AWS Lambdaを使用したAmazon Novaモデルカスタマイズのための効果的な報酬関数の構築方法
AWSの公式ブログ記事は、Amazon Novaモデルのカスタマイズにおいて、AWS Lambdaを活用して効果的な報酬関数を構築する方法を、実用的なコード例とともに解説している。
キーポイント
報酬関数の重要性とAWS Lambdaの利点
Amazon Novaモデルのカスタマイズ手法である強化学習によるファインチューニング(RFT)の中核を成す報酬関数の構築に、スケーラブルでコスト効率の良い基盤としてAWS Lambdaのサーバーレスアーキテクチャが活用できる。
教師ありファインチューニング(SFT)と強化学習によるファインチューニング(RFT)の比較
SFTは明確な入出力例がある場合に有効だが、RFTは最終出力に対する評価信号から学習し、望ましい行動をモデルに教えることができる。
報酬関数の設計手法の選択
客観的に検証可能なタスクにはRLVRを、主観的評価が必要なタスクにはRLAIFを選択し、報酬ハッキングを防ぐための多次元報酬システムの設計が重要である。
実装と運用のガイダンス
トレーニング規模に合わせたLambda関数の最適化、Amazon CloudWatchを用いた報酬分布の監視、および実際に実験を始めるための動作コード例とデプロイガイダンスが提供されている。
Novaモデル向け回答抽出関数の実装
chABSAタスク用に、Novaフォーマットの応答から感情極性を抽出する関数extract_answer_novaを提供している。まずsolutionブロック内のboxed形式を探し、なければ全文から探し、最後にキーワード検索を行う三段階のフォールバック構造を持つ。
AWS Lambdaでの報酬関数実装アーキテクチャ
Lambdaハンドラー内で、各サンプルの参照回答とモデル応答を比較し、RewardOutputオブジェクトを生成する報酬計算パイプラインを示している。データセットのID管理やエラーハンドリングの基本構造が含まれている。
RLVR関数の3つの重要な設計要素
効果的な学習のために、部分的な正解を認める滑らかな報酬地形の作成、複数の解析戦略を用いた堅牢な抽出ロジックの実装、不正な入力によるクラッシュを防ぐ防御的コーディングの実践が必要です。
重要な引用
At the heart of RFT lies the reward function—a scoring mechanism that guides the model toward better responses.
Lambda’s serverless architecture lets you focus on defining quality criteria while it handles the computational infrastructure.
You’ll learn to choose between Reinforcement Learning via Verifiable Rewards (RLVR) for objectively verifiable tasks and Reinforcement Learning via AI Feedback (RLAIF) for subjective evaluation, design multi-dimensional reward systems that help you prevent reward hacking
def extract_answer_nova(solution_str: str) -> Optional[str]: """Extract sentiment polarity from Nova-formatted response for chABSA."""
def compute_score( solution_str: str, ground_truth: str, format_score: float = 0.0, score: float = 1.0, data_source: str = 'chabsa', extra_info: Optional[dict] = None ) -> float: """chABSA scoring function with VeRL-compatible signature."""
Your RLVR function should incorporate three critical design elements for effective training. First, create a smooth reward landscape by awarding partial credit... Second, implement good extraction logic with multiple parsing strategies... Third, validate inputs at every step using defensive coding practices
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルのカスタマイズを実務レベルで進めようとする開発者や企業に対して、クラウドネイティブな実装アプローチを具体的に示している。AWSのサービス統合を前提とした実用的なガイドは、同社のAI/MLエコシステムの利用促進と、より洗練されたモデル調整技術の普及に寄与する可能性がある。
編集コメント
