtral 8x22B, to explain why developers should choose it over competitors.
Substituting active parameters as a proxy for cost is misleading. Source: Mistral.
In this figure, the number of active parameters is a poor proxy for cost. On Anyscale, Mixtral 8x7B costs twice as much as Llama 2 13B, yet Mistral's figure shows it costs about the same, because they only consider the number of active parameters. Of course, downstream developers don't care about the number of active parameters when they're using an API. They simply care about the dollar cost relative to accuracy. Mistral chose “active parameters” as a proxy, presumably because it makes their models look better than dense models such as Meta’s Llama and Cohere’s Command R+. If we start using proxies for cost, every model developer can pick a proxy that makes their model look good.
Some hurdles to cost evaluation remain. Different providers can charge different amounts for the same model, the cost of an API call might change overnight, and cost might vary based on model developer decisions, such as whether bulk API calls are charged differently. These downsides can be partly addressed by making the evaluation results customizable using mechanisms to adjust the cost of running models, i.e., providing users the option to adjust the cost of input and output tokens for their provider of choice to recalculate the tradeoff between cost and accuracy. In turn, downstream evaluations of agents should include input/output token counts in addition to dollar costs, so that anyone looking at the evaluation in the future can instantly recalculate the cost using current prices.
But ultimately, despite the hurdles, good measurement requires modeling the underlying construct of interest. For downstream evaluations, that underlying construct is cost. All other proxies are lacking.
Agent evaluations lack standardization and reproducibility
In the course of our evaluation, we found many shortcomings in the reproducibility and standardization of agent evaluations.
We were unable to reproduce the results of the LATS and LDB agents on HumanEval. In particular, across all 5 runs for LDB (Reflexion, GPT-3.5), the maximum accuracy was 91.5%, much lower than the 95.1% reported in the paper.14 The maximum accuracy of LATS across all five runs was similarly lower, at 91.5% instead of 94.4%.
Similarly, the accuracy for the baseline GPT-4 model reported in the LDB paper is drastically lower than our reproduction of the paper's code (75.0% vs. a mean of 89.6% across five runs). In fact, according to the paper, the GPT-3.5 and GPT-4 models perform very similarly (73.9% vs. 75.0%).15 Weak baselines could give a false sense of the amount of improvement attributable to the agent architecture.
The LATS agent was evaluated on only a subset of the test cases provided in the HumanEval benchmark. This exaggerated their accuracy numbers, since the code for a particular HumanEval problem might be incorrect, but if it passes only a portion of the test cases for that problem, it could still be marked as correct. In our analysis, this was responsible for a 3% difference in accuracy (mean across five runs), which explains a substantial part of the difference between the accuracy we found and the one reported in the paper. In addition, many details about the implementation, such as hyperparameter values, were not reported in the paper or GitHub repository (see appendix for details).
To the best of our knowledge, this post is the first time the four agents with the highest accuracy—Retry, Warming, LDB (GPT-4), and LDB (GPT-4 + Reflexion)—have been tested on HumanEval.16
Reflexion, LDB, and LATS all use different subsets of HumanEval. Three (out of 164) coding problems in the original version of HumanEval lack example tests. Since these agents require example tests to debug or rerun their solutions, Reflexion removes the three problems that don't have example tests. LATS removes these three problems, plus another problem, for unreported reasons.17 LDB adds example tests for the three problems that are missing in the original benchmark. None of the three papers reports this. The paper introducing LATS claims (incorrectly): "We use all 164 problems for our experiments."18 In our analysis, we conducted all evaluations on the version of the benchmark provided by LDB, since it contains example tests for all problems.
The LDB paper claims to use GPT-3.5 for code generation using Reflexion: "For Reflexion, we select the version based on GPT-3.5 and utilize the corresponding generated programs published in the official Github repository." However, the generated program they used from the Reflexion repository relies on GPT-4 for code generation, not GPT-3.5.19
These shortcomings in the empirical results have also led to errors of interpretation in broader discussions around the accuracy of AI agents. For example, a recent post by Andrew Ng claimed that agents that use GPT-3.5 can outperform GPT-4. In particular, he claimed:
[For HumanEval,] GPT-3.5 (zero shot) was 48.1% correct. GPT-4 (zero shot) does better at 67.0%. However, the improvement from GPT-3.5 to GPT-4 is dwarfed by incorporating an iterative agent workflow. Indeed, wrapped in an agent loop, GPT-3.5 achieves up to 95.1%.
While this claim received a lot of attention, it is incorrect. The claim ("GPT-3.5 wrapped in an agent workflow achieves 95.1% accuracy") seems to be about the LDB agent. The Papers With Code leaderboard for HumanEval makes the same claim. However, as we discussed above, for LDB, GPT-3.5 is only used to find bugs. The code is generated using GPT-4 (or the Reflexion agent that uses GPT-4), not GPT-3.5. Unfortunately, the error in the paper has led to much overoptimism about agents in the broader AI community.
Ng's post also makes the familiar error of repeating results from papers without verifying them or accounting for changes in prompts and model versions. For example, the zero-shot accuracy numbers of GPT-3.5 (48.1%) and GPT-4 (67.0%) seem to be copied from the GPT-4 technical report from March 2023. However, the models have been updated many times since release. Indeed, in our comparison, we find that the base models perform much better compared to the claimed figures in Ng's post when we use them with the prompts provided with the LDB paper (GPT-3.5: 73.9%, GPT-4: 89.6%). As a result, the post drastically overestimates the improvement attributable to agent architectures.
Evaluation frameworks like Stanford's HELM and EleutherAI's LM Evaluation Harness attempt to fix similar shortcomings for model evaluations, by providing standardized evaluation results. We are working on solutions to make agent evaluations standardized and reproducible, especially from the perspective of downstream evaluation of agents.
Finally, downstream developers should keep in mind that HumanEval or any other standardized benchmark is nothing more than a rough proxy for the specific tasks that arise in a particular downstream application. To understand how agents will perform in practice, it is necessary to evaluate them on a custom dataset from the domain of interest — or even better, A/B test different agents in the production environment.
Further reading
Zaharia et al. observe that state-of-the-art accuracy on AI benchmarks is often attained by composite systems. If the adoption of agents continues, visualizing cost and accuracy as a Pareto curve would become even more necessary.
Santhanam et al. point out the importance of evaluating cost alongside accuracy for information retrieval benchmarks.
Ozrmazabal et al. highlight the accuracy vs. cost per output token tradeoffs for various models (but not agents) on MMLU. While the cost of output tokens might not be a good indicator of the overall cost, given the varying input token costs as well as output lengths for different models, it is better than not reporting the tradeoffs at all.
The Berkeley Function Calling leaderboard includes various metrics for language model evaluations of function calling, including cost and latency.
Xie et al. develop OSWorld, a benchmark for evaluating agents in computer environments. In their GitHub repository (though not in the paper), they give a rough cost estimate for running various multimodal agents on their benchmark.
Unsurprisingly, the main impetus for cost vs. accuracy tradeoffs has come from the downstream developers who use AI.
In a previous talk, we discussed three major pitfalls in LLM evaluation: prompt sensitivity, construct validity, and contamination. The current research is largely orthogonal: prompt sensitivity isn’t a concern for agent evaluation (as agents are allowed to define their own prompts); downstream developers can address contamination and construct validity by evaluating on custom datasets.
The code for reproducing our analysis is available here. The appendix includes more details about our setup and results.
Acknowledgments
We thank Rishi Bommasani, Rumman Chowdhury, Percy Liang, Shayne Longpre, Yifan Mai, Nitya Nadgir, Matt Salganik, Hailey Schoelkopf, Zachary Siegel, and Venia Veselovsky for discussions and inputs that informed our analysis. We acknowledge Cunxiang Wang and Ruoxi Ning for their prompt responses to our questions about the NovelQA benchmark.
We are grateful to the authors of the papers we engage with in this post for their quick responses and for sharing their code, which makes such reproduction analysis possible in the first place. In particular, we are grateful to Zilong Wang (LDB), Andy Zhou (LATS), and Karthik Narasimhan (Reflexion), who gave us feedback in response to an earlier draft of this blog post.
1The leaderboard on the linked page lists AgentCoder as the most accurate system. However, the code or data for reproducing the results of this agent are not available online, so we do not consider it in this blog post.
2This post is about agents. Leaderboards are also becoming less useful for evaluating the underlying models. There are many problems, including gameability. But controlling for inference cost isn’t the main problem, so our arguments don’t necessarily apply.
3Tasks where increas
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み