AWSの自社サービス(AWS Lambda, Amazon Nova, Amazon CloudWatch)を組み合わせた実用的なチュートリアルであり、技術的な深みと実装ガイドの両方を備えている。ただし、内容は特定のクラウドプロバイダーとその製品に強く依存している点に注意が必要。
効果的な報酬関数の構築は、AWS Lambda がスケーラブルで費用対効果の高い基盤を提供することで、Amazon Nova モデルを特定のニーズに合わせてカスタマイズするのに役立ちます。Lambda のサーバーレスアーキテクチャにより、計算インフラストラクチャの管理に気を配ることなく、品質基準の定義に集中できます。
Amazon Nova には複数のカスタマイズアプローチがありますが、反復的なフィードバックを通じてモデルに望ましい行動を学習させる能力を持つ 強化学習ファインチューニング(Reinforcement fine-tuning、RFT)が際立っています。注釈付きの推論パスを持つ数千件のラベル付けされた例を必要とする 教師ありファインチューニング(Supervised fine-tuning、SFT)とは異なり、RFT は最終出力に対する評価信号から学習します。RFT の中核にあるのが報酬関数であり、これはより良い回答へとモデルを導くスコアリングメカニズムです。
この投稿では、Lambda が Amazon Nova のカスタマイズにおいてスケーラブルでコスト効率の高い報酬関数をどのように実現するかを示します。客観的に検証可能なタスクには Reinforcement Learning via Verifiable Rewards (RLVR) を、主観的な評価には Reinforcement Learning via AI Feedback (RLAIF) を選択する方法、報酬ハッキング(Reward Hacking)を防ぐための多次元報酬システムの設計、トレーニング規模に応じた Lambda 関数の最適化、そして Amazon CloudWatch を用いた報酬分布の監視について学びます。実験を開始するための動作コード例とデプロイメントガイドラインが含まれています。
AWS Lambda を用いたコードベース報酬の構築
基盤モデルのカスタマイズには複数のアプローチがあり、それぞれが異なるシナリオに適しています。明確な入力と出力の例が存在し、特定の応答パターンを学習させたい場合、SFT(Supervised Fine-Tuning:教師ありファインチューニング)が優れています。これは、分類や固有表現認識、あるいはドメイン固有の用語や書式規則へのモデル適応といったタスクにおいて特に効果的です。望ましい振る舞いが例を通じて示せる場合、SFT は一貫したスタイル、構造、または事実知識の伝達を教えるのに理想的です。しかし、一部のカスタマイズ課題には異なるアプローチが必要です。カスタマーサービス応答のように、正確性、共感、簡潔さ、ブランドとの整合性という複数の品質次元を同時にバランスさせる必要があるアプリケーションや、数千もの注釈付き推論パスを作成することが現実的でない場合、強化学習に基づく手法がより優れた代替案となります。RFT(Reinforcement Fine-Tuning:強化学習ファインチューニング)は、正しい推論プロセスの網羅的なラベル付き例を必要とするのではなく、評価信号から学習することで、これらのシナリオに対応します。
AWS Lambda を活用した報酬関数は、フィードバックベースの学習を通じてこのプロセスを簡素化します。モデルに数千もの効果的な例を示す代わりに、プロンプトを提供し、回答を採点する評価ロジックを定義することで、モデルは反復的なフィードバックを通じて改善する方法を学習します。このアプローチはラベル付きの例を少なく済みつつ、望ましい動作に対する精密な制御を提供します。多次元のスコアリングは、モデルが近道を利用するのを防ぐ細やかな品質基準を捉え、Lambda のサーバーレスアーキテクチャはインフラストラクチャ管理なしで可変のトレーニングワークロードを処理します。その結果、深い機械学習の専門知識を持たない開発者でもアクセス可能な Nova のカスタマイズが可能になり、一方で洗練された本番環境でのユースケースにも十分な柔軟性を備えています。
AWS Lambda ベースの報酬関数の仕組み
RFT アーキテクチャは、Amazon Nova のトレーニングパイプラインと統合されるサーバーレスの報酬評価系として AWS Lambda を使用し、モデルの学習を導くフィードバックループを作成します。このプロセスは、トレーニングジョブが各トレーニングプロンプトに対して Nova モデルから候補回答を生成することから始まります。これらの回答は Lambda 関数に送られ、そこでは正しさ、安全性、書式、簡潔さなどの次元に基づいて回答の品質が評価されます。その後、関数はスカラー数値スコア(ベストプラクティスとして通常 -1 から 1 の範囲)を返します。高いスコアは、それらを生成した行動をモデルが強化するよう導き、低いスコアは、不適切な回答につながったパターンから遠ざかるようモデルを導きます。このサイクルはトレーニング全体を通して数千回繰り返され、より高い報酬を一貫して得る回答へとモデルを段階的に形成していきます。
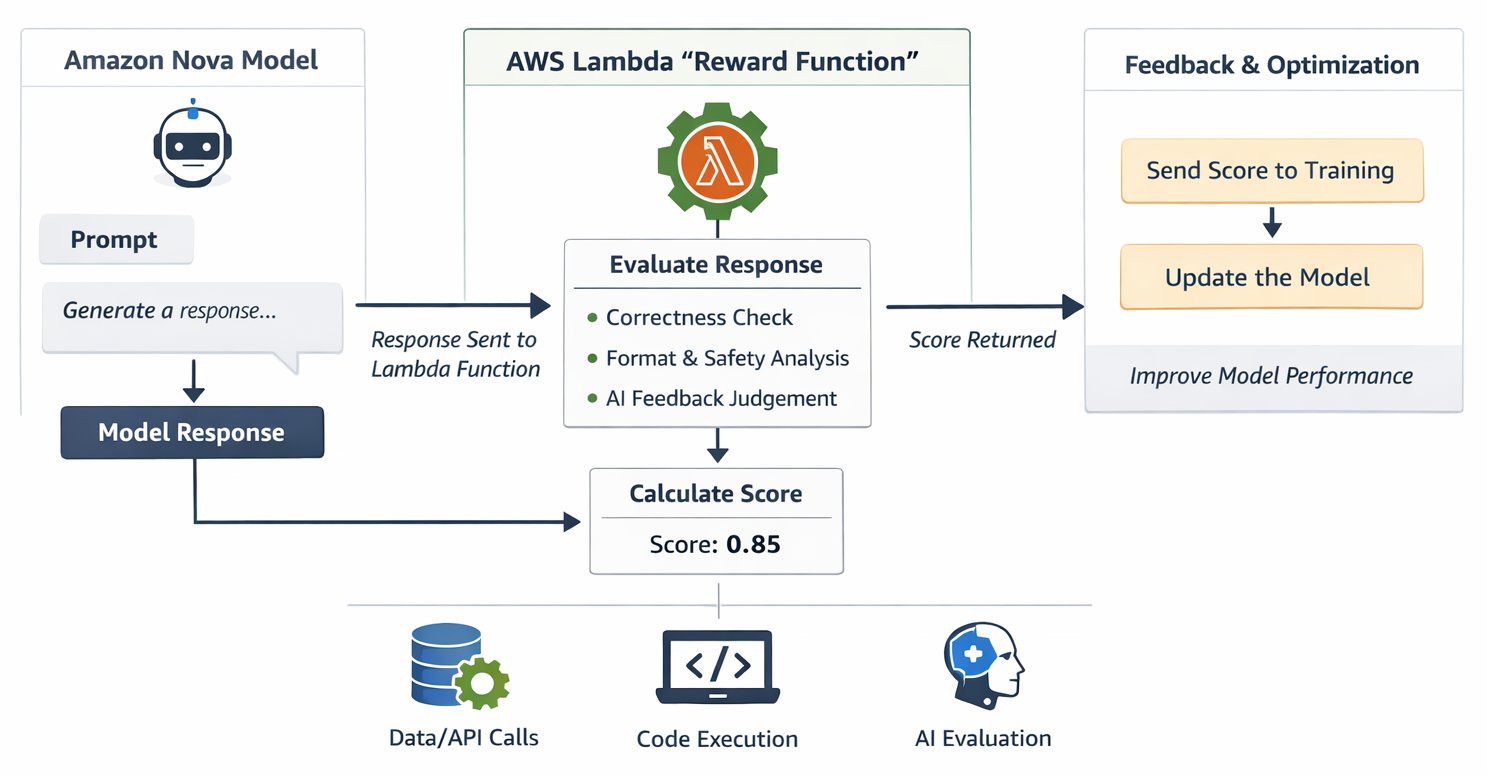
このアーキテクチャは、一貫性のあるカスタマイズソリューションとして複数の AWS サービスを統合しています。Lambda は、インフラストラクチャのプロビジョニングや管理を必要とせずに、変化するトレーニングの需要に対応する自動スケーリング機能で報酬評価ロジックを実行します。Amazon Bedrock は、統合された Lambda サポートを備えた完全に管理された RFT(Reinforcement Fine-Tuning:強化学習によるファインチューニング)体験を提供し、シンプルな Application Programming Interface (API) を介して RLAIF(Reinforcement Learning from AI Feedback:AI フィードバックからの強化学習)実装用の AI judge モデルを提供します。高度なトレーニング制御が必要なチーム向けには、Amazon SageMaker AI が、Amazon SageMaker AI Training Jobs および Amazon SageMaker AI HyperPod を通じてオプションを提供しており、これらはいずれも同じ Lambda ベースの報酬関数をサポートしています。Amazon CloudWatch は、Lambda のパフォーマンスをリアルタイムで監視し、報酬の分布やトレーニングの進捗に関する詳細なデバッグ情報をログに記録し、問題が発生した際にアラートをトリガーします。基盤には Amazon Nova 自身が位置しており、多様なユースケースに最適化されたカスタマイズレシピを備えたモデルは、報酬関数が提供するフィードバック信号に効果的に応答します。
このサーバーレスアプローチにより、Novaのカスタマイズは費用対効果が高まります。Lambdaは、初期の実験段階で毎秒10件の並列評価から、本番環境でのトレーニング時に400件以上の評価まで自動的にスケーリングします。インフラのチューニングやキャパシティプランニングは不要です。単一のLambda関数で複数の品質基準を同時に評価できるため、モデルが単純なスコアリングの抜け道を利用するのを防ぐ、細かく多角的なフィードバックが提供されます。このアーキテクチャは、テストケースに対してコードを実行したり構造化された出力を検証したりするRLVR(Reinforcement Learning from Verifiable Rewards)による客観的な検証と、トーンや有用性などの品質をAIモデルが評価するRLAIF(Reinforcement Learning from AI Feedback)による主観的な判断の両方をサポートします。評価中の実際の計算時間のみに対して、ミリ秒単位の課金粒度で支払いを行うため、実験を低コストで実施できながら、本番環境のコストはトレーニングの強度に比例して調整されます。反復的な開発において最も価値が高いのは、Lambda関数がAmazon SageMaker AI Studioで再利用可能な「Evaluator(評価者)」アセットとして保存され、複数のトレーニング実行にわたってカスタマイズ戦略を洗練する際に一貫した品質測定を維持できる点です。
適切な報酬メカニズムの選択
成功するRFT(Reward Fine-Tuning)の基盤は、適切なフィードバックメカニズムを選択することにあります。2つの補完的なアプローチが異なるユースケースに対応します:RLVRとRLAIFは、大規模言語モデル(LLM)の初期トレーニング後のファインチューニングに使用される2つの技術です。それらの主な違いは、モデルにフィードバックを提供する方法にあります。
RLVR(検証可能な報酬による強化学習)
RLVRは、客観的な正解性を検証するための決定論的コードを使用します。RLVRは、「正しい」答えが数学的または論理的に検証可能なドメイン、例えば数学の問題を解くような場合に設計されています。RLVRは学習済みの報酬モデルの代わりに、決定論的関数を使用して出力を採点します。絶対的な正解が存在しないクリエイティブライティングやブランドボイスのようなタスクでは、RLVRは機能しません。
- 最適な用途:コード生成、数学的推論、構造化された出力タスク
- 例:生成されたコードをテストケースで実行する、APIレスポンスを検証する、計算の正確性を確認する
- 利点:信頼性が高く、監査可能で、決定論的なスコアリング
RLVR関数は、正解に対してプログラマティックに正確性を検証します。ここでは感情分析の例を示します。
from typing import List
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Optional
def extract_answer_nova(solution_str: str) -> Optional[str]:
"""chABSA 用の Nova 形式のレスポンスから感情極性(センチメント・ポリラリティ)を抽出する。"""
# まず、solution ブロックから抽出を試みる
solution_match = re.search(r'(.*?)', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# solution ブロック内の boxed 形式を探す
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# フォールバック:どこにでも boxed 形式を探す
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# 最後の手段:感情キーワードを探す
solution_lower = solution_str.lower()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(answer: str) -> str:
"""比較のために回答を正規化する。"""
return answer.strip().lower()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
score: float = 1.0,
data_source: str = 'chabsa',
extra_info: Optional[dict] = None
) -> float:
"""VeRL互換のシグネチャを持つchABSAスコアリング関数。"""
answer = extract_answer_nova(solution_str)
if answer is None:
return 0.0
# 回答を取得するためにground_truthのJSONを解析する
gt_answer = ground_truth.get("answer", ground_truth)
clean_answer = normalize_answer(answer)
clean_ground_truth = normalize_answer(gt_answer)
return score if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""報酬サービス。"""
id: str
aggregate_reward_score: float
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
for sample in samples:
# 正解(ground truth)のキーを抽出する。現在のデータセットではanswerというキー名になっている
print("Sample: ", json.dumps(sample, indent=2))
ground_truth = sample["reference_answer"]
idx = "no id"
# print(sample)
if not "id" in sample:
print(f"ID is None/empty for sample: {sample}")
else:
idx = sample["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
もし 'messages' がサンプルに含まれていない場合:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# 正解データ辞書から回答を抽出
if ground_truth is None:
print(f"No answer found in ground truth for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# 最後のメッセージ(アシスタントのメッセージ)から完成テキストを取得
last_message = sample["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Last message is not from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
if not "content" in last_message:
print(f"Completion text is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]
効果的なトレーニングのため、RLVR関数には3つの重要な設計要素を組み込む必要があります。第一に、部分評価を与えることで報酬のランドスケープを滑らかにします。例えば、最終回答が不正解でも、適切なレスポンス構造に対してformat_scoreの加点を行います。これにより、学習を困難にするバイナリなスコアリングの急峻さを防ぎます。第二に、多様なレスポンス形式を柔軟に処理できる複数の解析戦略を用いた堅牢な抽出ロジックを実装します。第三に、不正な入力によるクラッシュを防ぐための防御的コーディングプラクティスを用いて、すべてのステップで入力を検証します。
RLAIF (Reinforcement Learning via AI Feedback)
RLAIFは、主観的な評価のためにAIモデルを審判として使用します。RLAIFは、大幅に高速かつ低コストでありながら、RLHF(Reinforcement Learning via Human Feedback)と同等の性能を実現します。以下は、感情分類のためのサンプルRLVR Lambda関数のコード例です。
- 最適な用途: クリエイティブライティング、要約、ブランドボイスの整合性、有用性の評価
- 例: レスポンストーンの評価、コンテンツ品質の判定、ユーザー意図との整合性の判断
- 利点: 手動ラベリングコストなしで、人間のような判断をスケーラブルに実行可能
RLAIF関数は、以下のサンプルコードに示すように、判断を高性能なAIモデルに委譲します
import json
import re
import time
import boto3
from typing import List, Dict, Any, Optional
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
JUDGE_MODEL_ID = "" #Replace with judge model id of your interest
SYSTEM_PROMPT = "You must output ONLY a number between 0.0 and 1.0. No explanations, no text, just the number."
JUDGE_PROMPT_TEMPLATE = """Compare the following two responses and rate how similar they are on a scale of 0.0 to 1.0, where:
- 1.0 means the responses are semantically equivalent (same meaning, even if worded differently)
- 0.5 means the responses are partially similar
- 0.0 means the responses are completely different or contradictory
Response A: {response_a}
Response B: {response_b}
Output ONLY a number between 0.0 and 1.0. No explanations."""
必ずJSON形式で返してください:
{"translation": "翻訳全文", "technical_terms": ["term1", "term2"]}
def extract_solution_nova(solution_str: str, method: str = "strict") -> Optional[str]:
"""Nova 形式のレスポンスから解答を抽出する。"""
assert method in ["strict", "flexible"]
if method == "strict":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].replace(",", "").replace("$", "")
return final_answer
return None
elif method == "flexible":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
numbers = re.findall(r"(\\-?[0-9\\.\\,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].replace(",", "").replace("$", "")
answer = re.findall(r"(\\-?[0-9\\.\\,]+)", solution_str)
if len(answer) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(answer):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Bedrockを呼び出して応答を比較し、類似度スコアを返す。"""
prompt = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for attempt in range(max_retries):
try:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
score = float(output)
return max(0.0, min(1.0, score))
except Exception as e:
if "ThrottlingException" in str(e) and attempt float:
"""train.jsonl形式のスコアを計算する。"""
answer = extract_solution_nova(solution_str=solution_str, method="flexible")
if answer is None:
return 0.0
clean_answer = str(answer)
clean_ground_truth = str(ground_truth)
score = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return score
def lambda_grader(samples: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
train.jsonl 形式のサンプルを処理し、スコアを返します。
Args:
samples: メッセージとメタデータを含む辞書のリスト
Returns:
報酬スコアを含む辞書のリスト
"""
results = []
for sample in samples:
sample_id = sample.get("id", "unknown")
# メタデータまたはトップレベルから参照回答を抽出
metadata = sample.get("metadata", {})
reference_answer = metadata.get("reference_answer", sample.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("answer", "")
else:
ground_truth = str(reference_answer)
# メッセージからアシスタントの応答を取得
messages = sample.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("role") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content", "")
break
if not assistant_response or not ground_truth:
results.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
continue
# スコアを計算
score = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
results.append({
"id": sample_id,
"aggregate_reward_score": score,
"metrics_list": [
{
原文を表示
Building effective reward functions can help you customize Amazon Nova models to your specific needs, with AWS Lambda providing the scalable, cost-effective foundation. Lambda’s serverless architecture lets you focus on defining quality criteria while it handles the computational infrastructure.
Amazon Nova offers multiple customization approaches, with Reinforcement fine-tuning (RFT) standing out for its ability to teach models desired behaviors through iterative feedback. Unlike Supervised fine-tuning (SFT) that requires thousands of labeled examples with annotated reasoning paths, RFT learns from evaluation signals on final outputs. At the heart of RFT lies the reward function—a scoring mechanism that guides the model toward better responses.
This post demonstrates how Lambda enables scalable, cost-effective reward functions for Amazon Nova customization. You’ll learn to choose between Reinforcement Learning via Verifiable Rewards (RLVR) for objectively verifiable tasks and Reinforcement Learning via AI Feedback (RLAIF) for subjective evaluation, design multi-dimensional reward systems that help you prevent reward hacking, optimize Lambda functions for training scale, and monitor reward distributions with Amazon CloudWatch. Working code examples and deployment guidance are included to help you start experimenting.
Building code-based rewards using AWS Lambda
You have multiple pathways to customize foundation models, each suited to different scenarios. SFT excels when you have clear input-output examples and want to teach specific response patterns—it’s particularly effective for tasks like classification, named entity recognition, or adapting models to domain-specific terminology and formatting conventions. SFT works well when the desired behavior can be demonstrated through examples, making it ideal for teaching consistent style, structure, or factual knowledge transfer.However, some customization challenges require a different approach. When applications need models to balance multiple quality dimensions simultaneously—like customer service responses that must be accurate, empathetic, concise, and brand-aligned simultaneously —or when creating thousands of annotated reasoning paths proves impractical, reinforcement-based methods offer a better alternative. RFT addresses these scenarios by learning from evaluation signals rather than requiring exhaustive labeled demonstrations of correct reasoning processes.
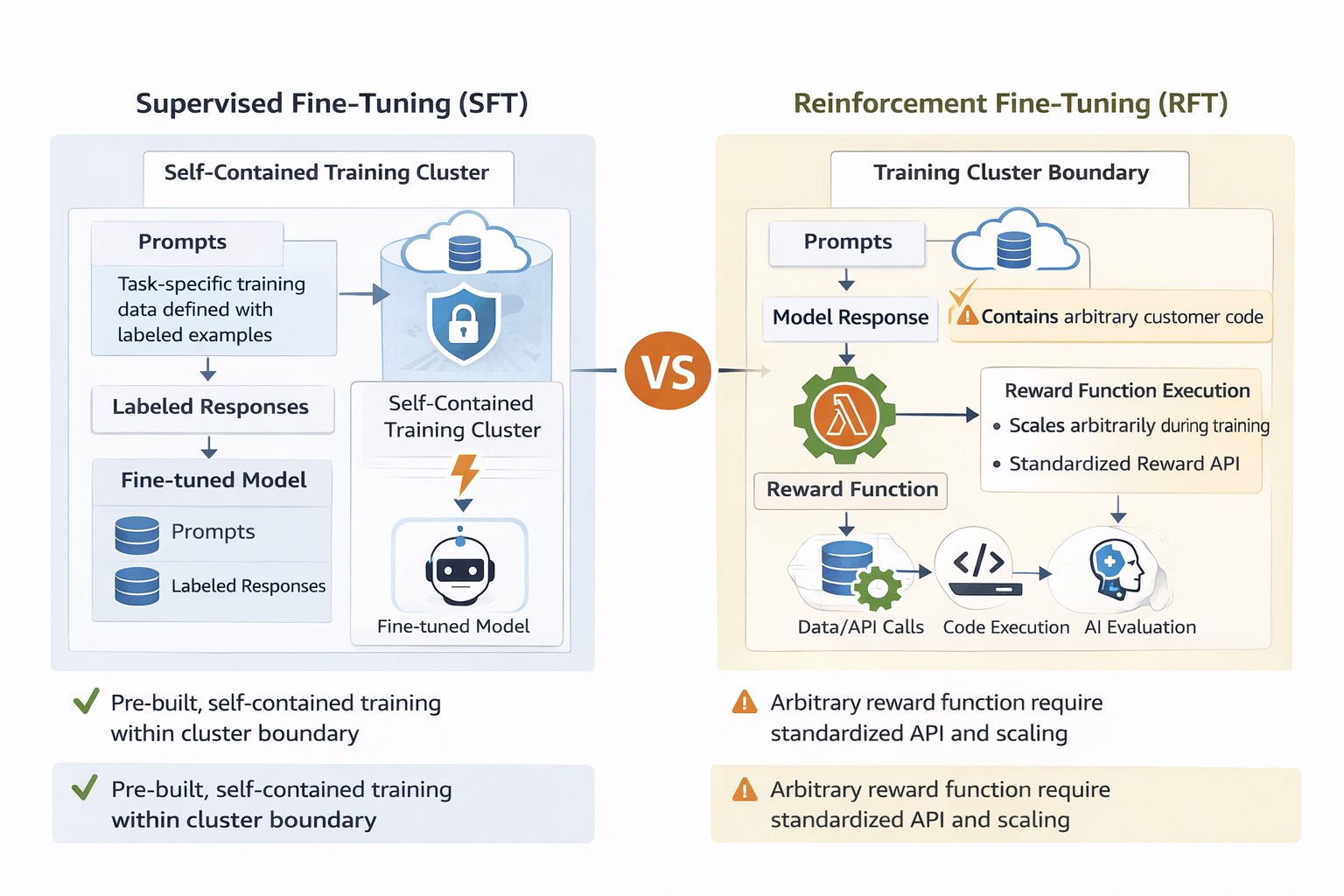
AWS Lambda-based reward functions simplifies this through feedback-based learning. Instead of showing the model thousands of effective examples, you provide prompts and define evaluation logic that scores responses—then the model learns to improve through iterative feedback. This approach requires fewer labelled examples while giving you precise control over desired behaviors. Multi-dimensional scoring captures nuanced quality criteria that prevent models from exploiting shortcuts, while Lambda’s serverless architecture handles variable training workloads without infrastructure management. The result is Nova customization that’s accessible to developers without deep machine learning expertise, yet flexible enough for sophisticated production use cases.
How AWS Lambda based rewards work
The RFT architecture uses AWS Lambda as a serverless reward evaluator that integrates with Amazon Nova training pipeline, creating an feedback loop that guides model learning. The process begins when your training job generates candidate responses from the Nova model for each training prompt. These responses flow to your Lambda function, which evaluates their quality across dimensions like correctness, safety, formatting, and conciseness. The function then returns scalar numerical scores—typically in the -1 to 1 range as a best practice. Higher scores guide the model to reinforce the behaviors that produced them, while lower scores guide it away from patterns that led to poor responses. This cycle repeats thousands of times throughout training, progressively shaping the model toward responses that consistently earn higher rewards.
The architecture brings together several AWS services in a cohesive customization solution. Lambda executes your reward evaluation logic with automatic scaling that handles variable training demands without requiring you to provision or manage infrastructure. Amazon Bedrock provides the fully managed RFT experience with integrated Lambda support, offering AI judge models for RLAIF implementations through a simple Application Programming Interface (API). For teams needing advanced training control, Amazon SageMaker AI offers options through Amazon SageMaker AI Training Jobs and Amazon SageMaker AI HyperPod, both supporting the same Lambda-based reward functions. Amazon CloudWatch monitors Lambda performance in real-time, logs detailed debugging information about reward distributions and training progress, and triggers alerts when issues arise. At the foundation sits Amazon Nova itself—models with customization recipes optimized across a wide variety of use cases that respond effectively to the feedback signals your reward functions provide
This serverless approach makes Nova customization cost-effective. Lambda automatically scales from handling 10 concurrent evaluations per second during initial experimentation to 400+ evaluations during production training, without infrastructure tuning or capacity planning. Your single Lambda function can assess multiple quality criteria simultaneously, providing the nuanced, multi-dimensional feedback that prevents models from exploiting simplistic scoring shortcuts. The architecture supports both objective verification through RLVR—running code against test cases or validating structured outputs—and subjective judgment through RLAIF, where AI models evaluate qualities like tone and helpfulness. You pay only for actual compute time during evaluation with millisecond billing granularity, making experimentation affordable while keeping production costs proportional to training intensity. Perhaps most valuable for iterative development, Lambda functions save as reusable “Evaluator” assets in Amazon SageMaker AI Studio, enabling you to maintain consistent quality measurement as you refine your customization strategy across multiple training runs.
Choosing the right rewards mechanism
The foundation of successful RFT is choosing the right feedback mechanism. Two complementary approaches serve different use cases: RLVR and RLAIF are two techniques used to fine-tune large language models (LLMs) after their initial training. Their major difference lies in how they provide feedback to the model.
RLVR (Reinforcement Learning via Verifiable Rewards)
RLVR uses deterministic code to verify objective correctness. RLVR is designed for domains where a “correct” answer can be mathematically or logically verified, for example, solving a math problem. RLVR uses deterministic functions to grade outputs instead of a learned reward model. RLVR fails for tasks like creative writing or brand voice where no absolute ground truth exists.
- Best for: Code generation, mathematical reasoning, structured output tasks
- Example: Running generated code against test cases, validating API responses, checking calculation accuracy
- Advantage: Reliable, auditable, deterministic scoring
RLVR functions programmatically verify correctness against ground truth. Here in this example doing sentiment analysis.
from typing import List
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Optional
def extract_answer_nova(solution_str: str) -> Optional[str]:
"""Extract sentiment polarity from Nova-formatted response for chABSA."""
# First try to extract from solution block
solution_match = re.search(r'(.*?)', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# Look for boxed format in solution block
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# Fallback: look for boxed format anywhere
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# Last resort: look for sentiment keywords
solution_lower = solution_str.lower()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(answer: str) -> str:
"""Normalize answer for comparison."""
return answer.strip().lower()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
score: float = 1.0,
data_source: str = 'chabsa',
extra_info: Optional[dict] = None
) -> float:
"""chABSA scoring function with VeRL-compatible signature."""
answer = extract_answer_nova(solution_str)
if answer is None:
return 0.0
# Parse ground_truth JSON to get the answer
gt_answer = ground_truth.get("answer", ground_truth)
clean_answer = normalize_answer(answer)
clean_ground_truth = normalize_answer(gt_answer)
return score if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""Reward service."""
id: str
aggregate_reward_score: float
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
for sample in samples:
# Extract the ground truth key. In the current dataset it's answer
print("Sample: ", json.dumps(sample, indent=2))
ground_truth = sample["reference_answer"]
idx = "no id"
# print(sample)
if not "id" in sample:
print(f"ID is None/empty for sample: {sample}")
else:
idx = sample["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
if not "messages" in sample:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Extract answer from ground truth dict
if ground_truth is None:
print(f"No answer found in ground truth for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Get completion from last message (assistant message)
last_message = sample["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Last message is not from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
if not "content" in last_message:
print(f"Completion text is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]
Your RLVR function should incorporate three critical design elements for effective training. First, create a smooth reward landscape by awarding partial credit—for example, providing format_score points for proper response structure even when the final answer is incorrect. This prevents binary scoring cliffs that make learning difficult. Second, implement good extraction logic with multiple parsing strategies that handle various response formats gracefully. Third, validate inputs at every step using defensive coding practices that prevent crashes from malformed inputs
RLAIF (Reinforcement Learning via AI Feedback)
RLAIF uses AI models as judges for subjective evaluation. RLAIF achieves performance comparable to RLHF(Reinforcement Learning via Human Feedback) while being significantly faster and less costly. Here is an example RLVR lambda function code for sentiment classification.
- Best for: Creative writing, summarization, brand voice alignment, helpfulness
- Example: Evaluating response tone, assessing content quality, judging user intent alignment
- Advantage: Scalable human-like judgment without manual labeling costs
RLAIF functions delegate judgment to capable AI models as shown in this sample code below
import json
import re
import time
import boto3
from typing import List, Dict, Any, Optional
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
JUDGE_MODEL_ID = "" #Replace with judge model id of your interest
SYSTEM_PROMPT = "You must output ONLY a number between 0.0 and 1.0. No explanations, no text, just the number."
JUDGE_PROMPT_TEMPLATE = """Compare the following two responses and rate how similar they are on a scale of 0.0 to 1.0, where:
- 1.0 means the responses are semantically equivalent (same meaning, even if worded differently)
- 0.5 means the responses are partially similar
- 0.0 means the responses are completely different or contradictory
Response A: {response_a}
Response B: {response_b}
Output ONLY a number between 0.0 and 1.0. No explanations."""
def extract_solution_nova(solution_str: str, method: str = "strict") -> Optional[str]:
"""Extract solution from Nova-formatted response."""
assert method in ["strict", "flexible"]
if method == "strict":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].replace(",", "").replace("$", "")
return final_answer
return None
elif method == "flexible":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
numbers = re.findall(r"(\\-?[0-9\\.\\,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].replace(",", "").replace("$", "")
answer = re.findall(r"(\\-?[0-9\\.\\,]+)", solution_str)
if len(answer) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(answer):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Call Bedrock to compare responses and return similarity score."""
prompt = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for attempt in range(max_retries):
try:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
score = float(output)
return max(0.0, min(1.0, score))
except Exception as e:
if "ThrottlingException" in str(e) and attempt float:
"""Compute score for train.jsonl format."""
answer = extract_solution_nova(solution_str=solution_str, method="flexible")
if answer is None:
return 0.0
clean_answer = str(answer)
clean_ground_truth = str(ground_truth)
score = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return score
def lambda_grader(samples: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
Process samples from train.jsonl format and return scores.
Args:
samples: List of dictionaries with messages and metadata
Returns:
List of dictionaries with reward scores
"""
results = []
for sample in samples:
sample_id = sample.get("id", "unknown")
Extract reference answer from metadata or top level
metadata = sample.get("metadata", {})
reference_answer = metadata.get("reference_answer", sample.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("answer", "")
else:
ground_truth = str(reference_answer)
Get assistant response from messages
messages = sample.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("role") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content", "")
break
if not assistant_response or not ground_truth:
results.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
continue
Compute score
score = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
results.append({
"id": sample_id,
"aggregate_reward_score": score,
"metrics_list": [
{
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み